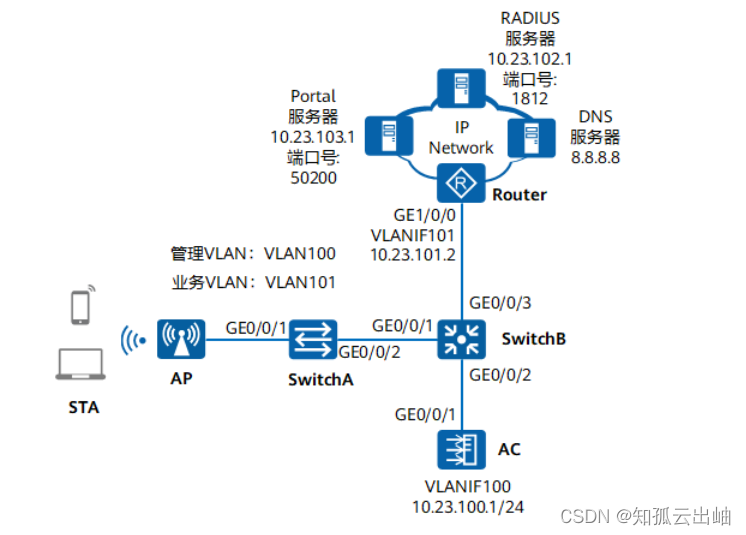
1 需求背景
在全球数据量呈指数级暴涨,算力相对于AI运算供不应求的现状下,存算一体技术主要解决了高算力带来的高能耗成本矛盾问题,有望实现降低一个数量级的单位算力能耗,在功耗敏感的百亿级AIoT设备上、高能耗的数据中心、自动驾驶等领域有望发挥其低功耗、低时延、高算力密度等优势。

在现有的成熟架构及工艺下,当前依靠制程技术进步,增加晶体管密度提升算力、降低功耗已逐步趋于物理极限,且成本逐步提高;
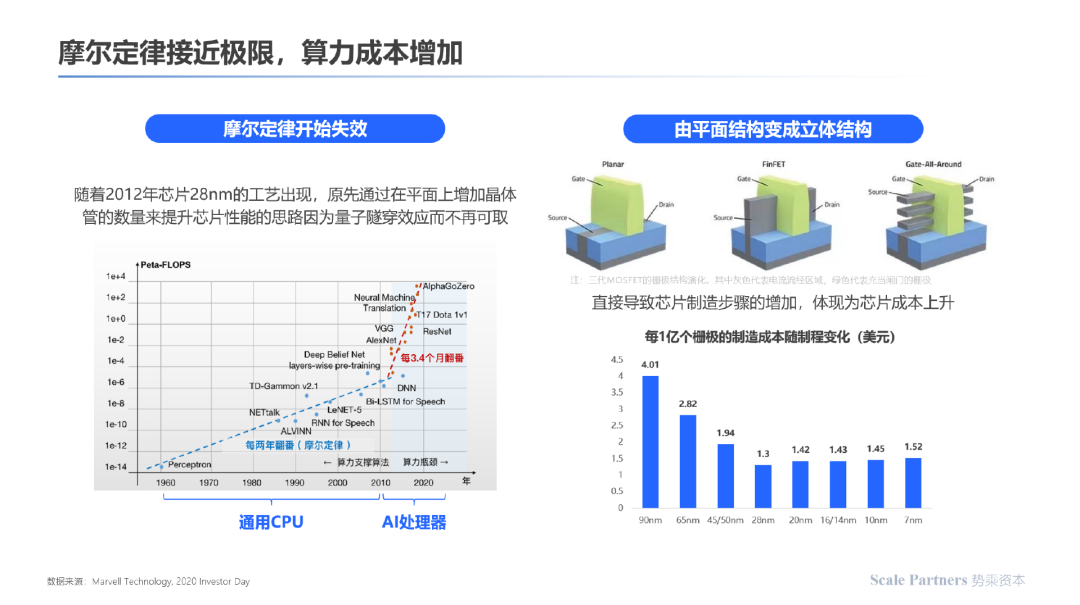
在冯诺依曼架构下,由于数据存储与运算单元分离,算力提升受限,功耗增加:
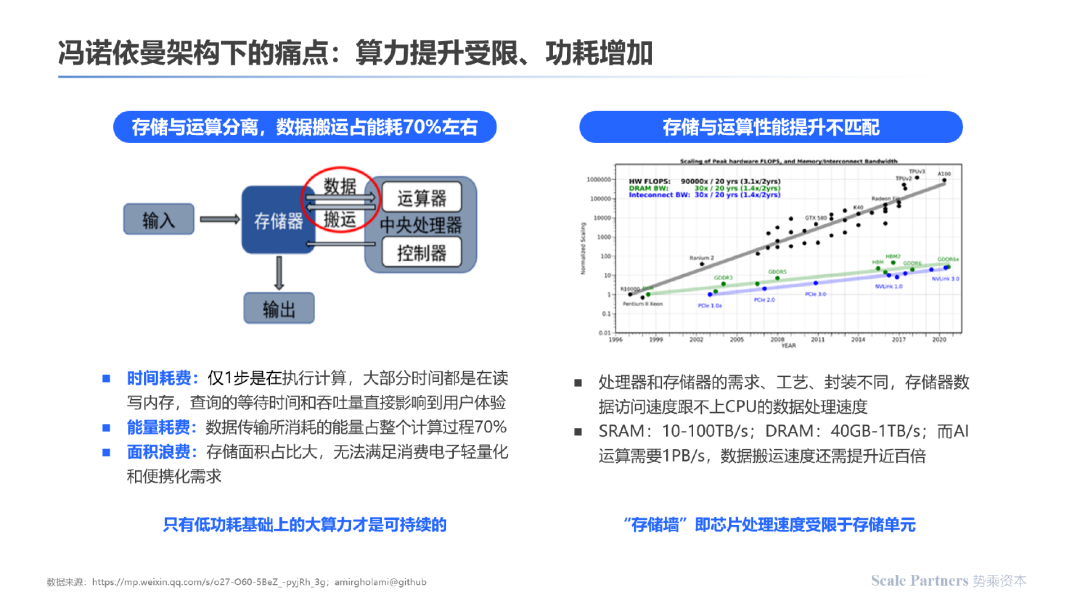
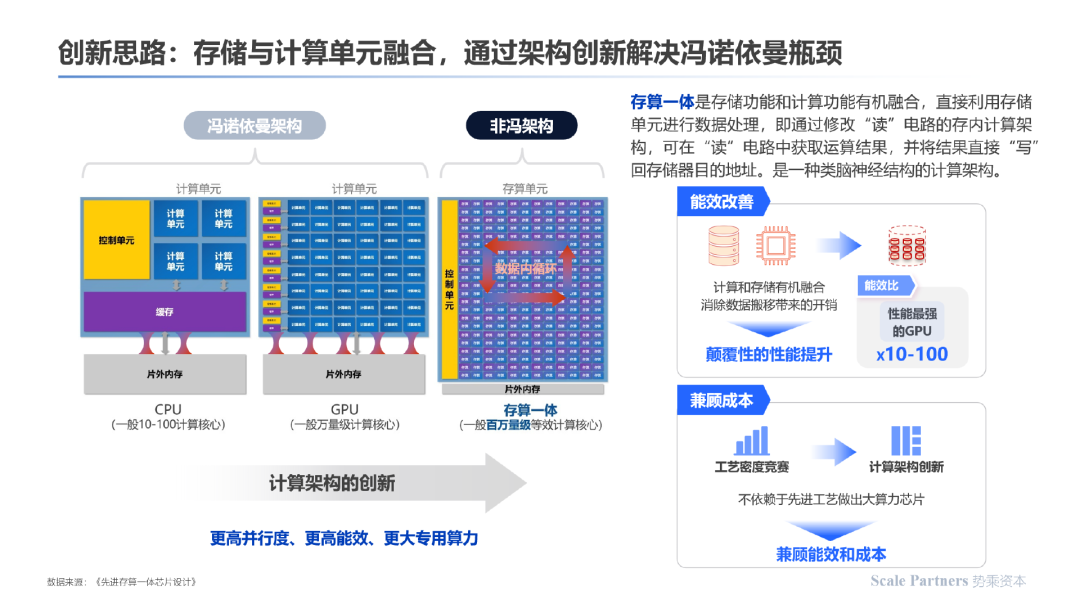
应对存储单元与计算单元分离的现状,存算一体技术思路应运而生,在器件单元上存储与计算单元融合,通过底层的架构创新解决冯诺依曼架构的固有瓶颈:
由于存储介质技术在近年来不断突破,此外AIoT时代对于设备的智能化、低功耗、体积小、低时延等特性提出了天然要求(而现有的技术路线未能很好的满足需求),在技术突破叠加市场需求的双重作用力下,存算一体技术当前已到达产业化爆发拐点:
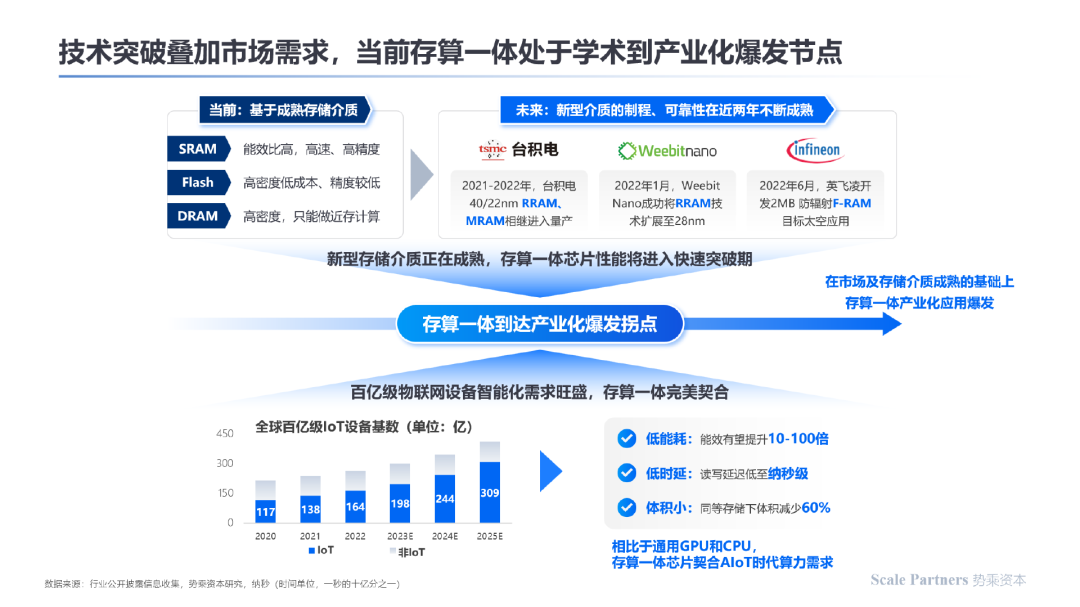
相对于五十多年前CPU的诞生以及二十多年前GPU的诞生,当前存算一体技术仍处于早期阶段,未来依靠其更好的并行度、更好的能效比等特性,有望成为智能化时代的主流算力平台之一,与现有的算力解决方案互为补充。
2 概念与原理
存算一体是一种通过将数据存储单元与计算单元距离拉近、互相融合,从而提升访存带宽、减少访存功耗的技术。
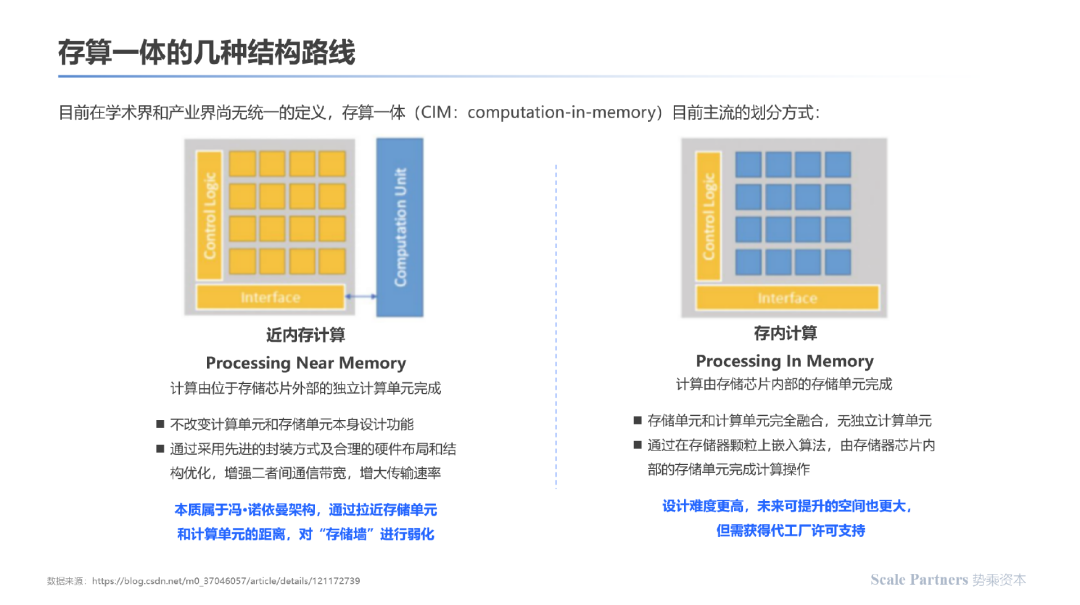
近存计算:不改变计算单元和存储单元本身设计功能,通过采用先进的封装方式及合理的硬件布局和结构优化,增强二者间通信宽带,增大传输速率;本质上属于冯诺依曼架构,通过拉近存储单元和计算单元的距离,对“存储墙”进行优化。
存内计算:存储单元与计算单元完全融合,无独立计算单元,通过存储器颗粒上嵌入算法,由存储器芯片内部的存储单元完成计算操作;其设计难度更高,未来可提升的空间也更大,但需要获得代工厂许可支持。本文所探讨是存算一体/存内计算企业主要集中于这类。

3 技术路线
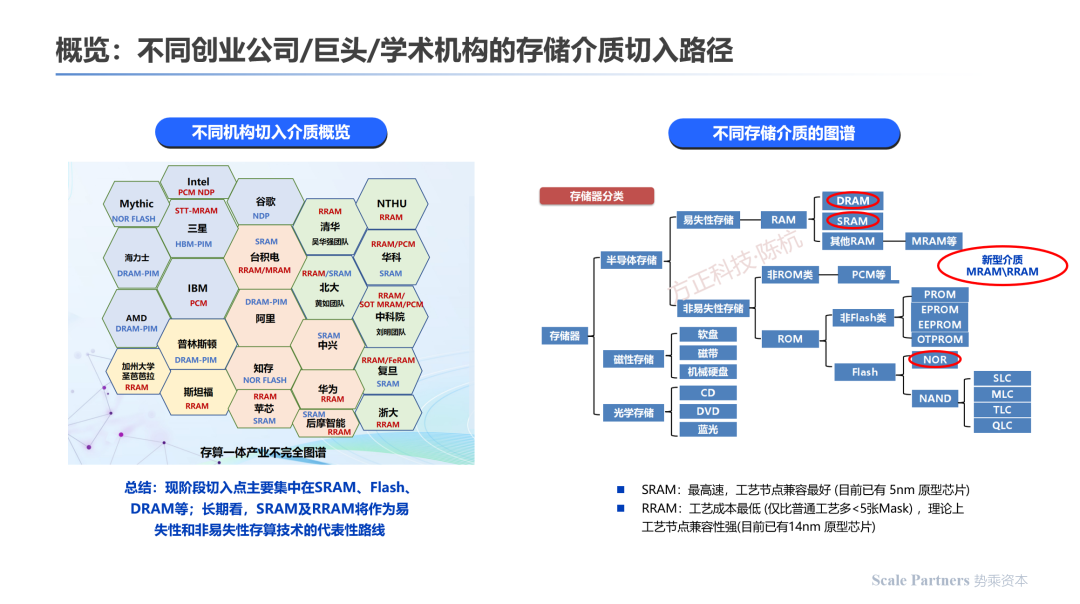
分析存算一体,当前存算一体芯片研发企业/机构在成熟介质上的切入点集中在SRAM、Nor-Flash和DRAM等;部分学术机构选择切入RRAM等新型介质研发。
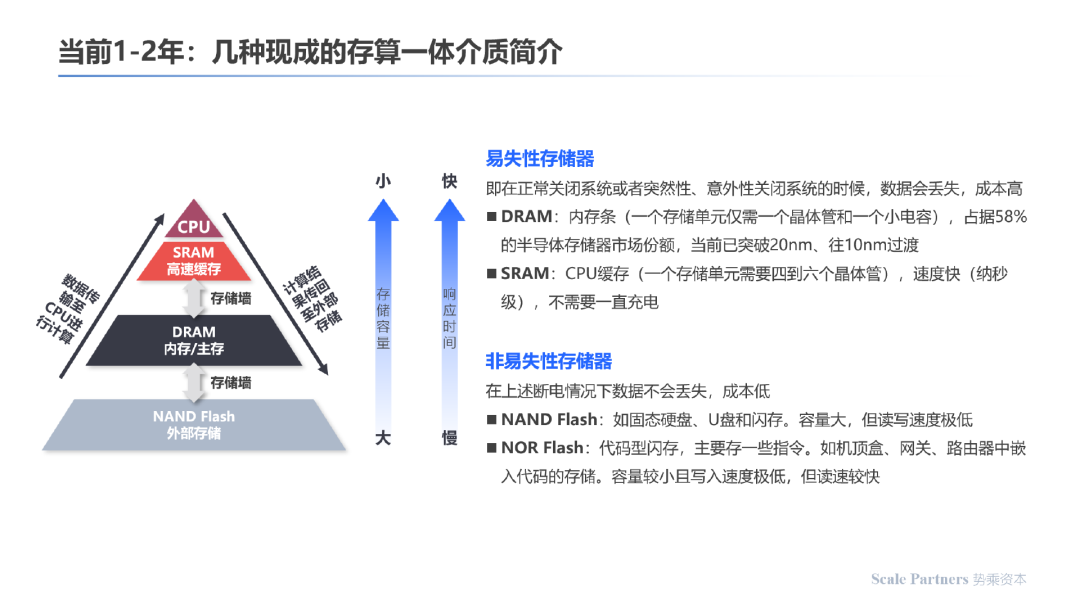
从存储介质的分类来讲,分为易失性存储器和非易失性存储器。
易失性存储器:即在正常关闭系统或者突然性、意外性关闭系统的时候,数据会丢失,成本高。如SRAM、DRAM;
非易失性存储器: 在上述断电情况下数据不会丢失,成本低。如FLASH;
不同的存储介质在计算机架构中均承担着必要的工作任务,其中SRAM距离CPU最近,响应时间最快,存储容量较小, 其次分别是DRAM、NAND-Flash等介质。
3.1 SRAM
SRAM:CPU缓存(一个存储单元需要4-6个晶体管),特点是速度最快(纳秒级),不需要一直充电。
优势是存储密度高于SRAM,适合数据中心等处理大容量模型的场景;但与CMOS工艺不兼容,访存性能和能效不如SRAM,其次设计需要DRAM vendor的支持。基于DRAM的存算技术路线大致有四类,具体如下:
- 基于SRAM的近存计算:通常指采用大量片上SRAM作为缓存的计算架构,计算采用数字方式、精度较高、通常面向大算力场景,代表:Graphcore、Tenstorrent等;
- 基于SRAM的数字存内计算:改造SRAM阵列,加入数字计算逻辑单元,在SRAM阵列中支持MAC计算,进一步提升Tensor计算的性能、减少功耗,适合AI大算力场景,代表:后摩智能、苹芯、TSMC等;
- 基于SRAM的模拟存内计算:改造SRAM宏单元,利用电流、电荷累计等模拟计算方式,支持MAC计算,在低精度计算场景有低功耗的优势,适合边缘/物联网等低算力、低功耗的场景。代表:九天睿芯;
3.2 DRAM
DRAM:内存条(一个存储单元仅需一个晶体管和一个小电容),占据58%的半导体存储市场份额,当前已突破20nm,往10nm过渡。
优势是存储密度高于SRAM,适合数据中心等处理大容量模型的场景;但与CMOS工艺不兼容,访存性能和能效不如SRAM,其次设计需要DRAM vendor的支持。基于DRAM的存算技术路线大致有四类,具体如下:
- 基于2D DRAM的近存计算:在DRAM芯片内部加入定制计算单元或者通用处理器,能够显著提升访存带宽,减少能耗,这种2D设计的好处是性价比高、可扩展性好,但是由于DRAM工艺的限制,能提供的计算密度受限,而且跨芯片间的通信带宽依旧受限,代表:Upmem、三星、海力士等;
- 基于2.5D DRAM的近存计算:利用2.5D集成技术,高性能计算芯片将HBM与处理单元集成在一起,提供大访存带宽,适用于大算力的场景,主要挑战是价格昂贵,功耗较高,代表:GPU、TPU、寒武纪等。
- 基于3D DRAM的近存计算:将计算单元与DRAM进行堆叠,甚至对HBM内部进行改造,把其中部分存储替换为计算单元,从而进一步提升带宽并减少访存功耗,相应的代价是增加了功耗密度、减少了存储容量等,代表:三星、平头哥等;
- 基于DRAM的存内计算:修改DRAM的存储阵列,来支持基本的计算逻辑,因为对DRAM修改较大,主要在学术界提出一些原型设计;
3.3 FLASH
优势是存储密度高,但读写速度慢、擦写次数受限明显。
NAND Flash:如固态硬盘、U盘和内存;容量大,但读写速度极低
NOR Flash:代码型内存,主要存一些指令;如机顶盒、网关、路由器中嵌入代码的存储;容量较小且写入数据极低,但读速较快。
基于Flash的存算技术路线大致有两类,具体如下:
- 基于SSD的近存计算:也称为计算存储设备(Computational Storage Drive, CSD),在SSD控制器内/附近加入计算单元或者处理器,主要面向数据中心的大规模数据密集应用(如数据库,大数据分析等),代表:三星/Xilinx,ScaleFlux, NGD Systems等;
- 基于Flash的模拟存内计算:基于Flash的模拟存内计算功耗低,但是由于写入速度慢,且高精度(即每个cell存储多比特)数值写入有挑战,适合模型固定的低功耗应用场景,代表:知存科技、Mythic、闪忆科技等;
3.4 新型工艺
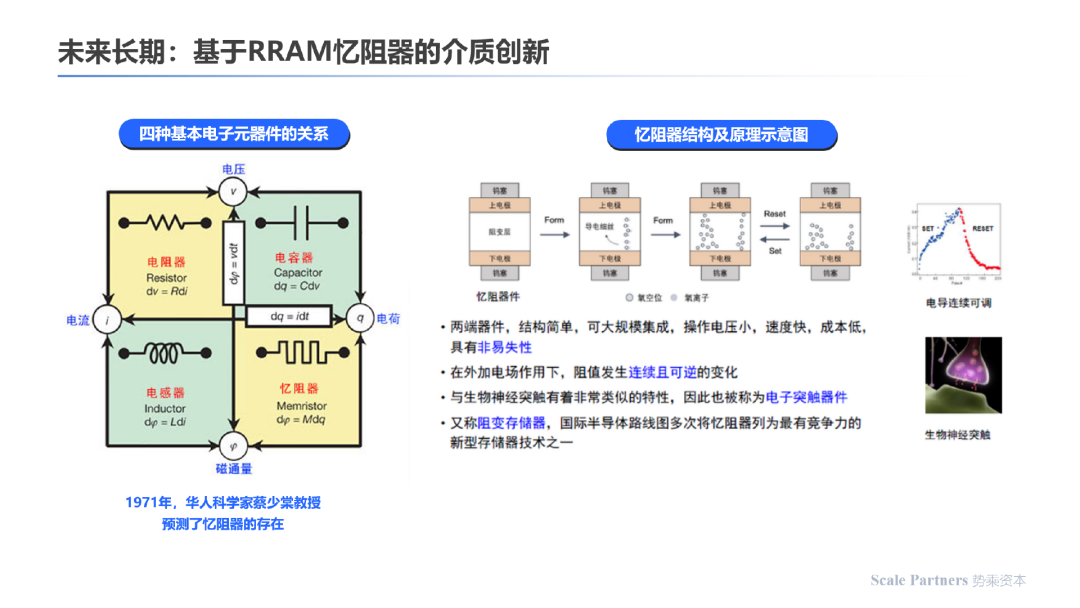
长期来看,存算一体芯片产品化的快速发展离不开新型存储介质成熟度提升的助推,以下为不同新型存储介质的原理比较:

长期来看,RRAM(忆阻器)是除了电阻器、电容器、电感器之外的一大新发现;其与生物神经突触有着非常类似的特性,因此也被成为电子突触器件。
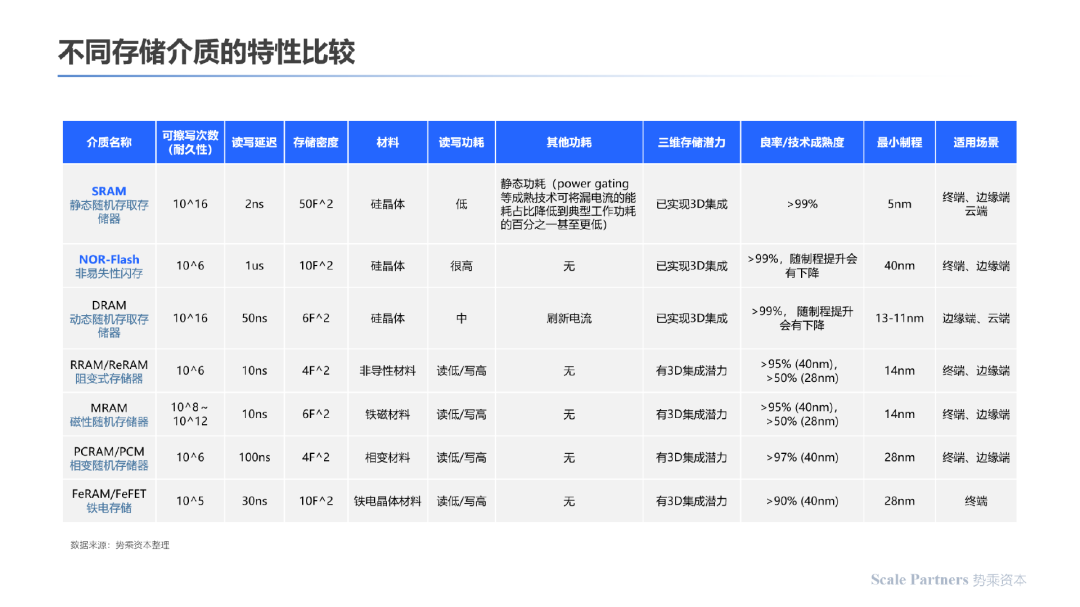
以下为新型存储介质的性能比较:

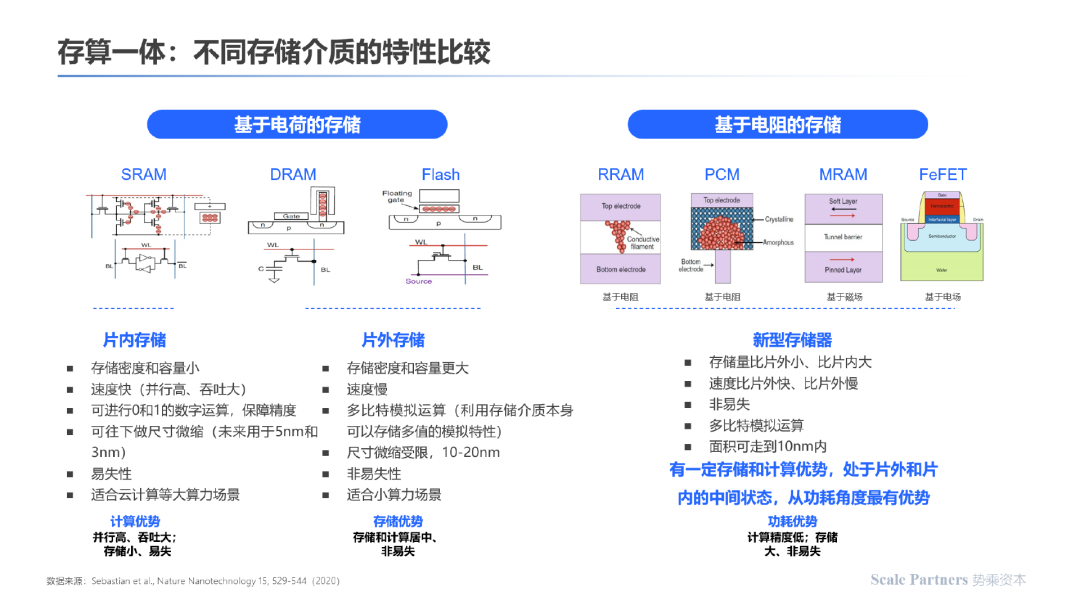
3.5 性能比较
以下为不同存储介质的存储原理及客观性能比较;其中成熟的存储介质如SRAM、DRAM、Flash基于电荷的移动完成数据存储;新型存储介质与RRAM、MRAM等基于电阻大小的变化完成数据存储功能。

4 挑战
存算一体技术是一门非常复杂的综合性创新,产业还算不上成熟,在产业链方面仍旧存在上游支撑不足,下游应用不匹配的诸多挑战,但诸多的挑战同时也构成了当前存算一体创新未来可构筑的综合性壁垒。

5 趋势
存算一体技术发展趋势:更高精度、更高算力、更高能效。

6 人才与生态
(1)作为一个新领域,存算一体芯片复合型人才稀缺,人才更多在学术界。
完成存算一体芯片的产品化开发,需同时具备较强的学术原创能力(存算一体的架构和编译器设计、存算相关的量化算法开发等)及工程实践能力(场景理解能力、芯片落地能力)。
(2)从上游到下游的生态不完整,既是挑战也是机遇。
存算一体芯片的大规模落地需与芯片厂商、软件工具厂商以及应用集成厂商等产业生态合作伙伴的大力协同研发和推广应用。
需有一套方便、可用的工具链和软件,让采购方迁移成本低。
兼容现有的软件生态,让采购方用起来“无感”,如可直接利用现有GPU训练软件框架。
引导采购方逐步切入专用工具链进行模型适配、压缩等,更好利用存算一体的优势,逐步建立生态。
7 相关企业
国内存算一体芯片企业有:知存科技、苹芯科技、后摩智能、亿铸科技、智芯科、千芯科技、九天睿芯等创新企业;国外有如Mythic、Syntiant等公司。
知存科技:在存内计算芯片的研发和推广方面处于领先地位。他们的WTM2101基于nor flash存储介质,40nm的制程实现了超低功耗以及高算力。特别适用于智能语音和智能健康等领域。该公司不仅在技术上取得了突破,2023年1月还获得了2亿元的B2轮融资,显示了市场对其发展的认可和期待。

CSDN首个存内计算开发者社区来了,基于各界产学研存内技术研究,涵盖最丰富的存内计算内容,以存内技术为核心,史无前例的技术开源内容,囊括云/边/端侧商业化应用解析以及AI时代新技术趋势洞察等, 邀请业内大咖定期举办存内workshop,实战演练体验前沿架构;从理论到实践,做为最佳窗口,存内计算让你触手可及。
传送门:https://bbs.csdn.net/forums/computinginmemory?category=10003;
首个存内计算开发者社区,现0门槛新人加入,发文享积分兑超值礼品;
存内计算先锋/大使在社区投稿,可获得双倍积分,以及社区精选流量推送;
此外,您的精选文章可获得社区奖金激励800,可获得线下训练营的免费名额以及存内主题活动大咖交流机会;
社区优先赠送存内计算技术与应用精选论文,GitHub - CIMDeveloper/CIM-Files,请查收~
参考文献:
https://mp.weixin.qq.com/s/XvxzFQnKFliabFf8iey7cQ
https://blog.csdn.net/younger_china/article/details/135960527

![【蓝桥杯冲冲冲】[NOIP2017 提高组] 宝藏](https://img-blog.csdnimg.cn/img_convert/0133354571d6164ee90cda7abb9e9549.png)