- 文献阅读:Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- 1. 文章简介
- 2. 方法介绍
- 1. State Space Models
- 2. Selective State Space Models
- 3. 实验考察 & 结论
- 1. 简单问题上的验证
- 2. 实际场景效果
- 1. 语言模型
- 2. DNA模型
- 3. 语音模型
- 3. 细节考察
- 1. 速度和内存考察
- 2. 消融实验
- 4. 结论 & 思考
- 文献链接:https://arxiv.org/pdf/2312.00752.pdf
- GitHub链接:https://github.com/state-spaces/mamba
1. 文章简介
这篇文章23年12月普林斯顿的一篇文章,文中提出了一个Mamba的模型结构,尝试挑战了一下Transformer的霸权地位。
众所周知,自从BERT和GPT分别在NLP任务以及生成任务上展现出绝对的统治力之后,transformer框架的模型同时开始进军CV和ASR领域,不断在各个领域当中出圈,大有一统天下的趋势。
不过,针对Transformer框架的挑战也是一直存在,从简单的对于Transformer框架中self attention结构的计算量优化到尝试复兴RNN的RetNet等等,整体的思路前者基本就是希望减少self attention的计算量从而使得可以容纳的context窗口长度,而后者干脆就回到RNN的框架来完全舍弃掉窗口的设置,通过设置并行训练的方式来修改掉RNN只能串行训练的问题。
这里,Mamba走的也是后者这个路线,完全舍弃掉了self-attention的框架,使用文中提到的state space model的框架来进行实现。
文中宣称:
- Mamba模型不但可以无视掉context长度限制进行任意长文本的生成,还可以并行高速地训练,甚至有着很好的可扩展性,可以容纳大量参数,和transformer一样,在大数据预训练的框架下依然没有看到效果的瓶颈。
更牛逼的是,这篇文章的作者几乎是一己之力推着这个模型框架往前走,最早是一个S4的模型框架,然后优化成了H3的结果,到现在的Mamba,都是同一个团队沿着同一条路子走下来的,也是牛逼的厉害。不过可惜的是S4和H3那两篇文章我还没看过,所以这里对于Mamba的结构理解多少还有一点难度,后面会找时间去把剩下那两篇文章也看一下,或许对这个文章会有更好的一个理解。
2. 方法介绍
下面,我们首先来看一下Mamba的具体模型结构。

整体来说,Mamba的模型结构是在这篇文章的前作中提出的State Space Model(SSM)的基础上进行优化得到的,加上了选择机制并使之适应GPU的并行加速机制。
因此,我们下面就会遵循稳重的思路首先来看一下State Space Model,然后来看一下文中优化得到的Selective State Space Model,也就是文中的Mamba模型框架。
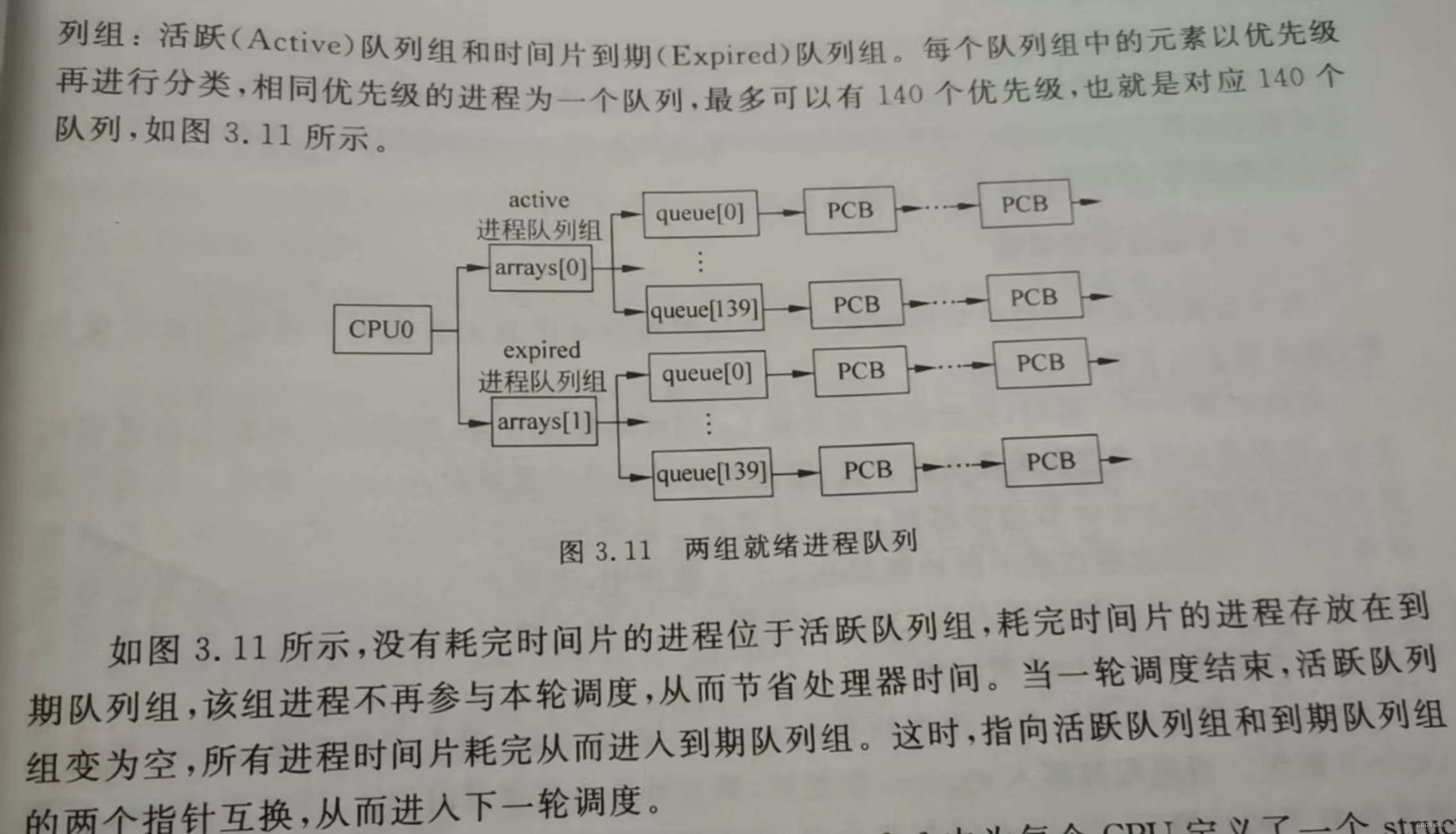
1. State Space Models
我们首先来考察一下State Space Model(SSM)。
本质上来说,包含输入 x t x_t xt输出 y t y_t yt以及态函数 h t h_t ht,且训练过程可以并行,然后infer过程可以做到迭代串行的模型结构都可以称之为SSM。
下面就是一个SSM的典型case,它参数主要包括4个部分 ( Δ , A , B , C ) (\Delta, A, B, C) (Δ,A,B,C),而整体的操作则是包括两个部分:
-
Discretization
A ˉ = e x p ( Δ A ) B ˉ = ( Δ A ) − 1 ( e x p ( Δ A ) − I ) ( Δ B ) \begin{aligned} \bar{A} &= exp(\Delta A) \\ \bar{B} &= (\Delta A)^{-1} (exp(\Delta A) - I) (\Delta B) \end{aligned} AˉBˉ=exp(ΔA)=(ΔA)−1(exp(ΔA)−I)(ΔB)
-
Computation
Computation部分则可以有以下两种等价地表述:
-
线性recurrence实现
h t = A ˉ h t − 1 + B ˉ x t y t = C h t \begin{aligned} h_t &= \bar{A}h_{t-1} + \bar{B} x_{t} \\ y_t &= C h_t \end{aligned} htyt=Aˉht−1+Bˉxt=Cht
-
卷积实现
K ˉ = ( C B ˉ , C A ˉ B ˉ , . . . C A ˉ k B ˉ , . . . ) y = x K ˉ \begin{aligned} \bar{K} &= (C\bar{B}, C\bar{A}\bar{B}, ... C\bar{A}^k \bar{B}, ...) \\ y &= x \bar{K} \end{aligned} Kˉy=(CBˉ,CAˉBˉ,...CAˉkBˉ,...)=xKˉ
通常,我们训练时使用卷积方式进行并行运算,而在infer过程中使用recurrent方式进行实现。
-
其他主要的SSM的结构主要包括以下一些:
- Linear attention (Katharopoulos et al. 2020)
- H3 (Dao, Fu, Saab, et al. 2023)
- Hyena (Poli et al. 2023)
- RetNet (Y. Sun et al. 2023)
- RWKV (B. Peng et al. 2023)
2. Selective State Space Models
下面,我们来看一下文中主要的优化结构,即SSSM模型。
如前所述,虽然SSM可以通过recurrent的方式在模型中加入时间信息,但是却并没有content的信息被加入其中,导致对于以summary为代表的一些需要copy的任务当中就很难获得很好的效果,因此文中在SSM的基础上加入了内容的selection,有些类似于attention或者LSTM当中的遗忘门和输出门,负责对前文进行重点选择。
具体的selective部分的示意图和SSSM的为代码逻辑如下:


最后,文中给出了一个典型的SSSM的实现,也就是文中最终使用的Mamba的模块如下:

3. 实验考察 & 结论
有了上述Mamba模型的介绍,下面,我们来看一下文中给出的针对Mamba模型的具体实验效果。
1. 简单问题上的验证
首先,如前所述,Selective机制的加入是为了增加输出内容对于历史信息的选择性记忆,因此,文中首先在两个Syntactic问题考察了一下Selective机制是否成功实现:
- Selective Copying
- Induction Heads
得到结果如下:

可以看到,在两个任务上,S6较之没有selective的S4都有着显著的效果增强。
2. 实际场景效果
然后,既然我们发现selective机制确实已经按照预定的设计发挥了作用,下面我们就来看一下Mamba的整体设计是否能够真正在各类场景下发挥出好的效果,文中主要考查了三个Transformer的典型应用场景:
- 语言模型
- DNA模型
- 语音模型
下面,我们来逐一看一下文中在这三个场景下的效果。
1. 语言模型
首先,文中在当前Transformer效果最显著的LM下面考察了Mamba的效果,得到结果如下表所示:

可以看到,在各个参数量级下,Mamba模型都表现出了不输于GPT的效果,并且模型总的size越小,这种趋势就越明显。
此外,传统的RNN的一大缺点就是缺乏可扩展性,当参数规模增大时模型效果无法有效地同比例增强,因此文中也进一步考察了Mamba模型的可扩展性,考察不同size下模型的效果,得到结果如下:

可以看到,随着模型size地增加,Mamba模型的效果是持续变好的。
2. DNA模型
同样的,文中先考察了一下Mamba模型和其他模型的效果对比,得到结果如下:

可以看到,同样有Mamba模型在长序列DNA模型上的表现优于HyenaDNA模型,且参数量更大的7M模型效果优于1.4M的Mamba模型。
文中同样考察了DNA模型上面Mamba模型的可扩展性,得到结果如下:

可以看到,在DNA模型上同样Mamba莫i选哪个满足可扩展性,参数量越大,模型效果越好,并没有看到显著的瓶颈现象。
3. 语音模型
文中考察的第三个使用场景是语音的场景,得到实验结果如下所示:

可以看到,Mamba模型是全面超越其他当前的语音模型的,且在Mamba系列模型内部做消融饰演的结果也同样由Mamba模型的效果是最好的。
另外,文中也在语音场景考察了Mamba模型的可扩展性,得到结果如下:

可以看到,随着序列长度的增加,Mamba的模型效果可以得到持续地提升。
3. 细节考察
除了上述在实际场景中的效果考察和对比之外,文中还针对Mamba本身的细节特质进行了考察,主要包括两部分的内容:
- Mamba模型设计初衷的在速度和内存上是否优于Transformer
- Mamba模型在迭代中的细节设计的消融实验
下面,我们来逐一看一下文中针对这两方面的考察。
1. 速度和内存考察
首先,如开头所说明的,Mamba的设计初衷是为了替代transformer架构,在不损失性能的情况下更加节省时间和内存,因此要证明这个目的,文中首先在相同尺寸的模型下对Transformer以及Mamba模型所需的内存和infer数据进行了一下对比,得到结果如下:

可以看到,确实在执行速度和内存使用上,Mamba都显然是更加优秀的一方。
2. 消融实验
然后,文中对Mamba模型本身的各个结构设计进行了消融实验,证明各个组成部分都是对模型效果有正向作用的,具体包括:
- 模型结构
- SSM Layer设计
- Selective机制的引入部位
- 参数初始化
- Δ \Delta Δ的投影维度
- SSM的维度

可以看到:
- S6的SSM结构设计是优于其他的SSM结构设计的
- 模型结构方面的话Mamba模型好于H3架构
- Selective机制的话最好在 Δ , A , B \Delta, A, B Δ,A,B上都加上
- 参数初始化的话最好还是正态分布初始化
- Δ \Delta Δ以及SSM的维度越大,模型效果越好。
4. 结论 & 思考
综上,在这篇文献当中,作者提出了一个名为Mamba的模型结构,它是在作者的前作S4以及H3模型的基础上持续优化得到的,效果上宣称可以匹敌Transformer,并且同样具有很好的可扩展性,且避开了Transformer的有限窗口长度的问题。
更牛逼的是,作者确实在LM,DNA以及语音领域展示了Mamba模型的有效性和可扩展性,真的是非常厉害。
不过可惜的是这个模型结构本身我并没有怎么完全看懂,后续可能还是得去看看作者的开源代码来好好理解一下Mamba的结构设计。
至于Mamba是否真的可以干掉Transformer,这个暂时还是让子弹再飞一会吧……