自然语言处理(Natural Language Processing,简称NLP)是人工智能和语言学领域的一个分支,它涉及到计算机和人类(自然)语言之间的相互作用。它的主要目标是让计算机能够理解、解释和生成人类语言的数据。NLP结合了计算机科学、人工智能和语言学的技术和理论,旨在填补人与机器之间的交流隔阂。
1 自然语言处理的基本介绍
1.1 相关概念
在定义NLP之前,先了解几个相关概念:
语言(Language):是人类用于沟通的一种结构化系统,可以包括声音、书写符号或手势。
自然语言(Natural Language):是指自然进化中通过使用和重复,无需有意计划或预谋而形成的语言。
计算语言学(Computational Linguistics):是语言学和计算机科学之间的跨学科领域,它包括:
a.计算机辅助语言学(Computer-aided Linguistics):利用计算机研究语言的学科,主要为语言学家所实践。
b.自然语言处理(NLP):使计算机能够解决以自然语言表达的数据问题的技术,主要由工程师和计算机科学家实践。
NLP的研究范围广泛,包括但不限于语言理解(让计算机理解输入的语言)、语言生成(让计算机生成人类可以理解的语言)、机器翻译(将一种语言翻译成另一种语言)、情感分析(分析文本中的情绪倾向)、语音识别和语音合成等。
在中文环境下,自然语言处理的定义和应用也与英文环境相似,但需要考虑中文的特殊性,如中文分词、中文语法和语义分析等,因为中文与英文在语言结构上有很大的不同,这对NLP技术的实现提出了特殊的挑战。自然语言处理使计算机不仅能够理解和解析人类的语言,还能在一定程度上模仿人类的语言使用方式,进行有效的沟通和信息交换。
1.2 为什么使用NLP
1.2.1 人与人、机器与机器之间的交流
当通信使用自然语言与人类进行时,或者是计算机之间使用形式化语言(如数据结构、标记、逻辑)进行时,NLP是不必要的。
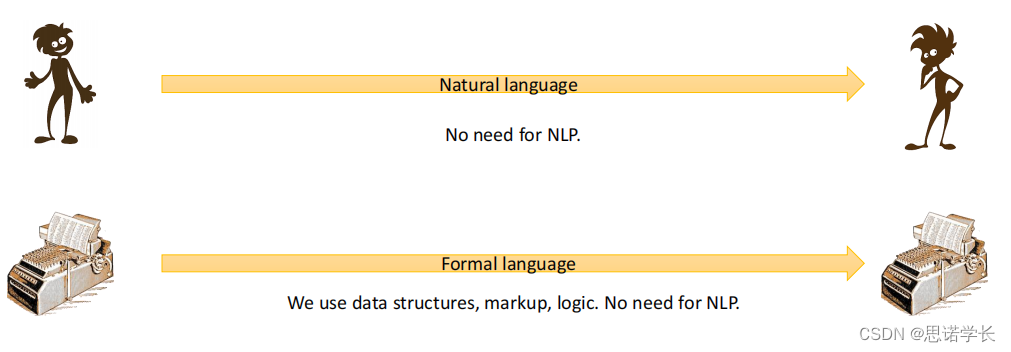
1.2.2 机器与人交流
1.2.2.1 自然语言理解(Natural Language Understanding)
目标:自动处理以自然语言表达的数据。
示例:语音和手写识别、信息提取、信息检索、情感分析等。
1.2.2.2 自然语言生成(Natural Language Generation)
目标:将形式化的数据转换为自然语言,以供人类理解。
示例:报告生成、语音合成等。
下图展示了从理解(Understanding)到生成(Generation)的流程,并指出了这些流程的一些目标和应用,如:

a.理解(Understanding):
目标:人到计算机或促进人与人之间的通信。
示例:聊天机器人、端到端对话系统(如呼叫中心)、机器翻译、自动摘要、自动字幕等。
b.生成(Generation):这里的生成与上面提到的自然语言生成相似,指的是由计算机创建的自然语言输出。
1.2.3 NLP的具体用途
在数据科学中,自然语言处理(NLP)是一个非常重要的工具,它可以用于从各种形式的自然语言数据中提取信息、理解含义、发现模式和生成语言。以下是一些数据科学中NLP的具体用途:
1.2.3.1 文本挖掘和信息提取
从原始文本、HTML页面、PDF文档中提取有用信息,如实体识别(识别人名、地点、组织名等)、关键词提取、主题建模等。
1.2.3.2 情感分析
分析社交媒体消息(评论、推文等)以确定作者的情感倾向,例如,判断一条评论是积极的、消极的还是中性的。
1.2.3.3 机器翻译
将一种语言的文档自动翻译成另一种语言,例如从英文翻译到中文。
1.2.3.4 自然语言生成
自动生成文本报告,将表格或树状结构数据的单元格/叶子中的文本转换成易于理解的叙述性文本。
1.2.3.5 文本分类和标签化
将文档分类到预先定义的类别中,或为文档自动分配标签,例如新闻文章的主题分类或给予电子邮件优先级标签。
1.2.3.6 问答系统和聊天机器人
开发能够理解自然语言查询并给出精确答案的系统,或与用户进行自然对话的聊天机器人。
1.2.3.7 搜索引擎优化
提高文档在搜索引擎结果中的排名,通过理解文档的内容和结构,优化关键词和元数据。
1.2.3.8 语音识别和语音合成
转换语音为文本进行进一步的处理,或将文本数据转换为语音输出。
1.2.3.9 摘要和概括
自动创建文档的摘要或概括,提取关键句子或概念以提供快速概览。
1.2.3.10 知识图谱和本体构建
从部分形式化的知识(如分类体系、关键词等)构建知识图谱,建立实体之间的关系和属性。
在处理这些自然语言数据时,NLP技术可以处理和分析非结构化的数据,这是传统数据分析技术难以处理的。通过NLP,数据科学家可以从文本中发现洞见,以指导决策制定、产品开发和市场策略。
1.3 自然语言处理(NLP)领域近年来的趋势
在自然语言处理(NLP)领域的研究中,近年来出现了几个明显的趋势。

1.3.1 自2017年起兴趣急剧上升
这一趋势的起点可以追溯到2017年,当时Google提出了Transformer模型。这种模型采用了自注意力机制,极大地改善了处理序列数据的效率和效果,为后续NLP模型的发展奠定了基础。自此之后,对NLP的研究兴趣急剧上升。
1.3.2 机器翻译一直是主要动力
机器翻译是NLP领域的一个核心任务,长期以来一直是推动该领域研究和技术发展的主要驱动力。从早期的基于规则的方法,到统计机器翻译,再到现在的基于神经网络的翻译模型,机器翻译的研究不断进步,推动了许多相关技术的发展。
1.3.3 文本生成任务非常受欢迎
随着生成式预训练变换器(GPT)的出现,文本生成相关的任务(如问答、摘要生成等)变得非常流行。这些任务的目标是自动生成文本,以回答问题、提供信息摘要或生成连贯的文本。GPT及其后续版本在这些领域显示出了令人印象深刻的性能,引发了广泛的关注和研究。
1.3.4 这些趋势不一定适用于工业界
虽然学术研究对这些任务表现出了极大的兴趣,但这些趋势并不一定完全适用于工业界。在实际应用中,企业和开发者可能更关注技术的可用性、成本效益以及如何解决特定的业务问题。因此,尽管基础研究在某些方向上取得了突破,但这些技术的工业应用可能会有不同的重点和发展速度。
来说,自然语言处理是一个快速发展的领域,近年来的研究趋势反映了技术进步和新模型的出现,尤其是在文本生成和机器翻译等任务上。然而,学术研究的热点并不总是直接转化为工业界的应用重点,两者之间存在差异。
1.4 在数据科学中常见的NLP任务
自然语言处理(NLP)在数据科学中的应用广泛,涉及多种任务,这些任务帮助数据科学家从文本数据中提取、理解和生成信息。以下是一些在数据科学中常见的NLP任务及其中文解释:
1.4.1 信息提取(自然语言理解)
这一任务旨在从自然语言文本中提取计算机可理解、无歧义的信息。例如,从新闻文章中提取事件的参与者、时间和地点,或从医疗记录中提取病人的病史和治疗信息。信息提取使得原本模糊的自然语言信息转化为结构化数据,便于进一步分析和处理。
1.4.1.1 信息提取的目标
将以自然语言形式表示的信息转换成形式化、无歧义、计算机可处理的格式。这一过程使得计算机能够以结构化的数据形式理解和处理信息。
1.4.1.2 推理方法
逻辑推理:通过逻辑推理,根据已知事实使用逻辑操作得出结论。
知识图谱:使用图算法在结构化数据上进行推理,数据以节点(实体)和边(关系)的形式表示。
1.4.1.3 半形式化表示
表格结构:以表格形式组织信息,便于计算机处理和分析。
树结构:如XML文档,将信息以层级方式组织,形成父子关系。
标注文本:在文本中标记出特定信息,如实体、属性等。
1.4.1.4 信息提取中的经典NLP任务
概念提取和消歧:从文本中提取词义并确定其确切含义。
命名实体识别和消歧:识别文本中的特定实体(如人名、地点、组织等)并准确判定其指代。
关系提取:识别和提取文本中实体之间的关系。

在图片的具体例子中,可以看到“John Doe lives in Plouzané, under number 12 in rue de la Résistance”这句话通过信息提取变成了结构化的数据,其中“John Doe”是人名,"Plouzané"是地名,“12”是房屋号码,“rue de la Résistance”是街道名。在这个结构化表示中,我们可以明确知道这个人的地址信息,包括居住的城市、街道和门牌号,而这些信息是非常清晰且易于计算机处理的。
在另一个例子中,“Meat and fish products”这个短语通过信息提取被理解为“肉类和鱼类产品”,并与产品这一概念相关联。这种提取使得原本模糊的自然语言描述转化为具体和明确的类别标签。
总体来说,信息提取是NLP中一个非常关键的任务,它能够帮助我们将大量的非结构化文本数据转化为有用的结构化信息。
1.4.2 信息检索(自然语言理解)
在大量文本数据中搜索特定信息的过程。这包括从互联网、数据库或任何大型文档集合中查找含有特定关键字或满足特定条件的文档。信息检索技术使用户能够快速找到他们需要的信息,是搜索引擎和在线查询系统的基础。
信息检索的目标是在大量数据中高效地找到所需的信息,就像在干草堆里找到一根针。这个过程面临着一系列挑战,主要是由于自然语言的模糊性所引起的,包括查询的模糊性和文档的模糊性。由于模糊性可以在上下文中得到一定程度的缓解,但搜索查询通常非常短,这就增加了理解查询意图的难度。此外,相同的概念可以通过同义词、改述、更宽泛或更狭窄的术语等多种方式表达,这进一步增加了信息检索的复杂性。
信息检索的典型子任务包括:
a.索引(Indexing):这是对文档库进行转换的过程,旨在减少搜索空间并使在短时间内的搜索成为可能。通过对文档内容进行分析和归类,建立一个有效的检索结构,以便快速准确地定位信息。
b.重写(Rewriting):在这一步骤中,系统尝试预测用户的意图,并对查询进行消歧、扩展,加入同义词和相似的术语等。这有助于提高检索的准确性和相关性,尤其是在面对模糊或多义词的情况下。
c.搜索(Search):这一步骤涉及到查询的转换、查询与索引库的匹配以及相关文档的检索。系统将用户的查询与索引库中的信息进行匹配,找出最相关的文档。
d.文档排名(Ranking of Documents):一旦检索到相关文档,接下来就是根据其相关性对这些文档进行排名。这通常涉及到复杂的算法,目的是将最有用的信息排在最前面。
e.结果展示(Presentation of the Results):最后一步是以用户友好的方式展示搜索结果。这可能包括高亮显示关键词、提供摘要以及实现一个直观易用的界面,使用户能够轻松地找到和浏览他们感兴趣的信息。
总的来说,信息检索是一个涉及多个步骤的复杂过程,旨在尽可能减少自然语言的模糊性,提高搜索的准确性和效率。
1.4.3 分类(自然语言理解)
将文本数据组织到不同的类别中。这可以是根据文档的主题、情感倾向(如正面或负面)、作者的意图等将文本分组。例如,新闻文章可以按主题(政治、经济、体育等)分类,产品评论可以根据情感倾向分类。文本分类帮助自动化处理和组织大量的文本数据,便于进一步的分析和决策。
在机器学习和文本处理领域,分类是一种常见的任务,旨在将实例分配到预定义的类别中。根据类别的数量和性质,分类任务可以分为几种类型:
a.二元分类(Binary Classification):这是最简单的分类形式,涉及到两个类别,例如判断电子邮件是否为垃圾邮件(spam, not-spam)。在这种情况下,模型的任务是将输入归类为两个明确的类别之一。
b.三元分类(Ternary Classification):这种分类涉及到三个类别,常见于社交媒体上的情感分析,例如将帖子分类为积极(positive)、消极(negative)和中性(neutral)。更复杂的模型还可能分类主观性,并提供连续的输出以表示情感的强度或倾向性。
c.多类分类(Multi-class Classification):在多类分类中,有多个类别,每个实例只能归类于一个类别。例如,将会议论文根据其研究领域分配给不同的审稿人。这要求模型能够识别并区分多个不同的类别。
d.层次分类(Hierarchical Classification):这种类型的分类涉及到按照一定的层次结构进行分类,不仅仅是简单的类别分配。例如,在医学领域,国际疾病分类(ICD)就是一个层次化的分类系统;在工业领域,有北美工业分类系统(NAICS);在食品领域,则有联合国粮农组织的食品分类(GSFA)。这些分类系统通常以自然语言文本形式表达,并可能需要解析以便于机器理解和使用。
总的来说,分类任务根据类别的不同和任务的复杂性,可以被分成多种形式。它们在机器学习和自然语言处理中有着广泛的应用,帮助我们对大量数据进行有效的组织、分析和理解。
1.4.4 数据到文本(自然语言生成)
从结构化(正式或半正式)数据生成人类可读的内容。这一任务涉及将数据库中的数据、统计报告或任何形式的结构化信息转化为自然语言描述。例如,自动生成天气预报、财务报告摘要或体育赛事结果的文本描述。数据到文本技术使得复杂数据更易于理解和交流。
1.4.5 文本摘要
为文档生成一个简短的文本摘要。这个任务旨在提取文档中的关键信息,生成一个精简的版本,保留主要的信息点和主题。文本摘要可以是抽取式的,直接从原文中抽取关键句子;也可以是生成式的,重新组织和表述原文的主要内容。文本摘要对于快速理解长文本内容(如报告、研究文章)非常有用。

通过这些任务,NLP技术支持数据科学家在处理和分析文本数据方面的各种需求,从而提高效率,促进信息的发现和利用。
1.5 自然语言生成
自然语言生成(Natural Language Generation, NLG)是自然语言理解的对立面,它涵盖了一系列将数据转化为自然语言文本的任务。NLG的目的是使计算机能够自动生成人类可以理解的文本,这些任务包括但不限于以下几种:
数据到文本(Data-to-Text):从图形化、表格化或数值数据生成文本报告。例如,根据财务报表数据自动生成公司财务状况的总结。
图像描述生成(Image Caption Generation):从图像生成描述文字,即根据图像内容自动生成相应的文字描述。
问答(Question Answering):根据用户的提问自动生成答案,这涉及到理解问题的内容并从知识库中提取或生成答案。
*机器翻译(Machine Translation):“解码”源语言输入生成的上下文向量,将其翻译成目标语言的文本。这是一种语言到另一种语言的转换。
摘要生成(Summarisation):为文档生成简短的摘要,比如一段摘要,以提供文档的主要内容和要点。
简化、改写(Simplification, Paraphrasing):改变文本的措辞和/或风格,包括简化文本使其更易理解或用不同的词语重述相同的意思。
叙事生成(Narrative Generation):生成故事、诗歌等文学作品,这要求计算机能够创造性地构思并表达故事情节或诗意表达。
聊天机器人(Chatbots)等:设计用于与人类用户进行交流的系统,能够理解用户的输入并以自然语言形式回应。
自然语言生成在许多领域都有应用,从自动化报告生成、辅助撰写和编辑,到增强交互式应用如聊天机器人和虚拟助手等。NLG技术的发展使得机器能够更自然、更有效地与人类沟通,提高了信息传递的效率和可接受度。

1.6 自然语言处理(NLP)的困难性
自然语言处理(NLP)之所以难,原因在于自然语言的复杂性和多样性。这里有一些导致NLP难度的关键因素:
1.6.1 形式与意义的复杂关系
一种形式,多种意义:这体现为歧义性或多义性。一个词或表达可以在不同的上下文中有不同的意义。
多种形式,一种意义:这涉及到异质性或同义性。不同的词或短语可以用来表达相同的概念或意义。
1.6.2 自然语言的非规则性/非组合性
自然语言中的词汇和表达不总是按照组合的原则工作,比如“hot dog”并不等于“hot”和“dog”的字面意义相加。
1.6.3 意义的分散性
意义不仅体现在单个词素中,还体现在词汇结构、词序、以及语篇上下文中:
在单个词素中:比如“kill”可以指杀死一个人、消磨时间等。
在词的结构中:如“killed”中的“ed”表达了过去时。
在词序中:如“The lion killed the man”与“The man killed the lion”意义完全相反。
在语篇上下文中:比如““our train is leaving in 10 minutes”,其暗示的意义取决于说话者和听话者的位置。
1.6.4 语言的多样性
世界上有超过7000种语言(不包括“方言”),每种语言都有其独特的特点和挑战。
1.6.5 专业领域的特定语言
每个知识领域都有其专门的术语和语法,这增加了理解和处理这些领域文本的难度。
1.6.6 风格、语体等的多样性
不同的语体(如正式文本、口语、网络语言等)具有不同的表达方式和规则,增加了NLP的复杂性。
综上所述,自然语言的这些特性使得理解、处理和生成人类语言对计算机而言是一个极其复杂的任务。这也是为什么NLP是人工智能领域中一个持续不断的研究挑战的原因。
2. NLP的历史
自然语言处理(NLP)的历史可以追溯到20世纪50年代,其最初的动机之一是机器翻译,特别是在冷战和全球化的背景下,人们希望能够自动翻译俄语和其他语言的文档。这一时期也见证了人工智能(AI)学科的诞生。
2.1 1956年
被广泛认为是现代AI学科诞生的一年,同时也是NLP领域开始发展的时期。在这一年,感知机(Perceptron)被发明,这是一种早期的机器学习算法,标志着对于AI和NLP研究的兴趣开始上升。
2.2 美国政府的资助
早期的NLP研究得到了美国政府的慷慨资助,主要是因为机器翻译在政治和军事上的潜在价值。初期的研究成果通常限于几百句话,且仅限于特定领域。
2.3 两种对立的哲学
在NLP和AI的发展过程中,存在两种主要的哲学思想——理性主义(Rationalism)和经验主义(Empiricism)。理性主义强调通过逻辑和规则来理解语言,而经验主义侧重于从数据中学习语言的模式。
2.4 AI冬天(1960-1980年)
ALPAC报告(1964年):美国语言学自动化咨询委员会(ALPAC)发布的报告对机器翻译的未来持悲观态度,认为它未能实现预期目标。这导致国家资助的削减。
计算能力的限制:当时的计算能力无法跟上理论想法的发展,这是导致AI研究进展缓慢的另一个主要原因。
石油危机:经济方面的问题,如70年代的石油危机,也影响了对研究的投资和发展。
3. NLP两种主要的哲学思想及其拓展
3.1 理性主义与结构主义
理性主义和结构主义在自然语言处理(NLP)的发展中占据了重要位置,特别是在早期的符号主义方法中。这些理论强调了语言的规则性和结构性,为后来的计算语言学提供了理论基础。
3.1.1 理性主义与结构主义:符号主义方法
费迪南·德·索绪尔(Ferdinand de Saussure):索绪尔提出了“言语”(parole)与“语言”(langue)之间的区别。其中,“言语”指的是个别的、不规则的语言行为,而“语言”则是共享的、有结构的语言系统。这一区分强调了研究语言结构(langue)的重要性,而不仅仅是个别言语行为。
3.1.2 结构主义
结构主义认为,语言基于一个复杂的内部结构,这个结构由基本成分和构成规则(组合性原则)组成。复杂表达式的意义依赖于其组成部分的意义以及这些部分的结构,例如“绿苹果”(green apple)的意义是“绿色”和“苹果”的组合。
3.1.3 结构主义的金字塔结构
结构主义语言学的模型,通常被比喻成一个金字塔结构,每一层代表了语言学的不同层面和组成部分:

音系学/书写学(Phonemics/Graphemics):这是金字塔的基础,代表语言的最小声音单元——音素,以及书写系统中的最小单位——字母或字形(graphemes)。在书面语言中,还包括标点符号。
形态学(Morphology):形态学研究词的形成以及构词规则,包括词素(意义的最小单位)及其构成:屈折变化、派生和复合。
句法(Syntax):句法层面涉及句子和短语的语法结构,研究如何将词和词素组合成有意义的句子。
语义学(Semantics):语义学关注短语和句子的意义构建,即词和短语的含义以及它们如何组合在一起传达复杂的概念。
语用学(Pragmatics):这是金字塔的顶层,涉及到语境在理解和构建语言意义中的作用。语用学不仅分析单句意义,还研究整个话语(discourse)的意义,即如何根据语境理解和使用语言。
这个模型强调了从语言的物理形式到意义构建的层次结构,每一层都在构建和理解语言中发挥着重要作用。在自然语言处理中,这个模型提醒我们在处理语言时需要考虑这些不同的层面。
3.1.4 自然语言处理(NLP)流水线
一个典型的自然语言处理(NLP)流水线,它展示了文本数据如何经过多个处理阶段,以达到深入理解语句的目的。下面是流水线的每个步骤的解释:

3.1.4.1 句子分割(Sentence Splitting)
这个步骤将文本分割成单独的句子。例如,“Prof. Dupont crossed the square. Suddenly he fell.”会被分割成“Prof. Dupont crossed the square.”和“Suddenly he fell.”两个句子。
3.1.4.2 分词(Tokenisation)
在这一步,句子被分解成单词或标点符号等基本单位(tokens)。比如,“Prof.”、“Dupont”、“crossed”等。
3.1.4.3 词性标注(Part-of-speech Tagging)
这一步为每个单词分配词性。例如,“Prof”被标注为名词(NC),“crossed”被标注为动词(V_PP)等。
3.1.4.4 词元还原(Lemmatisation)
这个步骤旨在找到每个单词的词元形式,即词典中单词的基本形式。比如,“crossed”将还原为“cross”。
3.1.4.5 句法分析(Syntactic Analysis)
句法分析构建句子的语法结构,识别名词短语(NP)、动词短语(VP)等,并分析它们如何组成一个完整的句子(S)。
3.1.4.6 词义消歧(Word Sense Disambiguation)
在这一步骤中,系统需要确定多义词的正确含义。例如,“cross”可以表示“穿过”、“阻碍”或“杂交”,在这个句子中,“cross”指的是“穿过”。
3.1.4.7 语篇消歧(Discourse Disambiguation)
这个阶段涉及到理解整个文本或语篇的意义,并解决指代等问题。比如,确定“he”指的是“Prof. Dupont”。
最终,NLP系统可能会生成一个逻辑表达式,如“professor1(Dupont) ∧ square3(x) ∧ cross1(Dupont, x) ∧ fall2(Dupont)”,这个表达式尝试准确地捕捉句子中提到的概念和它们之间的关系。这种表示可以用于更深层次的理解,比如问答系统、信息提取或其他高级NLP应用。
3.1.4 结构主义方法在自然语言处理(NLP)中的优势
结构主义方法在自然语言处理(NLP)中的优势主要体现在以下几个方面:
3.1.4.1 可组合性(Compositionality)
结构主义方法依赖于可组合性原则,即一个复杂的语言表达可以分解为更小的部分,这些部分的意义组合起来构成整体的意义。这允许将复杂任务分解为可管理的子任务,并从非正式的自然语言逐步过渡到形式化的表示。这种分解使得处理复杂语言数据变得更为可行。
3.1.4.2 利用现有语言学知识
结构主义方法可以利用现有的语言学成果来指导NLP系统的设计。语言学家对语言的深入研究为工程师提供了先验知识,这些知识可以在NLP中重复使用,以帮助构建更有效的处理模型。
3.1.4.3 可解释性(Explainability*:)
由于每个子任务都基于人类对语言的理解,结构主义方法通常具有较高的可解释性。这意味着系统的决策和处理过程对于人类来说是可理解和可解释的,这在需要解释模型决策的应用场景中是非常重要的。
3.1.4.4 双向处理
结构主义方法的一个重要优势是其处理过程可以反向进行,这在机器翻译等应用中尤为重要。例如,一个从英语到法语的翻译模型理论上可以反转,用于从法语到英语的翻译。这种双向性使得结构主义方法可以用于自然语言理解和自然语言生成两个方向的任务。
结构主义方法通过将语言分解为独立的层次和组件来工作,使得NLP系统能够更精确地理解和生成语言。然而,它也面临着无法处理非结构化数据和语言的不规则性等挑战,这导致了统计方法和机器学习技术在NLP领域的兴起,它们能够更灵活地处理语言的复杂性和多样性。
3.1.5 诺姆·乔姆斯基(Noam Chomsky)
乔姆斯基提出了通用语法的假设,以及人脑中存在一个专门负责语言能力的机制。这一理论部分通过神经科学和对人类及动物的实验得到了证实。
乔姆斯基还研究了形式语言和生成语法,提出语言分析可以自动化,前提是我们对语法有深入的了解。这一观点为后来的计算语言学和NLP研究提供了方法论基础。
3.1.6 结构主义的局限性
尽管结构主义为理解语言的规则性和系统性提供了有力的框架,但它也面临着挑战,特别是在处理语言的异常和不规则性方面。现实中,语言充满了例外和变异,这使得纯粹依靠规则和结构来解释语言现象变得复杂。
结构主义方法在NLP中确实有一些局限性,这些局限性在面对自然语言的复杂性和多样性时尤为明显:
3.1.6.1 子任务本身的难度
即使是细分出的子任务,也常常是非常复杂的。例如,在句子分割中,简单的规则(如“点号+空格+大写字母=新句子”)可能不足以准确处理所有情况,如下文中“prof.”的例子。需要额外的规则来处理特例,这些规则很难设计得既通用又精确。
I talked to prof. Dupont. He was helpful.
I talked to prof. | Dupont. | He was helpful.
I talked to prof. Dupont. | He was helpful.
I talked to the prof. He was helpful.
简化的例子,说明了在自然语言处理中句子分割的一些规则,以及这些规则可能遇到的问题。
a.DOT+SPACE+UPPERCASE => new sentence.
这条规则指出,当一个点号后面紧跟一个空格和一个大写字母时,可以认为是一个新句子的开始。例如,在“Prof. Dupont teaches. He is well-respected.”中,“He”后面应该开始一个新句子。
b.Except if preceded by “prof”.
第二条规则是第一条规则的例外情况,如果点号前面是“prof”这个词,那么不应该将其作为新句子的开始。这是因为“Prof.”常用作教授的缩写,并不一定表示句子的结束。例如,“I talked to Prof. Dupont.”中的点号实际上并不表示句子结束。
c.???!!!
最后的符号和表情符号表达了对规则的困惑和挫败感。这是因为自然语言中存在许多这样的特例和不规则情况,使得制定普遍适用的硬性规则变得非常困难。例如,“Dr. Smith”和“St. Louis”中的点号并不表示句子结束,而是名词的一部分。因此,需要更复杂的规则或机器学习模型来准确地识别句子边界。
这些表情符号可能还隐含了一种认识,即尽管有明确的规则,自然语言的复杂性意味着在实际应用中很难有一套完美无缺的规则。这就需要更高级的NLP技术,如基于机器学习的模型,这些模型可以通过在大量文本上的训练来识别句子的边界,而不仅仅依赖于简单的符号规则。
3.1.6.2 上游错误对下游任务的影响
结构主义方法通常采用线性流水线处理,这意味着一旦在流程的早期阶段发生错误,它会影响所有后续任务。例如,如果一个词被错误地解析,它可能会破坏对整个句子的分析。
3.1.6.3 自然语言中的例外和不规则性
自然语言中充满了例外情况和不规则现象,这使得为每个特例制定规则变得极其困难。结构主义方法往往难以灵活地适应这些不规则性。
3.1.6.4 不需要详尽分析的情况
在某些应用中,并不需要对语言进行详尽的结构分析,例如判断一封电子邮件是否为垃圾邮件,或者确定文本的语言。这时,过于复杂的结构分析可能是不必要的,并且会消耗额外的资源。
3.1.6.5 泛化能力有限
结构主义方法通常针对特定语言、特定领域或语体(如正式文体、口语等)设计。它们在跨语言、领域或语体时的泛化能力有限。这意味着为一个语言或领域开发的解决方案可能无法直接应用到另一个上,而需要进行大量的调整。
由于这些局限性,现代NLP更多地采用了统计和机器学习方法,特别是深度学习技术,以提供更灵活、更强大的语言处理能力,并提高泛化能力。这些方法通常不需要严格的规则设定,而是从大量的数据中学习语言的模式和变化。
总的来说,理性主义和结构主义为理解和处理自然语言提供了重要的理论基础,但随着时间的发展,研究者们逐渐认识到需要更灵活和包容的方法来应对语言的复杂性和多样性。这导致了后来统计方法和机器学习技术在NLP领域的兴起,这些方法更加注重从大量数据中学习语言规律,而不是完全依赖于预先定义的规则和结构。
3.2 经验主义和整体主义
经验主义和整体主义在自然语言处理(NLP)的历史中标志着从符号主义方法向统计方法和机器学习的转变。这种转变强调从大规模语料库中学习语言的规律,而不是依赖先验的语言知识。以下是这一转变的几个关键方面:
3.2.1 经验主义和整体主义:统计方法和机器学习
统计语言学的视角:语言的规律性是从实践中出现的,即通过分析大量的语料库(corpora)来发现。这种方法忽略了任何先验的语言知识,计算机从零开始学习(tabula rasa)。
行为主义与内在主义:这一转变与心理学中的行为主义相对应,行为主义强调从经验中学习,而内在主义(innatism)则认为某些知识是先天的。在NLP中,这体现为更多地依赖数据驱动的学习,而不是预设的规则。
3.2.1.1 上下文的重要性
与结构不同,上下文在构建意义中扮演了主要角色。意义不仅取决于词汇本身,还取决于它们在语料中出现的上下文。这种方法强调了理解语言使用背景的重要性。
3.2.1.2 对大规模语料库的需求
统计方法和机器学习的性能在很大程度上取决于语料库的大小。大规模的语料库和高计算能力是提高性能的关键。
3.2.1.3 人工神经网络的研究
人工神经网络自20世纪50年代以来就一直在研究中,其中感知机在1958年被提出。深度神经网络自60年代以来就已存在,但直到21世纪的2000至2010年代,所需的处理能力才真正可用。
这一时期标志着NLP从依赖语言学家定义的规则和结构,转向利用机器学习算法从大量数据中自动学习语言规律的方法。这种转变极大地扩展了NLP的能力,使其能够处理更复杂的语言现象,并在许多应用中取得了显著的进步,如机器翻译、语音识别和文本分析等。随着计算能力的持续提升和算法的不断优化,基于统计的方法和机器学习在NLP领域的重要性持续增长。
整体上,NLP在早期面临许多挑战,包括理论和技术上的限制以及经济和政治因素的影响。尽管如此,这一时期奠定了后续NLP研究和发展的基础,随着时间的推移,随着计算能力的增强和算法的改进,NLP领域逐渐克服了早期的一些障碍,发展成为今天我们所见的形式。
3.2.2 语料库的统计方法
基于语料库的统计方法依赖于从大量文本数据中归纳出语言知识。这些方法可以是统计型的,也可以是基于神经网络的。要有效地运用这些方法,有几个关键要求:
3.2.2.1 大型语料库
这些语料库需要包含成千上万甚至数十亿个句子。这是因为更大的数据集可以提供更丰富的语言信息,有助于提高模型的性能和泛化能力。
3.2.2.2 充足的计算能力
处理和分析大规模语料库需要强大的计算资源。随着数据量的增加,所需的计算能力也会成倍增长。
3.2.2.3 获取大型语料库的难度
在2000年代以前,即互联网、维基百科等资源变得普及之前,获取大型语料库是非常困难的。这限制了早期语言模型和统计方法的发展。
3.2.2.4 语料库工程处理
为了有效利用这些大型语料库,需要进行一系列的语料库工程处理,主要包括:

3.2.2.4.1 预处理
这包括句子和词汇的分割,以及根据具体任务需要进行的简化处理。预处理是为了将原始文本转换成更容易分析和处理的格式。
3.2.2.4.2 注释
通过在语料库中添加语言信息(如词性标注、句法结构等)来扩展语料库。这些注释信息通常通过监督学习的方式利用,以训练更准确的语言模型。
这些基于统计的方法通过分析大规模文本数据,能够自动学习语言规则和模式,从而支持各种自然语言处理应用,如机器翻译、语音识别和文本分析等。随着技术的进步和数据资源的增加,这些方法已经取得了显著的进步,并继续推动自然语言处理技术的发展。
3.3 符号主义的资源
在符号主义自然语言处理中,有许多资源可用于处理语言的不同层面,如形态学、词汇语义学和句法。以下是一些广泛使用的资源:
3.3.1 形态学(Morphology)
研究词的结构,包括词根、词缀、变形等。
UniMorph:提供169种语言的词形变化信息,可通过https://github.com/unimorph/访问。
MorphyNet:涵盖15种语言的派生词和词形变化网络,也可以在https://github.com/kbatsuren/MorphyNet上找到。
3.3.2 词汇语义学(Lexical Semantics)
关注词汇意义及其间的语义关系。
WordNet:是一个英文词汇数据库,包含超过100,000个单词,由专家维护,提供词义及其之间的各种语义关系。 http://wordnet.princeton.edu:
Universal Knowledge Core (UKC):链接了2000多种语言的词典,不过这些词典的覆盖范围各不相同。http://ukc.datascientia.eu
3.3.3 句法(Syntax)
涉及句子的结构,如短语的排列和层级关系。
Penn Treebank:专门为英语提供丰富的形态和句法注释的语料库。
Universal Dependencies**:提供跨语言的树库,覆盖100多种语言,使用共享的语言特征进行注释。
这些资源对于研究者和工程师来说是宝贵的工具,可以用来开发和改进NLP系统。通过这些资源,系统可以更好地理解和处理自然语言数据,无论是识别单词的不同形态,理解词汇之间的关系,还是分析句子结构。
4 NLP在机器学习的应用
4.1 监督学习的自然语言处理(NLP)流程图
这张图是一个典型的基于监督学习的自然语言处理(NLP)流程图。下面解释这个流程:

原始语料库(RAW CORPUS):这是未处理的文本数据集,是NLP系统学习的基础。
预处理和注释(PREPROC. & ANNOTATION):原始语料库经过预处理,如句子分割、词汇分割,以及大小写提取等,然后对其进行注释,如词性标注(POS Tagging)和命名实体识别(Named Entity Recognition,NER)。
注释语料库(ANNOTATED CORPUS):通过预处理和注释后得到的语料库,包含了丰富的语言信息,如词性标签和实体标签。
特征提取(FEATURE EXTRACTION):从注释语料库中提取出用于训练的特征,这些特征将用于模型的学习。
训练(TRAINING):使用机器学习组件(ML Component)对提取的特征和标签进行学习,从而训练出一个模型。
训练好的模型(TRAINED MODEL):经过训练的模型可以用来预测新的输入数据。
对于新的原始输入(RAW INPUT):
预处理(PRE-PROCESSING):新输入的文本也需要进行相同的预处理。
预处理后的输入(PREPROCESSED INPUT):完成预处理的文本,准备进行特征提取。
特征提取(FEATURE EXTRACTION):从预处理后的文本中提取特征。
特征(FEATURES):被提取出来的特征,将被用于预测。
预测(PREDICTION):使用训练好的模型和机器学习组件来对特征进行预测,产生标签。
图中的底部展示了一个具体例子:“Prof. Dupont crossed the square.”,展示了预处理、特征提取和预测的具体步骤,并给出了POS标签和NER标签的示例。如“Dupont”被标注为专有名词(NNP),并且在命名实体识别中被识别为人名的开始(B-PER)和内部(I-PER)。
4.2 统计机器学习方法优点和限制
统计机器学习方法在自然语言处理(NLP)中有许多优势,但也存在一些局限性。以下是这些方法的一些优点和限制:
4.2.1 优势
鲁棒性和泛化能力:基于监督学习的NLP组件通常更鲁棒,对未见过的数据具有更好的泛化能力,这意味着整个NLP流程的性能更高。
减少规则设计的人力:传统的基于规则的方法需要专家制定复杂的语言规则,而统计机器学习方法通过对大型语料库的注释学习这些规则,从而替代了设计规则的人力成本。
4.2.2 局限性
领域和跨语言转移的性能下降:即使一个模型在一个领域或语言上表现良好,将其应用到另一个领域或语言时,性能通常会显著下降。
语料库注释的人力成本:虽然替代了规则设计的人力,但现在需要大量的人力来注释语料库,这是一个耗时且复杂的过程。
对主流语言的偏好:由于大型注释语料库是必需的,这意味着那些已经拥有大量资源的主要语言会受到偏好,而资源较少的语言则难以发展相应的机器学习模型。
特征选择的难题:在机器学习中,选择哪些特征用于训练模型是一个非常重要但又非常复杂的经验问题(特征工程)。选择不当的特征可能会导致模型性能不佳。
总的来说,尽管基于统计的机器学习方法在NLP中取得了重大进步,但在跨领域、跨语言应用、数据注释成本和特征选择等方面仍面临挑战。解决这些问题通常需要更多的研究和创新。
5 NLP在深度学习的应用
深度神经网络在自然语言处理(NLP)中的两种范式:
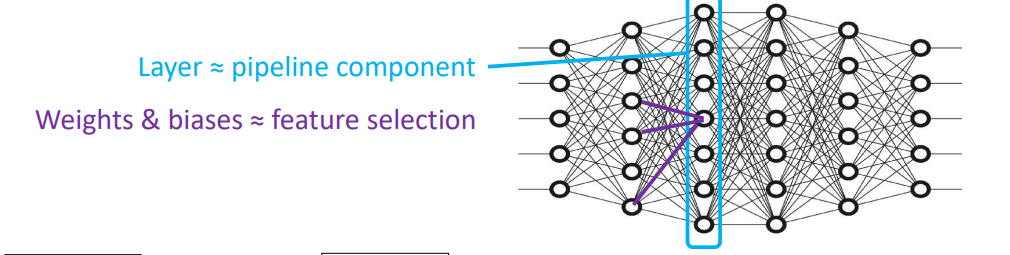
5.1 传统的监督学习范式

从原始语料库开始,经过预处理和注释得到注释语料库。
接着进行监督训练,从头开始训练一个深度神经网络模型。
在这个范式中,每一层的神经网络大约对应于传统NLP流水线中的一个组件,而网络中的权重和偏差(biases)负责特征选择的角色。
5.2 基于自监督学习的范式

这一范式同样从一个原始语料库开始,但此时使用的是大量未标记的语料库。
首先进行预处理,然后是自监督的预训练,这个过程完全自动化,不需要人工注释。
预训练得到一个预训练语言模型,然后在特定任务上进行监督式微调(fine-tuning)。
这种方法的优势在于,尽管微调阶段仍然需要监督,但所需的注释语料库规模可以小得多。
两种范式都涉及将原始文本数据转换为能够被机器学习模型理解的格式,但自监督学习范式通过利用大规模未标记数据减少了对注释数据的依赖,从而降低了对大型注释语料库的需求。这使得模型可以更好地泛化到新领域,也更容易适应不同的语言和任务。
5.3 深度神经网络方法在自然语言处理(NLP)领域中的优点和局限性
深度神经网络方法在自然语言处理(NLP)领域中带来了显著的进步,但同时也存在一些局限性。以下是这些方法的优点和局限性:
5.3.1 优点
最小或无需人工监督**:深度学习方法减少了对人工监督的依赖,对语言的先验知识的需求也消失了。
从大规模语料库中推断语言知识**:深度学习模型能够从非常大的语料库中(从整个维基百科到整个网络)推断出语言的一般知识。
在所有NLP任务中的性能改进**:深度学习方法在所有NLP任务上都实现了前所未有的性能提升。许多10年前还被认为对AI极具挑战性的问题现在已经被解决了,如机器翻译、Winograd模式识别等。
5.3.2 局限性
专业领域适应性的缺乏:尤其是在错误无法容忍的领域(例如医疗保健),深度学习模型没有直接的方法适应专业领域的推理;目前还不清楚如何让神经网络精确地对形式化知识进行推理。
网络获取的知识是隐式的:我们并不清楚隐藏层在做什么,这意味着没有可解释性。这对于需要理解模型决策过程的应用来说是一个缺点。
数字语言分割问题加剧:没有大型语料库,深度学习就无法工作。这可能加剧了数字鸿沟,使得资源较少的语言和社区更难利用深度学习技术。
尽管深度学习方法在NLP领域取得了巨大成功,但要充分利用这些方法,仍然需要解决它们的局限性,特别是在模型解释性和专业领域适应性方面。
6. 如何开发一个chatbot项目
对于一个旨在构建封闭世界聊天机器人的项目,您需要定义几个关键要素来确保项目的成功。封闭世界聊天机器人通常更容易管理和实施,因为它们在预定义的范围内操作。以下是对这样一个项目的要求和考量的一般指南:
6.1 设计流程
6.1.1 定义领域
确定一个具体的关注领域。这可能是零售店的客服、餐厅的预订助手或IT服务的帮助台。
6.1.2 设定范围
明确划定聊天机器人能够处理的话题范围。确定它应该回答哪些类型的问题以及它应该执行哪些任务。
6.1.3 设计对话流程
制定可能的对话流程图,包括问题、答案和后续提示。计划聊天机器人如何处理意外输入或超出其范围的请求。
6.1.4 选择平台
选择一个平台来构建和托管您的聊天机器人。这可以是社交媒体平台、网站或消息应用程序。
6.1.5 开发知识库
汇编聊天机器人用来回答查询的信息和数据。这可能包括常见问题解答、脚本、产品详情或政策信息。
6.1.6 实现自然语言处理能力
根据您的聊天机器人的复杂性,您可能会使用自然语言处理工具来解析用户输入和生成响应。这可能是非常基础机器人的简单关键词匹配,或者是理解意图和实体的更高级技术。
6.1.7 与后端系统集成
如果您的聊天机器人需要执行诸如预订桌位或检查账户状态之类的任务,则需要与相关数据库或API集成。
6.1.8 处理错误和升级
计划聊天机器人将如何将问题升级给人类代理,或响应它不理解的输入。
6.1.9 用户界面
设计一个用户友好的界面,可以处理输入类型(文本、按钮等)并清晰地显示响应。
6.1.10 测试和训练
开发测试用例,以确保聊天机器人对广泛输入的反应正确。使用这些案例训练机器人以提高准确性。
6.1.11 监控和反馈循环
建立一个系统来监控聊天机器人的互动并收集用户反馈,这对持续训练和改进至关重要。
6.1.12 合规性和隐私
确保您的聊天机器人遵守相关规定,特别是关于数据保护和隐私的规定。
您的最终目标是拥有一个能够在其领域内处理对话的功能性聊天机器人,展示对用户输入的理解并提供相关准确的响应。聊天机器人的复杂性可以根据可用时间、技术技能和资源而变化。
6.2 封闭世界聊天机器人的交互原则
在这种类型的聊天机器人中,对话的方向是受限的,它通过意图(intents)、行动(actions)和响应(responses)来控制聊天机器人的行为。这里是一个简单的对话流程,包括用户的输入、机器人识别的意图、所采取的行动以及给出的响应。
每当用户输入一个语句时,都被认为有一个特定的意图,例如打招呼、告别、预订航班、提供更多细节、抱怨等。针对每个用户的语句,机器人会:
a.猜测总体意图;
b.解析消息以获取细节;
c.如有必要,进行后台计算;
d.采取一个行动;
e.提供一个响应。

例如,用户说“Hi”,机器人识别出的意图是“user_greeting”,然后采取行动“greet_back”,响应“Hi there, how can I help you?”。当用户说“I’d like to book a ticket to Paris for tomorrow.”,机器人启动预订的意图“initiate_booking”,解析出目的地是巴黎,日期是08/02/2024,并询问出发城市。当用户回答“Brest”,机器人填充出发城市的槽位“fill_slot_departure_city”,并询问出发时间。
封闭世界聊天机器人如何在有限的对话范围内有效地工作,它可以明确地引导用户完成特定的任务,如预订机票。这种类型的聊天机器人适用于特定的应用场景,因为它们可以针对特定的问题提供精确的答案和解决方案。