视觉和语言模型的交叉导致了人工智能的变革性进步,使应用程序能够以类似于人类感知的方式理解和解释世界。大型视觉语言模型(LVLMs)在图像识别、视觉问题回答和多模态交互方面提供了无与伦比的能力。
MoE-LLaVA利用了“专家混合”策略融合视觉和语言数据,实现对多媒体内容的复杂理解和交互。为增强LVLMs提供了更高效、更有效的解决方案,而不受传统缩放方法的典型限制。
lvlm及其挑战
大型视觉语言模型(LVLMs)代表了人工智能和机器学习领域的重大突破。这些模型旨在理解和解释视觉和语言数据之间复杂的相互作用,从而能够更深入地理解多媒体内容。它们的重要性在于处理和分析大量数据类型的能力,包括图像和文本,这对于图像识别、自然语言处理和自动推理等人工智能应用的进步至关重要。
但是扩展lvlm带来了巨大的挑战。随着这些模型的规模不断扩大,它们需要的计算资源也呈指数级增长。这种规模和复杂性的增加导致更高的成本和更大的能源消耗。更大的模型可能变得更容易出错和效率低下,因为管理和训练它们变得越来越困难。

MoE-LLaVA
MoE-LLaVA,即大型视觉语言模型混合专家,在人工智能和机器学习领域引入了一个新的框架。这种方法在结构和功能上明显不同于传统的lvlm。传统的lvlm通常依赖于密集模型,其中模型的所有部分在处理期间都是活动的。相比之下,MoE-LLaVA采用了“专家混合”设计,这是一种稀疏模型的形式。
在“混合专家”方法中,模型由许多“专家”组成,每个“专家”专门从事数据处理任务的不同方面。然而,与密集模型不同,并非所有专家都同时活跃。MoE-LLaVA在任何给定时刻为给定任务动态选择最相关的专家(top-k专家)。
这种选择性激活减少了计算负载和资源消耗,显著提高了模型效率。通过专注于每个任务中模型最相关的部分,MoE-LLaVA在保持计算效率的同时实现了高性能水平,这是传统的密集结构LVLMs的一大进步。

技术框架
MoE-LLaVA中的专家是模型中的专门模块,每个模块都针对特定类型的数据或任务进行了微调。在处理过程中,模型会评估哪些专家最适合当前数据,并只激活这些专家,有效地提高了处理的针对性和效率。这种方法再计算成本很小的情况下确保了MoE-LLaVA的高性能和准确性,这种效率和效果的平衡是MoE-LLaVA在人工智能和机器学习领域脱颖而出的原因。
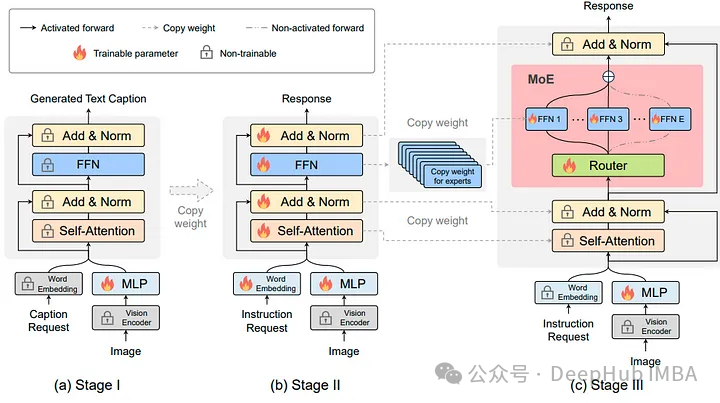
MoE-LLaVA的架构详细而复杂,包含多个组件:
视觉编码器:将输入图像转换为视觉表示。
词嵌入层:处理文本数据。
MLP(多层感知机):将视觉标记投射到语言模型的域中,将它们视为伪文本标记。
分层LLM块:由多头自注意机制和前馈神经网络组成,集成了视觉和文本数据。
MoE模块:作为架构的核心,这些模块包含多个专家的前馈网络(ffn)。
路由机制:决定令牌分配给不同的专家。
Top-k专家激活:只激活与给定令牌最相关的专家,从而提高效率。
稀疏路径:允许动态和有效的数据处理,适应不同的模式和任务。
MoE微调
MoE-tuning是一个复杂的三阶段训练策略,旨在优化具有混合专家的LVLMs的性能:
阶段1:重点关注使图像标记适应语言模型,使用MLP将这些标记投射到语言模型的领域,将它们视为伪文本标记。
阶段2:涉及对多模态指令数据进行调优,以增强模型的能力。这个阶段将模型调整为具有多模态理解的LVLM。
阶段3:FFN被多次复制以初始化模型中的专家。然后MoE层处理令牌,每个令牌由top-k专家处理,从而形成一个用稀疏方法有效处理任务的模型。
样例展示
# use phi2deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Phi2-2.7B-4e" --image-file "image.jpg"# use qwendeepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Qwen-1.8B-4e" --image-file "image.jpg"# use stablelmdeepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-StableLM-1.6B-4e" --image-file "image.jpg

使用代码示例
目前已经有多个预训练模型发布,可以直接拿来使用

我们首先安装必要的库
git clone https://github.com/PKU-YuanGroup/MoE-LLaVAcd MoE-LLaVAconda create -n moellava python=3.10 -yconda activate moellavapip install --upgrade pip # enable PEP 660 supportpip install -e .pip install -e ".[train]"pip install flash-attn --no-build-isolation# Below are optional. For Qwen model.git clone https://github.com/Dao-AILab/flash-attentioncd flash-attention && pip install .# Below are optional. Installing them might be slow.# pip install csrc/layer_norm# If the version of flash-attn is higher than 2.1.1, the following is not needed.# pip install csrc/rotary
我们这里加载模型(LanguageBind/MoE-LLaVA-Phi2-2.7B-4e),
import torchfrom PIL import Imagefrom moellava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKENfrom moellava.conversation import conv_templates, SeparatorStylefrom moellava.model.builder import load_pretrained_modelfrom moellava.utils import disable_torch_initfrom moellava.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteriadef main():disable_torch_init()image = 'moellava/serve/examples/extreme_ironing.jpg'inp = 'What is unusual about this image?'model_path = 'LanguageBind/MoE-LLaVA-Phi2-2.7B-4e' # LanguageBind/MoE-LLaVA-Qwen-1.8B-4e or LanguageBind/MoE-LLaVA-StableLM-1.6B-4edevice = 'cuda'load_4bit, load_8bit = False, False # FIXME: Deepspeed support 4bit or 8bit?model_name = get_model_name_from_path(model_path)tokenizer, model, processor, context_len = load_pretrained_model(model_path, None, model_name, load_8bit, load_4bit, device=device)image_processor = processor['image']conv_mode = "phi" # qwen or stablelmconv = conv_templates[conv_mode].copy()roles = conv.rolesimage_tensor = image_processor.preprocess(Image.open(image).convert('RGB'), return_tensors='pt')['pixel_values'].to(model.device, dtype=torch.float16)print(f"{roles[1]}: {inp}")inp = DEFAULT_IMAGE_TOKEN + '\n' + inpconv.append_message(conv.roles[0], inp)conv.append_message(conv.roles[1], None)prompt = conv.get_prompt()input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2keywords = [stop_str]stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)with torch.inference_mode():output_ids = model.generate(input_ids,images=image_tensor,do_sample=True,temperature=0.2,max_new_tokens=1024,use_cache=True,stopping_criteria=[stopping_criteria])outputs = tokenizer.decode(output_ids[0, input_ids.shape[1]:], skip_special_tokens=True).strip()print(outputs)if __name__ == '__main__':main()
将上面代码保存成predict.py,然后运行
deepspeed --include localhost:0 predict.py
结果评估
与最先进模型的比较分析
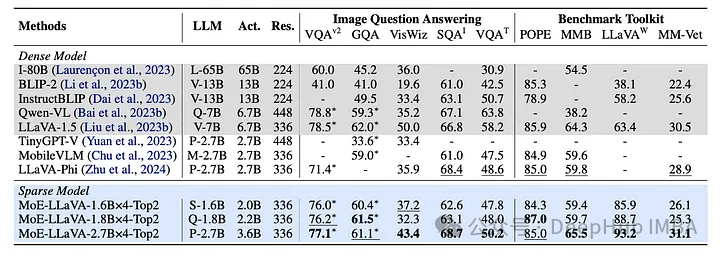
MoE-LLaVA框架在一系列视觉理解任务中表现出卓越的性能,通过严格的基准测试,MoE-LLaVA不仅匹配而且在某些情况下超过了现有LVLMs的性能。
总结
MoE-LLaVA代表了大型视觉语言模型(LVLMs)发展的重大飞跃。通过集成混合专家方法,解决了传统LVLMs固有的计算效率低下和缩放困难的核心挑战。MoE-LLaVA的创新设计,包括专家激活机制,不仅提高了效率,而且提高了准确性,减少了模型输出的幻觉。
MoE-LLaVA框架体现了LVLM研究的重大飞跃,提供了可扩展、高效和有效的解决方案,为该领域的未来发展铺平了道路。它的发展不仅展示了将MoE架构集成到lvlm中的潜力,而且还激发了在创建强大而实用的人工智能系统方面的持续探索和创新。
论文地址:
https://avoid.overfit.cn/post/2b965fa8f73647c19679f1611fd37af2