原文:Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
译者:飞龙
协议:CC BY-NC-SA 4.0
第十八章:强化学习
强化学习(RL)是当今最激动人心的机器学习领域之一,也是最古老的之一。自上世纪 50 年代以来一直存在,多年来产生了许多有趣的应用,特别是在游戏(例如 TD-Gammon,一个下棋程序)和机器控制方面,但很少成为头条新闻。然而,一场革命发生在2013 年,当时来自英国初创公司 DeepMind 的研究人员展示了一个系统,可以从头开始学习玩几乎任何 Atari 游戏,最终在大多数游戏中超越人类,只使用原始像素作为输入,而不需要任何关于游戏规则的先验知识。这是一系列惊人壮举的开始,最终在 2016 年 3 月,他们的系统 AlphaGo 在围棋比赛中击败了传奇职业选手李世石,并在 2017 年 5 月击败了世界冠军柯洁。没有任何程序曾经接近击败这个游戏的大师,更不用说世界冠军了。如今,整个强化学习领域充满了新的想法,具有广泛的应用范围。
那么,DeepMind(2014 年被 Google 以超过 5 亿美元的价格收购)是如何实现所有这些的呢?回顾起来似乎相当简单:他们将深度学习的力量应用于强化学习领域,而且效果超出了他们最疯狂的梦想。在本章中,我将首先解释什么是强化学习以及它擅长什么,然后介绍深度强化学习中最重要的两种技术:策略梯度和深度 Q 网络,包括对马尔可夫决策过程的讨论。让我们开始吧!
学习优化奖励
在强化学习中,软件 代理 在一个 环境 中进行 观察 和 行动,并从环境中获得 奖励。其目标是学会以一种方式行动,以最大化其随时间的预期奖励。如果您不介意有点拟人化,您可以将积极奖励视为快乐,将负面奖励视为痛苦(在这种情况下,“奖励”这个术语有点误导)。简而言之,代理在环境中行动,并通过试错学习来最大化其快乐并最小化其痛苦。
这是一个非常广泛的设置,可以应用于各种任务。以下是一些示例(参见 图 18-1):
-
代理程序可以是控制机器人的程序。在这种情况下,环境是真实世界,代理通过一组传感器(如摄像头和触摸传感器)观察环境,其行动包括发送信号以激活电机。它可能被编程为在接近目标位置时获得积极奖励,而在浪费时间或走错方向时获得负面奖励。
-
代理可以是控制 Ms. Pac-Man 的程序。在这种情况下,环境是 Atari 游戏的模拟,行动是九种可能的摇杆位置(左上、下、中心等),观察是屏幕截图,奖励只是游戏得分。
-
同样,代理可以是玩围棋等棋盘游戏的程序。只有在赢得比赛时才会获得奖励。
-
代理不必控制物理(或虚拟)移动的东西。例如,它可以是一个智能恒温器,每当接近目标温度并节省能源时获得积极奖励,当人类需要调整温度时获得负面奖励,因此代理必须学会预测人类需求。
-
代理可以观察股市价格并决定每秒买入或卖出多少。奖励显然是货币收益和损失。
请注意,可能根本没有任何正面奖励;例如,代理可能在迷宫中四处移动,在每个时间步都会获得负面奖励,因此最好尽快找到出口!还有许多其他适合强化学习的任务示例,例如自动驾驶汽车、推荐系统、在网页上放置广告,或者控制图像分类系统应该关注的位置。

图 18-1. 强化学习示例:(a) 机器人,(b) Ms. Pac-Man,© 围棋选手,(d) 恒温器,(e) 自动交易员⁵
策略搜索
软件代理用来确定其行动的算法称为其策略。策略可以是一个神经网络,将观察作为输入并输出要采取的行动(见图 18-2)。

图 18-2。使用神经网络策略的强化学习
策略可以是你能想到的任何算法,并且不必是确定性的。实际上,在某些情况下,它甚至不必观察环境!例如,考虑一个机器人吸尘器,其奖励是在 30 分钟内吸尘的量。它的策略可以是每秒以概率p向前移动,或者以概率 1 - p随机向左或向右旋转。旋转角度将是- r和+ r之间的随机角度。由于这个策略涉及一些随机性,它被称为随机策略。机器人将有一个不规则的轨迹,这保证了它最终会到达它可以到达的任何地方并清理所有的灰尘。问题是,在 30 分钟内它会吸尘多少?
你会如何训练这样的机器人?你只能调整两个策略参数:概率p和角度范围r。一个可能的学习算法是尝试许多不同的参数值,并选择表现最好的组合(参见图 18-3)。这是一个策略搜索的例子,这种情况下使用了一种蛮力方法。当策略空间太大时(这通常是情况),通过这种方式找到一组好的参数就像在一个巨大的草堆中寻找一根针。
探索政策空间的另一种方法是使用遗传算法。例如,您可以随机创建第一代 100 个政策并尝试它们,然后“淘汰”最差的 80 个政策,并让 20 个幸存者每人产生 4 个后代。后代是其父母的副本加上一些随机变化。幸存的政策及其后代一起构成第二代。您可以继续通过这种方式迭代生成,直到找到一个好的政策。

图 18-3。政策空间中的四个点(左)和代理的相应行为(右)
另一种方法是使用优化技术,通过评估奖励相对于策略参数的梯度,然后通过沿着梯度朝着更高奖励的方向调整这些参数。我们将在本章后面更详细地讨论这种方法,称为策略梯度(PG)。回到吸尘器机器人,您可以稍微增加p,并评估这样做是否会增加机器人在 30 分钟内吸尘的量;如果是,那么再增加p一些,否则减少p。我们将使用 TensorFlow 实现一个流行的 PG 算法,但在此之前,我们需要为代理创建一个环境——现在是介绍 OpenAI Gym 的时候了。
OpenAI Gym 简介
强化学习的一个挑战是,为了训练一个代理程序,您首先需要一个可用的环境。如果您想编写一个代理程序来学习玩 Atari 游戏,您将需要一个 Atari 游戏模拟器。如果您想编写一个行走机器人,那么环境就是现实世界,您可以直接在该环境中训练您的机器人。然而,这也有其局限性:如果机器人掉下悬崖,您不能简单地点击撤销。您也不能加快时间——增加计算能力不会使机器人移动得更快——而且通常来说,同时训练 1000 个机器人的成本太高。简而言之,在现实世界中训练是困难且缓慢的,因此您通常至少需要一个模拟环境来进行引导训练。例如,您可以使用类似PyBullet或MuJoCo的库进行 3D 物理模拟。
OpenAI Gym是一个工具包,提供各种模拟环境(Atari 游戏,棋盘游戏,2D 和 3D 物理模拟等),您可以用它来训练代理程序,比较它们,或者开发新的 RL 算法。
OpenAI Gym 在 Colab 上预先安装,但是它是一个较旧的版本,因此您需要用最新版本替换它。您还需要安装一些它的依赖项。如果您在自己的机器上编程而不是在 Colab 上,并且按照https://homl.info/install上的安装说明进行操作,那么您可以跳过这一步;否则,请输入以下命令:
# Only run these commands on Colab or Kaggle!
%pip install -q -U gym
%pip install -q -U gym[classic_control,box2d,atari,accept-rom-license]
第一个%pip命令将 Gym 升级到最新版本。-q选项代表quiet:它使输出更简洁。-U选项代表upgrade。第二个%pip命令安装了运行各种环境所需的库。这包括来自控制理论(控制动态系统的科学)的经典环境,例如在小车上平衡杆。它还包括基于 Box2D 库的环境——一个用于游戏的 2D 物理引擎。最后,它包括基于 Arcade Learning Environment(ALE)的环境,这是 Atari 2600 游戏的模拟器。几个 Atari 游戏的 ROM 会被自动下载,通过运行这段代码,您同意 Atari 的 ROM 许可证。
有了这个,您就可以使用 OpenAI Gym 了。让我们导入它并创建一个环境:
import gymenv = gym.make("CartPole-v1", render_mode="rgb_array")
在这里,我们创建了一个 CartPole 环境。这是一个 2D 模拟,其中一个小车可以被加速向左或向右,以平衡放在其顶部的杆(参见图 18-4)。这是一个经典的控制任务。
提示
gym.envs.registry字典包含所有可用环境的名称和规格。
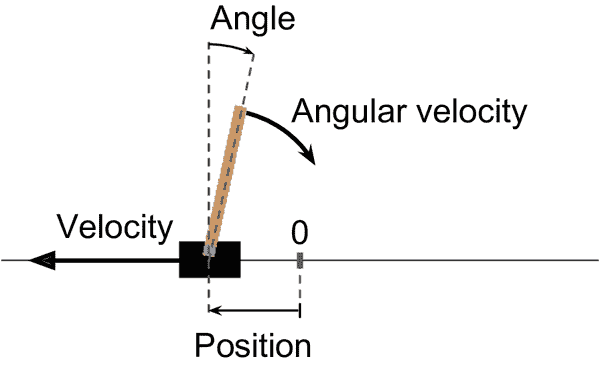
图 18-4。CartPole 环境
在创建环境之后,您必须使用reset()方法对其进行初始化,可以选择性地指定一个随机种子。这将返回第一个观察结果。观察结果取决于环境的类型。对于 CartPole 环境,每个观察结果都是一个包含四个浮点数的 1D NumPy 数组,表示小车的水平位置(0.0 = 中心),其速度(正数表示向右),杆的角度(0.0 = 垂直),以及其角速度(正数表示顺时针)。reset()方法还返回一个可能包含额外环境特定信息的字典。这对于调试或训练可能很有用。例如,在许多 Atari 环境中,它包含剩余的生命次数。然而,在 CartPole 环境中,这个字典是空的。
>>> obs, info = env.reset(seed=42)
>>> obs
array([ 0.0273956 , -0.00611216, 0.03585979, 0.0197368 ], dtype=float32)
>>> info
{}
让我们调用render()方法将这个环境渲染为图像。由于在创建环境时设置了render_mode="rgb_array",图像将作为一个 NumPy 数组返回:
>>> img = env.render()
>>> img.shape # height, width, channels (3 = Red, Green, Blue)
(400, 600, 3)
然后,您可以使用 Matplotlib 的imshow()函数来显示这个图像,就像往常一样。
现在让我们询问环境有哪些可能的动作:
>>> env.action_space
Discrete(2)
Discrete(2)表示可能的动作是整数 0 和 1,分别代表向左或向右加速。其他环境可能有额外的离散动作,或其他类型的动作(例如连续动作)。由于杆向右倾斜(obs[2] > 0),让我们加速小车向右:
>>> action = 1 # accelerate right
>>> obs, reward, done, truncated, info = env.step(action)
>>> obs
array([ 0.02727336, 0.18847767, 0.03625453, -0.26141977], dtype=float32)
>>> reward
1.0
>>> done
False
>>> truncated
False
>>> info
{}
step() 方法执行所需的动作并返回五个值:
obs
这是新的观察。小车现在向右移动(obs[1] > 0)。杆仍然向右倾斜(obs[2] > 0),但它的角速度现在是负的(obs[3] < 0),所以在下一步之后它可能会向左倾斜。
reward
在这个环境中,无论你做什么,每一步都会获得 1.0 的奖励,所以目标是尽可能让情节运行更长时间。
done
当情节结束时,这个值将是True。当杆倾斜得太多,或者离开屏幕,或者经过 200 步后(在这种情况下,你赢了),情节就会结束。之后,环境必须被重置才能再次使用。
truncated
当一个情节被提前中断时,这个值将是True,例如通过一个强加每个情节最大步数的环境包装器(请参阅 Gym 的文档以获取有关环境包装器的更多详细信息)。一些强化学习算法会将截断的情节与正常结束的情节(即done为True时)区别对待,但在本章中,我们将对它们进行相同处理。
info
这个特定于环境的字典可能提供额外的信息,就像reset()方法返回的那样。
提示
当你使用完一个环境后,应该调用它的close()方法来释放资源。
让我们硬编码一个简单的策略,当杆向左倾斜时加速向左,当杆向右倾斜时加速向右。我们将运行此策略,以查看它在 500 个情节中获得的平均奖励:
def basic_policy(obs):angle = obs[2]return 0 if angle < 0 else 1totals = []
for episode in range(500):episode_rewards = 0obs, info = env.reset(seed=episode)for step in range(200):action = basic_policy(obs)obs, reward, done, truncated, info = env.step(action)episode_rewards += rewardif done or truncated:breaktotals.append(episode_rewards)
这段代码是不言自明的。让我们看看结果:
>>> import numpy as np
>>> np.mean(totals), np.std(totals), min(totals), max(totals)
(41.698, 8.389445512070509, 24.0, 63.0)
即使尝试了 500 次,这个策略也从未成功让杆连续保持直立超过 63 步。不太好。如果你看一下本章笔记本中的模拟,你会看到小车左右摆动得越来越强烈,直到杆倾斜得太多。让我们看看神经网络是否能提出一个更好的策略。
神经网络策略
让我们创建一个神经网络策略。这个神经网络将以观察作为输入,并输出要执行的动作,就像我们之前硬编码的策略一样。更准确地说,它将为每个动作估计一个概率,然后我们将根据估计的概率随机选择一个动作(参见图 18-5)。在 CartPole 环境中,只有两种可能的动作(左或右),所以我们只需要一个输出神经元。它将输出动作 0(左)的概率p,当然动作 1(右)的概率将是 1 - p。例如,如果它输出 0.7,那么我们将以 70%的概率选择动作 0,或者以 30%的概率选择动作 1。
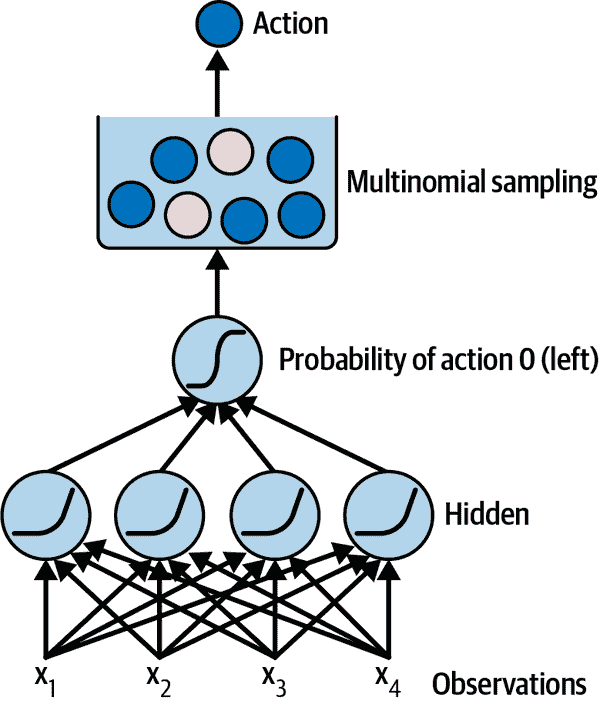
图 18-5. 神经网络策略
你可能会想为什么我们根据神经网络给出的概率随机选择一个动作,而不是只选择得分最高的动作。这种方法让代理人在探索新动作和利用已知效果良好的动作之间找到平衡。这里有一个类比:假设你第一次去一家餐馆,所有菜看起来都一样吸引人,所以你随机挑选了一个。如果它很好吃,你可以增加下次点它的概率,但你不应该将这个概率增加到 100%,否则你永远不会尝试其他菜,其中一些可能比你尝试的这个更好。这个探索/利用的困境在强化学习中是核心的。
还要注意,在这种特定环境中,过去的动作和观察可以安全地被忽略,因为每个观察包含了环境的完整状态。如果有一些隐藏状态,那么您可能需要考虑过去的动作和观察。例如,如果环境只透露了小车的位置而没有速度,那么您不仅需要考虑当前观察,还需要考虑上一个观察以估计当前速度。另一个例子是当观察是嘈杂的;在这种情况下,通常希望使用过去几个观察来估计最可能的当前状态。因此,CartPole 问题非常简单;观察是无噪声的,并且包含了环境的完整状态。
以下是使用 Keras 构建基本神经网络策略的代码:
import tensorflow as tfmodel = tf.keras.Sequential([tf.keras.layers.Dense(5, activation="relu"),tf.keras.layers.Dense(1, activation="sigmoid"),
])
我们使用Sequential模型来定义策略网络。输入的数量是观察空间的大小——在 CartPole 的情况下是 4——我们只有五个隐藏单元,因为这是一个相当简单的任务。最后,我们希望输出一个单一的概率——向左移动的概率——因此我们使用具有 sigmoid 激活函数的单个输出神经元。如果有超过两种可能的动作,每种动作将有一个输出神经元,并且我们将使用 softmax 激活函数。
好的,现在我们有一个神经网络策略,它将接收观察并输出动作概率。但是我们如何训练它呢?
评估动作:信用分配问题
如果我们知道每一步的最佳行动是什么,我们可以像平常一样训练神经网络,通过最小化估计概率分布与目标概率分布之间的交叉熵来实现,这将只是常规的监督学习。然而,在强化学习中,智能体得到的唯一指导是通过奖励,而奖励通常是稀疏和延迟的。例如,如果智能体设法在 100 步内平衡杆,它如何知道这 100 个动作中哪些是好的,哪些是坏的?它只知道在最后一个动作之后杆倒了,但肯定不是这个最后一个动作完全负责。这被称为信用分配问题:当智能体获得奖励时,它很难知道哪些动作应该得到赞扬(或责备)。想象一只狗表现良好几个小时后才得到奖励;它会明白为什么会得到奖励吗?
为了解决这个问题,一个常见的策略是基于之后所有奖励的总和来评估一个动作,通常在每一步应用一个折扣因子,γ(gamma)。这些折扣后的奖励之和被称为动作的回报。考虑图 18-6 中的例子。如果一个智能体连续三次向右移动,并在第一步后获得+10 奖励,在第二步后获得 0 奖励,最后在第三步后获得-50 奖励,那么假设我们使用一个折扣因子γ=0.8,第一个动作的回报将是 10 + γ × 0 + γ² × (–50) = –22。如果折扣因子接近 0,那么未来的奖励与即时奖励相比不会占据很大比重。相反,如果折扣因子接近 1,那么未来的奖励将几乎和即时奖励一样重要。典型的折扣因子从 0.9 到 0.99 不等。使用折扣因子 0.95,未来 13 步的奖励大约相当于即时奖励的一半(因为 0.95¹³ ≈ 0.5),而使用折扣因子 0.99,未来 69 步的奖励相当于即时奖励的一半。在 CartPole 环境中,动作具有相当短期的影响,因此选择折扣因子 0.95 似乎是合理的。
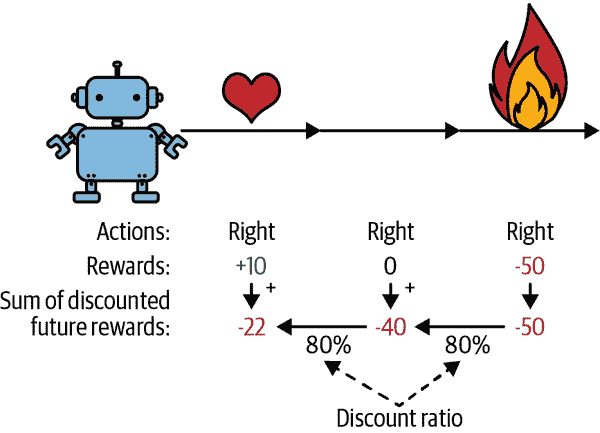
图 18-6。计算动作的回报:折扣未来奖励之和
当然,一个好的行动可能会被几个导致杆迅速倒下的坏行动跟随,导致好的行动获得较低的回报。同样,一个好的演员有时可能会出演一部糟糕的电影。然而,如果我们玩足够多次游戏,平均而言好的行动将获得比坏行动更高的回报。我们想要估计一个行动相对于其他可能行动的平均优势有多大。这被称为行动优势。为此,我们必须运行许多情节,并通过减去均值并除以标准差来标准化所有行动回报。之后,我们可以合理地假设具有负优势的行动是坏的,而具有正优势的行动是好的。现在我们有了一种评估每个行动的方法,我们准备使用策略梯度来训练我们的第一个代理。让我们看看如何。
策略梯度
正如前面讨论的,PG 算法通过沿着梯度朝着更高奖励的方向优化策略的参数。一种流行的 PG 算法类别称为REINFORCE 算法,由 Ronald Williams 于 1992 年提出。这里是一个常见的变体:
-
首先,让神经网络策略玩游戏多次,并在每一步计算使选择的行动更有可能的梯度,但暂时不应用这些梯度。
-
在运行了几个情节之后,使用前一节中描述的方法计算每个行动的优势。
-
如果一个行动的优势是正的,这意味着这个行动可能是好的,你希望应用之前计算的梯度,使这个行动在未来更有可能被选择。然而,如果一个行动的优势是负的,这意味着这个行动可能是坏的,你希望应用相反的梯度,使这个行动在未来略微减少。解决方案是将每个梯度向量乘以相应行动的优势。
-
最后,计算所有结果梯度向量的平均值,并用它执行一步梯度下降。
让我们使用 Keras 来实现这个算法。我们将训练之前构建的神经网络策略,使其学会在小车上平衡杆。首先,我们需要一个函数来执行一步。我们暂时假设无论采取什么行动都是正确的,以便我们可以计算损失及其梯度。这些梯度将暂时保存一段时间,我们稍后会根据行动的好坏来修改它们:
def play_one_step(env, obs, model, loss_fn):with tf.GradientTape() as tape:left_proba = model(obs[np.newaxis])action = (tf.random.uniform([1, 1]) > left_proba)y_target = tf.constant([[1.]]) - tf.cast(action, tf.float32)loss = tf.reduce_mean(loss_fn(y_target, left_proba))grads = tape.gradient(loss, model.trainable_variables)obs, reward, done, truncated, info = env.step(int(action))return obs, reward, done, truncated, grads
让我们来看看这个函数:
-
在
GradientTape块中(参见第十二章),我们首先调用模型,给它一个观察值。我们将观察值重塑为包含单个实例的批次,因为模型期望一个批次。这将输出向左移动的概率。 -
接下来,我们随机抽取一个介于 0 和 1 之间的浮点数,并检查它是否大于
left_proba。action将以left_proba的概率为False,或以1 - left_proba的概率为True。一旦我们将这个布尔值转换为整数,行动将以适当的概率为 0(左)或 1(右)。 -
现在我们定义向左移动的目标概率:它是 1 减去行动(转换为浮点数)。如果行动是 0(左),那么向左移动的目标概率将是 1。如果行动是 1(右),那么目标概率将是 0。
-
然后我们使用给定的损失函数计算损失,并使用 tape 计算损失相对于模型可训练变量的梯度。同样,这些梯度稍后会在应用之前进行调整,取决于行动的好坏。
-
最后,我们执行选择的行动,并返回新的观察值、奖励、该情节是否结束、是否截断,当然还有我们刚刚计算的梯度。
现在让我们创建另一个函数,它将依赖于play_one_step()函数来玩多个回合,返回每个回合和每个步骤的所有奖励和梯度:
def play_multiple_episodes(env, n_episodes, n_max_steps, model, loss_fn):all_rewards = []all_grads = []for episode in range(n_episodes):current_rewards = []current_grads = []obs, info = env.reset()for step in range(n_max_steps):obs, reward, done, truncated, grads = play_one_step(env, obs, model, loss_fn)current_rewards.append(reward)current_grads.append(grads)if done or truncated:breakall_rewards.append(current_rewards)all_grads.append(current_grads)return all_rewards, all_grads
这段代码返回了一个奖励列表的列表:每个回合一个奖励列表,每个步骤一个奖励。它还返回了一个梯度列表的列表:每个回合一个梯度列表,每个梯度列表包含每个步骤的一个梯度元组,每个元组包含每个可训练变量的一个梯度张量。
该算法将使用play_multiple_episodes()函数多次玩游戏(例如,10 次),然后它将回头查看所有奖励,对其进行折扣,并对其进行归一化。为此,我们需要几个额外的函数;第一个将计算每个步骤的未来折扣奖励总和,第二个将通过减去均值并除以标准差来对所有这些折扣奖励(即回报)在许多回合中进行归一化:
def discount_rewards(rewards, discount_factor):discounted = np.array(rewards)for step in range(len(rewards) - 2, -1, -1):discounted[step] += discounted[step + 1] * discount_factorreturn discounteddef discount_and_normalize_rewards(all_rewards, discount_factor):all_discounted_rewards = [discount_rewards(rewards, discount_factor)for rewards in all_rewards]flat_rewards = np.concatenate(all_discounted_rewards)reward_mean = flat_rewards.mean()reward_std = flat_rewards.std()return [(discounted_rewards - reward_mean) / reward_stdfor discounted_rewards in all_discounted_rewards]
让我们检查一下这是否有效:
>>> discount_rewards([10, 0, -50], discount_factor=0.8)
array([-22, -40, -50])
>>> discount_and_normalize_rewards([[10, 0, -50], [10, 20]],
... discount_factor=0.8)
...
[array([-0.28435071, -0.86597718, -1.18910299]),array([1.26665318, 1.0727777 ])]
调用discount_rewards()返回了我们预期的结果(见图 18-6)。您可以验证函数discount_and_normalize_rewards()确实返回了两个回合中每个动作的归一化优势。请注意,第一个回合比第二个回合差得多,因此它的归一化优势都是负数;第一个回合的所有动作都被认为是不好的,反之第二个回合的所有动作都被认为是好的。
我们几乎准备好运行算法了!现在让我们定义超参数。我们将运行 150 次训练迭代,每次迭代玩 10 个回合,每个回合最多持续 200 步。我们将使用折扣因子 0.95:
n_iterations = 150
n_episodes_per_update = 10
n_max_steps = 200
discount_factor = 0.95
我们还需要一个优化器和损失函数。一个常规的 Nadam 优化器,学习率为 0.01,将会很好地完成任务,我们将使用二元交叉熵损失函数,因为我们正在训练一个二元分类器(有两种可能的动作——左或右):
optimizer = tf.keras.optimizers.Nadam(learning_rate=0.01)
loss_fn = tf.keras.losses.binary_crossentropy
现在我们准备构建和运行训练循环!
for iteration in range(n_iterations):all_rewards, all_grads = play_multiple_episodes(env, n_episodes_per_update, n_max_steps, model, loss_fn)all_final_rewards = discount_and_normalize_rewards(all_rewards,discount_factor)all_mean_grads = []for var_index in range(len(model.trainable_variables)):mean_grads = tf.reduce_mean([final_reward * all_grads[episode_index][step][var_index]for episode_index, final_rewards in enumerate(all_final_rewards)for step, final_reward in enumerate(final_rewards)], axis=0)all_mean_grads.append(mean_grads)optimizer.apply_gradients(zip(all_mean_grads, model.trainable_variables))
让我们逐步走过这段代码:
-
在每次训练迭代中,此循环调用
play_multiple_episodes()函数,该函数播放 10 个回合,并返回每个步骤中每个回合的奖励和梯度。 -
然后我们调用
discount_and_normalize_rewards()函数来计算每个动作的归一化优势,这在这段代码中称为final_reward。这提供了一个衡量每个动作实际上是好还是坏的指标。 -
接下来,我们遍历每个可训练变量,并对每个变量计算所有回合和所有步骤中该变量的梯度的加权平均,权重为
final_reward。 -
最后,我们使用优化器应用这些均值梯度:模型的可训练变量将被微调,希望策略会有所改善。
我们完成了!这段代码将训练神经网络策略,并成功学会在小车上平衡杆。每个回合的平均奖励将非常接近 200。默认情况下,这是该环境的最大值。成功!
我们刚刚训练的简单策略梯度算法解决了 CartPole 任务,但是它在扩展到更大更复杂的任务时效果不佳。事实上,它具有很高的样本效率低,这意味着它需要很长时间探索游戏才能取得显著进展。这是因为它必须运行多个回合来估计每个动作的优势,正如我们所见。然而,它是更强大算法的基础,比如演员-评论家算法(我们将在本章末简要讨论)。
提示
研究人员试图找到即使代理最初对环境一无所知也能很好运行的算法。然而,除非你在写论文,否则不应该犹豫向代理注入先验知识,因为这将极大加快训练速度。例如,由于你知道杆应该尽可能垂直,你可以添加与杆角度成比例的负奖励。这将使奖励变得不那么稀疏,加快训练速度。此外,如果你已经有一个相当不错的策略(例如硬编码),你可能希望在使用策略梯度来改进之前,训练神经网络来模仿它。
现在我们将看一下另一个流行的算法家族。PG 算法直接尝试优化策略以增加奖励,而我们现在要探索的算法则不那么直接:代理学习估计每个状态的预期回报,或者每个状态中每个动作的预期回报,然后利用这些知识来决定如何行动。要理解这些算法,我们首先必须考虑马尔可夫决策过程(MDPs)。
马尔可夫决策过程
20 世纪初,数学家安德烈·马尔可夫研究了没有记忆的随机过程,称为马尔可夫链。这样的过程具有固定数量的状态,并且在每一步中随机从一个状态演变到另一个状态。它从状态s演变到状态s′的概率是固定的,仅取决于对(s, s′)这一对,而不取决于过去的状态。这就是为什么我们说该系统没有记忆。
图 18-7 显示了一个具有四个状态的马尔可夫链的示例。

图 18-7. 马尔可夫链示例
假设过程从状态s[0]开始,并且有 70%的概率在下一步保持在该状态。最终,它必定会离开该状态并永远不会回来,因为没有其他状态指向s[0]。如果它进入状态s[1],那么它很可能会进入状态s[2](90%的概率),然后立即返回到状态s[1](100%的概率)。它可能在这两个状态之间交替多次,但最终会陷入状态s[3]并永远留在那里,因为没有出路:这被称为终止状态。马尔可夫链的动态可能非常不同,并且在热力学、化学、统计学等领域被广泛使用。
马尔可夫决策过程是在 20 世纪 50 年代由理查德·贝尔曼首次描述的。¹² 它们类似于马尔可夫链,但有一个区别:在每一步中,代理可以选择几种可能的动作之一,转移概率取决于所选择的动作。此外,一些状态转移会产生一些奖励(正面或负面),代理的目标是找到一个能够随时间最大化奖励的策略。
例如,MDP 在图 18-8 中表示有三个状态(由圆圈表示),并且在每一步最多有三种可能的离散动作(由菱形表示)。
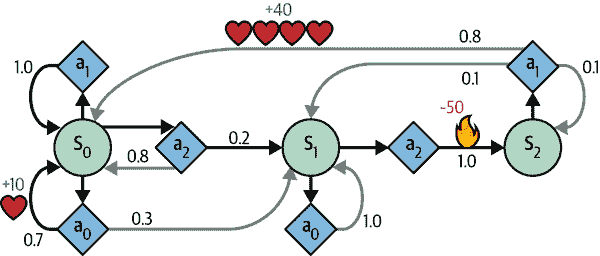
图 18-8. 马尔可夫决策过程示例
如果代理从状态 s[0] 开始,可以在行动 a[0]、a[1] 或 a[2] 之间选择。如果选择行动 a[1],它就会肯定留在状态 s[0],没有任何奖励。因此,如果愿意,它可以决定永远留在那里。但如果选择行动 a[0],它有 70%的概率获得+10 的奖励并留在状态 s[0]。然后它可以一次又一次地尝试获得尽可能多的奖励,但最终会进入状态 s[1]。在状态 s[1] 中,它只有两种可能的行动:a[0] 或 a[2]。它可以通过反复选择行动 a[0] 来保持原地,或者选择移动到状态 s[2] 并获得-50 的负奖励(疼)。在状态 s[2] 中,它别无选择,只能采取行动 a[1],这很可能会将其带回状态 s[0],在途中获得+40 的奖励。你明白了。通过观察这个 MDP,你能猜出哪种策略会随着时间获得最多的奖励吗?在状态 s[0] 中,很明显行动 a[0] 是最佳选择,在状态 s[2] 中,代理别无选择,只能采取行动 a[1],但在状态 s[1] 中,不明显代理应该保持原地(a[0])还是冒险前进(a[2])。
贝尔曼找到了一种估计任何状态 s 的最优状态值 V(s) 的方法,这是代理在到达该状态后可以期望的所有折扣未来奖励的总和,假设它采取最优行动。他表明,如果代理采取最优行动,那么贝尔曼最优性方程适用(参见方程 18-1)。这个递归方程表明,如果代理采取最优行动,那么当前状态的最优值等于在采取一个最优行动后平均获得的奖励,再加上这个行动可能导致的所有可能下一个状态的期望最优值。
方程 18-1. 贝尔曼最优性方程
V ( s ) = max a ∑ s‘ T ( s , a , s’ ) [ R ( s , a , s' ) + γ · V ( s' ) ] for all s
在这个方程中:
-
T(s, a, s′) 是从状态 s 转移到状态 s′ 的转移概率,假设代理选择行动 a。例如,在图 18-8 中,T(s[2], a[1], s[0]) = 0.8。
-
R(s, a, s′) 是代理从状态 s 转移到状态 s′ 时获得的奖励,假设代理选择行动 a。例如,在图 18-8 中,R(s[2], a[1], s[0]) = +40。
-
γ 是折扣因子。
这个方程直接导致了一个算法,可以精确估计每个可能状态的最优状态值:首先将所有状态值估计初始化为零,然后使用值迭代算法进行迭代更新(参见方程 18-2)。一个显著的结果是,给定足够的时间,这些估计将收敛到最优状态值,对应于最优策略。
方程 18-2. 值迭代算法
V k+1 ( s ) ← max a ∑ s‘ T ( s , a , s’ ) [ R ( s , a , s‘ ) + γ · V k ( s’ ) ] for all s
在这个方程中,V**k是算法的第k次迭代中状态s的估计值。
注意
这个算法是动态规划的一个例子,它将一个复杂的问题分解成可迭代处理的可解子问题。
知道最优状态值可能很有用,特别是用于评估策略,但它并不能为代理提供最优策略。幸运的是,贝尔曼找到了一个非常相似的算法来估计最优状态-动作值,通常称为Q 值(质量值)。状态-动作对(s, a)的最优 Q 值,记为Q**(s, a),是代理在到达状态s并选择动作a*后,在看到此动作结果之前,可以期望平均获得的折现未来奖励的总和,假设在此动作之后它表现最佳。
让我们看看它是如何工作的。再次,您首先将所有 Q 值的估计初始化为零,然后使用Q 值迭代算法进行更新(参见方程 18-3)。
方程 18-3。Q 值迭代算法
Q k+1 ( s , a ) ← ∑ s‘ T ( s , a , s’ ) [ R ( s , a , s‘ ) + γ · max a’ Q k ( s‘ , a’ ) ] for all ( s , a )
一旦您有了最优的 Q 值,定义最优策略π**(s)是微不足道的;当代理处于状态s时,它应该选择具有该状态最高 Q 值的动作:π(s)=argmaxaQ*(s,a)。
让我们将这个算法应用到图 18-8 中表示的 MDP 中。首先,我们需要定义 MDP:
transition_probabilities = [ # shape=[s, a, s'][[0.7, 0.3, 0.0], [1.0, 0.0, 0.0], [0.8, 0.2, 0.0]],[[0.0, 1.0, 0.0], None, [0.0, 0.0, 1.0]],[None, [0.8, 0.1, 0.1], None]
]
rewards = [ # shape=[s, a, s'][[+10, 0, 0], [0, 0, 0], [0, 0, 0]],[[0, 0, 0], [0, 0, 0], [0, 0, -50]],[[0, 0, 0], [+40, 0, 0], [0, 0, 0]]
]
possible_actions = [[0, 1, 2], [0, 2], [1]]
例如,要知道在执行动作a[1]后从s[2]到s[0]的转移概率,我们将查找transition_probabilities[2][1][0](为 0.8)。类似地,要获得相应的奖励,我们将查找rewards[2][1][0](为+40)。要获取s[2]中可能的动作列表,我们将查找possible_actions[2](在这种情况下,只有动作a[1]是可能的)。接下来,我们必须将所有 Q 值初始化为零(对于不可能的动作,我们将 Q 值设置为-∞):
Q_values = np.full((3, 3), -np.inf) # -np.inf for impossible actions
for state, actions in enumerate(possible_actions):Q_values[state, actions] = 0.0 # for all possible actions
现在让我们运行 Q 值迭代算法。它重复应用方程 18-3,对每个状态和每个可能的动作的所有 Q 值进行计算:
gamma = 0.90 # the discount factorfor iteration in range(50):Q_prev = Q_values.copy()for s in range(3):for a in possible_actions[s]:Q_values[s, a] = np.sum([transition_probabilities[s][a][sp]* (rewards[s][a][sp] + gamma * Q_prev[sp].max())for sp in range(3)])
就是这样!得到的 Q 值看起来像这样:
>>> Q_values
array([[18.91891892, 17.02702702, 13.62162162],[ 0\. , -inf, -4.87971488],[ -inf, 50.13365013, -inf]])
例如,当代理处于状态s[0]并选择动作a[1]时,预期的折现未来奖励总和约为 17.0。
对于每个状态,我们可以找到具有最高 Q 值的动作:
>>> Q_values.argmax(axis=1) # optimal action for each state
array([0, 0, 1])
这给出了在使用折扣因子为 0.90 时这个 MDP 的最优策略:在状态s[0]选择动作a[0],在状态s[1]选择动作a[0](即保持不动),在状态s[2]选择动作a[1](唯一可能的动作)。有趣的是,如果将折扣因子增加到 0.95,最优策略会改变:在状态s[1]中,最佳动作变为a[2](冲过火!)。这是有道理的,因为你越重视未来的奖励,你就越愿意忍受现在的一些痛苦,以换取未来的幸福。
时间差异学习
具有离散动作的强化学习问题通常可以建模为马尔可夫决策过程,但代理最初不知道转移概率是多少(它不知道T(s, a, s′)),也不知道奖励将会是什么(它不知道R(s, a, s′))。它必须至少体验每个状态和每个转换一次才能知道奖励,如果要对转移概率有合理的估计,它必须多次体验它们。
时间差异(TD)学习算法与 Q 值迭代算法非常相似,但经过调整以考虑代理只有对 MDP 的部分知识这一事实。通常我们假设代理最初只知道可能的状态和动作,什么也不知道。代理使用一个探索策略——例如,一个纯随机策略——来探索 MDP,随着探索的进行,TD 学习算法根据实际观察到的转换和奖励更新状态值的估计(参见方程 18-4)。
方程 18-4. TD 学习算法
V k+1 (s)←(1-α) Vk (s)+α r+γ· Vk (s‘) 或者,等价地: Vk+1 (s)←Vk (s)+α· δk (s,r, s’) 其中δk (s,r,s′ )=r+γ · Vk (s')- Vk(s)
在这个方程中:
-
α是学习率(例如,0.01)。
-
r + γ · V**k被称为TD 目标。
-
δk 被称为TD 误差。
写出这个方程的第一种形式的更简洁方法是使用符号a←αb,意思是a[k+1] ← (1 - α) · a[k] + α ·b[k]。因此,方程 18-4 的第一行可以重写为:V(s)←αr+γ·V(s')。
提示
TD 学习与随机梯度下降有许多相似之处,包括一次处理一个样本。此外,就像 SGD 一样,只有逐渐降低学习率,它才能真正收敛;否则,它将继续在最优 Q 值周围反弹。
对于每个状态s,该算法跟踪代理离开该状态后获得的即时奖励的平均值,以及它期望获得的奖励,假设它采取最优行动。
Q-Learning
同样,Q-learning 算法是 Q 值迭代算法在转移概率和奖励最初未知的情况下的一种适应。Q-learning 通过观察代理玩(例如,随机玩)并逐渐改进其对 Q 值的估计来工作。一旦它有准确的 Q 值估计(或足够接近),那么最优策略就是选择具有最高 Q 值的动作(即,贪婪策略)。
方程 18-5. Q-learning 算法
Q(s,a) ←α r+γ· maxa‘ Q(s’, a')
对于每个状态-动作对(s,a),该算法跟踪代理离开状态s并采取动作a后获得的奖励r的平均值,以及它期望获得的折现未来奖励的总和。为了估计这个总和,我们取下一个状态s′的 Q 值估计的最大值,因为我们假设目标策略将从那时开始最优地行动。
让我们实现 Q-learning 算法。首先,我们需要让代理探索环境。为此,我们需要一个步骤函数,以便代理可以执行一个动作并获得结果状态和奖励:
def step(state, action):probas = transition_probabilities[state][action]next_state = np.random.choice([0, 1, 2], p=probas)reward = rewards[state][action][next_state]return next_state, reward
现在让我们实现代理的探索策略。由于状态空间相当小,一个简单的随机策略就足够了。如果我们运行足够长的时间,代理将多次访问每个状态,并且还将多次尝试每种可能的动作:
def exploration_policy(state):return np.random.choice(possible_actions[state])
接下来,在我们像之前一样初始化 Q 值之后,我们准备使用学习率衰减的 Q-learning 算法运行(使用幂调度,引入于第十一章):
alpha0 = 0.05 # initial learning rate
decay = 0.005 # learning rate decay
gamma = 0.90 # discount factor
state = 0 # initial statefor iteration in range(10_000):action = exploration_policy(state)next_state, reward = step(state, action)next_value = Q_values[next_state].max() # greedy policy at the next stepalpha = alpha0 / (1 + iteration * decay)Q_values[state, action] *= 1 - alphaQ_values[state, action] += alpha * (reward + gamma * next_value)state = next_state
这个算法将收敛到最优的 Q 值,但需要很多迭代,可能需要相当多的超参数调整。正如您在图 18-9 中看到的那样,Q 值迭代算法(左侧)收敛得非常快,在不到 20 次迭代中,而 Q-learning 算法(右侧)需要大约 8000 次迭代才能收敛。显然,不知道转移概率或奖励使得找到最优策略变得更加困难!
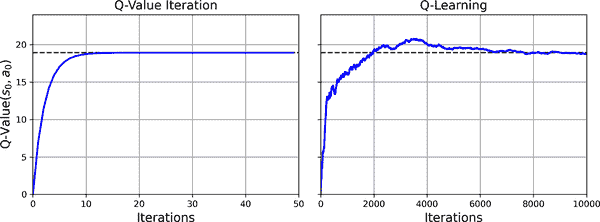
图 18-9. Q 值迭代算法与 Q-learning 算法的学习曲线
Q-learning 算法被称为离策略算法,因为正在训练的策略不一定是训练过程中使用的策略。例如,在我们刚刚运行的代码中,执行的策略(探索策略)是完全随机的,而正在训练的策略从未被使用过。训练后,最优策略对应于系统地选择具有最高 Q 值的动作。相反,策略梯度算法是在策略算法:它使用正在训练的策略探索世界。令人惊讶的是,Q-learning 能够通过观察代理随机行动来学习最优策略。想象一下,在一只被蒙住眼睛的猴子是你的老师时学习打高尔夫球。我们能做得更好吗?
探索策略
当然,只有当探索策略足够彻底地探索 MDP 时,Q 学习才能起作用。尽管纯随机策略保证最终会访问每个状态和每个转换多次,但这可能需要非常长的时间。因此,更好的选择是使用ε-贪心策略(ε是 epsilon):在每一步中,它以概率ε随机行动,或以概率 1-ε贪婪地行动(即选择具有最高 Q 值的动作)。ε-贪心策略的优势(与完全随机策略相比)在于,随着 Q 值估计变得越来越好,它将花费越来越多的时间探索环境的有趣部分,同时仍然花费一些时间访问 MDP 的未知区域。通常会从较高的ε值(例如 1.0)开始,然后逐渐降低它(例如降至 0.05)。
另一种方法是鼓励探索策略尝试之前尝试过的动作,而不仅仅依赖于机会。这可以作为添加到 Q 值估计中的奖励来实现,如方程 18-6 所示。
方程 18-6. 使用探索函数的 Q 学习
Q(s,a) ←α r+γ·max a‘ f Q(s’,a‘ ),N(s’, a')
在这个方程中:
-
N(s′, a′)计算动作a′在状态s′中被选择的次数。
-
f(Q, N)是一个探索函数,例如f(Q, N) = Q + κ/(1 + N),其中κ是一个好奇心超参数,衡量了代理对未知的吸引力。
近似 Q 学习和深度 Q 学习
Q 学习的主要问题是它在具有许多状态和动作的大型(甚至中等大小)MDP 中无法很好地扩展。例如,假设您想使用 Q 学习来训练一个代理玩《Ms. Pac-Man》(见图 18-1)。Ms. Pac-Man 可以吃约 150 个豆子,每个豆子可以存在或不存在(即已经被吃掉)。因此,可能的状态数量大于 2¹⁵⁰ ≈ 10⁴⁵。如果您考虑所有鬼和 Ms. Pac-Man 的所有可能位置组合,可能的状态数量将大于地球上的原子数量,因此绝对无法跟踪每个单个 Q 值的估计。
解决方案是找到一个函数Qθ,它用可管理数量的参数(由参数向量θ给出)来近似任何状态-动作对(s, a)的 Q 值。这被称为近似 Q 学习。多年来,人们建议使用从状态中提取的手工制作的特征的线性组合(例如,最近的鬼的距离、它们的方向等)来估计 Q 值,但在 2013 年,DeepMind表明使用深度神经网络可以工作得更好,特别是对于复杂问题,而且不需要任何特征工程。用于估计 Q 值的 DNN 称为深度 Q 网络(DQN),并且使用 DQN 进行近似 Q 学习称为深度 Q 学习。
现在,我们如何训练一个 DQN 呢?考虑 DQN 计算给定状态-动作对(s, a)的近似 Q 值。由于贝尔曼,我们知道我们希望这个近似 Q 值尽可能接近我们在状态s中执行动作a后实际观察到的奖励r,加上从那时开始最优地玩的折现值。为了估计未来折现奖励的总和,我们只需在下一个状态s′上执行 DQN,对所有可能的动作a′。我们得到每个可能动作的近似未来 Q 值。然后我们选择最高的(因为我们假设我们将最优地玩),并对其进行折现,这给我们一个未来折现奖励总和的估计。通过将奖励r和未来折现值估计相加,我们得到状态-动作对(s, a)的目标 Q 值y(s, a),如方程 18-7 所示。
方程 18-7. 目标 Q 值
y(s,a)=r+γ·maxa‘Qθ(s’,a')
有了这个目标 Q 值,我们可以使用任何梯度下降算法运行一个训练步骤。具体来说,我们通常试图最小化估计的 Q 值Qθ和目标 Q 值y(s, a)之间的平方误差,或者使用 Huber 损失来减少算法对大误差的敏感性。这就是深度 Q 学习算法!让我们看看如何实现它来解决 CartPole 环境。
实施深度 Q 学习
我们需要的第一件事是一个深度 Q 网络。理论上,我们需要一个神经网络,将状态-动作对作为输入,并输出一个近似 Q 值。然而,在实践中,使用一个只接受状态作为输入,并为每个可能动作输出一个近似 Q 值的神经网络要高效得多。为了解决 CartPole 环境,我们不需要一个非常复杂的神经网络;几个隐藏层就足够了:
input_shape = [4] # == env.observation_space.shape
n_outputs = 2 # == env.action_space.nmodel = tf.keras.Sequential([tf.keras.layers.Dense(32, activation="elu", input_shape=input_shape),tf.keras.layers.Dense(32, activation="elu"),tf.keras.layers.Dense(n_outputs)
])
使用这个 DQN 选择动作时,我们选择预测 Q 值最大的动作。为了确保代理程序探索环境,我们将使用ε-贪婪策略(即,我们将以概率ε选择一个随机动作):
def epsilon_greedy_policy(state, epsilon=0):if np.random.rand() < epsilon:return np.random.randint(n_outputs) # random actionelse:Q_values = model.predict(state[np.newaxis], verbose=0)[0]return Q_values.argmax() # optimal action according to the DQN
我们将不再仅基于最新经验训练 DQN,而是将所有经验存储在一个重放缓冲区(或重放内存)中,并在每次训练迭代中从中随机抽取一个训练批次。这有助于减少训练批次中经验之间的相关性,从而极大地帮助训练。为此,我们将使用一个双端队列(deque):
from collections import dequereplay_buffer = deque(maxlen=2000)
提示
deque是一个队列,可以高效地在两端添加或删除元素。从队列的两端插入和删除项目非常快,但当队列变长时,随机访问可能会很慢。如果您需要一个非常大的重放缓冲区,您应该使用循环缓冲区(请参阅笔记本中的实现),或查看DeepMind 的 Reverb 库。
每个体验将由六个元素组成:一个状态s,代理程序执行的动作a,产生的奖励r,它达到的下一个状态s′,一个指示该点是否结束的布尔值(done),最后一个指示该点是否截断的布尔值。我们将需要一个小函数从重放缓冲区中随机抽取一批体验。它将返回六个对应于六个体验元素的 NumPy 数组:
def sample_experiences(batch_size):indices = np.random.randint(len(replay_buffer), size=batch_size)batch = [replay_buffer[index] for index in indices]return [np.array([experience[field_index] for experience in batch])for field_index in range(6)] # [states, actions, rewards, next_states, dones, truncateds]
让我们还创建一个函数,该函数将使用ε-贪婪策略执行一个单步操作,然后将结果体验存储在重放缓冲区中:
def play_one_step(env, state, epsilon):action = epsilon_greedy_policy(state, epsilon)next_state, reward, done, truncated, info = env.step(action)replay_buffer.append((state, action, reward, next_state, done, truncated))return next_state, reward, done, truncated, info
最后,让我们创建一个最后一个函数,该函数将从重放缓冲区中抽取一批体验,并通过在该批次上执行单个梯度下降步骤来训练 DQN:
batch_size = 32
discount_factor = 0.95
optimizer = tf.keras.optimizers.Nadam(learning_rate=1e-2)
loss_fn = tf.keras.losses.mean_squared_errordef training_step(batch_size):experiences = sample_experiences(batch_size)states, actions, rewards, next_states, dones, truncateds = experiencesnext_Q_values = model.predict(next_states, verbose=0)max_next_Q_values = next_Q_values.max(axis=1)runs = 1.0 - (dones | truncateds) # episode is not done or truncatedtarget_Q_values = rewards + runs * discount_factor * max_next_Q_valuestarget_Q_values = target_Q_values.reshape(-1, 1)mask = tf.one_hot(actions, n_outputs)with tf.GradientTape() as tape:all_Q_values = model(states)Q_values = tf.reduce_sum(all_Q_values * mask, axis=1, keepdims=True)loss = tf.reduce_mean(loss_fn(target_Q_values, Q_values))grads = tape.gradient(loss, model.trainable_variables)optimizer.apply_gradients(zip(grads, model.trainable_variables))
这段代码中发生了什么:
-
首先我们定义一些超参数,然后创建优化器和损失函数。
-
然后我们创建
training_step()函数。它首先对经验进行批量采样,然后使用 DQN 来预测每个经验的下一个状态中每个可能动作的 Q 值。由于我们假设代理将会最优地进行游戏,我们只保留每个下一个状态的最大 Q 值。接下来,我们使用 Equation 18-7 来计算每个经验的状态-动作对的目标 Q 值。 -
我们希望使用 DQN 来计算每个经验状态-动作对的 Q 值,但是 DQN 还会输出其他可能动作的 Q 值,而不仅仅是代理实际选择的动作。因此,我们需要屏蔽掉所有我们不需要的 Q 值。
tf.one_hot()函数使得将动作索引数组转换为这样的屏蔽变得可能。例如,如果前三个经验包含动作 1、1、0,那么屏蔽将以[[0, 1], [0, 1], [1, 0], ...]开始。然后我们可以将 DQN 的输出与这个屏蔽相乘,这将将我们不想要的所有 Q 值置零。然后我们沿着轴 1 求和,去除所有零,只保留经验状态-动作对的 Q 值。这给我们了Q_values张量,包含批量中每个经验的一个预测 Q 值。 -
接下来,我们计算损失:它是经验状态-动作对的目标和预测 Q 值之间的均方误差。
-
最后,我们执行梯度下降步骤,以最小化损失与模型可训练变量的关系。
这是最困难的部分。现在训练模型就很简单了:
for episode in range(600):obs, info = env.reset()for step in range(200):epsilon = max(1 - episode / 500, 0.01)obs, reward, done, truncated, info = play_one_step(env, obs, epsilon)if done or truncated:breakif episode > 50:training_step(batch_size)
我们运行 600 个 episode,每个最多 200 步。在每一步中,我们首先计算ε-贪婪策略的epsilon值:它将从 1 线性下降到 0.01,在不到 500 个 episode 内。然后我们调用play_one_step()函数,该函数将使用ε-贪婪策略选择一个动作,然后执行它并记录经验到重放缓冲区。如果 episode 结束或被截断,我们退出循环。最后,如果我们超过第 50 个 episode,我们调用training_step()函数从重放缓冲区中采样一个批次来训练模型。我们之所以在没有训练的情况下运行多个 episode,是为了给重放缓冲区一些时间来填充(如果我们不等待足够长的时间,那么重放缓冲区中将没有足够的多样性)。就是这样:我们刚刚实现了深度 Q 学习算法!
Figure 18-10 显示了代理在每个 episode 中获得的总奖励。
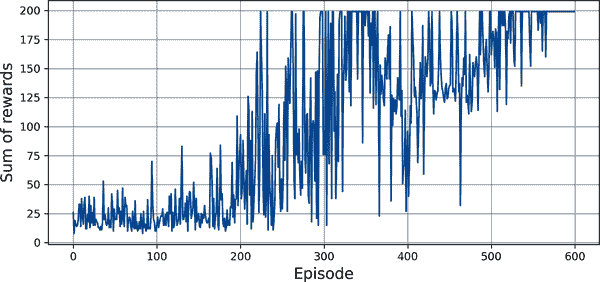
图 18-10. 深度 Q 学习算法的学习曲线
正如你所看到的,该算法花了一段时间才开始学习任何东西,部分原因是ε在开始时非常高。然后它的进展是不稳定的:它首先在第 220 集左右达到了最大奖励,但立即下降,然后上下几次反弹,不久后看起来它终于稳定在最大奖励附近,大约在第 320 集左右,它的得分再次急剧下降。这被称为灾难性遗忘,这是几乎所有 RL 算法面临的一个大问题之一:当代理探索环境时,它更新其策略,但它在环境的一个部分学到的东西可能会破坏它在环境的其他部分早期学到的东西。经验是相当相关的,学习环境不断变化——这对于梯度下降来说并不理想!如果增加回放缓冲区的大小,算法将不太容易受到这个问题的影响。调整学习率也可能有所帮助。但事实是,强化学习很难:训练通常不稳定,您可能需要尝试许多超参数值和随机种子,才能找到一个表现良好的组合。例如,如果您尝试将激活函数从"elu"更改为"relu",性能将大大降低。
注意
强化学习因训练不稳定性和对超参数值和随机种子选择的极度敏感性而臭名昭著。正如研究人员 Andrej Karpathy 所说,“[监督学习]想要工作。[…]强化学习必须被迫工作”。您需要时间、耐心、毅力,也许还需要一点运气。这是 RL 不像常规深度学习(例如,卷积网络)那样被广泛采用的一个主要原因。但除了 AlphaGo 和 Atari 游戏之外,还有一些真实世界的应用:例如,谷歌使用 RL 来优化其数据中心成本,并且它被用于一些机器人应用、超参数调整和推荐系统中。
你可能会想为什么我们没有绘制损失。事实证明,损失是模型性能的一个很差的指标。损失可能会下降,但代理可能表现更差(例如,当代理陷入环境的一个小区域时,DQN 开始过度拟合这个区域时可能会发生这种情况)。相反,损失可能会上升,但代理可能表现更好(例如,如果 DQN 低估了 Q 值并开始正确增加其预测,代理可能表现更好,获得更多奖励,但损失可能会增加,因为 DQN 还设置了目标,这也会更大)。因此,最好绘制奖励。
到目前为止,我们一直在使用的基本深度 Q 学习算法对于学习玩 Atari 游戏来说太不稳定了。那么 DeepMind 是如何做到的呢?嗯,他们调整了算法!
深度 Q 学习变体
让我们看看一些可以稳定和加速训练的深度 Q 学习算法的变体。
固定 Q 值目标
在基本的深度 Q 学习算法中,模型既用于进行预测,也用于设置自己的目标。这可能导致类似于狗追逐自己尾巴的情况。这种反馈循环可能使网络不稳定:它可能发散、振荡、冻结等。为了解决这个问题,在他们 2013 年的论文中,DeepMind 的研究人员使用了两个 DQN 而不是一个:第一个是在线模型,它在每一步学习并用于移动代理,另一个是目标模型,仅用于定义目标。目标模型只是在线模型的一个克隆:
target = tf.keras.models.clone_model(model) # clone the model's architecture
target.set_weights(model.get_weights()) # copy the weights
然后,在training_step()函数中,我们只需要更改一行,使用目标模型而不是在线模型来计算下一个状态的 Q 值:
next_Q_values = target.predict(next_states, verbose=0)
最后,在训练循环中,我们必须定期将在线模型的权重复制到目标模型中(例如,每 50 个 episode):
if episode % 50 == 0:target.set_weights(model.get_weights())
由于目标模型更新的频率远低于在线模型,Q 值目标更加稳定,我们之前讨论的反馈循环被减弱,其影响也变得不那么严重。这种方法是 DeepMind 研究人员在 2013 年的一篇论文中的主要贡献之一,使代理能够从原始像素学习玩 Atari 游戏。为了稳定训练,他们使用了非常小的学习率 0.00025,他们每 10000 步才更新一次目标模型(而不是 50 步),并且他们使用了一个非常大的重放缓冲区,包含 100 万个经验。他们非常缓慢地减小了epsilon,在 100 万步内从 1 减小到 0.1,并让算法运行了 5000 万步。此外,他们的 DQN 是一个深度卷积网络。
现在让我们来看看另一个 DQN 变体,它再次超越了现有技术水平。
双重 DQN
在一篇 2015 年的论文中,DeepMind 研究人员调整了他们的 DQN 算法,提高了性能并在一定程度上稳定了训练。他们将这个变体称为双重 DQN。更新基于这样一个观察:目标网络容易高估 Q 值。实际上,假设所有动作都是同样好的:目标模型估计的 Q 值应该是相同的,但由于它们是近似值,一些可能略大于其他值,纯粹是偶然的。目标模型将始终选择最大的 Q 值,这个值将略大于平均 Q 值,很可能高估真实的 Q 值(有点像在测量池的深度时计算最高随机波浪的高度)。为了解决这个问题,研究人员建议在选择下一个状态的最佳动作时使用在线模型而不是目标模型,并且仅使用目标模型来估计这些最佳动作的 Q 值。以下是更新后的training_step()函数:
def training_step(batch_size):experiences = sample_experiences(batch_size)states, actions, rewards, next_states, dones, truncateds = experiencesnext_Q_values = model.predict(next_states, verbose=0) # ≠ target.predict()best_next_actions = next_Q_values.argmax(axis=1)next_mask = tf.one_hot(best_next_actions, n_outputs).numpy()max_next_Q_values = (target.predict(next_states, verbose=0) * next_mask).sum(axis=1)[...] # the rest is the same as earlier
仅仅几个月后,DQN 算法的另一个改进被提出;我们接下来将看看这个改进。
优先经验回放
与从重放缓冲区中均匀采样经验不同,为什么不更频繁地采样重要经验呢?这个想法被称为重要性采样(IS)或优先经验回放(PER),并且是由 DeepMind 研究人员在 2015 年的一篇论文中介绍的(再次!)。
更具体地说,如果经验很可能导致快速学习进展,那么这些经验被认为是“重要的”。但是我们如何估计这一点呢?一个合理的方法是测量 TD 误差的大小δ = r + γ·V(s′) – V(s)。较大的 TD 误差表明一个转换(s, a, s′)非常令人惊讶,因此可能值得学习。当一个经验被记录在重放缓冲区中时,其优先级被设置为一个非常大的值,以确保至少被采样一次。然而,一旦被采样(并且每次被采样时),TD 误差δ被计算,并且这个经验的优先级被设置为p = |δ|(再加上一个小常数,以确保每个经验有非零的采样概率)。具有优先级p的经验被采样的概率P与p^(ζ)成正比,其中ζ是一个控制我们希望重要性采样有多贪婪的超参数:当ζ = 0 时,我们只得到均匀采样,当ζ = 1 时,我们得到完全的重要性采样。在论文中,作者使用了ζ = 0.6,但最佳值将取决于任务。
然而,有一个问题:由于样本将偏向于重要经验,我们必须在训练过程中通过根据其重要性降低经验的权重来补偿这种偏差,否则模型将只是过度拟合重要经验。明确地说,我们希望重要经验被更频繁地抽样,但这也意味着我们必须在训练过程中给它们更低的权重。为了做到这一点,我们将每个经验的训练权重定义为w = (n P)^(–β),其中n是回放缓冲区中的经验数量,β是一个超参数,控制我们想要补偿重要性抽样偏差的程度(0 表示根本不补偿,而 1 表示完全补偿)。在论文中,作者在训练开始时使用β = 0.4,并在训练结束时线性增加到β = 1。再次强调,最佳值将取决于任务,但如果你增加一个值,通常也会想要增加另一个值。
现在让我们看一下 DQN 算法的最后一个重要变体。
决斗 DQN
决斗 DQN算法(DDQN,不要与双重 DQN 混淆,尽管这两种技术可以很容易地结合在一起)是由 DeepMind 研究人员在另一篇2015 年的论文中介绍的。要理解它的工作原理,我们首先必须注意到一个状态-动作对(s, a)的 Q 值可以表示为Q(s, a) = V(s) + A(s, a),其中V(s)是状态s的值,A(s, a)是在状态s中采取动作a的优势,与该状态下所有其他可能的动作相比。此外,一个状态的值等于该状态的最佳动作a^的 Q 值(因为我们假设最优策略将选择最佳动作),所以V*(s) = Q(s, a^),这意味着A*(s, a^*) = 0。在决斗 DQN 中,模型估计了状态的值和每个可能动作的优势。由于最佳动作应该具有优势为 0,模型从所有预测的优势中减去了最大预测的优势。这里是一个使用功能 API 实现的简单 DDQN 模型:
input_states = tf.keras.layers.Input(shape=[4])
hidden1 = tf.keras.layers.Dense(32, activation="elu")(input_states)
hidden2 = tf.keras.layers.Dense(32, activation="elu")(hidden1)
state_values = tf.keras.layers.Dense(1)(hidden2)
raw_advantages = tf.keras.layers.Dense(n_outputs)(hidden2)
advantages = raw_advantages - tf.reduce_max(raw_advantages, axis=1,keepdims=True)
Q_values = state_values + advantages
model = tf.keras.Model(inputs=[input_states], outputs=[Q_values])
算法的其余部分与之前完全相同。事实上,你可以构建一个双重决斗 DQN 并将其与优先经验重放结合起来!更一般地说,许多 RL 技术可以结合在一起,正如 DeepMind 在一篇2017 年的论文中展示的:论文的作者将六种不同的技术结合到一个名为Rainbow的代理中,这在很大程度上超越了现有技术水平。
正如你所看到的,深度强化学习是一个快速发展的领域,还有很多东西等待探索!
一些流行 RL 算法的概述
在我们结束本章之前,让我们简要看一下其他几种流行的算法:
AlphaGo
AlphaGo 使用基于深度神经网络的蒙特卡洛树搜索(MCTS)的变体,在围棋比赛中击败人类冠军。MCTS 是由 Nicholas Metropolis 和 Stanislaw Ulam 于 1949 年发明的。它在运行许多模拟之后选择最佳移动,重复地探索从当前位置开始的搜索树,并在最有希望的分支上花费更多时间。当它到达一个以前未访问过的节点时,它会随机播放直到游戏结束,并更新每个访问过的节点的估计值(排除随机移动),根据最终结果增加或减少每个估计值。AlphaGo 基于相同的原则,但它使用策略网络来选择移动,而不是随机播放。这个策略网络是使用策略梯度进行训练的。原始算法涉及另外三个神经网络,并且更加复杂,但在AlphaGo Zero 论文中被简化,使用单个神经网络来选择移动和评估游戏状态。AlphaZero 论文推广了这个算法,使其能够处理不仅是围棋,还有国际象棋和将棋(日本象棋)。最后,MuZero 论文继续改进这个算法,即使代理开始时甚至不知道游戏规则,也能胜过以前的迭代!
Actor-critic 算法
Actor-critics 是一类将策略梯度与深度 Q 网络结合的 RL 算法。一个 actor-critic 代理包含两个神经网络:一个策略网络和一个 DQN。DQN 通过从代理的经验中学习来进行正常训练。策略网络学习方式不同(并且比常规 PG 快得多):代理不是通过多个情节估计每个动作的价值,然后为每个动作总结未来折现奖励,最后对其进行归一化,而是依赖于 DQN 估计的动作值(评论家)。这有点像运动员(代理)在教练(DQN)的帮助下学习。
异步优势 actor-critic(A3C)²³
这是 DeepMind 研究人员在 2016 年引入的一个重要的 actor-critic 变体,其中多个代理并行学习,探索环境的不同副本。定期但异步地(因此得名),每个代理将一些权重更新推送到主网络,然后从该网络中拉取最新的权重。因此,每个代理都有助于改进主网络,并从其他代理学到的知识中受益。此外,DQN 估计每个动作的优势,而不是估计 Q 值(因此名称中的第二个 A),这有助于稳定训练。
优势 actor-critic(A2C)
A2C 是 A3C 算法的一个变体,它去除了异步性。所有模型更新都是同步的,因此梯度更新是在更大的批次上执行的,这使模型能够更好地利用 GPU 的性能。
软 actor-critic(SAC)²⁴
SAC 是由 Tuomas Haarnoja 和其他加州大学伯克利分校研究人员于 2018 年提出的 actor-critic 变体。它不仅学习奖励,还要最大化其动作的熵。换句话说,它试图尽可能不可预测,同时尽可能获得更多奖励。这鼓励代理探索环境,加快训练速度,并使其在 DQN 产生不完美估计时不太可能重复执行相同的动作。这个算法展示了惊人的样本效率(与所有以前的算法相反,学习速度非常慢)。
近端策略优化(PPO)
这个由 John Schulman 和其他 OpenAI 研究人员开发的算法基于 A2C,但它剪切损失函数以避免过大的权重更新(这经常导致训练不稳定)。PPO 是前一个信任区域策略优化(TRPO)算法的简化版本,也是由 OpenAI 开发的。OpenAI 在 2019 年 4 月的新闻中以其基于 PPO 算法的 AI OpenAI Five 而闻名,该 AI 在多人游戏Dota 2中击败了世界冠军。
基于好奇心的探索
在强化学习中经常出现的问题是奖励的稀疏性,这使得学习变得非常缓慢和低效。加州大学伯克利分校的 Deepak Pathak 和其他研究人员提出了一种激动人心的方法来解决这个问题:为什么不忽略奖励,只是让代理人对探索环境感到极大的好奇心呢?奖励因此变得内在于代理人,而不是来自环境。同样,激发孩子的好奇心更有可能取得好的结果,而不仅仅是因为孩子取得好成绩而奖励他。这是如何运作的呢?代理人不断尝试预测其行动的结果,并寻找结果与其预测不符的情况。换句话说,它希望受到惊喜。如果结果是可预测的(无聊),它会去其他地方。然而,如果结果是不可预测的,但代理人注意到自己无法控制它,那么它也会在一段时间后感到无聊。只有好奇心,作者们成功地训练了一个代理人玩了很多视频游戏:即使代理人输掉了也没有惩罚,游戏重新开始,这很无聊,所以它学会了避免这种情况。
开放式学习(OEL)
OEL 的目标是训练代理人能够不断学习新颖有趣的任务,通常是通过程序生成的。我们还没有达到这一目标,但在过去几年中取得了一些惊人的进展。例如,Uber AI 团队在 2019 年发表的一篇论文介绍了POET 算法,该算法生成多个带有凸起和洞的模拟 2D 环境,并为每个环境训练一个代理人:代理人的目标是尽可能快地行走,同时避开障碍物。该算法从简单的环境开始,但随着时间的推移逐渐变得更加困难:这被称为课程学习。此外,尽管每个代理人只在一个环境中接受训练,但它必须定期与其他代理人竞争,跨所有环境。在每个环境中,获胜者被复制并取代之前的代理人。通过这种方式,知识定期在环境之间传递,并选择最具适应性的代理人。最终,这些代理人比单一任务训练的代理人更擅长行走,并且能够应对更加困难的环境。当然,这个原则也可以应用于其他环境和任务。如果您对 OEL 感兴趣,请务必查看增强 POET 论文,以及 DeepMind 在这个主题上的2021 年论文。
提示
如果您想了解更多关于强化学习的知识,请查看 Phil Winder(O’Reilly)的书籍强化学习。
本章涵盖了许多主题:策略梯度、马尔可夫链、马尔可夫决策过程、Q 学习、近似 Q 学习、深度 Q 学习及其主要变体(固定 Q 值目标、双重 DQN、对决 DQN 和优先经验重放),最后我们简要介绍了一些其他流行算法。强化学习是一个庞大且令人兴奋的领域,每天都会涌现出新的想法和算法,因此希望本章引发了您的好奇心:有一个整个世界等待您去探索!
练习
-
您如何定义强化学习?它与常规监督学习或无监督学习有何不同?
-
你能想到本章未提及的三种强化学习的可能应用吗?对于每一种,环境是什么?代理是什么?可能的行动有哪些?奖励是什么?
-
什么是折扣因子?如果修改折扣因子,最优策略会改变吗?
-
如何衡量强化学习代理的表现?
-
什么是信用分配问题?它何时发生?如何缓解它?
-
使用重放缓冲区的目的是什么?
-
什么是离策略强化学习算法?
-
使用策略梯度来解决 OpenAI Gym 的 LunarLander-v2 环境。
-
使用双重对决 DQN 训练一个代理,使其在著名的 Atari Breakout 游戏(
"ALE/Breakout-v5")中达到超人水平。观察结果是图像。为了简化任务,您应该将它们转换为灰度图像(即在通道轴上取平均),然后裁剪和降采样,使它们足够大以进行游戏,但不要过大。单个图像无法告诉您球和挡板的移动方向,因此您应该合并两到三个连续图像以形成每个状态。最后,DQN 应该主要由卷积层组成。 -
如果您有大约 100 美元可以花费,您可以购买一个树莓派 3 加上一些廉价的机器人组件,在树莓派上安装 TensorFlow,然后尽情玩耍!例如,可以查看 Lukas Biewald 的这篇 有趣的帖子,或者看看 GoPiGo 或 BrickPi。从简单的目标开始,比如让机器人转身找到最亮的角度(如果有光传感器)或最近的物体(如果有声纳传感器),然后朝着那个方向移动。然后您可以开始使用深度学习:例如,如果机器人有摄像头,可以尝试实现一个目标检测算法,使其检测到人并朝他们移动。您还可以尝试使用强化学习,让代理学习如何独立使用电机来实现这个目标。玩得开心!
这些练习的解答可在本章笔记本的末尾找到,网址为 https://homl.info/colab3。
(1)想了解更多细节,请务必查看 Richard Sutton 和 Andrew Barto 的关于强化学习的书籍 Reinforcement Learning: An Introduction(麻省理工学院出版社)。
(2)Volodymyr Mnih 等人,“使用深度强化学习玩 Atari 游戏”,arXiv 预印本 arXiv:1312.5602(2013)。
(3)Volodymyr Mnih 等人,“通过深度强化学习实现人类水平控制”,自然 518(2015):529–533。
(4)查看 DeepMind 系统学习 Space Invaders、Breakout 和其他视频游戏的视频,网址为 https://homl.info/dqn3。
(5)图像(a)、(d)和(e)属于公共领域。图像(b)是来自 Ms. Pac-Man 游戏的截图,由 Atari 版权所有(在本章中属于合理使用)。图像(c)是从维基百科复制的;由用户 Stevertigo 创建,并在 知识共享署名-相同方式共享 2.0 下发布。
(6)通常更好地给予表现不佳者一点生存的机会,以保留“基因池”中的一些多样性。
⁷ 如果只有一个父母,这被称为无性繁殖。有两个(或更多)父母时,这被称为有性繁殖。后代的基因组(在这种情况下是一组策略参数)是随机由其父母的基因组的部分组成的。
⁸ 用于强化学习的遗传算法的一个有趣例子是增强拓扑的神经进化(NEAT)算法。
⁹ 这被称为梯度上升。它就像梯度下降一样,但方向相反:最大化而不是最小化。
¹⁰ OpenAI 是一家人工智能研究公司,部分资金来自埃隆·马斯克。其宣称的目标是推广和发展有益于人类的友好人工智能(而不是消灭人类)。
¹¹ Ronald J. Williams,“用于连接主义强化学习的简单统计梯度跟随算法”,机器学习8(1992):229–256。
¹² Richard Bellman,“马尔可夫决策过程”,数学与力学杂志6,第 5 期(1957):679–684。
¹³ Alex Irpan 在 2018 年发表的一篇很棒的文章很好地阐述了强化学习的最大困难和局限性。
¹⁴ Hado van Hasselt 等人,“双 Q 学习的深度强化学习”,第 30 届 AAAI 人工智能大会论文集(2015):2094–2100。
¹⁵ Tom Schaul 等人,“优先经验重放”,arXiv 预印本 arXiv:1511.05952(2015)。
¹⁶ 也可能只是奖励有噪音,此时有更好的方法来估计经验的重要性(请参阅论文中的一些示例)。
¹⁷ Ziyu Wang 等人,“用于深度强化学习的对抗网络架构”,arXiv 预印本 arXiv:1511.06581(2015)。
¹⁸ Matteo Hessel 等人,“彩虹:深度强化学习改进的结合”,arXiv 预印本 arXiv:1710.02298(2017):3215–3222。
¹⁹ David Silver 等人,“用深度神经网络和树搜索掌握围棋”,自然529(2016):484–489。
²⁰ David Silver 等人,“在没有人类知识的情况下掌握围棋”,自然550(2017):354–359。
²¹ David Silver 等人,“通过自我对弈掌握国际象棋和将棋的一般强化学习算法”,arXiv 预印本 arXiv:1712.01815。
²² Julian Schrittwieser 等人,“通过学习模型计划掌握 Atari、围棋、国际象棋和将棋”,arXiv 预印本 arXiv:1911.08265(2019)。
²³ Volodymyr Mnih 等人,“深度强化学习的异步方法”,第 33 届国际机器学习会议论文集(2016):1928–1937。
²⁴ Tuomas Haarnoja 等人,“软演员-评论家:带有随机演员的离策略最大熵深度强化学习”,第 35 届国际机器学习会议论文集(2018):1856–1865。
²⁵ John Schulman 等人,“近端策略优化算法”,arXiv 预印本 arXiv:1707.06347(2017)。
²⁶ John Schulman 等人,“信任区域策略优化”,第 32 届国际机器学习会议论文集(2015):1889–1897。
²⁷ Deepak Pathak 等,“由自监督预测驱动的好奇心探索”,第 34 届国际机器学习会议论文集(2017):2778–2787。
²⁸ 王锐等,“配对开放式先驱者(POET):不断生成越来越复杂和多样化的学习环境及其解决方案”,arXiv 预印本 arXiv:1901.01753(2019)。
²⁹ 王锐等,“增强 POET:通过无限创造学习挑战及其解决方案的开放式强化学习”,arXiv 预印本 arXiv:2003.08536(2020)。
³⁰ Open-Ended Learning Team 等,“开放式学习导致普遍能力代理”,arXiv 预印本 arXiv:2107.12808(2021)。
第十九章:规模化训练和部署 TensorFlow 模型
一旦您拥有一个能够做出惊人预测的美丽模型,您会怎么处理呢?嗯,您需要将其投入生产!这可能只是在一批数据上运行模型,也许编写一个每晚运行该模型的脚本。然而,通常情况下会更加复杂。您的基础设施的各个部分可能需要在实时数据上使用该模型,这种情况下,您可能会希望将模型封装在一个 Web 服务中:这样,您的基础设施的任何部分都可以随时使用简单的 REST API(或其他协议)查询模型,正如我们在第二章中讨论的那样。但随着时间的推移,您需要定期使用新数据对模型进行重新训练,并将更新后的版本推送到生产环境。您必须处理模型版本控制,优雅地从一个模型过渡到另一个模型,可能在出现问题时回滚到上一个模型,并可能并行运行多个不同的模型来执行A/B 实验。如果您的产品变得成功,您的服务可能会开始每秒收到大量查询(QPS),并且必须扩展以支持负载。如您将在本章中看到的,一个很好的扩展服务的解决方案是使用 TF Serving,无论是在您自己的硬件基础设施上还是通过诸如 Google Vertex AI 之类的云服务。它将有效地为您提供模型服务,处理优雅的模型过渡等。如果您使用云平台,您还将获得许多额外功能,例如强大的监控工具。
此外,如果你有大量的训练数据和计算密集型模型,那么训练时间可能会变得过长。如果你的产品需要快速适应变化,那么长时间的训练可能会成为一个阻碍因素(例如,想象一下一个新闻推荐系统在推广上周的新闻)。更重要的是,长时间的训练会阻止你尝试新想法。在机器学习(以及许多其他领域),很难事先知道哪些想法会奏效,因此你应该尽可能快地尝试尽可能多的想法。加快训练的一种方法是使用硬件加速器,如 GPU 或 TPU。为了更快地训练,你可以在多台配备多个硬件加速器的机器上训练模型。TensorFlow 的简单而强大的分布策略 API 使这一切变得容易,你将会看到。
在这一章中,我们将学习如何部署模型,首先使用 TF Serving,然后使用 Vertex AI。我们还将简要介绍如何将模型部署到移动应用程序、嵌入式设备和 Web 应用程序。然后我们将讨论如何使用 GPU 加速计算,以及如何使用分布策略 API 在多个设备和服务器上训练模型。最后,我们将探讨如何使用 Vertex AI 规模化训练模型并微调其超参数。这是很多要讨论的话题,让我们开始吧!
为 TensorFlow 模型提供服务
一旦您训练了一个 TensorFlow 模型,您可以在任何 Python 代码中轻松地使用它:如果它是一个 Keras 模型,只需调用它的predict()方法!但随着基础设施的增长,会出现一个更好的选择,即将您的模型封装在一个小型服务中,其唯一作用是进行预测,并让基础设施的其余部分查询它(例如,通过 REST 或 gRPC API)。这样可以将您的模型与基础设施的其余部分解耦,从而可以轻松地切换模型版本或根据需要扩展服务(独立于您的基础设施的其余部分),执行 A/B 实验,并确保所有软件组件依赖于相同的模型版本。这也简化了测试和开发等工作。您可以使用任何您想要的技术(例如,使用 Flask 库)创建自己的微服务,但为什么要重新发明轮子,当您可以直接使用 TF Serving 呢?
使用 TensorFlow Serving
TF Serving 是一个非常高效、经过实战验证的模型服务器,用 C++编写。它可以承受高负载,为您的模型提供多个版本,并监视模型存储库以自动部署最新版本,等等(参见图 19-1)。
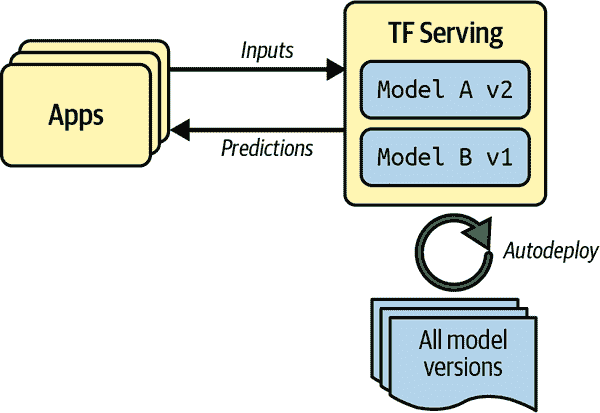
图 19-1。TF Serving 可以为多个模型提供服务,并自动部署每个模型的最新版本。
假设您已经使用 Keras 训练了一个 MNIST 模型,并且希望将其部署到 TF Serving。您需要做的第一件事是将此模型导出为 SavedModel 格式,该格式在第十章中介绍。
导出 SavedModels
您已经知道如何保存模型:只需调用model.save()。现在要对模型进行版本控制,您只需要为每个模型版本创建一个子目录。很简单!
from pathlib import Path
import tensorflow as tfX_train, X_valid, X_test = [...] # load and split the MNIST dataset
model = [...] # build & train an MNIST model (also handles image preprocessing)model_name = "my_mnist_model"
model_version = "0001"
model_path = Path(model_name) / model_version
model.save(model_path, save_format="tf")
通常最好将所有预处理层包含在最终导出的模型中,这样一旦部署到生产环境中,模型就可以以其自然形式摄取数据。这样可以避免在使用模型的应用程序中单独处理预处理工作。将预处理步骤捆绑在模型中也使得以后更新它们更加简单,并限制了模型与所需预处理步骤之间不匹配的风险。
警告
由于 SavedModel 保存了计算图,因此它只能用于基于纯粹的 TensorFlow 操作的模型,不包括tf.py_function()操作,该操作包装任意的 Python 代码。
TensorFlow 带有一个小的saved_model_cli命令行界面,用于检查 SavedModels。让我们使用它来检查我们导出的模型:
$ saved_model_cli show --dir my_mnist_model/0001
The given SavedModel contains the following tag-sets:
'serve'这个输出是什么意思?嗯,一个 SavedModel 包含一个或多个metagraphs。一个 metagraph 是一个计算图加上一些函数签名定义,包括它们的输入和输出名称、类型和形状。每个 metagraph 都由一组标签标识。例如,您可能希望有一个包含完整计算图的 metagraph,包括训练操作:您通常会将这个标记为"train"。您可能有另一个包含经过修剪的计算图的 metagraph,只包含预测操作,包括一些特定于 GPU 的操作:这个可能被标记为"serve", "gpu"。您可能还想要其他 metagraphs。这可以使用 TensorFlow 的低级SavedModel API来完成。然而,当您使用 Keras 模型的save()方法保存模型时,它会保存一个标记为"serve"的单个 metagraph。让我们检查一下这个"serve"标签集:
$ saved_model_cli show --dir 0001/my_mnist_model --tag_set serve
The given SavedModel MetaGraphDef contains SignatureDefs with these keys:
SignatureDef key: "__saved_model_init_op"
SignatureDef key: "serving_default"这个元图包含两个签名定义:一个名为"__saved_model_init_op"的初始化函数,您不需要担心,以及一个名为"serving_default"的默认服务函数。当保存一个 Keras 模型时,默认的服务函数是模型的call()方法,用于进行预测,这一点您已经知道了。让我们更详细地了解这个服务函数:
$ saved_model_cli show --dir 0001/my_mnist_model --tag_set serve \--signature_def serving_default
The given SavedModel SignatureDef contains the following input(s):inputs['flatten_input'] tensor_info:dtype: DT_UINT8shape: (-1, 28, 28)name: serving_default_flatten_input:0
The given SavedModel SignatureDef contains the following output(s):outputs['dense_1'] tensor_info:dtype: DT_FLOATshape: (-1, 10)name: StatefulPartitionedCall:0
Method name is: tensorflow/serving/predict请注意,函数的输入被命名为"flatten_input",输出被命名为"dense_1"。这些对应于 Keras 模型的输入和输出层名称。您还可以看到输入和输出数据的类型和形状。看起来不错!
现在您已经有了一个 SavedModel,下一步是安装 TF Serving。
安装和启动 TensorFlow Serving
有许多安装 TF Serving 的方法:使用系统的软件包管理器,使用 Docker 镜像,从源代码安装等。由于 Colab 运行在 Ubuntu 上,我们可以像这样使用 Ubuntu 的apt软件包管理器:
url = "https://storage.googleapis.com/tensorflow-serving-apt"
src = "stable tensorflow-model-server tensorflow-model-server-universal"
!echo 'deb {url} {src}' > /etc/apt/sources.list.d/tensorflow-serving.list
!curl '{url}/tensorflow-serving.release.pub.gpg' | apt-key add -
!apt update -q && apt-get install -y tensorflow-model-server
%pip install -q -U tensorflow-serving-api
这段代码首先将 TensorFlow 的软件包存储库添加到 Ubuntu 的软件包源列表中。然后它下载 TensorFlow 的公共 GPG 密钥,并将其添加到软件包管理器的密钥列表中,以便验证 TensorFlow 的软件包签名。接下来,它使用apt来安装tensorflow-model-server软件包。最后,它安装tensorflow-serving-api库,这是我们与服务器通信所需的库。
现在我们想要启动服务器。该命令将需要基本模型目录的绝对路径(即my_mnist_model的路径,而不是0001),所以让我们将其保存到MODEL_DIR环境变量中:
import osos.environ["MODEL_DIR"] = str(model_path.parent.absolute())
然后我们可以启动服务器:
%%bash --bg
tensorflow_model_server \--port=8500 \--rest_api_port=8501 \--model_name=my_mnist_model \--model_base_path="${MODEL_DIR}" >my_server.log 2>&1
在 Jupyter 或 Colab 中,%%bash --bg魔术命令将单元格作为 bash 脚本执行,在后台运行。>my_server.log 2>&1部分将标准输出和标准错误重定向到my_server.log文件。就是这样!TF Serving 现在在后台运行,其日志保存在my_server.log中。它加载了我们的 MNIST 模型(版本 1),现在正在分别等待 gRPC 和 REST 请求,端口分别为 8500 和 8501。
现在服务器已经启动运行,让我们首先使用 REST API,然后使用 gRPC API 进行查询。
通过 REST API 查询 TF Serving
让我们从创建查询开始。它必须包含您想要调用的函数签名的名称,当然还有输入数据。由于请求必须使用 JSON 格式,我们必须将输入图像从 NumPy 数组转换为 Python 列表:
import jsonX_new = X_test[:3] # pretend we have 3 new digit images to classify
request_json = json.dumps({"signature_name": "serving_default","instances": X_new.tolist(),
})
请注意,JSON 格式是 100%基于文本的。请求字符串如下所示:
>>> request_json
'{"signature_name": "serving_default", "instances": [[[0, 0, 0, 0, ... ]]]}'
现在让我们通过 HTTP POST 请求将这个请求发送到 TF Serving。这可以使用requests库来完成(它不是 Python 标准库的一部分,但在 Colab 上是预安装的):
import requestsserver_url = "http://localhost:8501/v1/models/my_mnist_model:predict"
response = requests.post(server_url, data=request_json)
response.raise_for_status() # raise an exception in case of error
response = response.json()
如果一切顺利,响应应该是一个包含单个"predictions"键的字典。相应的值是预测列表。这个列表是一个 Python 列表,所以让我们将其转换为 NumPy 数组,并将其中包含的浮点数四舍五入到第二位小数:
>>> import numpy as np
>>> y_proba = np.array(response["predictions"])
>>> y_proba.round(2)
array([[0\. , 0\. , 0\. , 0\. , 0\. , 0\. , 0\. , 1\. , 0\. , 0\. ],[0\. , 0\. , 0.99, 0.01, 0\. , 0\. , 0\. , 0\. , 0\. , 0\. ],[0\. , 0.97, 0.01, 0\. , 0\. , 0\. , 0\. , 0.01, 0\. , 0\. ]])
万岁,我们有了预测!模型几乎 100%确信第一张图片是 7,99%确信第二张图片是 2,97%确信第三张图片是 1。这是正确的。
REST API 简单易用,当输入和输出数据不太大时效果很好。此外,几乎任何客户端应用程序都可以在没有额外依赖的情况下进行 REST 查询,而其他协议并不总是那么容易获得。然而,它基于 JSON,这是基于文本且相当冗长的。例如,我们不得不将 NumPy 数组转换为 Python 列表,每个浮点数最终都表示为一个字符串。这非常低效,无论是在序列化/反序列化时间方面——我们必须将所有浮点数转换为字符串然后再转回来——还是在有效载荷大小方面:许多浮点数最终使用超过 15 个字符来表示,这相当于 32 位浮点数超过 120 位!这将导致在传输大型 NumPy 数组时出现高延迟和带宽使用。因此,让我们看看如何改用 gRPC。
提示
在传输大量数据或延迟重要时,最好使用 gRPC API,如果客户端支持的话,因为它使用紧凑的二进制格式和基于 HTTP/2 framing 的高效通信协议。
通过 gRPC API 查询 TF Serving
gRPC API 期望一个序列化的PredictRequest协议缓冲区作为输入,并输出一个序列化的PredictResponse协议缓冲区。这些 protobufs 是tensorflow-serving-api库的一部分,我们之前安装过。首先,让我们创建请求:
from tensorflow_serving.apis.predict_pb2 import PredictRequestrequest = PredictRequest()
request.model_spec.name = model_name
request.model_spec.signature_name = "serving_default"
input_name = model.input_names[0] # == "flatten_input"
request.inputs[input_name].CopyFrom(tf.make_tensor_proto(X_new))
这段代码创建了一个PredictRequest协议缓冲区,并填充了必需的字段,包括模型名称(之前定义的),我们想要调用的函数的签名名称,最后是输入数据,以Tensor协议缓冲区的形式。tf.make_tensor_proto()函数根据给定的张量或 NumPy 数组创建一个Tensor协议缓冲区,这里是X_new。
接下来,我们将向服务器发送请求并获取其响应。为此,我们将需要grpcio库,该库已预先安装在 Colab 中:
import grpc
from tensorflow_serving.apis import prediction_service_pb2_grpcchannel = grpc.insecure_channel('localhost:8500')
predict_service = prediction_service_pb2_grpc.PredictionServiceStub(channel)
response = predict_service.Predict(request, timeout=10.0)
代码非常简单:在导入之后,我们在 TCP 端口 8500 上创建一个到localhost的 gRPC 通信通道,然后我们在该通道上创建一个 gRPC 服务,并使用它发送一个带有 10 秒超时的请求。请注意,调用是同步的:它将阻塞,直到收到响应或超时期限到期。在此示例中,通道是不安全的(没有加密,没有身份验证),但 gRPC 和 TF Serving 也支持通过 SSL/TLS 的安全通道。
接下来,让我们将PredictResponse协议缓冲区转换为张量:
output_name = model.output_names[0] # == "dense_1"
outputs_proto = response.outputs[output_name]
y_proba = tf.make_ndarray(outputs_proto)
如果您运行此代码并打印y_proba.round(2),您将获得与之前完全相同的估计类概率。这就是全部内容:只需几行代码,您现在就可以远程访问您的 TensorFlow 模型,使用 REST 或 gRPC。
部署新的模型版本
现在让我们创建一个新的模型版本并导出一个 SavedModel,这次导出到my_mnist_model/0002目录:
model = [...] # build and train a new MNIST model versionmodel_version = "0002"
model_path = Path(model_name) / model_version
model.save(model_path, save_format="tf")
在固定的时间间隔(延迟可配置),TF Serving 会检查模型目录是否有新的模型版本。如果找到一个新版本,它会自动优雅地处理过渡:默认情况下,它会用前一个模型版本回答待处理的请求(如果有的话),同时用新版本处理新请求。一旦每个待处理的请求都得到回答,之前的模型版本就会被卸载。您可以在 TF Serving 日志(my_server.log)中看到这个过程:
[...]
Reading SavedModel from: /models/my_mnist_model/0002
Reading meta graph with tags { serve }
[...]
Successfully loaded servable version {name: my_mnist_model version: 2}
Quiescing servable version {name: my_mnist_model version: 1}
Done quiescing servable version {name: my_mnist_model version: 1}
Unloading servable version {name: my_mnist_model version: 1}提示
如果 SavedModel 包含assets/extra目录中的一些示例实例,您可以配置 TF Serving 在开始使用它来处理请求之前在这些实例上运行新模型。这称为模型预热:它将确保一切都被正确加载,避免第一次请求的长响应时间。
这种方法提供了平稳的过渡,但可能会使用过多的 RAM,特别是 GPU RAM,通常是最有限的。在这种情况下,您可以配置 TF Serving,使其处理所有挂起的请求与先前的模型版本,并在加载和使用新的模型版本之前卸载它。这种配置将避免同时加载两个模型版本,但服务将在短时间内不可用。
正如您所看到的,TF Serving 使部署新模型变得简单。此外,如果您发现第二个版本的效果不如预期,那么回滚到第一个版本就像删除my_mnist_model/0002目录一样简单。
提示
TF Serving 的另一个重要特性是其自动批处理能力,您可以在启动时使用--enable_batching选项来激活它。当 TF Serving 在短时间内接收到多个请求时(延迟可配置),它会在使用模型之前自动将它们批处理在一起。通过利用 GPU 的性能,这将显著提高性能。一旦模型返回预测结果,TF Serving 会将每个预测结果分发给正确的客户端。通过增加批处理延迟(参见--batching_parameters_file选项),您可以在一定程度上牺牲一点延迟以获得更大的吞吐量。
如果您希望每秒获得许多查询,您将希望在多台服务器上部署 TF Serving 并负载平衡查询(请参见图 19-2)。这将需要在这些服务器上部署和管理许多 TF Serving 容器。处理这一问题的一种方法是使用诸如Kubernetes之类的工具,它是一个简化跨多台服务器容器编排的开源系统。如果您不想购买、维护和升级所有硬件基础设施,您将希望在云平台上使用虚拟机,如 Amazon AWS、Microsoft Azure、Google Cloud Platform、IBM Cloud、Alibaba Cloud、Oracle Cloud 或其他平台即服务(PaaS)提供商。管理所有虚拟机,处理容器编排(即使借助 Kubernetes 的帮助),照顾 TF Serving 配置、调整和监控——所有这些都可能成为一项全职工作。幸运的是,一些服务提供商可以为您处理所有这些事务。在本章中,我们将使用 Vertex AI:它是今天唯一支持 TPUs 的平台;它支持 TensorFlow 2、Scikit-Learn 和 XGBoost;并提供一套不错的人工智能服务。在这个领域还有其他几家提供商也能够提供 TensorFlow 模型的服务,比如 Amazon AWS SageMaker 和 Microsoft AI Platform,所以请确保也查看它们。
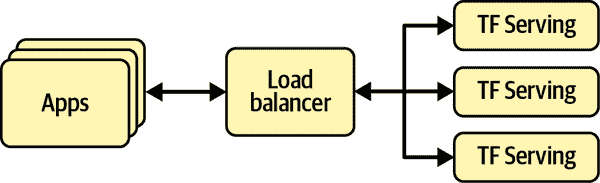
图 19-2。使用负载平衡扩展 TF Serving
现在让我们看看如何在云上提供我们出色的 MNIST 模型!
在 Vertex AI 上创建一个预测服务
Vertex AI 是 Google Cloud Platform(GCP)内的一个平台,提供各种与人工智能相关的工具和服务。您可以上传数据集,让人类对其进行标记,将常用特征存储在特征存储中,并将其用于训练或生产中,使用多个 GPU 或 TPU 服务器进行模型训练,并具有自动超参数调整或模型架构搜索(AutoML)功能。您还可以管理已训练的模型,使用它们对大量数据进行批量预测,为数据工作流程安排多个作业,通过 REST 或 gRPC 以规模化方式提供模型服务,并在名为Workbench的托管 Jupyter 环境中对数据和模型进行实验。甚至还有一个Matching Engine服务,可以非常高效地比较向量(即,近似最近邻)。GCP 还包括其他 AI 服务,例如计算机视觉、翻译、语音转文本等 API。
在我们开始之前,有一些设置需要处理:
-
登录您的 Google 账户,然后转到Google Cloud Platform 控制台(参见图 19-3)。如果您没有 Google 账户,您将需要创建一个。
-
如果这是您第一次使用 GCP,您将需要阅读并接受条款和条件。新用户可以获得免费试用,包括价值 300 美元的 GCP 信用,您可以在 90 天内使用(截至 2022 年 5 月)。您只需要其中的一小部分来支付本章中将使用的服务。注册免费试用后,您仍然需要创建一个付款配置文件并输入您的信用卡号码:这是用于验证目的——可能是为了避免人们多次使用免费试用,但您不会被收取前 300 美元的费用,之后只有在您选择升级到付费账户时才会收费。
图 19-3. Google Cloud Platform 控制台
-
如果您以前使用过 GCP 并且您的免费试用已经过期,那么您在本章中将使用的服务将会花费一些钱。这不应该太多,特别是如果您记得在不再需要这些服务时关闭它们。在运行任何服务之前,请确保您理解并同意定价条件。如果服务最终花费超出您的预期,我在此不承担任何责任!还请确保您的计费账户是活动的。要检查,请打开左上角的☰导航菜单,点击计费,然后确保您已设置付款方式并且计费账户是活动的。
-
GCP 中的每个资源都属于一个 项目。这包括您可能使用的所有虚拟机、存储的文件和运行的训练作业。当您创建一个帐户时,GCP 会自动为您创建一个名为“我的第一个项目”的项目。如果您愿意,可以通过转到项目设置来更改其显示名称:在 ☰ 导航菜单中,选择“IAM 和管理员 → 设置”,更改项目的显示名称,然后单击“保存”。请注意,项目还有一个唯一的 ID 和编号。您可以在创建项目时选择项目 ID,但以后无法更改。项目编号是自动生成的,无法更更改。如果您想创建一个新项目,请单击页面顶部的项目名称,然后单击“新项目”并输入项目名称。您还可以单击“编辑”来设置项目 ID。确保此新项目的计费处于活动状态,以便可以对服务费用进行计费(如果有免费信用)。
警告
请始终设置提醒,以便在您知道只需要几个小时时关闭服务,否则您可能会让其运行数天或数月,从而产生潜在的显著成本。
-
现在您已经拥有 GCP 帐户和项目,并且计费已激活,您必须激活所需的 API。在☰导航菜单中,选择“API 和服务”,确保启用了 Cloud Storage API。如果需要,点击+启用 API 和服务,找到 Cloud Storage,并启用它。还要启用 Vertex AI API。
您可以继续通过 GCP 控制台完成所有操作,但我建议改用 Python:这样您可以编写脚本来自动化几乎任何您想要在 GCP 上完成的任务,而且通常比通过菜单和表单点击更方便,特别是对于常见任务。
在您使用任何 GCP 服务之前,您需要做的第一件事是进行身份验证。在使用 Colab 时最简单的解决方案是执行以下代码:
from google.colab import authauth.authenticate_user()
认证过程基于 OAuth 2.0:一个弹出窗口会要求您确认您希望 Colab 笔记本访问您的 Google 凭据。如果您接受,您必须选择与 GCP 相同的 Google 帐户。然后,您将被要求确认您同意授予 Colab 对 Google Drive 和 GCP 中所有数据的完全访问权限。如果您允许访问,只有当前笔记本将具有访问权限,并且仅在 Colab 运行时到期之前。显然,只有在您信任笔记本中的代码时才应接受此操作。
警告
如果您不使用来自 https://github.com/ageron/handson-ml3 的官方笔记本,则应格外小心:如果笔记本的作者心怀不轨,他们可能包含代码来对您的数据进行任何操作。
现在让我们创建一个 Google Cloud Storage 存储桶来存储我们的 SavedModels(GCS 的存储桶是您数据的容器)。为此,我们将使用预先安装在 Colab 中的google-cloud-storage库。我们首先创建一个Client对象,它将作为与 GCS 的接口,然后我们使用它来创建存储桶:
from google.cloud import storageproject_id = "my_project" # change this to your project ID
bucket_name = "my_bucket" # change this to a unique bucket name
location = "us-central1"storage_client = storage.Client(project=project_id)
bucket = storage_client.create_bucket(bucket_name, location=location)
提示
如果您想重用现有的存储桶,请将最后一行替换为bucket = storage_client.bucket(bucket_name)。确保location设置为存储桶的地区。
GCS 使用单个全球命名空间用于存储桶,因此像“machine-learning”这样的简单名称很可能不可用。确保存储桶名称符合 DNS 命名约定,因为它可能在 DNS 记录中使用。此外,存储桶名称是公开的,因此不要在名称中放入任何私人信息。通常使用您的域名、公司名称或项目 ID 作为前缀以确保唯一性,或者只需在名称中使用一个随机数字。
如果您想要,可以更改区域,但请确保选择支持 GPU 的区域。此外,您可能需要考虑到不同区域之间价格差异很大,一些区域产生的 CO₂比其他区域多得多,一些区域不支持所有服务,并且使用单一区域存储桶可以提高性能。有关更多详细信息,请参阅Google Cloud 的区域列表和Vertex AI 的位置文档。如果您不确定,最好选择"us-central1"。
接下来,让我们将my_mnist_model目录上传到新的存储桶。在 GCS 中,文件被称为blobs(或objects),在幕后它们都只是放在存储桶中,没有任何目录结构。Blob 名称可以是任意的 Unicode 字符串,甚至可以包含斜杠(/)。GCP 控制台和其他工具使用这些斜杠来产生目录的幻觉。因此,当我们上传my_mnist_model目录时,我们只关心文件,而不是目录。
def upload_directory(bucket, dirpath):dirpath = Path(dirpath)for filepath in dirpath.glob("**/*"):if filepath.is_file():blob = bucket.blob(filepath.relative_to(dirpath.parent).as_posix())blob.upload_from_filename(filepath)upload_directory(bucket, "my_mnist_model")
这个函数现在运行良好,但如果有很多文件要上传,它会非常慢。通过多线程可以很容易地大大加快速度(请参阅笔记本中的实现)。或者,如果您有 Google Cloud CLI,则可以使用以下命令:
!gsutil -m cp -r my_mnist_model gs://{bucket_name}/
接下来,让我们告诉 Vertex AI 关于我们的 MNIST 模型。要与 Vertex AI 通信,我们可以使用google-cloud-aiplatform库(它仍然使用旧的 AI Platform 名称而不是 Vertex AI)。它在 Colab 中没有预安装,所以我们需要安装它。之后,我们可以导入该库并进行初始化——只需指定一些项目 ID 和位置的默认值——然后我们可以创建一个新的 Vertex AI 模型:我们指定一个显示名称,我们模型的 GCS 路径(在这种情况下是版本 0001),以及我们希望 Vertex AI 使用的 Docker 容器的 URL 来运行此模型。如果您访问该 URL 并向上导航一个级别,您将找到其他可以使用的容器。这个支持带有 GPU 的 TensorFlow 2.8:
from google.cloud import aiplatformserver_image = "gcr.io/cloud-aiplatform/prediction/tf2-gpu.2-8:latest"aiplatform.init(project=project_id, location=location)
mnist_model = aiplatform.Model.upload(display_name="mnist",artifact_uri=f"gs://{bucket_name}/my_mnist_model/0001",serving_container_image_uri=server_image,
)
现在让我们部署这个模型,这样我们就可以通过 gRPC 或 REST API 查询它以进行预测。为此,我们首先需要创建一个端点。这是客户端应用程序在想要访问服务时连接的地方。然后我们需要将我们的模型部署到这个端点:
endpoint = aiplatform.Endpoint.create(display_name="mnist-endpoint")endpoint.deploy(mnist_model,min_replica_count=1,max_replica_count=5,machine_type="n1-standard-4",accelerator_type="NVIDIA_TESLA_K80",accelerator_count=1
)
这段代码可能需要几分钟才能运行,因为 Vertex AI 需要设置一个虚拟机。在这个例子中,我们使用一个相当基本的 n1-standard-4 类型的机器(查看https://homl.info/machinetypes 获取其他类型)。我们还使用了一个基本的 NVIDIA_TESLA_K80 类型的 GPU(查看https://homl.info/accelerators 获取其他类型)。如果您选择的区域不是 "us-central1",那么您可能需要将机器类型或加速器类型更改为该区域支持的值(例如,并非所有区域都有 Nvidia Tesla K80 GPU)。
注意
Google Cloud Platform 实施各种 GPU 配额,包括全球范围和每个地区:您不能在未经 Google 授权的情况下创建成千上万个 GPU 节点。要检查您的配额,请在 GCP 控制台中打开“IAM 和管理员 → 配额”。如果某些配额太低(例如,如果您需要在特定地区更多的 GPU),您可以要求增加它们;通常需要大约 48 小时。
Vertex AI 将最初生成最少数量的计算节点(在这种情况下只有一个),每当每秒查询次数变得过高时,它将生成更多节点(最多为您定义的最大数量,这种情况下为五个),并在它们之间负载均衡查询。如果一段时间内 QPS 速率下降,Vertex AI 将自动停止额外的计算节点。因此,成本直接与负载、您选择的机器和加速器类型以及您在 GCS 上存储的数据量相关。这种定价模型非常适合偶尔使用者和有重要使用高峰的服务。对于初创公司来说也是理想的:价格保持低延迟到公司真正开始运营。
恭喜,您已经将第一个模型部署到云端!现在让我们查询这个预测服务:
response = endpoint.predict(instances=X_new.tolist())
我们首先需要将要分类的图像转换为 Python 列表,就像我们之前使用 REST API 向 TF Serving 发送请求时所做的那样。响应对象包含预测结果,表示为 Python 浮点数列表的列表。让我们将它们四舍五入到两位小数并将它们转换为 NumPy 数组:
>>> import numpy as np
>>> np.round(response.predictions, 2)
array([[0\. , 0\. , 0\. , 0\. , 0\. , 0\. , 0\. , 1\. , 0\. , 0\. ],[0\. , 0\. , 0.99, 0.01, 0\. , 0\. , 0\. , 0\. , 0\. , 0\. ],[0\. , 0.97, 0.01, 0\. , 0\. , 0\. , 0\. , 0.01, 0\. , 0\. ]])
是的!我们得到了与之前完全相同的预测结果。我们现在在云上有一个很好的预测服务,我们可以从任何地方安全地查询,并且可以根据 QPS 的数量自动扩展或缩小。当您使用完端点后,请不要忘记将其删除,以避免无谓地支付费用:
endpoint.undeploy_all() # undeploy all models from the endpoint
endpoint.delete()
现在让我们看看如何在 Vertex AI 上运行作业,对可能非常大的数据批次进行预测。
在 Vertex AI 上运行批量预测作业
如果我们需要进行大量预测,那么我们可以请求 Vertex AI 为我们运行预测作业,而不是重复调用我们的预测服务。这不需要端点,只需要一个模型。例如,让我们在测试集的前 100 张图像上运行一个预测作业,使用我们的 MNIST 模型。为此,我们首先需要准备批处理并将其上传到 GCS。一种方法是创建一个文件,每行包含一个实例,每个实例都格式化为 JSON 值——这种格式称为 JSON Lines——然后将此文件传递给 Vertex AI。因此,让我们在一个新目录中创建一个 JSON Lines 文件,然后将此目录上传到 GCS:
batch_path = Path("my_mnist_batch")
batch_path.mkdir(exist_ok=True)
with open(batch_path / "my_mnist_batch.jsonl", "w") as jsonl_file:for image in X_test[:100].tolist():jsonl_file.write(json.dumps(image))jsonl_file.write("\n")upload_directory(bucket, batch_path)
现在我们准备启动预测作业,指定作业的名称、要使用的机器和加速器的类型和数量,刚刚创建的 JSON Lines 文件的 GCS 路径,以及 Vertex AI 将保存模型预测的 GCS 目录的路径:
batch_prediction_job = mnist_model.batch_predict(job_display_name="my_batch_prediction_job",machine_type="n1-standard-4",starting_replica_count=1,max_replica_count=5,accelerator_type="NVIDIA_TESLA_K80",accelerator_count=1,gcs_source=[f"gs://{bucket_name}/{batch_path.name}/my_mnist_batch.jsonl"],gcs_destination_prefix=f"gs://{bucket_name}/my_mnist_predictions/",sync=True # set to False if you don't want to wait for completion
)
提示
对于大批量数据,您可以将输入拆分为多个 JSON Lines 文件,并通过gcs_source参数列出它们。
这将需要几分钟的时间,主要是为了在 Vertex AI 上生成计算节点。一旦这个命令完成,预测将会以类似prediction.results-00001-of-00002的文件集合中可用。这些文件默认使用 JSON Lines 格式,每个值都是包含实例及其对应预测(即 10 个概率)的字典。实例按照输入的顺序列出。该作业还会输出prediction-errors文件,如果出现问题,这些文件对于调试可能会有用。我们可以使用batch_prediction_job.iter_outputs()迭代所有这些输出文件,所以让我们遍历所有的预测并将它们存储在y_probas数组中:
y_probas = []
for blob in batch_prediction_job.iter_outputs():if "prediction.results" in blob.name:for line in blob.download_as_text().splitlines():y_proba = json.loads(line)["prediction"]y_probas.append(y_proba)
现在让我们看看这些预测有多好:
>>> y_pred = np.argmax(y_probas, axis=1)
>>> accuracy = np.sum(y_pred == y_test[:100]) / 100
0.98
很好,98%的准确率!
JSON Lines 格式是默认格式,但是当处理大型实例(如图像)时,它太冗长了。幸运的是,batch_predict()方法接受一个instances_format参数,让您可以选择另一种格式。它默认为"jsonl",但您可以将其更改为"csv"、"tf-record"、"tf-record-gzip"、"bigquery"或"file-list"。如果将其设置为"file-list",那么gcs_source参数应指向一个文本文件,其中每行包含一个输入文件路径;例如,指向 PNG 图像文件。Vertex AI 将读取这些文件作为二进制文件,使用 Base64 对其进行编码,并将生成的字节字符串传递给模型。这意味着您必须在模型中添加一个预处理层来解析 Base64 字符串,使用tf.io.decode_base64()。如果文件是图像,则必须使用类似tf.io.decode_image()或tf.io.decode_png()的函数来解析结果,如第十三章中所讨论的。
当您完成使用模型后,如果需要,可以通过运行mnist_model.delete()来删除它。您还可以删除在您的 GCS 存储桶中创建的目录,可选地删除存储桶本身(如果为空),以及批量预测作业。
for prefix in ["my_mnist_model/", "my_mnist_batch/", "my_mnist_predictions/"]:blobs = bucket.list_blobs(prefix=prefix)for blob in blobs:blob.delete()bucket.delete() # if the bucket is empty
batch_prediction_job.delete()
您现在知道如何将模型部署到 Vertex AI,创建预测服务,并运行批量预测作业。但是如果您想将模型部署到移动应用程序,或者嵌入式设备,比如加热控制系统、健身追踪器或自动驾驶汽车呢?
将模型部署到移动设备或嵌入式设备
机器学习模型不仅限于在拥有多个 GPU 的大型集中式服务器上运行:它们可以更接近数据源运行(这被称为边缘计算),例如在用户的移动设备或嵌入式设备中。去中心化计算并将其移向边缘有许多好处:它使设备即使未连接到互联网时也能智能化,通过不必将数据发送到远程服务器来减少延迟并减轻服务器负载,并且可能提高隐私性,因为用户的数据可以保留在设备上。
然而,将模型部署到边缘也有其缺点。与强大的多 GPU 服务器相比,设备的计算资源通常很少。一个大模型可能无法适应设备,可能使用过多的 RAM 和 CPU,并且可能下载时间过长。结果,应用可能变得无响应,设备可能会发热并迅速耗尽电池。为了避免这一切,您需要制作一个轻量级且高效的模型,而不会牺牲太多准确性。 TFLite库提供了几个工具,帮助您将模型部署到边缘,主要有三个目标:
-
减小模型大小,缩短下载时间并减少 RAM 使用量。
-
减少每次预测所需的计算量,以减少延迟、电池使用量和发热。
-
使模型适应特定设备的限制。
为了减小模型大小,TFLite 的模型转换器可以接受 SavedModel 并将其压缩为基于 FlatBuffers 的更轻量级格式。这是一个高效的跨平台序列化库(有点像协议缓冲区),最初由谷歌为游戏创建。它设计成可以直接将 FlatBuffers 加载到 RAM 中,无需任何预处理:这样可以减少加载时间和内存占用。一旦模型加载到移动设备或嵌入式设备中,TFLite 解释器将执行它以进行预测。以下是如何将 SavedModel 转换为 FlatBuffer 并保存为 .tflite 文件的方法:
converter = tf.lite.TFLiteConverter.from_saved_model(str(model_path))
tflite_model = converter.convert()
with open("my_converted_savedmodel.tflite", "wb") as f:f.write(tflite_model)
提示
您还可以使用 tf.lite.TFLiteConverter.from_keras_model(model) 将 Keras 模型直接保存为 FlatBuffer 格式。
转换器还优化模型,既缩小模型大小,又减少延迟。它修剪所有不需要进行预测的操作(例如训练操作),并在可能的情况下优化计算;例如,3 × a + 4 ×_ a_ + 5 × a 将被转换为 12 × a。此外,它尝试在可能的情况下融合操作。例如,如果可能的话,批量归一化层最终会合并到前一层的加法和乘法操作中。要了解 TFLite 可以对模型进行多少优化,可以下载其中一个预训练的 TFLite 模型,例如Inception_V1_quant(点击tflite&pb),解压缩存档,然后打开优秀的Netron 图形可视化工具并上传*.pb文件以查看原始模型。这是一个庞大而复杂的图形,对吧?接下来,打开优化后的.tflite*模型,惊叹于其美丽!
除了简单地使用较小的神经网络架构之外,您可以减小模型大小的另一种方法是使用较小的位宽:例如,如果您使用半精度浮点数(16 位)而不是常规浮点数(32 位),模型大小将缩小 2 倍,代价是(通常很小的)准确度下降。此外,训练速度将更快,您将使用大约一半的 GPU 内存。
TFLite 的转换器可以进一步将模型权重量化为固定点、8 位整数!与使用 32 位浮点数相比,这导致了四倍的大小减小。最简单的方法称为后训练量化:它只是在训练后量化权重,使用一种相当基本但高效的对称量化技术。它找到最大绝对权重值m,然后将浮点范围–m到+m映射到固定点(整数)范围–127 到+127。例如,如果权重范围从–1.5 到+0.8,则字节–127、0 和+127 将分别对应于浮点–1.5、0.0 和+1.5(参见图 19-5)。请注意,当使用对称量化时,0.0 始终映射为 0。还请注意,在此示例中不会使用字节值+68 到+127,因为它们映射到大于+0.8 的浮点数。
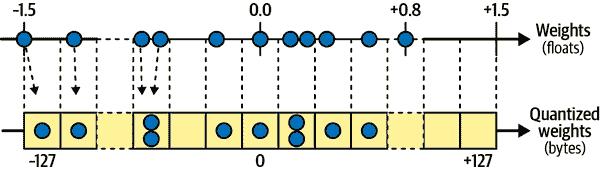
图 19-5。从 32 位浮点数到 8 位整数,使用对称量化
要执行这种训练后的量化,只需在调用convert()方法之前将DEFAULT添加到转换器优化列表中:
converter.optimizations = [tf.lite.Optimize.DEFAULT]
这种技术显著减小了模型的大小,使得下载速度更快,占用的存储空间更少。在运行时,量化的权重在使用之前会被转换回浮点数。这些恢复的浮点数与原始浮点数并不完全相同,但也不会相差太远,因此精度损失通常是可以接受的。为了避免一直重新计算浮点值,这样会严重减慢模型的速度,TFLite 会对其进行缓存:不幸的是,这意味着这种技术并不会减少 RAM 的使用量,也不会加快模型的速度。它主要用于减小应用程序的大小。
减少延迟和功耗的最有效方法是对激活进行量化,使得计算可以完全使用整数,而无需任何浮点运算。即使使用相同的位宽(例如,32 位整数而不是 32 位浮点数),整数计算使用的 CPU 周期更少,消耗的能量更少,产生的热量也更少。如果还减少位宽(例如,降至 8 位整数),可以获得巨大的加速。此外,一些神经网络加速器设备(如 Google 的 Edge TPU)只能处理整数,因此权重和激活的完全量化是强制性的。这可以在训练后完成;它需要一个校准步骤来找到激活的最大绝对值,因此您需要向 TFLite 提供代表性的训练数据样本(不需要很大),它将通过模型处理数据并测量量化所需的激活统计信息。这一步通常很快。
量化的主要问题是它会失去一点准确性:这类似于在权重和激活中添加噪声。如果准确性下降太严重,那么您可能需要使用量化感知训练。这意味着向模型添加虚假量化操作,以便它在训练过程中学会忽略量化噪声;最终的权重将更加稳健地适应量化。此外,校准步骤可以在训练过程中自动处理,这简化了整个过程。
我已经解释了 TFLite 的核心概念,但要完全编写移动或嵌入式应用程序需要一本专门的书。幸运的是,一些书籍存在:如果您想了解有关为移动和嵌入式设备构建 TensorFlow 应用程序的更多信息,请查看 O’Reilly 的书籍TinyML: Machine Learning with TensorFlow on Arduino and Ultra-Low Power Micro-Controllers,作者是 Pete Warden(TFLite 团队的前负责人)和 Daniel Situnayake,以及AI and Machine Learning for On-Device Development,作者是 Laurence Moroney。
那么,如果您想在网站中使用您的模型,在用户的浏览器中直接运行呢?
在网页中运行模型
在客户端,即用户的浏览器中运行您的机器学习模型,而不是在服务器端运行,可以在许多场景下非常有用,例如:
-
当您的网络应用经常在用户的连接不稳定或缓慢的情况下使用(例如,徒步者的网站),因此在客户端直接运行模型是使您的网站可靠的唯一方法。
-
当您需要模型的响应尽可能快时(例如,用于在线游戏)。消除查询服务器进行预测的需要肯定会减少延迟,并使网站更加响应。
-
当您的网络服务基于一些私人用户数据进行预测,并且您希望通过在客户端进行预测来保护用户的隐私,以便私人数据永远不必离开用户的设备。
对于所有这些场景,您可以使用TensorFlow.js(TFJS)JavaScript 库。该库可以在用户的浏览器中加载 TFLite 模型并直接进行预测。例如,以下 JavaScript 模块导入了 TFJS 库,下载了一个预训练的 MobileNet 模型,并使用该模型对图像进行分类并记录预测结果。您可以在https://homl.info/tfjscode上尝试这段代码,使用 Glitch.com,这是一个允许您免费在浏览器中构建 Web 应用程序的网站;点击页面右下角的预览按钮查看代码的运行情况:
import "https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@latest";
import "https://cdn.jsdelivr.net/npm/@tensorflow-models/mobilenet@1.0.0";const image = document.getElementById("image");mobilenet.load().then(model => {model.classify(image).then(predictions => {for (var i = 0; i < predictions.length; i++) {let className = predictions[i].classNamelet proba = (predictions[i].probability * 100).toFixed(1)console.log(className + " : " + proba + "%");}});
});
甚至可以将这个网站转变成一个渐进式 Web 应用程序(PWA):这是一个遵守一系列标准的网站,使其可以在任何浏览器中查看,甚至可以在移动设备上作为独立应用程序安装。例如,在移动设备上尝试访问https://homl.info/tfjswpa:大多数现代浏览器会询问您是否想要将 TFJS 演示添加到主屏幕。如果您接受,您将在应用程序列表中看到一个新图标。点击此图标将在其自己的窗口中加载 TFJS 演示网站,就像常规移动应用程序一样。PWA 甚至可以配置为离线工作,通过使用服务工作者:这是一个在浏览器中以自己独立线程运行的 JavaScript 模块,拦截网络请求,使其可以缓存资源,从而使 PWA 可以更快地运行,甚至完全离线运行。它还可以传递推送消息,在后台运行任务等。PWA 允许您管理 Web 和移动设备的单个代码库。它们还使得更容易确保所有用户运行您应用程序的相同版本。您可以在 Glitch.com 上玩这个 TFJS 演示的 PWA 代码,网址是https://homl.info/wpacode。
提示
在https://tensorflow.org/js/demos上查看更多在您的浏览器中运行的机器学习模型的演示。
TFJS 还支持在您的网络浏览器中直接训练模型!而且速度相当快。如果您的计算机有 GPU 卡,那么 TFJS 通常可以使用它,即使它不是 Nvidia 卡。实际上,TFJS 将在可用时使用 WebGL,由于现代网络浏览器通常支持各种 GPU 卡,TFJS 实际上支持的 GPU 卡比常规的 TensorFlow 更多(后者仅支持 Nvidia 卡)。
在用户的网络浏览器中训练模型可以特别有用,可以确保用户的数据保持私密。模型可以在中央进行训练,然后在浏览器中根据用户的数据进行本地微调。如果您对这个话题感兴趣,请查看联邦学习。
再次强调,要全面涵盖这个主题需要一本完整的书。如果您想了解更多关于 TensorFlow.js 的内容,请查看 O’reilly 图书《云端、移动和边缘的实用深度学习》(Anirudh Koul 等著)或《学习 TensorFlow.js》(Gant Laborde 著)。
现在您已经看到如何将 TensorFlow 模型部署到 TF Serving,或者通过 Vertex AI 部署到云端,或者使用 TFLite 部署到移动和嵌入式设备,或者使用 TFJS 部署到 Web 浏览器,让我们讨论如何使用 GPU 加速计算。
使用 GPU 加速计算
在第十一章中,我们看了几种可以显著加快训练速度的技术:更好的权重初始化、复杂的优化器等等。但即使使用了所有这些技术,使用单个 CPU 的单台机器训练大型神经网络可能需要几个小时、几天,甚至几周,具体取决于任务。由于 GPU 的出现,这种训练时间可以缩短到几分钟或几小时。这不仅节省了大量时间,还意味着您可以更轻松地尝试各种模型,并经常使用新数据重新训练您的模型。
在之前的章节中,我们在 Google Colab 上使用了启用 GPU 的运行时。您只需从运行时菜单中选择“更改运行时类型”,然后选择 GPU 加速器类型;TensorFlow 会自动检测 GPU 并使用它加速计算,代码与没有 GPU 时完全相同。然后,在本章中,您看到了如何将模型部署到 Vertex AI 上的多个启用 GPU 的计算节点:只需在创建 Vertex AI 模型时选择正确的启用 GPU 的 Docker 镜像,并在调用endpoint.deploy()时选择所需的 GPU 类型。但是,如果您想购买自己的 GPU 怎么办?如果您想在单台机器上的 CPU 和多个 GPU 设备之间分发计算(参见图 19-6)?这是我们现在将讨论的内容,然后在本章的后面部分我们将讨论如何在多个服务器上分发计算。
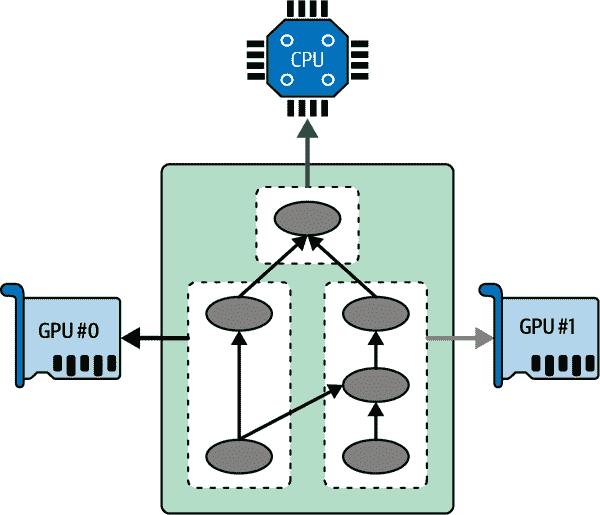
图 19-6。在多个设备上并行执行 TensorFlow 图
获取自己的 GPU
如果你知道你将会长时间大量使用 GPU,那么购买自己的 GPU 可能是经济上合理的。你可能也想在本地训练模型,因为你不想将数据上传到云端。或者你只是想购买一张用于游戏的 GPU 卡,并且想将其用于深度学习。
如果您决定购买 GPU 卡,那么请花些时间做出正确的选择。您需要考虑您的任务所需的 RAM 数量(例如,图像处理或 NLP 通常至少需要 10GB),带宽(即您可以将数据发送到 GPU 和从 GPU 中发送数据的速度),核心数量,冷却系统等。Tim Dettmers 撰写了一篇优秀的博客文章来帮助您选择:我鼓励您仔细阅读。在撰写本文时,TensorFlow 仅支持具有 CUDA Compute Capability 3.5+的 Nvidia 卡(当然还有 Google 的 TPU),但它可能会将其支持扩展到其他制造商,因此请务必查看TensorFlow 的文档以了解今天支持哪些设备。
如果您选择 Nvidia GPU 卡,您将需要安装适当的 Nvidia 驱动程序和几个 Nvidia 库。这些包括计算统一设备架构库(CUDA)工具包,它允许开发人员使用支持 CUDA 的 GPU 进行各种计算(不仅仅是图形加速),以及CUDA 深度神经网络库(cuDNN),一个 GPU 加速的常见 DNN 计算库,例如激活层、归一化、前向和反向卷积以及池化(参见第十四章)。cuDNN 是 Nvidia 的深度学习 SDK 的一部分。请注意,您需要创建一个 Nvidia 开发者帐户才能下载它。TensorFlow 使用 CUDA 和 cuDNN 来控制 GPU 卡并加速计算(参见图 19-7)。
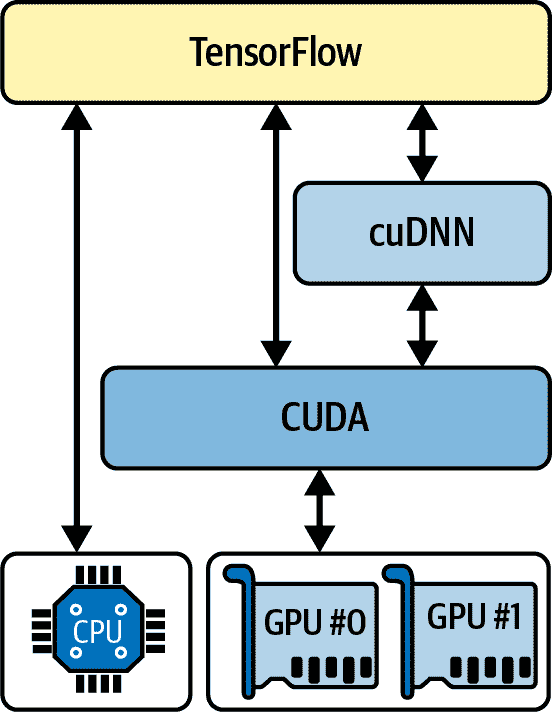
图 19-7. TensorFlow 使用 CUDA 和 cuDNN 来控制 GPU 并加速 DNNs
安装了 GPU 卡和所有必需的驱动程序和库之后,您可以使用nvidia-smi命令来检查一切是否正确安装。该命令列出了可用的 GPU 卡,以及每张卡上运行的所有进程。在这个例子中,这是一张 Nvidia Tesla T4 GPU 卡,大约有 15GB 的可用内存,并且当前没有任何进程在运行:
$ nvidia-smi
Sun Apr 10 04:52:10 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 34C P8 9W / 70W | 3MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------++-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+要检查 TensorFlow 是否真正看到您的 GPU,请运行以下命令并确保结果不为空:
>>> physical_gpus = tf.config.list_physical_devices("GPU")
>>> physical_gpus
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
管理 GPU 内存
默认情况下,TensorFlow 在第一次运行计算时会自动占用几乎所有可用 GPU 的 RAM,以限制 GPU RAM 的碎片化。这意味着如果您尝试启动第二个 TensorFlow 程序(或任何需要 GPU 的程序),它将很快耗尽 RAM。这种情况并不像您可能认为的那样经常发生,因为通常您会在一台机器上运行一个单独的 TensorFlow 程序:通常是一个训练脚本、一个 TF Serving 节点或一个 Jupyter 笔记本。如果出于某种原因需要运行多个程序(例如,在同一台机器上并行训练两个不同的模型),那么您需要更均匀地在这些进程之间分配 GPU RAM。
如果您的机器上有多个 GPU 卡,一个简单的解决方案是将每个 GPU 卡分配给单个进程。为此,您可以设置CUDA_VISIBLE_DEVICES环境变量,以便每个进程只能看到适当的 GPU 卡。还要设置CUDA_DEVICE_ORDER环境变量为PCI_BUS_ID,以确保每个 ID 始终指向相同的 GPU 卡。例如,如果您有四个 GPU 卡,您可以启动两个程序,将两个 GPU 分配给每个程序,通过在两个单独的终端窗口中执行以下命令来实现:
$ CUDA_DEVICE_ORDER=PCI_BUS_IDCUDA_VISIBLE_DEVICES=0,1python3program_1.py*`#` `and``in``another``terminal:`*$ CUDA_DEVICE_ORDER=PCI_BUS_IDCUDA_VISIBLE_DEVICES=3,2python3program_2.py
程序 1 将只看到 GPU 卡 0 和 1,分别命名为"/gpu:0"和"/gpu:1",在 TensorFlow 中,程序 2 将只看到 GPU 卡 2 和 3,分别命名为"/gpu:1"和"/gpu:0"(注意顺序)。一切都将正常工作(参见图 19-8)。当然,您也可以在 Python 中通过设置os.environ["CUDA_DEVICE_ORDER"]和os.environ["CUDA_VISIBLE_DEVICES"]来定义这些环境变量,只要在使用 TensorFlow 之前这样做。
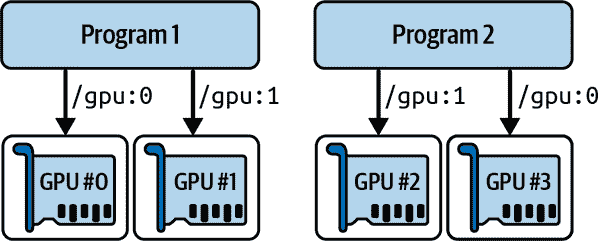
图 19-8。每个程序获得两个 GPU
另一个选项是告诉 TensorFlow 只获取特定数量的 GPU RAM。这必须在导入 TensorFlow 后立即完成。例如,要使 TensorFlow 只在每个 GPU 上获取 2 GiB 的 RAM,您必须为每个物理 GPU 设备创建一个逻辑 GPU 设备(有时称为虚拟 GPU 设备),并将其内存限制设置为 2 GiB(即 2,048 MiB):
for gpu in physical_gpus:tf.config.set_logical_device_configuration(gpu,[tf.config.LogicalDeviceConfiguration(memory_limit=2048)])
假设您有四个 GPU,每个 GPU 至少有 4 GiB 的 RAM:在这种情况下,可以并行运行两个像这样的程序,每个程序使用所有四个 GPU 卡(请参见图 19-9)。如果在两个程序同时运行时运行nvidia-smi命令,则应该看到每个进程在每张卡上占用 2 GiB 的 RAM。
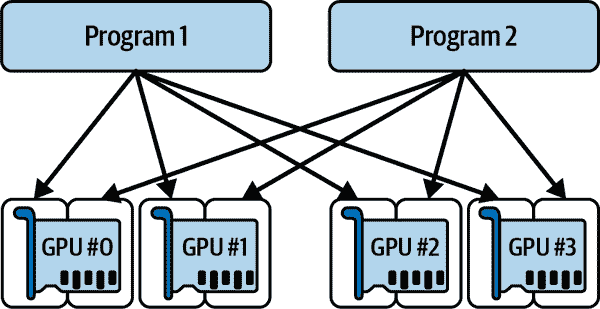
图 19-9。每个程序都可以获得四个 GPU,但每个 GPU 只有 2 GiB 的 RAM
另一个选项是告诉 TensorFlow 只在需要时获取内存。同样,在导入 TensorFlow 后必须立即执行此操作:
for gpu in physical_gpus:tf.config.experimental.set_memory_growth(gpu, True)
另一种方法是将TF_FORCE_GPU_ALLOW_GROWTH环境变量设置为true。使用这个选项,TensorFlow 一旦分配了内存就不会释放它(再次,为了避免内存碎片化),除非程序结束。使用这个选项很难保证确定性行为(例如,一个程序可能会崩溃,因为另一个程序的内存使用量激增),因此在生产环境中,您可能会选择之前的选项之一。然而,有一些情况下它非常有用:例如,当您使用一台机器运行多个 Jupyter 笔记本时,其中几个使用了 TensorFlow。在 Colab 运行时,TF_FORCE_GPU_ALLOW_GROWTH环境变量被设置为true。
最后,在某些情况下,您可能希望将一个 GPU 分成两个或更多逻辑设备。例如,如果您只有一个物理 GPU,比如在 Colab 运行时,但您想要测试一个多 GPU 算法,这将非常有用。以下代码将 GPU#0 分成两个逻辑设备,每个设备有 2 GiB 的 RAM(同样,在导入 TensorFlow 后立即执行):
tf.config.set_logical_device_configuration(physical_gpus[0],[tf.config.LogicalDeviceConfiguration(memory_limit=2048),tf.config.LogicalDeviceConfiguration(memory_limit=2048)]
)
这两个逻辑设备被称为"/gpu:0"和"/gpu:1", 你可以像使用两个普通 GPU 一样使用它们。你可以像这样列出所有逻辑设备:
>>> logical_gpus = tf.config.list_logical_devices("GPU")
>>> logical_gpus
[LogicalDevice(name='/device:GPU:0', device_type='GPU'),LogicalDevice(name='/device:GPU:1', device_type='GPU')]
现在让我们看看 TensorFlow 如何决定应该使用哪些设备来放置变量和执行操作。
将操作和变量放在设备上
Keras 和 tf.data 通常会很好地将操作和变量放在它们应该在的位置,但如果您想要更多控制,您也可以手动将操作和变量放在每个设备上:
-
通常,您希望将数据预处理操作放在 CPU 上,并将神经网络操作放在 GPU 上。
-
GPU 通常具有相对有限的通信带宽,因此重要的是要避免不必要的数据传输进出 GPU。
-
向机器添加更多的 CPU RAM 是简单且相对便宜的,因此通常有很多,而 GPU RAM 是内置在 GPU 中的:它是一种昂贵且有限的资源,因此如果一个变量在接下来的几个训练步骤中不需要,它可能应该放在 CPU 上(例如,数据集通常应该放在 CPU 上)。
默认情况下,所有变量和操作都将放置在第一个 GPU 上(命名为"/gpu:0"),除非变量和操作没有 GPU 内核:这些将放置在 CPU 上(始终命名为"/cpu:0")。张量或变量的device属性告诉您它被放置在哪个设备上。
>>> a = tf.Variable([1., 2., 3.]) # float32 variable goes to the GPU
>>> a.device
'/job:localhost/replica:0/task:0/device:GPU:0'
>>> b = tf.Variable([1, 2, 3]) # int32 variable goes to the CPU
>>> b.device
'/job:localhost/replica:0/task:0/device:CPU:0'
您现在可以安全地忽略前缀/job:localhost/replica:0/task:0;我们将在本章后面讨论作业、副本和任务。正如您所看到的,第一个变量被放置在 GPU#0 上,这是默认设备。但是,第二个变量被放置在 CPU 上:这是因为整数变量没有 GPU 内核,或者涉及整数张量的操作没有 GPU 内核,因此 TensorFlow 回退到 CPU。
如果您想在与默认设备不同的设备上执行操作,请使用tf.device()上下文:
>>> with tf.device("/cpu:0"):
... c = tf.Variable([1., 2., 3.])
...
>>> c.device
'/job:localhost/replica:0/task:0/device:CPU:0'
注意
CPU 始终被视为单个设备("/cpu:0"),即使您的计算机有多个 CPU 核心。放置在 CPU 上的任何操作,如果具有多线程内核,则可能在多个核心上并行运行。
如果您明确尝试将操作或变量放置在不存在或没有内核的设备上,那么 TensorFlow 将悄悄地回退到默认选择的设备。当您希望能够在不具有相同数量的 GPU 的不同机器上运行相同的代码时,这是很有用的。但是,如果您希望获得异常,可以运行tf.config.set_soft_device_placement(False)。
现在,TensorFlow 如何在多个设备上执行操作呢?
跨多个设备并行执行
正如我们在第十二章中看到的,使用 TF 函数的一个好处是并行性。让我们更仔细地看一下这一点。当 TensorFlow 运行一个 TF 函数时,它首先分析其图形,找到需要评估的操作列表,并计算每个操作的依赖关系数量。然后 TensorFlow 将每个具有零依赖关系的操作(即每个源操作)添加到该操作设备的评估队列中(参见图 19-10)。一旦一个操作被评估,依赖于它的每个操作的依赖计数器都会减少。一旦一个操作的依赖计数器达到零,它就会被推送到其设备的评估队列中。一旦所有输出都被计算出来,它们就会被返回。
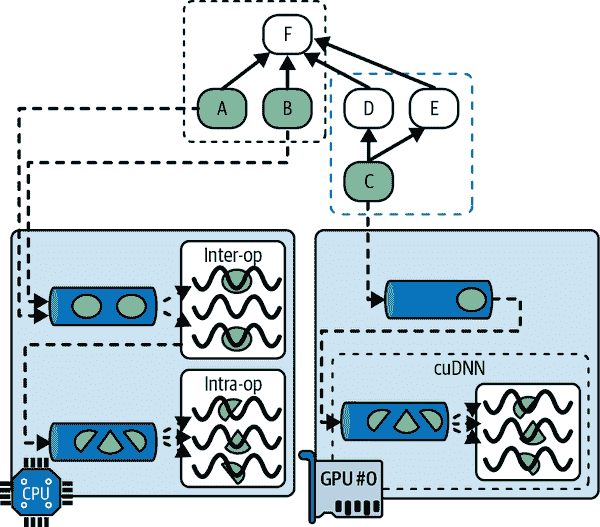
图 19-10. TensorFlow 图的并行执行
CPU 的评估队列中的操作被分派到一个称为inter-op 线程池的线程池中。如果 CPU 有多个核心,那么这些操作将有效地并行评估。一些操作具有多线程 CPU 内核:这些内核将其任务分割为多个子操作,这些子操作被放置在另一个评估队列中,并分派到一个称为intra-op 线程池的第二线程池中(由所有多线程 CPU 内核共享)。简而言之,多个操作和子操作可能在不同的 CPU 核心上并行评估。
对于 GPU 来说,情况要简单一些。GPU 的评估队列中的操作是按顺序评估的。然而,大多数操作都有多线程 GPU 内核,通常由 TensorFlow 依赖的库实现,比如 CUDA 和 cuDNN。这些实现有自己的线程池,它们通常会利用尽可能多的 GPU 线程(这就是为什么 GPU 不需要一个跨操作线程池的原因:每个操作已经占用了大部分 GPU 线程)。
例如,在图 19-10 中,操作 A、B 和 C 是源操作,因此它们可以立即被评估。操作 A 和 B 被放置在 CPU 上,因此它们被发送到 CPU 的评估队列,然后被分派到跨操作线程池并立即并行评估。操作 A 恰好有一个多线程内核;它的计算被分成三部分,在操作线程池中并行执行。操作 C 进入 GPU #0 的评估队列,在这个例子中,它的 GPU 内核恰好使用 cuDNN,它管理自己的内部操作线程池,并在许多 GPU 线程之间并行运行操作。假设 C 先完成。D 和 E 的依赖计数器被减少到 0,因此两个操作都被推送到 GPU #0 的评估队列,并按顺序执行。请注意,即使 D 和 E 都依赖于 C,C 也只被评估一次。假设 B 接下来完成。然后 F 的依赖计数器从 4 减少到 3,由于不为 0,它暂时不运行。一旦 A、D 和 E 完成,那么 F 的依赖计数器达到 0,它被推送到 CPU 的评估队列并被评估。最后,TensorFlow 返回请求的输出。
TensorFlow 执行的另一个神奇之处是当 TF 函数修改状态资源(例如变量)时:它确保执行顺序与代码中的顺序匹配,即使语句之间没有显式依赖关系。例如,如果您的 TF 函数包含v.assign_add(1),然后是v.assign(v * 2),TensorFlow 将确保这些操作按照这个顺序执行。
提示
您可以通过调用tf.config.threading.set_inter_op_parallelism_threads()来控制 inter-op 线程池中的线程数。要设置 intra-op 线程数,请使用tf.config.threading.set_intra_op_parallelism_threads()。如果您不希望 TensorFlow 使用所有 CPU 核心,或者希望它是单线程的,这将非常有用。¹²
有了这些,您就拥有了在任何设备上运行任何操作并利用 GPU 的能力所需的一切!以下是您可以做的一些事情:
-
您可以并行训练多个模型,每个模型都在自己的 GPU 上:只需为每个模型编写一个训练脚本,并在并行运行时设置
CUDA_DEVICE_ORDER和CUDA_VISIBLE_DEVICES,以便每个脚本只能看到一个 GPU 设备。这对于超参数调整非常有用,因为您可以并行训练具有不同超参数的多个模型。如果您有一台具有两个 GPU 的单台机器,并且在一个 GPU 上训练一个模型需要一个小时,那么并行训练两个模型,每个模型都在自己专用的 GPU 上,只需要一个小时。简单! -
您可以在单个 GPU 上训练一个模型,并在 CPU 上并行执行所有预处理操作,使用数据集的
prefetch()方法提前准备好接下来的几批数据,以便在 GPU 需要时立即使用(参见第十三章)。 -
如果您的模型接受两个图像作为输入,并在使用两个 CNN 处理它们之前将它们连接起来,那么如果您将每个 CNN 放在不同的 GPU 上,它可能会运行得更快。
-
您可以创建一个高效的集成:只需在每个 GPU 上放置一个不同训练过的模型,这样您就可以更快地获得所有预测结果,以生成集成的最终预测。
但是如果您想通过使用多个 GPU 加速训练呢?
在多个设备上训练模型
训练单个模型跨多个设备有两种主要方法:模型并行,其中模型在设备之间分割,和数据并行,其中模型在每个设备上复制,并且每个副本在不同的数据子集上进行训练。让我们看看这两种选择。
模型并行
到目前为止,我们已经在单个设备上训练了每个神经网络。如果我们想要在多个设备上训练单个神经网络怎么办?这需要将模型分割成单独的块,并在不同的设备上运行每个块。不幸的是,这种模型并行化实际上非常棘手,其有效性确实取决于神经网络的架构。对于全连接网络,从这种方法中通常无法获得太多好处。直觉上,似乎将模型分割的一种简单方法是将每一层放在不同的设备上,但这并不起作用,因为每一层都需要等待前一层的输出才能执行任何操作。也许你可以垂直切割它——例如,将每一层的左半部分放在一个设备上,右半部分放在另一个设备上?这样稍微好一些,因为每一层的两半确实可以并行工作,但问题在于下一层的每一半都需要上一层两半的输出,因此会有大量的跨设备通信(由虚线箭头表示)。这很可能会完全抵消并行计算的好处,因为跨设备通信速度很慢(当设备位于不同的机器上时更是如此)。
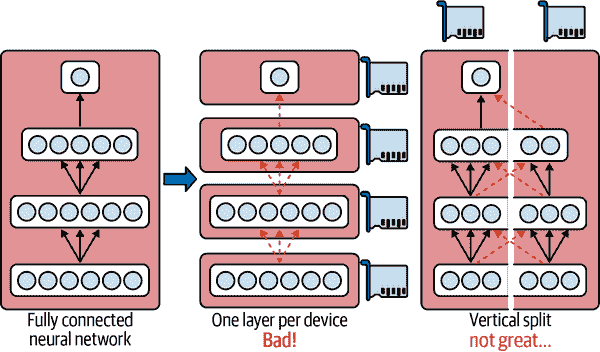
图 19-11。拆分完全连接的神经网络
一些神经网络架构,如卷积神经网络(参见第十四章),包含仅部分连接到较低层的层,因此更容易以有效的方式在设备之间分发块(参见图 19-12)。
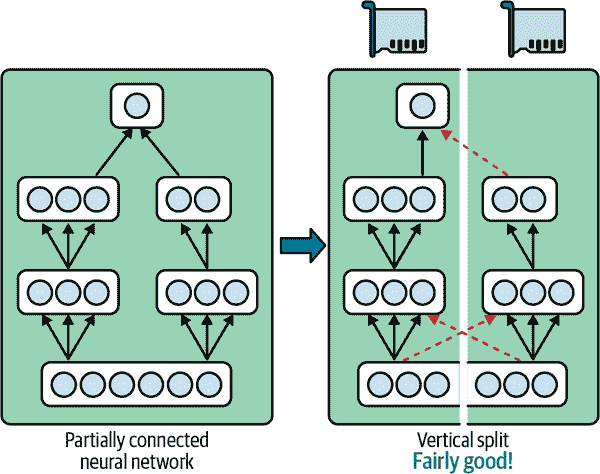
图 19-12。拆分部分连接的神经网络
深度递归神经网络(参见第十五章)可以更有效地跨多个 GPU 进行分割。如果将网络水平分割,将每一层放在不同的设备上,并将输入序列输入网络进行处理,那么在第一个时间步中只有一个设备会处于活动状态(处理序列的第一个值),在第二个时间步中两个设备会处于活动状态(第二层将处理第一层的输出值,而第一层将处理第二个值),当信号传播到输出层时,所有设备将同时处于活动状态(图 19-13)。尽管设备之间仍然存在大量的跨设备通信,但由于每个单元可能相当复杂,理论上并行运行多个单元的好处可能会超过通信惩罚。然而,在实践中,在单个 GPU 上运行的常规堆叠LSTM层实际上运行得更快。
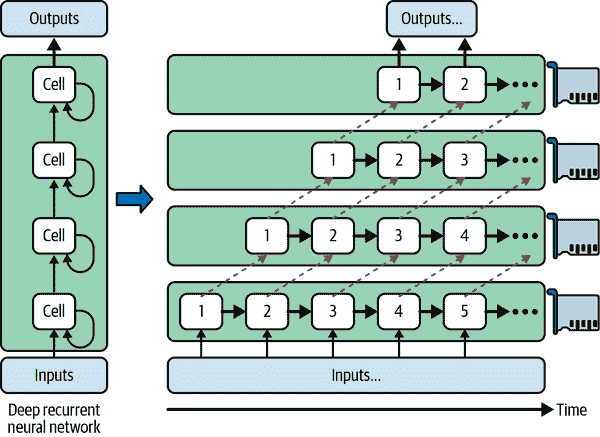
图 19-13。拆分深度递归神经网络
简而言之,模型并行可能会加快某些类型的神经网络的运行或训练速度,但并非所有类型的神经网络都适用,并且需要特别注意和调整,例如确保需要进行通信的设备在同一台机器上运行。接下来我们将看一个更简单且通常更有效的选择:数据并行。
数据并行
另一种并行训练神经网络的方法是在每个设备上复制它,并在所有副本上同时运行每个训练步骤,为每个副本使用不同的小批量。然后对每个副本计算的梯度进行平均,并将结果用于更新模型参数。这被称为数据并行,有时也称为单程序,多数据(SPMD)。这个想法有许多变体,让我们看看最重要的几种。
使用镜像策略的数据并行
可以说,最简单的方法是在所有 GPU 上完全镜像所有模型参数,并始终在每个 GPU 上应用完全相同的参数更新。这样,所有副本始终保持完全相同。这被称为镜像策略,在使用单台机器时特别高效(参见图 19-14)。
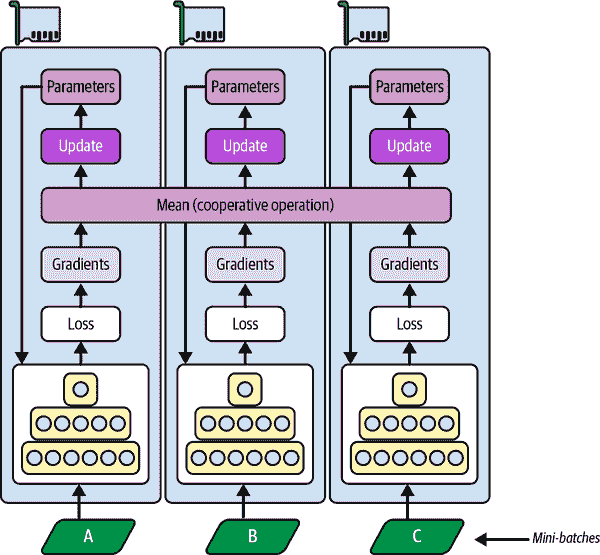
图 19-14. 使用镜像策略的数据并行
使用这种方法的棘手部分是高效地计算所有 GPU 的所有梯度的平均值,并将结果分布到所有 GPU 上。这可以使用AllReduce算法来完成,这是一类算法,多个节点合作以高效地执行reduce 操作(例如计算平均值、总和和最大值),同时确保所有节点获得相同的最终结果。幸运的是,有现成的实现这种算法,您将会看到。
集中式参数的数据并行
另一种方法是将模型参数存储在执行计算的 GPU 设备之外(称为工作器);例如,在 CPU 上(参见图 19-15)。在分布式设置中,您可以将所有参数放在一个或多个仅称为参数服务器的 CPU 服务器上,其唯一作用是托管和更新参数。
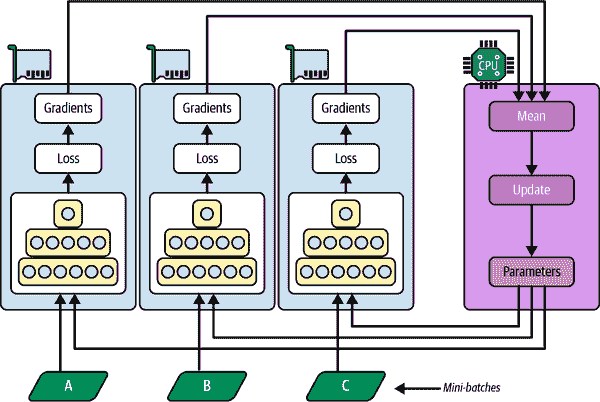
图 19-15. 集中式参数的数据并行
镜像策略强制所有 GPU 上的权重更新同步进行,而这种集中式方法允许同步或异步更新。让我们来看看这两种选择的优缺点。
同步更新
在同步更新中,聚合器会等待所有梯度可用后再计算平均梯度并将其传递给优化器,优化器将更新模型参数。一旦一个副本完成计算其梯度,它必须等待参数更新后才能继续下一个小批量。缺点是一些设备可能比其他设备慢,因此快速设备将不得不在每一步等待慢速设备,使整个过程与最慢设备一样慢。此外,参数将几乎同时复制到每个设备上(在梯度应用后立即),这可能会饱和参数服务器的带宽。
提示
为了减少每个步骤的等待时间,您可以忽略最慢几个副本(通常约 10%)的梯度。例如,您可以运行 20 个副本,但每个步骤只聚合来自最快的 18 个副本的梯度,并忽略最后 2 个的梯度。一旦参数更新,前 18 个副本可以立即开始工作,而无需等待最慢的 2 个副本。这种设置通常被描述为有 18 个副本加上 2 个备用副本。
异步更新
使用异步更新时,每当一个副本完成梯度计算后,梯度立即用于更新模型参数。没有聚合(它删除了“均值”步骤在图 19-15 中)和没有同步。副本独立于其他副本工作。由于不需要等待其他副本,这种方法每分钟可以运行更多的训练步骤。此外,尽管参数仍然需要在每一步复制到每个设备,但对于每个副本,这发生在不同的时间,因此带宽饱和的风险降低了。
使用异步更新的数据并行是一个吸引人的选择,因为它简单、没有同步延迟,并且更好地利用了带宽。然而,尽管在实践中它表现得相当不错,但它能够工作几乎令人惊讶!事实上,当一个副本基于某些参数值计算梯度完成时,这些参数将已经被其他副本多次更新(如果有N个副本,则平均更新N - 1 次),并且无法保证计算出的梯度仍然指向正确的方向(参见图 19-16)。当梯度严重过时时,它们被称为过时梯度:它们可以减慢收敛速度,引入噪声和摆动效应(学习曲线可能包含临时振荡),甚至可能使训练算法发散。
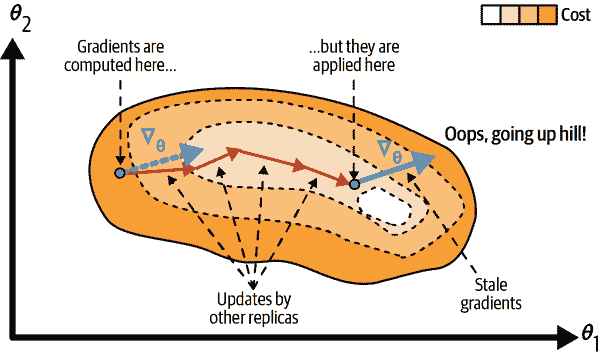
图 19-16。使用异步更新时的过时梯度
有几种方法可以减少陈旧梯度的影响:
-
降低学习率。
-
丢弃陈旧的梯度或将其缩小。
-
调整小批量大小。
-
在开始的几个时期只使用一个副本(这被称为热身阶段)。在训练开始阶段,梯度通常很大,参数还没有稳定在成本函数的谷底,因此陈旧的梯度可能会造成更大的损害,不同的副本可能会将参数推向完全不同的方向。
2016 年,Google Brain 团队发表的一篇论文对各种方法进行了基准测试,发现使用同步更新和一些备用副本比使用异步更新更有效,不仅收敛更快,而且产生了更好的模型。然而,这仍然是一个活跃的研究领域,所以你不应该立刻排除异步更新。
带宽饱和
无论您使用同步还是异步更新,具有集中参数的数据并行仍然需要在每个训练步骤开始时将模型参数从参数服务器传递到每个副本,并在每个训练步骤结束时将梯度传递到另一个方向。同样,当使用镜像策略时,每个 GPU 生成的梯度将需要与每个其他 GPU 共享。不幸的是,通常会出现这样一种情况,即添加额外的 GPU 将不会改善性能,因为将数据移入和移出 GPU RAM(以及在分布式设置中跨网络)所花费的时间将超过通过分割计算负载获得的加速效果。在那一点上,添加更多的 GPU 将只会加剧带宽饱和,并实际上减慢训练速度。
饱和对于大型密集模型来说更严重,因为它们有很多参数和梯度需要传输。对于小型模型来说,饱和程度较轻(但并行化增益有限),对于大型稀疏模型也较轻,因为梯度通常大部分为零,可以有效传输。Google Brain 项目的发起人和负责人 Jeff Dean 报告 在将计算分布到 50 个 GPU 上时,密集模型的典型加速为 25-40 倍,而在 500 个 GPU 上训练稀疏模型时,加速为 300 倍。正如你所看到的,稀疏模型确实更好地扩展。以下是一些具体例子:
-
神经机器翻译:在 8 个 GPU 上加速 6 倍
-
Inception/ImageNet:在 50 个 GPU 上加速 32 倍
-
RankBrain:在 500 个 GPU 上加速 300 倍
有很多研究正在进行,以缓解带宽饱和问题,目标是使训练能够与可用的 GPU 数量成线性比例扩展。例如,卡内基梅隆大学、斯坦福大学和微软研究团队在 2018 年提出了一个名为PipeDream的系统,成功将网络通信减少了 90%以上,使得可以在多台机器上训练大型模型成为可能。他们使用了一种称为管道并行的新技术来实现这一目标,该技术结合了模型并行和数据并行:模型被切分成连续的部分,称为阶段,每个阶段在不同的机器上进行训练。这导致了一个异步的管道,所有机器都在很少的空闲时间内并行工作。在训练过程中,每个阶段交替进行一轮前向传播和一轮反向传播:它从输入队列中提取一个小批量数据,处理它,并将输出发送到下一个阶段的输入队列,然后从梯度队列中提取一个小批量的梯度,反向传播这些梯度并更新自己的模型参数,并将反向传播的梯度推送到前一个阶段的梯度队列。然后它一遍又一遍地重复整个过程。每个阶段还可以独立地使用常规的数据并行(例如使用镜像策略),而不受其他阶段的影响。

图 19-17。PipeDream 的管道并行性
然而,正如在这里展示的那样,PipeDream 不会工作得那么好。要理解原因,考虑在 Figure 19-17 中的第 5 个小批次:当它在前向传递过程中经过第 1 阶段时,来自第 4 个小批次的梯度尚未通过该阶段进行反向传播,但是当第 5 个小批次的梯度流回到第 1 阶段时,第 4 个小批次的梯度将已经被用来更新模型参数,因此第 5 个小批次的梯度将有点过时。正如我们所看到的,这可能会降低训练速度和准确性,甚至使其发散:阶段越多,这个问题就会变得越糟糕。论文的作者提出了缓解这个问题的方法:例如,每个阶段在前向传播过程中保存权重,并在反向传播过程中恢复它们,以确保相同的权重用于前向传递和反向传递。这被称为权重存储。由于这一点,PipeDream 展示了令人印象深刻的扩展能力,远远超出了简单的数据并行性。
这个研究领域的最新突破是由谷歌研究人员在一篇2022 年的论文中发表的:他们开发了一个名为Pathways的系统,利用自动模型并行、异步团队调度等技术,实现了数千个 TPU 几乎 100%的硬件利用率!调度意味着组织每个任务必须运行的时间和位置,团队调度意味着同时并行运行相关任务,并且彼此靠近,以减少任务等待其他任务输出的时间。正如我们在第十六章中看到的,这个系统被用来在超过 6,000 个 TPU 上训练一个庞大的语言模型,几乎实现了 100%的硬件利用率:这是一个令人惊叹的工程壮举。
在撰写本文时,Pathways 尚未公开,但很可能在不久的将来,您将能够使用 Pathways 或类似系统在 Vertex AI 上训练大型模型。与此同时,为了减少饱和问题,您可能会希望使用一些强大的 GPU,而不是大量的弱 GPU,如果您需要在多台服务器上训练模型,您应该将 GPU 分组在少数且连接非常良好的服务器上。您还可以尝试将浮点精度从 32 位(tf.float32)降低到 16 位(tf.bfloat16)。这将减少一半的数据传输量,通常不会对收敛速度或模型性能产生太大影响。最后,如果您正在使用集中式参数,您可以将参数分片(分割)到多个参数服务器上:增加更多的参数服务器将减少每个服务器上的网络负载,并限制带宽饱和的风险。
好的,现在我们已经讨论了所有的理论,让我们实际在多个 GPU 上训练一个模型!
使用分布策略 API 进行规模训练
幸运的是,TensorFlow 带有一个非常好的 API,它负责处理将模型分布在多个设备和机器上的所有复杂性:分布策略 API。要在所有可用的 GPU 上(暂时只在单台机器上)使用数据并行性和镜像策略训练一个 Keras 模型,只需创建一个MirroredStrategy对象,调用它的scope()方法以获取一个分布上下文,并将模型的创建和编译包装在该上下文中。然后正常调用模型的fit()方法:
strategy = tf.distribute.MirroredStrategy()with strategy.scope():model = tf.keras.Sequential([...]) # create a Keras model normallymodel.compile([...]) # compile the model normallybatch_size = 100 # preferably divisible by the number of replicas
model.fit(X_train, y_train, epochs=10,validation_data=(X_valid, y_valid), batch_size=batch_size)
在底层,Keras 是分布感知的,因此在这个MirroredStrategy上下文中,它知道必须在所有可用的 GPU 设备上复制所有变量和操作。如果你查看模型的权重,它们是MirroredVariable类型的:
>>> type(model.weights[0])
tensorflow.python.distribute.values.MirroredVariable
请注意,fit() 方法会自动将每个训练批次在所有副本之间进行分割,因此最好确保批次大小可以被副本数量(即可用的 GPU 数量)整除,以便所有副本获得相同大小的批次。就是这样!训练通常会比使用单个设备快得多,而且代码更改确实很小。
训练模型完成后,您可以使用它高效地进行预测:调用predict()方法,它会自动将批处理在所有副本之间分割,以并行方式进行预测。再次强调,批处理大小必须能够被副本数量整除。如果调用模型的save()方法,它将被保存为常规模型,而不是具有多个副本的镜像模型。因此,当您加载它时,它将像常规模型一样运行,在单个设备上:默认情况下在 GPU#0 上,如果没有 GPU 则在 CPU 上。如果您想加载一个模型并在所有可用设备上运行它,您必须在分发上下文中调用tf.keras.models.load_model():
with strategy.scope():model = tf.keras.models.load_model("my_mirrored_model")
如果您只想使用所有可用 GPU 设备的子集,您可以将列表传递给MirroredStrategy的构造函数:
strategy = tf.distribute.MirroredStrategy(devices=["/gpu:0", "/gpu:1"])
默认情况下,MirroredStrategy类使用NVIDIA Collective Communications Library(NCCL)进行 AllReduce 均值操作,但您可以通过将cross_device_ops参数设置为tf.distribute.HierarchicalCopyAllReduce类的实例或tf.distribute.ReductionToOneDevice类的实例来更改它。默认的 NCCL 选项基于tf.distribute.NcclAllReduce类,通常更快,但这取决于 GPU 的数量和类型,因此您可能想尝试一下其他选择。
如果您想尝试使用集中式参数的数据并行性,请将MirroredStrategy替换为CentralStorageStrategy:
strategy = tf.distribute.experimental.CentralStorageStrategy()
您可以选择设置compute_devices参数来指定要用作工作器的设备列表-默认情况下将使用所有可用的 GPU-您还可以选择设置parameter_device参数来指定要存储参数的设备。默认情况下将使用 CPU,或者如果只有一个 GPU,则使用 GPU。
现在让我们看看如何在一组 TensorFlow 服务器上训练模型!
在 TensorFlow 集群上训练模型
TensorFlow 集群是一组在并行运行的 TensorFlow 进程,通常在不同的机器上,并相互通信以完成一些工作,例如训练或执行神经网络模型。集群中的每个 TF 进程被称为任务或TF 服务器。它有一个 IP 地址,一个端口和一个类型(也称为角色或工作)。类型可以是"worker"、"chief"、"ps"(参数服务器)或"evaluator":
-
每个worker执行计算,通常在一台或多台 GPU 的机器上。
-
首席执行计算任务(它是一个工作者),但也处理额外的工作,比如编写 TensorBoard 日志或保存检查点。集群中只有一个首席。如果没有明确指定首席,则按照惯例第一个工作者就是首席。
-
参数服务器只跟踪变量值,并且通常在仅有 CPU 的机器上。这种类型的任务只能与
ParameterServerStrategy一起使用。 -
评估者显然负责评估。这种类型并不经常使用,当使用时,通常只有一个评估者。
要启动一个 TensorFlow 集群,必须首先定义其规范。这意味着定义每个任务的 IP 地址、TCP 端口和类型。例如,以下集群规范定义了一个有三个任务的集群(两个工作者和一个参数服务器;参见图 19-18)。集群规范是一个字典,每个作业对应一个键,值是任务地址(IP:port)的列表:
cluster_spec = {"worker": ["machine-a.example.com:2222", # /job:worker/task:0"machine-b.example.com:2222" # /job:worker/task:1],"ps": ["machine-a.example.com:2221"] # /job:ps/task:0
}
通常每台机器上会有一个任务,但正如这个示例所示,如果需要,您可以在同一台机器上配置多个任务。在这种情况下,如果它们共享相同的 GPU,请确保 RAM 适当分配,如前面讨论的那样。
警告
默认情况下,集群中的每个任务可以与其他任务通信,因此请确保配置防火墙以授权这些机器之间这些端口上的所有通信(如果每台机器使用相同的端口,则通常更简单)。
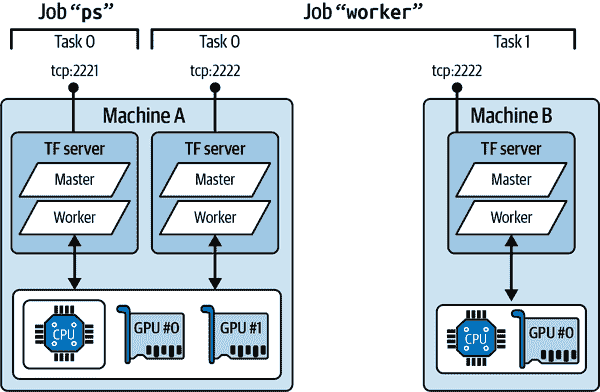
图 19-18。一个示例 TensorFlow 集群
当您开始一个任务时,您必须给它指定集群规范,并且还必须告诉它它的类型和索引是什么(例如,worker #0)。一次性指定所有内容的最简单方法(包括集群规范和当前任务的类型和索引)是在启动 TensorFlow 之前设置TF_CONFIG环境变量。它必须是一个 JSON 编码的字典,包含集群规范(在"cluster"键下)和当前任务的类型和索引(在"task"键下)。例如,以下TF_CONFIG环境变量使用我们刚刚定义的集群,并指定要启动的任务是 worker #0:
os.environ["TF_CONFIG"] = json.dumps({"cluster": cluster_spec,"task": {"type": "worker", "index": 0}
})
提示
通常您希望在 Python 之外定义TF_CONFIG环境变量,这样代码就不需要包含当前任务的类型和索引(这样可以在所有工作节点上使用相同的代码)。
现在让我们在集群上训练一个模型!我们将从镜像策略开始。首先,您需要为每个任务适当设置TF_CONFIG环境变量。集群规范中不应该有参数服务器(删除集群规范中的"ps"键),通常每台机器上只需要一个工作节点。确保为每个任务设置不同的任务索引。最后,在每个工作节点上运行以下脚本:
import tempfile
import tensorflow as tfstrategy = tf.distribute.MultiWorkerMirroredStrategy() # at the start!
resolver = tf.distribute.cluster_resolver.TFConfigClusterResolver()
print(f"Starting task {resolver.task_type} #{resolver.task_id}")
[...] # load and split the MNIST datasetwith strategy.scope():model = tf.keras.Sequential([...]) # build the Keras modelmodel.compile([...]) # compile the modelmodel.fit(X_train, y_train, validation_data=(X_valid, y_valid), epochs=10)if resolver.task_id == 0: # the chief saves the model to the right locationmodel.save("my_mnist_multiworker_model", save_format="tf")
else:tmpdir = tempfile.mkdtemp() # other workers save to a temporary directorymodel.save(tmpdir, save_format="tf")tf.io.gfile.rmtree(tmpdir) # and we can delete this directory at the end!
这几乎是您之前使用的相同代码,只是这次您正在使用MultiWorkerMirroredStrategy。当您在第一个工作节点上启动此脚本时,它们将在 AllReduce 步骤处保持阻塞,但是一旦最后一个工作节点启动,训练将开始,并且您将看到它们以完全相同的速度前进,因为它们在每一步都进行同步。
警告
在使用MultiWorkerMirroredStrategy时,重要的是确保所有工作人员做同样的事情,包括保存模型检查点或编写 TensorBoard 日志,即使您只保留主要写入的内容。这是因为这些操作可能需要运行 AllReduce 操作,因此所有工作人员必须保持同步。
这个分发策略有两种 AllReduce 实现方式:基于 gRPC 的环形 AllReduce 算法用于网络通信,以及 NCCL 的实现。要使用哪种最佳算法取决于工作人员数量、GPU 数量和类型,以及网络情况。默认情况下,TensorFlow 会应用一些启发式方法为您选择合适的算法,但您可以强制使用 NCCL(或 RING)如下:
strategy = tf.distribute.MultiWorkerMirroredStrategy(communication_options=tf.distribute.experimental.CommunicationOptions(implementation=tf.distribute.experimental.CollectiveCommunication.NCCL))
如果您希望使用参数服务器实现异步数据并行处理,请将策略更改为ParameterServerStrategy,添加一个或多个参数服务器,并为每个任务适当配置TF_CONFIG。请注意,虽然工作人员将异步工作,但每个工作人员上的副本将同步工作。
最后,如果您可以访问Google Cloud 上的 TPU——例如,如果您在 Colab 中设置加速器类型为 TPU——那么您可以像这样创建一个TPUStrategy:
resolver = tf.distribute.cluster_resolver.TPUClusterResolver()
tf.tpu.experimental.initialize_tpu_system(resolver)
strategy = tf.distribute.experimental.TPUStrategy(resolver)
这需要在导入 TensorFlow 后立即运行。然后您可以正常使用这个策略。
提示
如果您是研究人员,您可能有资格免费使用 TPU;请查看https://tensorflow.org/tfrc获取更多详细信息。
现在您可以跨多个 GPU 和多个服务器训练模型:给自己一个鼓励!然而,如果您想训练一个非常大的模型,您将需要许多 GPU,跨多个服务器,这将要求要么购买大量硬件,要么管理大量云虚拟机。在许多情况下,使用一个云服务来为您提供所有这些基础设施的配置和管理会更方便、更经济,只有在您需要时才会提供。让我们看看如何使用 Vertex AI 来实现这一点。
在 Vertex AI 上运行大型训练作业
Vertex AI 允许您使用自己的训练代码创建自定义训练作业。实际上,您可以几乎使用与在自己的 TF 集群上使用的相同的训练代码。您必须更改的主要内容是首席应该保存模型、检查点和 TensorBoard 日志的位置。首席必须将模型保存到 GCS,使用 Vertex AI 在AIP_MODEL_DIR环境变量中提供的路径,而不是将模型保存到本地目录。对于模型检查点和 TensorBoard 日志,您应该分别使用AIP_CHECKPOINT_DIR和AIP_TENSORBOARD_LOG_DIR环境变量中包含的路径。当然,您还必须确保训练数据可以从虚拟机访问,例如在 GCS 上,或者从另一个 GCP 服务(如 BigQuery)或直接从网络上访问。最后,Vertex AI 明确设置了"chief"任务类型,因此您应该使用resolved.task_type == "chief"来识别首席,而不是使用resolved.task_id == 0:
import os
[...] # other imports, create MultiWorkerMirroredStrategy, and resolverif resolver.task_type == "chief":model_dir = os.getenv("AIP_MODEL_DIR") # paths provided by Vertex AItensorboard_log_dir = os.getenv("AIP_TENSORBOARD_LOG_DIR")checkpoint_dir = os.getenv("AIP_CHECKPOINT_DIR")
else:tmp_dir = Path(tempfile.mkdtemp()) # other workers use temporary dirsmodel_dir = tmp_dir / "model"tensorboard_log_dir = tmp_dir / "logs"checkpoint_dir = tmp_dir / "ckpt"callbacks = [tf.keras.callbacks.TensorBoard(tensorboard_log_dir),tf.keras.callbacks.ModelCheckpoint(checkpoint_dir)]
[...] # build and compile using the strategy scope, just like earlier
model.fit(X_train, y_train, validation_data=(X_valid, y_valid), epochs=10,callbacks=callbacks)
model.save(model_dir, save_format="tf")
提示
如果您将训练数据放在 GCS 上,您可以创建一个tf.data.TextLineDataset或tf.data.TFRecordDataset来访问它:只需将 GCS 路径作为文件名(例如,gs://my_bucket/data/001.csv)。这些数据集依赖于tf.io.gfile包来访问文件:它支持本地文件和 GCS 文件。
现在您可以在 Vertex AI 上基于这个脚本创建一个自定义训练作业。您需要指定作业名称、训练脚本的路径、用于训练的 Docker 镜像、用于预测的镜像(训练后)、您可能需要的任何其他 Python 库,以及最后 Vertex AI 应该使用作为存储训练脚本的暂存目录的存储桶。默认情况下,这也是训练脚本将保存训练模型、TensorBoard 日志和模型检查点(如果有的话)的地方。让我们创建这个作业:
custom_training_job = aiplatform.CustomTrainingJob(display_name="my_custom_training_job",script_path="my_vertex_ai_training_task.py",container_uri="gcr.io/cloud-aiplatform/training/tf-gpu.2-4:latest",model_serving_container_image_uri=server_image,requirements=["gcsfs==2022.3.0"], # not needed, this is just an examplestaging_bucket=f"gs://{bucket_name}/staging"
)
现在让我们在两个拥有两个 GPU 的工作节点上运行它:
mnist_model2 = custom_training_job.run(machine_type="n1-standard-4",replica_count=2,accelerator_type="NVIDIA_TESLA_K80",accelerator_count=2,
)
这就是全部内容:Vertex AI 将为您请求的计算节点进行配置(在您的配额范围内),并在这些节点上运行您的训练脚本。一旦作业完成,run()方法将返回一个经过训练的模型,您可以像之前创建的那样使用它:您可以部署到端点,或者用它进行批量预测。如果在训练过程中出现任何问题,您可以在 GCP 控制台中查看日志:在☰导航菜单中,选择 Vertex AI → 训练,点击您的训练作业,然后点击查看日志。或者,您可以点击自定义作业选项卡,复制作业的 ID(例如,1234),然后从☰导航菜单中选择日志记录,并查询resource.labels.job_id=1234。
提示
要可视化训练进度,只需启动 TensorBoard,并将其--logdir指向日志的 GCS 路径。它将使用应用程序默认凭据,您可以使用gcloud auth application-default login进行设置。如果您喜欢,Vertex AI 还提供托管的 TensorBoard 服务器。
如果您想尝试一些超参数值,一个选项是运行多个作业。您可以通过在调用run()方法时设置args参数将超参数值作为命令行参数传递给您的脚本,或者您可以使用environment_variables参数将它们作为环境变量传递。
然而,如果您想在云上运行一个大型的超参数调整作业,一个更好的选择是使用 Vertex AI 的超参数调整服务。让我们看看如何做。
Vertex AI 上的超参数调整
Vertex AI 的超参数调整服务基于贝叶斯优化算法,能够快速找到最佳的超参数组合。要使用它,首先需要创建一个接受超参数值作为命令行参数的训练脚本。例如,您的脚本可以像这样使用argparse标准库:
import argparseparser = argparse.ArgumentParser()
parser.add_argument("--n_hidden", type=int, default=2)
parser.add_argument("--n_neurons", type=int, default=256)
parser.add_argument("--learning_rate", type=float, default=1e-2)
parser.add_argument("--optimizer", default="adam")
args = parser.parse_args()
超参数调整服务将多次调用您的脚本,每次使用不同的超参数值:每次运行称为trial,一组试验称为study。然后,您的训练脚本必须使用给定的超参数值来构建和编译模型。如果需要,您可以使用镜像分发策略,以便每个试验在多 GPU 机器上运行。然后脚本可以加载数据集并训练模型。例如:
import tensorflow as tfdef build_model(args):with tf.distribute.MirroredStrategy().scope():model = tf.keras.Sequential()model.add(tf.keras.layers.Flatten(input_shape=[28, 28], dtype=tf.uint8))for _ in range(args.n_hidden):model.add(tf.keras.layers.Dense(args.n_neurons, activation="relu"))model.add(tf.keras.layers.Dense(10, activation="softmax"))opt = tf.keras.optimizers.get(args.optimizer)opt.learning_rate = args.learning_ratemodel.compile(loss="sparse_categorical_crossentropy", optimizer=opt,metrics=["accuracy"])return model[...] # load the dataset
model = build_model(args)
history = model.fit([...])
提示
您可以使用我们之前提到的AIP_*环境变量来确定在哪里保存检查点、TensorBoard 日志和最终模型。
最后,脚本必须将模型的性能报告给 Vertex AI 的超参数调整服务,以便它决定尝试哪些超参数。为此,您必须使用hypertune库,在 Vertex AI 训练 VM 上自动安装:
import hypertunehypertune = hypertune.HyperTune()
hypertune.report_hyperparameter_tuning_metric(hyperparameter_metric_tag="accuracy", # name of the reported metricmetric_value=max(history.history["val_accuracy"]), # metric valueglobal_step=model.optimizer.iterations.numpy(),
)
现在您的训练脚本已准备就绪,您需要定义要在其上运行的机器类型。为此,您必须定义一个自定义作业,Vertex AI 将使用它作为每个试验的模板:
trial_job = aiplatform.CustomJob.from_local_script(display_name="my_search_trial_job",script_path="my_vertex_ai_trial.py", # path to your training scriptcontainer_uri="gcr.io/cloud-aiplatform/training/tf-gpu.2-4:latest",staging_bucket=f"gs://{bucket_name}/staging",accelerator_type="NVIDIA_TESLA_K80",accelerator_count=2, # in this example, each trial will have 2 GPUs
)
最后,您准备好创建并运行超参数调整作业:
from google.cloud.aiplatform import hyperparameter_tuning as hpthp_job = aiplatform.HyperparameterTuningJob(display_name="my_hp_search_job",custom_job=trial_job,metric_spec={"accuracy": "maximize"},parameter_spec={"learning_rate": hpt.DoubleParameterSpec(min=1e-3, max=10, scale="log"),"n_neurons": hpt.IntegerParameterSpec(min=1, max=300, scale="linear"),"n_hidden": hpt.IntegerParameterSpec(min=1, max=10, scale="linear"),"optimizer": hpt.CategoricalParameterSpec(["sgd", "adam"]),},max_trial_count=100,parallel_trial_count=20,
)
hp_job.run()
在这里,我们告诉 Vertex AI 最大化名为 "accuracy" 的指标:这个名称必须与训练脚本报告的指标名称匹配。我们还定义了搜索空间,使用对数尺度来设置学习率,使用线性(即均匀)尺度来设置其他超参数。超参数的名称必须与训练脚本的命令行参数匹配。然后我们将最大试验次数设置为 100,同时最大并行运行的试验次数设置为 20。如果你将并行试验的数量增加到(比如)60,总搜索时间将显著减少,最多可减少到 3 倍。但前 60 个试验将同时开始,因此它们将无法从其他试验的反馈中受益。因此,您应该增加最大试验次数来补偿,例如增加到大约 140。
这将需要相当长的时间。一旦作业完成,您可以使用 hp_job.trials 获取试验结果。每个试验结果都表示为一个 protobuf 对象,包含超参数值和结果指标。让我们找到最佳试验:
def get_final_metric(trial, metric_id):for metric in trial.final_measurement.metrics:if metric.metric_id == metric_id:return metric.valuetrials = hp_job.trials
trial_accuracies = [get_final_metric(trial, "accuracy") for trial in trials]
best_trial = trials[np.argmax(trial_accuracies)]
现在让我们看看这个试验的准确率,以及其超参数值:
>>> max(trial_accuracies)
0.977400004863739
>>> best_trial.id
'98'
>>> best_trial.parameters
[parameter_id: "learning_rate" value { number_value: 0.001 },parameter_id: "n_hidden" value { number_value: 8.0 },parameter_id: "n_neurons" value { number_value: 216.0 },parameter_id: "optimizer" value { string_value: "adam" }
]
就是这样!现在您可以获取这个试验的 SavedModel,可选择性地再训练一下,并将其部署到生产环境中。
提示
Vertex AI 还包括一个 AutoML 服务,完全负责为您找到合适的模型架构并为您进行训练。您只需要将数据集以特定格式上传到 Vertex AI,这取决于数据集的类型(图像、文本、表格、视频等),然后创建一个 AutoML 训练作业,指向数据集并指定您愿意花费的最大计算小时数。请参阅笔记本中的示例。
现在你拥有了所有需要创建最先进的神经网络架构并使用各种分布策略进行规模化训练的工具和知识,可以在自己的基础设施或云上部署它们,然后在任何地方部署它们。换句话说,你现在拥有超能力:好好利用它们!
练习
-
SavedModel 包含什么?如何检查其内容?
-
什么时候应该使用 TF Serving?它的主要特点是什么?有哪些工具可以用来部署它?
-
如何在多个 TF Serving 实例上部署模型?
-
在查询由 TF Serving 提供的模型时,何时应该使用 gRPC API 而不是 REST API?
-
TFLite 通过哪些不同的方式减小模型的大小,使其能在移动设备或嵌入式设备上运行?
-
什么是量化感知训练,为什么需要它?
-
什么是模型并行和数据并行?为什么通常推荐后者?
-
在多台服务器上训练模型时,您可以使用哪些分发策略?您如何选择使用哪种?
-
训练一个模型(任何您喜欢的模型)并部署到 TF Serving 或 Google Vertex AI。编写客户端代码,使用 REST API 或 gRPC API 查询它。更新模型并部署新版本。您的客户端代码现在将查询新版本。回滚到第一个版本。
-
在同一台机器上使用
MirroredStrategy在多个 GPU 上训练任何模型(如果您无法访问 GPU,可以使用带有 GPU 运行时的 Google Colab 并创建两个逻辑 GPU)。再次使用CentralStorageStrategy训练模型并比较训练时间。 -
在 Vertex AI 上微调您选择的模型,使用 Keras Tuner 或 Vertex AI 的超参数调整服务。
这些练习的解决方案可以在本章笔记本的末尾找到,网址为https://homl.info/colab3。
谢谢!
在我们结束这本书的最后一章之前,我想感谢您读到最后一段。我真诚地希望您阅读这本书和我写作时一样开心,并且它对您的项目,无论大小,都有用。
如果您发现错误,请发送反馈。更一般地,我很想知道您的想法,所以请不要犹豫通过 O’Reilly、ageron/handson-ml3 GitHub 项目或 Twitter 上的@aureliengeron 与我联系。
继续前进,我给你的最好建议是练习和练习:尝试完成所有的练习(如果你还没有这样做),玩一下笔记本电脑,加入 Kaggle 或其他机器学习社区,观看机器学习课程,阅读论文,参加会议,与专家会面。事情发展迅速,所以尽量保持最新。一些 YouTube 频道定期以非常易懂的方式详细介绍深度学习论文。我特别推荐 Yannic Kilcher、Letitia Parcalabescu 和 Xander Steenbrugge 的频道。要了解引人入胜的机器学习讨论和更高层次的见解,请务必查看 ML Street Talk 和 Lex Fridman 的频道。拥有一个具体的项目要去做也会极大地帮助,无论是为了工作还是为了娱乐(最好两者兼顾),所以如果你一直梦想着建造某样东西,就试一试吧!逐步工作;不要立即朝着月球开火,而是专注于你的项目,一步一步地构建它。这需要耐心和毅力,但当你拥有一个行走的机器人,或一个工作的聊天机器人,或者其他你喜欢的任何东西时,这将是极其有益的!
我最大的希望是这本书能激发你构建一个美妙的 ML 应用程序,使我们所有人受益。它会是什么样的?
—Aurélien Géron
¹ A/B 实验包括在不同的用户子集上测试产品的两个不同版本,以检查哪个版本效果最好并获得其他见解。
² Google AI 平台(以前称为 Google ML 引擎)和 Google AutoML 在 2021 年合并为 Google Vertex AI。
³ REST(或 RESTful)API 是一种使用标准 HTTP 动词(如 GET、POST、PUT 和 DELETE)以及使用 JSON 输入和输出的 API。gRPC 协议更复杂但更高效;数据使用协议缓冲区进行交换(参见第十三章)。
如果您对 Docker 不熟悉,它允许您轻松下载一组打包在Docker 镜像中的应用程序(包括所有依赖项和通常一些良好的默认配置),然后使用Docker 引擎在您的系统上运行它们。当您运行一个镜像时,引擎会创建一个保持应用程序与您自己系统良好隔离的Docker 容器,但如果您愿意,可以给它一些有限的访问权限。它类似于虚拟机,但速度更快、更轻,因为容器直接依赖于主机的内核。这意味着镜像不需要包含或运行自己的内核。
还有 GPU 镜像可用,以及其他安装选项。有关更多详细信息,请查看官方安装说明。
公平地说,这可以通过首先序列化数据,然后将其编码为 Base64,然后创建 REST 请求来减轻。此外,REST 请求可以使用 gzip 进行压缩,从而显著减少有效负载大小。
还要查看 TensorFlow 的Graph Transform Tool,用于修改和优化计算图。
例如,PWA 必须包含不同移动设备大小的图标,必须通过 HTTPS 提供,必须包含包含应用程序名称和背景颜色等元数据的清单文件。
请查看 TensorFlow 文档,获取详细和最新的安装说明,因为它们经常更改。
¹⁰ 正如我们在第十二章中所看到的,内核是特定数据类型和设备类型的操作实现。例如,float32 tf.matmul() 操作有一个 GPU 内核,但 int32 tf.matmul() 没有 GPU 内核,只有一个 CPU 内核。
¹¹ 您还可以使用 tf.debugging.set_log_device_placement(True) 来记录所有设备放置情况。
¹² 如果您想要保证完美的可重现性,这可能很有用,正如我在这个视频中所解释的,基于 TF 1。
¹³ 在撰写本文时,它只是将数据预取到 CPU RAM,但使用 tf.data.experimental.prefetch_to_device() 可以使其预取数据并将其推送到您选择的设备,以便 GPU 不必等待数据传输而浪费时间。
如果两个 CNN 相同,则称为孪生神经网络。
如果您对模型并行性感兴趣,请查看Mesh TensorFlow。
这个名字有点令人困惑,因为听起来好像有些副本是特殊的,什么也不做。实际上,所有副本都是等价的:它们都努力成为每个训练步骤中最快的,失败者在每一步都会变化(除非某些设备真的比其他设备慢)。但是,这意味着如果一个或两个服务器崩溃,训练将继续进行得很好。
Jianmin Chen 等人,“重新审视分布式同步 SGD”,arXiv 预印本 arXiv:1604.00981(2016)。
¹⁸ Aaron Harlap 等人,“PipeDream: 快速高效的管道并行 DNN 训练”,arXiv 预印本 arXiv:1806.03377(2018)。
¹⁹ Paul Barham 等人,“Pathways: 异步分布式数据流 ML”,arXiv 预印本 arXiv:2203.12533(2022)。
²⁰ 有关 AllReduce 算法的更多详细信息,请阅读 Yuichiro Ueno 的文章,该文章介绍了深度学习背后的技术,以及 Sylvain Jeaugey 的文章,该文章介绍了如何使用 NCCL 大规模扩展深度学习训练。