随着金融业务转型步伐加快、业务连续性要求趋严,对金融业信息系统运行的稳定性要求日益提升。数据库作为信息系统中关键技术基础,如何应用数据库海量运行数据,提升运行指标数据观测性,及时发现数据库运行潜在风险,是G行数据库管理团队一直探索的课题。
数据库管理团队负责G行所有生产数据库的运维,虽然数据库领域相关监控趋于完善,数据库巡检实现了从脚本巡检到使用管理台巡检的改进,但面对近千套生产数据库每天产生的海量运行数据,如何提升巡检效率,实现数据横向、纵向对比,提高巡检数据精度,优化运行观测性,及时准确发现生产数据库运行的潜在隐患,仍具有一定的挑战。
本文以数据库关键运行指标为切入点,探索智能运维在数据库领域中的应用。
探索智能运维思路
为了弥补传统巡检及监控的不足,G行探索利用智能运维平台对生产数据库关键指标数据进行采集和分析,从中识别有价值的数据,力求实现对数据细粒度采集、偏离基线精准预警。
数据采集:通过统一的采集方案、采集策略,对数百套数据库实例运行中的关键性能指标进行细粒度采集,如活动会话数、QPS、TPS、硬解析、日志落盘时间、锁等待、索引分裂等指标,也可根据不同数据库灵活定制个性化采集项。
趋势分析:通过智能运维平台对采集的数据运行趋势及研判,优化数据存储策略,并以图表等形式展示运行状态,相比于传统模式下的手工巡检,数据更为直观。
风险预警:借助智能算法分析对数据进行异常检测,配置适当的阈值预警,当监控指标超过预设阈值时,及时发现数据库运行中的异常波动,自动发出预警通知。通过对生产数据库关键运行数据的实时采集,针对不同数据库业务类型的差异、联机交易和批量时间段的区别,配置适合的预警基线,实现对生产数据库运行态的实时监控与预警。
关键指标解读及智能运维应用
数据库运行指标众多,可分为资源、容量、性能、连接管理、SQL质量、异常事件等六个大类。
1.资源:包括CPU、内存、操作系统大页、磁盘性能(IOPS、吞吐量)等;
2.容量:包括磁盘空间、表空间、归档空间、序列使用率等;
3.性能:包括数据库活动会话、QPS、TPS、数据库内存管理、sql执行计划跳变等;
4.连接管理:用户并发连接数、是否存在短连接等;
5.SQL质量:硬解析、过长的sql语句、不合适的分组、排序等;
6.异常事件:内存争用、锁、索引分裂、过多的全表扫描等;
上述运行指标间彼此依赖,相互影响,任何指标的异常都可能影响生产数据库运行的效率及稳定性,那么究竟哪些需要我们重点关注,各个指标间的意义如何,造成的影响有哪些,接下来利用智能运维平台来对一些关键指标进行分析。
1.数据库活动会话(AAS)
数据库活动会话指的是当前正在执行操作或处于等待状态的会话,可能是正在执行SQL语句、等待资源(如CPU、内存、磁盘I/O)或进行其他数据库操作的会话,是数据库运行态描述、生产问题排查的切入点。应长期监控数据库的活动会话,观察数据库一段时间内活动会话运行趋势,如下图所示:

【图1】 数据库活动会话运行趋势
蓝色实线表示某个时间段内该数据库实时的活动会话数,蓝色阴影部分表示历史上相同时点活动会话数曾达到的波峰和波谷,红色圆点表示该时点活动会话数突破了历史峰值。
通常,在一个平稳运行的系统中,某个时间段内其活动会话数所呈现出的现象是在一个特定的区间内波动,根据该指标在联机业务和批量时段的运行特性,结合应用系统交易量趋势进行分析,对超出阈值范围的红色圆点部分应及时发现、分析、处理异常会话,如长时间运行的SQL语句、锁等待等,需要对活动会话偏离基线的现象制定合理的监控策略,及时发现数据库运行的异常情况,为管理员巡检和问题分析提供准确信息,以避免这些异常会话对数据库性能造成潜在的运行风险。
2.数据库每秒执行sql数(QPS)
反映数据库服务器每秒处理查询请求的数量,是衡量数据库性能的关键指标之一,高QPS意味着数据库能够在单位时间内处理大量的查询请求,可满足高并发的业务需求,该指标可帮助管理员了解数据库的负载情况,以便合理的规划硬件资源、调整数据库配置等,需要对QPS波动范围进行长期跟踪,如下图所示:
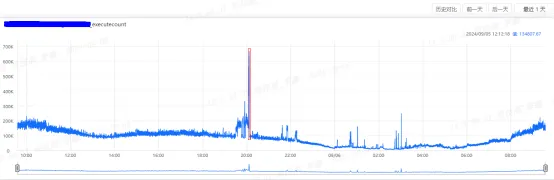
【图2】 数据库QPS
对QPS大幅偏离基线的时段进行深入分析,如上图时段数据库QPS峰值达到66万,并持续5分钟,短期内大幅增加了数据库压力,需要结合业务特性进行排查,为后续批量、数据库设计优化提供依据,减少在联机高峰时段数据库的压力。
3.数据库每秒事务数(TPS)
事务是数据库中的基本操作单位,具有原子性、一致性、隔离性、持久性的特性。该指标用于表示系统在单位时间内处理的事务数,受系统硬件诸如CPU、光纤链路、存储性能、等因素影响,高性能的CPU可以更快的处理事务,高效的存储性能可提升数据库日志落盘的效率,确保数据的完整性。对TPS波动范围进行长期跟踪,如下图所示:

【图2】 数据库TPS
管理员应长期关注业务交易量情况,识别业务高、低峰的周期,为评估数据库容量提供数据支持,为系统容量扩充提供依据。
4.数据库每秒硬解析(Hard Parse)
硬解析是指在执行SQL时,在库缓存中找不到可以重用的解析树和执行计划,而不得不重新解析SQL并生成相应的子游标的过程。这个过程相对耗时,它包括了语法检查、语义检查、查询转换以及根据统计信息生成执行计划等多个步骤。
硬解析对数据库性能的影响主要体现在以下几个方面:
增加CPU负担:硬解析过程中需要进行大量的计算和比较,这会增加CPU的负担。
增加内存消耗:每次硬解析都会生成新的游标和执行计划,需要消耗内存资源。
降低系统性能:如果数据库中存在大量的硬解析,那么系统的整体性能将会受到影响,大量的CPU和内存资源因被用于sql硬解析,而不是用于执行实际的数据库操作。
需要关注各个时段数据库中硬解析情况,如下图所示:
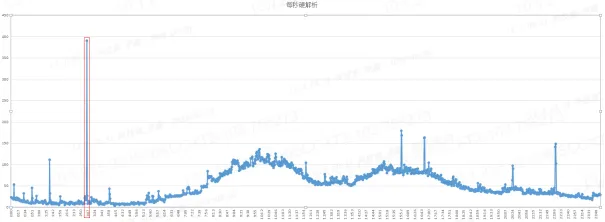
【图3】 数据库硬解析情况
某系统凌晨批量时段,在长达2分钟的时间内,硬解析均值达到400/每秒,峰值突破了1000/每秒,需及时找出导致硬解析高的sql语句,并使用绑定变量来降低硬解析次数,规避硬解析对数据库内存的冲击,对提高数据库的性能和稳定性具有重要意义。
5.数据库Redo日志生成量
采集生产数据库每天各个时段归档日志生成情况,识别联机交易高峰、批量高峰时段归档日志生成量,制定合适的归档日志备份和清理任务。如下图所示:
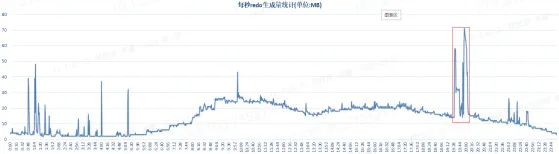
【图4】 各个时段Redolog生成量
在一个完整交易周期,对各个时段Redolog生成量进行采集和分析,由上图可见联机交易时段Redolog产生的峰值在10点,联机交易均值约为25M/秒,压力比较均衡,但批量时段的峰值需要特殊关注,如每日20点左右的批量,Redolog产生的峰值突破70M/秒,持续时间约10分钟,短期内将给数据库日志写入造成极大的压力,如果使用了日志层面的Primary-Standby架构,主库Redolog瞬时的写入压力高也将造成主从的同步延迟,影响主从之间数据的一致性,如果Standby备库承担实时读交易,会影响交易的准确性,针对这种情况需要从Redolog大小、日志组数量、存储的写入压力、光纤链路、网络带宽等全方位进行评估,避免出现因日志写入量大而影响联机交易。
G行后续将利用智能运维平台在横向、纵向两个维度进一步加大探索力度,在横向方面,全面覆盖行内重要系统数据库运行指标的采集与趋势分析;在纵向方面,建立动态数据预警基线;针对生产数据库的运行做到实时监控、精准定位异常、优化资源配置。基线作为数据库健康状况的“晴雨表”,需要引起足够的重视,通过及时分析、处理预警信息,防止小问题演变成大故障,提高数据库的可用性和可靠性,保障业务的顺利开展。
原创 李鑫 匠心独运维妙维效