有时候我们经常说行业大模型,医疗大模型,开源大模型,甚至用「产品+大模型」的固定结构去称呼一个模型,例如百度的文心一言大模型,但是文心一言其实是大语言模型,大模型和大语言模型,差别就两个字,但是他们的关系却是主从关系。
一、什么是大模型?
一句话介绍就是:大模型是指具有大量参数的机器学习模型,通常指深度学习模型。
首先,大模型这个词是建立在神经网络模型上的。神经网络是一种基于生物学神经系统结构和功能的计算模型,旨在模仿人脑的学习和决策过程该模型由多个神经元组成,这些神经元通过权重连接形成层次结构,通常分为输入层、隐藏层和输出层。输入层接收原始数据,输出层产生最终的输出,而隐藏层在这两者之间进行中间处理。
神经网络通过学习调整连接权重,从而能够识别模式、进行分类、回归等任务。训练神经网络通常包括提供输入数据和相应的期望输出,然后通过反向传播算法来调整权重,使得网络的输出逼近期望的输出。这个过程反复进行,直到网络能够准确地进行任务。
不妨把神经网络想象成一个初生的婴儿,每当婴儿看到一个新东西,比如苹果,我们就告诉他:“这是一个苹果。”这就相当于在神经网络中调整连接的权重,让大脑建立起“苹果”的概念。这个过程就是在训练神经网络,随着时间的推移,婴儿逐渐长大,它就能够分清不同的事物,并依靠计算机强大的计算能力完成许多更复杂的任务。
大模型的模型参数量达到了亿的级别,近期的研究成果基本在百亿到千亿的范围。当然这不会是终点,大模型的神经元数量和相关参数量必定会朝着远超人类大脑神经元数量的方向发展。
二、大模型分类
模型的发展最初是伴随着自然语言处理技术的不断发展的,这是由于文本数据的数据量更大且更容易获取。所以目前大模型最大的分类还是大语言模型,近两年衍生出一些语言与其他形式融合的大模型,例如:文字生成音乐(MusicLM)、文字生成图像(DALL-E2,Midjourney)、文字图像生成机器人动作(RT-1)等。
大模型包括但不限于以下几类:
-
大语言模型(LLM):专注于处理自然语言,能够理解、生成和处理大规模文本数据。大语言模型在机器翻译、文本生成、对话系统等任务上取得显著成果。OpenAI的GPT系列是其中的代表,包括最新的GPT-4、文心一言、通义千问。开源大模型中有meta 开源的 LLaMA、ChatGLM - 6B、Yi-34B-Chat等;
-
视觉大模型:专注于计算机视觉任务,例如图像分类、目标检测、图像生成等。它们能够从图像中提取有关对象、场景和结构的信息。例如Vision Transformer(ViT)就是一种基于自注意力机制的视觉大模型,用于图像分类任务。
-
多模态大模型:能够处理多种不同类型的数据,如文本、图像、音频等,并在这些数据之间建立关联。多模态大模型在处理涉及多种感知输入的任务上表现出色,如文图融合、图像描述生成等。多模态是大模型接下来发展的一大趋势。国内的华为盘古大模型就是一个多模态大模型,能够同时理解文本和图像,用于任务如图像分类和自然语言推理,国外的谷歌Gemini也是一个多模态大模型
-
决策大模型:专注于进行决策和规划,通常应用于强化学习等领域。它们能够在面对不确定性和复杂环境时做出智能决策。深度强化学习中的模型,如AlphaGo和AlphaZero,是决策大模型的代表,能够在围棋等游戏中取得超人类水平的表现。
-
行业垂直大模型:专门设计用于特定行业或领域的任务,如医学、环境、教育等。它们通常在处理特定领域的数据和问题时表现出色。在医疗领域有DoctorGPT、华佗GPT,大规模的医学图像处理模型用于诊断和分析。在金融领域,模型可能用于风险评估和交易策略。携程的问道是旅游行业的大模型等等
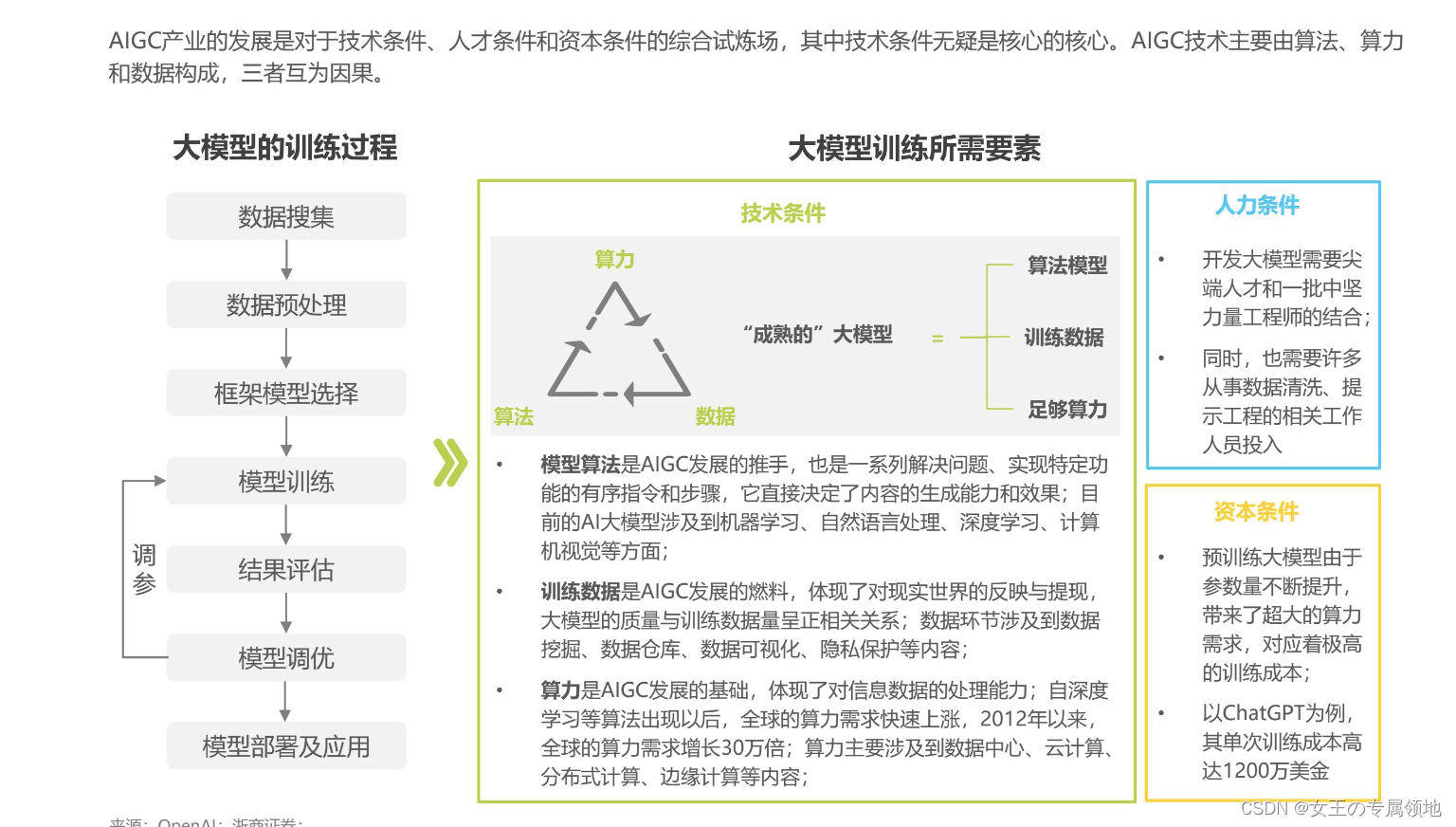
三、大模型训练要素
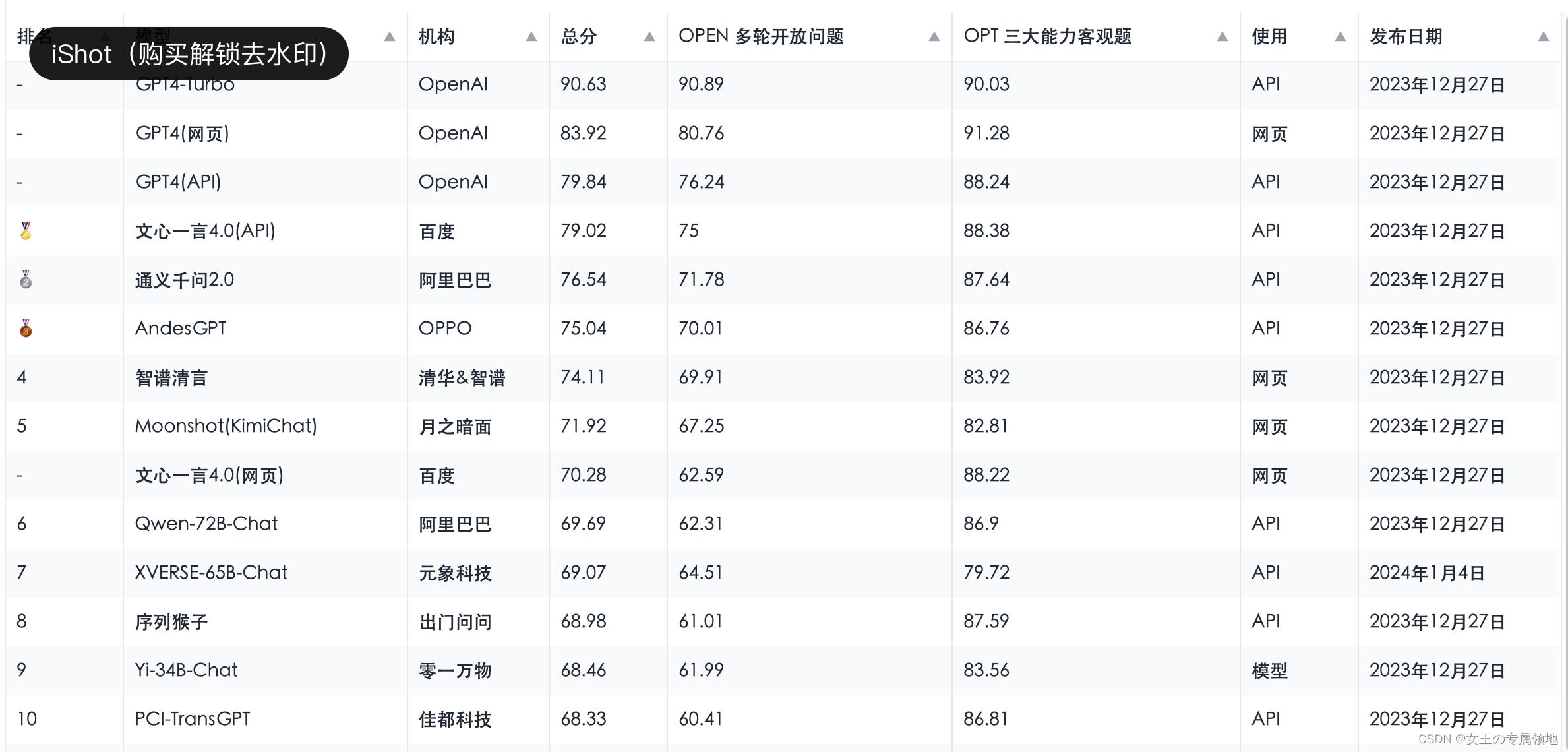
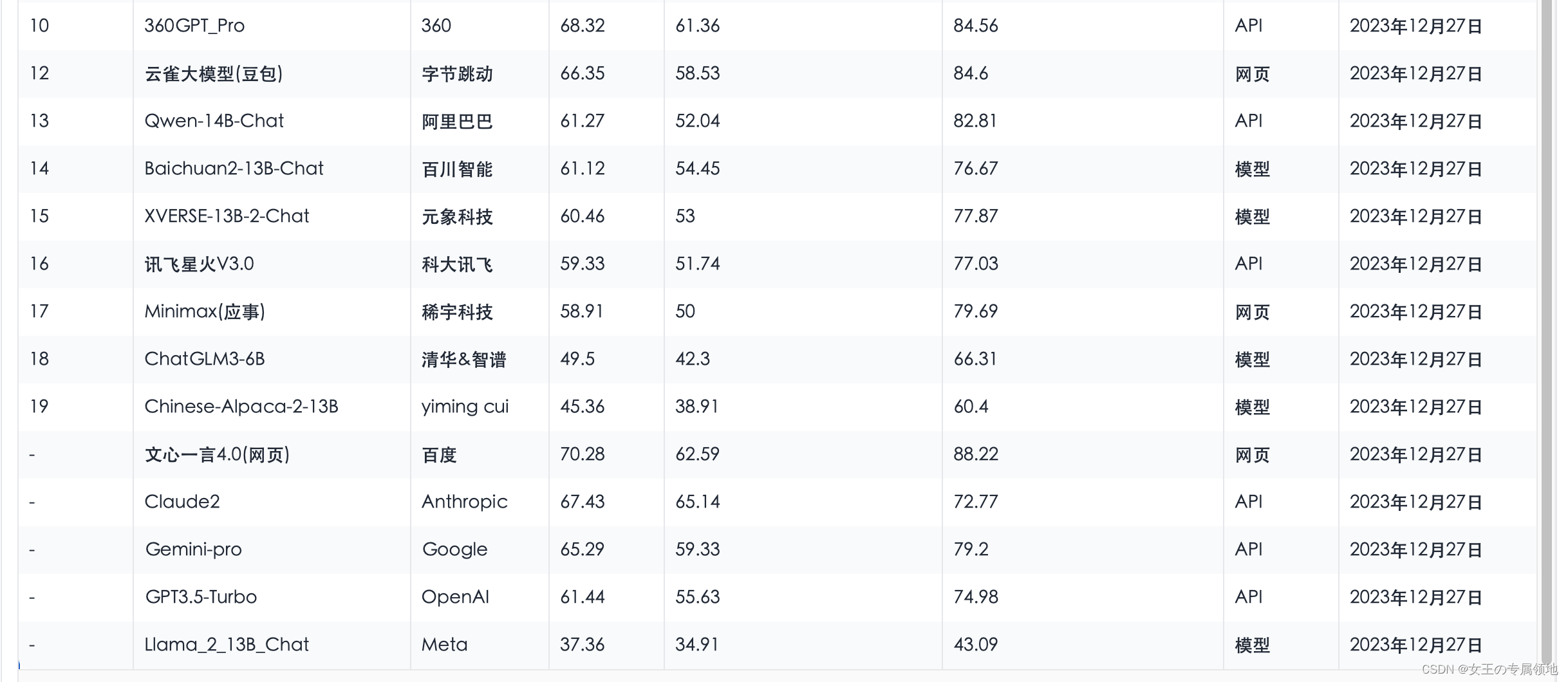
四、大模型排行榜单
-
SuperCLUE排行榜:https://www.superclueai.com

-
CLUE官网地址:https://www.cluebenchmarks.com
-
GitHub地址:https://github.com/CLUEbenchmark/SuperCLUE-Agent