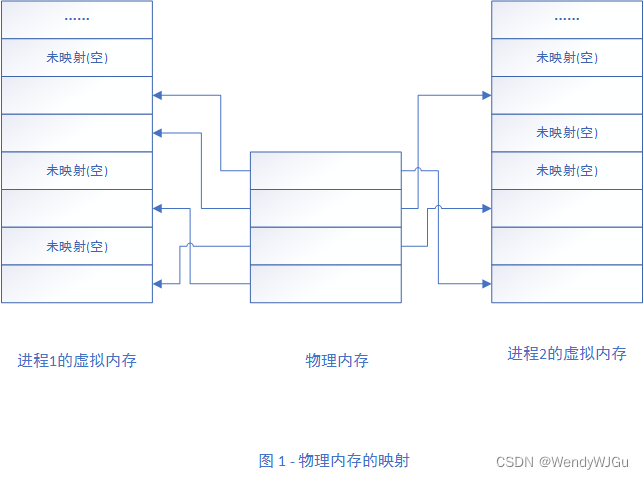
MySQL 在高并发和大数据量场景下,单个实例的扩展性有限。而 TiDB 作为一款分布式NewSQL数据库,设计之初就支持水平扩展(Scale-Out),通过增加节点来线性提升处理能力和存储容量,能够很好地应对大规模数据和高并发读写需求。
TiDB 对 MySQL 协议提供了高度兼容,应用程序可以几乎无感知地从 MySQL 迁移到 TiDB,同时许多现有的 MySQL 工具和框架也能直接应用于 TiDB。
但是TiDB毕竟不等于 MySQL,还是有一些少许的差异,今天就带大家了解下 TIDB 与MySQL 的差异。
TiDB与MySQL兼容性对比
TiDB 高度兼容 MySQL 5.7 协议、MySQL 5.7 常用的功能及语法。TiDB 尚未支持一些MySQL 功能,可能得原因如下:
- 有更好的解决方案,例如 JSON 取代 XML。
- 目前对这些功能需求度不高,例如存储流程和函数。
- 一些功能在分布式系统上的实现难度较大。
除此之外 TiDB 不支持 MySQL 复制协议,但提供了专用工具与 MySQL 复制数据:
- 从 MySQL 复制:TiDB Data Migration(DM) 是将 MySQL/MariaDB 数据迁移到 TiDB 的工具,可用于增量数据复制。
- 向 MySQL 复制:TiCDC 是一款通过拉取TiKV变更日志实现的TiDB增量数据同步工具。
下面来看下 TiDB 与 MySQL 的详细差异。
自增ID
TiDB 的自增列既能保证唯一,也能保证在单个 TiDB server 中自增,只用AUTO_INCREMENT MySQL 兼容模式能保证多个 TiDB server 中自增 ID,但不保证自动分配的值的连续性。
TiDB 可通过 tidb_allow_remove_auto_inc 系统变量开启或者关闭允许移除列的 AUTO_INCREMENT 属性。删除列属性的语法是:ALTER TABLE MODIFY 或 ALTER TABLE CHANGE。
TiDB 不支持添加列的 AUTO_INCREMENT 属性,移除该属性后不可恢复。
若创建表时没有指定主键时,TiDB会使用 _tidb_rowid 来标识行,该数值的分配和自增列(如果存在的话)公用一个分配器。如果指定了自增列为主键,则TiDB会用该列来标识行。
使用 AUTO_INCREMENT 可能会给生产环境带来热点问题,因此推荐使用AUTO_RANDOM代替。
执行计划
TiDB中,执行计划(EXPLAIN 和 EXPLAIN FOR),在输出格式、内容、权限设置方面与MySQL有较大差异。
使用 EXPLAIN 可查看 TiDB 执行某条语句时选用的执行计划。也就是说,TiDB 在考虑上数百或数千种可能的执行计划后,最终认定该执行计划消耗的资源最少、执行的速度最快。
CREATE TABLE t (id INT NOT NULL PRIMARY KEY auto_increment, a INT NOT NULL, pad1 VARCHAR(255), INDEX(a)
);INSERT INTO t VALUES (1, 1, 'aaa'),(2,2, 'bbb');EXPLAIN SELECT * FROM t WHERE a = 1;返回结果如下:
Query OK, 0 rows affected (0.96 sec)Query OK, 2 rows affected (0.02 sec)
Records: 2 Duplicates: 0 Warnings: 0+-------------------------------+---------+-----------+---------------------+---------------------------------------------+
| id | estRows | task | access object | operator info |
+-------------------------------+---------+-----------+---------------------+---------------------------------------------+
| IndexLookUp_10 | 10.00 | root | | |
| ├─IndexRangeScan_8(Build) | 10.00 | cop[tikv] | table:t, index:a(a) | range:[1,1], keep order:false, stats:pseudo |
| └─TableRowIDScan_9(Probe) | 10.00 | cop[tikv] | table:t | keep order:false, stats:pseudo |
+-------------------------------+---------+-----------+---------------------+---------------------------------------------+
3 rows in set (0.00 sec) EXPLAIN 实际不会执行查询。EXPLAIN ANALYZE 可用于实际执行查询并显示执行计划。如果 TiDB 所选的执行计划非最优,可用 EXPLAIN 或 EXPLAIN ANALYZE 来进行诊断。
内建函数
支持MySQL常见的内建函数,有部分函数并未支持。可通过执行 SHOW BUILTINS 语句查看可用的内建函数。
DDL限制
TiDB中,所有支持的DDL变更操作都是在线执行的。与MySQL相比,TiDB中的DDL存在以下限制:
- 使用 ALTER TABLE 修改一个表的多个模式对象(如列、索引)时,不允许在多个更改中指定一个模式对象。例如,ALTER TABLE t1 MODIFY COLUMN c1 INT, DROP COLUMN c1 在两个更改中都指定了 c1 列,执行该语句会输出 Unsupported operate same column/index 的错误。
- 不支持使用单个 ALTER TABLE 语句同时修改多个TiDB特有的模式对象。
- ALTER TABLE 不支持少部分类型的变更。比如,TiDB 不支持从 DECIMAL 到 DATE 的变更。当遇到不支持的类型变更时,TiDB 将会报 Unsupported modify column: type %d not match origin %d 的错误
- 不支持指定不同类型的索引 (HASH|BTREE|RTREE|FULLTEXT)。若指定了不同类型的索引,TiDB 会解析并忽略这些索引。
- 分区表支持HASH、RANGE 和 LIST 分区类型。对于不支持的分区类型,TiDB 可能会报 Warning: Unsupported partition type %s, treat as normal table 错误,其中 %s 为不支持的具体分区类型。
select 限制
- 不支持 SELECT ... INTO @变量 语法。
- 不支持 SELECT ... GROUP BY ... WITH ROLLUP 语法。
- TiDB 中的 SELECT .. GROUP BY expr 的返回结果与 MySQL 5.7 并不一致。MySQL 5.7 的结果等价于 GROUP BY expr ORDER BY expr。
字符集和排序规则
字符集 (character set) 是符号与编码的集合。TiDB 中的默认字符集是 utf8mb4,与 MySQL 8.0 及更高版本中的默认字符集匹配。
排序规则 (collation) 是在字符集中比较字符以及字符排序顺序的规则。例如,在二进制排序规则中,比较 A 和 a 的结果是不一样的:

TiDB 默认使用二进制排序规则。这一点与 MySQL 不同,MySQL 默认使用不区分大小写的排序规则。
存储引擎
仅在语法上兼容创建表时指定存储引擎,实际上 TiDB 会将元信息统一描述为 InnoDB 存储引擎。TiDB 支持类似 MySQL 的存储引擎抽象,但需要在系统启动时通过--store 配置项来指定存储引擎。
日期时间处理的区别
TiDB 与 MySQL 在日期时间处理上有如下差异:
- TiDB 采用系统当前安装的所有时区规则进行计算(一般为
tzdata包),不需要导入时区表数据就能使用所有时区名称,导入时区表数据不会修改计算规则。 - MySQL 默认使用本地时区,依赖于系统内置的当前的时区规则(例如什么时候开始夏令时等)进行计算;且在未导入时区表数据的情况下不能通过时区名称来指定时区。
总结
从MySQL迁移到TiDB主要是为了满足业务发展带来的海量数据处理、高并发访问、实时分析等需求,同时利用TiDB的分布式优势提高系统的稳定性和可扩展性,并维持较低的运维成本。在使用过程中能满足绝大多数的应用场景,但是要注意细微差异。