分类目录:《自然语言处理从入门到应用》总目录
从大量无标注数据中进行预训练使许多自然语言处理任务获得显著的性能提升。总的来看,预训练模型的优势包括:
- 在庞大的无标注数据上进行预训练可以获取更通用的语言表示,并有利于下游任务
- 为模型提供了一个更好的初始化参数,在目标任务上具备更好的泛化性能、并加速收敛
- 是一种有效的正则化手段,避免在小数据集上过拟合,而一个随机初始化的深层模型容易对小数据集过拟合
下图就是各种预训练模型的思维导图,其分别按照词嵌入(Word Embedding)方式分为静态词向量(Static Word Embedding)和动态词向量(Dynamic Word Embedding)方式分类、按照监督学习和自监督学习方式进行分类、按照拓展能力等分类方式展现:
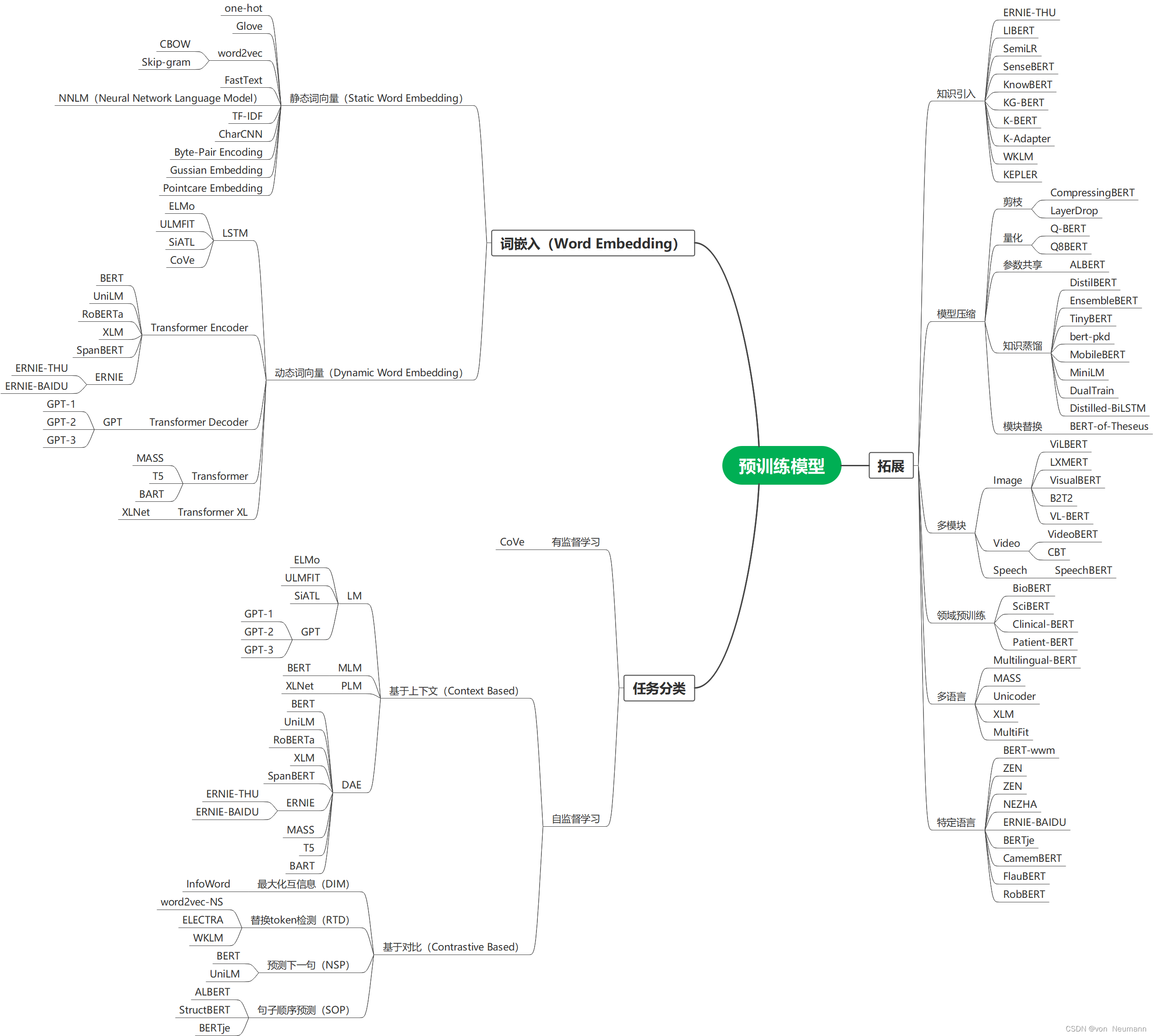
思维导图可编辑源文件下载地址:https://download.csdn.net/download/hy592070616/87954682
引入知识
预训练模型通常从通用大型文本语料库中学习通用语言表示,但是缺少特定领域的知识。预训练模型中设计一些辅助的预训练任务,将外部知识库中的领域知识整合到预训练模型中被证明是有效的。
- ERNIE-THU:将在知识图谱中预先训练的实体嵌入与文本中相应的实体提及相结合,以增强文本表示。由于语言表征的预训练过程和知识表征过程有很大的不同,会产生两个独立的向量空间。为解决上述问题,在有实体输入的位置,将实体向量和文本表示通过非线性变换进行融合,以融合词汇、句法和知识信息。
- LIBERT(语言知识的BERT):通过附加的语言约束任务整合了语言知识。
- SentiLR:集成了每个单词的情感极性,以将MLM扩展到标签感知MLM(LA-MLM),ABSA任务上都达到SOTA。
- SenseBERT:不仅能够预测被mask的token,还能预测它们在给定语境下的实际含义。使用英语词汇数据库WordNet作为标注参照系统,预测单词在语境中的实际含义,显著提升词汇消歧能力。
- KnowBERT:与实体链接模型以端到端的方式合并实体表示。
- KG-BERT:显示输入三元组形式,采取两种方式进行预测:构建三元组识别和关系分类,共同优化知识嵌入和语言建模目标。这些工作通过实体嵌入注入知识图的结构信息。
- K-BERT:将从KG提取的相关三元组显式地注入句子中,以获得BERT的扩展树形输入。
- K-Adapter:通过针对不同的预训练任务独立地训练不同的适配器来注入多种知识,从而可以不断地注入知识,以解决注入多种知识时可能会出现灾难性遗忘问题。
此外,这类预训练模型还有WKLM、KEPLER等。
模型压缩
由于预训练的语言模型通常包含至少数亿个参数,因此很难将它们部署在现实应用程序中的在线服务和资源受限的设备上。模型压缩是减小模型尺寸并提高计算效率的有效方法。
- Pruning(剪枝):将模型中影响较小的部分舍弃。如Compressing BERT,还有结构化剪枝LayerDrop,其在训练时进行Dropout,预测时再剪掉Layer,不像知识蒸馏需要提前固定student模型的尺寸大小。
- Quantization(量化):将高精度模型用低精度来表示。如Q-BERT和Q8BERT,量化通常需要兼容的硬件。
- Parameter Sharing (参数共享):相似模型单元间的参数共享。ALBERT主要是通过矩阵分解和跨层参数共享来做到对参数量的减少。
- Module Replacing(模块替换):BERT-of-Theseus根据伯努利分布进行采样,决定使用原始的大模型模块还是小模型,只使用task loss。
- Knowledge Distillation (知识蒸馏):通过一些优化目标从大型、知识丰富、fixed的teacher模型学习一个小型的student模型。蒸馏机制主要分为3种类型:
- 从软标签蒸馏:DistilBERT、EnsembleBERT
- 从其他知识蒸馏:TinyBERT、BERT-PKD、MobileBERT 、MiniLM、DualTrain
- 蒸馏到其他结构:Distilled-BiLSTM
| 预训练模型 | 知识蒸馏方法 |
|---|---|
| DistilBERT | 软标签蒸馏,KL散度作为沁ss |
| TinyBERT | 层与层蒸馏:Embedding / Hidden State / Self-attention Dlstributions |
| BERT-PKD | 层与层蒸馏:Hidden State |
| MobileBERT | 软标签蒸馏+层与层蒸馏:Hidden State / Self-attention Dlstributions |
| MiniLM | Self-attention Dlstributions / Self-attention Value Relation |
| Dual Train | Dual Projection |
| Distilled-BiLSTM | 软标签蒸馏,将Transformer蒸馏到LSTM |
| EnsembleBERT | 取多个Ensemble模型的软标签进行蒸馏 |
多模态
随着预训练模型在自然语言处理领域的成功,许多研究者开始关注多模态领域的预训练模型,主要为通用的视觉和语言特征编码表示而设计。多模态的预训练模型在一些庞大的跨模式数据语料库(带有文字的语音、视频、图像)上进行了预训练,如带有文字的语音、视频、图像等,主要有 VideoBERT、CBT 、UniViLM、ViL-BERT、LXMERT、 VisualBERT、B2T2、Unicoder-VL、UNITER、VL-BERT、SpeechBERT等。
领域预训练
大多数预训练模型都在诸如Wikipedia的通用语料中训练,而在领域化的特定场景会收到限制。如基于生物医学文本的BioBERT,基于科学文本的SciBERT,基于临床文本的Clinical-BERT。一些工作还尝试将预训练模型适应目标领域的应用,如医疗实体标准化、专利分类PatentBERT、情感分析SentiLR关键词提取。
多语言和特定语言
学习跨语言共享的多语言文本表示形式对于许多跨语言的NLP任务起着重要的作用。Multi-lingualBERT在104种Wikipedia文本上进行MLM训练(共享词表),每个训练样本都是单语言文档,没有专门设计的跨语言目标,也没有任何跨语言数据,Multi-lingualBERT也可以很好的执行跨语言任务。XLM通过融合跨语言任务(翻译语言模型)改进了M-BERT,该任务通过拼接平行语料句子对进行MLM训练。Unicoder提出了3种跨语言预训练任务:cross-lingual word recovery、cross-lingual paraphrase classification和cross-lingual masked language model。虽然多语言的预训练模型在跨语言上任务表现良好,但用单一语言训练的预训练模型明显好于多语言的预训练模型。此外一些单语言的预训练模型被提出:BERT-wwm、ZEN、NEZHA[、ERNIE-Baidu、BERTje、CamemBERT、FlauBERT、RobBERT。
参考文献:
[1] QIU XIPENG, SUN TIANXIANG, XU YIGE, et al. Pre-trained models for natural language processing: A survey[J]. 中国科学:技术科学(英文版),2020.