本地部署DeepSeek-RI打造自己的私有知识库
一、本地部署需要借助Ollama,Ollama是一个开源框架,专为在本地机器上便捷部署和运行大模型语言模型LLLM而设计
官网:https://ollama.com/
1、安装ollama
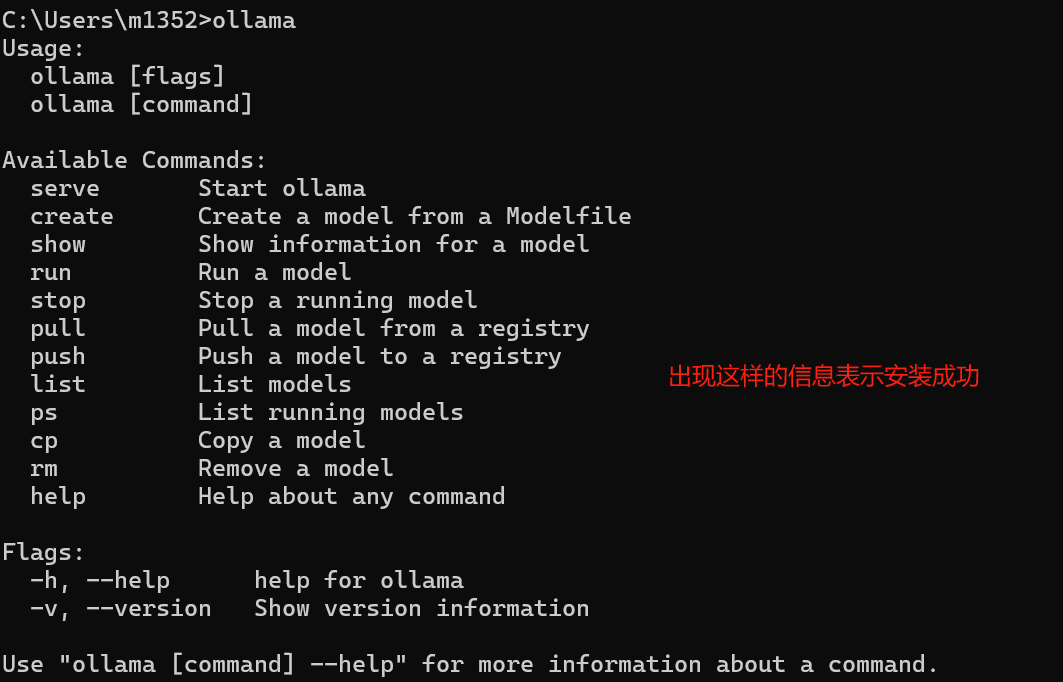
官网下载后,直接就可以进行安装,安装后再终端输入:olllama
2、 本地部署DeepSeek RI
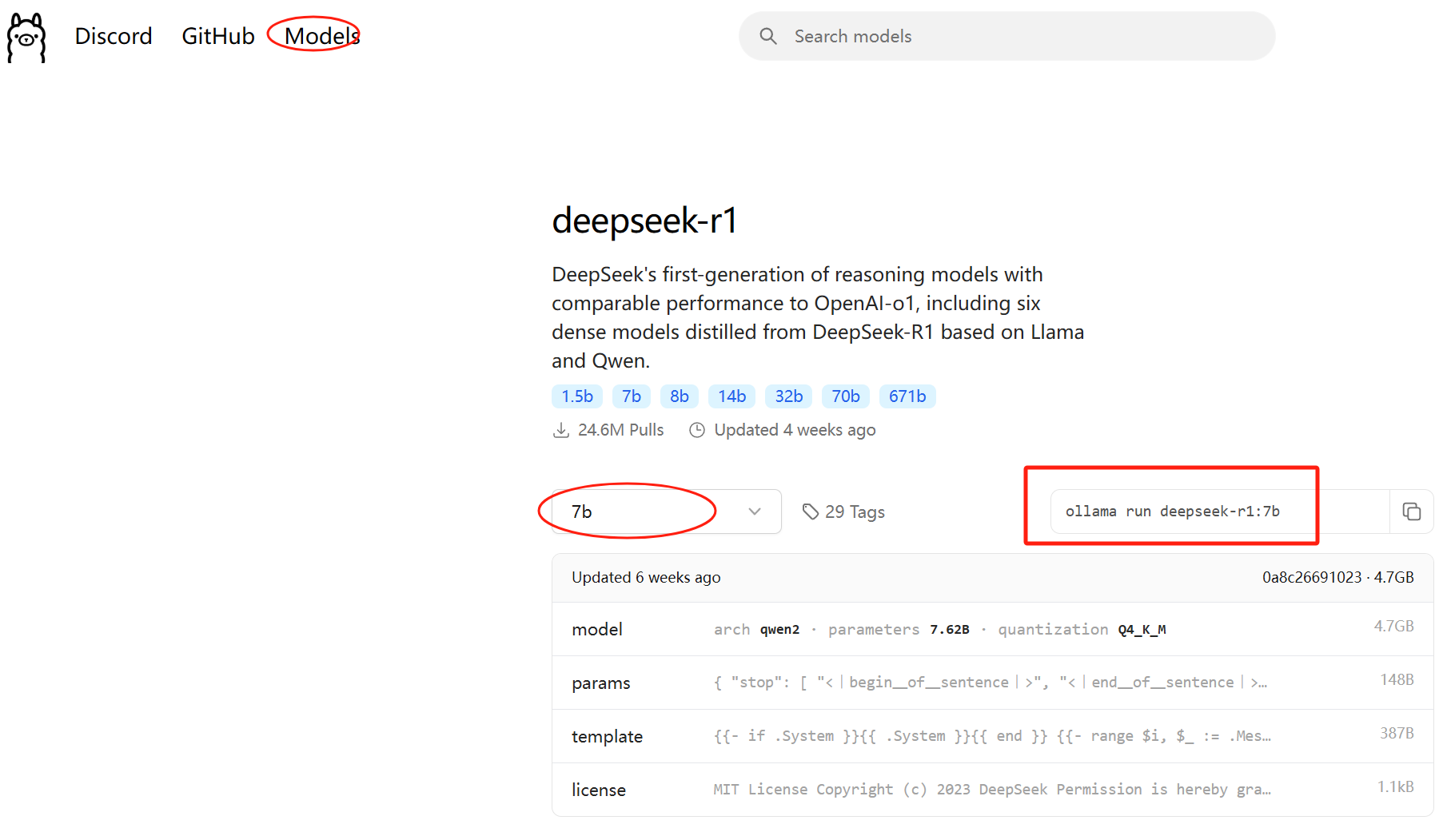
1)在ollma官网,点击Models按钮,进入模型选择页面,可以看到有deepseek ri等模型
2)点击deepseek-r1,可以看到提供了1.5b、7b、8b、14b、32b、70b、671b 这几种规模大小的模型下载。毫无疑问,数字越大,需要的机器配置越高
选择哪种,可以参考下面的列表: 1.5B:CPU最低4核,内存8GB+,硬盘3GB+存储空间,显卡非必需,若GPU加速可选4GB+ 显存,适合低资源设备部署等场景。 7B:CPU 8核以上,内存16GB+,硬盘8GB+,显卡推荐8GB+显存,可用于本地开发测试等 场景。 8B:硬件需求与7B相近略高,适合需更高精度的轻量级任务。 14B:CPU 12核以上,内存32GB+,硬盘15GB+,显卡16GB+显存,可用于企业级复杂任务 等场景。 32B:CPU 16核以上,内存64GB+,硬盘30GB+,显卡24GB+显存,适合高精度专业领域任 务等场景。 70B:CPU 32核以上,内存128GB+,硬盘70GB+,显卡需多卡并行,适合科研机构等进行高 复杂度生成任务等场景。选择哪种,可以参考下面的列表: 1.5B:CPU最低4核,内存8GB+,硬盘3GB+存储空间,显卡非必需,若GPU加速可选4GB+ 显存,适合低资源设备部署等场景。 7B:CPU 8核以上,内存16GB+,硬盘8GB+,显卡推荐8GB+显存,可用于本地开发测试等 场景。 8B:硬件需求与7B相近略高,适合需更高精度的轻量级任务。 14B:CPU 12核以上,内存32GB+,硬盘15GB+,显卡16GB+显存,可用于企业级复杂任务 等场景。 32B:CPU 16核以上,内存64GB+,硬盘30GB+,显卡24GB+显存,适合高精度专业领域任 务等场景。 70B:CPU 32核以上,内存128GB+,硬盘70GB+,显卡需多卡并行,适合科研机构等进行高 复杂度生成任务等场景。
3)选择合适的参数后,复制具体的命令(ollama run deepseek-r1:7b),在终端黏贴惊醒安装
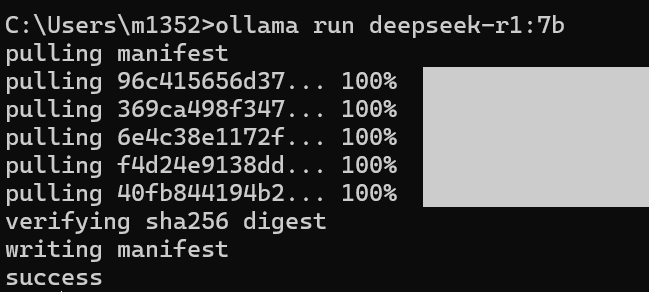
4)安装完成后,就可以在本地使用deepseek-R1了

二、本地部署DIfy
什么是dify:生成式AI应用创新引擎。开源的LLM应用开发平台,提供从Agent构建到AI workflow编排、RAG检索、模型管理等能力,轻松构建和运营生成式AI原生应用。比LangChain更易用
上面的步骤已经部署了dp了,但是为了方便后面的RAG的使用,我们需要借助Dify改进这一点
dify官网:https://dify.ai/zh
1、dify的运行需要docker,docker官网:https://www.docker.com/ 下载安装docker的桌面客户端
 双击运行
双击运行
2、