众所周知,机器学习是一门跨学科的学科,主要研究计算机如何通过学习人类的行为和思维模式,以实现某些特定的功能或目标。它涉及到概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科,使用计算机作为工具并致力于真实实时的模拟人类学习方式, 并将现有内容进行知识结构划分来有效提高学习效率。
机器学习流程主要分为四步:1.数据获取--> 2.特征工程 -->3. 建立模型 --> 4.评估与应用。
深度学习是机器学习的一个子集或一个重要分支。深度学习是机器学习的一种方法,通过模仿人类神经网络来实现学习。深度学习的目标是让计算机能够从大量数据中自动提取出有用的特征,并进行分类或回归等任务。深度学习的应用范围包括语音识别、图像识别、自然语言处理等。
以上是官方对于深度学习的定义,实际上深度学习可以用一句话来总结:自动寻找特征的方法。深度学习是一个黑箱模型,他的内部各种参数其实比较缺乏解释性,但是他可以从样本数据中提取出机器能用的特征。因此,深度学习本质上就是一个特殊的特征工程,自动找出可以用来做分类或者预测的特征。数据特征决定了模型的上限,因此预处理和特征提取是最核心的,算法与参数选择决定了如何逼近这个上限。
1. 权重参数和偏置项参数

对于图像而言,每张图片都是采用“宽度 x 高度 x 颜色通道”来进行表示,上图的图像数据32x32x3表示图像的宽度和高度都是32像素,而颜色通道为3,通常代表RGB颜色模式。这意味着图像是一个32x32像素的RGB图像,其中每个像素由三个值(R、G、B)表示,每个值的范围通常是0-255。这三个通道的数值可以组合成不同的颜色,从而实现彩色图像的表示。
在最基本的神经网络中,对于图像数据而言,通过维度扩展,将32x32x3的图像直接拉成一个3072x1的一个向量,然后结合权重参数和偏执参数来进行学习。在神经网络中,权重参数和偏置参数都是重要的组成部分,它们分别具有以下作用:
权重参数:
- 决定每个神经元对输入的重要性。
- 通过不断调整权重,神经网络可以学习到适应任务的特征表示。
- 每个权重对应一个输入特征,可以理解为输入特征的系数,用于计算加权输入。
偏置参数:
- 偏置是一个常数项,用于为神经元引入一个偏移量。
- 它与神经元的输入加权求和相结合,并通过激活函数进行非线性变换。
- 偏置的作用是使得神经元能够更好地拟合数据和提取特征。
- 在前向传播过程中,偏置用于调整神经元的输入和输出。
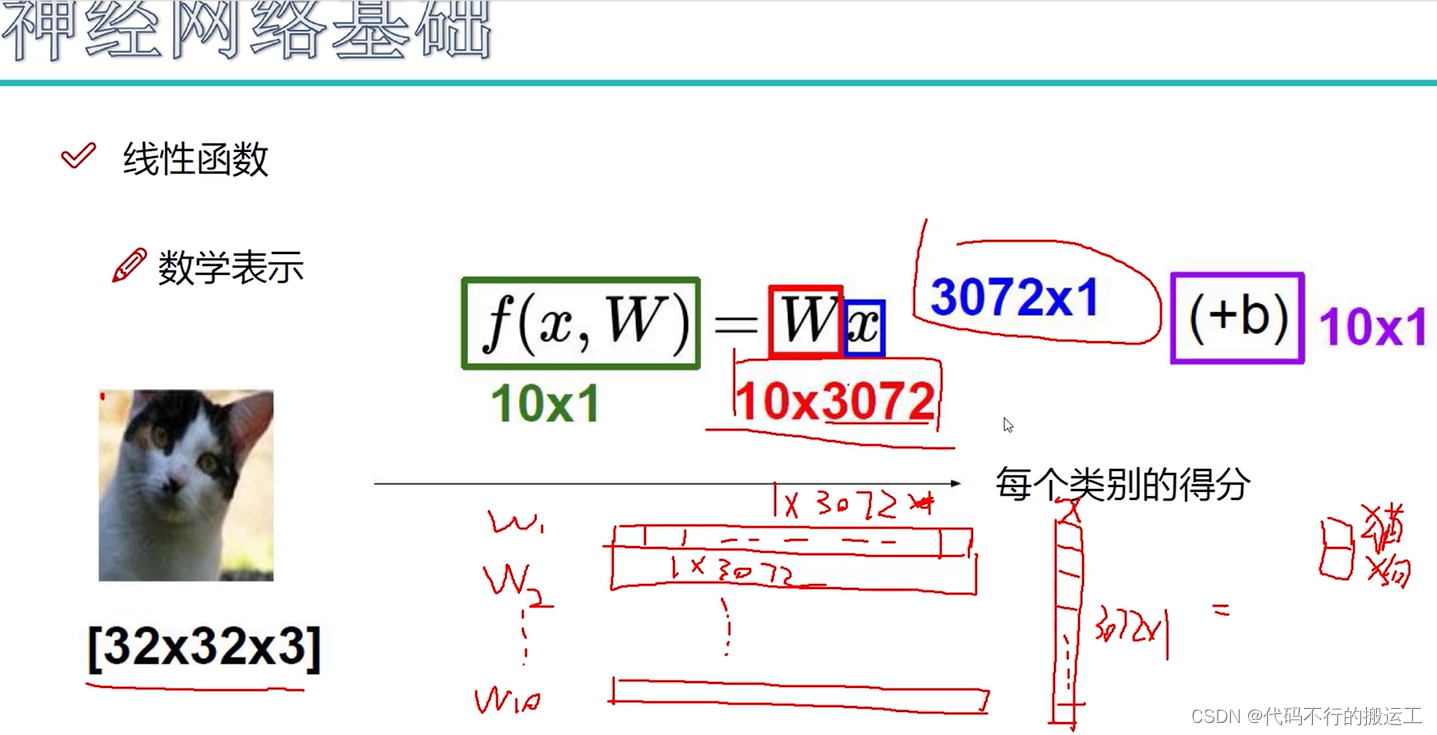
在上图中,假设存在10个类别,因此权重参数是10x3072,偏置参数是10x1,每个类别都存在一个1x3072的权重参数,1x1的偏置参数。具体举例可以看下图:
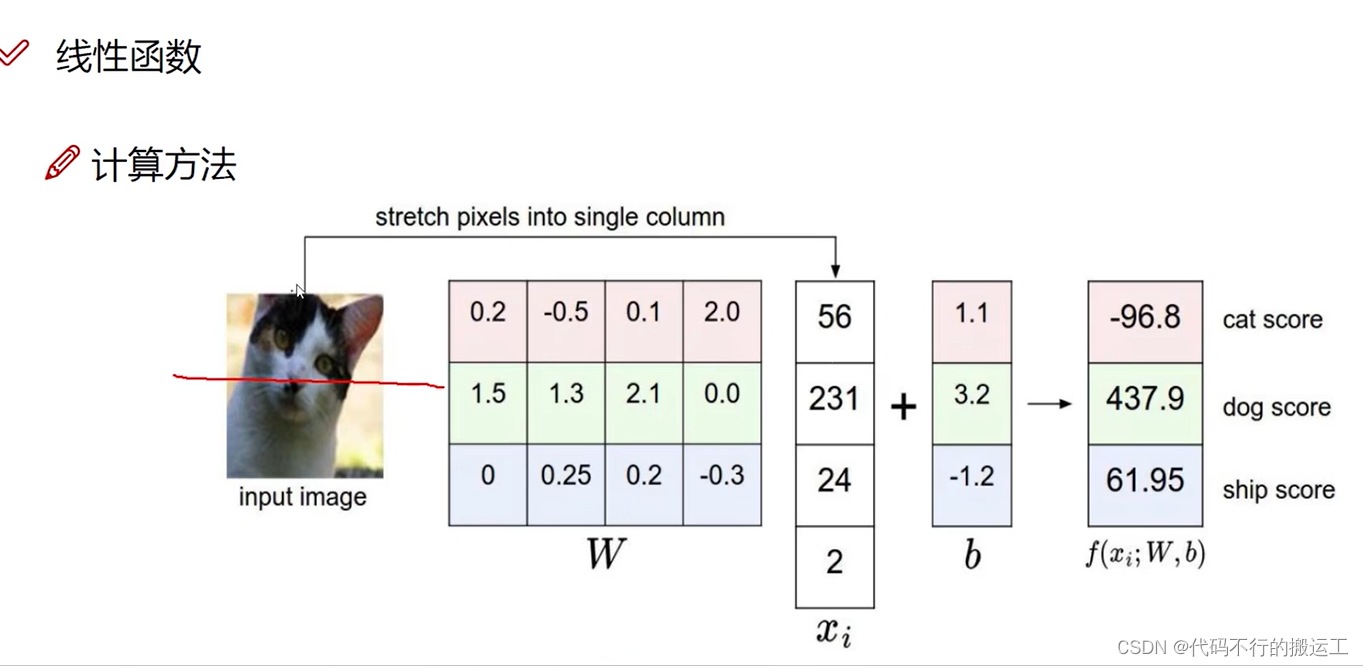
在得到神经网络的输出之后,我们既可以根据输出结果直接进行分类(输出得分),也可以衔接其他的分类器开进行进一步分类(输出特征)。
2. 损失函数
损失函数(也称为代价函数)在神经网络中是一个非常重要的概念,主要用于衡量模型预测结果与真实值之间的差异或错误程度。在下图的距离中,我们利用每个样本在不正确的类别的得分与在正确类别得分的差值来评估模型。

损失函数的选择取决于问题的类型和具体任务。
- 在回归问题中,常见的损失函数是均方误差(Mean Squared Error,MSE),它计算预测值与真实值之间的平方差的均值。均方误差可以用于连续值的预测问题,并且具有收敛速度快等优点。
- 在分类问题中,常见的损失函数是交叉熵损失(Cross-Entropy Loss)。对于多分类问题,通常使用多分类交叉熵损失;对于二分类问题,可以使用二分类交叉熵损失。交叉熵损失通过计算预测概率分布与真实标签之间的交叉熵来衡量模型的错误程度。
此外,损失函数还有许多其他选择,如平均绝对误差(Mean Absolute Error,MAE)等。在实践中,选择适当的损失函数需要根据具体问题和数据集的特点来决定。除了选择适当的损失函数外,还需要注意损失函数的计算方式和优化方法。在神经网络的训练过程中,通常使用梯度下降等优化算法来最小化损失函数。通过计算损失函数的梯度,可以逐步更新神经网络的权重和偏置参数,以逐渐减小损失函数的值,提高模型的预测精度。
3. 正则化惩罚项
对于损失函数相同的模型,我们可以使用正则化惩罚项项来优化损失函数。正则化惩罚项是用来调整权重参数的,一般是使得权重参数分布更加平滑。因此实际上使用的损失函数一般是:损失函数 = 数据损失 + 正则化惩罚项(R(W)) 。
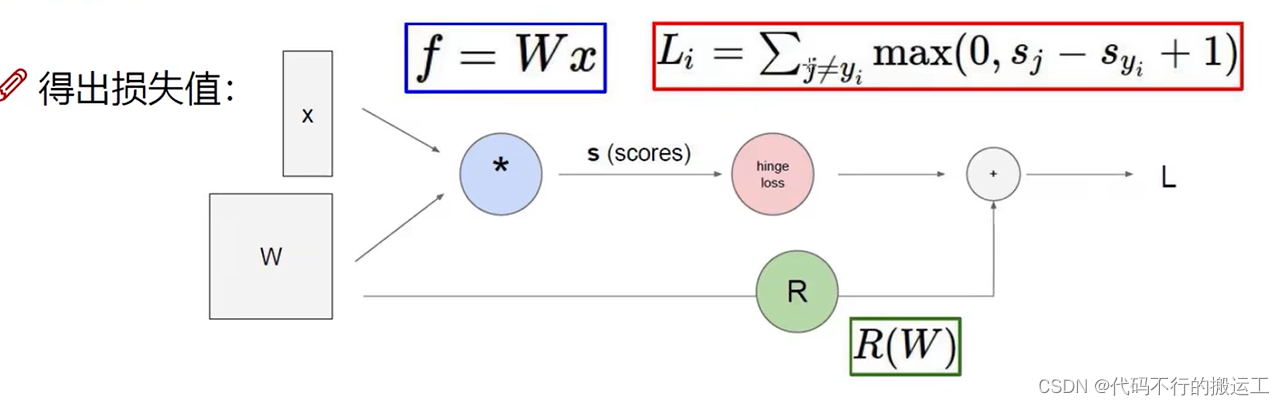
正则化惩罚项是在机器学习和统计学习领域中常用的一种方法,用于防止过拟合和提升模型的泛化能力。通过在目标函数中增加一个或多个正则化项,可以约束模型的复杂度,从而使得模型更加简洁、稳定和可靠。
正则化惩罚项通常包括L1正则化、L2正则化等多种形式。这些正则化项的作用是增加模型复杂度的惩罚,使得模型更加倾向于选择简单的解,而不是过度拟合训练数据。具体来说,
- L1正则化也称为Lasso回归,它通过对权重参数的绝对值之和进行惩罚,从而使得模型中的某些权重参数变得接近于零,达到简化模型的效果。
- L2正则化也称为Ridge回归,它通过对权重参数的平方进行惩罚,使得模型中的权重参数变得较小,从而避免过拟合。
在实际应用中,正则化惩罚项的强度可以通过超参数进行调整。例如,在支持向量机(SVM)中,可以通过调整C参数来控制对错分样本的惩罚程度和模型的复杂度。在神经网络中,可以通过调整正则化强度的超参数来平衡模型的复杂度和拟合能力。
4. Softmax分类器
Softmax分类器可以将获得的得分转换成概率。对于得分值,可以通过归一化,标准化的方式先预处理数据,如下图所示。

Softmax分类器是一种基于概率的分类模型,主要用于解决多分类问题。它通过构建一个softmax函数,将输入特征映射到各个类别的概率分布上,从而实现对未知样本的分类。具体来说,Softmax分类器通常使用神经网络或决策树等模型作为基础,通过训练学习得到每个类别的概率分布。在分类过程中,对于给定的输入样本,Softmax分类器计算其属于各个类别的概率,并将概率最大的类别作为预测结果。
Softmax分类器的优点在于它可以处理多分类问题,并且能够给出每个类别的概率分布,从而提供更多的分类信息。此外,Softmax分类器还可以与其他机器学习算法结合使用,例如支持向量机、决策树等,以实现更精确和稳定的分类效果。
然而,Softmax分类器也存在一些缺点,例如对于输入特征的选择和处理、模型的训练和调参等方面需要一定的技巧和经验。此外,对于大规模高维数据集,Softmax分类器的计算复杂度较高,需要进行高效的算法优化和并行处理。






![[python]基于Ultra-Fast-Lane-Detection-v2车道线实时检测onnx部署](https://img-blog.csdnimg.cn/direct/1b66e0a6121548ecb61d49ab9b800c9a.jpeg)