Spark系列文章:
大数据 - Spark系列《一》- 从Hadoop到Spark:大数据计算引擎的演进-CSDN博客
大数据 - Spark系列《二》- 关于Spark在Idea中的一些常用配置-CSDN博客
目录
3.1🧀加载文件(本地)
1. 加载本地文件路径
🌮使用textFile加载本地txt文件
🌮使用textFile加载本地json文件
🌮使用sequenceFile加载本地二进制文件
🌮HDFS也可以 (hdfs://doe01:8020/data/wds/)
3.2 🧀本地集合(测试)
3.3 🧀加载mysql
1. 🌮环境准备
2. 🌮创建Spark应用程序
3.1🧀加载文件(本地)
1. 加载本地文件路径
-
🌮使用textFile加载本地txt文件
-
🌮使用textFile加载本地json文件
-
🌮使用sequenceFile加载本地二进制文件
二进制文件加载后的RDD中每个元素都是一个键值对,其中键和值的类型由用户指定。
/*** 加载文本文件 创建RDD* 参数1 文件路径* 参数2 最小分区数 默认2* RDD = 迭代器+分区信息 一行一行的迭代数据*/
// 从本地文件系统加载(只适用于开发测试)
val rdd: RDD[String] = sc.textFile("local/path/to/text/file", 2)
val rdd: RDD[String] = sc.textFile("local/path/to/json/file", 2)//-------------------------------------------------
// User.class asInstanceOf
val res = sc.sequenceFile("local/path/to/binary/file", classOf[String], classOf[Int])
// 其中第一个参数是文件路径,第二个参数是键的类型,第三个参数是值的类型。-
🌮HDFS也可以 (hdfs://doe01:8020/data/wds/)
// 从HDFS文件系统加载(对应绝大多数生产应用场景)
val data: RDD[String] = sc.textFile("hdfs://hadoop01:8020/data/words/", 2)
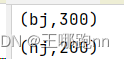
data.foreach(println)🥙练习1:使用textFile加载本地txt文件 - 统计每个城市下订单总额
//数据:orders.txt
oid01,100,bj
oid02,100,bj
oid03,100,bj
oid04,100,nj
oid05,100,njpackage com.doit.day0130import org.apache.spark.{SparkConf, SparkContext}/*** @日期: 2024/1/31* @Author: Wang NaPao* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343* @Tips: 和我一起学习吧* @Description: Spark应用程序入口,用于计算订单数据中各个城市的订单总金额*/object StartGetting {def main(args: Array[String]): Unit = {// 创建SparkConf对象,并设置应用程序名称和运行模式val conf = new SparkConf().setAppName("Starting...") // 设置应用程序名称.setMaster("local[*]") // 设置运行模式为本地模式// 创建SparkContext对象,并传入SparkConf对象val sc = new SparkContext(conf)// 加载订单数据val rdd1 = sc.textFile("data/orders.txt")// 将订单数据转换为键值对(city, amount),其中city为键,amount为值val rdd2 = rdd1.map(line => {val arr = line.split(",")(arr(2), arr(1))})// 根据城市对订单数据进行分组val rdd3 = rdd2.groupBy(_._1)// 计算每个城市的订单总金额val rdd4 = rdd3.map(tp => {val city = tp._1val sum = tp._2.map(_._2.toInt).sum(city, sum)})// 将结果保存到输出文件中rdd4.saveAsTextFile("data/citysum_output")// 将结果保存并保存为sequenceFile文件rdd4.saveAsTextFile("data/citysum_output_seq")// 关闭SparkContext对象,释放资源sc.stop()}
}结果:
🥙练习2:使用textFile加载本地json文件 - 去获取每部电影的平均分
Spark-关于Json数据格式的数据的处理与练习
🥙练习3:使用sequenceFile加载本地二进制文件(练习1出来的结果data/citysum_output_seq) - 将seq文件的数据转换为Object对象,并打印出所有的城市
// 城市对象类
case class CityObj(// 城市名称city: String,// 数量num: Int)package com.doit.day0201import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.log4j.{Level, Logger}
import org.apache.hadoop.io.Text
import org.apache.hadoop.io.IntWritable/*** @日期: 2024/2/1* @Author: Wang NaPao* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343* @Tips: 和我一起学习吧* @Description:*/object Test01 {def main(args: Array[String]): Unit = {// 创建SparkConf对象,并设置应用程序名称和运行模式val conf = new SparkConf().setAppName("Starting...") // 设置应用程序名称.setMaster("local[*]") // 设置运行模式为本地模式// 创建SparkContext对象,并传入SparkConf对象val sc = new SparkContext(conf)Logger.getLogger("org.apache.spark").setLevel(Level.WARN)//sequenceFile 就是序列化文件 K-V K-V K1-V1 【序列化】// 加载 Sequence 文件并创建 RDDval rdd1 = sc.sequenceFile("data/citysum_output_seq/", classOf[Text], classOf[IntWritable])val newrdd = sc.sequenceFile[String, Int]("data/citysum_output_seq/", 2)newrdd.foreach(println)// 转换为对象并提取城市数据val cities = rdd1.map { case (textKey, intValue) =>// 将 Hadoop 的 Text 对象和 IntWritable 对象转换为 Scala 字符串和整数val city = textKey.toStringval count = intValue.get()// 创建 CityObj 对象CityObj(city, count)}// 提取并打印所有城市val uniqueCities = cities.map(_.city).foreach(println)sc.stop()}
}结果:

注意点:
类型匹配:
sequenceFile方法需要指定键和值的类型参数,这些类型应该与文件中实际的数据类型匹配。通常情况下,键和值的类型会使用 Hadoop 库中的数据类型,如Text、IntWritable等。类型转换:在处理文件数据时,需要将 Hadoop 的
Text类型转换为 Scala 的String类型,将IntWritable类型转换为 Scala 的Int类型。
🥙练习4:使用textFile加载hdfs txt文件 - 每个字母代表一个人 , 统计任意一个人和其他人的共同好友
//数据:f.txt
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,Jpackage com.doit.day0201import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.log4j.{Level, Logger}
import org.apache.hadoop.io.Text
import org.apache.hadoop.io.IntWritable/*** @日期: 2024/2/2* @Author: Wang NaPao* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343* @Tips: 和我一起学习吧* @Description: 实现统计每个人与其他人的共同好友*/object Test02 {def main(args: Array[String]): Unit = {// 创建SparkConf对象,并设置应用程序名称和运行模式val conf = new SparkConf().setAppName("Starting...") // 设置应用程序名称.setMaster("local[*]") // 设置运行模式为本地模式// 创建SparkContext对象,并传入SparkConf对象val sc = new SparkContext(conf)// 从HDFS读取数据创建RDDval rdd1 = sc.textFile("hdfs://hadoop01:8020/spark/data/f.txt", 2)// 对每行数据进行处理,生成以每个人为key,其好友为value的RDDval rdd2: RDD[(String, String)] = rdd1.flatMap(line => {val arr1 = line.split(":")val name = arr1(0)val arr2 = arr1(1).split(",")arr2.map(tp => (name, tp))})// 将数据按照每个人分组,形成键值对的RDD,键为人名,值为其好友列表val rdd3 = rdd2.groupBy(_._1)// 转换RDD结构,将Iterable转换为Listval rdd4 = rdd3.map(tp => {val name = tp._1val fr: Iterable[String] = tp._2.map(_._2)(name, fr)})// 将RDD转换为Listval list: List[(String, Iterable[String])] = rdd4.collect().toList// 遍历List中的每个元素,计算交集for (i <- 0 to list.size; j <- i + 1 to list.size) {val tuple: (String, Iterable[String]) = list(i)val tuple1 = list(j)// 计算两人好友列表的交集val v3 = tuple._2.toList.intersect(tuple1._2.toList)println(s"${tuple._1}与${tuple1._1}的交集为" + v3)}// 关闭SparkContextsc.stop()}
}结果:

3.2 🧀本地集合(测试)
在Spark中,makeRDD方法用于将本地集合或序列转换为RDD。它接受一个Seq类型的集合作为参数,并可选地接受一个表示分区数量的整数参数。
-
默认分区 环境的所有可用核数
-
创建的时候可以通过参数设置分区
package com.doit.day0201import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.log4j.{Level, Logger}
import org.apache.hadoop.io.Text
import org.apache.hadoop.io.IntWritableimport scala.collection.mutable/*** @日期: 2024/2/4* @Author: Wang NaPao* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343* @Tips: 和我一起学习吧* @Description: 示例RDD的创建和并行度设置*/// 定义一个城市对象,包含城市名和人口数量
case class CityObj(name: String, population: Int)object Test04 {def main(args: Array[String]): Unit = {// 创建SparkConf对象,并设置应用程序名称和运行模式val conf = new SparkConf().setAppName("Starting...") // 设置应用程序名称.setMaster("local[*]") // 设置运行模式为本地模式// 创建SparkContext对象,并传入SparkConf对象val sc = new SparkContext(conf)// 创建一个List集合,包含城市对象val city = List(CityObj("shanghai", 5000000),CityObj("beijing", 9800000),CityObj("nanjing", 5500000))// 将List集合直接转换为RDD,默认并行度为所有可用核数val rdd1 = sc.makeRDD(city)// 将List集合转换为RDD,并指定并行度为2val rdd2 = sc.makeRDD(city, 2)// 打印RDD的分区数println(rdd1.getNumPartitions) // 16println(rdd2.getNumPartitions) // 2// 创建一个可变的HashMap,包含姓名和年龄val map = mutable.HashMap[String, Int](("zss", 23), "lss" -> 33)// HashMap不可以直接传入makeRDD,需要先转换为List再传入val rdd3 = sc.makeRDD(map.toList)// 打印RDD的分区数println(rdd3.getNumPartitions) // 16// 关闭SparkContextsc.stop()}
}HashMap不可直接使用makeRDD方法
对于HashMap类型的集合,由于其不是
Seq的子类,因此无法直接使用makeRDD方法进行转换。通常情况下,可以先将HashMap转换为List,再使用makeRDD方法,示例如下:val map = mutable.HashMap[String, Int](("zss", 23), "lss" -> 33) // HashMap不可以直接传入makeRDD,需要先转换为List再传入 val rdd3 = sc.makeRDD(map.toList)
3.3 🧀加载mysql
1. 🌮环境准备
在开始之前,需要确保以下环境已经准备好:
-
Spark环境:确保已经安装和配置了Spark,并且可以正常运行Spark应用程序。
-
MySQL数据库:确保MySQL数据库已经安装并且可以访问。需要提供数据库连接地址、用户名和密码。
//创建表和插入数据
CREATE TABLE `salary` (`empid` int NOT NULL,`basesalary` double DEFAULT NULL,`titlesalary` double DEFAULT NULL,`deduction` double DEFAULT NULL,PRIMARY KEY (`empid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;INSERT INTO `salary` (`empid`, `basesalary`, `titlesalary`, `deduction`) VALUES
(1001, 2200, 1100, 200),
(1002, 1200, 200, NULL),
(1003, 2900, 700, 200),
(1004, 1950, 700, 150);
-
在pom.xml里面添加mysql依赖
<!-- https://mvnrepository.com/artifact/com.mysql/mysql-connector-j -->
<dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><version>8.2.0</version>
</dependency>2. 🌮创建Spark应用程序
使用JdbcRDD从MySQL数据库读取数据,需要注意以下几个关键参数:
1)SparkContext 对象 (sc): 这是 Spark 应用程序的主要入口点,需要传递给 JdbcRDD 构造函数。
2)数据库连接函数 (conn): 这是一个无参数的函数,用于获取数据库连接。在函数体内,应该使用 DriverManager.getConnection 方法来获取数据库连接,并指定数据库的连接地址、用户名和密码。
3)查询 SQL 语句 (sql): 这是用于执行数据库查询的 SQL 语句。你可以在 SQL 语句中使用占位符(?)来表示查询参数,后续会通过 JdbcRDD 的其他参数来提供具体的查询范围。
4)查询参数范围: 通过指定起始和结束的查询参数值来定义查询范围。这些参数值会传递给 SQL 语句中的占位符,以便在查询时动态指定查询条件。
5)并行度 (numPartitions): 这指定了创建的 RDD 的分区数,也就是并行度。它决定了查询在 Spark 集群中并行执行的程度。通常情况下,可以根据数据量和集群资源情况来设置并行度,以提高查询性能。
6)结果集处理函数 (resultSetHandler): 这是一个函数,用于处理从数据库返回的查询结果。你需要实现这个函数来定义对查询结果的处理逻辑,例如提取需要的字段、转换数据类型等。
package com.doit.day0201import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext}import java.sql.{DriverManager, ResultSet}/*** @日期: 2024/2/4* @Author: Wang NaPao* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343* @Tips: 和我一起学习吧* @Description: 使用JdbcRDD从MySQL数据库读取数据的示例*/object Tes05 {def main(args: Array[String]): Unit = {// 创建SparkConf对象,并设置应用程序名称和运行模式val conf = new SparkConf().setAppName("Starting...") // 设置应用程序名称.setMaster("local[*]") // 设置运行模式为本地模式// 创建SparkContext对象,并传入SparkConf对象val sc = new SparkContext(conf)/*** 参数一 sc* 参数二 函数 获取连接对象* 参数三 查询sql 要求 必须指定查询范围* 参数4 5 数据范围* 参数6 并行个数* 参数7 处理返回结果的函数*/// 定义一个函数来获取数据库连接val conn = () => {DriverManager.getConnection("jdbc:mysql://localhost:3306/day02_test02_company", "root", "123456")};// 定义查询SQL语句val sql = "select empid,basesalary,titlesalary from salary where empid >= ? and empid <= ?"// 定义结果集处理函数val f2 = (rs: ResultSet) => {// 每条结果数据的处理逻辑val id = rs.getInt(1)val basesalary = rs.getDouble(2)val titlesalary = rs.getDouble(3)(id, basesalary, titlesalary)}// 创建JdbcRDD并执行查询val rdd1 = new JdbcRDD(sc, conn, sql, 1002, 1003, 1, f2)rdd1.foreach(println)// 停止SparkContextsc.stop()}
}