【深度学习: 计算机视觉】如何改进计算机视觉数据集
- 训练模型并评估性能
- 确定数据集需要改进的原因和位置
- 收集或创建新的图像或视频数据
- 重新训练机器学习模型并重新评估,直到达到所需的性能标准
机器学习算法需要大量数据集来训练、提高性能并生成组织所需的结果。
数据集是计算机视觉应用程序和模型运行的燃料。数据越多越好。这些数据应该是高质量的,以确保人工智能项目获得最佳的结果和产出。
获取训练机器学习模型所需数据的最佳方法之一是使用开源数据集。
幸运的是,数据科学家可以使用数百个高质量、免费和大量的开源数据集来训练算法生成的模型。
根据您的行业和用例,一些最流行的机器学习和计算机视觉数据集包括:
保险: Car Damage Assessment Dataset;
体育: Multiview Football Dataset I & II (from KTH), and the OpenTTGames Dataset;
SAR(合成孔径雷达)机器学习数据集: xView and xView3, both from the Copernicus Sentinel-1 mission of the European Space Agency (ESA), and the EU Copernicus Constellation;
智能城市和自动驾驶汽车(自动驾驶汽车)数据集: BDD100K and The KITTI Vision Benchmark Suite
零售商和制造商: RPC-Dataset Project
医疗和保健: The Cancer Imaging Archive (TCIA) and the NIH Chest X-Rays (on Kaggle)
开放数据集聚合器: Kaggle and OpenML
在本教程中,我们将仔细研究改进用于训练模型的开源数据集所需采取的步骤。
训练模型并评估性能
如果您使用的是公共开源数据集,则图像和视频很可能已经被注释和标记。出于所有意图和目的,这些数据集尽可能接近模型就绪。
使用公共数据集是启动和运行概念验证 (POC) 训练模型的一种有用的捷径。让您距离运行经过全面测试的生产模型又近了一步。
然而,在将这些数据集输入机器学习模型之前,您需要:
- 确保数据与您的项目目标一致。
- 确保注释(边界框、图像分割等)和元数据是高质量的,具有足够的模式和对象类型。
- 检查是否有足够的图像或视频来减少偏差(例如,就医学成像数据集而言,种族、性别、年龄组以及患有或不患有所研究疾病的患者的分布是否足够广泛?)
- 不同条件下是否有足够的图像或视频(例如,明亮与黑暗、白天与夜晚、阴影与无阴影)
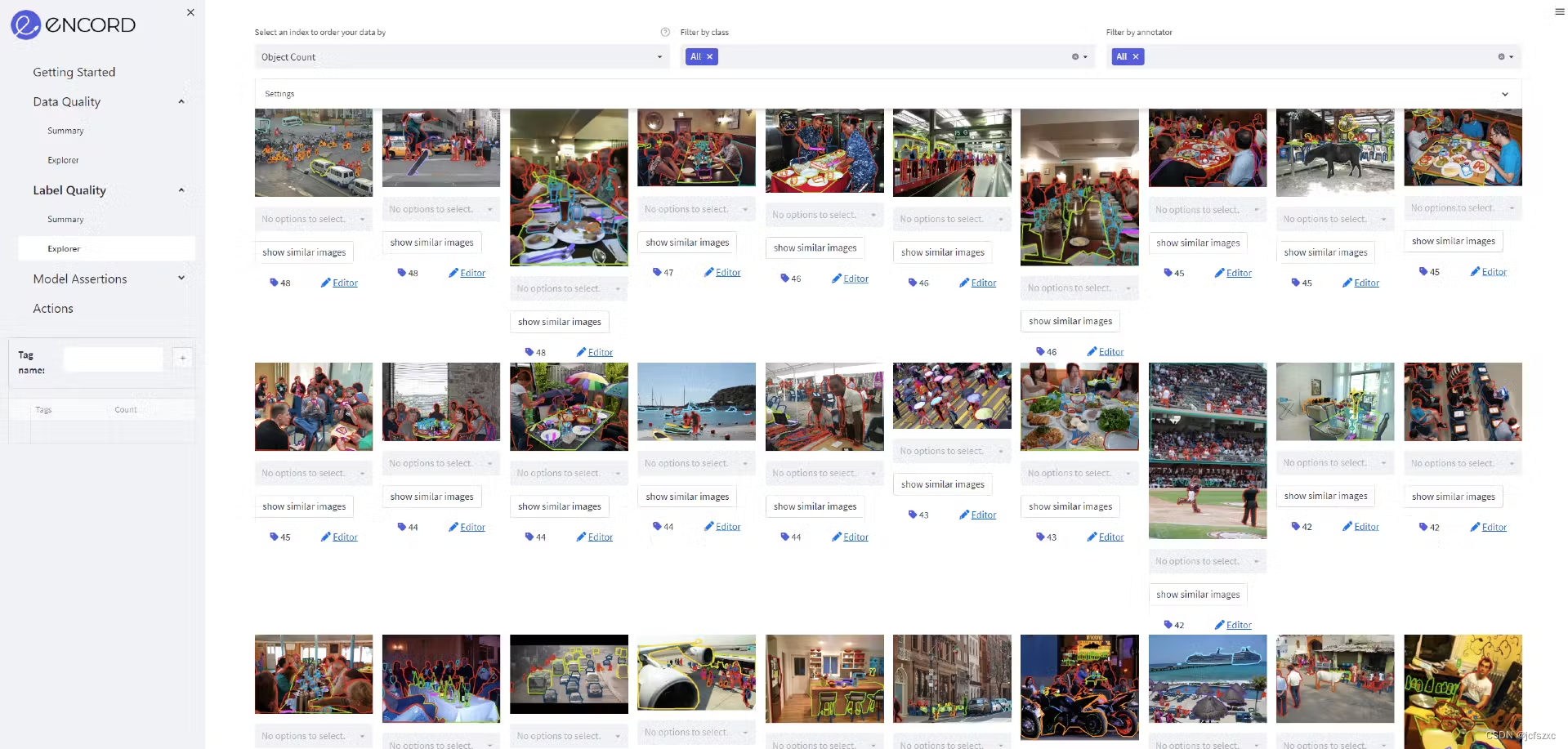
现在您已经获得了数据并检查了它是否合适,您可以开始训练机器学习模型来执行计算机视觉任务。
对于每个训练任务,您可以针对特定目标设置机器学习模型。例如,“识别 2000 年至 2010 年生产的黑色福特汽车。”
为了训练该模型,您可能需要向模型展示数以万计的汽车图像或视频。训练数据中应该有足够的示例,以便它可以积极地识别对象“X”;在本例中:黑色福特汽车,并且仅限于特定年份之间制造的汽车。
同样重要的是,训练数据中有数千个非福特汽车的示例,即相关对象。
要训练机器学习或 CV 模型,您需要向模型展示足够多的对象示例,这些对象与其训练识别的对象相反。因此,在此示例中,数据集应包含大量不同颜色、品牌和型号的汽车图像。
机器学习和计算机视觉算法只有在显示足够广泛的与相关目标对象形成对比的图像和视频时才能有效地进行训练。确保您使用的任何公共开源数据集也受益于广泛的环境因素(例如光明和黑暗、白天和黑夜、阴影以及其他所需的变量)非常有用。
一旦开始训练模型,您的团队就可以开始评估其性能。
不要期望从第一天起就能获得高性能的输出。您很有可能运行 100 个训练测试,但只有 30% 的得分足够高,足以获得有关如何将其中一两个模型转变为工作生产模型的宝贵见解。
训练模型失败是计算机视觉项目中自然而正常的一部分。
确定数据集需要改进的原因和位置
现在您已经开始训练在此数据集上使用的机器学习模型(或多个模型),结果将开始出现。
这些结果将向您展示模型失败的原因和位置。别担心,数据科学家、数据运营和机器学习专家都知道,失败是过程中不可避免且正常的部分。
没有失败,机器学习模型就不可能取得进步。
首先,预期故障率较高,或者至少准确率相对较低,例如 70%。
使用这些数据创建反馈循环,以便您可以更清楚地确定提高成功率所需的内容。例如,您可能需要:
- 更多图片或视频;
- 特定类型的图像或视频,以提高效率输出和准确性(有关这方面的更多信息,请查看我们关于数据增强的博客);
- 图像或视频数量的增加会导致结果更加平衡,例如减少偏见。
接下来,这些结果常常会产生另一个问题:如果我们需要更多数据,我们可以从哪里获得?
收集或创建新的图像或视频数据
大规模解决问题通常涉及使用大量高质量数据来训练机器学习模型。如果您可以从开源或专有数据集访问所需的数据量,则继续为模型提供数据 - 并相应地调整数据集标签和注释 - 直到它开始生成您需要的结果。
但是,如果这是不可能的,并且您无法从其他开源的真实数据集中获取所需的数据,那么还有另一种解决方案。
例如,如果您需要数千张车祸或火车脱轨的图像或视频怎么办?
您认为存在多少不经常发生的事情的图像和视频?即使确实发生了,这些边缘情况也并不总是能在图像或视频中清晰地捕捉到。
在这些场景中,您需要合成数据。
有关更多信息,请参阅综合训练数据简介
计算机生成图像 (CGI)、3D 游戏引擎(例如 Unity 和 Unreal)以及生成对抗网络 (GAN) 是创建团队训练计算机视觉模型所需的逼真合成图像或视频的最佳来源。
还可以选择购买合成数据集。如果您没有时间/预算来等待生成定制图像和视频。无论哪种方式,当您的机器学习团队尝试解决困难的边缘情况并且没有足够的原始数据时,始终可以创建或购买一些可以提高训练模型准确性的合成数据。
重新训练机器学习模型并重新评估,直到达到所需的性能标准
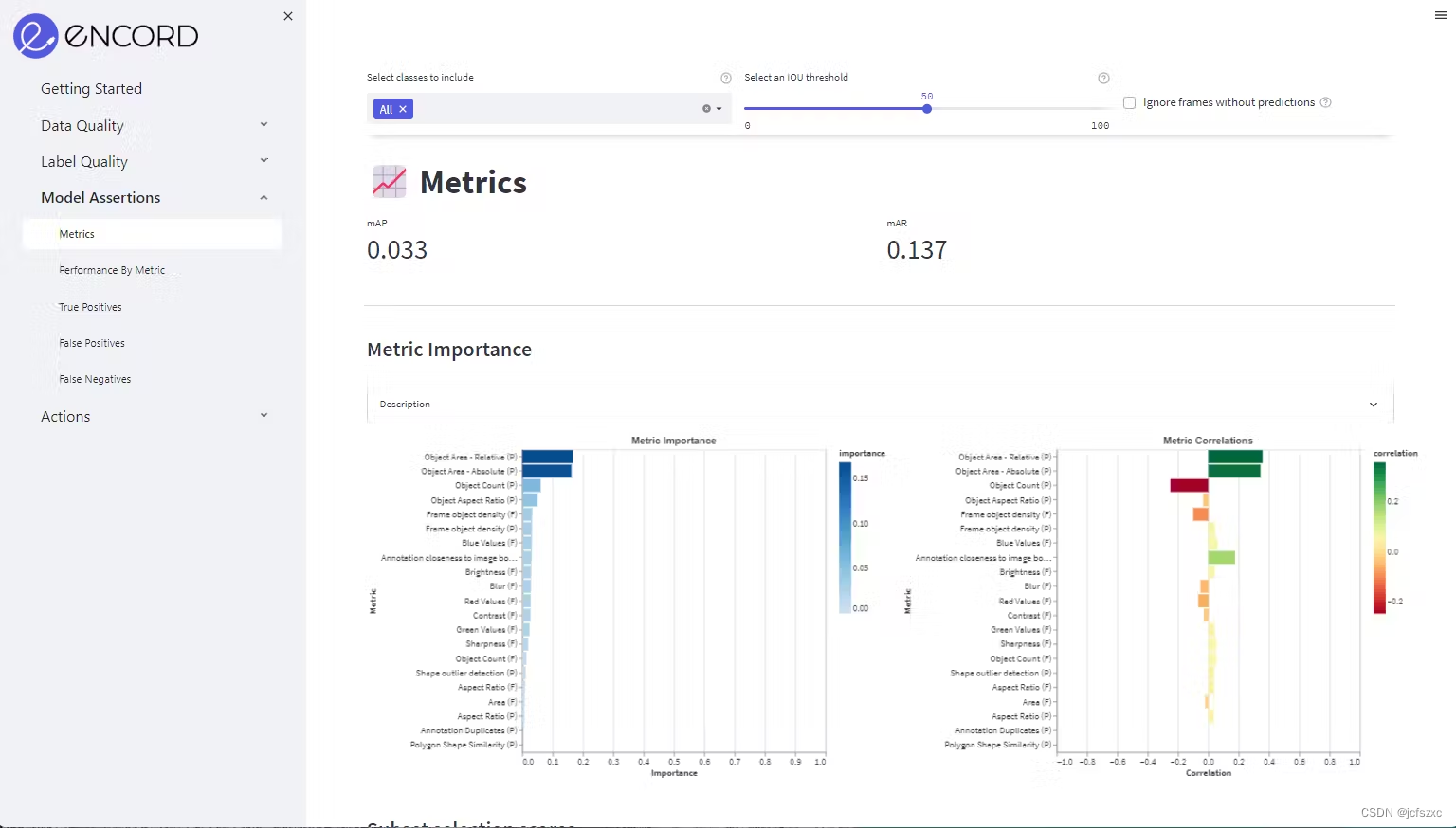
现在您已经获得了足够的数据来继续训练和重新训练模型,应该可以开始实现您所需的性能和准确性标准。假设初始结果为 70%,一旦结果在 90-95%+ 范围内,那么您的模型就朝着正确的方向发展!
继续测试和实验,直到可以开始对模型的准确性进行基准测试。
一旦准确性结果足够高,偏差评级足够低,并且结果与模型的目标一致,那么您就可以将工作模型投入生产。



![[Python] scikit-learn中数据集模块介绍和使用案例](https://img-blog.csdnimg.cn/direct/61fb9a63a6fa4395b6eeed3e166d2de8.png)