目录
- Solr 全文检索 之 为索引库添加中文分词器
- 添加中文分词器
- 1、添加中文分词器的 jar 包
- 2、修改 managed-schema 配置文件
- 什么是 fieldType
- 3、添加 停用词文档
- 4、重启 solr
- 5、添加【*_cn】动态字段,并为该字段设置中文分词器
- 6、演示分词器的区别
- 演示 text_cjk 这个简单的分词器
- 演示 text_cn 这个中文分词器
Solr 全文检索 之 为索引库添加中文分词器
添加中文分词器
1、添加中文分词器的 jar 包
将 Solr 的 contrib\analysis-extras\lucene-libs 文件夹
目录下的 lucene-analyzers-smartcn-x.x.x.jar 包
复制到 Solr的 server\solr-webapp\webapp\WEB-INF\lib 目录下。
如果要添加第三方中文分词器,只要同样将JAR包复制到WEB-INF\lib目录下。

2、修改 managed-schema 配置文件
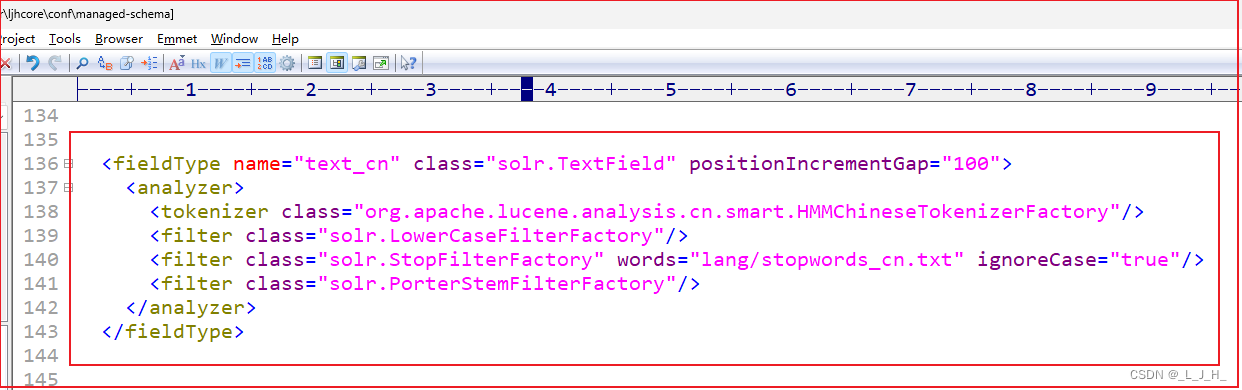
设置使用中文分词器的Field类型(修改这个 managed-schema 文件 ):
在配置文件里面添加这个中文分词器:
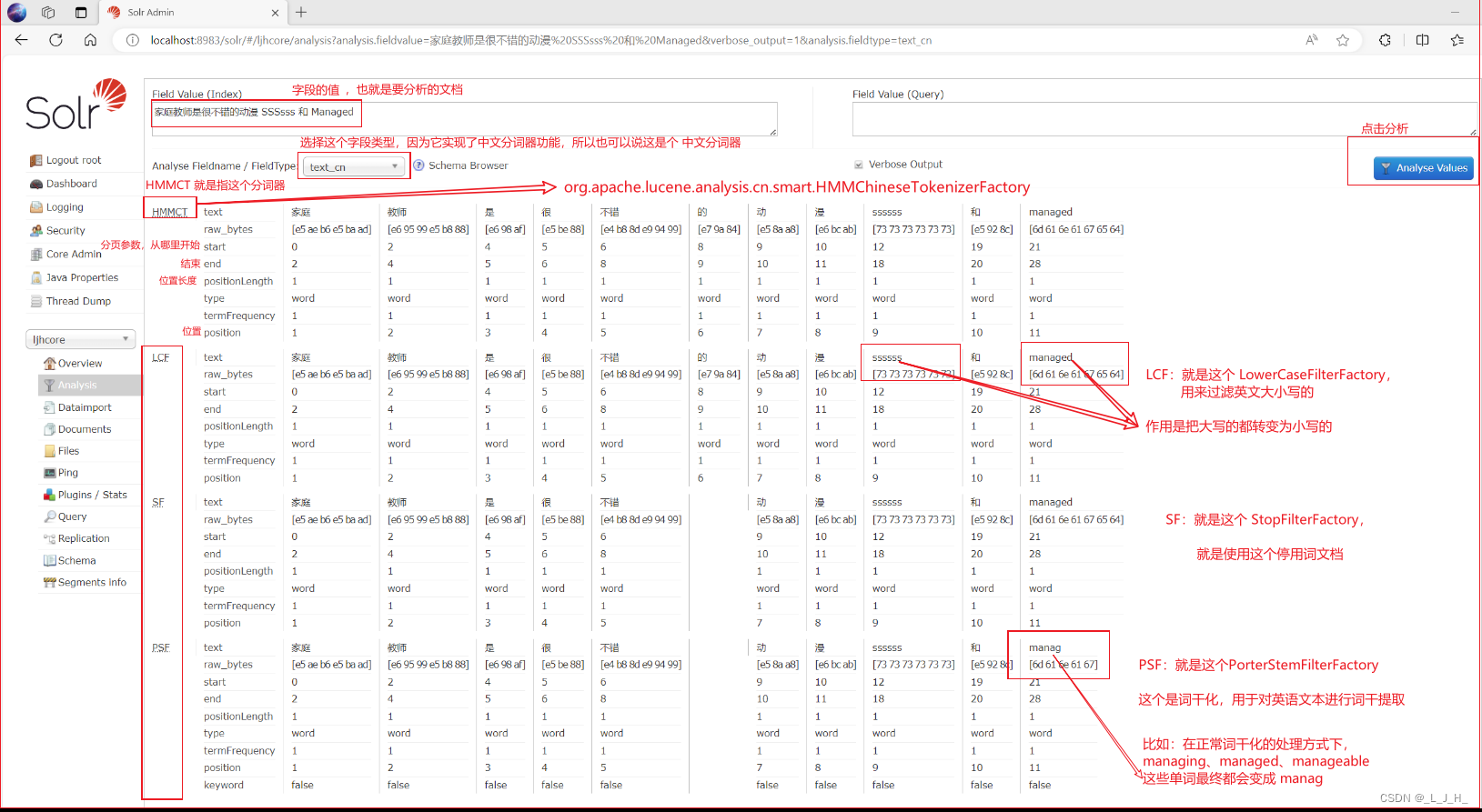
text_cn (中文分词器) 其实只是一个字段类型而已,因为实现了 HMMChineseTokenizerFactory 这个中文分词器的功能,所以也可以说 text_cn 是一个中文分词器。

<!-- 设置中文分词器 --><fieldType name="text_cn" class="solr.TextField" positionIncrementGap="100"><analyzer><!-- HMMChineseTokenizerFactory 是一个中文分词器 --><tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/><!-- 过滤英文大小写,就是保存关键字的时候不区分大小写,统统把关键字都弄成小写再保存 --><filter class="solr.LowerCaseFilterFactory"/><!-- 添加停用词文档,用于过滤停用词 --><!-- 停用词列表在 words 属性中指定,并且忽略大小写(ignoreCase="true") --><filter class="solr.StopFilterFactory" words="lang/stopwords_cn.txt" ignoreCase="true"/><!-- 这个是词干化,用于对英语文本进行词干提取。它基于 Porter 算法,可以将英语单词转换为其基本形式(词干 --><filter class="solr.PorterStemFilterFactory"/></analyzer></fieldType>
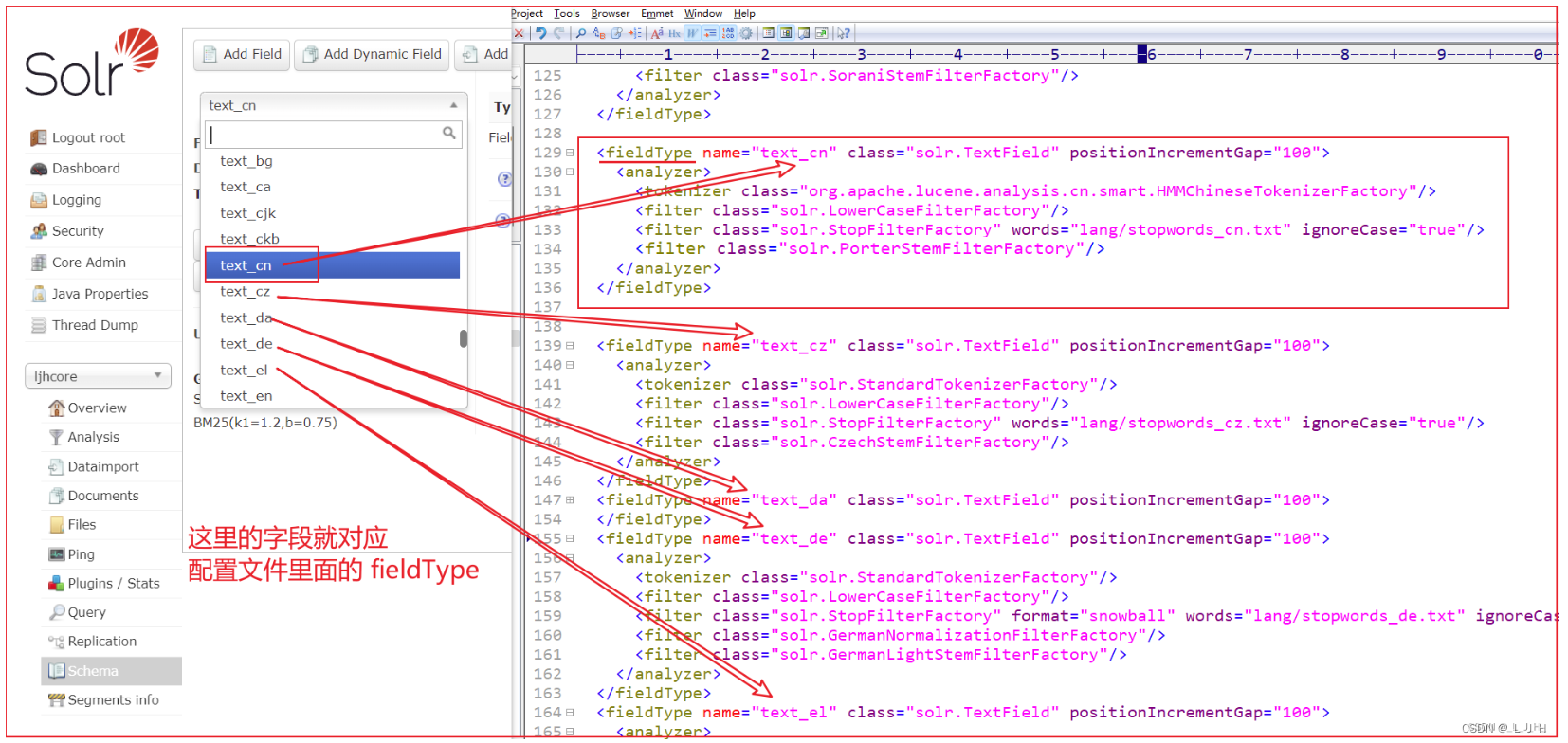
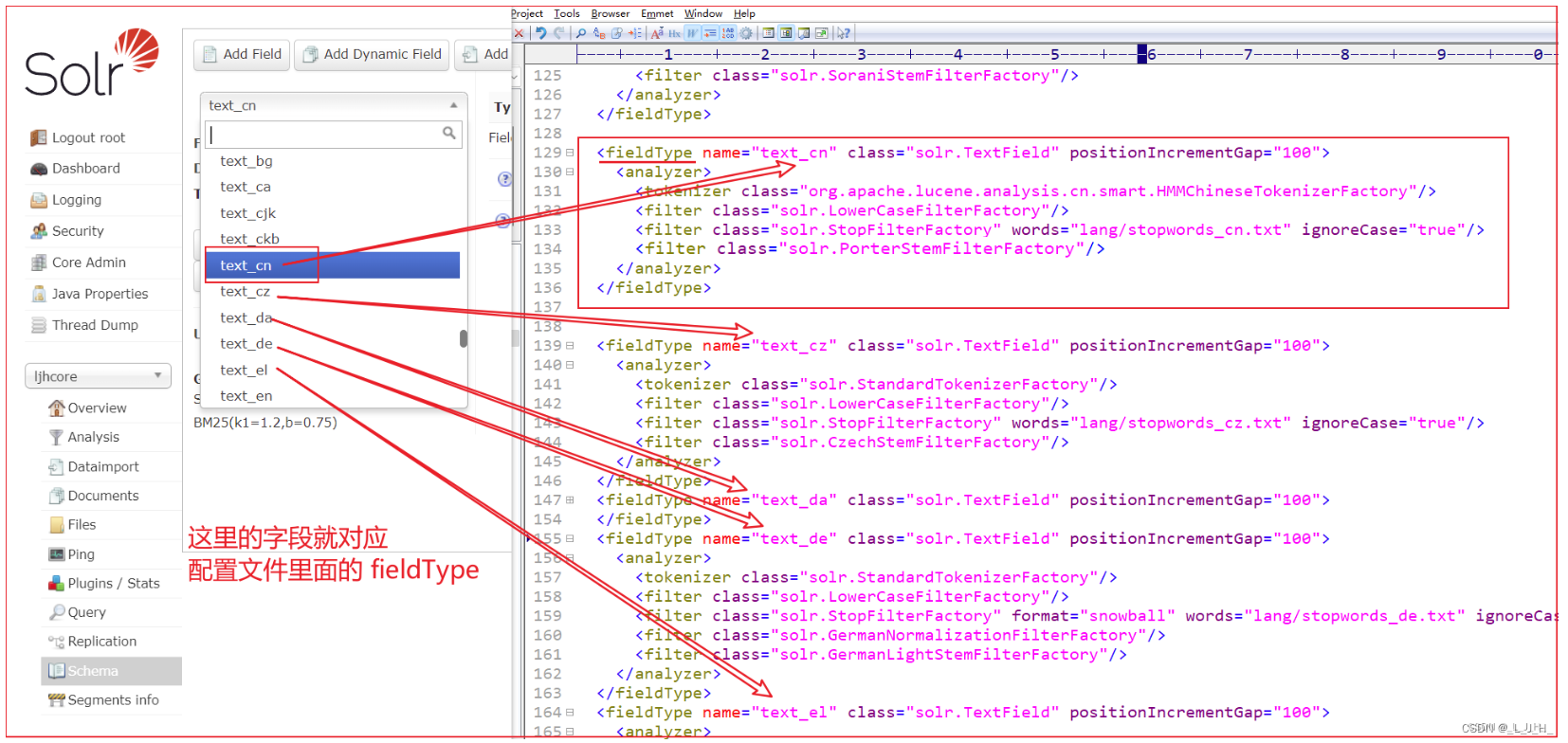
如图: 图形管理界面的这些字段类型,就对应着 managed-schema 配置文件里面的 fieldType
不同的一些字段类型,在 managed-schema 配置文件里面,就实现了针对不同语言的分词器功能。
比如上面的 text_cn 的解释。
什么是 fieldType
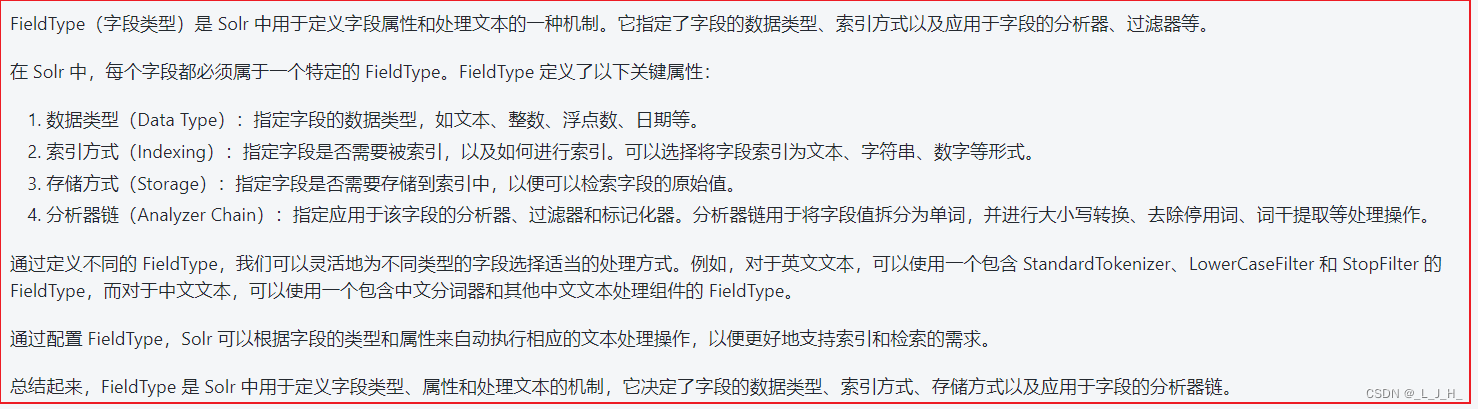
在 Solr 中,fieldType 是一种抽象类别,用于定义字段的类型和属性。每个 fieldType 包含了一组分析器、过滤器和标记化器,用于处理特定类型的文本。
在 managed-schema 配置文件中,我们通常会定义多个 fieldType,以便为不同类型的字段设置不同的分析器和过滤器。
3、添加 停用词文档
在conf/lang下添加中文的停用词列表文档。然后重启Solr
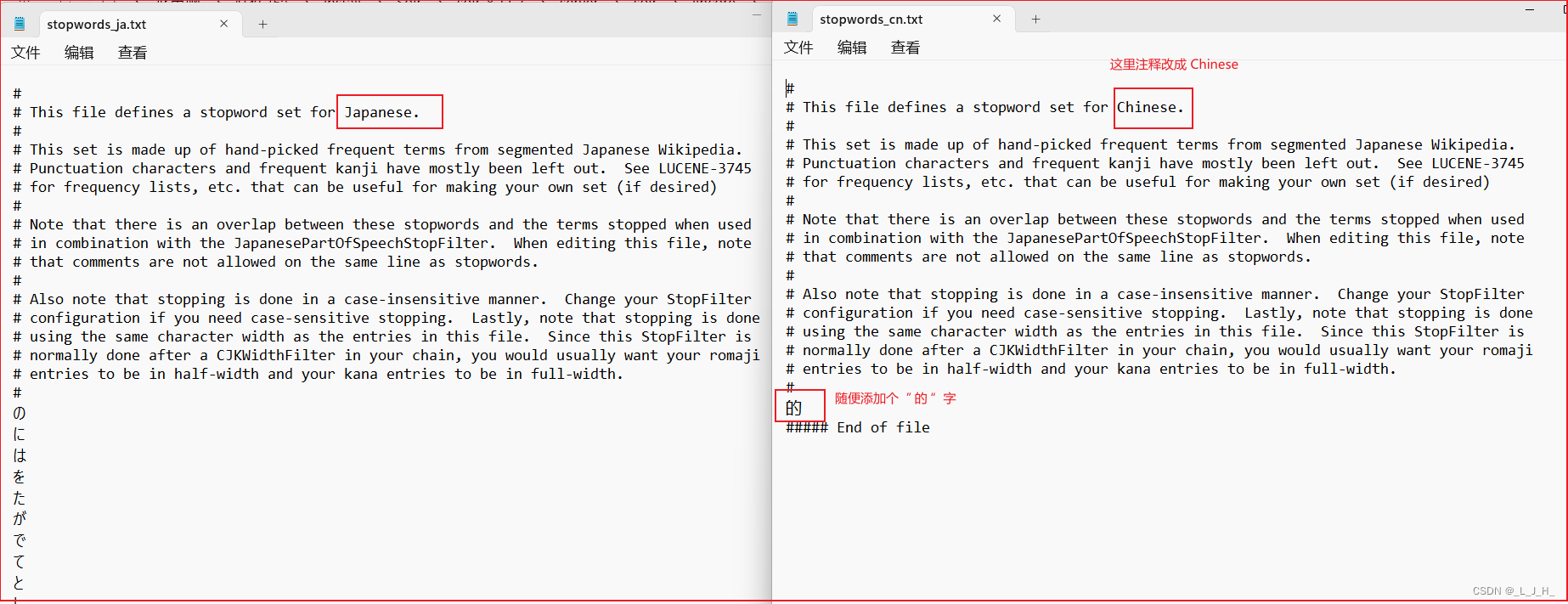
上面第二步的配置中,配置了这个【 words="lang/stopwords_cn.txt 】中文的停用词文档,但是此时还没有这个文档,所以需要我们自己添加
随便拷贝一份日文的停用词文档,重命名改成中文的就行
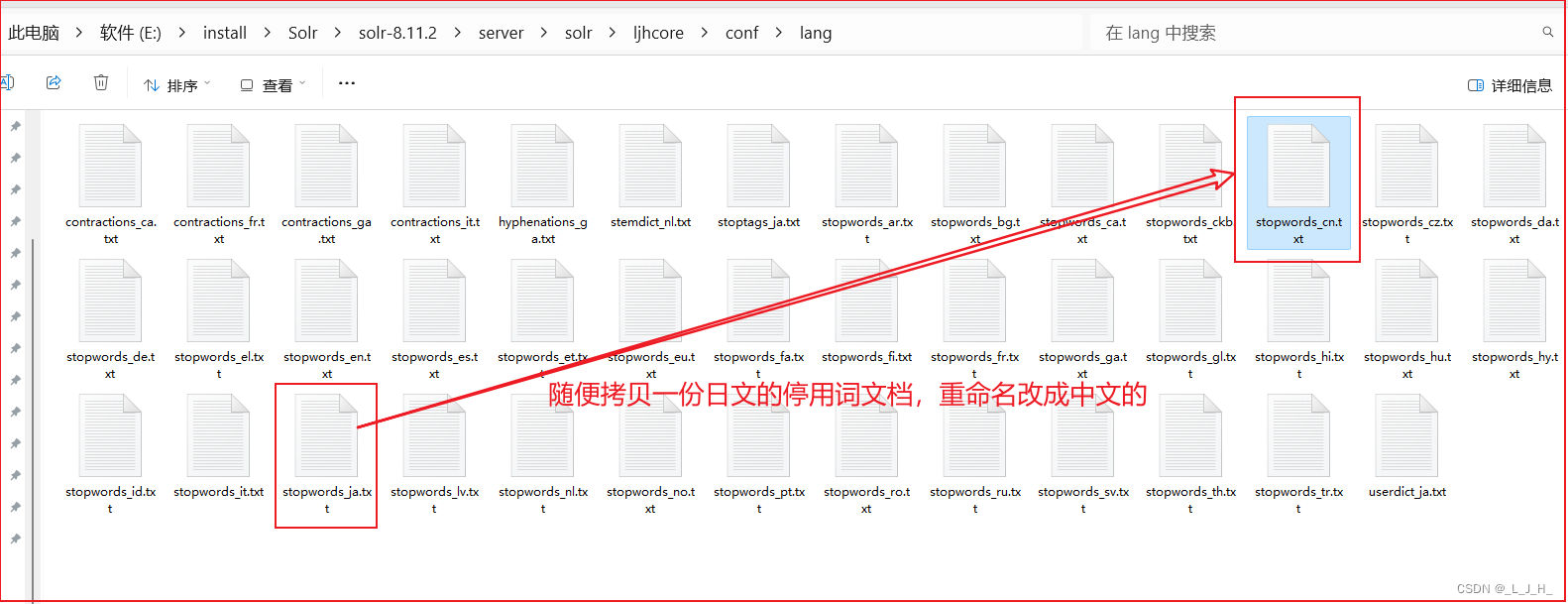
然后把日文的删掉,改成中文的就可以了,此时就有了一个 stopwords_cn.txt 的中文停用词文档
4、重启 solr
重启下,重启需要指定端口号
solr restart -p 8983
重启失败,因为字符集的原因,所以我把配置文件里面的中文注释给删除掉了,然后再重启就成功了。
如图:出现了 text_cn 这个 FieldType 字段类型
5、添加【*_cn】动态字段,并为该字段设置中文分词器
添加动态字段,可以在图形化界面添加,也可以直接在 managed-schema 配置文件里面添加,但是在配置文件里面添加的话,需要重启 solr 。
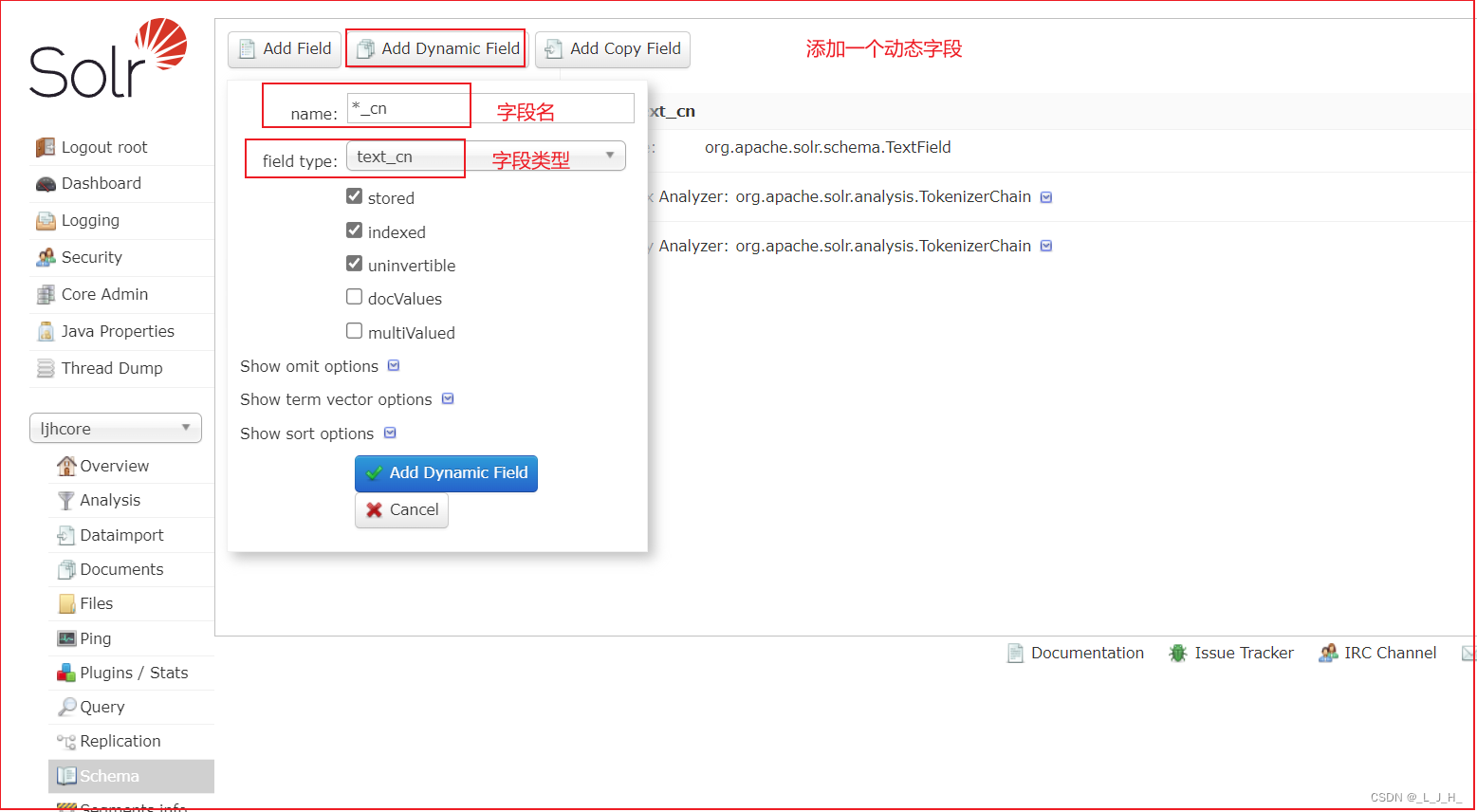
在图形界面添加动态字段,并为该字段设置中文分词器
1、如图:添加一个 【*_cn】 的动态字段,只要后缀是 _cn 结尾的,就可以匹配到。
然后将 Field 的类型设为【使用了中文分词器功能的字段类型(text_cn)】即可。
2、成功创建这个动态字段。
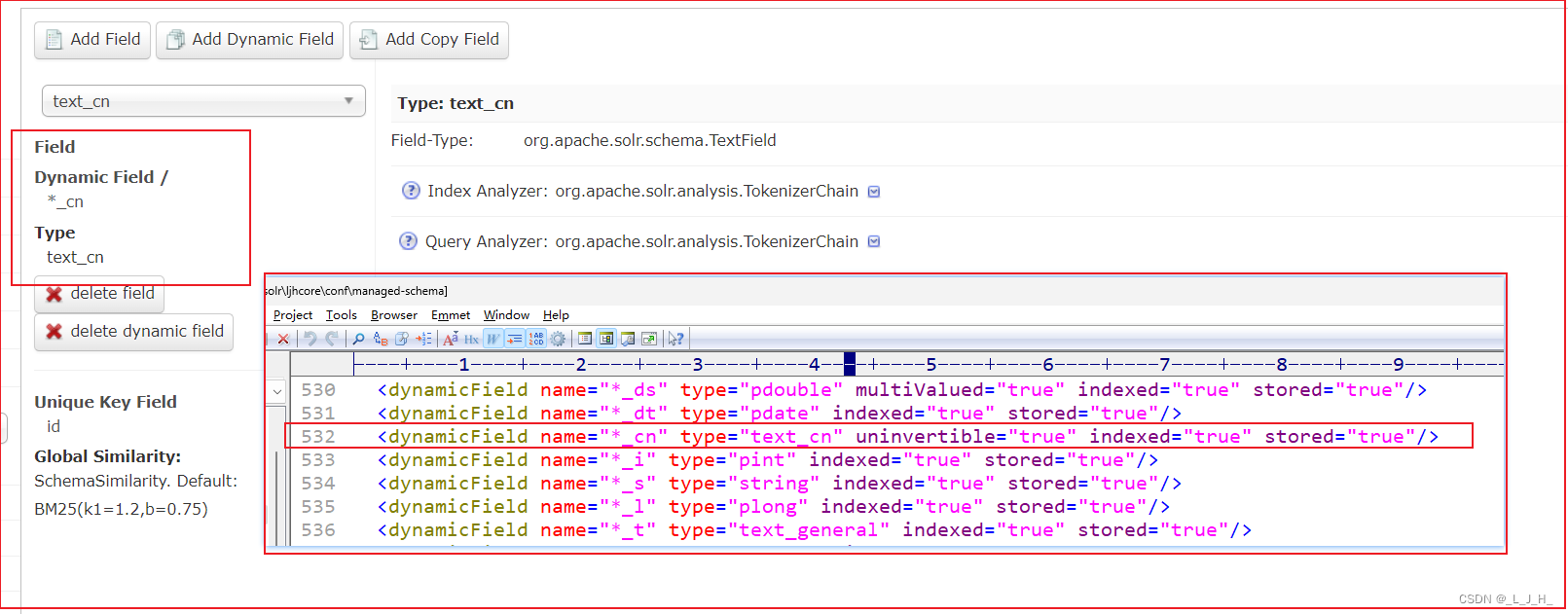
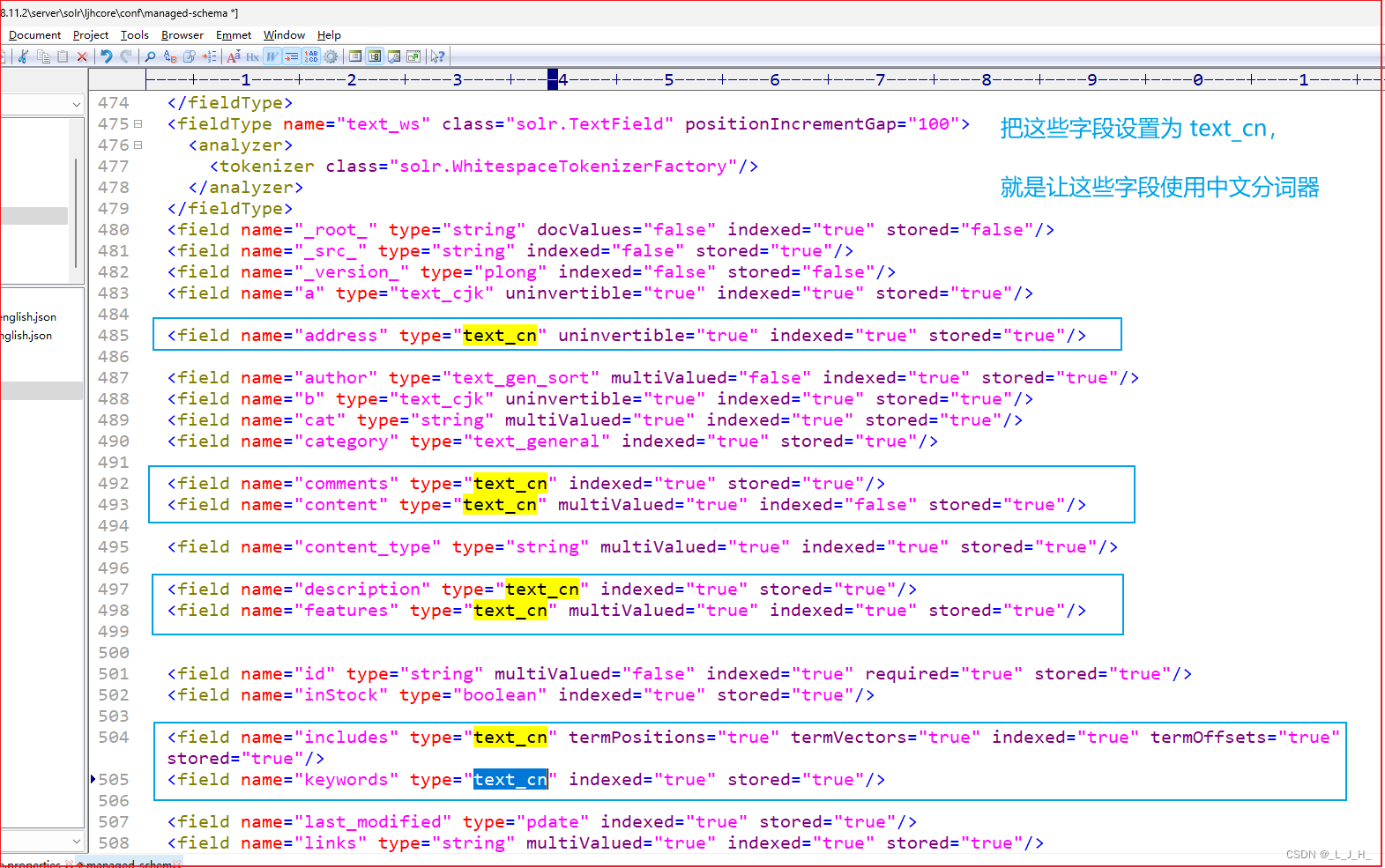
如图:也可以在配置文件里面,把这些字段的类型都修改成 text_cn ,那么在查询关键字的时候,对后缀有“_cn”的这些字段,就会使用到中文分词器来分词。
如果在配置文件里面进行内容修改,那么需要重启 solr 。
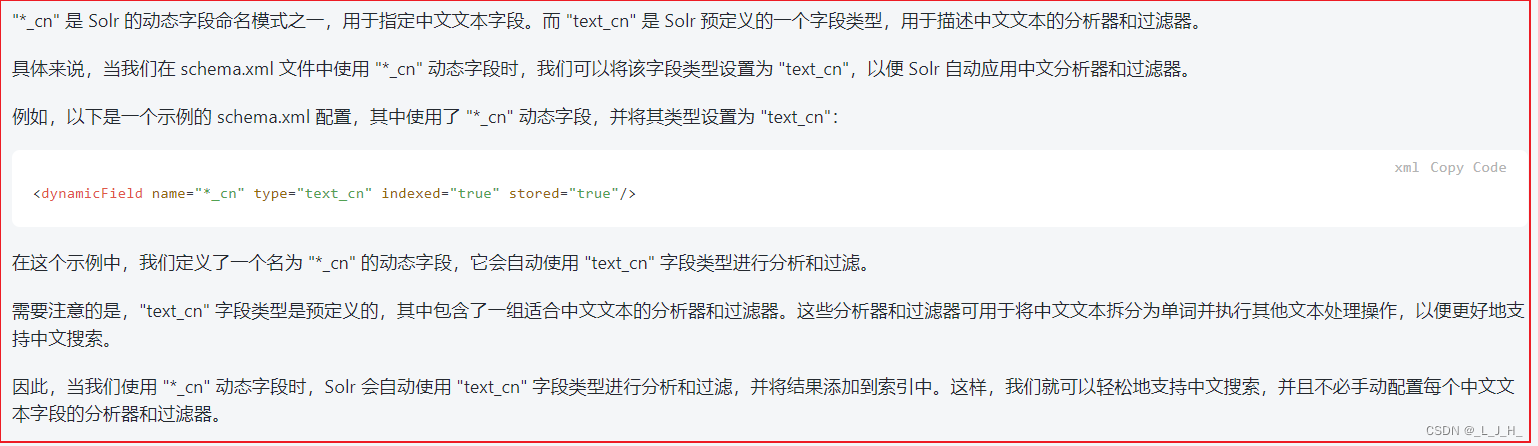
解释下这个 动态字段 “*_cn” 和 text_cn 字段类型 的关系

“*_cn” 和 text_cn 的关系
“*_cn” 是 Solr 的动态字段命名模式之一,用于指定中文文本字段。
而 “text_cn” 是 Solr 预定义的一个字段类型,用于描述中文文本的分析器和过滤器。
6、演示分词器的区别
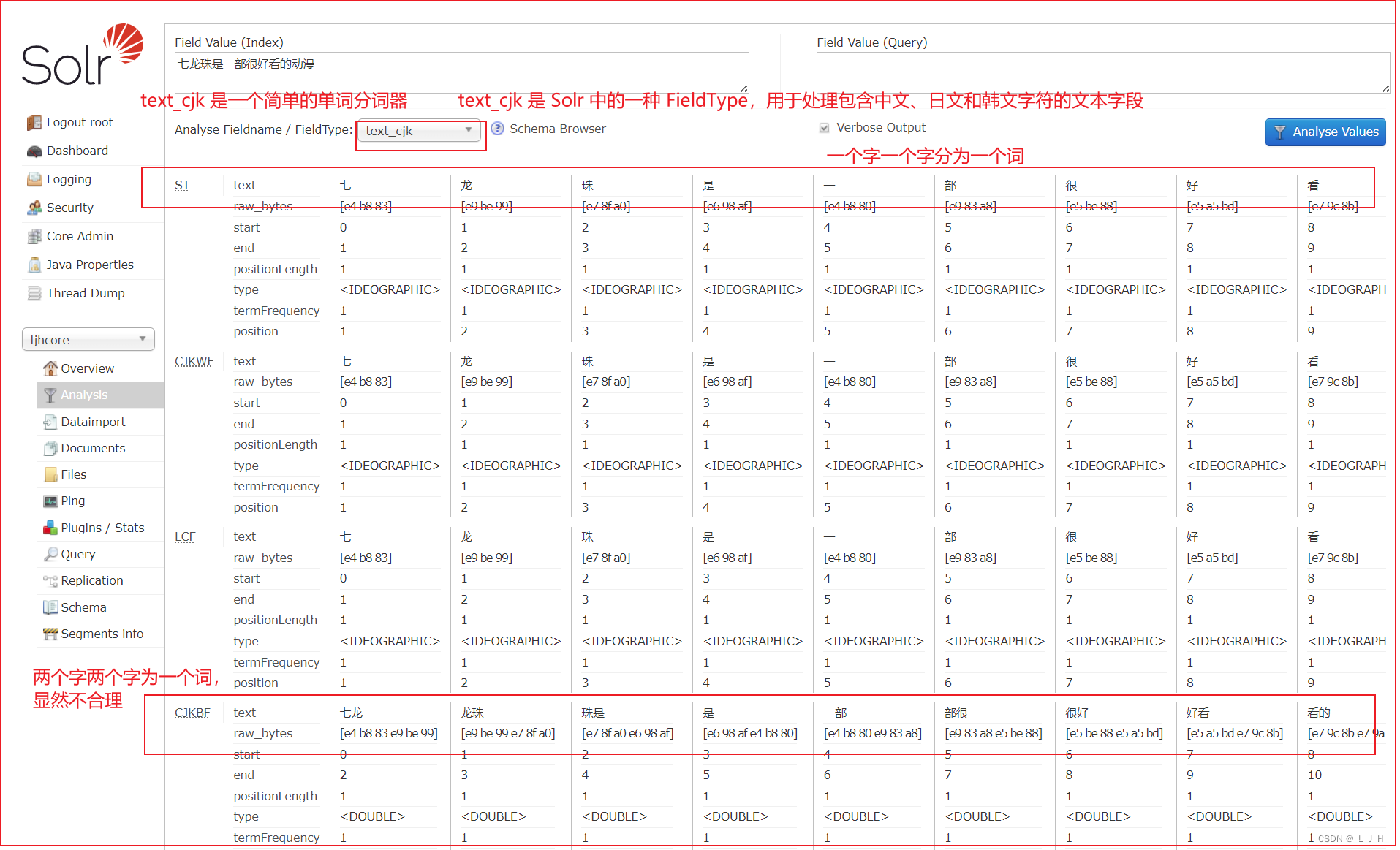
演示 text_cjk 这个简单的分词器
text_cjk 是一个简单的单词分词器。
text_cjk 是 Solr 中的一种 FieldType,用于处理包含中文、日文和韩文字符的文本字段。
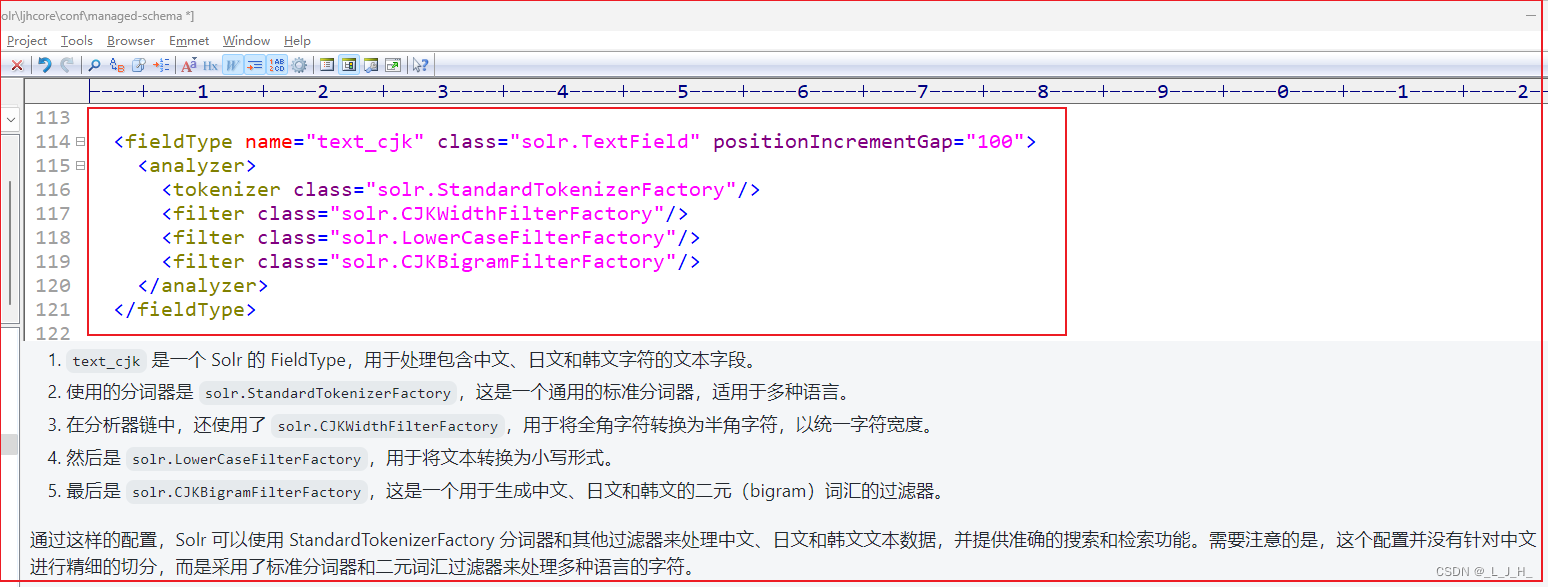
这个分词器的效果如图:
输入【七龙珠是一部很好看的动漫】
演示 text_cn 这个中文分词器
因为 text_cn 这个字段类型,使用了 HMMChineseTokenizerFactory 这个智能的中文分词器,所以可以对中文文档进行分词
如图:真正按照汉语的语言习惯来进行分词,建立索引库