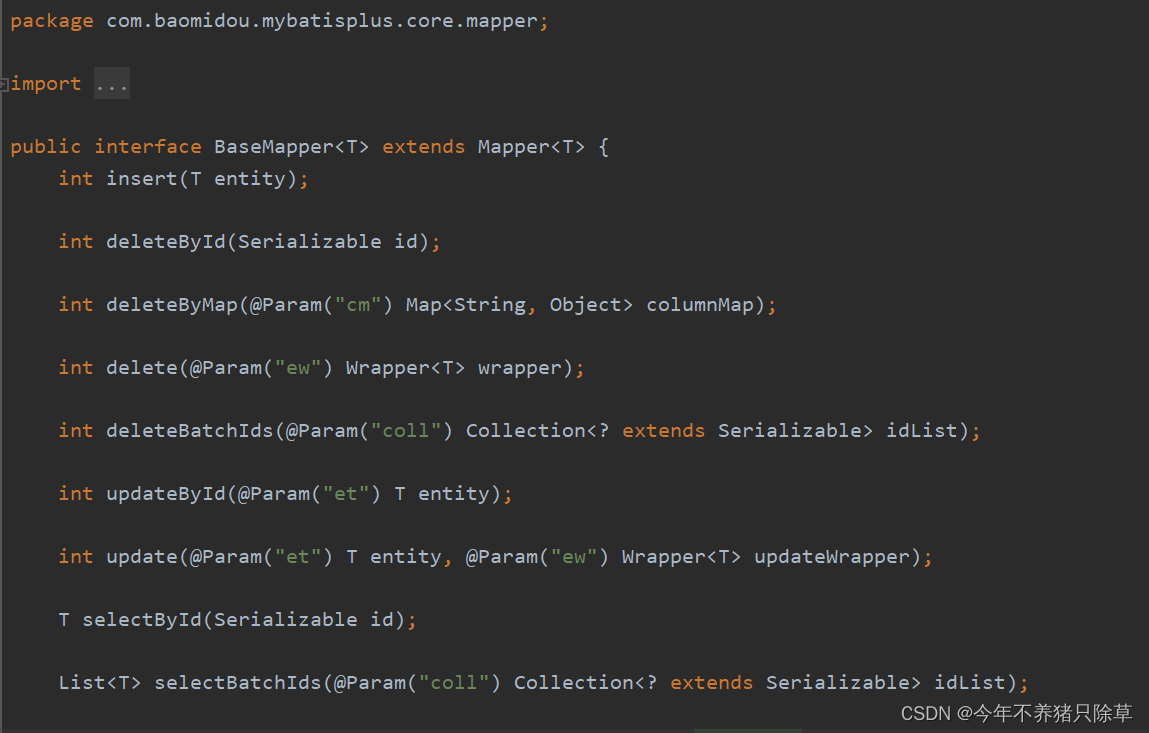
BaseMapper封装的17种增删改查方法
MybatisPlus框架中mapper层继承了BaseMapper接口,该接口中封装了常用的增删改查方法,共有17种,以下是方法的详情介绍
首先需要明确的括号内的一些对象定义
- 泛型
T:实体类类型 @Param注解:指定了参数名称et:实体类对象ew:查询条件wrapper对象
1.插入一条数据 int insert(T entity)
T entity = new T(); // 创建实体对象baseMapper.insert(entity); // 插入数据
2.根据主键id删除数据 int deleteById(Serializable id)
Serializable id = 1L; // 要删除的实体的主键ID=xxxbaseMapper.deleteById(id); // 删除数据
3.map集合根据条件删除数据 int deleteByMap(@Param(“cm”) Map<String, Object> columnMap)
Map<String, Object> columnMap = new HashMap<>();//创建一个map集合存放符合删除条件需要删除的数据columnMap.put("name", "wonwoo"); // 设置删除条件,比如name字段等于"wonwoo",将name字段等于"wonwoo"的数据放入创建的map集合baseMapper.deleteByMap(columnMap); // 删除满足条件的数据
4.高级查询根据条件删除数据 int delete(@Param(“ew”) Wrapper wrapper)
// 创建Wrapper对象,设置删除条件LambdaQueryWrapper<T> wrapper = new LambdaQueryWrapper<>();wrapper.eq(T::getName, "wonwoo"); // 设置删除条件,比如name字段等于"wonwoo"baseMapper.delete(wrapper); // 删除满足条件的数据
5.根据主键id批量删除数据 int deleteBatchIds(@Param(“coll”) Collection<? extends Serializable> idList)
Collection<? extends Serializable> idList = Arrays.asList(1L, 2L, 3L); // 要删除的实体的主键ID列表baseMapper.deleteBatchIds(idList); // 批量删除数据
6.根据主键id更新数据 int updateById(@Param(“et”) T entity)
T entity = new T(); // 创建实体对象entity.setId(1L); // 设置要更新的实体的主键IDbaseMapper.updateById(entity); // 更新数据
7.高级查询根据条件更新数据 int update(@Param(“et”) T entity, @Param(“ew”) Wrapper updateWrapper)
T entity = new T(); // 创建实体对象// 创建Wrapper对象,设置更新条件LambdaUpdateWrapper<T> updateWrapper = new LambdaUpdateWrapper<>();updateWrapper.eq(T::getName, "wonwoo"); // 设置更新条件,比如name字段等于"wonwoo"baseMapper.update(entity, updateWrapper); // 更新满足条件的数据
8.根据主键id查询数据 T selectById(Serializable id)
Serializable id = 1L; // 要查询的实体的主键IDT entity = baseMapper.selectById(id); // 查询数据
9.根据主键ID批量查询数据 List selectBatchIds(@Param(“coll”) Collection<? extends Serializable> idList)
Collection<? extends Serializable> idList = Arrays.asList(1L, 2L, 3L); // 要查询的实体的主键ID列表List<T> entityList = baseMapper.selectBatchIds(idList); // 批量查询数据
10.根据条件查询数据 List selectByMap(@Param(“cm”) Map<String, Object> columnMap)
Map<String, Object> columnMap = new HashMap<>();columnMap.put("name", "wonwoo"); // 设置查询条件,比如name字段等于"wonwoo"List<T> entityList = baseMapper.selectByMap(columnMap); // 查询满足条件的数据
11.根据条件查询单条数据 T selectOne(@Param(“ew”) Wrapper queryWrapper)
// 创建Wrapper对象,设置查询条件LambdaQueryWrapper<T> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.eq(T::getName, "wonwoo"); // 设置查询条件,比如name字段等于"wonwoo"T entity = baseMapper.selectOne(queryWrapper); // 查询满足条件的数据
12.根据条件查询数据总数 Integer selectCount(@Param(“ew”) Wrapper queryWrapper)
// 创建Wrapper对象,设置查询条件LambdaQueryWrapper<T> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.eq(T::getName, "wonwoo"); // 设置查询条件,比如name字段等于"wonwoo"int count = baseMapper.selectCount(queryWrapper); // 查询满足条件的数据总数
13.根据条件查询数据列表 List selectList(@Param(“ew”) Wrapper queryWrapper)
// 创建Wrapper对象,设置查询条件LambdaQueryWrapper<T> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.eq(T::getAge, 18); // 设置查询条件,比如age字段等于18List<T> entityList = baseMapper.selectList(queryWrapper); // 查询满足条件的数据列表
14.根据条件查询数据列表,并返回Map集合 List<Map<String, Object>> selectMaps(@Param(“ew”) Wrapper queryWrapper)
// 创建Wrapper对象,设置查询条件LambdaQueryWrapper<T> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.eq(T::getAge, 18); // 设置查询条件,比如age字段等于18List<Map<String, Object>> mapList = baseMapper.selectMaps(queryWrapper); // 查询满足条件的数据列表,并返回Map集合
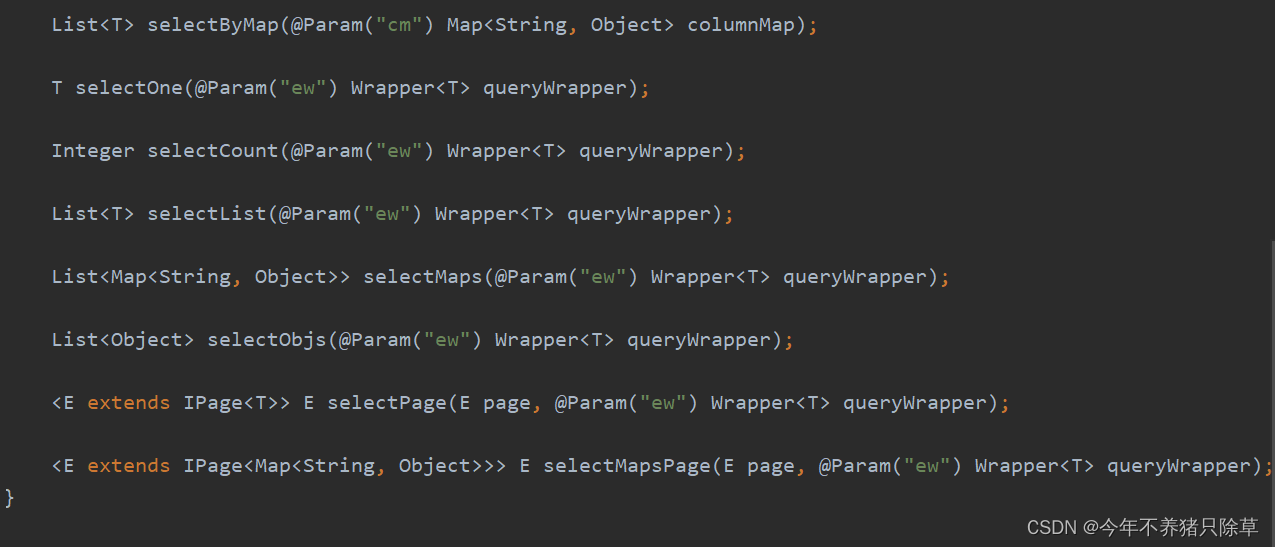
15.根据条件查询的父类 List selectObjs(@Param(“ew”) Wrapper queryWrapper)
16.根据条件分页查询数据 <E extends IPage> E selectPage(E page, @Param(“ew”) Wrapper queryWrapper)
// 创建Wrapper对象,设置查询条件LambdaQueryWrapper<T> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.eq(T::getAge, 18); // 设置查询条件,比如age字段等于18Page<T> page = new Page<>(1, 10); // 创建分页对象,设置当前页和每页显示数量IPage<T> pageResult = baseMapper.selectPage(page, queryWrapper); // 分页查询满足条件的数据List<T> entityList = pageResult.getRecords(); // 当前页的数据列表long total = pageResult.getTotal(); // 总记录数
17.根据条件分页查询(返回Map结果)<E extends IPage<Map<String, Object>>> E selectMapsPage(E page, @Param(“ew”) Wrapper queryWrapper)
Page<Map<String, Object>> mapPage = userMapper.selectMapsPage(page, queryWrapper);
总结
public interface UserMapper extends BaseMapper<User> {// 这里继承了BaseMapper中的所有方法,可以直接使用
}@Service
public class UserService {@Autowiredprivate UserMapper userMapper;public void example() {// 1. 根据ID查询User user1 = userMapper.selectById(1L);// 2. 插入数据User user = new User();user.setName("wonwoo");userMapper.insert(user);// 3. 更新数据user.setName("dk");userMapper.updateById(user);// 4. 根据ID删除userMapper.deleteById(user.getId());// 5. 根据条件查询QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.eq("name", "dk");List<User> users = userMapper.selectList(queryWrapper);// 6. 根据条件查询(返回Map结果)Map<String, Object> map = userMapper.selectMaps(queryWrapper);// 7. 根据条件分页查询Page<User> page = new Page<>(1, 10);queryWrapper.eq("name", "dk");Page<User> userPage = userMapper.selectPage(page, queryWrapper);// 8. 根据条件分页查询(返回Map结果)Page<Map<String, Object>> mapPage = userMapper.selectMapsPage(page, queryWrapper);// 9. 根据ID批量查询List<User> usersByIds = userMapper.selectBatchIds(Arrays.asList(1L, 2L, 3L));// 10. 根据条件查询一条数据User one = userMapper.selectOne(queryWrapper);// 11. 根据条件查询总记录数Integer count = userMapper.selectCount(queryWrapper);// 12. 根据ID批量删除userMapper.deleteBatchIds(Arrays.asList(1L, 2L, 3L));// 13. 根据条件批量删除userMapper.delete(queryWrapper);// 14. 根据ID批量更新user.setName("wonwoo");userMapper.updateById(user);// 15. 根据条件批量更新user.setName("dk");userMapper.update(user, queryWrapper);// 16. 根据ID批量插入userMapper.insertBatch(Arrays.asList(user1, user2));


![[word] word小数点对齐怎么设置 #微信#其他#其他](https://img-blog.csdnimg.cn/img_convert/b0974f455d620ab945b728f1d5982635.png)