建表删表
建表语句
--建表语句
create table Student
(ID INTEGER constraint Student_KEY_1 primary key,--设定主键,同时会自动创建唯一索引NAME VARCHAR2(50) NOT NULL , --设定非空SEX CHAR(1) constraint SEX_CHK CHECK (SEX IN ('0','1')),--添加检查性约束,值只能为0/1AGE NUMBER(3),BIRTHDAY DATE,Student_NUMBER NUMBER(3,1),--设定为:3位数字.1位数字Student_CHAR CHAR(10) default '默认值1',--注意CHAR类型对于不足的长度会自动补空格Student_VARCHAR2 VARCHAR2(10) default '默认值2'
);--添加注释
comment on table Student is '学生表';
comment on column Student.ID is '主键';
comment on column Student.NAME is '姓名';
comment on column Student.SEX is '性别';
comment on column Student.AGE is '年龄';
comment on column Student.BIRTHDAY is '生日';
comment on column Student.Student_NUMBER is 'NUMBER类型测试';
comment on column Student.Student_CHAR is 'CHAR类型测试';
comment on column Student.Student_VARCHAR2 is 'VARCHAR2类型测试';
删除表
--删除表,包括表数据和结构
drop table 表名-- 清空表数据
truncate table 表名
添加注释
--表注释
comment on table 表名 is '注释';
comment on table 所有者.表名 is '注释';--字段注释
comment on column 表名.字段名 is '注释';
comment on column 所有者.表名.字段名 is '注释';
字段类型
下表列出了几种常用数据类型。要注意,不同的关系数据库管理系统中支持的数据类型不完全相同
| 数据类型 | 含义 |
|---|---|
| CHAR(n),CHARACTER(n) | 长度为 n 的定长字符串,对于长度不足n的数据会自动补空格 |
| VARCHAR(n) ,CHARACTERVARYING(n) | 最大长度为 n 的变长字符串 |
| CLOB | 字符串大对象 |
| BLOB | 二进制大对 |
| INT,INTEGER | 长整数(4字节) |
| SMALLINT | 短整数(2字节) |
| BIGINT | 大整数(8字节) |
| NUMERIC(p,d) | 定点数,由 p 位数字(不包括符号、小数点)组成,小数点后面有 d 位数字。即(3,1)应为:3位数字.1位数字 |
| DECIMAL(p,d),DEC(p,d) | 同 NUMERIC |
| REAL | 取决于机器精度的单精度浮点数 |
| DOUBLE PRECISION | 取决于机器精度的双精度浮点数 |
| FLOAT(n) | 可选精度的浮点数,精度至少为 n 位数字 |
| BOOLEAN | 逻辑布尔量 |
| DATE | 日期,包含年、月、日,格式为 YYYY - MM - DD |
| TIME | 时间,包含一日的时、分、秒,格式为 HH : MM : SS |
| TIMESTAMP | 时间戳类型 |
| INTERVAL | 时间间隔类型 |
字段修改
--新增字段
--新增字段名之后跟新增字段的类型
alter table 表名 add(新增字段名 varchar2(4))--修改字段类型
--修改字段名之后跟修改为的参数类型和长度
alter table 表名 modify(修改字段名 NUMBER(8,2));
--修改字段名
alter table 表名 rename column 旧字段名 to 修改后的新字段名;--删除字段
alter table 表名 drop column 删除字段名
修改字段默认值
--修改字段默认值
--主要此修改不会影响到存量数据,之后影响之后的增量数据
alter table 表名 modify 字段 default 默认值;
关键字约束
类型和概念
| 类型 | 含义 | 备注 |
|---|---|---|
| unique | 唯一约束 | 创建唯一约束会自动创建唯一索引 |
| primary | 主键约束 | 创建主键约束会自动创建唯一索引 |
| foreign | 外键约束 |
主键约束(PRIMARY KEY)
1、主键用于唯一地标识表中的每一条记录,可以定义一列或多列为主键。
2、是不可能(或很难)更新.
3、主键列上没有任何两行具有相同值(即重复值),不允许空(NULL).
4、主健可作外健,唯一索引不可;
唯一性约束(PRIMARY KEY)
1、唯一性约束用来限制不受主键约束的列上的数据的唯一性,用于作为访问某行的可选手段,一个表上可以放置多个唯一性约束.
2、只要唯一就可以更新.
3、即表中任意两行在指定列上都不允许有相同的值, 允许空(NULL).
4、一个表上可以放置多个唯一性约束
相关语句
--新增单个唯一性约束
alter table 表名 add constraint 添加的唯一性约束名 unique(对应的字段列);
--新增组合唯一性约束
alter table 表名 add constraint 添加的唯一性约束名 unique(对应的字段列1,对应的字段列2);--新增单个主键约束
alter table 表名 add constraint 添加的关键字名称 primary key(对应的主键列);
--新增组合主键约束
alter table 表名 add constraint 添加的关键字名称 primary key(对应的主键列1,对应的主键列2);--新增外键约束
--与外键关联的主表的字段必须设置为主键
--要求从表不能是临时表,主从表的字段具备相同的数据类型、字符长度和约束。
alter table 表名 add constraint 外键约束名 foreign key(表名对应的字段) references 外键约束对应的表名(外键约束对应的字段名);--删除关键字约束
alter table 表名 drop constraint 删除的关键字名称;--禁用关键字约束
alter table 表名 disable constraint 关键字约束名;
--启用关键字约束
alter table 表名 enable constraint 关键字约束名;
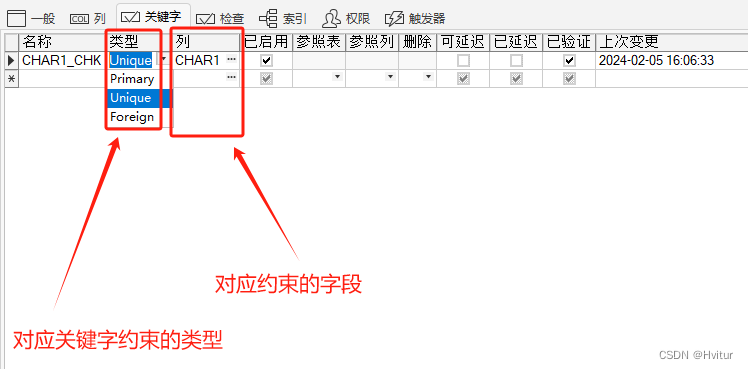
关键字约束的区别
唯一性约束和主键约束的区别:(PRIMARY KEY)
1、唯一性约束允许在该列上存在NULL值,而主键约束的限制更为严格,不但不允许有重复,而且也不允许有空值。
2、在创建唯一性约束和主键约束时可以创建聚集索引和非聚集索引,但在 默认情况下主键约束产生聚集索引,而唯一性约束产生非聚集索引
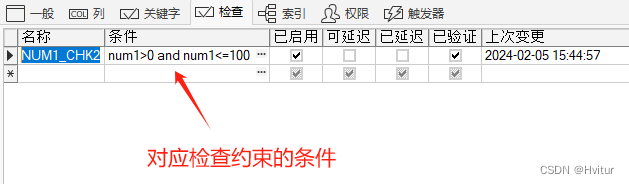
检查约束
--添加检查约束
--只能输入限定的值
alter table 表名 add constraint 检查约束名称 check(检查字段 in ('检查值1','检查值2'));
--只能输入限制范围的值
alter table 表名 add constraint 检查约束名称 check(检查字段>0 and 检查字段<=100);--删除检查
ALTER TABLE 表名 DROP constraint 检查约束名称
索引
查询现有的索引
SELECT c.table_name AS 表名,i.index_name AS 索引名,i.index_type AS 索引类型,c.column_name AS 索引列名称,c.column_position AS 列的位置FROM user_ind_columns cJOIN user_indexes iON c.index_name = i.index_nameWHERE c.table_name = '表名';
索引类型
| 索引类型 | 含义 |
|---|---|
| NORMAL | 普通 B 树索引 |
| UNIQUE | 唯一索引 |
| BITMAP | 位图索引 |
| FUNCTION-BASED NORMAL | 基于函数的普通 B 树索引 |
| FUNCTION-BASED BITMAP | 基于函数的位图索引 |
| DOMAIN | 域索引,用于实现对象类型的索引 |
| LOB | LOB 索引,用于索引长对象(Large Object,LOB)数据类型的表 |
| IOT - TOP | 索引组织表(Index-Organized Table,IOT)的顶层索引 |
| IOT - NESTED | IOT 的嵌套索引 |
| IOT - OVERFLOW | IOT 的溢出段索引 |
| DOMAIN - LOB | 用于索引基于对象类型的 LOB 数据类型的表的域索引 |
| XMLTYPE | XML 数据类型的索引 |
索引的分类
按数据结构分类:B+tree索引、Hash索引、Full-text索引。
按物理存储分类:聚集索引、非聚集索引(也叫二级索引、辅助索引)。
按字段特性分类:主键索引(PRIMARY KEY)、唯一索引(UNIQUE)、普通索引(INDEX)、全文索引(FULLTEXT)。
按字段个数分类:单列索引、联合索引(也叫复合索引、组合索引)。
各种索引的概念
🎈按数据结构分类
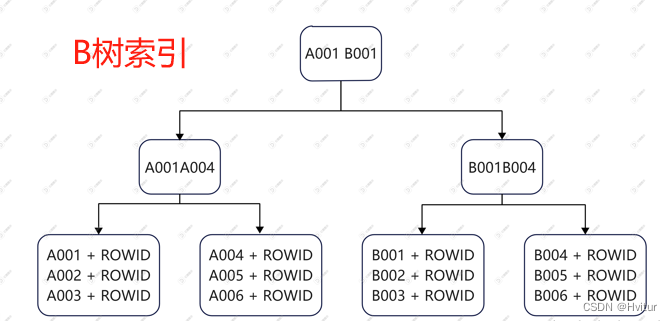
B树索引:普通 B 树索引。B树索引是Oracle默认的索引类型,它以B树结构组织并存储索引数据,不懂什么是B树的可以百度一下,你就知道。B树索引中的数据是以升序方式排序的,B树索引由根块、分支块和叶块组成,其中主要数据都集中在叶子节点上。Oracle采用这种方式的索引,可以确保无论索引条目在何处,只需要花费相同的I/O即可获取它,所以它被称为B(Balanced)树索引。如果在Where子句中要经常引用某列或某几列,应该基于这些列建立B树索引
位图索引:位图索引是一种高度压缩的索引类型,适用于在大型表中包含少量不同值的列上。位图索引适用于等值搜索,并且可以更快地处理多个位图索引之间的逻辑运算。位图索引不适用于频繁的插入、更新和删除操作。
对于不同值多少的划分,采用Oracel基数划分,比如一个表有10000行数据,其中的某一字段只有100种取值,基数则为1%,Oracle推荐,当一个字段基数小于1%时,适合建立位图索引
散列索引:散列索引使用散列函数将索引键转换为散列值,从而提高索引搜索性能。散列索引适用于等值搜索,但不适用于范围搜索或排序操作。散列索引在写入高并发表时性能通常很好,但是当表的大小增长时,它们可能会变得不稳定。
反向键索引:Oracle会自动为表的主键创建B树索引,通常主键会是一个递增的序列编号,如果使用默认的B树索引,当数据量巨大时会导致索引数据分布不均,叶子节点可能会偏向某一个方向,这时就需要另一个索引机制,反向键索引,它可以将添加的数据随机(全部数据都会进行反向)分散到索引中,它在顺序递增列上建立索引时非常有用。反向键索引的工作原理非常简单,在存储结构方面它与常规的B树索引相同。然而,如果用户使用序列在表中输入记录,则反向键索引首先指向每个列键值的字节,然后在反向后的新数据上进行索引。例如,如果用户输入的索引列为2011,则反向转换后为1102; 9527 反向转换后为7259。需要注意的是,刚才提及的两个序列编号是递增的,但是当进行反向键索引时却是非递增的。这意味着,如果将其添加到子叶节点中,则可能会在任意的子叶节点中进行。这样就使得新数据在值的范围上的分布通常比原来的有序数更均匀。
函数索引:函数索引是基于表达式的索引,可以用于在非直接存储在列中的值上进行搜索,例如,将字符串转换为大写字母。函数索引可以帮助您避免在查询中使用昂贵的函数操作,但是创建和维护函数索引可能会增加查询的成本。
--例如有函数索引
SUBSTR(字段名,1,1)--则只能触发
SELECT * FROM 表名 WHERE SUBSTR(字段名,1,1)=''--下面的这种方式也不能触发
SELECT * FROM 表名 WHERE SUBSTR(字段名,1,2)=''
🎃按物理存储分类
聚集索引(主键索引):将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据(所有字段的值)
非聚集索引(辅助索引):将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置
⚽按字段特性分类
主键索引:是基于表的主键列创建的索引。主键是唯一标识表中每一行的列,它可以确保表中的每一行都有一个唯一的标识。主键索引可以加速对表的快速查找和唯一性约束。
唯一索引:唯一性是很常见的一种索引约束需求,重复的数据记录会带来许多处理上的麻烦,比如订单的编号、用户的登录名等。通过建立唯一性索引,可以保证集合中文档的指定字段拥有唯一值。.唯一性索引对于文档中缺失的字段,会使用null值代替,因此不允许存在多个文档缺失索引字段的情况
普通索引(INDEX):建立在普通字段上的索引被称为普通索引。
全文索引(Full-text Index):全文索引是用于对文本数据进行全文搜索的索引。它可以加速对文本内容的关键字搜索,支持模糊匹配和语义搜索等功能。
🎄按索引字段的个数分类
单列索引:建立在单个列上的索引被称为单列索引。
联合索引(复合索引、组合索引):建立在多个列上的索引被称为联合索引,又叫复合索引、组合索引。