文章目录
- @[TOC]
- 基于Kaggle电信用户流失案例数据(可在官网进行下载)
- 一、离散字段的数据重编码
- 1.OrdinalEncoder自然数排序
- 2.OneHotEncoder独热编码
- 3.ColumnTransformer转化流水线
- 二、连续字段的特征变换
- 1.标准化(Standardization)和归一化(Normalization)
- 2.连续变量分箱
- 3.连续变量特征转化的ColumnTransformer集成
文章目录
- @[TOC]
- 基于Kaggle电信用户流失案例数据(可在官网进行下载)
- 一、离散字段的数据重编码
- 1.OrdinalEncoder自然数排序
- 2.OneHotEncoder独热编码
- 3.ColumnTransformer转化流水线
- 二、连续字段的特征变换
- 1.标准化(Standardization)和归一化(Normalization)
- 2.连续变量分箱
- 3.连续变量特征转化的ColumnTransformer集成
基于Kaggle电信用户流失案例数据(可在官网进行下载)
基本信息探索部分可见:
机器学习数据预处理方法(基本信息探索)
import numpy as np
import pandas as pdimport seaborn as sns
import matplotlib.pyplot as plt
from sklearn import preprocessing# 读取数据
tcc = pd.read_csv('WA_Fn-UseC_-Telco-Customer-Churn.csv')# 标注连续/离散字段
# 离散字段
category_cols = ['gender', 'SeniorCitizen', 'Partner', 'Dependents','PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling','PaymentMethod']# 连续字段
numeric_cols = ['tenure', 'MonthlyCharges', 'TotalCharges']# 标签
target = 'Churn'# ID列
ID_col = 'customerID'# 验证是否划分能完全
assert len(category_cols) + len(numeric_cols) + 2 == tcc.shape[1]# 我们暂时将tenure划为连续性字段,以防止后续One-Hot编码时候诞生过多特征。
# 然后进行连续变量的缺失值填补:
tcc['TotalCharges']= tcc['TotalCharges'].apply(lambda x: x if x!= ' ' else np.nan).astype(float)
tcc['MonthlyCharges'] = tcc['MonthlyCharges'].astype(float)
# 将 TotalCharges空缺值替换为 0
tcc['TotalCharges'] = tcc['TotalCharges'].fillna(0)
# 将 Yes和 No 替换成 1 和 0
tcc['Churn'].replace(to_replace='Yes', value=1, inplace=True)
tcc['Churn'].replace(to_replace='No', value=0, inplace=True)
一、离散字段的数据重编码
1.OrdinalEncoder自然数排序
首先是自然数排序方法,该方法的过程较为简单,即先对离散字段的不同取值进行排序,然后对其进行自然数值取值转化,例如下述过程:
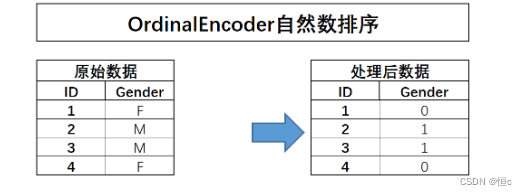
对于自然数排序过程,我们可以通过简单的pandas中的列取值调整来进行,例如就像此前对标签字段取值的调整过程,此外也可以直接考虑调用sklearn中的OrdinalEncoder()评估器(转化器)。
具体代码实现见:数据处理方法–OrdinalEncoder自然数排序
2.OneHotEncoder独热编码
对于独热编码的使用,有一点是额外需要注意的,那就是对于二分类离散变量来说,独热编码往往是没有实际作用的。例如对于上述极简数据集而言,Gender的取值是能是M或者F,独热编码转化后,某行Gender_F取值为1、则Gender_M取值必然为0,反之亦然。因此很多时候我们在进行独热编码转化的时候会考虑只对多分类离散变量进行转化,而保留二分类离散变量的原始取值。此时就需要将OneHotEncoder中drop参数调整为’if_binary’,以表示跳过二分类离散变量列。
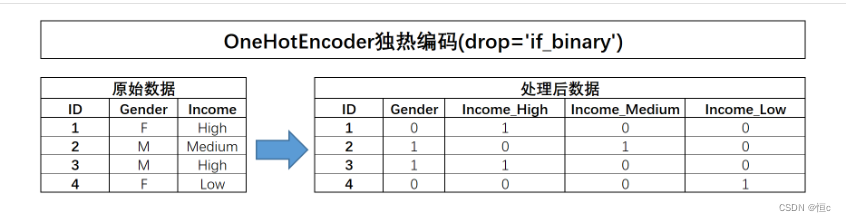
具体代码实现见:数据处理方法–OneHotEncoder独热编码
3.ColumnTransformer转化流水线
在执行单独的转化器时,我们需要单独将要转化的列提取出来,然后对其转化,并且在转化完成后再和其他列拼接成新的数据集。尽管很多时候表格的拆分和拼接不可避免,但该过程显然不够“自动化”。在sklearn的0.20版本中,加入了ColumnTransformer转化流水线评估器,使得上述情况得以改善。该评估器和pipeline类似,能够集成多个评估器(转化器),并一次性对输入数据的不同列采用不同处理方法,并输出转化完成并且拼接完成的数据。
from sklearn.compose import ColumnTransformerpreprocess_col = ColumnTransformer([('cat', preprocessing.OneHotEncoder(drop='if_binary'), category_cols), ('num', 'passthrough', numeric_cols)
])
而此时preprocess_col则表示对数据集的离散变量进行多分类独热编码处理,对连续变量不处理。如果从效果上看,preprocess_col和我们单独使用多分类独热编码处理离散变量过程并无区别,但实际上我们更推荐使用preprocess_col来进行处理,原因主要有以下几点:其一,通过preprocess_col处理后的数据集无需再进行拼接工作,preprocess_col能够直接输出离散变量独热编码+连续变量保持不变的数据集;其二, preprocess_col过程还能够对未选择的字段进行删除或者保留、或者统一再使用某种转化器来进行转化(默认是删除其他所有列),通过remainder参数来进行说明。例如,我们现在可以借助preprocess_col直接对tcc数据集进行离散变量独热编码、连续变量保留、以及剔除ID列和标签列的操作:
# 训练转化器
preprocess_col.fit(tcc)
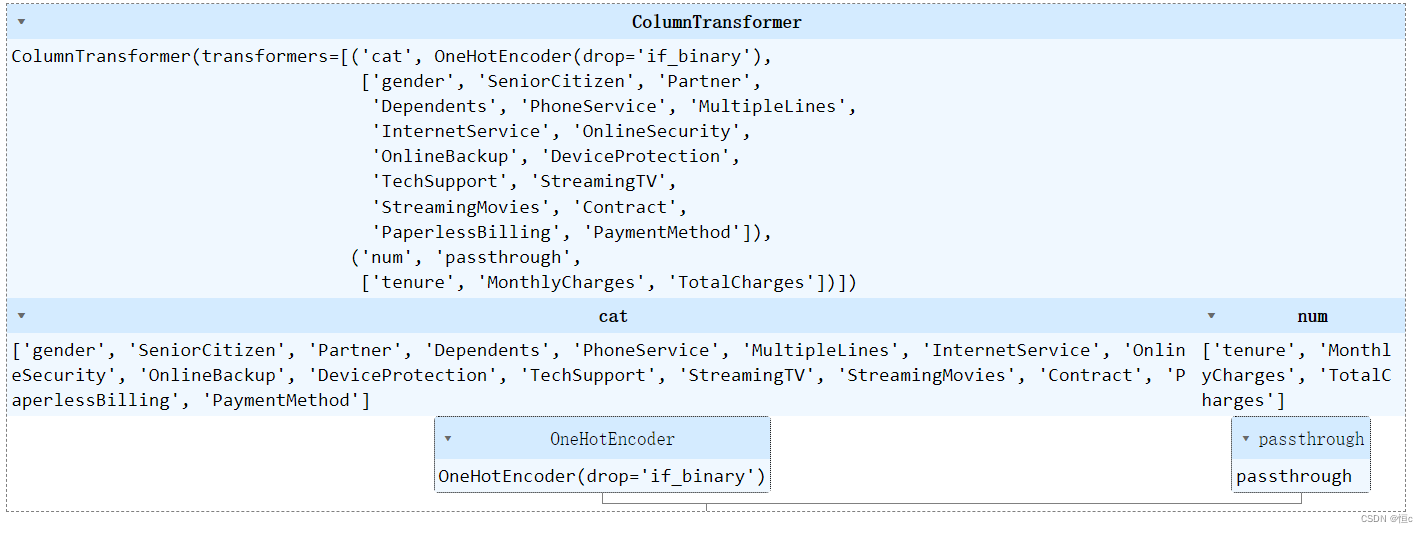
# 输出转化结果
pd.DataFrame(preprocess_col.transform(tcc))# 进行列名称转化 (定义函数)
# 封装函数
def cate_colName(Transformer, category_cols, drop='if_binary'):"""离散字段独热编码后字段名创建函数:param Transformer: 独热编码转化器:param category_cols: 输入转化器的离散变量:param drop: 独热编码转化器的drop参数"""cate_cols_new = []col_value = Transformer.categories_for i, j in enumerate(category_cols):if (drop == 'if_binary') & (len(col_value[i]) == 2):cate_cols_new.append(j)else:for f in col_value[i]:feature_name = j + '_' + fcate_cols_new.append(feature_name)return(cate_cols_new)# 转化后离散变量列名称
category_cols_new = cate_colName(preprocess_col.named_transformers_['cat'], category_cols)
# 所有字段名称
cols_new = category_cols_new + numeric_cols
# 输出最终dataframe
pd.DataFrame(preprocess_col.transform(tcc), columns=cols_new)
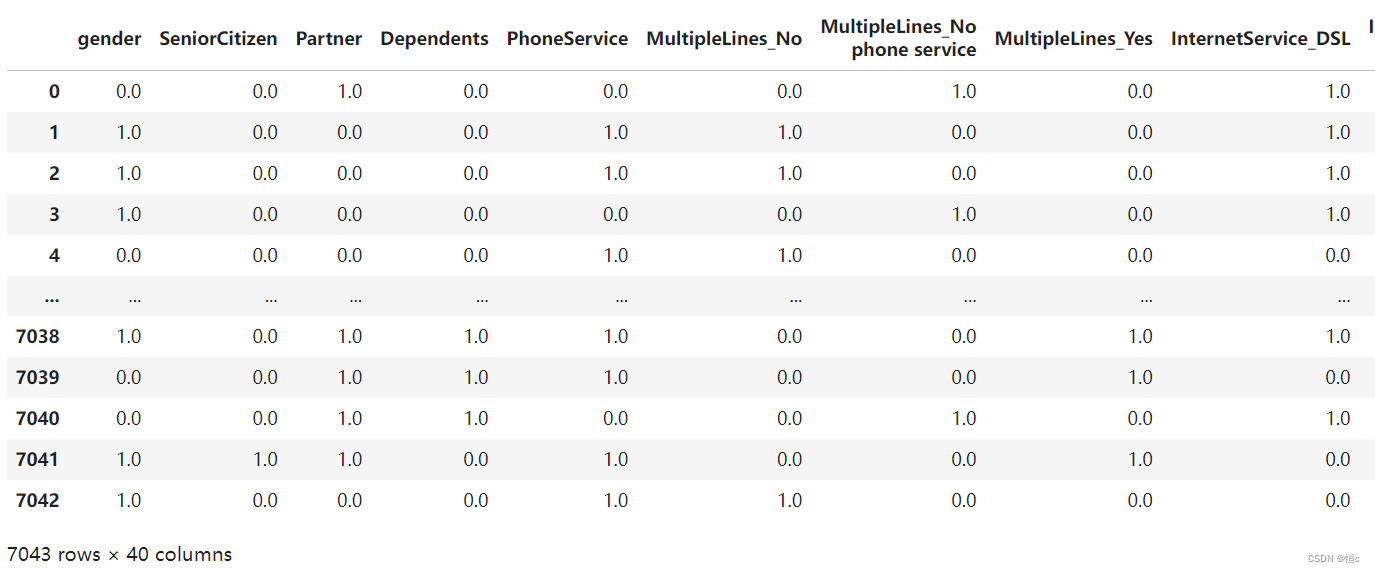 此外,在使用ColumnTransformer时我们还能自由设置系数矩阵的阈值,通过sparse_threshold参数来进行调整,默认是0.3,即超过30%的数据是0值时,ColumnTransformer输出的特征矩阵是稀疏矩阵。
此外,在使用ColumnTransformer时我们还能自由设置系数矩阵的阈值,通过sparse_threshold参数来进行调整,默认是0.3,即超过30%的数据是0值时,ColumnTransformer输出的特征矩阵是稀疏矩阵。
二、连续字段的特征变换
连续字段特征变换包括:
1.标准化(Standardization)和归一化(Normalization)
标准化和归一化
2.连续变量分箱
连续变量分箱
3.连续变量特征转化的ColumnTransformer集成
# 创建如下转化流
ColumnTransformer([('cat', preprocessing.OneHotEncoder(drop='if_binary'), category_cols), ('num', preprocessing.StandardScaler(), numeric_cols)
])

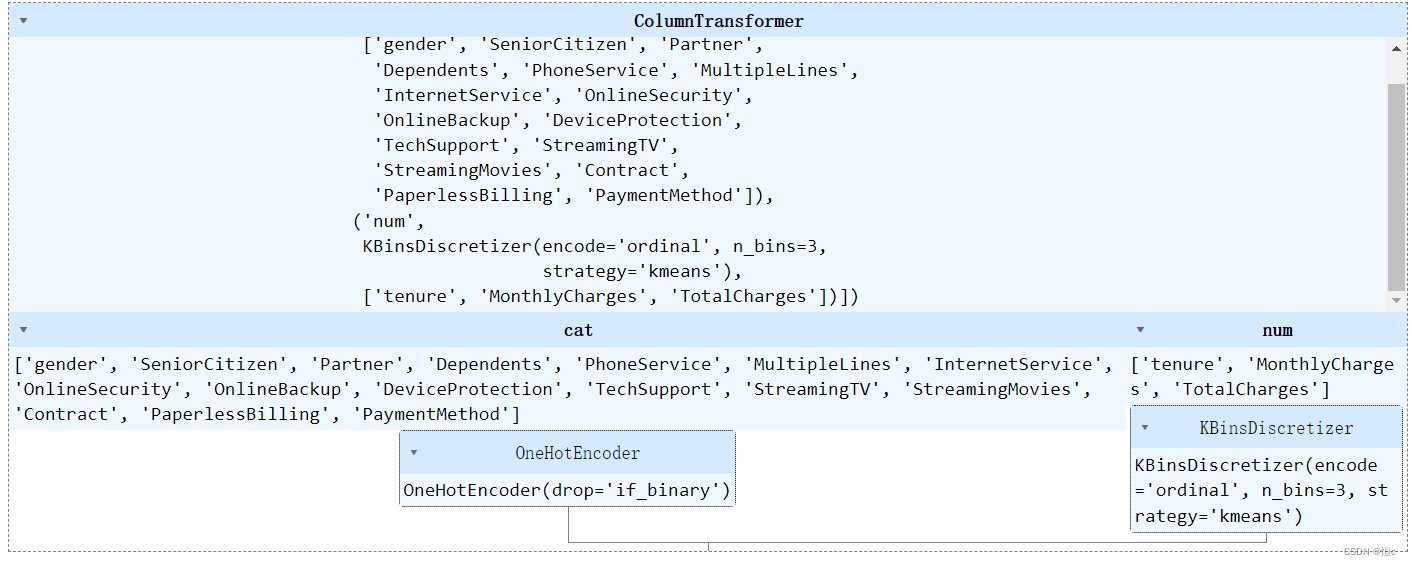
类似的,如果需要同时对离散变量进行多分类独热编码、对连续字段进行基于kmeans的三分箱,则可以创建如下转化流:
ColumnTransformer([('cat', preprocessing.OneHotEncoder(drop='if_binary'), category_cols), ('num', preprocessing.KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='kmeans'), numeric_cols)
])