1 一些概念和问题
- YOLO中的darknet到底指的是什么?
darknet到底是一个类似于TensorFlow、PyTorch的框架,还是一个类似于AlexNet、VGG的模型?
其实都是。YOLO作者自己写的一个深度学习框架叫darknet(见YOLO原文2.2部分),后来在YOLO9000中又提出了一个19层卷积网络作为YOLO9000的主干,称为Darknet-19,在YOLOv3中继续改进,提出了一个更深的、借鉴了ResNet和的FPN的网络Darknet-53。这两者都是用于提取特征的主干网络。
Darknet is an open source neural network framework written in C and CUDA. It is fast, easy to install, and supports CPU and GPU computation.
首先作者造了一个开源的深度学习框架,然后又提出了一个backbone,它们的名字都叫darknet。你可以用这个框架实现resnet mobilenet等其他backbone,也可以实现darknet这个backbone。
- 深度学习框架是什么?
深度学习框架也就像Caffe、tensorflow这些帮助你进行深度学习的工具,简单来说就是库,编程时需要import caffe。作一个简单的比喻,一套深度学习框架就是这个品牌的一套积木,各个组件就是某个模型或算法的一部分,你可以自己设计如何使用积木去堆砌符合你数据集的积木。
好处是你不必重复造轮子,模型也就是积木,是给你的,你可以直接组装,但不同的组装方式,也就是不同的数据集则取决于你。
深度学习框架的出现降低了入门的门槛,你不需要从复杂的神经网络开始编代码,你可以依据需要,使用已有的模型,模型的参数你自己训练得到,你也可以在已有模型的基础上增加自己的layer,或者是在顶端选择自己需要的分类器。
当然也正因如此,没有什么框架是完美的,就像一套积木里可能没有你需要的那一种积木,所以不同的框架适用的领域不完全一致。
因为caffe,CNN模型是给的,直接训练就行了,那如何设计自己的模型呢。但后来深入后,就发现框架不就是像积木一样嘛,总不能说积木就没有自己设计的成分吧?如果你不嫌麻烦,从头开始设计网络结构,也可以。
- 训练数据每类需要多少图片才可以?
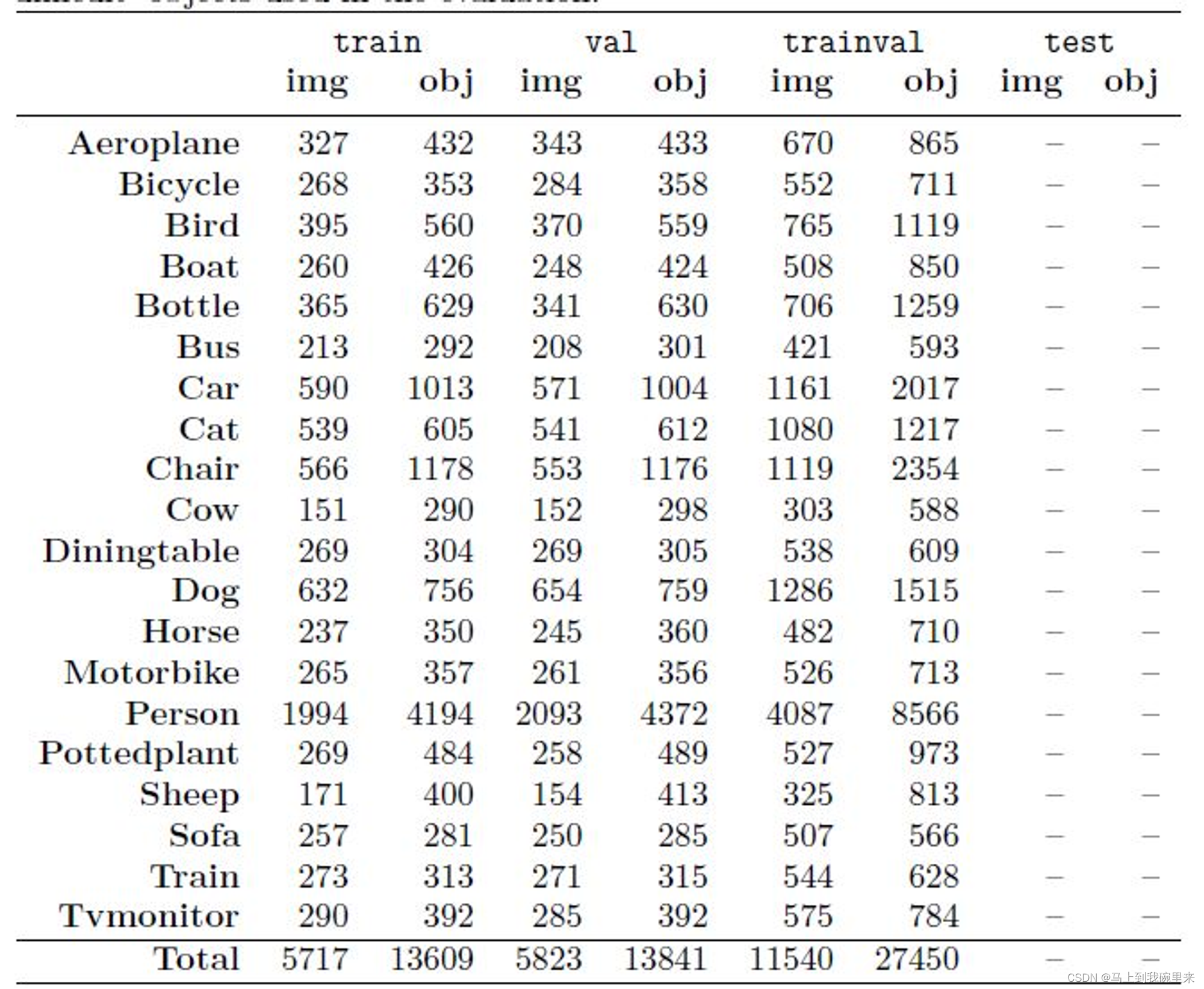
一张图片可以标注多种类别, 至于多少图片才可以,取决于对最终效果的期望,可以参考pascal voc数据集每类的数量。
Pascal VOC2012 Main中统计的训练、验证、验证与训练、测试图像如下:参考链接
- yolo与其他faster cnn等?
一般来说,yolo带给我们的是在检测速度上的优势,同时又保证了不错的准确率,但如果更关注的是检测的准确度,建议用二阶段模型,例如faster rcnn等
- 预训练权重是什么?
首先权重文件保存的就是训练好的网络各层的权值,也就是通过训练集训练出来的。训练好之后,应用时只要加载权值就可以,不再需要训练集了。
问题:权重是各层之间的一个权值的话,那我没开始训练我自己的数据集之前,这个每层的权值是很不准确的(或者根本没关系),所以这个预训练权重只是起到一个让模型运行的初始值的作用?这个预训练权重并不会对我即将要训练的对象产生任何正向或者负向的影响。
2 准备工作
2.1 yolov4文件夹
下载项目代码:git clone https://github.com/AlexeyAB/darknet.git
哪个版本都可以yolov3,yolov4,darknet,都是基于darknet的框架,所以结构基本都一致。
下载项目文件夹后,需要对其中的Makefile做一个简单的修改并且编译。
2.2 权重文件和预训练权重文件
- yolov4.weights 权重文件(分为tiny和一般的)
- yolov4.conv.137 预训练权重文件
测试权重文件的检测效果:./darknet detect cfg/yolov4.cfg yolov4.weights data/dog.jpg
3 数据集准备
yolo的数据包括训练数据和验证数据(训练数据用来训练模型,验证数据用来调整模型)。训练数据和验证数据都包括:a.图片;b.标签。需要说明的是,如果采用VOC的话,标签需要特定xml格式,还要转化为txt。
3.1 采集数据并标记
采集数据,并使用labelImg工具标注完成自己的数据集,到此为止得到一个xml格式的数据集,将这些xml文件放在一个文件夹中以待使用。
3.2 标记好的数据存放位置
1、标记好数据文件结构
首先将自己的数据集标记生成为VOC数据集的格式,至少生成如下格式的文件夹:
(或者可以直接下载VOC2007数据集,把所有文件夹里面的东西删除,保留所有文件夹的名字。)
以下链接介绍了比较常用的两个数据集的下载地址。
此文介绍了用coco和Pascal VOC数据集进行训练
Annotations
ImageSets--Main--test.txt--train.txt--trainval.txt--val.txt //其中这四个txt文件,需要用代码生成。
JPEGImages
Annotations:该文件夹存放的是标记数据集的xml文件(VOC数据集格式)JPEGImage:该文件夹存放的是待标记的原始数据集ImageSets/Main:该文件夹存放的是划分数据集的文件名,文件中的文件名不包含文件后缀
2、标记好数据放到Darknet项目的位置
/darknet/scripts/VOCdevkit/VOC2007
VOCdevkit和VOC两个文件夹需要自己创建:
mkdir -p scripts/VOCdevkit/VOC2007
然后把上面的Annotations、ImageSets、JPEGImage三个文件夹放到VOC2007文件夹下.
3.3 修改和数据类别相关文件
对/darknet/scripts/voc_label.py文件进行修改:
voc_label.py复制到项目根目录下(darknet),并对其内容进行修改。
1、第一处:修改第7行,修改数据集
sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]# 修改为如下:
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
2、第二处:修改第9行,修改数据集的类别,改为自己数据集定义的类别
# 把下面类表中定义的类别换成自己定义的类别即可classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
需要的文件:
- 标记的xml文件,在VOCdevkit/VOC2007/Annotations下
- 划分数据集的文件:ImageSets/Main/train.txt,test.txt,val.txt 里面存的是图片的名字
需要代码生成这三个文件train.txt,test.txt,val.txt*。代码如下:test.py*
import os
import randomtrainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')for i in list:name = total_xml[i][:-4] + '\n'if i in trainval:ftrainval.write(name)if i in train:ftest.write(name)else:fval.write(name)else:ftrain.write(name)ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
修改完成以后,运行: voc_label.py 文件,生成YOLO训练时使用的labels (labels包含标注物体的位置和类别信息)
python voc_label.py
生成的文件:
运行结束以后,可以在/darknet/scripts/VOCdevkit/VOC2007文件夹内看到labels文件夹,文件夹下是把VOC格式标签文件xml文件转换为的YOLO格式标签txt文件。
- 生成训练数据集大小的n个
YOLO格式的txt文件 - 在
/darknet/scripts文件夹内会生成2007_train.txt、2007_test.txt、2007_val.txt三个文件(文件中的内容是数据集的绝对路径)
举例:008890.txt 是转换后的,第一个数是类别标签,后面的是框的中心坐标以及框的宽和高
(yolo) dw@estar-cvip:/HDD/shl/1_YOLO/darknet-master/scripts/VOCdevkit/VOC2007/labels$ cat 008890.txt
11 0.6213333333333333 0.401 0.6613333333333333 0.19
到这里数据的准备工作就已经全部完成了
voc_labe.py主要做了什么事?主要是把标签框的标签进行了归一化
4 修改训练的配置文件
训练之前需要对一些文件进行自定义修改
4.1 修改cfg/voc.data
classes= 20 //修改为训练分类的个数
train = /home/ws/darknet/scripts/2007_train.txt //修改为数据阶段生成的2007_train.txt文件路径
valid = /home/ws/darknet/scripts/2007_val.txt //修改为数据阶段生成的2007_val.txt文件路径
names = data/voc.names
backup = backup
这里的几个路径是不对的!!!需要按自己的电脑设置!!!
4.2 修改data/voc.names
在上边修改的文件内有一个data/voc.names文件,里边保存目标分类的名称,修改为自己类别的名称即可。
4.3 修改cfg/yolo-voc.cfg
第一处
文件开头的配置文件可以按照下边的说明进行修改
其实训练过程中最关键的应该就是这个cfg了!
# Testing
# batch=1
# subdivisions=1
# Training
batch=64 //每次迭代要进行训练的图片数量 ,在一定范围内,一般来说Batch_Size越大,其确定的下降方向越准,引起的训练震荡越小。
subdivisions=8 //源码中的图片数量int imgs = net.batch * net.subdivisions * ngpus,按subdivisions大小分批进行训练
height=416 //输入图片高度,必须能被32整除
width=416 //输入图片宽度,必须能被32整除
channels=3 //输入图片通道数
momentum=0.9 //冲量
decay=0.0005 //权值衰减
angle=0 //图片角度变化,单位为度,假如angle=5,就是生成新图片的时候随机旋转-5~5度
saturation = 1.5 //饱和度变化大小
exposure = 1.5 //曝光变化大小
hue=.1 //色调变化范围,tiny-yolo-voc.cfg中-0.1~0.1
learning_rate=0.001 //学习率
burn_in=1000
max_batches = 120200 //训练次数
policy=steps //调整学习率的策略
steps=40000,80000 //根据batch_num调整学习率,若steps=100,25000,35000,则在迭代100次,25000次,35000次时学习率发生变化,该参数与policy中的steps对应
scales=.1,.1 //相对于当前学习率的变化比率,累计相乘,与steps中的参数个数保持一致;
注意:如果修改max_batches总的训练次数,也需要对应修改steps,适当调整学习率!!!!!!
比如 batch=16,subdivisions=16, 每次计算的图片数目 = batch/subdivisions,在这里把结果合起来也就是一个batch更新模型一次。
如果batch设置过大,而你的电脑配置不够,就会报显存不够的错误
具体的含义可以查看YOLO网络中参数的解读:附以下解释
另外加一篇参考链接: https://zhuanlan.zhihu.com/p/352494414
[net] ★ [xxx]开始的行表示网络的一层,其后的内容为该层的参数配置,[net]为特殊的层,配置整个网络
# Testing ★ #号开头的行为注释行,在解析cfg的文件时会忽略该行
# batch=1
# subdivisions=1
# Training
batch=64 ★ 这儿batch与机器学习中的batch有少许差别,仅表示网络积累多少个样本后进行一次BP
subdivisions=16 ★ 这个参数表示将一个batch的图片分sub次完成网络的前向传播★★ 敲黑板:在Darknet中,batch和sub是结合使用的,例如这儿的batch=64,sub=16表示训练的过程中将一次性加载64张图片进内存,然后分16次完成前向传播,意思是每次4张,前向传播的循环过程中累加loss求平均,待64张图片都完成前向传播后,再一次性后传更新参数★★★ 调参经验:sub一般设置16,不能太大或太小,且为8的倍数,其实也没啥硬性规定,看着舒服就好batch的值可以根据显存占用情况动态调整,一次性加减sub大小即可,通常情况下batch越大越好,还需注意一点,在测试的时候batch和sub都设置为1,避免发生神秘错误!width=608 ★ 网络输入的宽width
height=608 ★ 网络输入的高height
channels=3 ★ 网络输入的通道数channels 3为RGB彩色图片,1为灰度图,4为RGBA图,A通道表示透明度★★★ width和height一定要为32的倍数,否则不能加载网络★ 提示:width也可以设置为不等于height,通常情况下,width和height的值越大,对于小目标的识别效果越好,但受到了显存的限制,读者可以自行尝试不同组合momentum=0.9 ★ 动量 DeepLearning1中最优化方法中的动量参数,这个值影响着梯度下降到最优值的速度
decay=0.0005 ★ 权重衰减正则项,防止过拟合,decay参数越大对过拟合的抑制能力越强angle=5 ★ 数据增强参数,通过旋转角度来生成更多训练样本,生成新图片的时候随机旋转-5~5度
saturation = 1.5 ★ 数据增强参数,通过调整饱和度来生成更多训练样本,饱和度变化范围1/1.5到1.5倍
exposure = 1.5 ★ 数据增强参数,通过调整曝光量来生成更多训练样本,曝光量变化范围1/1.5到1.5倍
hue=.1 ★ 数据增强参数,通过调整色调来生成更多训练样本,色调变化范围-0.1~0.1 learning_rate=0.001 ★ 学习率决定着权值更新的速度,设置得太大会使结果超过最优值,太小会使下降速度过慢。如果仅靠人为干预调整参数,需要不断修改学习率。刚开始训练时可以将学习率设置的高一点,而一定轮数之后,将其减小在训练过程中,一般根据训练轮数设置动态变化的学习率。刚开始训练时:学习率以 0.01 ~ 0.001 为宜。一定轮数过后:逐渐减缓。接近训练结束:学习速率的衰减应该在100倍以上。学习率的调整参考https://blog.csdn.net/qq_33485434/article/details/80452941★★★ 学习率调整一定不要太死,实际训练过程中根据loss的变化和其他指标动态调整,手动ctrl+c结束此次训练后,修改学习率,再加载刚才保存的模型继续训练即可完成手动调参,调整的依据是根据训练日志来,如果loss波动太大,说明学习率过大,适当减小,变为1/5,1/10均可,如果loss几乎不变,可能网络已经收敛或者陷入了局部极小,此时可以适当增大学习率,注意每次调整学习率后一定要训练久一点,充分观察,调参是个细活,慢慢琢磨★★ 一点小说明:实际学习率与GPU的个数有关,例如你的学习率设置为0.001,如果你有4块GPU,那真实学习率为0.001/4
burn_in=1000 ★ 在迭代次数小于burn_in时,其学习率的更新有一种方式,大于burn_in时,才采用policy的更新方式
max_batches = 500200 ★ 训练次数达到max_batches后停止学习,一次为跑完一个batchpolicy=steps ★ 学习率调整的策略:constant, steps, exp, poly, step, sig, RANDOM,constant等方式参考https://nanfei.ink/2018/01/23/YOLOv2%E8%B0%83%E5%8F%82%E6%80%BB%E7%BB%93/#more
steps=400000,450000
scales=.1,.1 ★ steps和scale是设置学习率的变化,比如迭代到400000次时,学习率衰减十倍,45000次迭代时,学习率又会在前一个学习率的基础上衰减十倍[convolutional] ★ 一层卷积层的配置说明
batch_normalize=1 ★ 是否进行BN处理,什么是BN此处不赘述,1为是,0为不是
filters=32 ★ 卷积核个数,也是输出通道数
size=3 ★ 卷积核尺寸
stride=1 ★ 卷积步长
pad=1 ★ 卷积时是否进行0 padding,padding的个数与卷积核尺寸有关,为size/2向下取整,如3/2=1# 如果pad为0,padding由 padding参数指定。如果pad为1,padding大小为size/2
activation=leaky ★ 网络层激活函数★★ 卷积核尺寸3*3配合padding且步长为1时,不改变feature map的大小# Downsample
[convolutional] ★ 下采样层的配置说明
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leaky ★★ 卷积核尺寸为3*3,配合padding且步长为2时,feature map变为原来的一半大小[shortcut] ★ shotcut层配置说明
from=-3 ★ 与前面的多少次进行融合,-3表示前面第三层
activation=linear ★ 层次激活函数包括,logistic, loggy, relu, elu, relie, plse, hardtan, lhtan, linear, ramp, leaky, tanh, stair............
[convolutional] ★ YOLO层前面一层卷积层配置说明
size=1
stride=1
pad=1
filters=255 ★ 每一个[region/yolo]层前的最后一个卷积层中的 filters=(classes+5)*anchors_num,其中5的意义是4个坐标加一个置信率,即论文中的tx,ty,tw,th,toanchors_num 是该层mask的一个值.如果没有mask则 anchors_num=numclasses为类别数,COCO为80,num表示YOLO中每个cell预测的框的个数,YOLOV3中为3★★★ 自己使用时,此处的值一定要根据自己的数据集进行更改,例如你识别80个类,则:filters=3*(80+5)=255,三个fileters都需要修改,切记
activation=linear[yolo] ★ YOLO层配置说明
mask = 0,1,2 ★ 使用anchor的索引,0,1,2表示使用下面定义的anchors中的前三个anchor
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 ★ 预测框的初始宽高,第一个是w,第二个是h,总数量是num*2,YOLOv2作者说anchors是使用K-MEANS获得,其实就是先统计出哪种大小的框比较多,可以增加收敛速度,如果不设置anchors,默认是0.5;
classes=80 ★ 类别数目
num=9 ★ 每个grid cell总共预测几个box,和anchors的数量一致。当想要使用更多anchors时需要调大num,且如果调大num后训练时Obj趋近0的话可以尝试调大object_scale
jitter=.3 ★ 数据增强手段,此处jitter为随机调整宽高比的范围,通过抖动增加噪声来抑制过拟合[?]利用数据抖动产生更多数据,YOLOv2中使用的是crop,filp,以及net层的angle,flip是随机的,jitter就是crop的参数,tiny-yolo-voc.cfg中jitter=.3,就是在0~0.3中进行crop
ignore_thresh = .7
truth_thresh = 1 ★ 参与计算的IOU阈值大小.当预测的检测框与ground true的IOU大于ignore_thresh的时候,参与loss的计算,否则,检测框的不参与损失计算。★ 理解:目的是控制参与loss计算的检测框的规模,当ignore_thresh过于大,接近于1的时候,那么参与检测框回归loss的个数就会比较少,同时也容易造成过拟合;而如果ignore_thresh设置的过于小,那么参与计算的会数量规模就会很大。同时也容易在进行检测框回归的时候造成欠拟合。★ 参数设置:一般选取0.5-0.7之间的一个值,之前的计算基础都是小尺度(13*13)用的是0.7,(26*26)用的是0.5。这次先将0.5更改为0.7。参考:https://www.e-learn.cn/content/qita/804953
random=1 ★ 为1打开随机多尺度训练,为0则关闭★★ 提示:当打开随机多尺度训练时,前面设置的网络输入尺寸width和height其实就不起作用了,width会在320到608之间随机取值,且width=height,每10轮随机改变一次,一般建议可以根据自己需要修改随机尺度训练的范围,这样可以增大batch,望读者自行尝试!
第二处
修改107行最后一个卷积层中filters,按照filter=5*(classes+5)来进行修改。如果类目为3,则为5*(3+5)=40。
[convolutional]
size=1
stride=1
pad=1
filters=40 //计算公式为:filter=3*(classes+5)
activation=linear
第三处
修改类别数,直接搜索关键词“classes”即可,全文就一个。
classes=3
修改好之后,可以开始进行训练:
这里应该是yolo3的代码
./darknet detector train cfg/voc.data cfg/yolo-voc.cfg darknet19_448.conv.23 >> log.txt
yolov4的代码
./darknet detector train cfg/voc.data cfg/yolo-voc.cfg yolov4.conv.137 >> log.txt
输入上边的指令就可以进行训练,在命令最后的命令>> log.txt是将输出的日志保存到log.txt文件内,这样便于后期训练结果的查看。
在训练过程中,与之前yolov3不同的是yolov4在训练过程中会弹出训练过程中的loss的实时图像,如下图所示,会动态的显示每一代的损失,当前代数和预计剩余时间。

- 系统默认会迭代45000次batch,如果需要修改训练次数,进入cfg/yolo_voc.cfg修改max_batches的值。
- 在训练的过程中,darknet会自动保存权重文件
在之前设置的voc.data中,我们设置了产生的权重文件的保存目录,训练过程中会以yolo_xxx_last.weights每隔100个iterations保存一次,新的会替代旧的。
而这个文件夹下,yolo-obj_xxxx.weights文件会每隔1000个iterations保存一次。特别注意这里的1000次保存一次的文件,在后面需要我们进行比较,具体到多少个1000次的时候的权重最为适合,然后选取此权重文件作为我们进行检测的权重文件
darknet总的训练步长可以在yolov4-obj.cfg或者yolo-voc.cfg文件中修改max_batches的大小(默认max_batches = 80000+)
补充:如果想要指定具体的gpu进行训练,可以使用-i来指定,比如我想使用索引为2的gpu进行训练,可以这样写:
./darknet detector train data/obj.data cfg/yolov4-obj.cfg yolov4.conv.137 -i 2 -map
参考链接:https://blog.csdn.net/qq_38316300/article/details/106771964
疑问:为什么avg loss在训练过程中忽上忽下的?
5 训练yolov4-tiny
(1) yolov4-tiny前29层的预训练权重:点击这里
(2) 基于yolov4-tiny-obj.cfg进行修改配置文件
(3) 执行下面的命令进行训练:
./darknet detector train data/obj.data cfg/yolov4-tiny-obj.cfg yolov4-tiny.conv.29
6 停止训练的时机
随着训练的进行,不可避免的会出现过拟合现象的发生,那我们什么时候应该停止训练呢?
通常来说每一类都要充分训练2000个iterator,而且不少于训练集中图片的数量,总共不应小于6000个iterations。但是为了获得一个更好的训练精度,你应该手动停止训练,停止的时机可以参考下面;
(1) 在训练的过程中,你会看到各种各样的指标,当0.xxxxxxx avg不再变化的时候,你就应该停止训练

9002:表示当前的iteration
0.600730:表示平均的损失函数(越小越好)
当你观察到平均损失函数(average loss)0.xxxxxxx avg不再变化的时候,你就应该停止训练。最终的平均损失函数在0.5(对于小的模型、简单的数据集)到3.0(对于较大的模型、复杂的数据集)之间。
或者当你在终端中加上 -map 参数的时候,你就会看到mAP指标,Last accuracy mAP@0.5 = 18.50%,这个指标比损失函数作为指标要合适的多,因此在训练的过程中mAP不断增加,你就应该继续进行训练。
(2) 一旦你停止了训练,你就应该在backup文件夹中选择最合适的权重。
举例来说,如果你在9000 iterations停止训练,但是最好的模型在7000, 8000, 9000之间,而且不确定会不会产生过拟合,因此你需要找到提前停止训练的点(Early Stopping Point)。
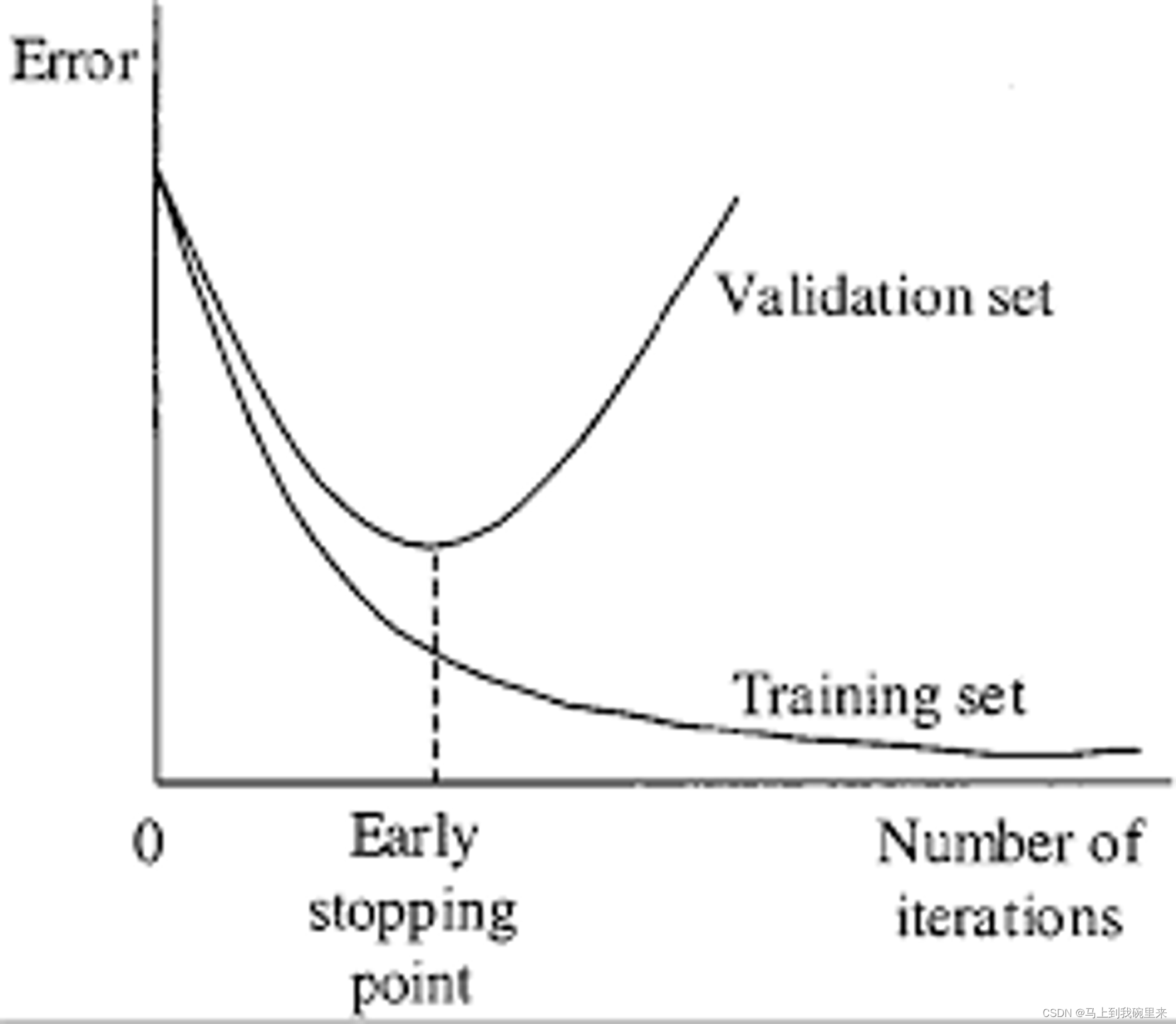
首先,准备验证集。你需要在 obj.data或者voc.data(具体看你自己设置数据集时用的那个文件)中将valid = data/test.txt 修改成 valid = data/valid.txt (valid.txt的格式和train.txt的合适一样),如果你没有验证集,你可以直接将train.txt的内容直接复制到valid.txt文件中。
其次,对候选的权重测试mAP。如果你是在9000 iterations停止训练的,你就需要对之前保存的权重进行测试。
# step1: 测试7000 iterations的mAP
./darknet detector map data/obj.data yolo-obj.cfg backup\yolo-obj_7000.weights# step2: 测试8000 iterations的mAP
./darknet detector map data/obj.data yolo-obj.cfg backup\yolo-obj_8000.weights# step3: 测试9000 iterations的mAP
./darknet detector map data/obj.data yolo-obj.cfg backup\yolo-obj_9000.weights
然后选择一个mAP最高的权重作为最优的训练权重。
(3) 当然,你也可以在训练的时候就显示mAP,然后根据训练过程图选择最合适的权重(上文使用的就是这样方式)
7 测试
最后用得到的权重文件进行测试
7.1 单张图像测试
./darknet detect cfg/yolo-voc.cfg backup/yolo-voc_final.weights data/dog.jpg
./darknet detect [训练cfg文件路径] [权重文件路径] [检测图片的路径]你训练用的哪个就是哪个自己训练出来的权重文件
按照上边的格式进行填写即可。
7.2 多张图像测试
./darknet detect cfg/yolov3.cfg yolov3.weights
7.3 检测视频
(1)只显示FPS,但是不显示图像:
注意要用自己设置过的data文件,cfg文件,以及自己产生的权重文件
./darknet detector demo data/obj.data cfg/yolov4-obj.cfg backup/yolov4-obj_9000.weights data/demo3.mp4 -dont_show -ext_output
(2)显示FPS也显示图像,并且保存检测视频结果:
./darknet detector demo data/obj.data cfg/yolov4-obj.cfg backup/yolov4-obj_9000.weights data/demo3.mp4 -ext_output -out_filename res.mp4
7.4 网络摄像头或视频文件测试
加一个参数demo
1、网络摄像头实时检测
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
2、视频文件实时检测
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights <video file>