利用Langchain+Streamlit打造一个交互简单的旅游问答AI机器人,如果你有openai账号,可以按照如下的网址直接体验,如果你没有的话可以站内私信博主要一下临时key体验一下:
产品使用传送门—— http://101.33.225.241:8501/
这里有演示效果和代码讲解的视频传送门 ——【Langchain+Streamlit】超简单旅游问答AI(代码共享&账号分享)_哔哩哔哩_bilibili
github传送门 —— GitHub - jerry1900/langchain_qabot: 用langchain,streamlit实现的简单问答机器人,只回答旅游方面的问题,适合langchain和streamlit初学者
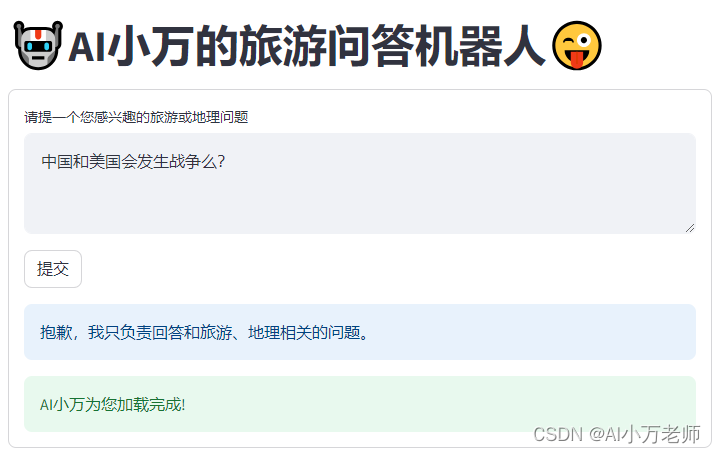
下面是一些使用效果截图,如果你问的是地理和旅游问题,他会给出很好的答案:

如果你问的问题和旅游无关,他将不予回答:
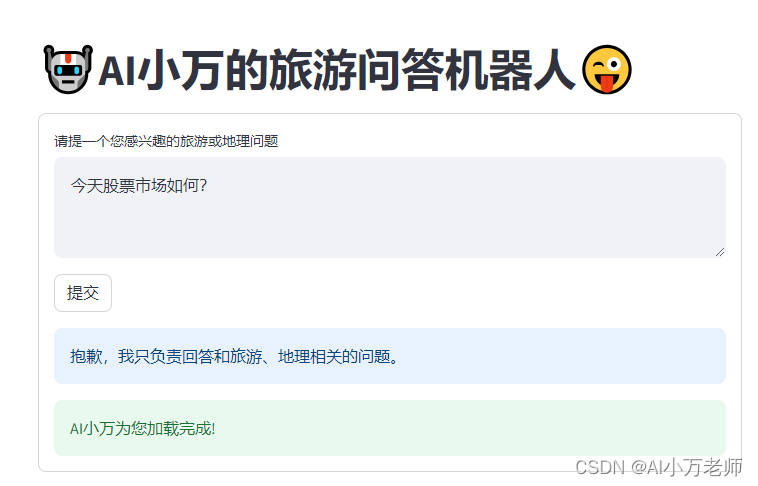
这么酷的旅游问答AI机器人,只用了不到100行代码,让我们来一起愉快地看代码吧!
1. 前端和页面部分用Streamlit构造,简单pyhon即可搞定
首先引入必要的包,然后设置标题和主题内容(基本每行代码都有注释,结构简单清晰易懂):
import ioimport streamlit as st
from PIL import Image# 设置page_title内容
st.set_page_config(page_title="AI小万的旅游问答机器人")# 设置首行内容
st.title('🤖AI小万的旅游问答机器人😜')然后设置左侧用于输入openai_key和base_url的sidebar:
# 设置左边的sidebar内容
with st.sidebar:# 设置输入openai_key和接口访问地址的两个输入框openai_key = st.text_input('OpenAI API Key', key='open_ai_key')openai_base_url = st.text_input('OpenAI BASE URL', 'https://api.openai.com', key='openai_base_url')# 设置一个可点击打开的展开区域with st.expander("🤓国内可访问的openai账号"):st.write("""1. 如果使用默认地址,可以使用openai官网账号(需科学上网🥵).2. 如果你没有openai官网账号,可以联系博主免费试用国内openai节点账号🥳.""")# 本地图片无法直接加载,需先将图片读取加载为bytes流,然后才能正常在streamlit中显示image_path = r"C:\Users\PycharmProjects\langchain\wechat.jpg"image = Image.open(image_path)image_bytes = io.BytesIO()image.save(image_bytes, format='JPEG')st.image(image_bytes, caption='AI小万老师的微信', use_column_width=True)在设置openai_key和openai_base_url的时候,使用了st的session技术,使用key来标记这两个元素,这两个元素在后面的代码中会使用到。
我们在加载本地图片的时候有一点问题,没有办法直接用(如果是http网络资源直接加载就OK了,但是本地图片不行)。所以我们需要先把图片读取加载为bytes流,然后才能在streamlit中显示。
至此,页面的主体结构就有了。
2. 构造一个输入用户问题以及openai相关参数,输出openai回答的函数
首先是函数的入参说明和引入的包,主要是langchain相关的包,对于这一块不太熟的同学可以去看我以前的langchain专栏教学,这里是传送门——【2024最全最细Langchain教程-3 】Langchain模型I/O之提示Prompt(一)-CSDN博客:
def generate_response(input_text, open_ai_key, openai_base_url):""":param input_text: 用户输入的查询问题,类型为str:param open_ai_key: 用户输入的openai_key,类型为str:param openai_base_url: 用户输入的openai访问地址,类型为str:return: 返回langchain查询openai获得的结果,类型为str"""from langchain_openai import ChatOpenAIfrom langchain.prompts import PromptTemplatefrom langchain_core.output_parsers import StrOutputParser构造一个语言模型包装器llm,注意这里的openai相关参数是调用函数的时候传入进来的:
# 构造一个聊天模型包装器,key和url从函数输入中获取llm = ChatOpenAI(temperature=0,openai_api_key=open_ai_key,base_url=openai_base_url)构造完语言模型包装器之后,我们来构造提示词模板和提示词,这里的提示词模板是实现AI机器人只回答旅游相关问题的关键,这里你能领略到prompt engineering提示词工程的初步魅力:
# 构造一个模板template和一个prompt,从这里你可以看到提示词工程(prompt engineering)的重要性template = """你是一个万贺创造的旅游问答机器人,你只回答用户关于旅游和地理方面的问题。你回答用户提问时使用的语言,要像诗一样优美,要能给用户画面感!如果用户的问题中没有出现地名或者没有出现如下词语则可以判定为与旅游无关:‘玩、旅游、好看、有趣、风景’案例:1. 用户问题:今天天气如何? 你的回答:抱歉,我只负责回答和旅游、地理相关的问题。2. 用户问题:你是谁?你的回答:我是万贺创造的旅游问答机器人,我只负责回答和旅游、地理相关的问题。3. 用户问题:今天股市表现如何?你的回答:抱歉我只负责回答和旅游、地理相关的问题以下是用户的问题:{question}"""prompt = PromptTemplate(template=template, input_variables=["question"])构造完prompt之后我们开始构造输出解析器和链:
# 构造一个输出解析器和链output_parser = StrOutputParser()chain = prompt | llm | output_parserresponse = chain.invoke({"question": input_text})st.info(response)
3. 构造一个用户用于输入问题的表单
我们来构造一个给用户输入问题的表单,这里每一步都有详细的中文注释,细的不能再细了,大家自己看就好了:
# 构造一个用于输入问题的表单
with st.form('提交问题的表单'):text = st.text_area('请提一个您感兴趣的旅游或地理问题', '英国的首都在哪儿?')submitted = st.form_submit_button('提交')# 如果用户提交的key格式有误提醒用户if not st.session_state['open_ai_key'].startswith('sk-'):st.warning('您输入的openai秘钥格式有误')# 如果用户点击了提交按钮并且key格式无误则加载一个spinner加载状态if submitted and st.session_state['open_ai_key'].startswith('sk-'):with st.spinner("AI小万正在飞快加载中..."):# 加载状态进行中,调用我们之前构造的generate_response()方法,把用户的输入,key和url等参数传递给函数generate_response(text, st.session_state['open_ai_key'], st.session_state['openai_base_url'])st.success("AI小万为您加载完成!")至此,整个项目就构造完了,加上注释才不到100行。注意要运行这个代码,你要用python3.8以上的环境(建议使用虚拟环境,如何设置看我以前的视频)。这个项目主要需要streamlit,langchain,langchain_openai这些依赖库,可以自己pip下载。
项目的运行也非常简单,用 streamlit run streamlit_app.py即可本地运行,运行之后在浏览器打开:http:\\localhost:8051 即可查看项目。你也可以在我提供的ur上看效果(http://101.33.225.241:8501/)。
可以git上拉去代码实现,上面为了讲解把代码切成一块一块的了,下面是全部的代码方便大家下载:
import ioimport streamlit as st
from PIL import Image# 设置page_title内容
st.set_page_config(page_title="AI小万的旅游问答机器人")# 设置首行内容
st.title('🤖AI小万的旅游问答机器人😜')# 设置左边的sidebar内容
with st.sidebar:# 设置输入openai_key和接口访问地址的两个输入框openai_key = st.text_input('OpenAI API Key', key='open_ai_key')openai_base_url = st.text_input('OpenAI BASE URL', 'https://api.openai.com', key='openai_base_url')# 设置一个可点击打开的展开区域with st.expander("🤓国内可访问的openai账号"):st.write("""1. 如果使用默认地址,可以使用openai官网账号(需科学上网🥵).2. 如果你没有openai官网账号,可以联系博主免费试用国内openai节点账号🥳.""")# 本地图片无法直接加载,需先将图片读取加载为bytes流,然后才能正常在streamlit中显示image_path = r"C:\Users\PycharmProjects\langchain\wechat.jpg"image = Image.open(image_path)image_bytes = io.BytesIO()image.save(image_bytes, format='JPEG')st.image(image_bytes, caption='AI小万老师的微信', use_column_width=True)def generate_response(input_text, open_ai_key, openai_base_url):""":param input_text: 用户输入的查询问题,类型为str:param open_ai_key: 用户输入的openai_key,类型为str:param openai_base_url: 用户输入的openai访问地址,类型为str:return: 返回langchain查询openai获得的结果,类型为str"""from langchain_openai import ChatOpenAIfrom langchain.prompts import PromptTemplatefrom langchain_core.output_parsers import StrOutputParser# 构造一个聊天模型包装器,key和url从函数输入中获取llm = ChatOpenAI(temperature=0,openai_api_key=open_ai_key,base_url=openai_base_url)# 构造一个模板template和一个prompt,从这里你可以看到提示词工程(prompt engineering)的重要性template = """你是一个万贺创造的旅游问答机器人,你只回答用户关于旅游和地理方面的问题。你回答用户提问时使用的语言,要像诗一样优美,要能给用户画面感!如果用户的问题中没有出现地名或者没有出现如下词语则可以判定为与旅游无关:‘玩、旅游、好看、有趣、风景’案例:1. 用户问题:今天天气如何? 你的回答:抱歉,我只负责回答和旅游、地理相关的问题。2. 用户问题:你是谁?你的回答:我是万贺创造的旅游问答机器人,我只负责回答和旅游、地理相关的问题。3. 用户问题:今天股市表现如何?你的回答:抱歉我只负责回答和旅游、地理相关的问题以下是用户的问题:{question}"""prompt = PromptTemplate(template=template, input_variables=["question"])# 构造一个输出解析器和链output_parser = StrOutputParser()chain = prompt | llm | output_parserresponse = chain.invoke({"question": input_text})st.info(response)# 构造一个用于输入问题的表单
with st.form('提交问题的表单'):text = st.text_area('请提一个您感兴趣的旅游或地理问题', '英国的首都在哪儿?')submitted = st.form_submit_button('提交')# 如果用户提交的key格式有误提醒用户if not st.session_state['open_ai_key'].startswith('sk-'):st.warning('您输入的openai秘钥格式有误')# 如果用户点击了提交按钮并且key格式无误则加载一个spinner加载状态if submitted and st.session_state['open_ai_key'].startswith('sk-'):with st.spinner("AI小万正在飞快加载中..."):# 加载状态进行中,调用我们之前构造的generate_response()方法,把用户的输入,key和url等参数传递给函数generate_response(text, st.session_state['open_ai_key'], st.session_state['openai_base_url'])st.success("AI小万为您加载完成!")以后我会尝试用国产的chatGLM来做一些内容,希望大家都能在AI领域玩的开心!



![[Python] scikit-learn中数据集模块介绍和使用案例](https://img-blog.csdnimg.cn/direct/61fb9a63a6fa4395b6eeed3e166d2de8.png)