这里写目录标题
- 质数(素数)
- 定义
- 判断是否为质数
- 暴力写法,试除法
- 基本思想
- 具体写法
- 优化
- 基本思想(时间复杂度根号n)
- 具体写法
- 分解质因数
- 分析题意
- 暴力写法
- 基本思想
- 具体代码
- 优化
- 基本思想(时间复杂度小于等于根号n)
- 具体代码
- 筛质数(区别于判断质数,这个是筛选出来并保存,质数的数目较多)
- 基本思想
- 具体代码
- 优化(埃氏算法)
- 基本思想(时间复杂度约为n)
- 具体代码
- 优化2(线性筛法)
- 基本思想
- 具体代码
- 约数
- 求一个数的所有约数
- 试除法
- 约数个数
- 基本思想
- 具体题目+代码
- 题目以及分析
- 代码
- 约数之和
- 基本思想
- 具体代码
- 求最大公约数
- 基本思想(欧几里得算法)
- 具体代码
- 欧拉函数
- 公式法求欧拉函数
- 定义
- 基本思想
- 例题+代码
- 筛法求欧拉函数
- 基本思想
- 例题+代码
- 欧拉定理
- 快速幂
- 求a的k次方modp
- 基本思想
- 例题+代码
- 快速幂求逆元
- 例题+代码
- 基本思想
- 关于逆元
- 具体代码
- 扩展欧几里得算法
- 使用扩展欧几里得算法求裴蜀定理中的系数x,y
- 裴蜀定理
- 例题+代码
- 使用扩展欧几里得算法求线性同余方程
- 线性同余方程
- 代码基本思想
- 代码
质数(素数)
定义

判断是否为质数
暴力写法,试除法
基本思想
从定义出发,判断是否为质数
1、小于2的数,统一返回false
2、遍历 i 从2到小于n(即除去1和n)
判断是否有n % i == 0 的,表示这中间有i可以整除,如果有,返回false
最后返回true
具体写法
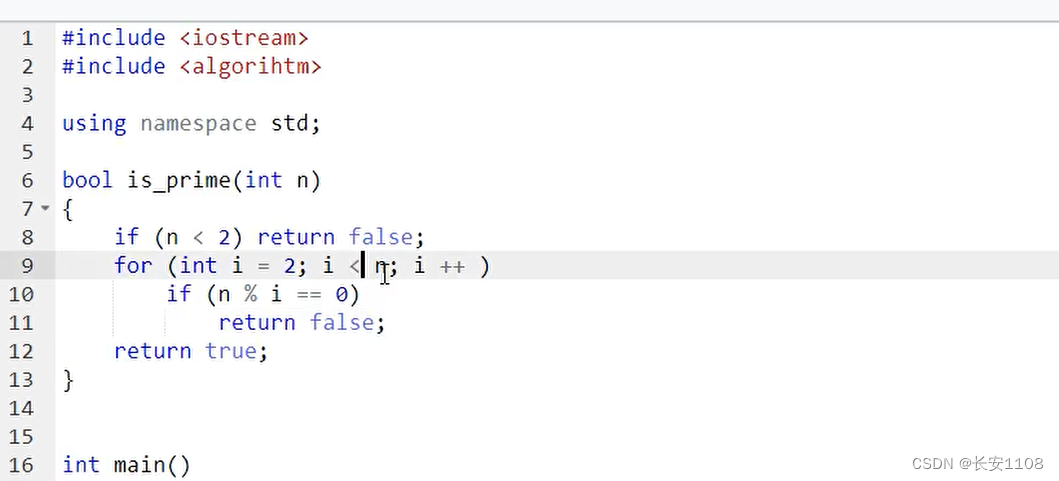
优化
基本思想(时间复杂度根号n)
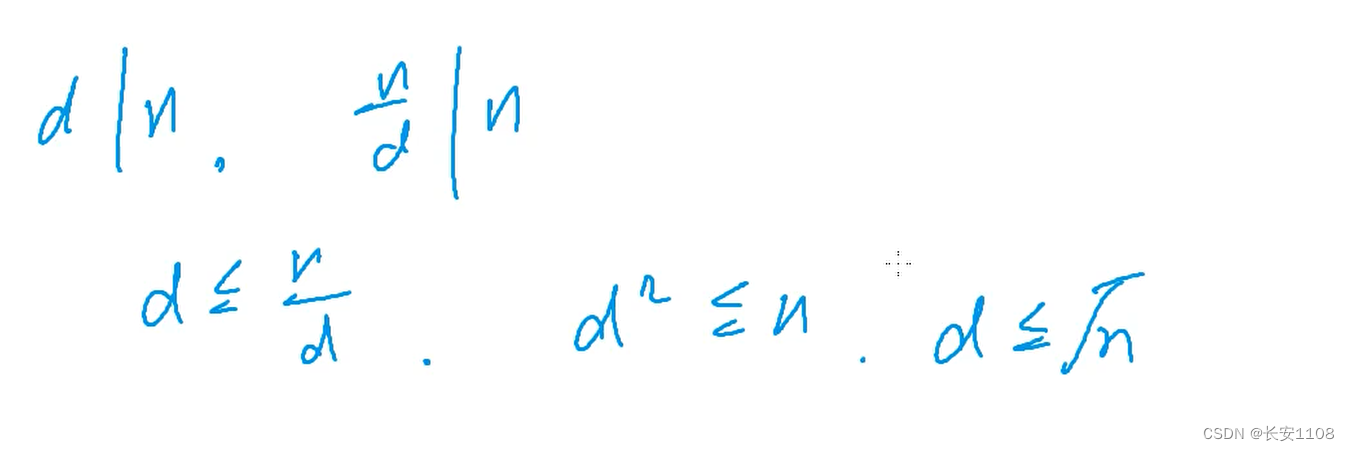
利用质数的性质,当d能被n整除时,n/d 也能被n整除,
所以,只需要判断从2到根号n有无能让d整除的数即可
具体写法
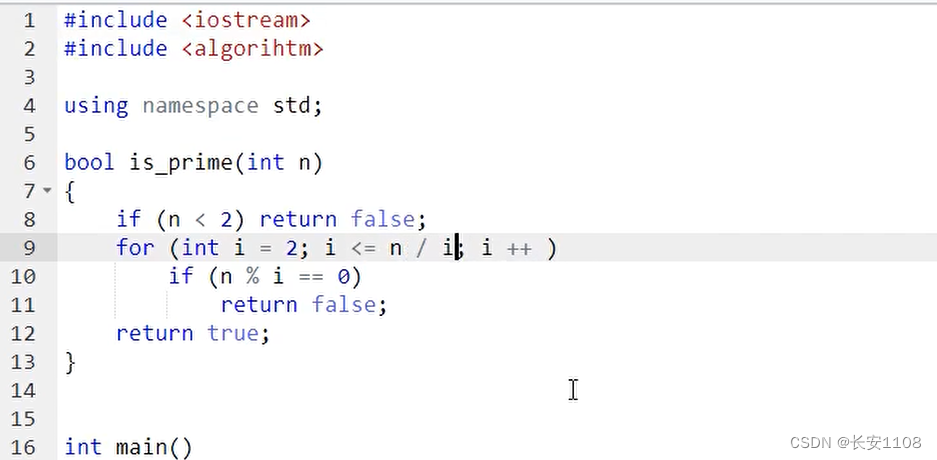
这里的 i 就是上面的d,循环 i 判断是否有数能让n整除,也就是上面的判断d是否能让n整除
分解质因数
分析题意

质因子分解,就是输出几组质数并输出他们对应的数量,他们乘积等于输入的数
暴力写法
基本思想
直接循环所有从2到等于n的数,如果能找到一个被n整除的 i ,那么 i 一定是一个质数,这里与上面判断质数的代码要区分开,
上面写到:
for循环里,if(n % i == 0) return false
因为上面是判断n是否为质数,跟 i 没有关系
而本题的重点不在n,而是他的因子 i,所以这里当可以整除时, i 一定是一个质数,这句话就不会与上面矛盾了
具体代码

纠正:int x 改为 int n
循环i从2到小于等于n,其中如果找到了一个i能被n整除,那么这个i一定是质数,他就是我们要找的质因子之一(具体原因见上方“基本思想”),之后循环计算 i 的次数即可
循环计算质数次数时:
首先定义一个计数器s=0;
之后,while循环,条件是n 还可以整除 i
条件成立,就更新n 为 n/i,(因为题设是多个质因子的乘积,所以要进行下一步判断的话,要先将已经判断出来的 i 除去)
之后计数器++
输出质子以及出现的次数
优化
基本思想(时间复杂度小于等于根号n)

利用性质:n中最多只包含一个大于根号n的质因子
证明:如果有两个大于跟好n的质因子,那么这两个相乘,一定大于n,不成立,所以该性质成立,我们可以利用这个性质进行优化
具体代码

将for循环的 i ,从2开始循环到 小于等于n/i
然后,其他的不变,在for循环结束之后,如果n>1(因为n在上面的过程中,不断的被除开,不断的变小,被除开的原因见上面“未优化时具体代码的解释”),那么这个n就是那个大于根号n的质因子,他的个数永远为1,因为只存在一个大于根号n的质因子
tip:puts(“”);可以输出一行回车
同时puts(“字符串”);可以输出字符串
筛质数(区别于判断质数,这个是筛选出来并保存,质数的数目较多)
基本思想
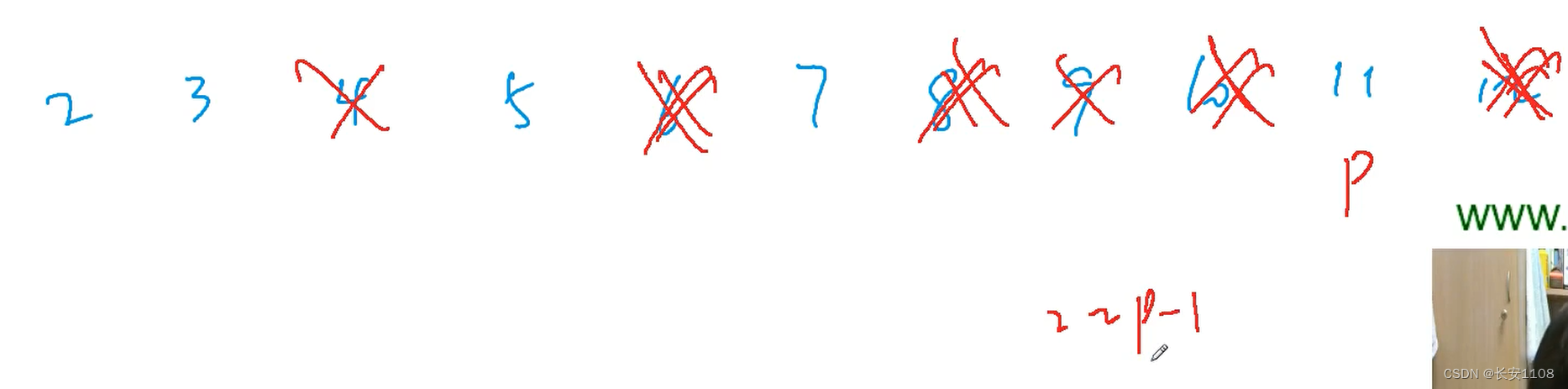
从2开始,删除后面2的倍数、删除3的倍数、4、5…
最后留下的都是质数,
因为假设p被留下了,那么就是前面2到p-1都没能把p删掉,也就是前面的倍数都没有p,所以p也就没有除去1和本身以外的因子,所以p一定是质数
具体代码
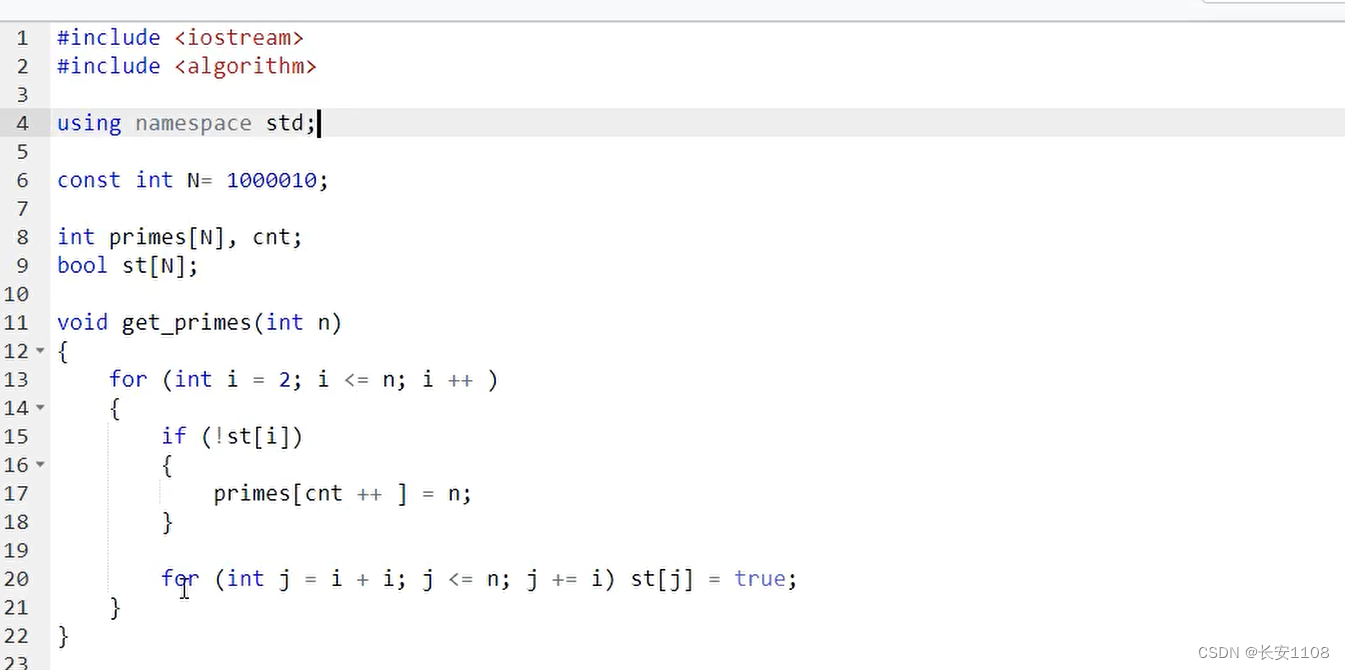
纠正:17行 primes【】= i
prime数组用来存放质数
cnt用来移动prime数组里的坐标,同时也在计数
st数组用来记录某个数是否被删掉了
首先从2到小于等于n遍历 i
之后 直接判断是否st[i]为假,如果是,那么放入prime数组中,并且cnt++
if之后,使用for循环对倍数进行删除:
初始化 j 为 i+i ; j <=n ; j += i
st[j]=true
初始化为 i 的2倍,之后递增条件是在 j 的基础上依次加 i,这样就可以找到 i 的所有倍数
优化(埃氏算法)
基本思想(时间复杂度约为n)
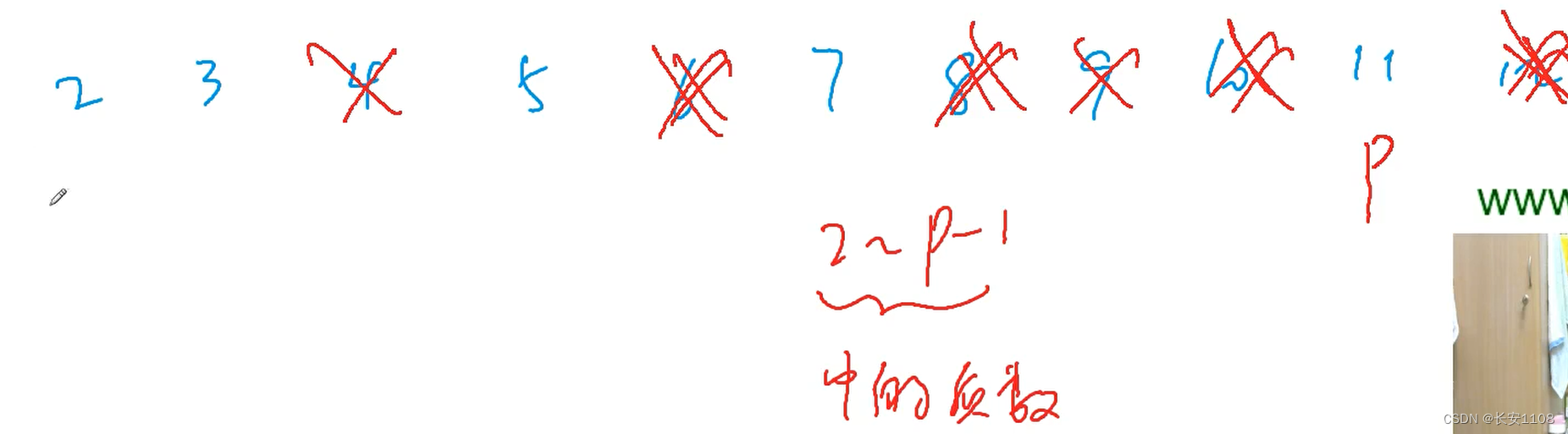
我们的目的是删掉合数,
任何一个合数都会被筛掉,因为质数的倍数包括所有的合数,任何一个合数都有一个质因子
所以我们只需要删除出来前面质数的倍数即可
具体代码

纠正:17行 primes【】= i
将for循环放入if里面即可
优化2(线性筛法)
基本思想

埃氏筛法:
我们的目的是删掉合数,
任何一个合数都会被筛掉,因为质数的倍数包括所有的合数,任何一个合数都有一个质因子
所以我们只需要删除出来前面质数的倍数即可
线性筛法的思路仍然是删掉质数的倍数 , 但是这种算法是根据每个最小质因子的倍数去筛,效率更高
具体代码
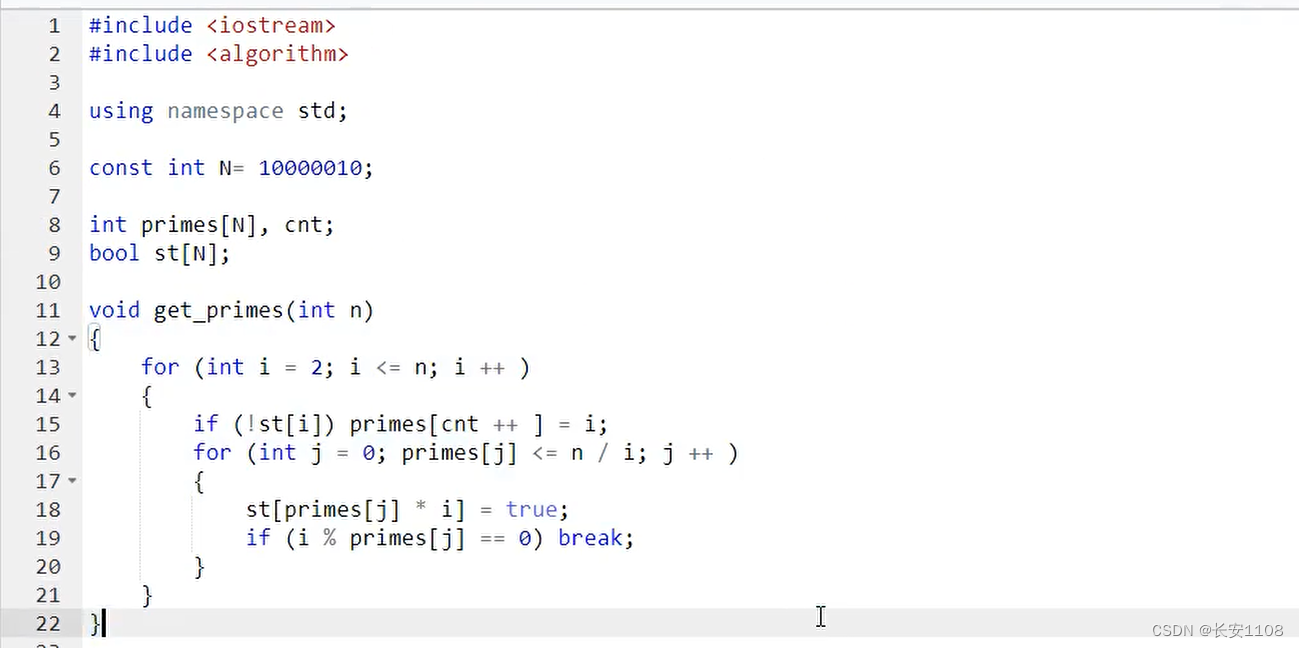
仍然是for循环 i 从2到小于等于 n
之后if不变
改变一下第二个for循环 :
j初始化为0 ;之后primes[j]<= n/i ;j++
然后标记st[primes[ j ] * i ]=true; (删除每个最小质因子的倍数)
之后加一个if (i % primes[ j ] == 0) break; (这一步可以保证primes[ j ]是 i 的最小质因子)
注意点:关于筛质数的三个算法中,只有该算法的第二个for循环不同于其他两个,前两个的第二个for循环都一样,只是位置不同,要特别注意
约数
求一个数的所有约数
试除法
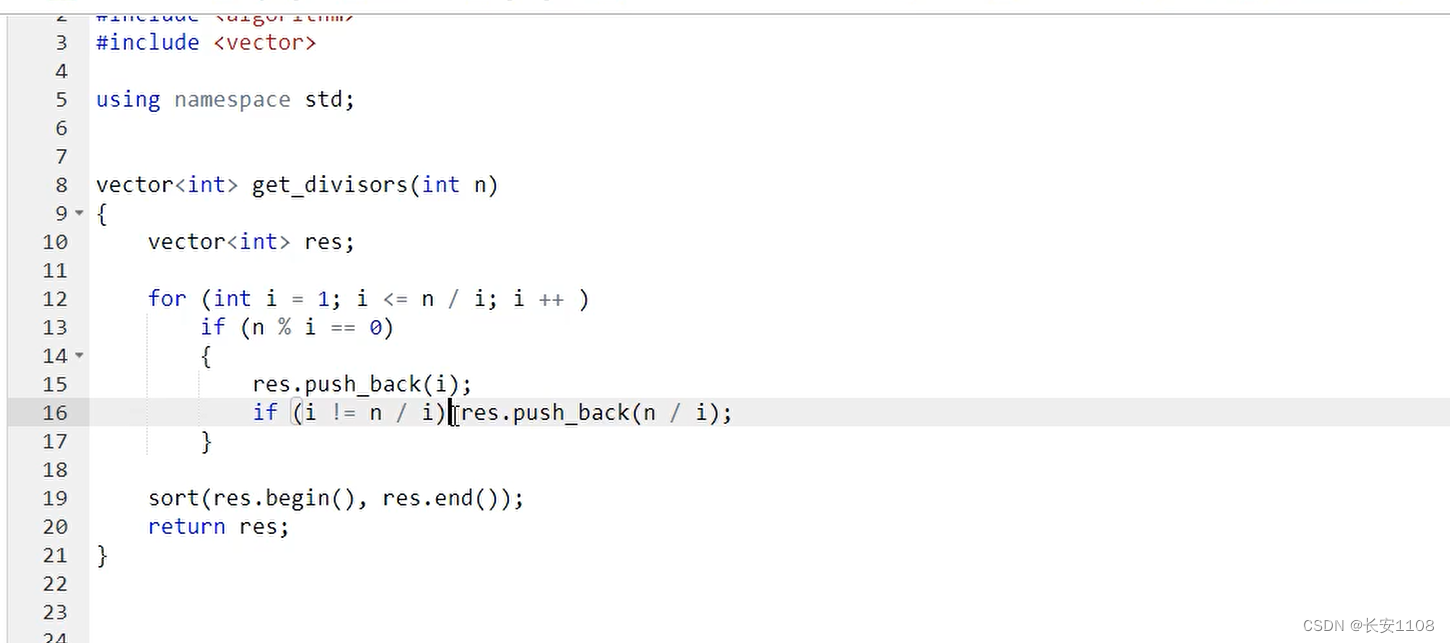
注意返回值是一个vector容器
首先是for循环从1到小于等于n
if i能被n整除
那么这个i就是一个约数,加入到容器中
另外这里需要一个特判:如果 i != n / i ,就把n / i 加到容器中,(因为约数不同于质数,约数是成对出现的,当我们找到一个 i 之后,可以顺势将其成对的另一个也加入到容器,前提是 i != n / i ,保证是两个成对的约数不相同时才加进去)
约数个数
基本思想
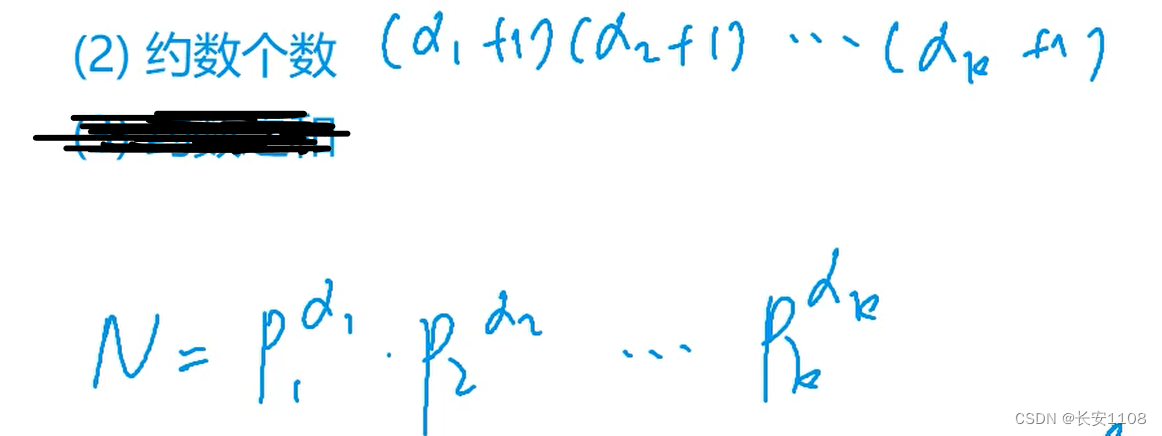
对于一个数N,可以写成多项的多次相乘的形式,这样的话,约数个数就是各个指数各自加一之后相乘的结果
原因:因为约数也就是N的因子,当N写成上图这种形式的时候,随便去掉一个p的一个次幂,相当于提出来了一个p的一次,而剩下的部分,还是N的因子,也还是N的约数,而a1次方的话,有0到a1一共(a1+1)种提法,所以所有的提法排列组合的个数,就是约数的个数
具体题目+代码
题目以及分析
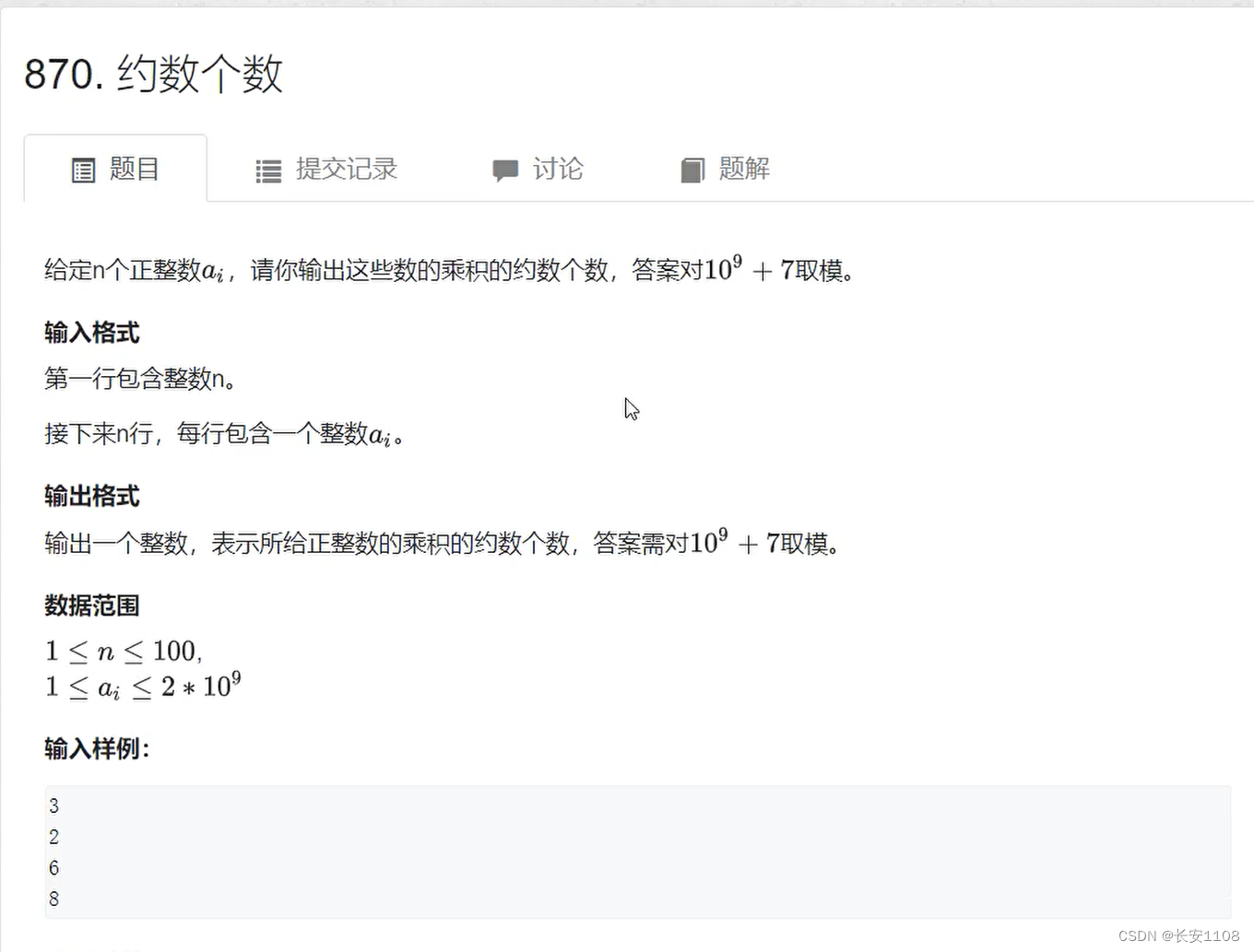
该题是一个n个整数乘积的原始数,所以,我们在求这个数的约数个数时,要先将乘积得到的结构进行分解,分解成指数相乘形式,具体我们可以先对每一个数进行分解,每个数分解出来指数形式之后,存入一个map里,这样依次进行下去,就可以得到一个个的底数和次幂组合,拿到这些组合,就可以计算约数个数或者约数之和
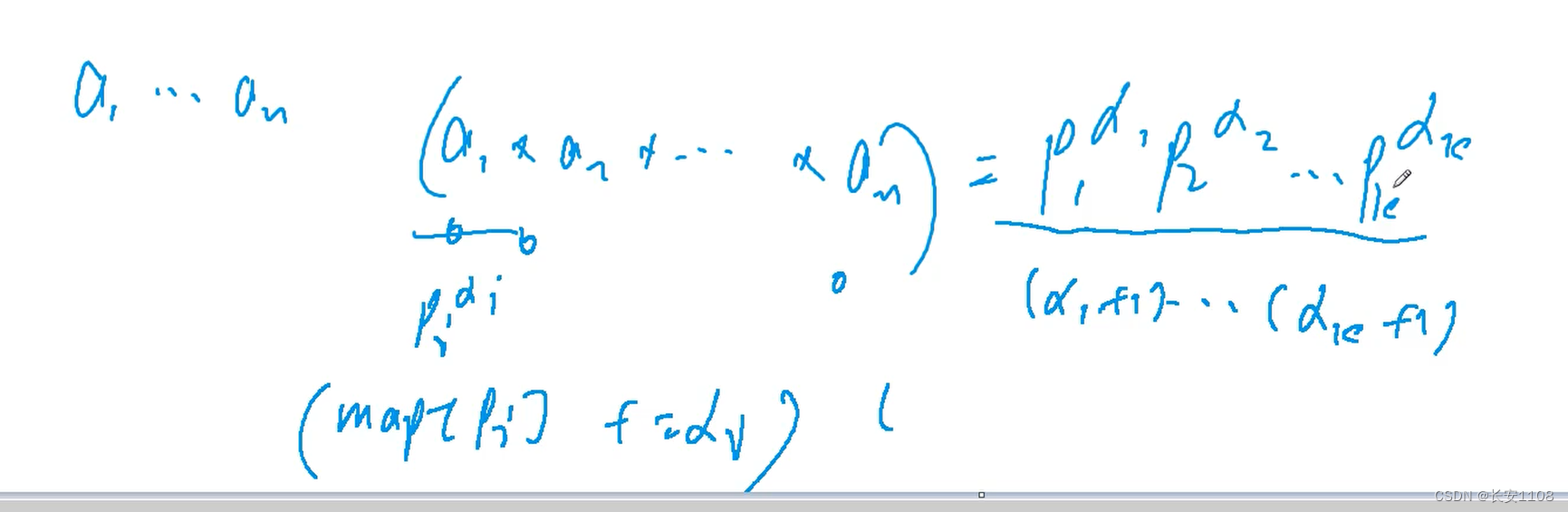
代码
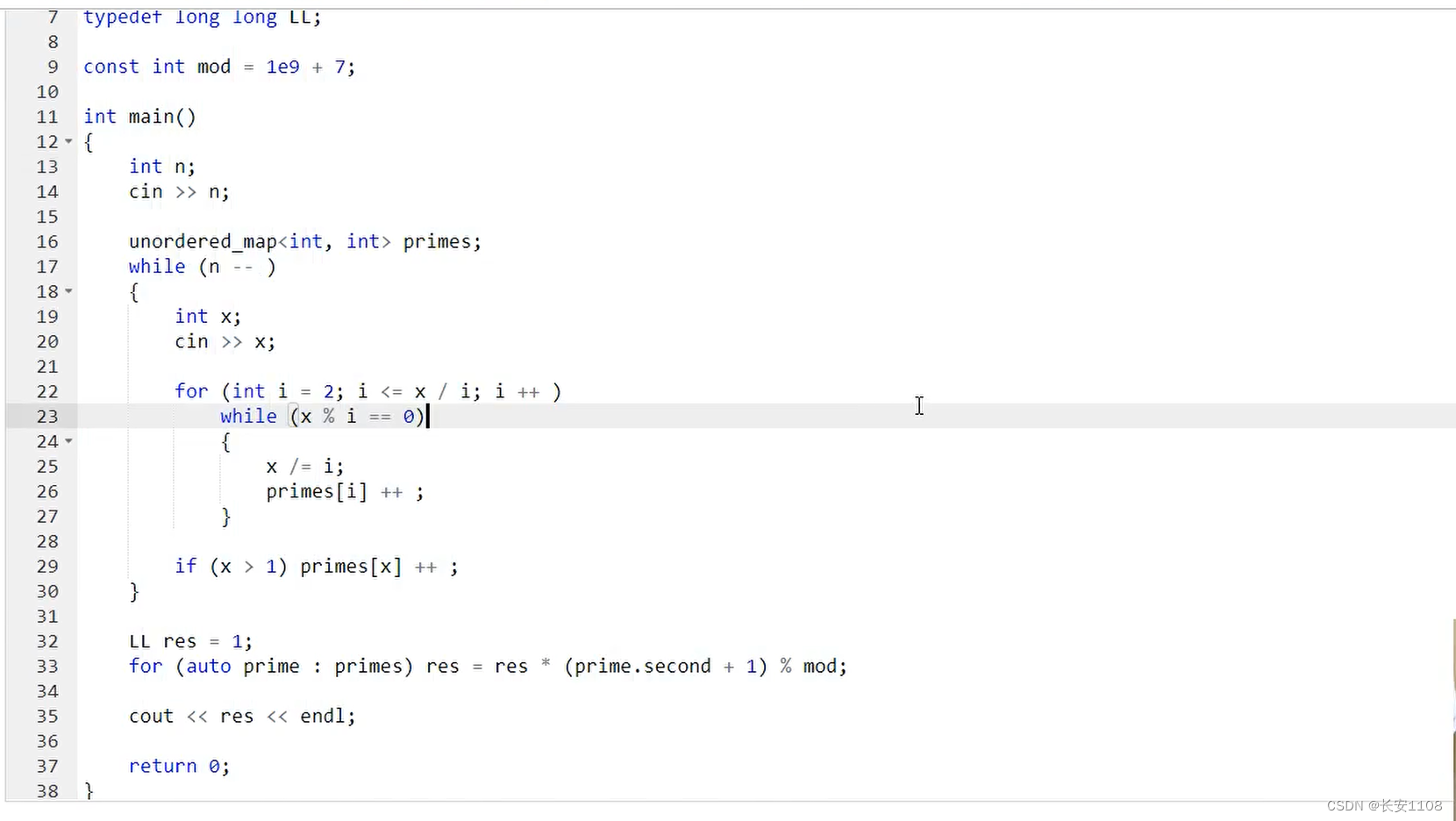
首先,操作的目标放在每一个输入进来的数,依次对其进行分解,分解的方式采用质因子分解:(实际上与上面的质因子分解如出一辙):
对于n个循环,每输入一个x,
我们对其进行一个for循环,i 从2到 小于等于 x / i
for循环里while循环,如果有x % i ==0
更新x(去除掉 i 部分)
同时primes[ i ] ++,i 的map值就是以 i 为底的组合中的次幂部分
for循环之后,就是对那个大于根号x的质子的特判,将其加入到primes的map中
之后就是根据题设套不同的公式,这里是求约数的个数,带入约数的个数公式即可,如上图
tips:

typedef long long LL;
数据范围巨大的数会用到LL
10的9次方+7,表示为: 1e9+7
约数之和
基本思想
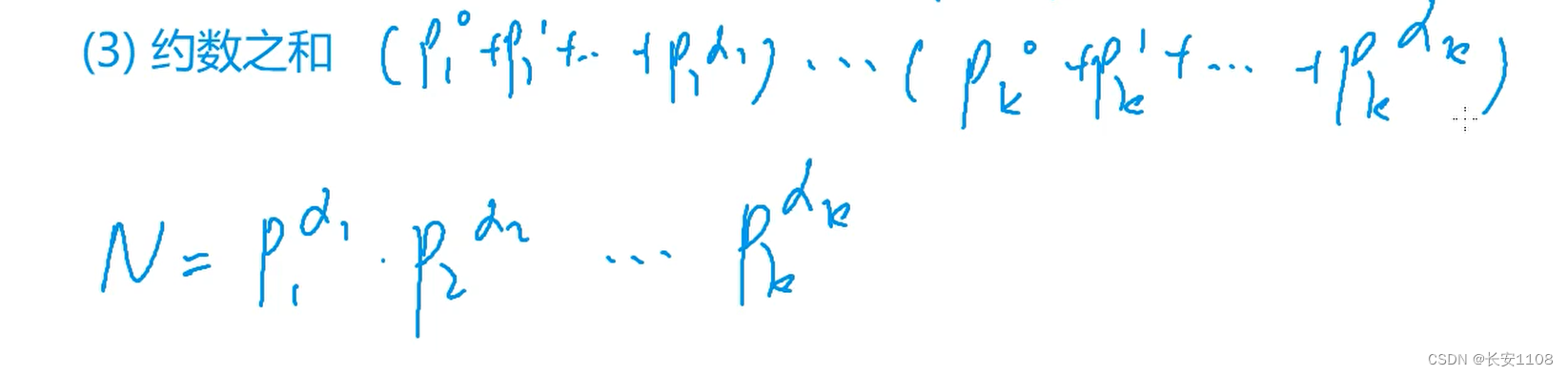
具体代码
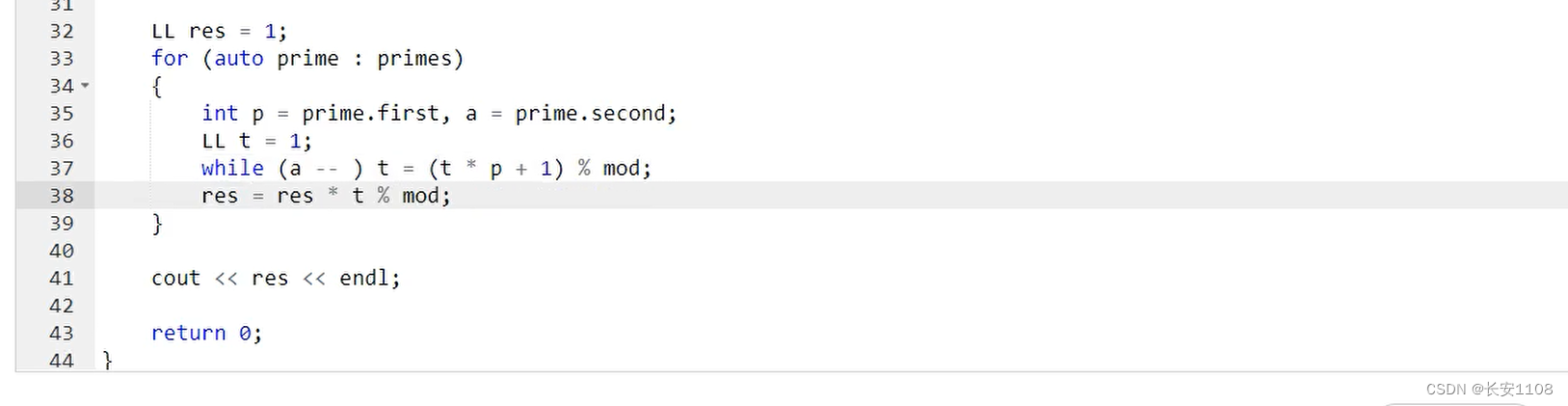
核心代码与上面的一样,不同的是公式的计算
for循环里面使用迭代器
对于每一个prime,先取出来first 以及 second
然后计算出他的p的0+p的1+p的2+p的3+…:
while(a–)t = (t * p +1),这样的话就可以得到p的0+p的1+p的2+p的3+…,上图取mod,是为了在这里取一次,可以节省效率
之后将while得到的t,乘入res,并取模,即可
具体while中的公式效果见下图:

求最大公约数
基本思想(欧几里得算法)

重要的是上图第二行被框住的部分
a 和 b 的最大公约数,可以转化为求b 和 a mod b 的最大公约数
具体代码
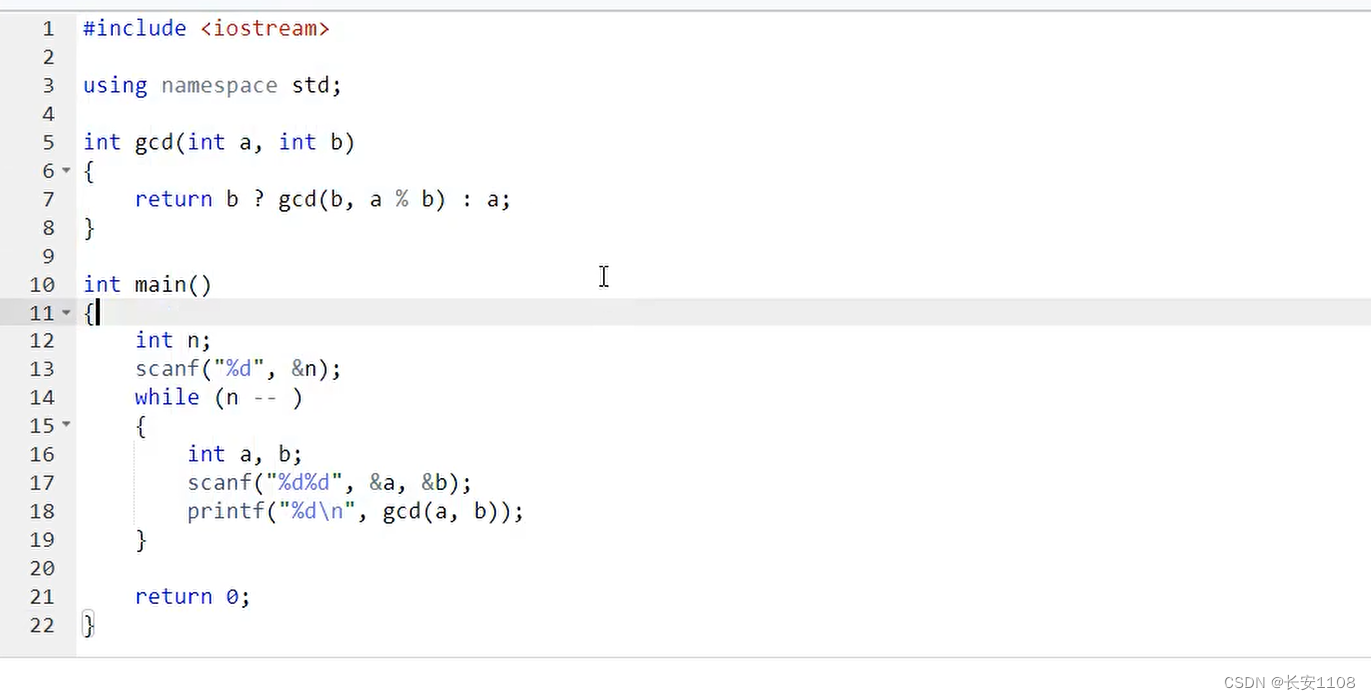
一行的模版
直接返回 b ?gcd(b, a % b ) : a
当b不为0时,返回gcd(b , a % b),递归下去
当b等于0,返回a即可
欧拉函数
公式法求欧拉函数
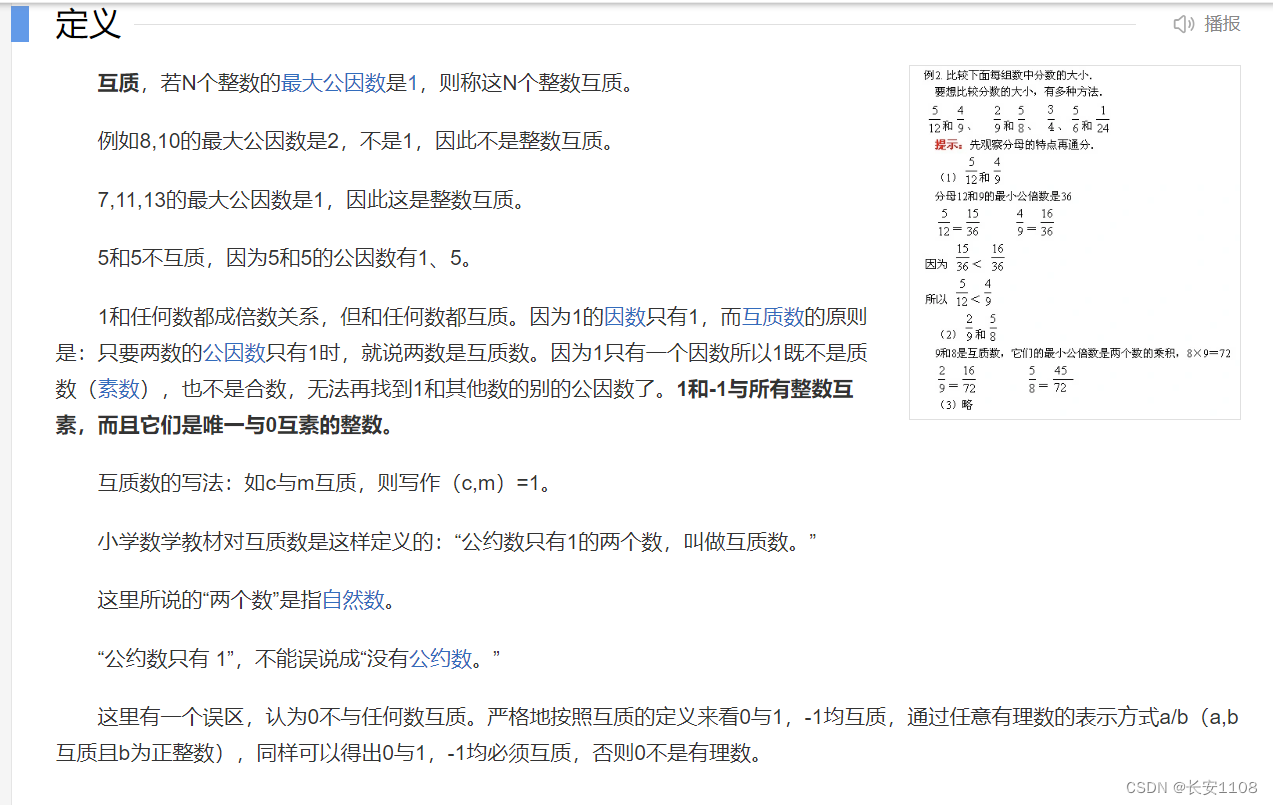
定义

1~n中与n互质的数的个数,就是欧拉函数
关于互质:
基本思想
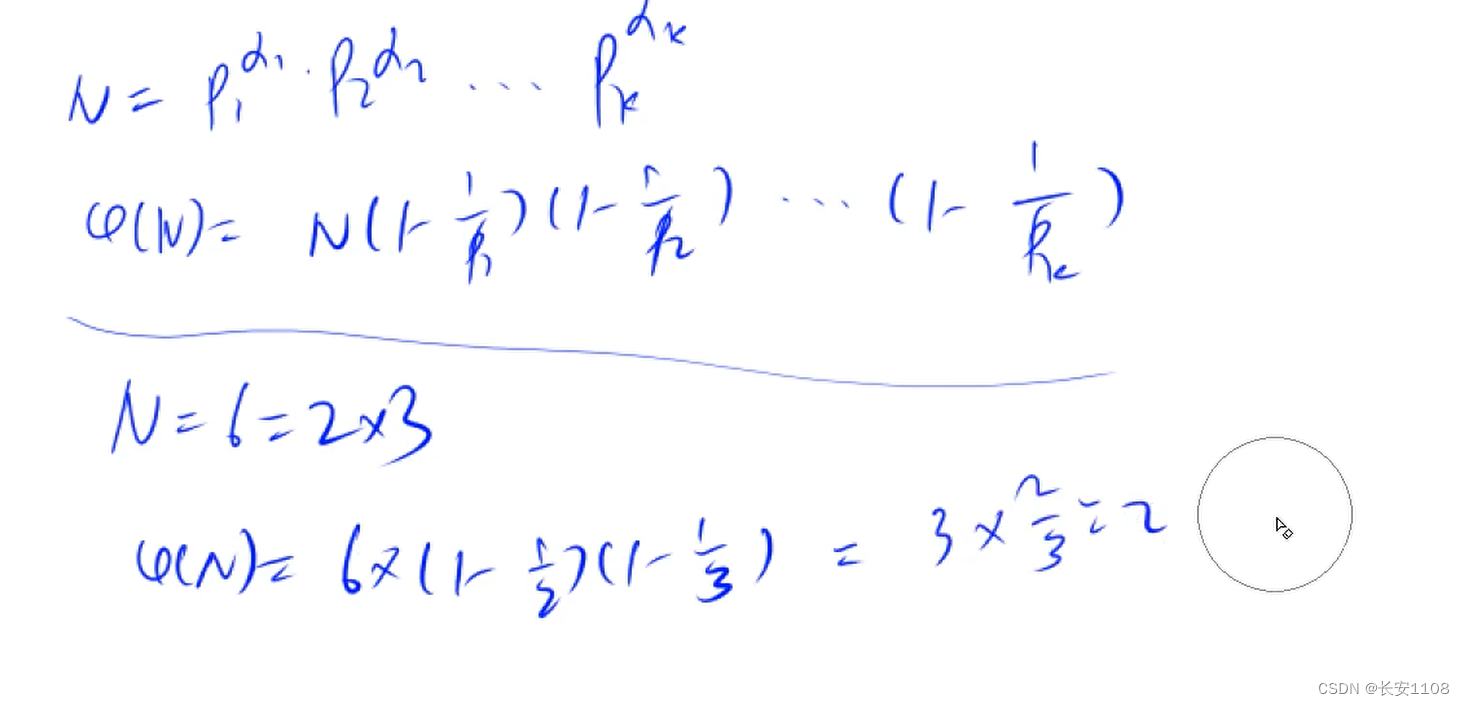
求f(N)时,1、对N质因数分解
2、套入公式
对于公式的证明,见数论知识(2)视频
时间复杂度:根号N
(如果求n个数的欧拉函数,那么最终的时间复杂度就是n乘根号N)
例题+代码
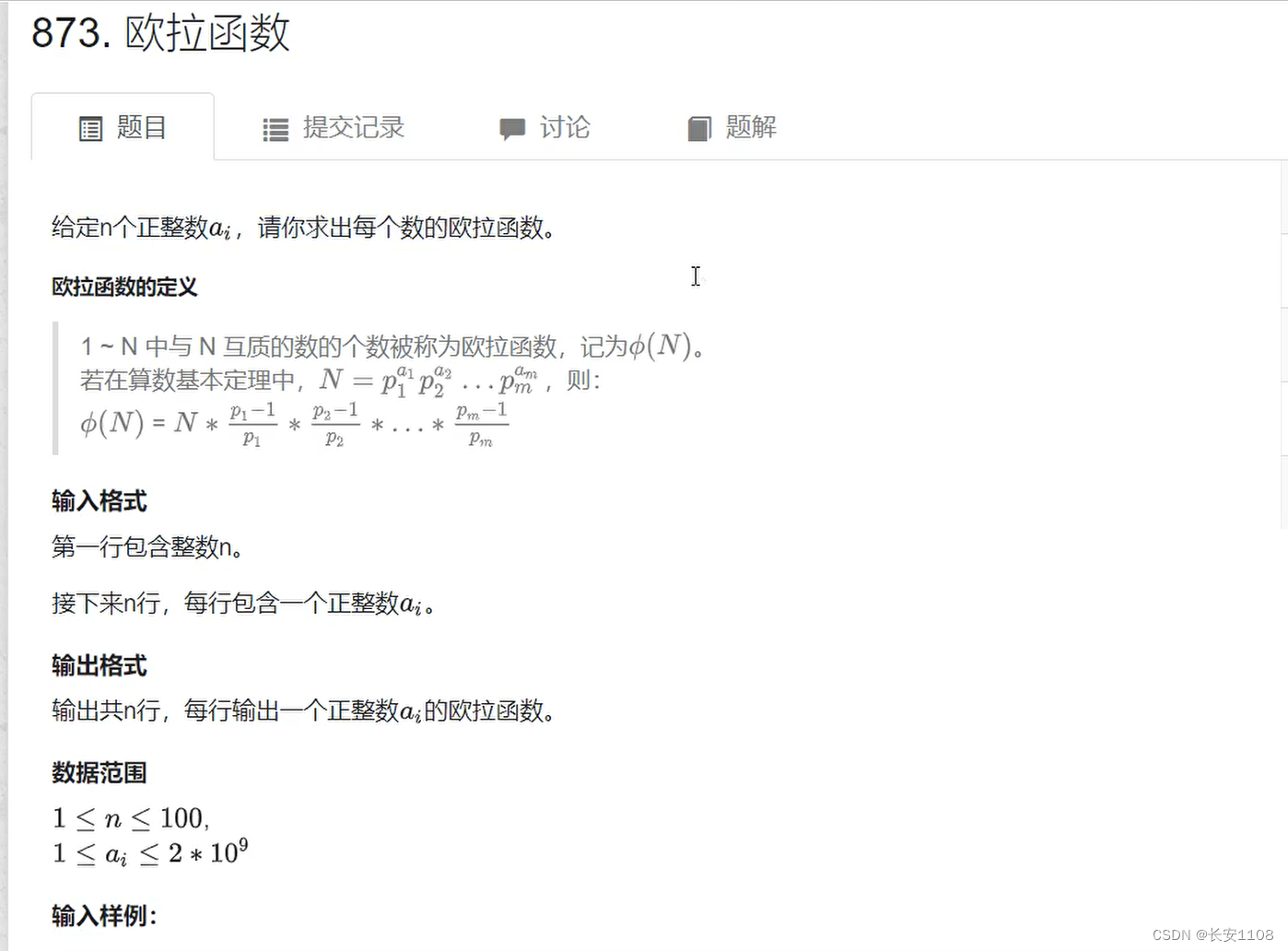
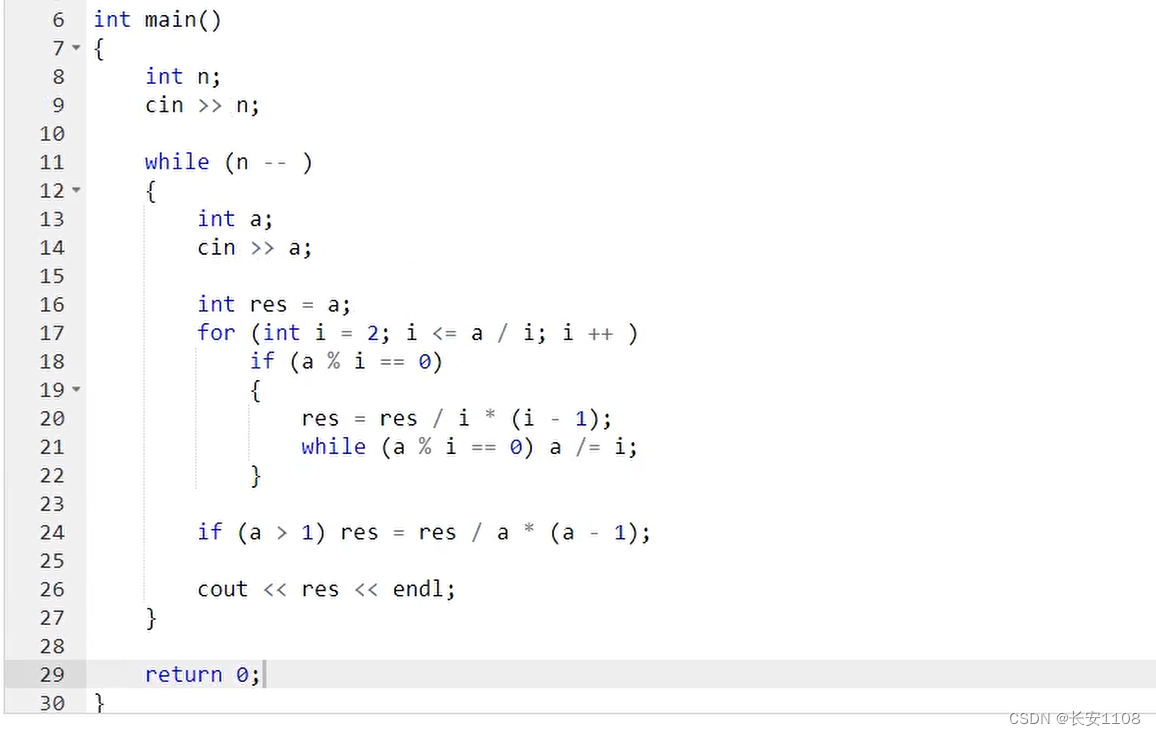
主要就是先:质因子分解
之后套用欧拉函数的公式即可
补充:其中在while进行质因子操作之前的对于res的计算:
按照公式应该是:res = res * (1-1/ i )
经过化简才成为上图的样子
筛法求欧拉函数
基本思想
借鉴“线性筛质数”的代码,在线性筛法的基础上进行改造
适用场景:

如果题目分别求1~N每个数的欧拉函数,那么时间复杂度就会变成N倍的根号N,当我们使用筛法求欧拉函数的方法的时候,就可以把时间复杂度优化成O(N)
例题+代码
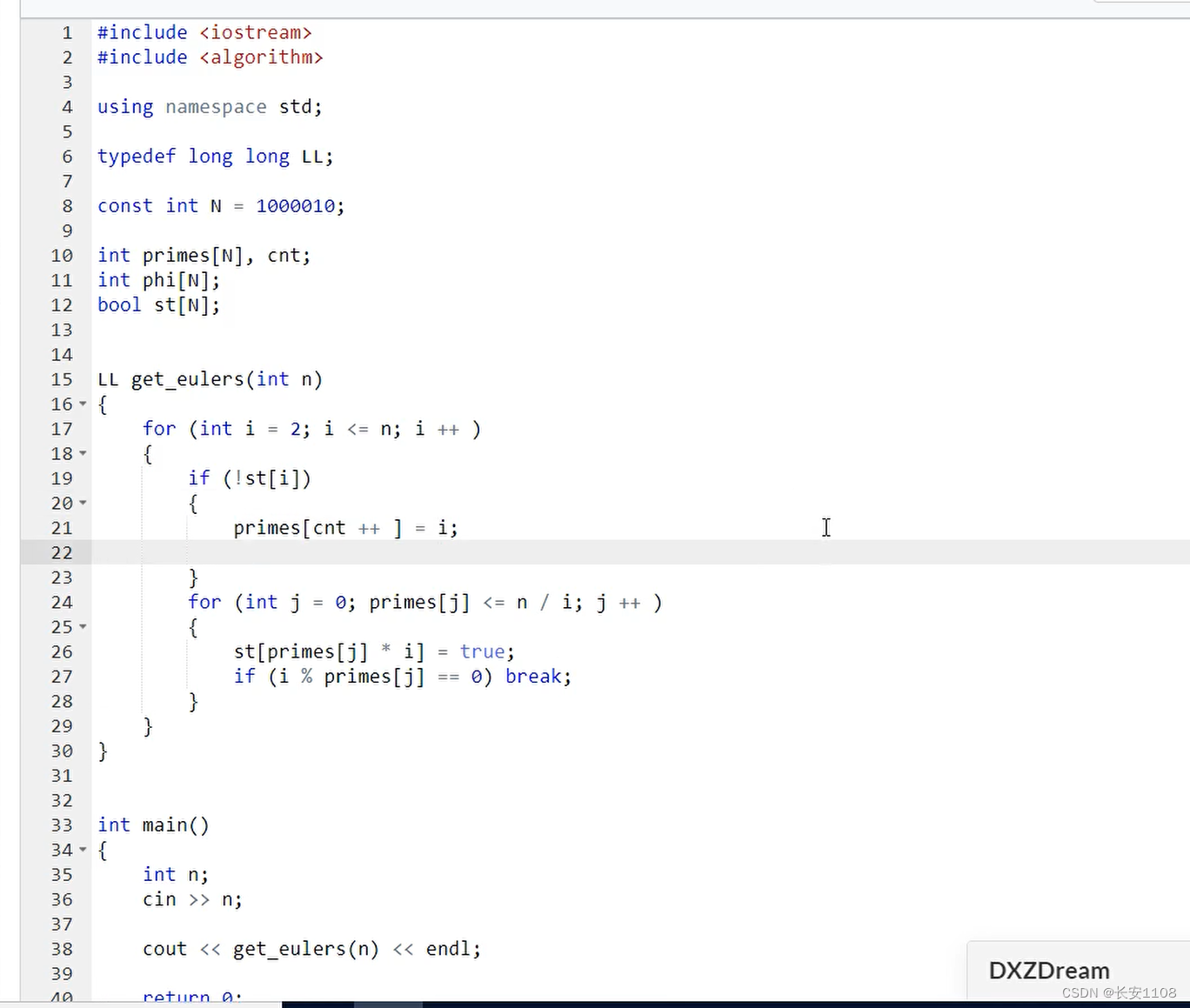
上图是单纯的一个线性筛质数法的代码,接下来,在这个的基础上进行添加代码,
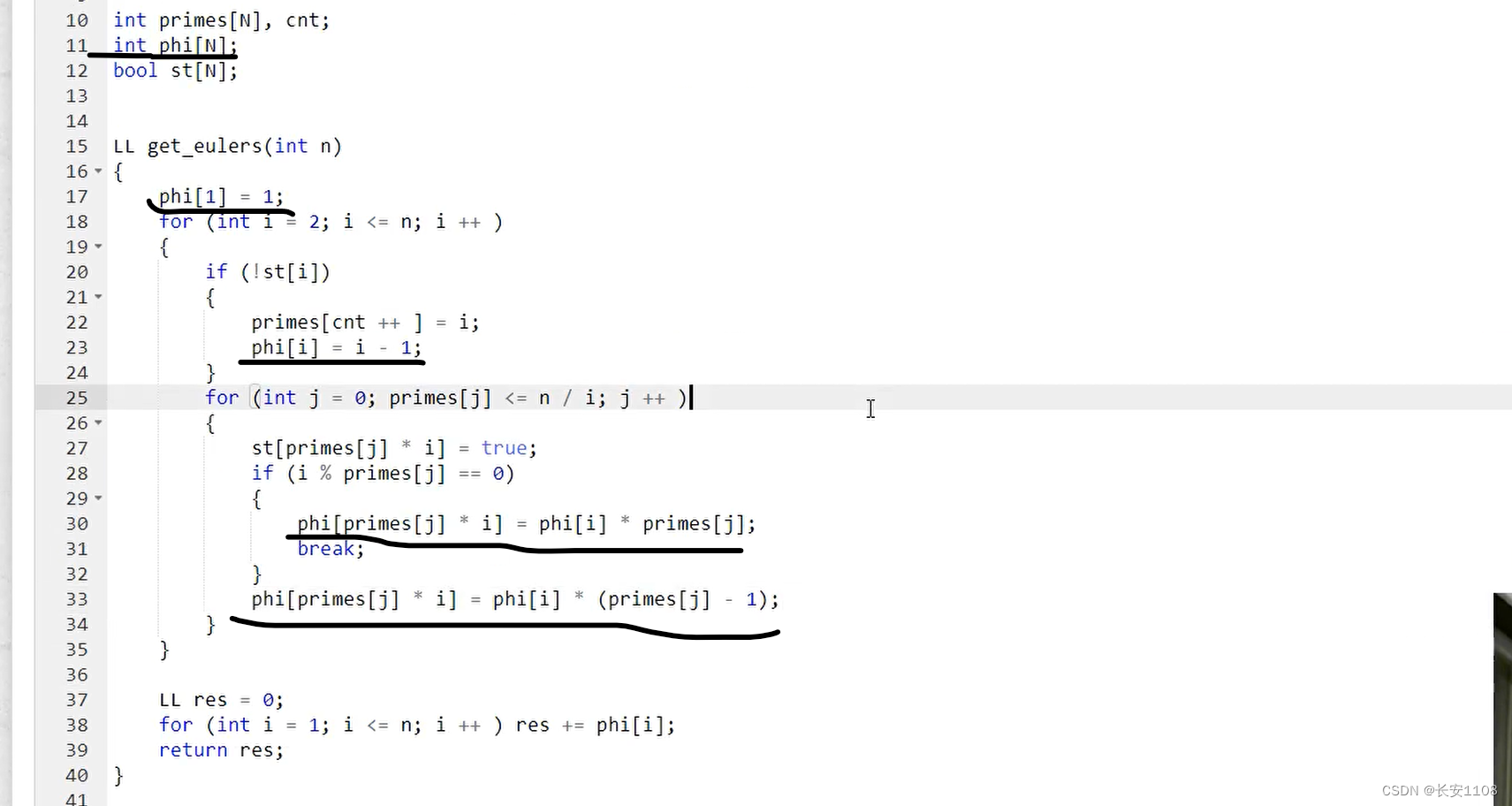
首先,要加一个数组用来存放每个数的欧拉函数(即1~某个数中与该数互质的个数)
之后增加的第一行,phi[1]=1;(数学规定,1的互质数只有一个)
之后是增加的第二行,phi[i]=i-1;(如果 i 是质数,那么1~i 中与 i 互质的数有i-1个,除了 i 本身,其他都与 i 互质)
之后是增加的第三行, 当i % primes[ j ]时 ,phi[ primes[j] i ] = phi[ i ] 星 primes[ j ];(具体解释见下图)
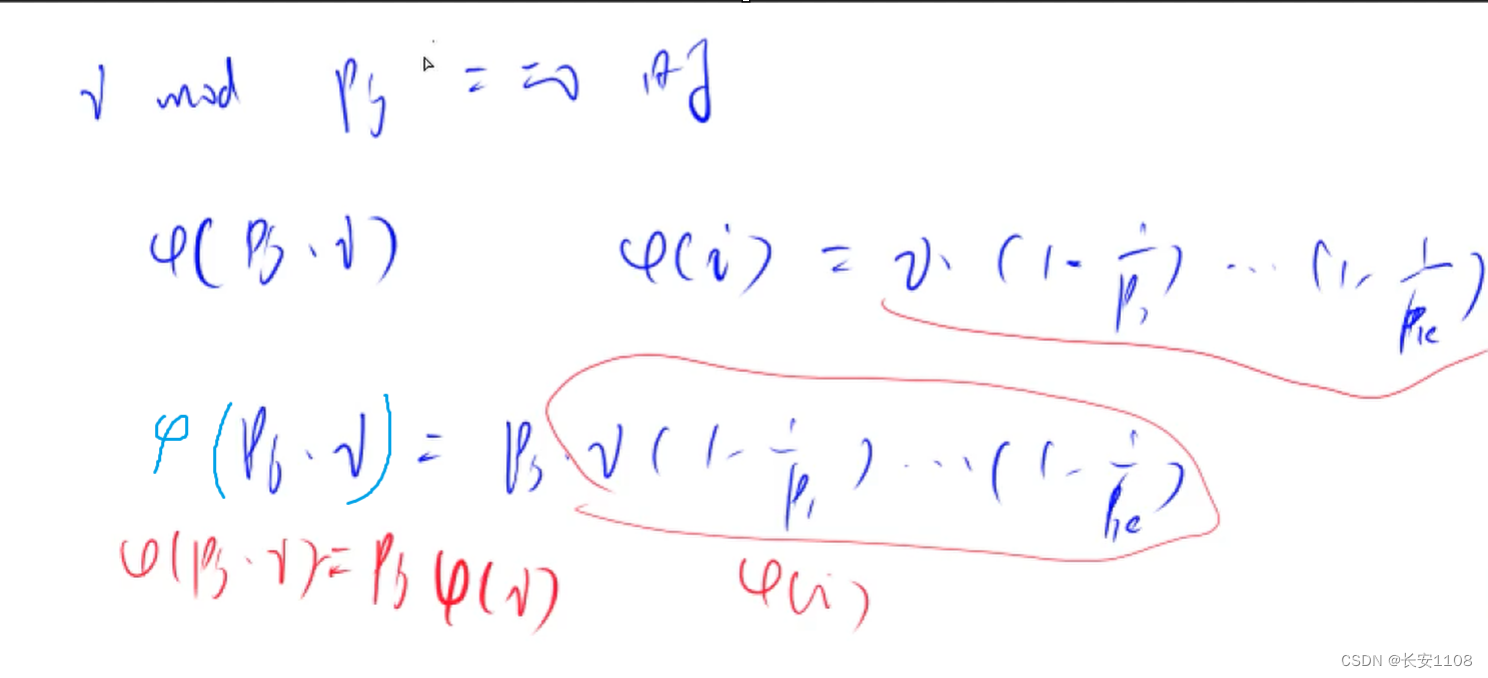
当i % primes[ j ]时,根据欧拉函数的公式,primes[j](之后简称pj),pji的欧拉函数比 i 自己的欧拉函数要多出一个pj
因为欧拉函数的公式是与质因子以及括号里的自变量有关,由于i % primes[ j ],所以pj是 i 的一个质因子,所以,pji的质因子底数与 i 的质因子底数一模一样,只不过pji的质因子中pj的指数多一,但是欧拉函数并不考虑指数,所以二者质因子部分并无差异,只是在括号里的自变量不同,从而推出来上面的式子

当 i % primes[ j ] 不等于0时,这时借鉴上面的分析,pj*i的欧拉函数比 i的欧拉函数多了一个pj以及(1-1/pj),化简可得,上图红色公式,所以有了增加的第四行代码
欧拉定理
如下公式即是欧拉定理

推论:
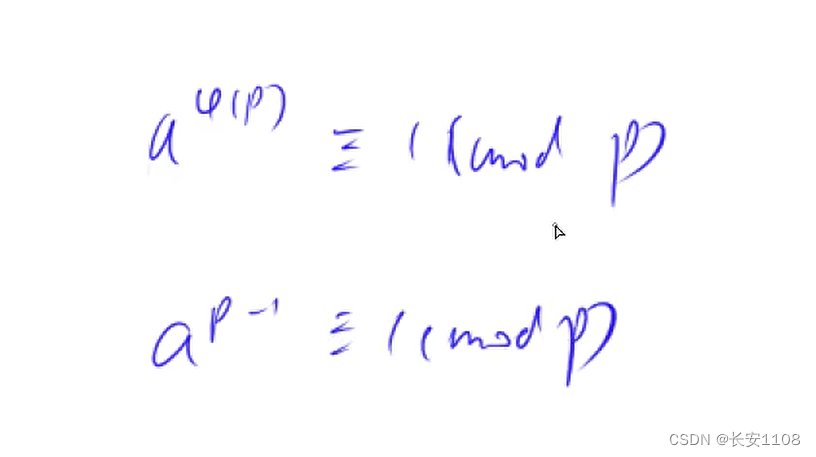
当p为质数的时候,会有这样的推论,因为p如果是质数,有p的欧拉函数是p-1
快速幂
求a的k次方modp
基本思想
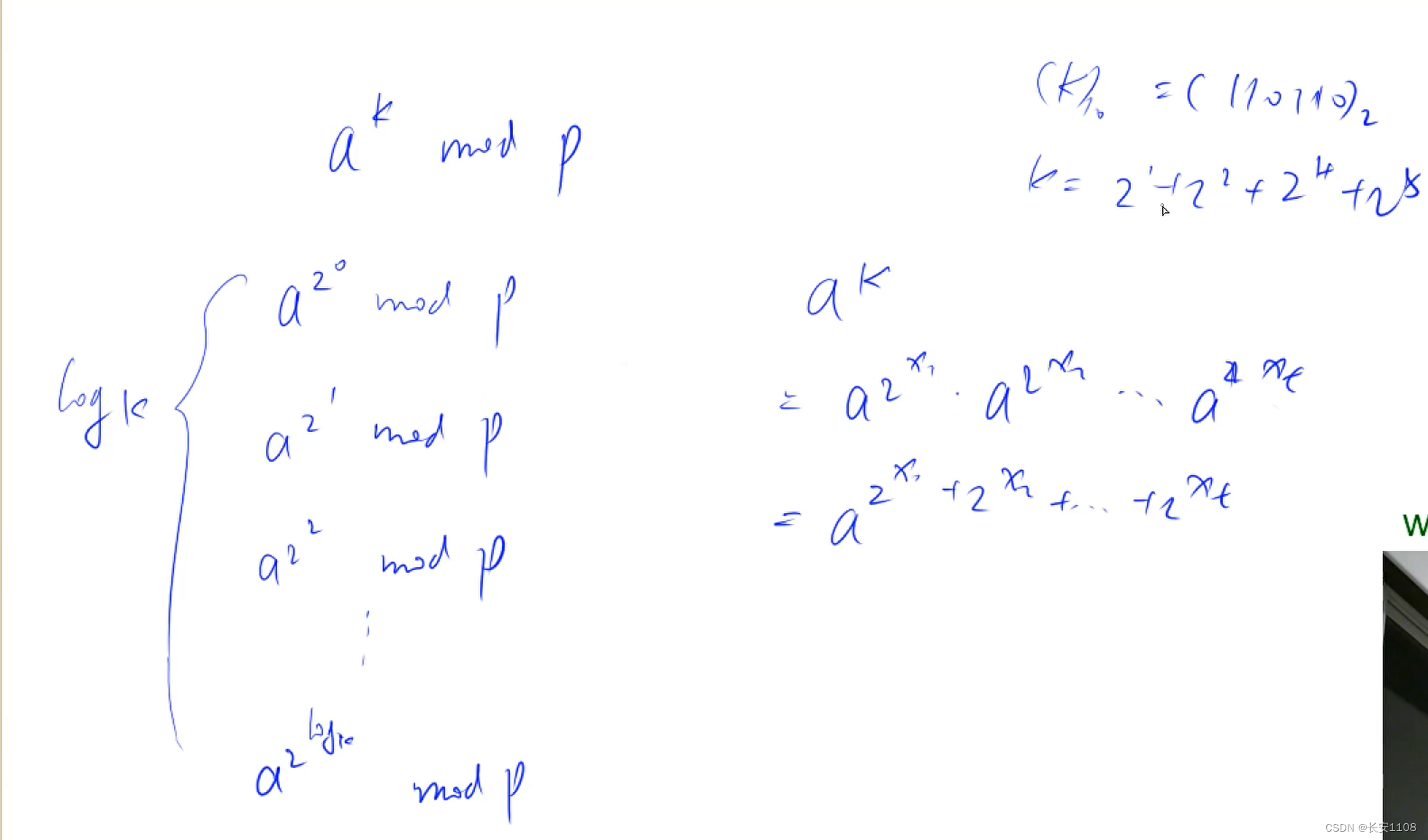
使用快速幂,可以在O(log K)的时间复杂度下得到a的k次方 mod p 的结果
具体步骤:
1、首先我们预处理出来a的(2的0次)次方、a的(2的1次)次方、…a的(2的log K次)次方,这些mod p的结果
2、之后,我们可以将任何一个a的k次方,使用这些预处理出来的结果表示出来,具体原理依据二进制,任何一个十进制的k,都可以写成二进制的k,也就可以写成2的各个次方的和,也就可以写成多个a的(2的某次方)的乘积,从而就可以用那些以及预处理出来的数据,对任何一个数据进行表示
而对于log k个预处理出来的数据,得到的方式如下:
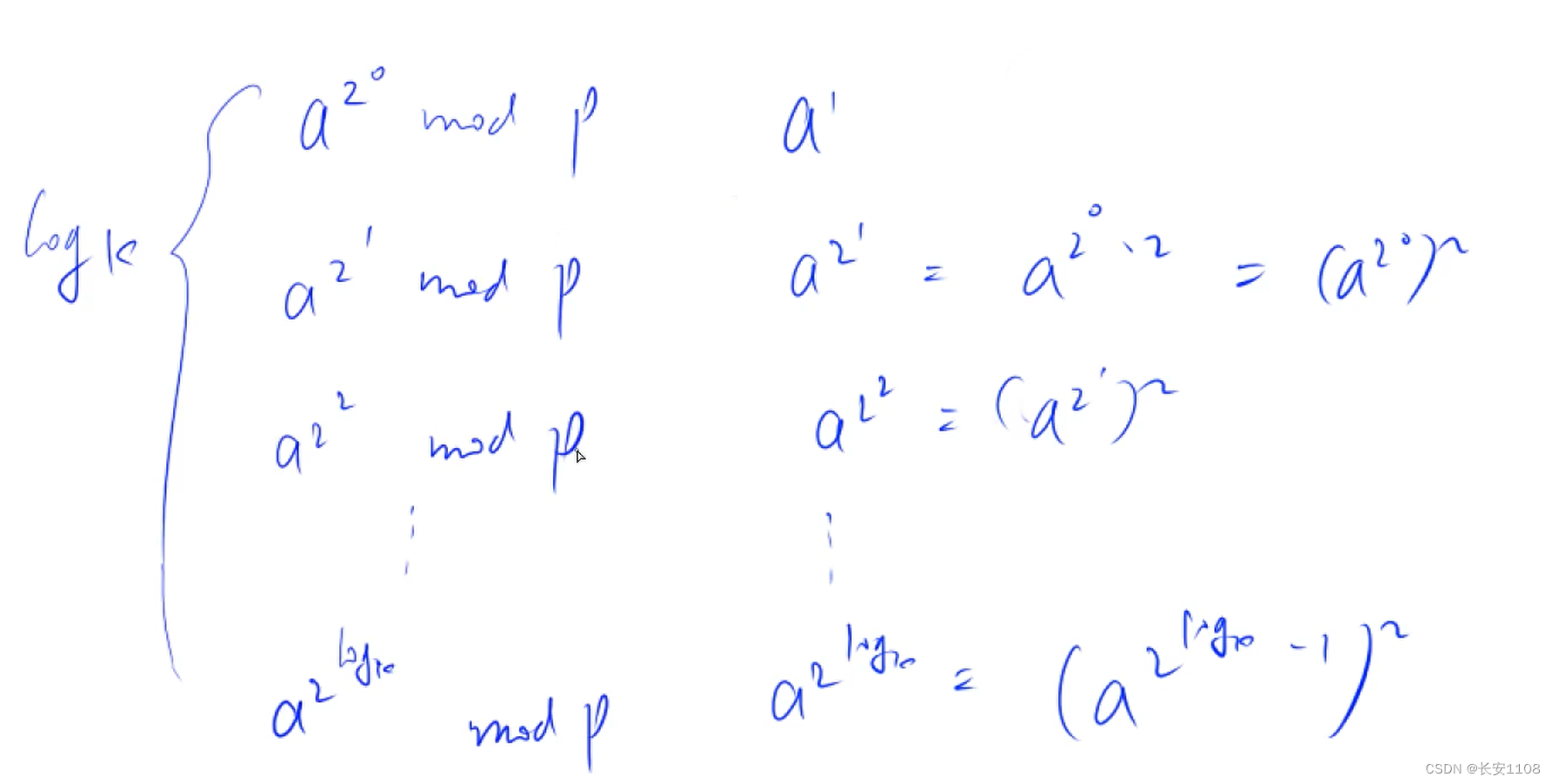
可以看到,每个数都是前一个数的平方得到的,或者可以直接使用mod p 之后的最终结果
都是前一个结果平方后再mod p 得到的
如下是一个例子:
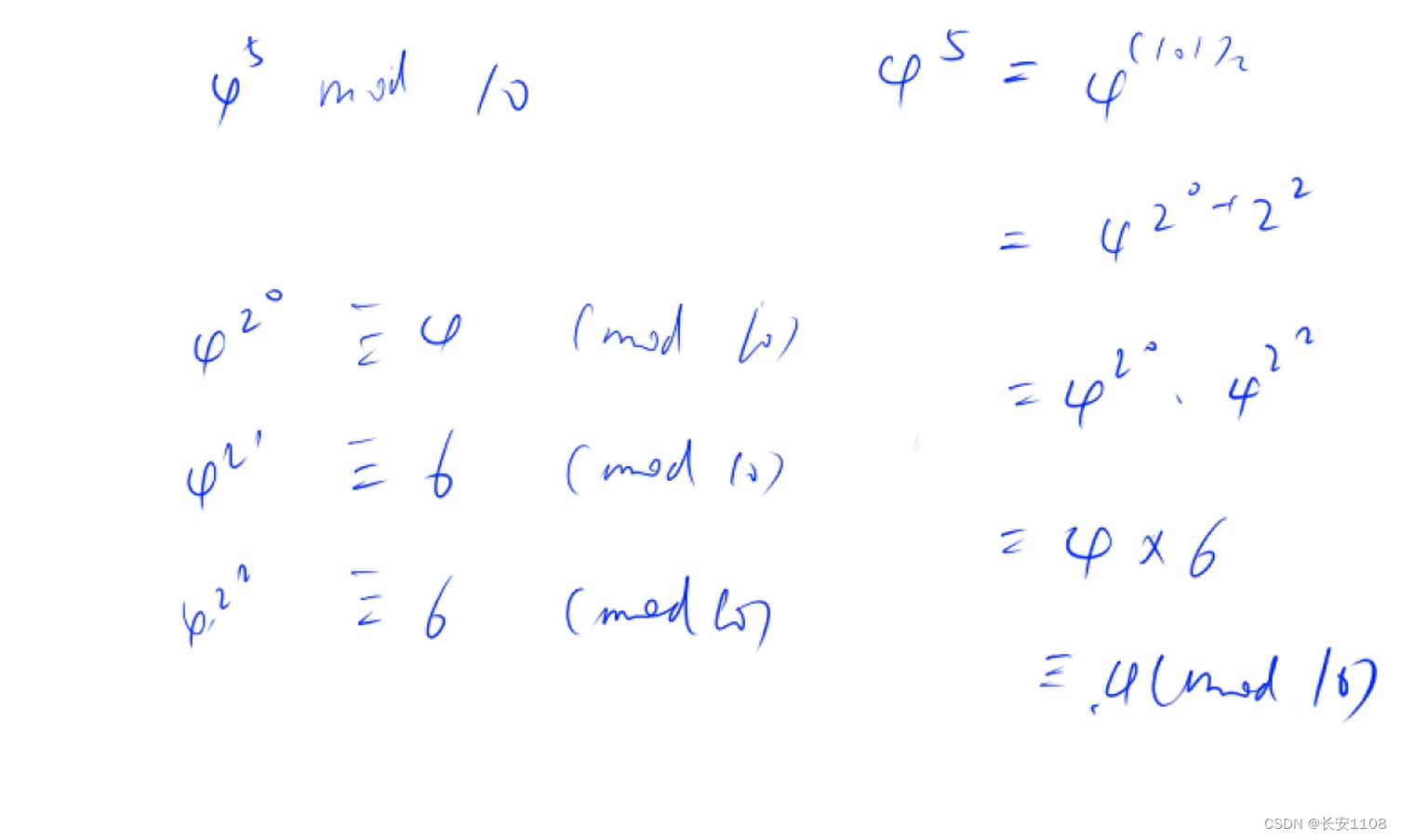
例题+代码
tips:int 能承载的范围是10的9次方,即1e9,所以,一旦有超过这个范围的数据,就要使用long long来接管了
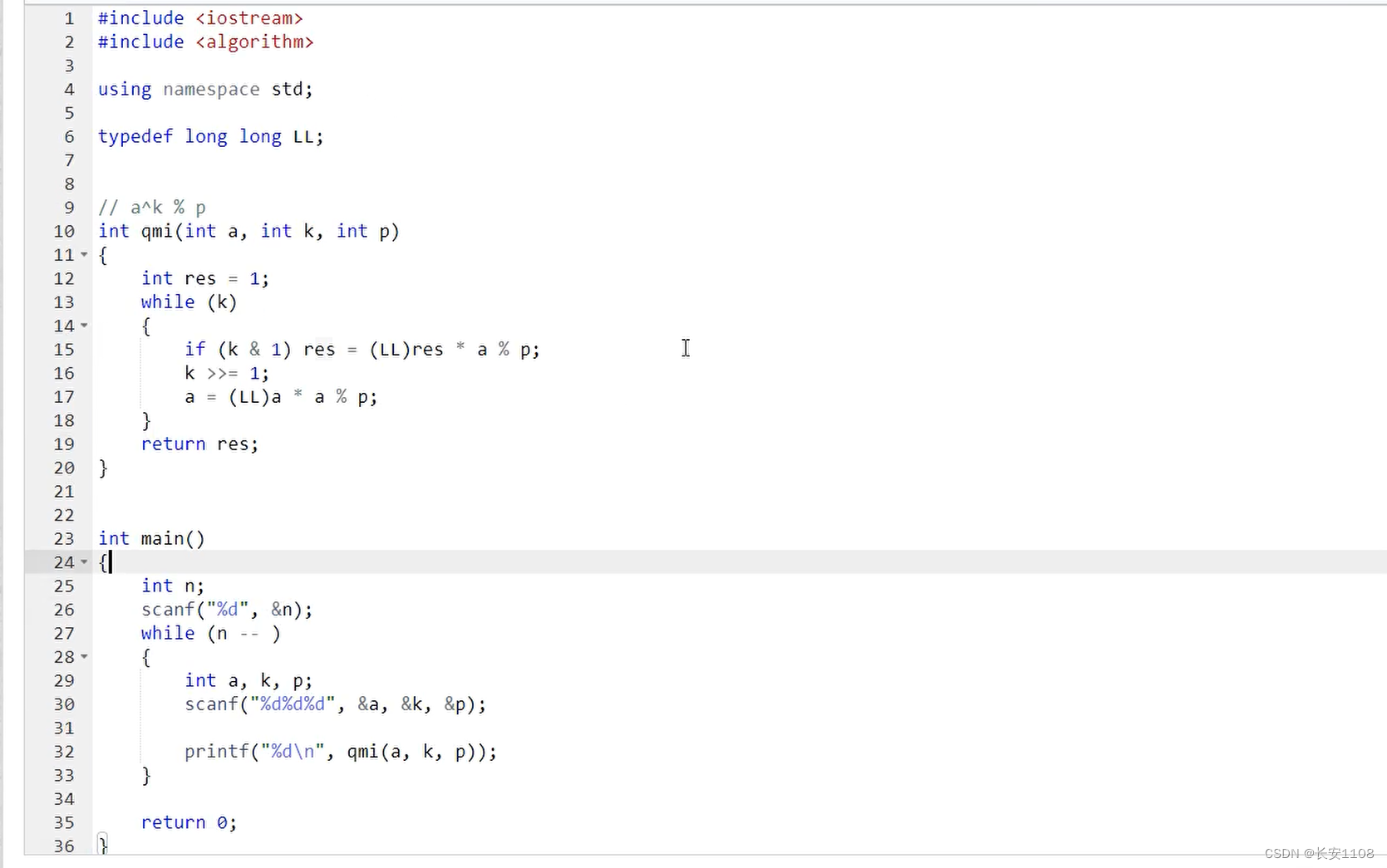
k & 1,是用来查看k的个位数是否为1
k >> 1,是用来消除k的个位数
首先,初始化res=1,
之后while(k){
if 如果k的个位是1,那么表示这里有二进制要使用当前预处理的数据,那么就将答案乘以当前的a,同时mod p, 即 res = res *a % p
判断完之后,更新k,将其个位删除,即k >> 1
之后更新下一个预处理的数据,a = a *a % p
}
最后返回res
快速幂求逆元
例题+代码

基本思想
关于逆元
由逆元的定义可以得到下图:,在mod m的情况下,a/b的余数等于a*x的余数,则x是b在mod m下的逆元,其实根据定义的描述就可以知道,逆元的定义与a无关,所以可以进行化简
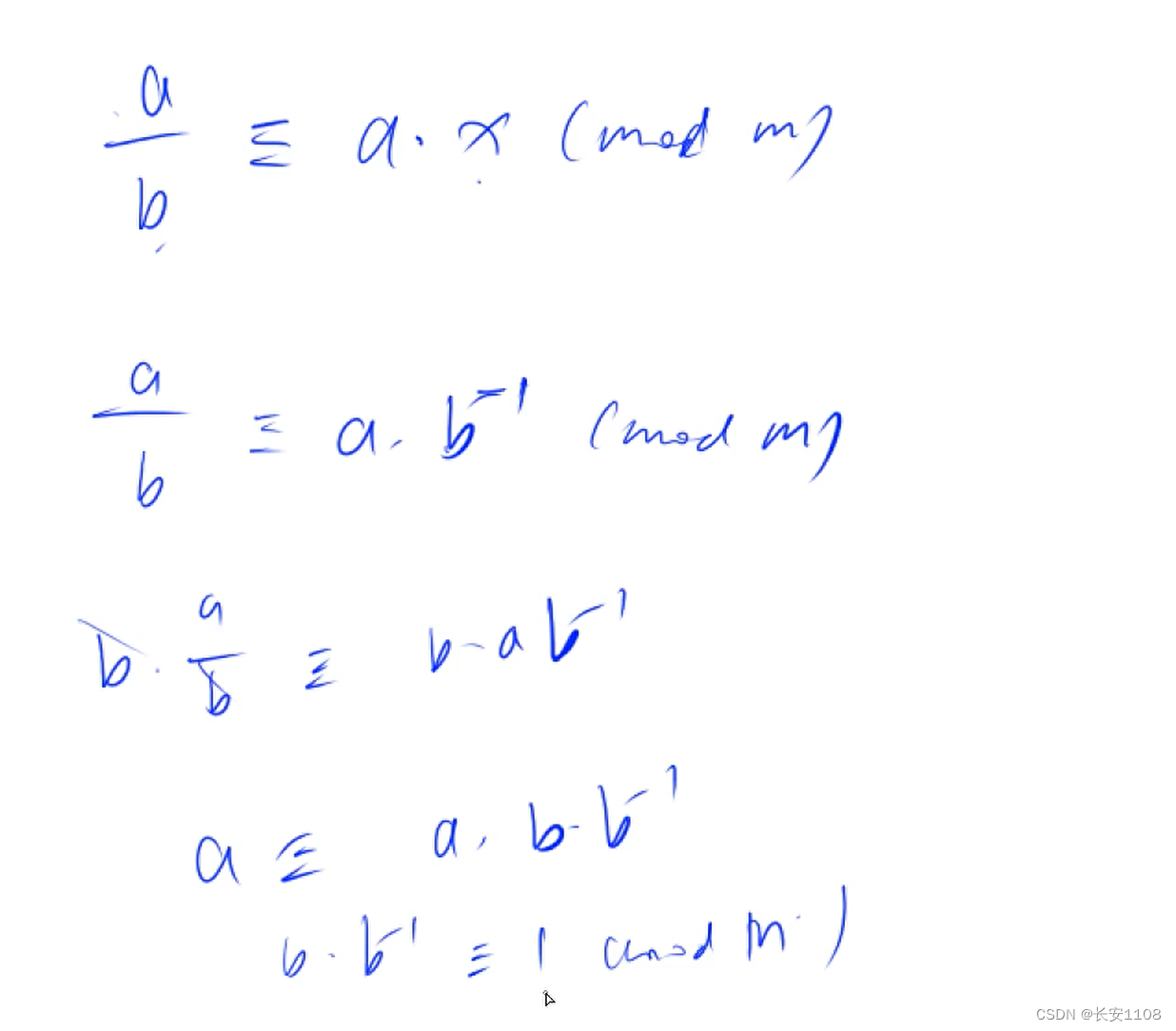
化简之后,可以得到,当b * x 在mod p的情况下等于1的话,则x称为b在mod p下的逆元,
特殊的,如果p是一个质数,那么就可以得到b在mod p下的逆元就是b的(p-2)次方,如下图:
(ps:虽然我们是在求b的(p-2)次方,但是为了保证答案的唯一性,我们要求出b的(p-2)次方 mod p,推到这里,就可以用上面的“快速幂求a的k次方mod p”,带入“底数”、“次方”、“模”)
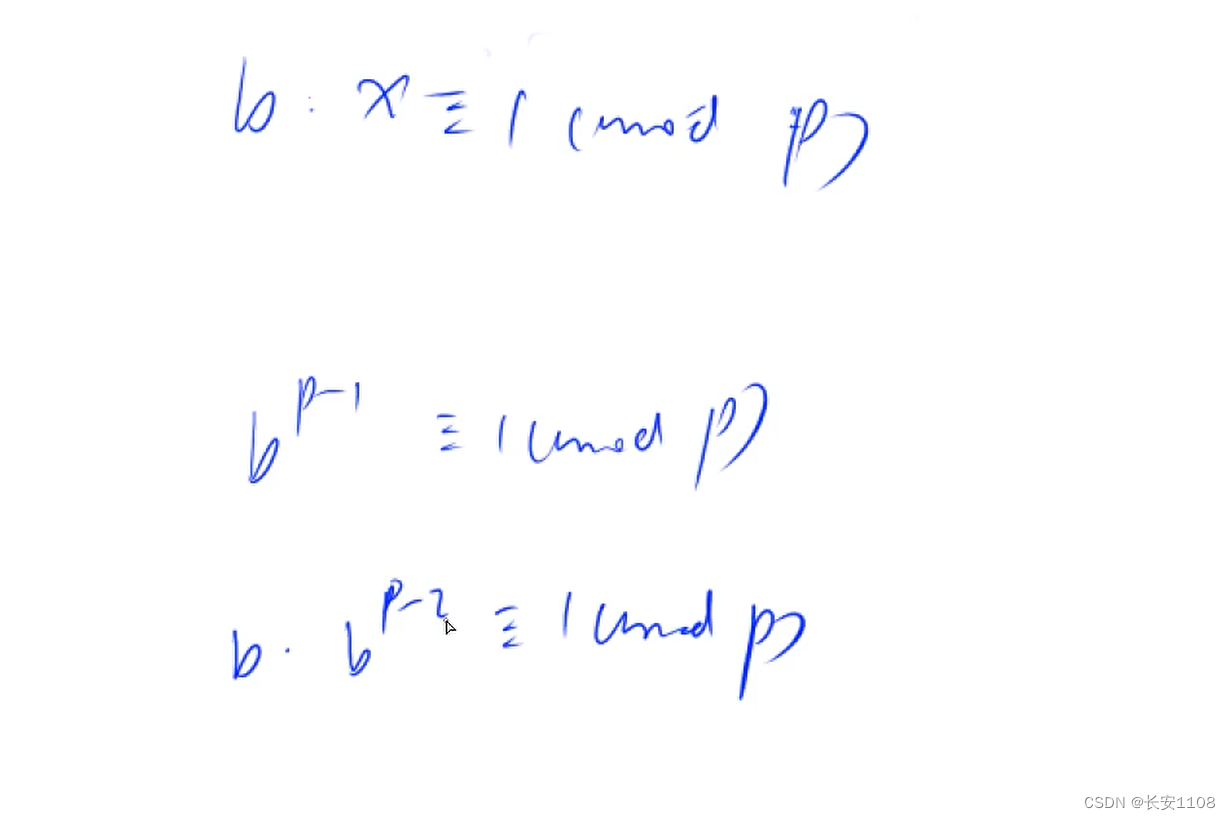
具体代码
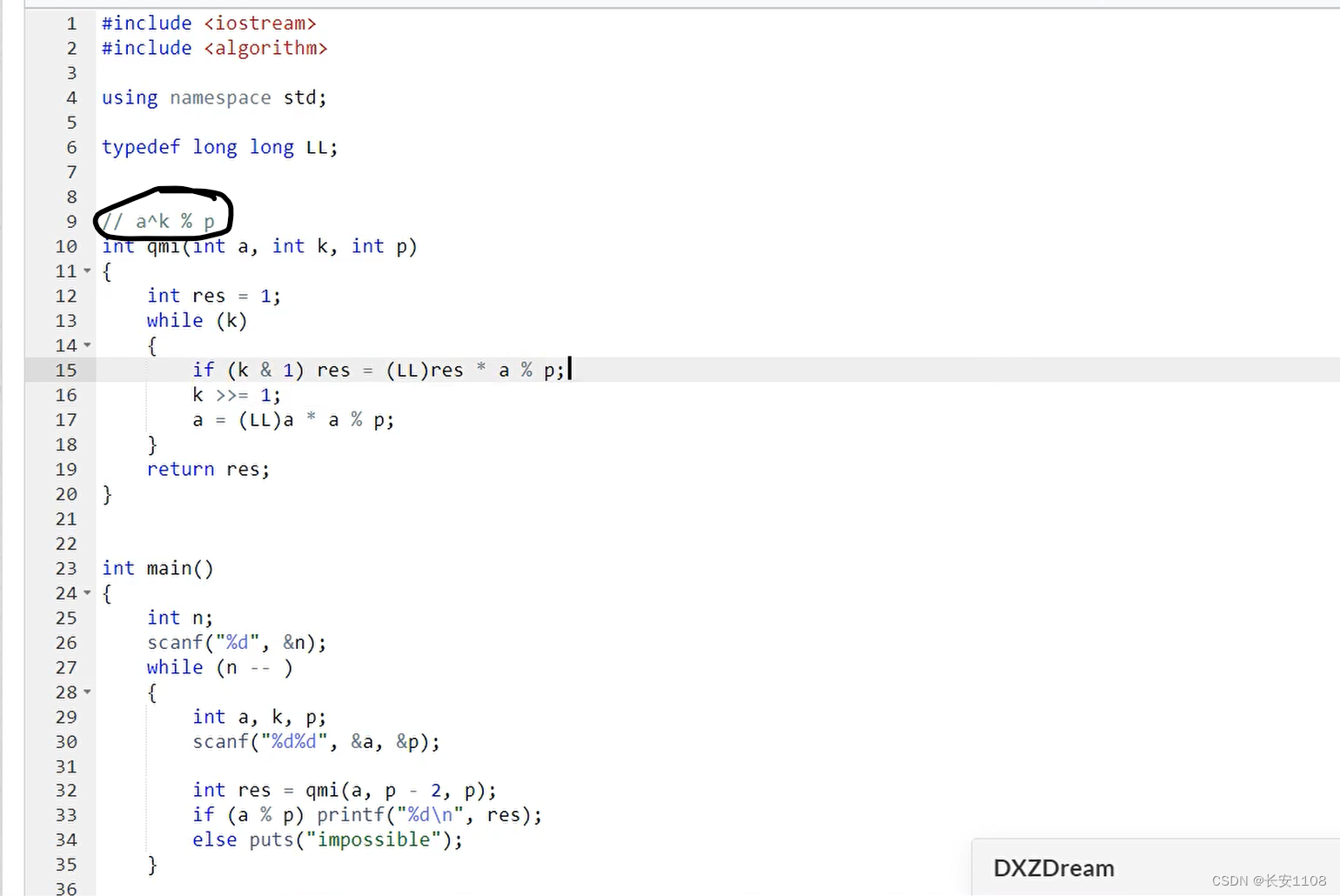
(ps:虽然我们是在求b的(p-2)次方,但是为了保证答案的唯一性,我们要求出b的(p-2)次方 mod p,推到这里,就可以用上面的“快速幂求a的k次方mod p”,带入“底数”、“次方”、“模”),
据此可知,我们带入a p-2 p 即可计算出a的p-2次方mod p的结果,该结果就是答案
特别注意:此类型有无解的情况,即a%p为0时,即a是p的倍数,那么无逆元,按题目要求输出即可
扩展欧几里得算法
使用扩展欧几里得算法求裴蜀定理中的系数x,y
裴蜀定理

对于任意的正整数a,b,一定存在整数非零x,y。使得ax+by=(a,b)。这里的(a,b)表示a b的最大公约数gcd(a,b)
此时x,y所组合出来的数既是a b的最大公约数,同时也是能组合出来的最小的数,
之后其他x,y组合出来的都是(a,b)的倍数
例题+代码
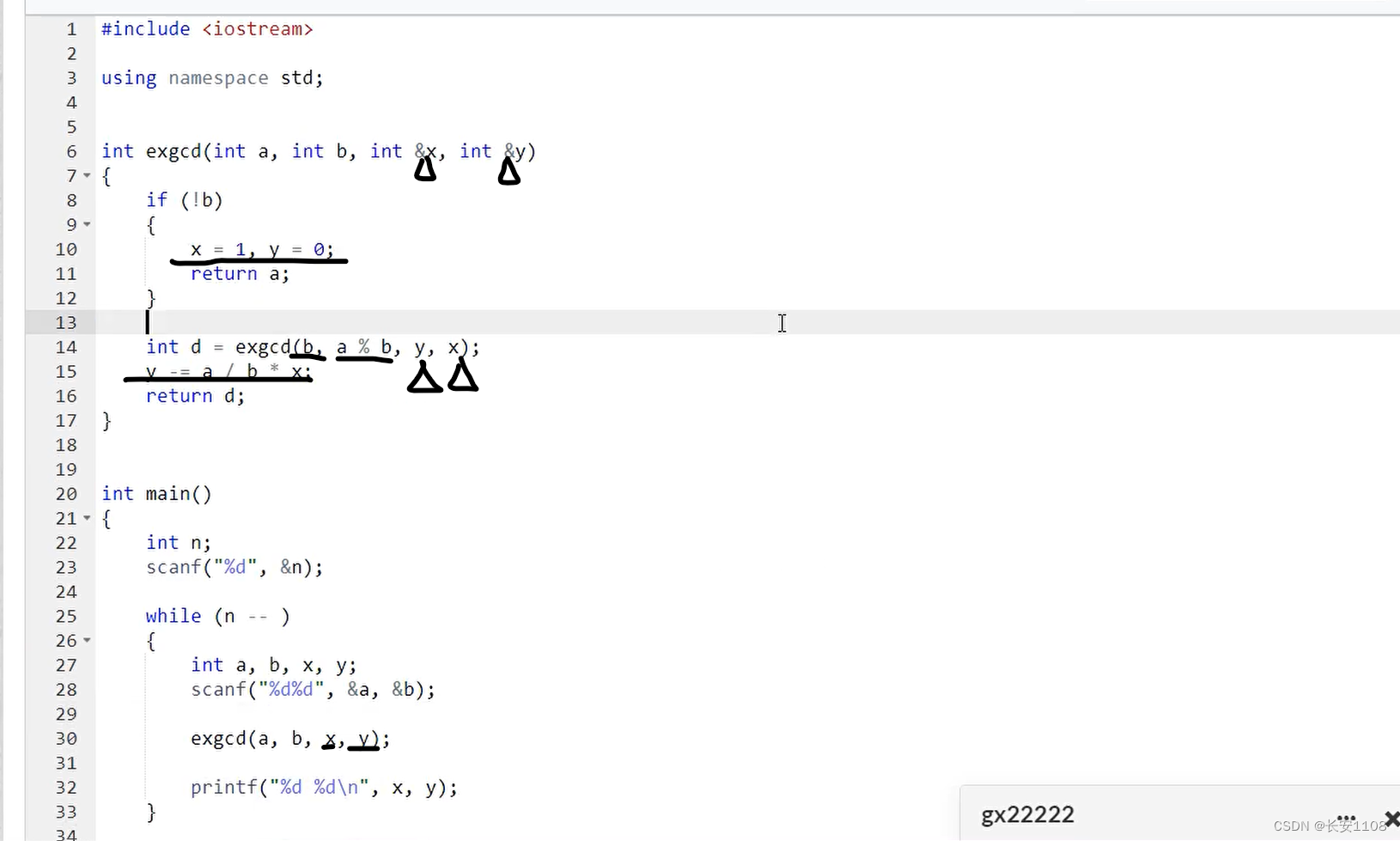
首先注意,比欧几里得算法多了两个引用类型的系数
引用就是变量起别名
之后,将基础版的欧几里得算法扩展开,并加入了一些新的代码
1、在b等于0的时候,得到一组系数x=1,y=0;
2、递归时,不再直接return递归,而是拿到递归的值,同时递归传入时的系数要额外注意,注意他们的顺序(b,a%b,y,x);
3、要更新y的值,y -= a/b *x;
4、最后返回递归的结果d
5、由于参数是引用,所以x,y通过参数返回了回去
tips:本题的答案不唯一,因为根据裴蜀定理,是存在“x与y”,具体x与y有几个,不确定,所以例题中也说明,本题答案不唯一
使用扩展欧几里得算法求线性同余方程
线性同余方程
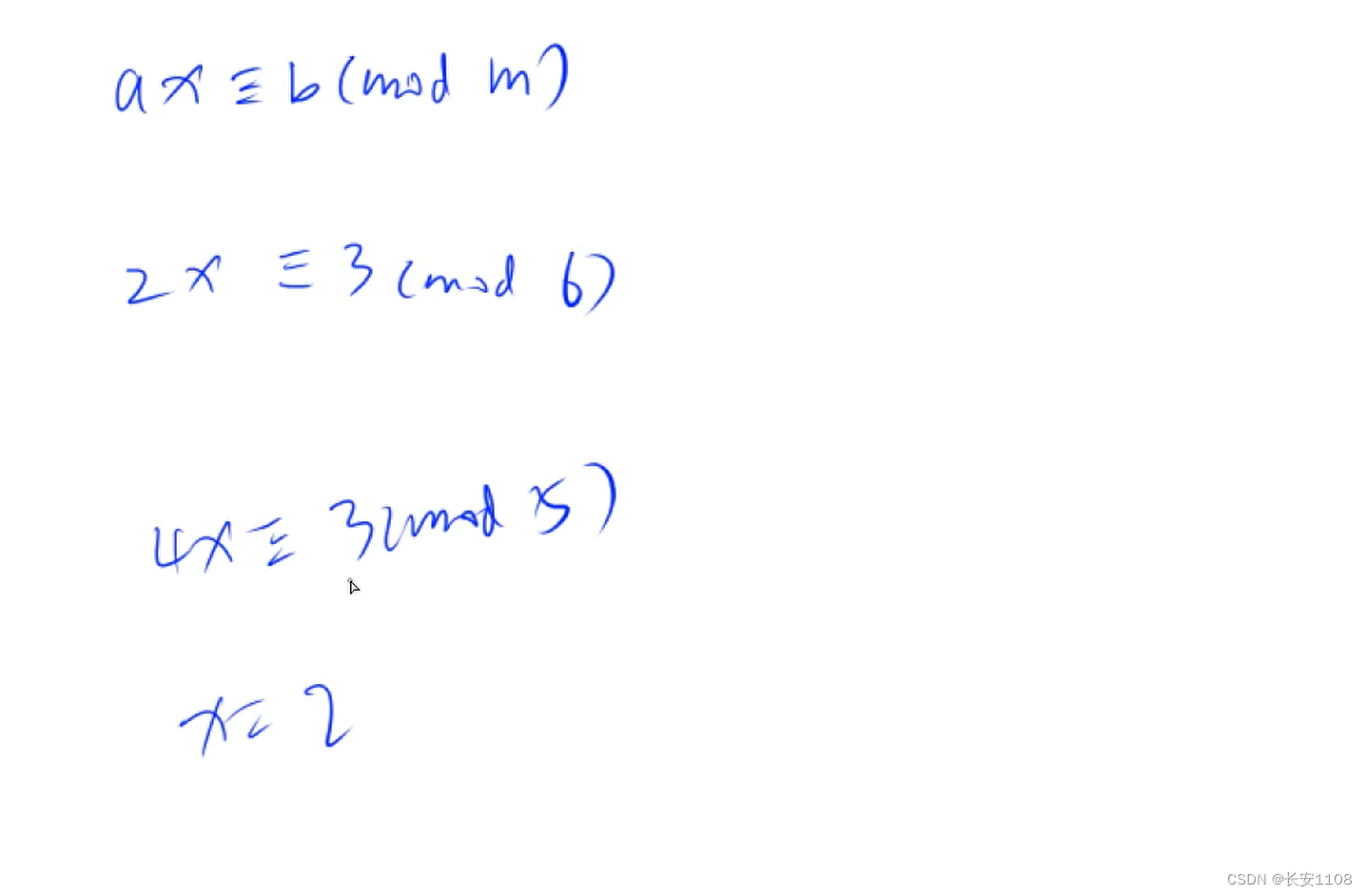
线性同余方程,就是上图中第一个方程,ax在mod m的情况下,余数是b,这就构成了一个线性同余方程,最后求出x的值
代码基本思想
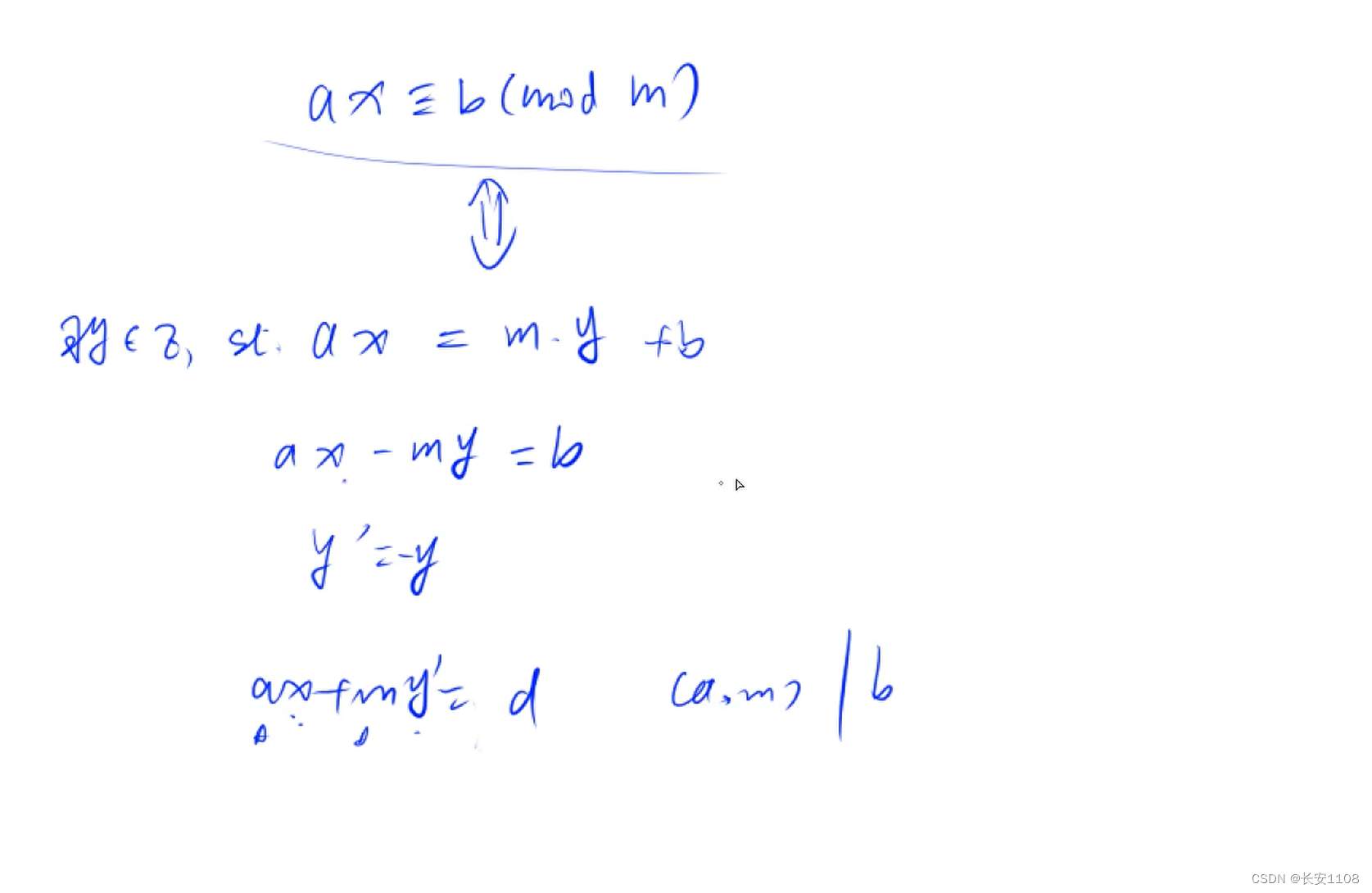
根据线性同余方程,想要求出x,那么可以对其进行变换,
设y是任意一个整数,那么一定有上图第二行的式子
之后,移项,得到第三行的式子
之后,将负号并入到y中,(因为y是任意一个整数)
所以就有了最后一行的式子(y还是y’都无所谓,都是表示任意一个整数)
这时就转化成了扩展欧几里得算法,但是没完全转化,要对b进行讨论:
如果b能整除(a,m),那么就是有解,系数乘以对应的倍数即可
如果不能整除,就是无解
(上图中的d表示a和m的最大公约数)
代码

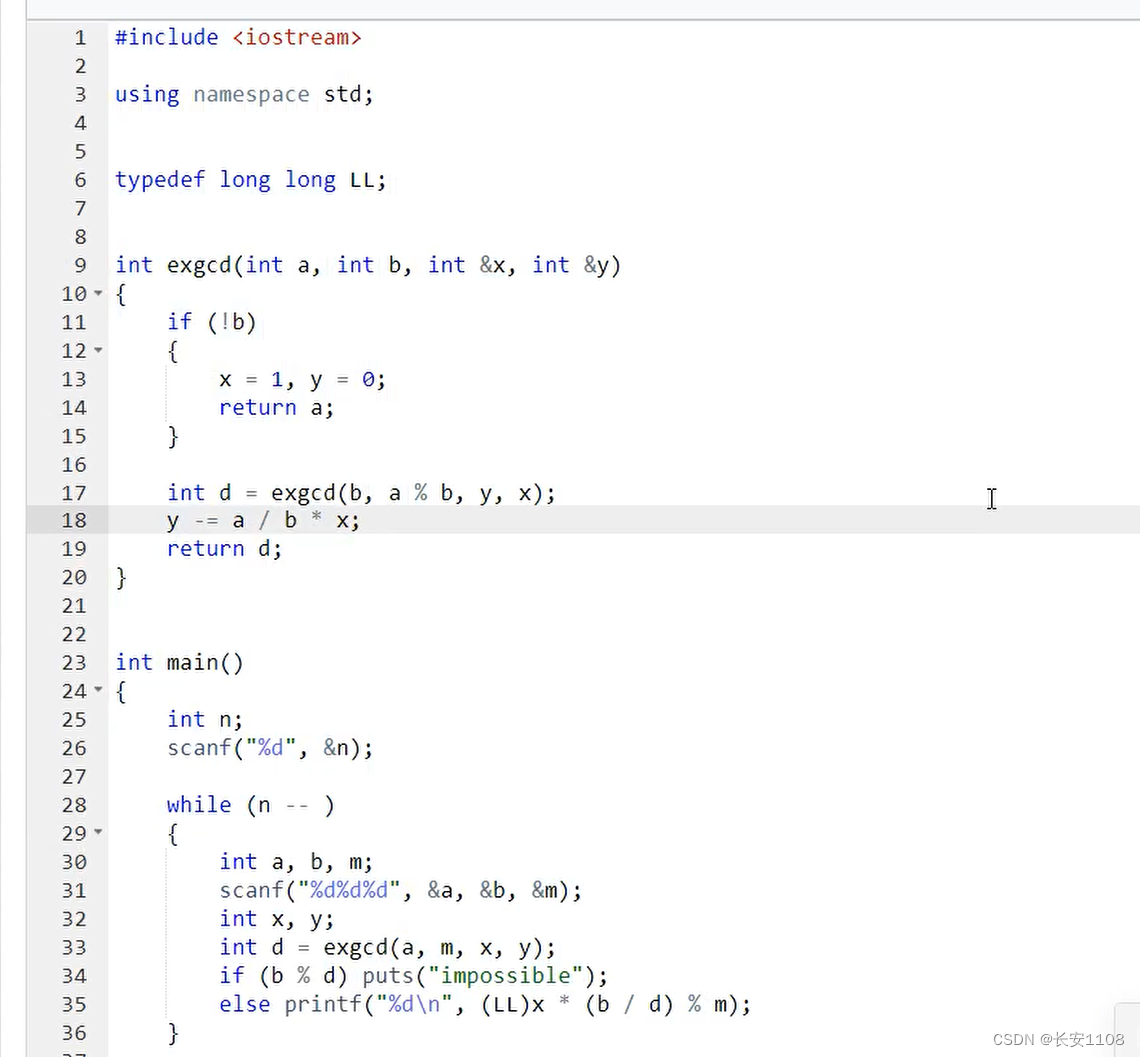
所以,拿到a和m之后,传入exgcd,得到系数x y,之后用d接住,这个d就是a和m的最大公约数,
之后分类讨论有无解,以及解对应的倍数,
如果b%d不等于0,那么无解
如果等于0,那么输出x*(b/d),注意要取模,然后由于超了范围,转为LL