目录
前言
参考资料+格式
头文件LinkList.h
LocateElem函数,定位查找
有序插入(没测试)
完整代码
头文件polynomial.h
测试函数(主函数)
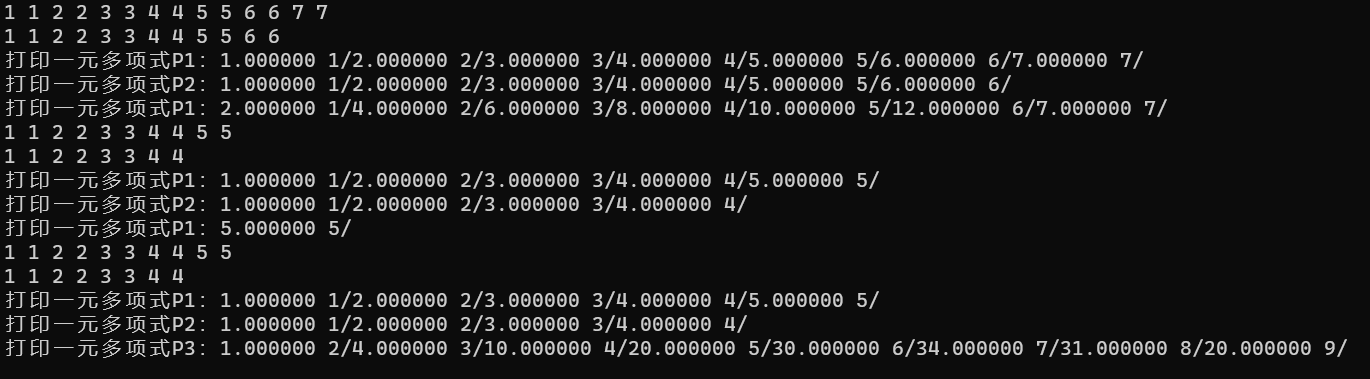
测试结果
前言
寒假在家,有点学不下去,写文章的速度也很慢,看来四十天完成这项任务是不可能了。但比较兴奋的是,在这个过程中,我调试代码的速度有了明显的提升,很多时候一些小细节我可以通过网上资源的帮助解决,这是我以前严重缺乏的能力。第二个收获就是在复现代码的过程中真正意识到了模块化的好处,就想这篇文章,就与上一篇单链表的代码实现息息相关,可以说,上一篇稍微改改,就可以成为这一篇的一个头文件,因此节省了我很大的工作量。这一章也算告一段落,下面就看看我的成果吧。
数据结构(C语言)代码实现(六)——单链表的实现-CSDN博客
参考资料+格式
1、数据结构C语言严蔚敏版
2、LocateElem函数用的这个博主的代码。
数据结构——算法总结:一元多项式的表示与相加_建立一元多项式链表,实现相加操作,输出结果-CSDN博客
头文件LinkList.h
LocateElem函数,定位查找
Status LocateElem(LinkList L, ElemType e, Position& q, int(*compare)(ElemType, ElemType))
{ // 若升序链表L中存在与e满足判定函数compare()取值为0的元素,则q指示L中// 第一个值为e的结点的位置,并返回TRUE;否则q指示第一个与e满足判定函数// compare()取值>0的元素的前驱的位置。并返回FALSEPosition p = L->head;Position pp = NULL;while (p != NULL && compare(p->data, e) < 0){//没到表尾且没有比当前指数大的指数pp = p; //记录当前位置p = p->next; //继续往后找}if (p == NULL || compare(p->data, e) > 0) // 到表尾或比当前指数大的指数{q = pp;return FALSE;}else // 找到{// 没到表尾且p->data.expn=e.expnq = p;return TRUE;}
}有序插入(没测试)
//有序插入
Status OrderInsert(LinkList& L, ElemType e, int(*compare)(ElemType, ElemType)) {//按有序判定函数compare()的约定,将值为e的结点插入到有序链表L的适当位置上Position s = L->head;Position p = L->head->next;while (p != NULL && compare(p->data, e) < 0) {p = p->next;s = s->next;}Link pp = (Link)malloc(sizeof(LNode));if (pp == NULL)return ERROR;//警告C6011pp->data = e;s->next = pp;pp->next = p;return OK;
}不加上面的代码,报错警告C6011,原因是由于内存不够,malloc函数不能分配足够的空间,返回NULL,此时pp为空指针。
完整代码
本来想把Elemtype这个结构体放在polynomial.h这个头文件中,因为和课本代码顺序对得上。但是放在了后面的头文件,第一个头文件中的Elemtype没有办法定义,想互相调用,结果失败。最后就成了现在这个样子。
#pragma once
#include <cstdio>
#include <cstdlib>
#include <cstring>#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;//Status是函数的类型,其值是函数结果状态代码//-----线性链表的存储结构---------
//-----实现单向非循环有序链表-----
//-----头结点与首元结点不一致-----typedef struct term {double coef;//系数int expn;//指数
}term, ElemType;//两个类型名:term用于本ADT,ElemType为LinkList的数据对象名typedef struct LNode {//结点类型ElemType data;struct LNode* next;
}LNode, * Link, * Position;typedef struct LinkNode { //链表类型Link head, tail; //分别指向线性链表中的头结点和最后一个结点int len; //指示线性链表中数据元素的个数
}LinkNode, * LinkList;typedef LinkList polynomial;//用带表头节点的有序链表表示多项式Status MakeNode(Link& p, ElemType e) {//分配由p指向的值为e的结点,并返回OK;若分配失败,则返回ERRORp = (Link)malloc(sizeof(LNode));if (!p)return ERROR;p->data = e;return OK;
}
void FreeNode(Link& p) {//相当于free函数重命名//释放p所指结点free(p);p = NULL;
}Status InitList(LinkList& L) {//构造一个空的线性链表LL = (LinkList)malloc(sizeof(LinkNode));if (!L)return ERROR;L->head = L->tail = (Link)malloc(sizeof(LNode));if (!L->head)return ERROR;L->head->next = NULL;L->len = 0;return OK;
}Status DestroyList(LinkList& L) {//销毁线性链表L,L不再存在Link p;while (L->head) {//删除所有结点p = L->head;L->head = L->head->next;free(p);}free(L);L = NULL;return OK;
}Status ClearList(LinkList& L) {//将线性链表L重置为空表,并释放原链表的结点空间Link p = L->head;while (L->head->next) {//保留一个结点,让其作为头结点p = L->head->next;L->head->next = p->next;free(p);}L->tail = L->head;L->len = 0;return OK;
}Status InsFirst(Link h, Link s) {//已知h指向线性链表的头结点,将s所指结点插入到首元结点之前s->next = h->next;h->next = s;//这个函数没修改L->len的值,课本算法2.20需要补充L->len++。return OK;
}Status DelFirst(Link h, Link& q) {//已知h指向线性链表的头结点,删除链表中的首元结点并以q返回q = h->next;h->next = q->next;q->next = NULL;return OK;
}Status Append_add(LinkList& L, Link s) {//将指针s所指(彼此以指针相链)的一串结点链接在线性链表L的最后一个结点(用L->tail寻找)//之后,并改变链表L的尾指针指向新的尾结点while (s) {L->tail->next = s;L->tail = s;L->len++;s = s->next;}return OK;
}Status Append_sub(LinkList& L, Link s) {//将指针s所指(彼此以指针相链)的一串结点链接在线性链表L的最后一个结点(用L->tail寻找)//之后,并改变链表L的尾指针指向新的尾结点while (s) {s->data.coef = -s->data.coef;L->tail->next = s;L->tail = s;L->len++;s = s->next;}return OK;
}Status Remove(LinkList& L, Link& q) {//删除线性链表L中的尾节点并以q返回,改变链表L的尾指针指向新的尾结点if (!L->tail)return ERROR;Link p = L->head;while (p->next != L->tail)p = p->next;//寻找尾结点的上一个结点q = L->tail;L->tail = p;//改变尾结点L->tail->next = NULL;L->len--;return OK;
}Status InsBefore(LinkList& L, Link& p, Link s) {//已知p指向线性链表L中的一个结点,将s所指结点插入在p所指结点之前//并修改指针p指向新插入的结点Link q = L->head;while (q->next != p)q = q->next;//寻找结点q的上一个结点q->next = s;s->next = p;//插入sp = s;//修改指针pL->len++;return OK;
}Status InsAfter(LinkList& L, Link& p, Link s) {//已知p指向线性链表L中的一个结点,将s所指的结点插入在p所指结点之后//并修改指针p指向新插入的结点s->next = p->next;p->next = s;p = s;L->len++;return OK;
}Status SetCurElem(Link& p, ElemType e) {//已知p指向线性链表L中的一个结点,用e更新p所指结点中数据元素的值p->data = e;return OK;
}ElemType GetCurElem(Link p) {//已知p指向线性链表L中的一个结点,返回p所指结点中数据元素的值return p->data;
}Status ListEmpty(LinkList L) {//若线性链表L为空表,则返回TRUE,否则返回FALSEif (!L->len)return TRUE;elsereturn FALSE;
}int ListLength(LinkList L) {//返回线性链表L中元素个数return L->len;
}Position GetHead(LinkList L) {//返回线性链表L中头结点的位置return L->head;
}Position GetLast(LinkList L) {//返回线性链表L中尾结点的位置return L->tail;
}Position PriorPos(LinkList L, Link p) {//已知p指向线性链表L中的一个结点,返回p所指结点中的直接前驱的位置//若无前驱,则返回NULLLink q = L->head;if (p == L->head)return NULL;while (q->next != p)q = q->next;return q;
}Position NextPos(LinkList L, Link p) {//已知p指向线性链表L中的一个结点,返回p所指结点中的直接后继的位置//若无后继,则返回NULLreturn p->next;
}Status LocatePos(LinkList L, int i, Link& p) {//返回p指示线性链表L中第i个结点的位置并返回OK,i值不合法时返回ERROR//头结点当作第0结点,首元结点第1个,尾结点第(L->len)个if (i<0 || i>L->len)return ERROR;int j = 0;Link q = L->head;while (j < i) {q = q->next;++j;//j++也一样}p = q;return OK;
}Status LocateElem(LinkList L, ElemType e, Position& q, int(*compare)(ElemType, ElemType))
{ // 若升序链表L中存在与e满足判定函数compare()取值为0的元素,则q指示L中// 第一个值为e的结点的位置,并返回TRUE;否则q指示第一个与e满足判定函数// compare()取值>0的元素的前驱的位置。并返回FALSEPosition p = L->head;Position pp = NULL;while (p != NULL && compare(p->data, e) < 0){//没到表尾且没有比当前指数大的指数pp = p; //记录当前位置p = p->next; //继续往后找}if (p == NULL || compare(p->data, e) > 0) // 到表尾或比当前指数大的指数{q = pp;return FALSE;}else // 找到{// 没到表尾且p->data.expn=e.expnq = p;return TRUE;}
}//有序插入
Status OrderInsert(LinkList& L, ElemType e, int(*compare)(ElemType, ElemType)) {//按有序判定函数compare()的约定,将值为e的结点插入到有序链表L的适当位置上Position s = L->head;Position p = L->head->next;while (p != NULL && compare(p->data, e) < 0) {p = p->next;s = s->next;}Link pp = (Link)malloc(sizeof(LNode));if (pp == NULL)return ERROR;//警告C6011pp->data = e;s->next = pp;pp->next = p;return OK;
}//遍历链表
Status ListTraverse(LinkList L, void (*visit)(Link)) {//依次对L的每个元素调用函数visit()。一旦visit()失败,则操作失败。Link p = L->head;for (int i = 1;i <= L->len;i++) {p = p->next;visit(p);}printf("\n");return OK;
}头文件polynomial.h
#pragma once#include "LinkList.h"//请注意前提,课本中的一元多项式项数为非递减排列//-----基本操作的算法描述(部分)-----
int cmp(term a, term b) {//依a的指数值<(或=)(或>)b的指数值,分别返回-1、0和+1if (a.expn < b.expn)return -1;else if (a.expn > b.expn)return 1;elsereturn 0;
}void CreatPolyn(polynomial& P, int m) {//输入m项的系数和指数,建立表示一元多项式的有序链表PInitList(P);Link h = GetHead(P);ElemType e;e.coef = 0.0;e.expn = -1;SetCurElem(h, e);//设置头结点的数据元素Link q = NULL;Link s = NULL;for (int i = 1;i <= m;++i) {//依次输入m个非零项scanf_s("%lf%d", &e.coef, &e.expn);char ch = getchar();//吸收多余的回车或空格if (!LocateElem(P, e, q, cmp))//当前链表不存在该指数项{if (MakeNode(s, e))InsFirst(q, s);//生成结点并插入链表P->len++;}}
}void DestroyPolyn(polynomial& P) {//销毁一元多项式PDestroyList(P);
}void PrintPolyn(polynomial P) {//打印输出一元多项式PLink q = P->head->next;while (q) {printf("%f %d/", q->data.coef, q->data.expn);q = q->next;}printf("\n");
}int PolynLength(polynomial P) {//返回一元多项式的项数return ListLength(P);
}void AddPolyn(polynomial& Pa, polynomial& Pb) {//多项式加法:Pa=Pa+Pb,利用两个多项式的结点构成“和多项式”。//并销毁一元多项式Pb。Link ha = GetHead(Pa);Link hb = GetHead(Pb);//ha和hb分别指向Pa和Pb的头结点Link qa = NextPos(Pa, ha);Link qb = NextPos(Pb, hb);//qa和qb分别指向Pa和Pb中当前结点while (qa && qb) {//qa和qb均非空term a = GetCurElem(qa);term b = GetCurElem(qb);switch (cmp(a, b)) {case -1://多项式PA中当前结点的指数很小ha = qa;qa = NextPos(Pa, qa);break;case 0://两者的指数值相等a.coef = a.coef + b.coef;if (a.coef != 0.0) {//修改多项式PA中当前结点的系数值SetCurElem(qa, a);ha = qa;}else{//删除多项式PA中当前结点DelFirst(ha, qa);FreeNode(qa);Pa->len--;//所有的删除与插入操作都有点缺陷,因为没有判断是否应该修改尾指针。}DelFirst(hb, qb);FreeNode(qb);Pb->len--;qb = NextPos(Pb, hb);qa = NextPos(Pb, ha);break;case 1://多项式PB中当前结点的指数值小DelFirst(hb, qb);Pb->len--;InsFirst(ha, qb);Pa->len++;qb = NextPos(Pb, hb);ha = NextPos(Pa, ha);break;}}if (!ListEmpty(Pb))Append_add(Pa, qb);//链接Pb中剩余结点FreeNode(hb);//释放Pb的头结点
}void SubtractPolyn(polynomial& Pa, polynomial& Pb) {//多项式减法:Pa=Pa-Pb,利用两个多项式的结点构成“差多项式”。//并销毁一元多项式Pb。//在本代码中唯一的区别是case 0中的+号改成-号。Link ha = GetHead(Pa);Link hb = GetHead(Pb);//ha和hb分别指向Pa和Pb的头结点Link qa = NextPos(Pa, ha);Link qb = NextPos(Pb, hb);//qa和qb分别指向Pa和Pb中当前结点while (qa && qb) {//qa和qb均非空term a = GetCurElem(qa);term b = GetCurElem(qb);switch (cmp(a, b)) {case -1://多项式PA中当前结点的指数很小ha = qa;qa = NextPos(Pa, qa);break;case 0://两者的指数值相等a.coef = a.coef - b.coef;if (a.coef != 0.0) {//修改多项式PA中当前结点的系数值SetCurElem(qa, a);ha = qa;}else {//删除多项式PA中当前结点DelFirst(ha, qa);FreeNode(qa);Pa->len--;//所有的删除与插入操作都有点缺陷,因为没有判断是否应该修改尾指针。}DelFirst(hb, qb);FreeNode(qb);Pb->len--;qb = NextPos(Pb, hb);qa = NextPos(Pb, ha);break;case 1://多项式PB中当前结点的指数值小DelFirst(hb, qb);Pb->len--;InsFirst(ha, qb);Pa->len++;qb = NextPos(Pb, hb);ha = NextPos(Pa, ha);break;}}if (!ListEmpty(Pb))//链接Pb中剩余结点Append_sub(Pa, qb);//这里要系数变为相反数,所以仿照Append又写了个,为了区分,两个函数后缀不同//有点为这点醋包的饺子的意思FreeNode(hb);//释放Pb的头结点
}void MutiplyPolyn(polynomial& Pa, polynomial& Pb,polynomial& Pc) {//完成多项式相乘计算,即:Pa = Pa X Pb,并销毁一元多项式Pb//实在不知道怎么像加法一样仅调用两个变量//最终效果是保留Pa,Pb,PcLink hb = GetHead(Pb);Link qb = NextPos(Pb, hb);Link ha, qa;while (qb) {polynomial Pd;//过渡变量InitList(Pd);Link hd = GetHead(Pd);ha = GetHead(Pa);qa = NextPos(Pa, ha);while (qa) {//Pb的一项与整个Pa相乘ElemType e;Link p = NULL;e.coef = qa->data.coef * qb->data.coef;e.expn = qa->data.expn + qb->data.expn;MakeNode(p, e);InsFirst(hd, p);Pd->len++;ha = qa;qa = NextPos(Pa, ha);hd = p;}AddPolyn(Pc, Pd);hb = qb;qb = NextPos(Pb, hb);}
}测试函数(主函数)
#include "Polynomial.h"int main()
{polynomial p1, p2;CreatPolyn(p1, 7);CreatPolyn(p2, 6);printf("打印一元多项式P1:");PrintPolyn(p1);printf("打印一元多项式P2:");PrintPolyn(p2);AddPolyn(p1, p2);printf("打印一元多项式P1:");PrintPolyn(p1);DestroyPolyn(p1);CreatPolyn(p1, 5);CreatPolyn(p2, 4);printf("打印一元多项式P1:");PrintPolyn(p1);printf("打印一元多项式P2:");PrintPolyn(p2);SubtractPolyn(p1, p2);printf("打印一元多项式P1:");PrintPolyn(p1);DestroyPolyn(p1);polynomial p3;CreatPolyn(p1, 5);CreatPolyn(p2, 4);InitList(p3);printf("打印一元多项式P1:");PrintPolyn(p1);printf("打印一元多项式P2:");PrintPolyn(p2);MutiplyPolyn(p1, p2, p3);printf("打印一元多项式P3:");PrintPolyn(p3);DestroyList(p1);DestroyList(p2);DestroyList(p3);return 0;
}测试结果