RDD概述
RDD最初的概述来源于一片论文-伯克利实验室的Resilient Distributed Datasets:A Fault-Tolerant Abstraction for In-Memory Cluster Computing。这篇论文奠定了RDD基本功能的思想
RDD实际为Resilient Distribution Datasets的简称,意为弹性分布式数据集
RDD的基本属性
1、分区
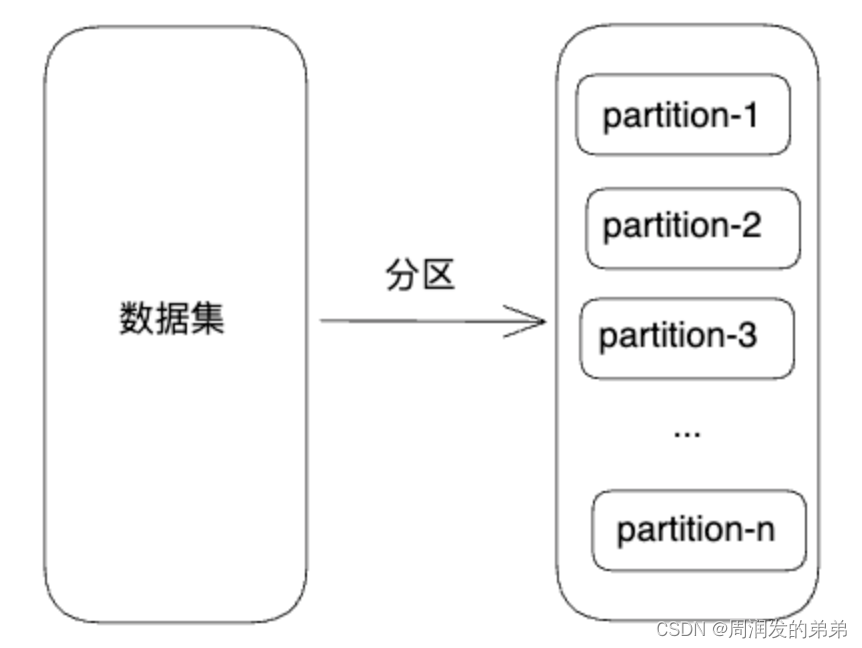
RDD的中文含义是弹性分布式数据集,其中分区的概念实现了分布式所需的功能。每个分区中包含一部分数据,通过对每个分区的数据计算以及最后对结果数据的汇总,从而实现对整个数据集的计算。RDD的计算是以分区为单位进行的,而且同一分区的所有数据都进行相同的计算。对于同一分区的数据而言,要么全执行,要么全不执行。理论上分区越多,能够并行计算任务数据越多,但还是会收到物理资源如CPU等的限制。
2、计算函数
RDD的数据被分区了,但是每个分区的数据是如何来的呢,一个RDD的数据来源只有两种:一是从数据源或集合中进行加载运行的到RDD的数据;而是通过其他RDD进行一定的转换的来的数据,无论哪种方式,RDD的数据都是通过其计算函数得到的。计算函数compute返回值为迭代器器类型。
如Spark在加载HDFS中的数据时,每个分区的数据通过计算函数加载对应的block块的数据,从而实现了数据分布式加载的过程,如下图

Spark还可以从集合中创建RDD,实现每个分区加载集合中的一部分数据,如SparkContext中实现的parallelize的并行集合的方法。甚至可以自定义分区函数实现特定加载数据的方式,如将历史数据按照时间分区进行加载

3、依赖
在RDD进行转换过程中,子RDD是通过父RDD转换而来的。但在具体的实现过程中,所有RDD的数据都是通过其计算函数而得到的,所以,子RDD在计算过程中需要得到父RDD的,分局父RDD的数据算出子RDD每个分区的数据。
在RDD计算时有些子RDD的一个分区只依赖父RDD的一个分区,即每个父RDD的分区最多被子RDD的一个分区所使用,则这种依赖方式称为窄依赖,如下图

在RDD计算时,如果一个分区的数据依赖了父RDD多个分区的数据,即多个子RDD的分区数据依赖了父RDD的同一个分区的数据,这种依赖方式称为宽依赖

4、分区器
并不是所有的RDD都有分区器(partitioner),一般只有(Key,Value)形式的RDD才有分区器。分区器在Shuffle的Map阶段使用,当RDD的计算发生Shuffle时,Map阶段虽然将结果进行保存,供Reduce阶段的任务来拉取数据,但是Map阶段的每个分区的数据可能会被Reduce阶段的多个分区使用。如何把Map阶段的数据进行分组,区分出时给Reduce阶段的RDD哪个分区使用呢,这就是分区器(pattitioner)的作用

5、首选运行位置
每个RDD对于每个分区来说都有一组首选运行位置,用于表示RDD的这个分区数据最好能在哪台主机上运行。通过RDD的首选运行位置,可以让RDD的某个分区的计算任务直接在指定主机上运行,从而实现了移动计算而不是移动数据的目的,减小了网络传输的开销,如Spark中HadoopRDD能够实现加载数据的任务在相应的数据节点上执行
RDD的缓存
如果一个RDD在计算完成后,不是通过流水线的方式被一个RDD调用,而是被多个RDD调用,则在计算过程中就需要对RDD进行缓存,避免二次计算。尤其是一个RDD经过多次特别复杂的Shuffle生成的数据,缓存之后可以极大的提升程序运行的效率。
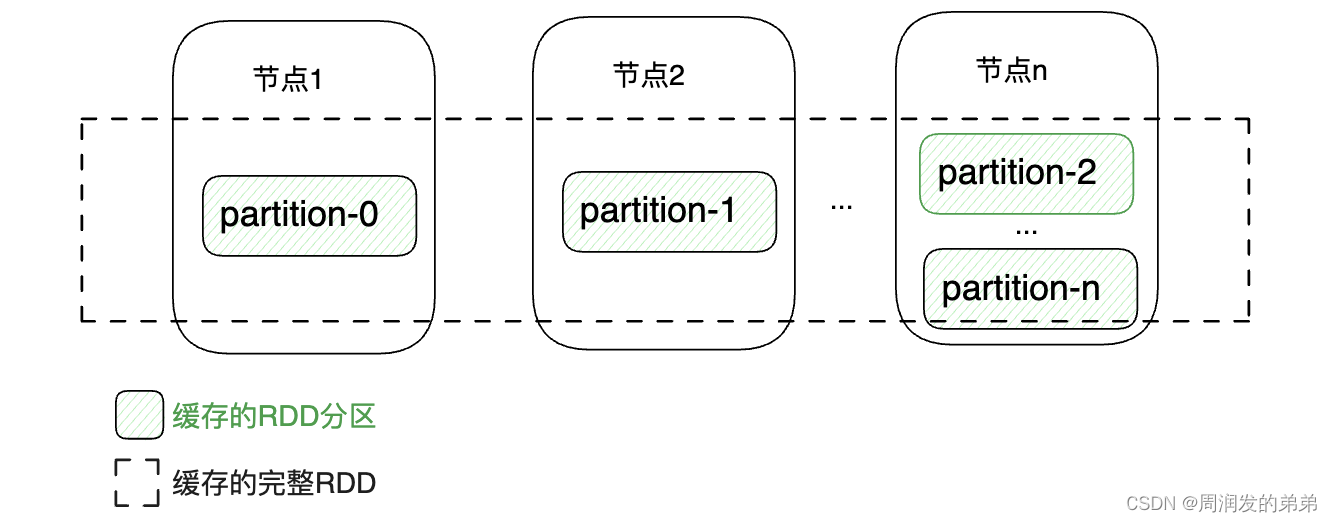
因为RDD是分布式的,不同的分区散落在不同的物理节点上,所以RDD的缓存也是分布式的。让对RDD进行缓存时,可以将每个分区的数据直接缓存在当前计算节点,每个计算节点缓存一部分数据,完成整个RDD的缓存,如图
RDD的容错机制
RDD的容错时通过lineage机制实现的。因为每个RDD的数据都可以通过其父RDD转换而来。如果运行的过程中,某一个分区的数据丢失,则重新计算该分区的数据。当此RDD的依赖时窄依赖时,只需要计算依赖的父RDD的一个分区的数据即可,避免了一个节点出错则所有数据节点都重新计算的缺点。但是如果丢失数据的RDD的依赖是宽依赖,那么分区的数据可能是父依赖的所有分区数据,这种情况下必须重新计算父RDD分区的所有数据,从而完成数据的恢复
Spark RDD的操作
Spark定义了很多对RDD的操作,主要分为两类:transformation 和 action。transformation操作并不会真正的触发Job的执行,它只是定义了RDD和RDD之间的lineage,只有action操作才会触发Job的真正执行。
1、transformation操作
在Spark中,主要的transformation操作如下
| 操作 | 说明 |
|---|---|
| map | 迭代RDD中的每个元素生成新的RDD |
| filter | 对RDD的元素进行过滤 |
| flatMap | 和Map类似,将每个元素转为0个或多个元素 |
| mapPartitions | 迭代每个分区,这在操作数据库时,可以将每个分区创建一个连接 |
| distinct | 将数据去重,涉及shuffle |
| groupByKey | 按照Key进行分组 |
| reduceByKey | 按照Key进行聚合 |
| union | 将两个RDD整合成一个RDD |
| coalesce | 减小分区数量,一般用在执行filter,过滤掉大量数据后调用 |
| repartition | 重新分区,这会在城所有的数据进行shuffle |
2、action操作
| 操作 | 说明 |
|---|---|
| collect | 将所有的数据作为一个数据返回Driver程序。当每个分区数据较多,返回Driver中时,可能会造成内存溢出。 |
| count | 返回RDD数据的总数 |
| first | 返回RDD中的第一个元素 |
| take | 将RDD中的前n个元素作为数组返回 |
| saveAsTextFile | 将数据写入文件系统 |
| foreach | 对RDD中的每个元素都应用给定的函数 |
| reduce | 按照给定的函数将数据聚合 |
![[技术杂谈]nvidia-smi参数和显示信息解释](https://img-blog.csdnimg.cn/direct/5116fb18173e4e2c9634ec902c9de805.jpeg)