背景
部门内有一些亿级别核心业务表增速非常快,增量日均100W,但线上业务只依赖近一周的数据。随着数据量的迅速增长,慢SQL频发,数据库性能下降,系统稳定性受到严重影响。本篇文章,将分享如何使用MyBatis拦截器低成本的提升数据库稳定性。
业界常见方案
针对冷数据多的大表,常用的策略有以2种:
1. 删除/归档旧数据。
2. 分表。
归档/删除旧数据
定期将冷数据移动到归档表或者冷存储中,或定期对表进行删除,以减少表的大小。此策略逻辑简单,只需要编写一个JOB定期执行SQL删除数据。我们开始也是用这种方案,但此方案也有一些副作用:
1.数据删除会影响数据库性能,引发慢sql,多张表并行删除,数据库压力会更大。
2.频繁删除数据,会产生数据库碎片,影响数据库性能,引发慢SQL。
综上,此方案有一定风险,为了规避这种风险,我们决定采用另一种方案:分表。
分表
我们决定按日期对表进行横向拆分,实现让系统每周生成一张周期表,表内只存近一周的数据,规避单表过大带来的风险。
分表方案选型
经调研,考虑2种分表方案:Sharding-JDBC、利用Mybatis自带的拦截器特性。
经过对比后,决定采用Mybatis拦截器来实现分表,原因如下:
1.JAVA生态中很常用的分表框架是Sharding-JDBC,虽然功能强大,但需要一定的接入成本,并且很多功能暂时用不上。
2.系统本身已经在使用Mybatis了,只需要添加一个mybaits拦截器,把SQL表名替换为新的周期表就可以了,没有接入新框架的成本,开发成本也不高。
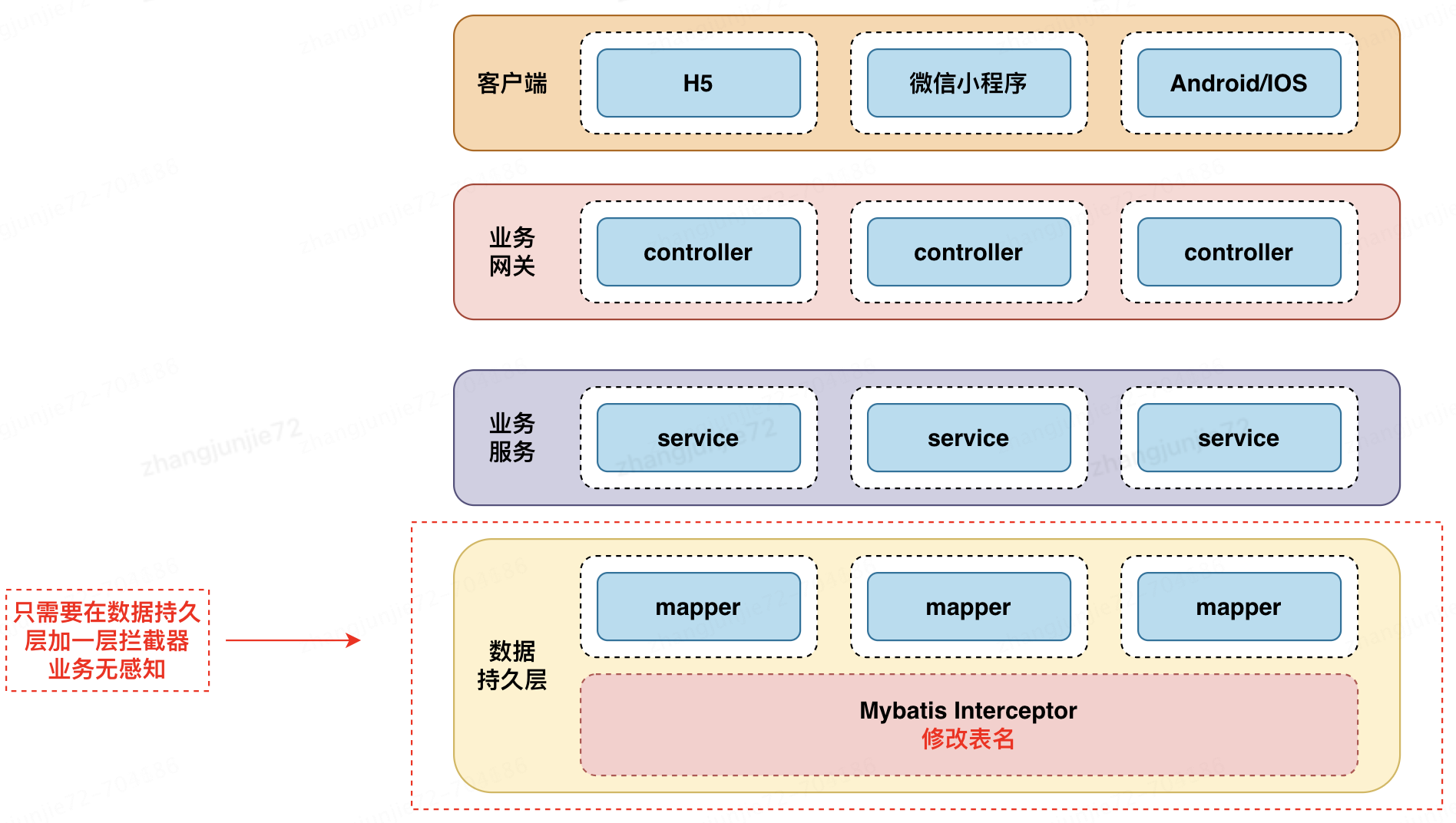
分表具体实现代码
分表配置对象
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;import java.util.Date;@Data
@AllArgsConstructor
@NoArgsConstructor
public class ShardingProperty {// 分表周期天数,配置7,就是一周一分private Integer days;// 分表开始日期,需要用这个日期计算周期表名private Date beginDate;// 需要分表的表名private String tableName;
}分表配置类
import java.util.concurrent.ConcurrentHashMap;public class ShardingPropertyConfig {public static final ConcurrentHashMap<String, ShardingProperty> SHARDING_TABLE = new ConcurrentHashMap<>();static {ShardingProperty orderInfoShardingConfig = new ShardingProperty(15, DateUtils.string2Date("20231117"), "order_info");ShardingProperty userInfoShardingConfig = new ShardingProperty(7, DateUtils.string2Date("20231117"), "user_info");SHARDING_TABLE.put(orderInfoShardingConfig.getTableName(), orderInfoShardingConfig);SHARDING_TABLE.put(userInfoShardingConfig.getTableName(), userInfoShardingConfig);}
}拦截器
import lombok.extern.slf4j.Slf4j;
import o2o.aspect.platform.function.template.service.TemplateMatchService;
import org.apache.commons.lang3.StringUtils;
import org.apache.ibatis.executor.statement.StatementHandler;
import org.apache.ibatis.mapping.BoundSql;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.plugin.*;
import org.apache.ibatis.reflection.DefaultReflectorFactory;
import org.apache.ibatis.reflection.MetaObject;
import org.apache.ibatis.reflection.ReflectorFactory;
import org.apache.ibatis.reflection.factory.DefaultObjectFactory;
import org.apache.ibatis.reflection.factory.ObjectFactory;
import org.apache.ibatis.reflection.wrapper.DefaultObjectWrapperFactory;
import org.apache.ibatis.reflection.wrapper.ObjectWrapperFactory;
import org.springframework.stereotype.Component;import java.sql.Connection;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.Date;
import java.util.Properties;@Slf4j
@Component
@Intercepts({@Signature(type = StatementHandler.class, method = "prepare", args = {Connection.class, Integer.class})})
public class ShardingTableInterceptor implements Interceptor {private static final ObjectFactory DEFAULT_OBJECT_FACTORY = new DefaultObjectFactory();private static final ObjectWrapperFactory DEFAULT_OBJECT_WRAPPER_FACTORY = new DefaultObjectWrapperFactory();private static final ReflectorFactory DEFAULT_REFLECTOR_FACTORY = new DefaultReflectorFactory();private static final String MAPPED_STATEMENT = "delegate.mappedStatement";private static final String BOUND_SQL = "delegate.boundSql";private static final String ORIGIN_BOUND_SQL = "delegate.boundSql.sql";private static final DateTimeFormatter FORMATTER = DateTimeFormatter.ofPattern("yyyyMMdd");private static final String SHARDING_MAPPER = "com.jd.o2o.inviter.promote.mapper.ShardingMapper";private ConfigUtils configUtils = SpringContextHolder.getBean(ConfigUtils.class);@Overridepublic Object intercept(Invocation invocation) throws Throwable {boolean shardingSwitch = configUtils.getBool("sharding_switch", false);// 没开启分表 直接返回老数据if (!shardingSwitch) {return invocation.proceed();}StatementHandler statementHandler = (StatementHandler) invocation.getTarget();MetaObject metaStatementHandler = MetaObject.forObject(statementHandler, DEFAULT_OBJECT_FACTORY, DEFAULT_OBJECT_WRAPPER_FACTORY, DEFAULT_REFLECTOR_FACTORY);MappedStatement mappedStatement = (MappedStatement) metaStatementHandler.getValue(MAPPED_STATEMENT);BoundSql boundSql = (BoundSql) metaStatementHandler.getValue(BOUND_SQL);String originSql = (String) metaStatementHandler.getValue(ORIGIN_BOUND_SQL);if (StringUtils.isBlank(originSql)) {return invocation.proceed();}// 获取表名String tableName = TemplateMatchService.matchTableName(boundSql.getSql().trim());ShardingProperty shardingProperty = ShardingPropertyConfig.SHARDING_TABLE.get(tableName);if (shardingProperty == null) {return invocation.proceed();}// 新表String shardingTable = getCurrentShardingTable(shardingProperty, new Date());String rebuildSql = boundSql.getSql().replace(shardingProperty.getTableName(), shardingTable);metaStatementHandler.setValue(ORIGIN_BOUND_SQL, rebuildSql);if (log.isDebugEnabled()) {log.info("rebuildSQL -> {}", rebuildSql);}return invocation.proceed();}@Overridepublic Object plugin(Object target) {if (target instanceof StatementHandler) {return Plugin.wrap(target, this);}return target;}@Overridepublic void setProperties(Properties properties) {}public static String getCurrentShardingTable(ShardingProperty shardingProperty, Date createTime) {String tableName = shardingProperty.getTableName();Integer days = shardingProperty.getDays();Date beginDate = shardingProperty.getBeginDate();Date date;if (createTime == null) {date = new Date();} else {date = createTime;}if (date.before(beginDate)) {return null;}LocalDateTime targetDate = SimpleDateFormatUtils.convertDateToLocalDateTime(date);LocalDateTime startDate = SimpleDateFormatUtils.convertDateToLocalDateTime(beginDate);LocalDateTime intervalStartDate = DateIntervalChecker.getIntervalStartDate(targetDate, startDate, days);LocalDateTime intervalEndDate = intervalStartDate.plusDays(days - 1);return tableName + "_" + intervalStartDate.format(FORMATTER) + "_" + intervalEndDate.format(FORMATTER);}
}临界点数据不连续问题
分表方案有1个难点需要解决:周期临界点数据不连续。举例:假设要对operate_log(操作日志表)大表进行横向分表,每周一张表,分表明细可看下面表格。
| 第一周(operate_log_20240107_20240108) | 第二周(operate_log_20240108_20240114) | 第三周(operate_log_20240115_20240121) |
| 1月1号 ~ 1月7号的数据 | 1月8号 ~ 1月14号的数据 | 1月15号 ~ 1月21号的数据 |
1月8号就是分表临界点,8号需要切换到第二周的表,但8号0点刚切换的时候,表内没有任何数据,这时如果业务需要查近一周的操作日志是查不到的,这样就会引发线上问题。
我决定采用数据冗余的方式来解决这个痛点。每个周期表都冗余一份上个周期的数据,用双倍数据量实现数据滑动的效果,效果见下面表格。
| 第一周(operate_log_20240107_20240108) | 第二周(operate_log_20240108_20240114) | 第三周(operate_log_20240115_20240121) |
| 12月25号 ~ 12月31号的数据 | 1月1号 ~ 1月7号的数据 | 1月8号 ~ 1月14号的数据 |
| 1月1号 ~ 1月7号的数据 | 1月8号 ~ 1月14号的数据 | 1月15号 ~ 1月21号的数据 |
注:表格内第一行数据就是冗余的上个周期表的数据。
思路有了,接下来就要考虑怎么实现双写(数据冗余到下个周期表),有2种方案:
1.在SQL执行完成返回结果前添加逻辑(可以用AspectJ 或 mybatis拦截器),如果SQL内的表名是当前周期表,就把表名替换为下个周期表,然后再次执行SQL。此方案对业务影响大,相当于串行执行了2次SQL,有性能损耗。
2.监听增量binlog,京东内部有现成的数据订阅中间件DRC,读者也可以使用cannal等开源中间件来代替DRC,原理大同小异,此方案对业务无影响。
方案对比后,选择了对业务性能损耗小的方案二。
监听binlog并双写流程图
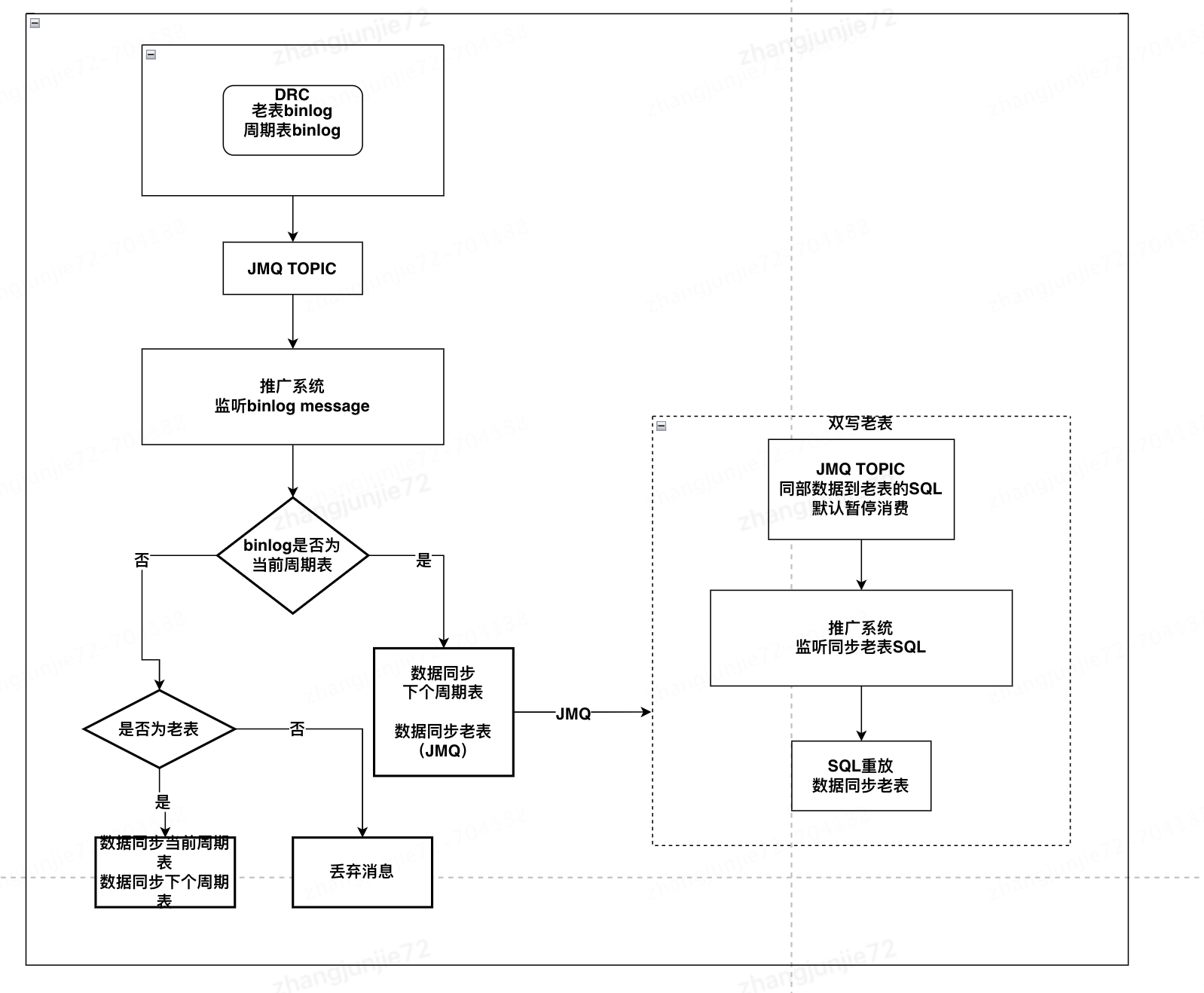
监听binlog数据双写注意点
1.提前上线监听程序,提前把老表数据同步到新的周期表。分表前只监听老表binlog就可以,分表前只需要把老表数据同步到新表。
2.切换到新表的临界点,为了避免丢失积压的老表binlog,需要同时处理新表binlog和老表binlog,这样会出现死循环同步的问题,因为老表需要同步新表,新表又需要双写老表。为了打破循环,需要先把双写老表消费堵上让消息暂时积压,切换新表成功后,再打开双写消费。
监听binlog数据双写代码
注:下面代码不能直接用,只提供基本思路
/*** 监听binlog ,分表双写,解决数据临界问题
*/
@Slf4j
@Component
public class BinLogConsumer implements MessageListener {private MessageDeserialize deserialize = new JMQMessageDeserialize();private static final String TABLE_PLACEHOLDER = "%TABLE%";@Value("${mq.doubleWriteTopic.topic}")private String doubleWriteTopic;@Autowiredprivate JmqProducerService jmqProducerService;@Overridepublic void onMessage(List<Message> messages) throws Exception {if (messages == null || messages.isEmpty()) {return;}List<EntryMessage> entryMessages = deserialize.deserialize(messages);for (EntryMessage entryMessage : entryMessages) {try {syncData(entryMessage);} catch (Exception e) {log.error("sharding sync data error", e);throw e;}}}private void syncData(EntryMessage entryMessage) throws JMQException {// 根据binlog内的表名,获取需要同步的表// 3种情况:// 1、老表:需要同步当前周期表,和下个周期表。// 2、当前周期表:需要同步下个周期表,和老表。// 3、下个周期表:不需要同步。List<String> syncTables = getSyncTables(entryMessage.tableName, entryMessage.createTime);if (CollectionUtils.isEmpty(syncTables)) {log.info("table {} is not need sync", tableName);return;}if (entryMessage.getHeader().getEventType() == WaveEntry.EventType.INSERT) {String insertTableSqlTemplate = parseSqlForInsert(rowData);for (String syncTable : syncTables) {String insertSql = insertTableSqlTemplate.replaceAll(TABLE_PLACEHOLDER, syncTable);// 双写老表发Q,为了避免出现同步死循环问题if (ShardingPropertyConfig.SHARDING_TABLE.containsKey(syncTable)) {Long primaryKey = getPrimaryKey(rowData.getAfterColumnsList());sendDoubleWriteMsg(insertSql, primaryKey);continue;}mysqlConnection.executeSql(insertSql);}continue;}}数据对比
为了保证新表和老表数据一致,需要编写对比程序,在上线前进行数据对比,保证binlog同步无问题。
具体实现代码不做展示,思路:新表查询一定量级数据,老表查询相同量级数据,都转换成JSON,equals对比。
作者:京东零售业务研发 张均杰
来源:京东零售技术 转载请注明来源