文章目录
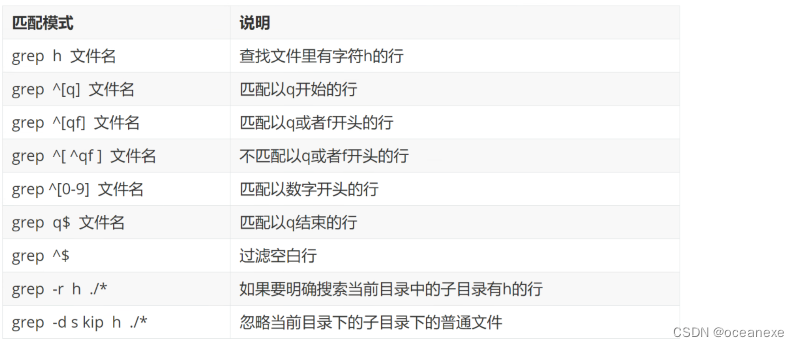
- 1. 再识重定向
- 2.浅谈perror()
- 3.初始文件系统
- 4.软硬链接
1. 再识重定向
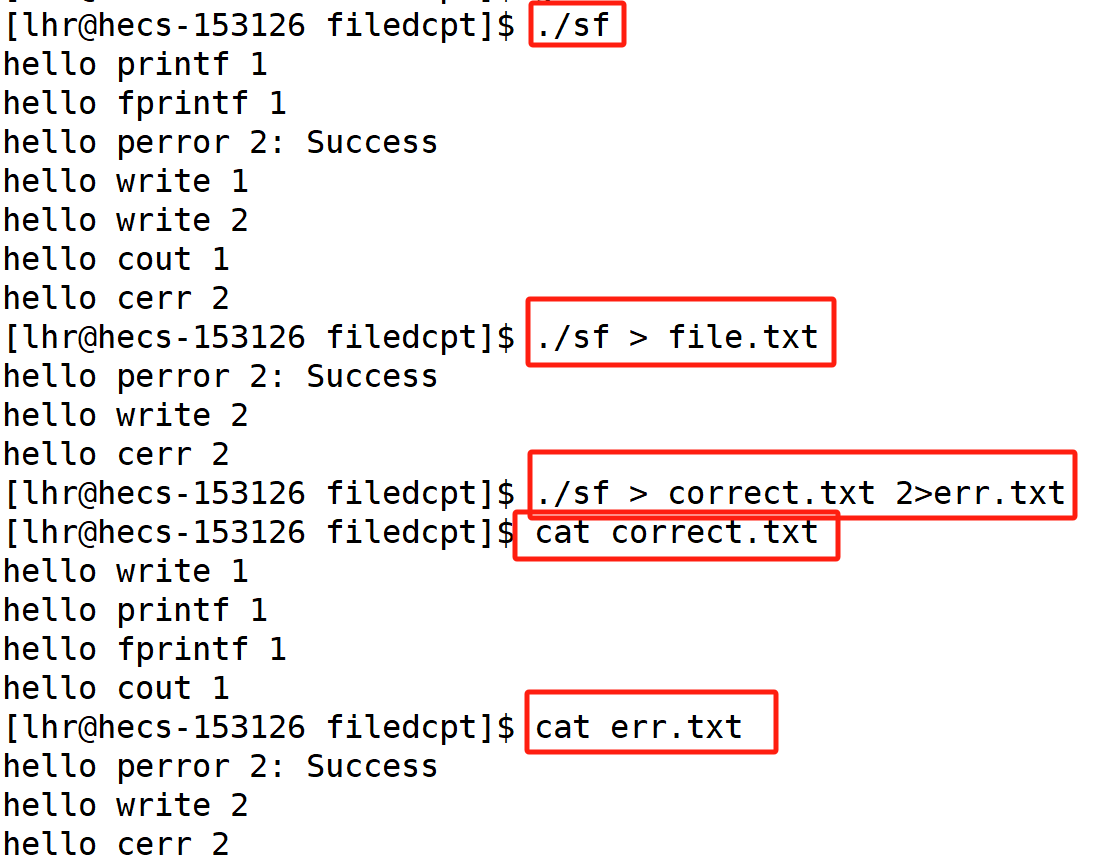


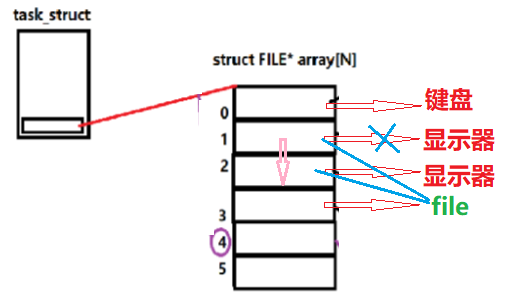
图解
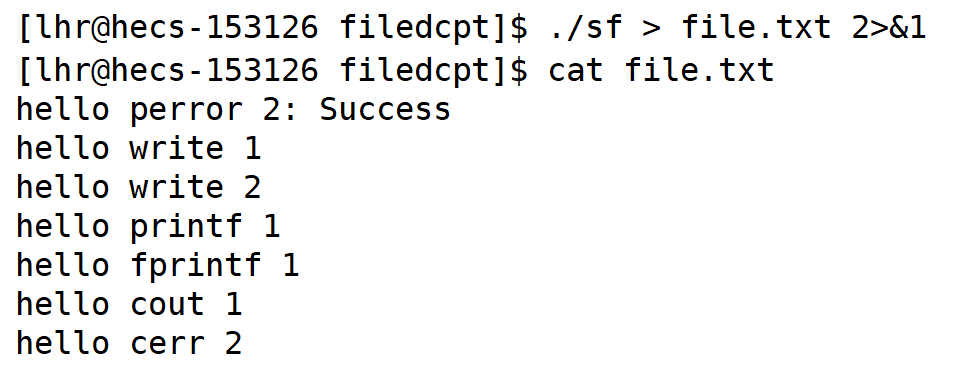
./sf > file.txt 2>&1
1中内容拷贝给2 使得2指向file
再学一个
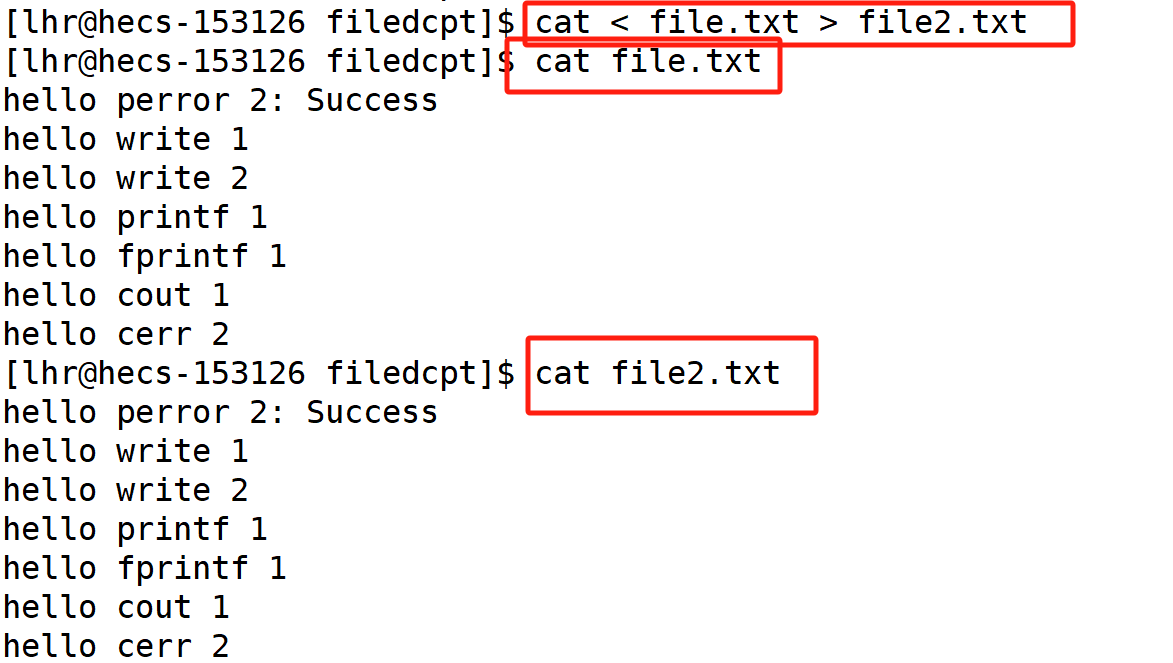
把file的内容传给cat cat拿到后再给file2
2.浅谈perror()
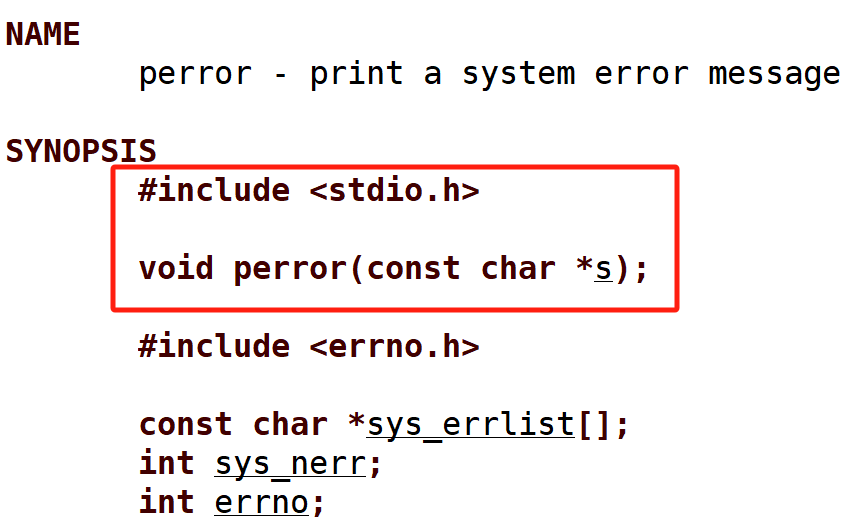

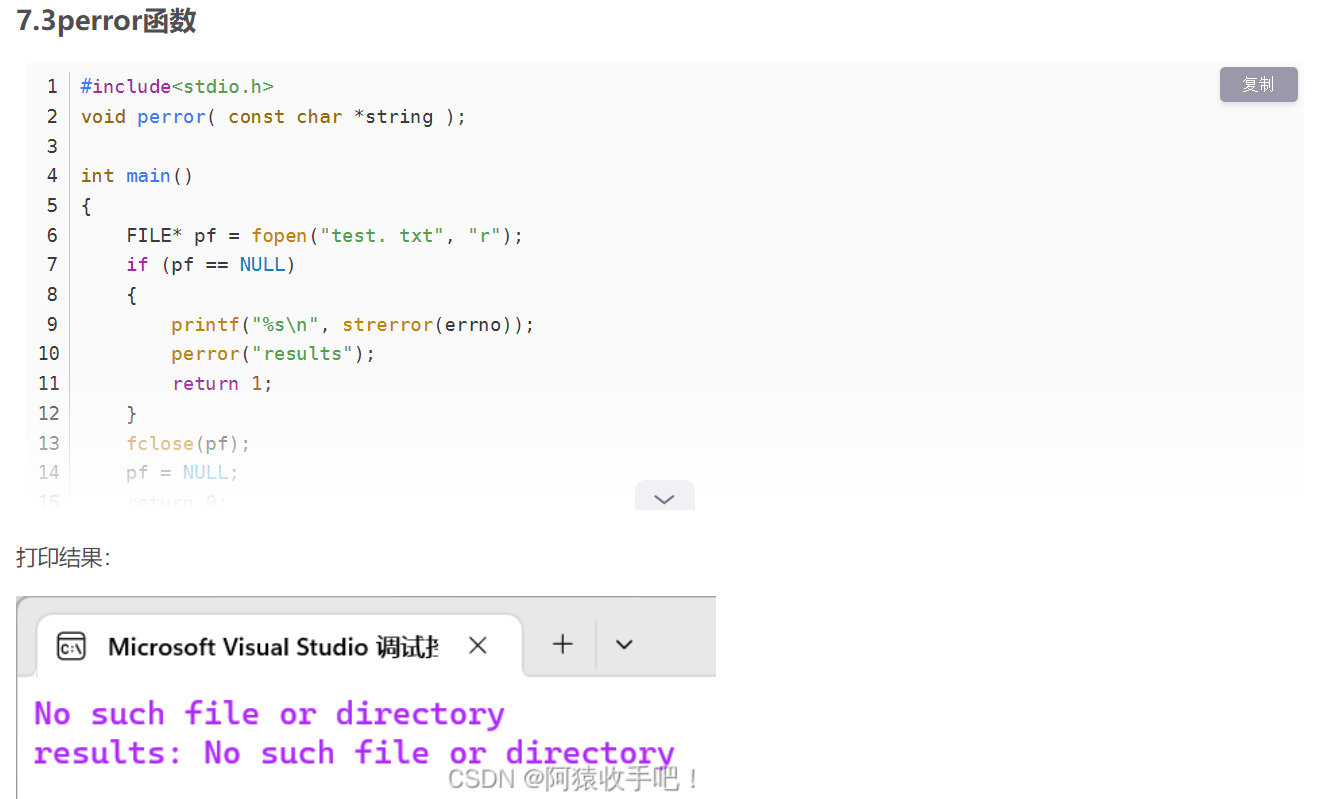
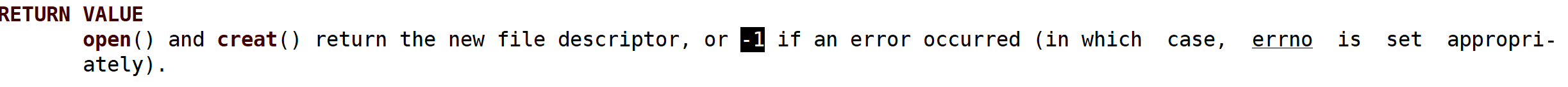
open()接口调用失败返回-1,并且错误码errno被适当的设置,如果在调用perror前显示设置errno,perror会输出对应的错误信息(for debug,Meaningless)
模拟实现perror()

3.初始文件系统
- 文件分为被打开的文件(内存文件)和未被打开的文件(磁盘文件)
- 内存文件:被进程打开的文件,文件被加载到内存中供进程快速读写。
- 磁盘文件:没有被打开的文件,保存在磁盘上。磁盘文件被分门别类的存储和管理,用于支持更好的存取。
- 学习磁盘文件的重点:
- 单个文件角度: 文件的位置 大小 属性…
- 系统角度: 文件的个数 每个文件的属性存储在哪里 如何快速找到 还可以存储多少文件 如何快速找到指定文件
- 了解对磁盘文件进行分门别类的存储方式 支持更好更快的存取
了解磁盘文件
- 已知内存(Random Access Memory)是一种掉电易失存储介质 而磁盘(Hard Disk Drive)是一种永久性存储介质(除了磁盘还有 SSD[Solid State Drive]/U盘/flash卡/光盘/磁带)[速度内存>SSD>磁盘]
- 磁盘是一个外设 是计算机中唯一一个机械设备 速度慢(相比之下) OS有提速方式(后期讲)
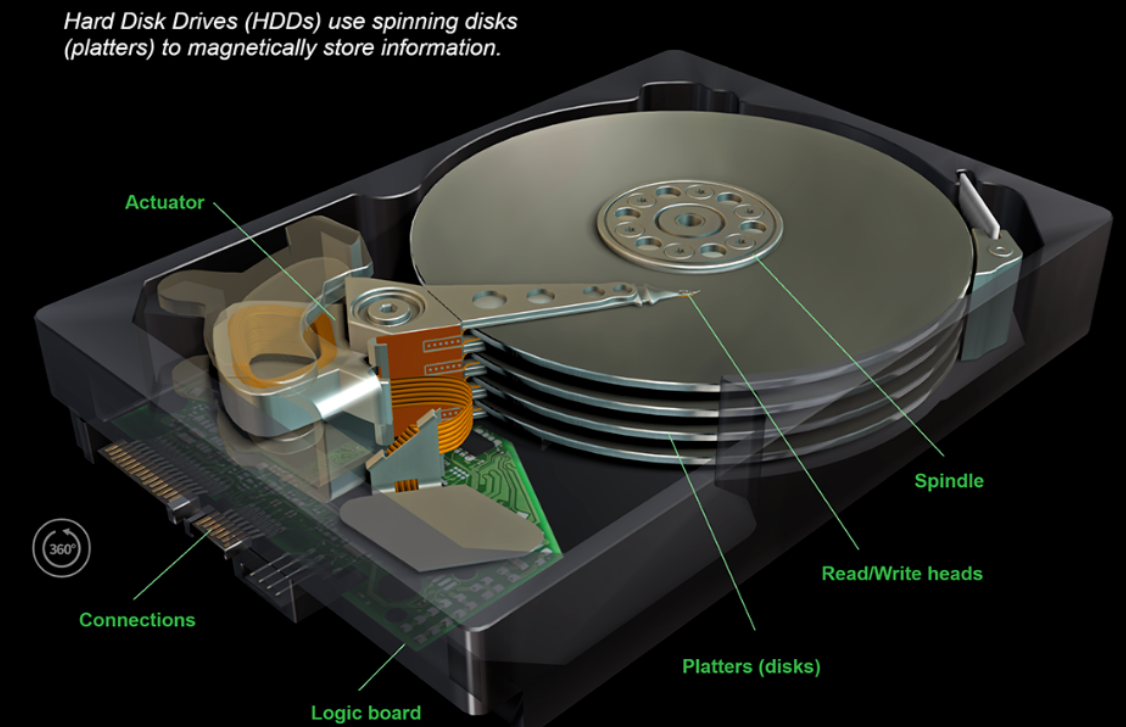
磁盘的物理结构(笔记本不要在开机状态下来回移动 以免损坏磁盘)

- actuator:伺服电机(音圈马达,包括永磁铁和线圈)
- spindle:主轴(包括轴承与马达)
- read/write heads:磁头(读写头)
- platters(disks):磁盘盘片
- logic board:磁盘主板(逻辑板)
- connections:接口
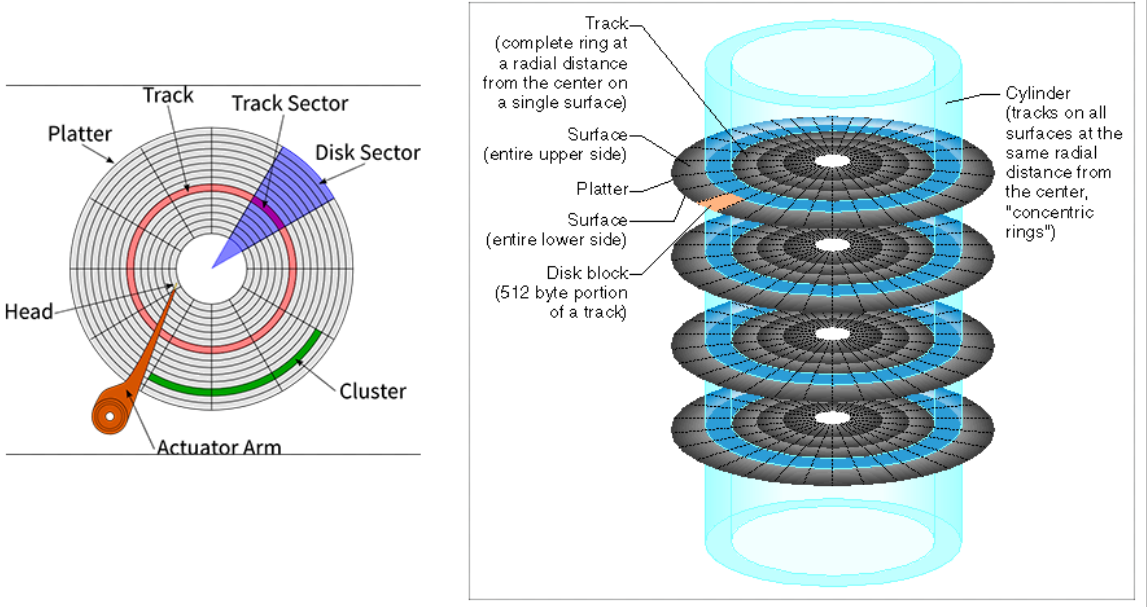
- 磁盘盘面上存储二进制数据(通过磁头改变磁盘上的正负性)
- 利用磁性材料在磁场作用下的磁化性质,在磁盘表面上划分成许多小区域,根据不同的磁化方向来表示0和1的二进制数据,读写磁头在磁盘上移动实现数据的读写
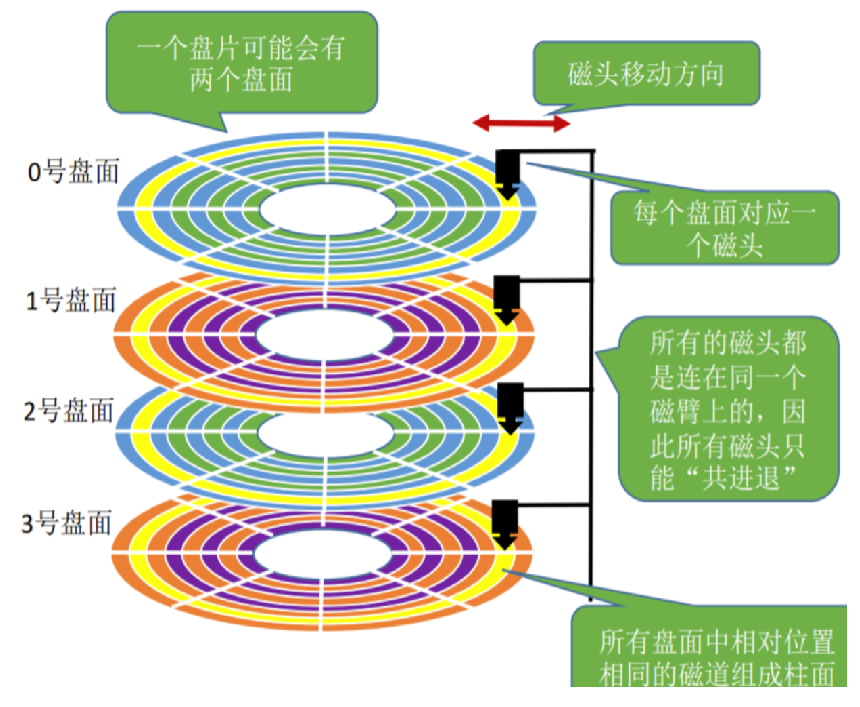
磁盘的存储结构
- 一个盘面有两面,两面都可以读写数据,一个磁盘有多个盘面
- 盘片中有很多微小的磁块。磁头对磁块进行放磁,用南北极来标识0或1
- 在盘面上,每一圈对应着一个磁道,磁道又分为多个扇区。磁头在定位对应盘面的时候,整体共进退的,磁头共同在同一个磁道上找,整体形成柱面。
- 对于扇区来说,靠近圆心的扇区面积小,远离圆心的扇区面积大,每个扇区都是512byte,密度不一样。靠近圆心的密度大
- 扇区(Sector):扇区是磁盘上最小的存储单位。它是一个固定大小的数据块,通常为512字节或4KB。磁盘上的数据以扇区为单位进行读写
- 磁道(Track):磁盘上的一个圆形轨道,位于磁盘的表面上。磁盘由多个同心圆组成,每个同心圆上都有一个磁道。磁道是磁盘上的物理结构,用于存储数据。磁道上的扇区可以被读写
- 柱面(Cylinder):柱面由多个磁盘盘片(Platter)上的相同磁道组成的垂直堆叠。每个盘片上的相同编号磁道构成一个柱面。柱面是磁盘存储系统中的逻辑概念,用于组织和寻址数据。操作系统和磁盘控制器使用柱面号来定位和访问磁盘上的数据
- 扇区是磁盘上最小的存储单位,磁道是磁盘上的一个圆形轨道,柱面是由多个磁盘盘片上的相同磁道组成的垂直堆叠。chs在磁盘存储系统中用于组织和管理数据,提供对数据的读写
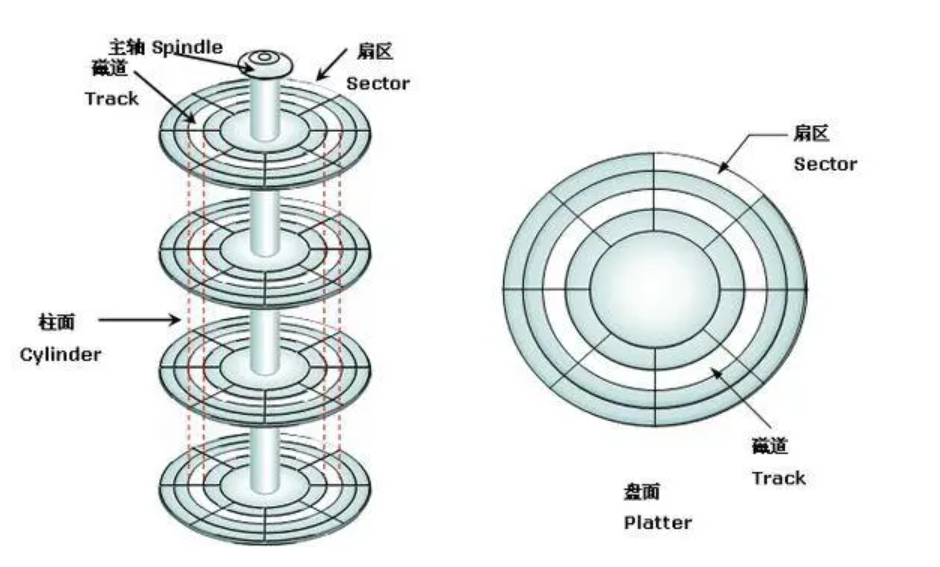
扇区是一个相对独立的存储单元,扇区容量的存储大小通常是固定的。一个扇区可以存储512Byte的有效数据。(目前已存在能存储4kb的扇区).扇区的标号从1开始
寻址方式[磁盘的寻址方式按512byte(一个扇区)]
- CHS(Cylinder-Head-Sector)寻址方式是一种早期的磁盘寻址方式,用于定位和访问磁盘上的数据。它将磁盘的物理结构抽象为柱面、磁头和扇区的组合。将磁盘划分成多个柱面,每个柱面有多个磁头,每个磁头上有多个扇区。通过指定柱面、磁头和扇区的地址,可以定位到磁盘上的特定位置。
- CHS寻址方式使用柱面号、磁头号和扇区号来定位和访问磁盘上的数据。 通过指定柱面号、磁头号和扇区号,操作系统或磁盘控制器可以精确地定位到磁盘上的特定数据位置。
- CHS寻址方式存在一些问题,比如柱面、磁头和扇区数的限制以及寻址的不规则性,导致对于大容量磁盘的支持较为困难。
- LBA寻址方式使用逻辑块号来定位和访问磁盘上的数据,更加简单和灵活,能够支持更大容量的磁盘 LBA寻址方式是一种依据逻辑块号对磁盘进行寻址的方式。逻辑块号是磁盘上每个扇区的唯一标识,通过逻辑块号可以直接寻址到磁盘上的特定扇区
- CHS寻址方式是使用柱面、磁头和扇区三个参数来确定磁盘上的数据位置。这种方式的优点是寻址方式简单,寻址速度快,但缺点是只能用于容量较小的硬盘,并且由于物理参数的限制,寻址范围有限。
- 随着硬盘容量的增长,CHS寻址方式的局限性越来越明显。为了解决这个问题,LBA寻址方式被引入。LBA将磁盘上的数据位置表示为一个逻辑块地址,这个地址是一个线性地址,与实际的物理参数(柱面、磁头和扇区)无关。这种方式使得硬盘容量可以更大,寻址范围更广,并且简化了操作系统对磁盘的管理。
- 在LBA寻址方式中,磁盘被抽象为逻辑块的序列,每个逻辑块都有一个唯一的逻辑块号(LBA)。逻辑块是磁盘上的最小可寻址单位,对应磁盘上的扇区,通常为512字节或4KB。LBA寻址方式不需要考虑磁盘的物理结构,如柱面、磁头和扇区。通过指定逻辑块号,操作系统或磁盘控制器可以直接定位到磁盘上的特定逻辑块,无需关心磁盘的物理布局。LBA寻址方式的优点是简单和灵活。它可以支持更大容量的磁盘,并且不受物理结构的限制。此外,LBA寻址方式还可以提供更高的数据传输速率和更好的数据可靠性。
- 相比于CHS,LBA有以下优点:
更大的硬盘容量:由于LBA使用线性地址,可以轻松管理大容量硬盘。
更简单的寻址方式:LBA只需要一个逻辑块地址即可找到数据,比CHS的三个物理参数更简单。
更快的寻址速度:由于LBA的线性地址结构,寻址计算更简单,寻址速度更快。
更好的兼容性:LBA可以用于不同类型的磁盘,包括固态硬盘和网络存储设备等。
从技术角度看,LBA比CHS更先进,更适合现代计算机系统对大容量存储的需求。
磁盘的逻辑存储结构
- 将磁盘盘片抽象为线性结构(类似于数组),扇区抽象为逻辑块(数组元素),每个逻辑块都有逻辑块号(数组下标)
- 磁盘在物理上的存储结构是圆形的,将其抽象成数组进行认识。数组含多个磁道,磁道含多个扇区.
将逻辑块序列当成数组,逻辑块号作为数组下标
- 将数据存储到磁盘 ⇒ 将数据存储到数组
- 找到磁盘特定扇区的位置 ⇒ 找到数组特定的位置
- 对磁盘的管理 ⇒ 对该数组的管理 ⇒ 对一个小分区的管理
内存访问磁盘
- 磁盘在读取时基本单位是512Byte,OS一次读取多个扇区(512Byte太小了),比如1KB、2KB、3KB、4KB(主要)
- 一次读多个扇区,访问一个字节时,也要将4kb空间加载到到内存。
- 当访问数据A时,A附近的数据也可能被访问到。加载更多的数据到内存一定程度上减少了IO次数,本质是一种数据预加载,空间换时间!
- 内存也被划分成了多个4KB大小的空间,这个空间称为页框,一个4KB大小的块被称为页帧。
文件系统[文件 =内容 +属性]
- Linux管理磁盘文件,是将文件内容和文件属性分开管理的 Linux在磁盘上存储文件的时候,将内容和属性是分开存储的
- 虽然磁盘的基本单位是扇区(512字节),但是操作系统(文件系统)和磁盘进行I0的基本单位是4KB(8*512byte) 4kb ⇒ block大小 磁盘⇒ 块设备
- 磁盘存储数据的基本单位是扇区(512B~4KB),一个block是4KB(8*512B)大小。为什么不以扇区大小作为IO操作的基本单位呢?
- 太小了,导致多次I0,导致效率的降低
- 如果操作系统使用和磁盘一样的大小,当磁盘基本大小改变,0S的源代码也得改呢 ⇒ 硬件和软件(0S)进行解耦
文件系统与磁盘分区
- 磁盘分区是将一个物理硬盘分成多个逻辑区域的过程。每个分区可以看作是一个独立的硬盘,可以分别安装操作系统和存储数据。磁盘分区可以提高磁盘的利用率,提高系统的性能和安全性。
- 文件系统是操作系统用来管理磁盘上文件和目录的一种机制。文件系统定义了文件和目录的命名规则、存储方式、访问权限等信息。常见的文件系统有FAT、NTFS、EXT4等。
- 磁盘分区和文件系统密切相关,每个分区都需要使用一种文件系统来管理其中的文件和目录。Windows系统通常使用NTFS文件系统,Linux系统则通常使用EXT4文件系统。
- EXT是Linux系统中最常用的文件系统之一,它是一种基于磁盘块的文件系统,支持文件和目录的权限控制、硬链接和软链接等功能。EXT系列的文件系统在Linux系统中广泛使用,是Linux系统的重要组成部分。
- EXT:最早的EXT文件系统,已经很少使用。
EXT2:EXT2是Linux系统中最常用的文件系统之一,支持文件和目录的权限控制、硬链接和软链接等功能。
EXT3:增加了日志功能,可以更好地保护文件系统的完整性和稳定性。
EXT4:增加了一些新的特性,如更快的文件系统检查和修复、更大的文件和分区支持、更好的性能和可靠性等。
磁盘文件系统图
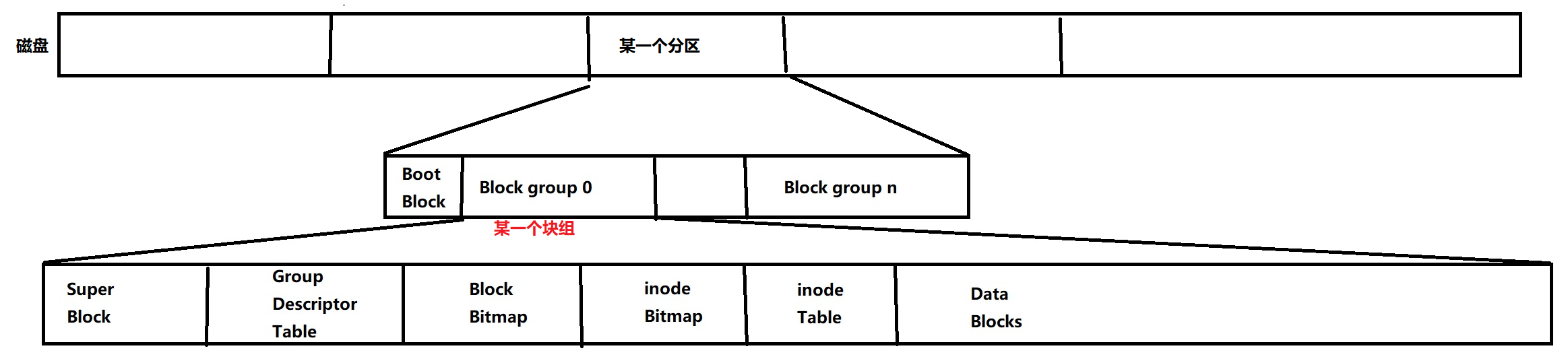
Boot Block:引导块,磁盘分区中的引导块是存储引导加载程序、引导信息和分区表的特殊区域。引导加载程序和引导信息用于启动操作系统和提供必要的配置信息;分区表中记录了磁盘上的分区布局和分区的起始位置、大小等信息。boot block有多份拷贝,防止一份损坏,全盘皆失
Block group:块组,一个磁盘分区可以再划分为多个块组。
block:数据块,操作系统和磁盘进行IO操作的基本单位是4KB,即1个block大小,因此磁盘又叫做块设备。block用于保存文件内容,一个文件可能包含多个block。
Super Block:存储文件系统的属性信息 存放文件系统本身的结构信息,有属性信息、磁盘布局和资源使用情况等信息。超级块属于整个分区,分区有许多分组都有对应的超级块,多个意味着备份,保存在不同分组,若某一个分组的文件系统坏了,可以用其它分组的超级块恢复。存储了该分区文件系统的元数据信息。包括文件系统的大小、块大小、inode数量等,以及文件系统的状态和配置信息。
Data blocks:多个4KB(扇区*8)大小的集合 ,保存的都是特定文件的内容
inode:索引节点,是一个大小为128字节的空间,用于保存对应文件的属性。每个inode节点都有一个唯一的inode编号。一个文件只有一个inode。 一般而言一个文件,一个inode,一个inode编号
inode Table:该块组内,所有文件的inode空间的集合,需要标识唯一性,每一个inode块,都要有一个inode编号 索引节点表,多个文件的inode节点的集合,用于保存对应文件的属性。每个分区都有自己的inode table,用于存储该分区中所有文件和目录的inode信息。在同一分区中,通过inode编号,可以唯一地标识和定位一个文件或目录。
Block Bitmap:比特位和特定的block一一对应,比特位为1代表该block被占用
inode Bitmap:比特位和特定的inode是一一对应的。比特位为1,代表该inode被占用
GDT:[快组描述符,这个快组多大,已经使用了多少了,有多少个inode,已经占用了多少个,还剩多少,一共有多少个block,使用了多少… ] 用于存储该块组的元数据信息。包括块组的起始位置,块组的大小,块位图的位置,索引节点位图的位置,索引节点表的位置,块组中可用空间的大小,块组中可用索引节点的数量,其他块组特定的信息等,以便操作系统能够快速定位和管理文件系统中的数据块和索引节点。
元数据: 描述数据的数据,它提供了关于数据的属性、结构、格式、位置和其他相关信息,帮助系统理解和管理数据。对于文件来说,元数据信息可能包括文件的名称、大小、创建时间、修改时间、访问权限等。对于分区文件系统来说,不单单只是保存文件信息,还有一批元数据结构专门负责管理信息,如Bitmap,用于管理Data blocks和inode Table;GDT,用于描述和管理整个块组;super block,用于描述和管理整个分区文件系统;元数据结构的存在才能够让文件的信息可追溯,可管理。
格式化: 磁盘格式化通常包括以下步骤:分区,创建文件系统(创建元数据结构,初始化元数据结构),完成格式化。实际上就是在写入文件系统。磁盘格式化是一个重要的步骤,确保磁盘上的文件系统结构正确创建,为文件和数据的存储提供了必要的基础。
- 能够让一个文件的信息可追溯,可管理
- 文件 = 内容 + 属性 文件内容保存在数据块中(Data Blocks),文件属性保存在Inode中。
- Inode(ext3-128byte ext4-256byte)包括一个文件的几乎所有属性(文件名不在Inode中)每个文件都有一个Inode
- 将块组分割成为上面的内容,写入相关的管理数据 每一个块组都这么搞 整个分区就被写入了文件系统信息 ⇒ 格式化
如何查找指定文件
一个文件"只"对应一个inode属性节点,inode编号但是一个文件可以有多个block
目录结构 – inode编号 – 某一个分区下的某一个块组 – inode区域 – 属性 – 内容
如何找到同一个文件的多个block?想要找到文件,只要找到文件对应的inode编号,就能找到该文件的inode属性集合,如何找到文件的内容?⇒ blocks[]
struct inode{int size;mode_t mode;...int blocks[15];blocks[0] blocks[1] blocks[2]
}
- 在inode中有一个blocks数组,0-11一般指向一个数据块,如果文件只占少量数据块,下标定位即可
- 12-13-14指向的数据块,里面可以保存其它数据块的块号,可以指向很多给数据块
inode中有文件名吗?
- inode属性中没有文件名。
- 目录也是文件,有自己的inode和data block。
- inode保存目录文件的属性;data block保存目录文件的内容 ⇒ 文件名和inode编号的映射关系。
- 进入目录需要x权限
在目录下创建文件需要w权限: 向目录的data block中写数据 ⇒ 即文件名和inode的映射关系
显示文件名与属性需要r权限 : 从目录的data block中读数据 ⇒ 即文件名和inode的映射关系 - 在同一目录下,不能创建同名文件。因为要保持文件名和inode编号的一一映射关系。
重新认识文件的操作
- 创建文件:
- 在分区中找一块大小合适的块组;
- 遍历inode Bitmap找到第一个为0的比特位将该位置1,创建文件inode。获得文件的inode编号。
- 初始化文件inode,将文件的初始属性信息填入到inode中。若为空文件则清空和data blocks的映射关系
- 向当前目录的data block中写入文件名(用户)和inode编号(文件系统)的映射关系。
- 删除文件:
-
通过文件名,在目录文件的block中找到对应的inode编号。
-
通过inode编号,找到文件的inode。其中包含一部分属于该文件的block编号。
-
在block bitmap中将文件所属的block位,置0。在inode bitmap中将文件的inode位,置0。
-
删除目录文件中记录的文件名和inode编号的映射关系。
-
删除文件时,不需要将数据清空,只需要将文件所占的空间标定无效即可。⇒ 删除文件要比拷贝文件要快。
-
系统会记录文件的删除日志,包括删除文件的文件名及inode编号。如果对应空间没有被覆盖写入的话,是可以利用工具恢复已经删除的文件的(将inode/block bitmap中的对应位置1)。
- 查看文件(ls -l):
- 通过文件名,在目录文件的block中找到对应文件的inode编号。
- 通过inode编号,找到文件的inode。inode中包含文件的属性信息。
- 格式化输出文件名及各种属性。
- 修改文件:
-
打开文件,将文件加载到内存,获取对应的文件描述符。
-
进程将数据拷贝到缓冲区,根据刷新策略将缓冲区中的数据刷新到文件描述符对应的磁盘文件。
-
通过文件名,在目录文件的block中找到对应文件的inode编号。
-
通过inode编号,找到文件的inode。将数据刷新到文件的data block。
-
为什么分区/块组有剩余空间但无法创建新文件?
块组中的inode和data block的大小和个数是固定的,当inode有空余但data block占满,或data block有空余但inode占满 ⇒ 该分区/块组有剩余空间,但无法创建新文件(inode占满),或文件无法进行写入(data block占满)。
4.软硬链接
如何创建?
创建软链接的命令:ln -s 路径+文件名 soft.link [-s: soft]
创建硬链接的命令:ln 路径+文件名 hard.link
有何区别?
- 软链接
- 软链接有独立的inode,是一个独立的文件。
- 软链接的文件内容是目标文件的路径。
- 软链接相当于Windows系统下文件的快捷方式。
- 硬链接
- 硬链接没有独立的inode,不是一个独立的文件。
- 与目标文件共享同一个inode,其内容,属性与目标文件完全相同。
- 本质上是在指定目录下建立了文件名和目标文件inode编号的映射关系,并没有创建新文件 ⇒ 起别名
- 文件属性中的硬链接数表示与文件inode关联的文件名的数量。每创建一个硬链接,硬链接数就+1
- 当删除文件时,如果文件的硬链接数大于1,就将硬链接数-1。如果文件的硬链接数等于1,真正删除这个文件。
对硬链接的认识
新创建的普通文件只有1个文件名与其inode关联,硬链接数为1。
新创建的目录文件硬链接数为2。分别为: 当前目录名,目录中的当前目录即.
在目录中每创建一个子目录都会使硬链接数+1 ⇒ 每一个子目录中都有一个上级目录…
目录的硬链接数 -2 == 个数子目录
如何删除?
- unlink:用于删除普通文件的系统调用,实际是解除文件名和inode的链接关系
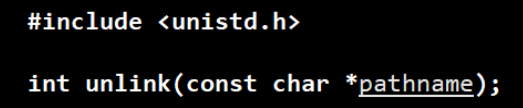
- 一般命令 rm
言外知识点
在linux下 . [ 也可以是文件名