1,大模型本地部署
视频说明地址:
https://www.bilibili.com/video/BV1BF4m1u769/
【创新思考】(1):使用x86架构+Nvidia消费显卡12G显存,搭建智能终端,将大模型本地化部署,语音交互机器人设计,初步设计
慢慢的,1-2B的小模型也发展起来。
在消费显卡上面的显存也足够运行了。让设备在终端运行速度更快了。
服务端虽然也可以解决智能化,但是本地的优势是速度快,离线。
市面上大部分的都是基于 arm 做android 应用开发。
有个局限性就是算力不够。
但是使用x86 和消费显卡,可以解决这个问题。相对的功耗也增加了。
这些智能设备可以固定使用电源供电。
并不是要解决所有问题,只解决特殊的需要离线的速度快的智能计算场景上。
2,基于大模型的语言交互方案
基于大模型的语言处理
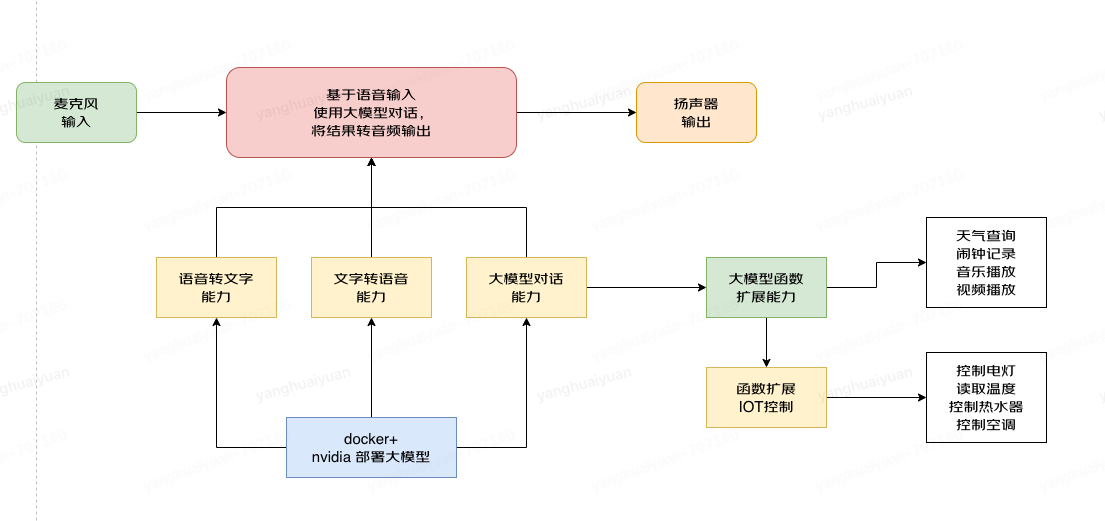
3,在边缘端持函数调用的模型chatglm3,qwen7b
目前有两个模型支持函数调用,chatglm3 qwen7b 都可以在本地部署。
使用 8bit 量化版本部署内存占用在 8G 左右。
之前的技术调研研究过:
使用Xinference框架,部署Qwen和ChatGLM3的大模型,支持函数调用:
https://yanghuaiyuan.blog.csdn.net/article/details/135964461
函数调用是 OpenAI GPT-4 和 GPT-3.5 Turbo 模型的高级特性,它使得模型能够根据用户指令决定是否调用相应的函数,以结构化的格式返回信息,而不是仅提供普通的文本回答。 这种整合了大型语言模型与外部工具及API的能力,显著增强了模型的应用潜力。
例如,要获取实时天气信息,ChatGPT 本身不具备实时数据;函数调用则开辟了一条通道,使得 AI 能够与外部系统互动,如接入信息检索系统、查询实时天气、执行代码等。 这使得基于大型语言模型的智能代理能够执行更为复杂的任务,大幅提升了模型的实用性和应用领域的广度。
在接下来的内容中,我们将演示如何利用 Xinference 在本地部署大语言模型 Qwen,并实现类似 OpenAI 的函数调用。此外,我们将评估 ChatGLM3 和 Qwen 在特定数据集上,函数调用的准确性, 并分析其出错的潜在原因。这些评估将帮助我们更深入地理解这些模型的能力和限制,为实际应用提供洞见。
然后就可以根据相关的,天气预报,开发特定函数接口实现了。
使用 xinference 启动成:
4,硬件设备MX3060 有12G显存
并不需要去自己制作设备,有现成的使用游戏小主机就可以。
然后再配合触摸屏实现。
还真的有这么小的MX3060显卡设备:

https://item.jd.com/10094149248405.html
再配合电容屏 10英寸1024*600触摸屏:
https://item.jd.com/44632987581.html#crumb-wrap
5,创新就是利用现有的技术创新
组合创新,对现有技术进行理解思考。
能不能有新的方案,带来不一样的体验。
为啥要在设备端部署大模型。
因为模型的运行需要大量的资源消耗,同时也存在热点问题,高峰问题。
需要海量的资源,去提高吞吐量。
但是要是模型在边缘端完成了主要的运行,就可以降低服务端的负载。
同时在边缘端也可以降低延迟,提高响应速度,也可以进行离线计算。
6,设备外形
外形设计成这样,可以使用现成的壳子,因为没有人帮忙设计外壳。

https://item.jd.com/10077452549041.html#crumb-wrap