除了白月光我们也需要朱砂痣
我最近也在反思,可能有时候算法和论文也不是每个读者都爱看,我也会在今后的文章中加点code或者debug模型的内容,也许还有一些好玩的应用demo,会提升这部分在文章类型中的比例
今天带着大家通过代码角度看一下Llama,或者说看一下Casual-LLM的Transfomer到底长啥样
对Transfomer架构需要更了解的读者,可以先看这个系列
小周带你读论文-2之"草履虫都能看懂的Transformer老活儿新整"Attention is all you need(1) (qq.com)
小周带你读论文-2之"草履虫都能看懂的Transformer老活儿新整"Attention is all you need(2) (qq.com)
小周带你读论文-2之"草履虫都能看懂的Transformer老活儿新整"Attention is all you need(3) (qq.com)
小周带你读论文-2之"草履虫都能看懂的Transformer老活儿新整"Attention is all you need(4) (qq.com)
友情提示,看代码和debug都不需要GPU,在你的PC上就可以做
首先先安装transfomer库
pip install transfomers
然后进入到库下面,一般在这

进去就能找到Transfomers的库,往下拉到models,可以发现各种模型都在里面
找到Llama,包含以下文件
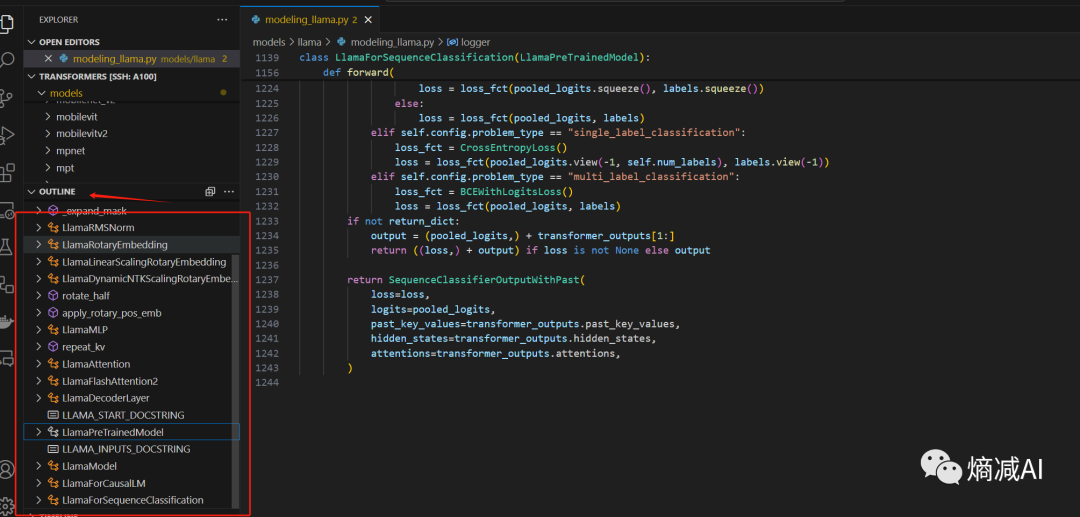
点进modeling_llama.py发现1200多行,根本没法看(一般人没那么多耐心,但是其实仔细看两遍还是很有收获的),然后点击左边outline 大纲,(或者ctrl+shift+o),就可以有选择的看你想要研究的具体网络层,这样感觉压力瞬间小了百分之80以上
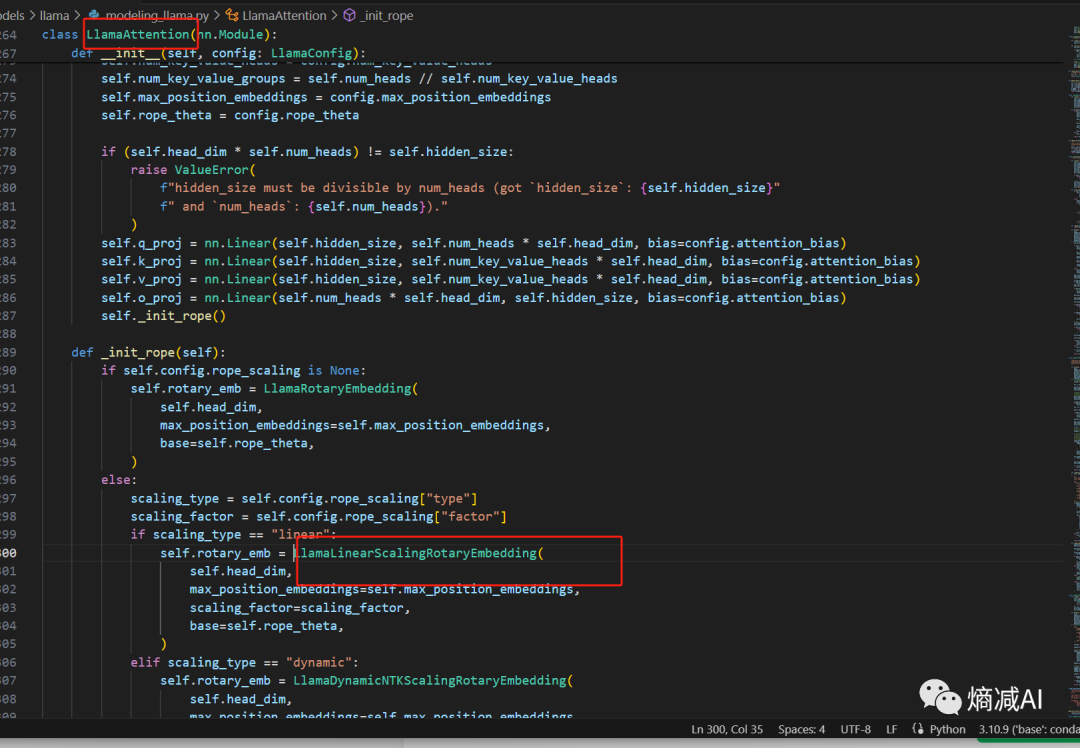
我想查某个函数的代码块,想对它加深了解,举个例子,看起来比较怪异命名的,这个线性扩展RoPE embedding的函数
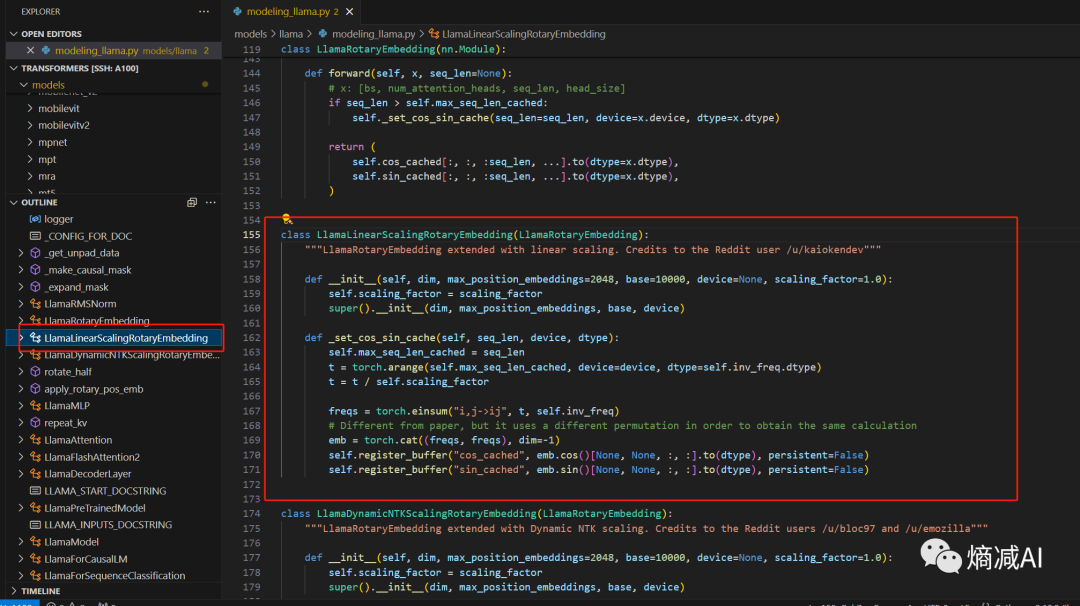
然后ctl按住函数名字就能查到它作用于attetion的机制里面,在这种情况下即使我不知道它到底干啥,也能猜个89不离10,至少和什么主模块相关我清楚了
本章的话,我们先从模型主体部分看起,点LlamaModel,就能看到非常清晰的逻辑
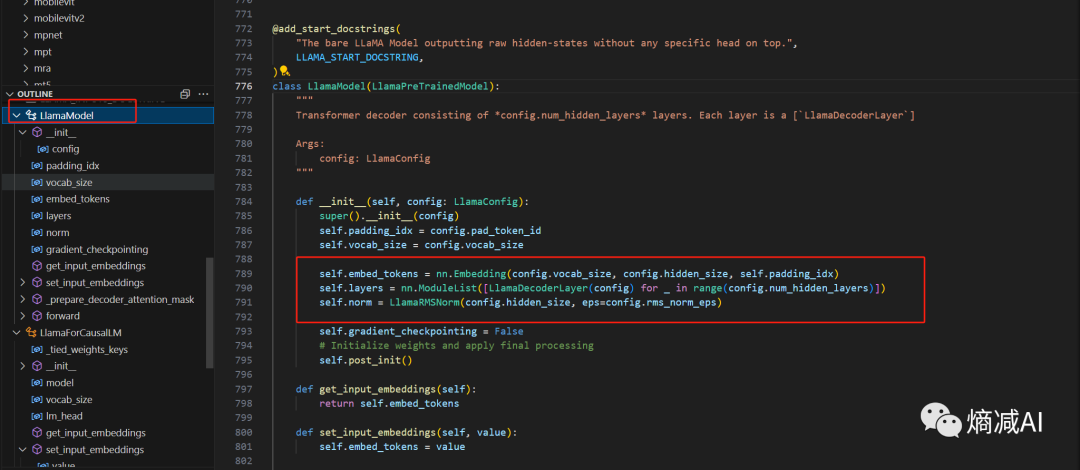
主体部分包含3个子模块:
-
先要embedding token
-
再要包含一个通过for循环,不断的持续经过的decoder层
-
还要包含一个Normal(RMSNorm)
从大面上看也就这么3个操作
初始化部分,初始了哪些模块我们看完了,再看看细节,从forward看起(大家看任何网络都要重点看forward)
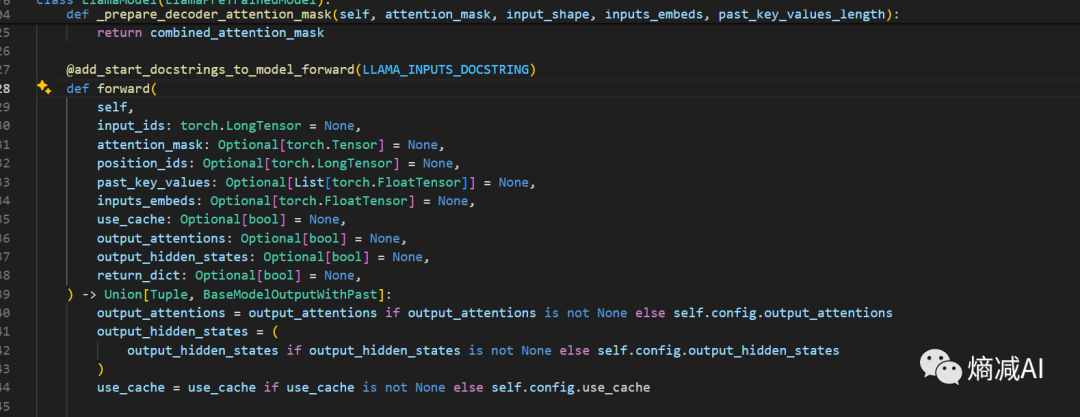
forward输入部分,要求输入的参数:
-
input_ids:输入序列标记的索引,形状为(batch_size, sequence_length)的torch.LongTensor。
-
attention_mask:避免对填充标记进行注意力计算的掩码,形状为(batch_size, sequence_length)的torch.Tensor
-
position_ids:输入序列标记在位置嵌入中的索引,形状为(batch_size, sequence_length)的torch.LongTensor
-
past_key_values:包含预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),用于加速顺序解码的tuple,推理用的,当use_cache=True时,会返回这个参数,训练不用管
-
inputs_embeds:直接传入embedding表示而不是input_ids,形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor
-
use_cache:是否使用缓存加速解码的布尔值,当设置为True时,past_key_values的键值状态将被返回,用于加速解码
-
output_attentions:是否返回所有注意力层的注意力张量,布尔值,当设置为True时,会在返回的结果中包含注意力张量
-
output_hidden_states:是否返回所有层的隐藏状态,布尔值,当设置为True时,会在返回的结果中包含隐藏状态
-
return_dict:是否返回utils.ModelOutput对象而不是普通的元组,布尔值,当设置为True时,会返回一个ModelOutput对象
我们继续看,下面就是一些操作步骤,输入的input_id,会被向量化,生成hidden_states
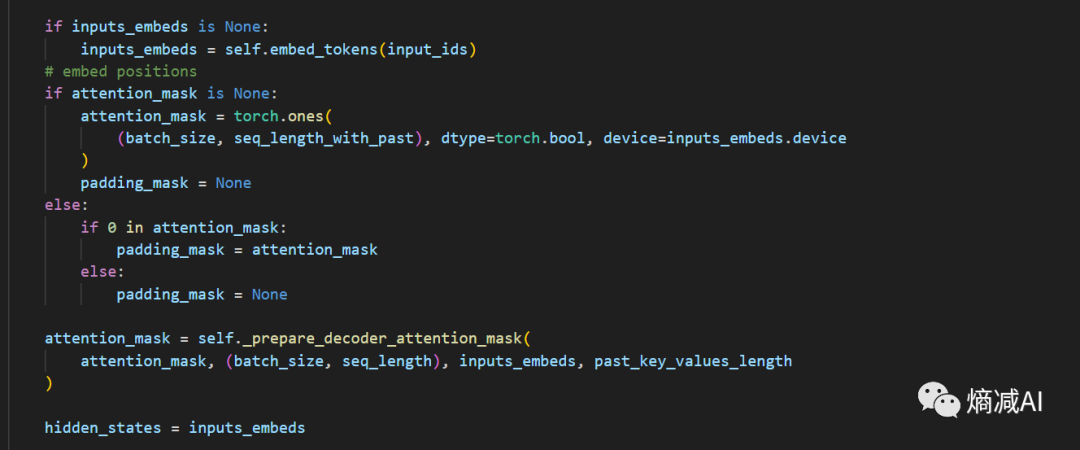
hidden_states然后就被扔进了若干个hidden_layer被for循环来回的操作,比如Llama7B的32层
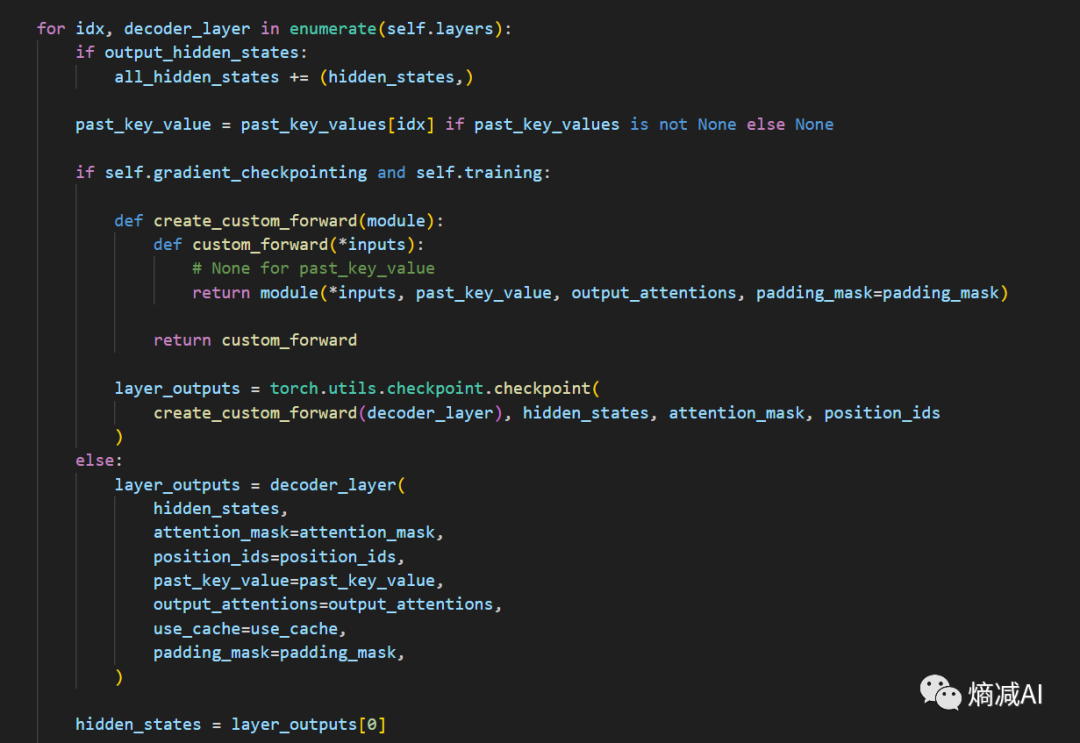
我们简单写一段逻辑描述上述的代码
比如在把"我爱你"已经分词的情况下 我=100,爱=200,你=300
input_ids = [100,200,300]
input_ids -> nn.Emebdding(dims=3) -> hidden_states
hidden_states = [[0.1,0.2,0.3],[0.4,0.5,0.6],[0.7.0.8.1.1]]
hidden_states ->layer1 ->layer2 ------>layer32
最终还是hidden_states
也就是最终的shape和初始的hidden_states的shape的相同的
hidden_states -> Norm -> hidden_states
其实没必要把hidden_states理解的那么悬,就当它是个中间变量就可以了
Layer里面都有什么呢?我们点进去Layer里面就能看到
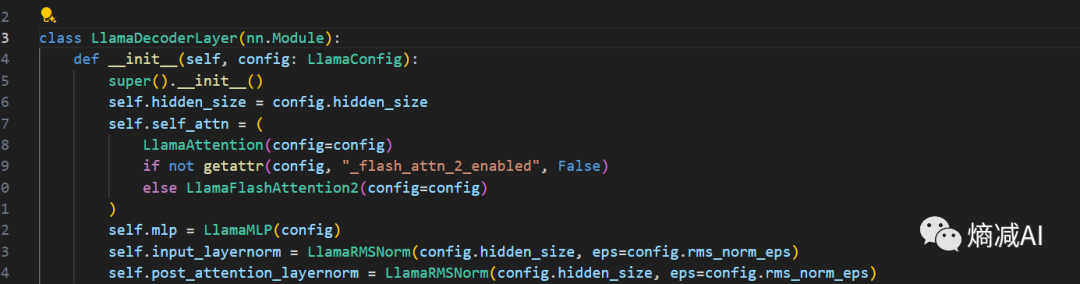
包含了我们在Transfomer里学到的attention层,MLP层,LayerNorm这些层
继续往下
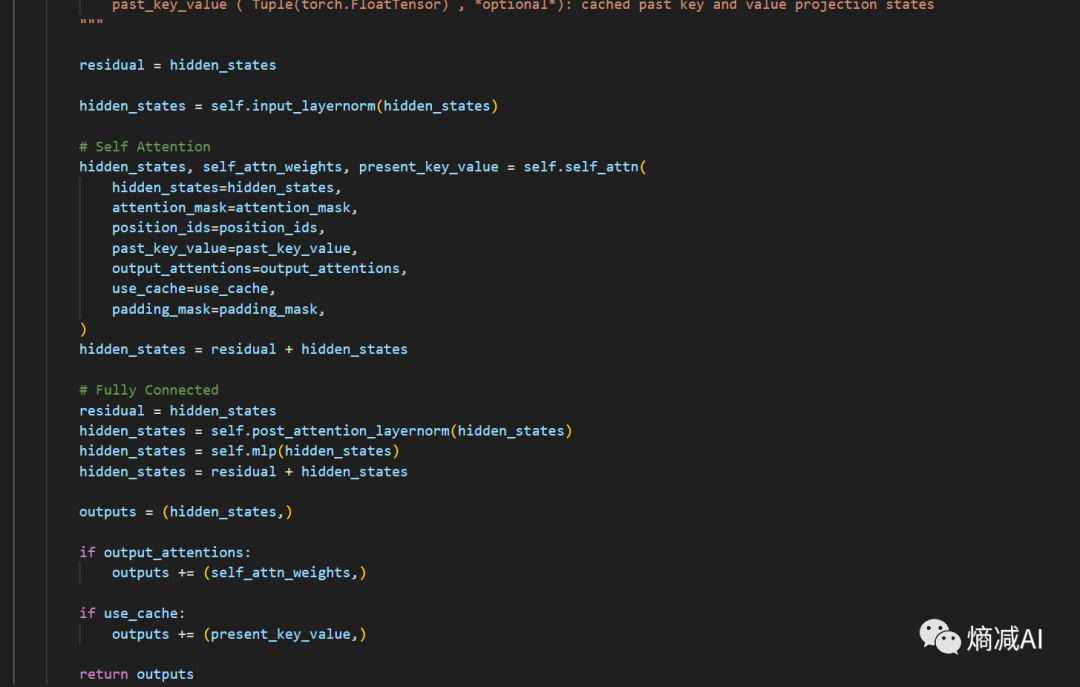
我们可以看到首先定义了残差,然后hidden_states在没过layer之前就先被Normal了一下(这个知识点以前也讲过,Llama RMS LN是前LN),然后过attetion,过MLP,最后hidden_states=residual+hidden_states, 这样就把位置编码啥的也都带过来了
然后我们点击进入attetion这块,看看它是咋做的
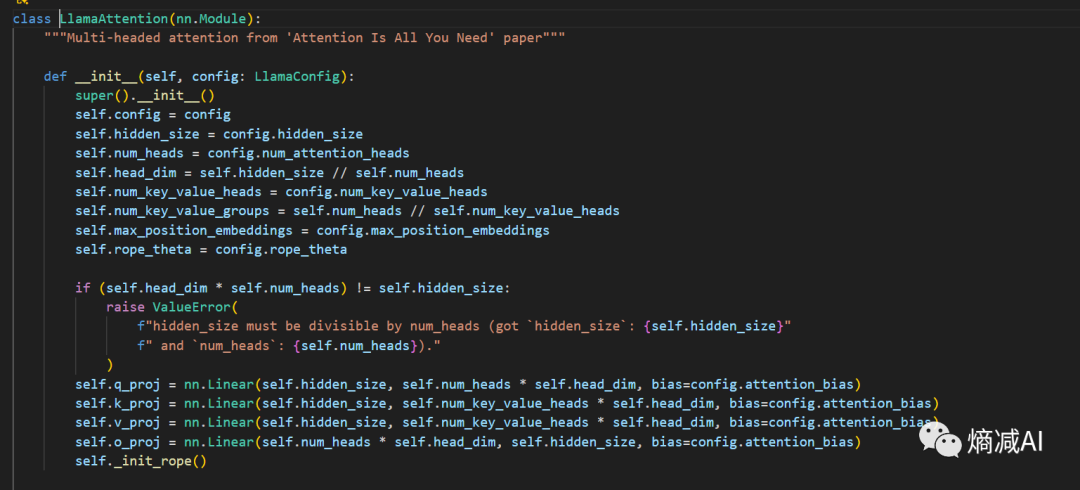
这块其实感觉都不用讲了,我觉得全部代码就这块写的逻辑是最清楚的

,QKV矩阵就是下面前三个线性层,然后分别主管生成qkv,上面的参数也解释了多头,和多头dim是咋算出来的,GQA咋算,这块代码写的实在清晰,属实没啥可说的
最后看一眼MLP层,就是FFN
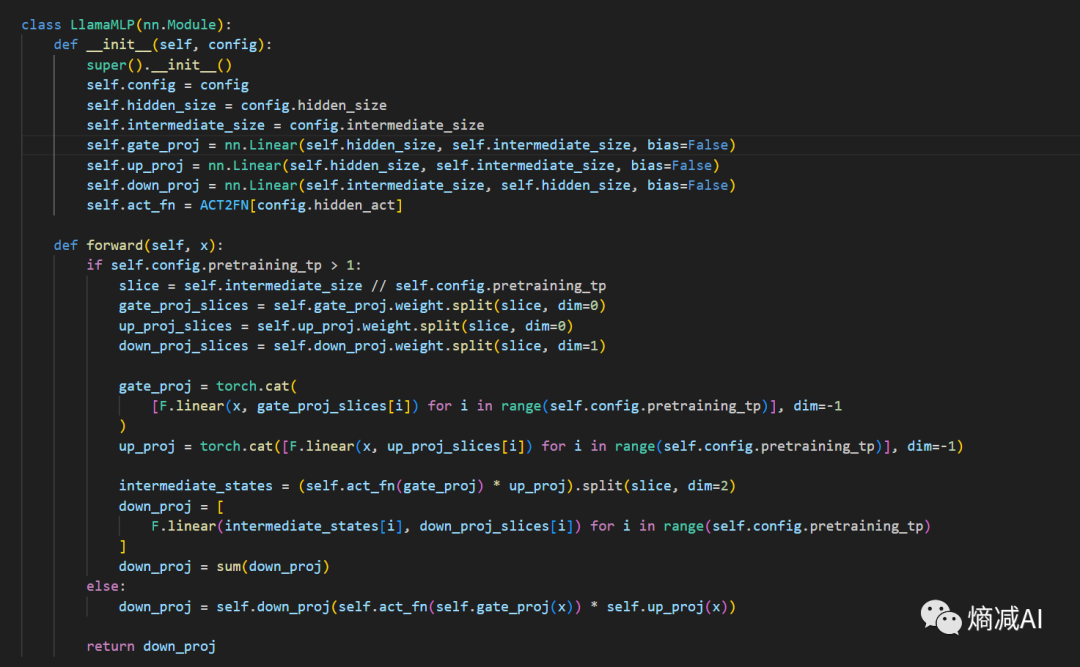
这一层是由3个线性层组成的gate+up+down,和标准transfomer的FFN是真不一样,主要有两点不同:
1- 原始transfomer是由两个线性层组成,这里有3个,原因就在于 SwiGLU 激活函数比类似 ReLU 的激活函数,需要多一个 Linear 层(gate)进行门控,所以你说SwiGLU是比ReLU效率高了,还是低了呢?

(当然这个门控可以并行操作)
2- 原始Transfomer第一个线性层先将维度映射为4h维,第二个线性层再映射回h维,接着进行激活函数操作。而llama则是将原有4h变成一个常量作为输入,且计算方式也略有不同,可能是因为4h这个说法如果模型太大会罩不住,就用一个常量来代替了(我瞎猜的)
这基本网络就讲完了,其实大家看看也没啥玩意,比较简单
再比如说我们像看一下Llama是咋做下游任务的,modeling里面有2个,我们挑CLM任务(主管生成的任务,CasualLM)来看
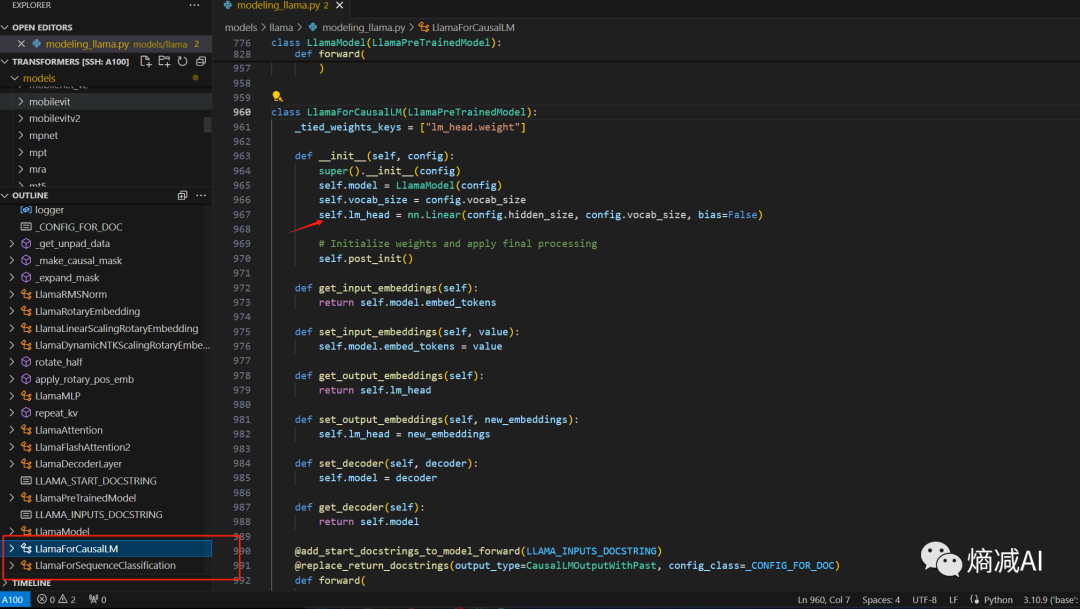
如上图所示,就是在Llama的基础模型之上,加了一个线性层
然后我们展开LlamaForCausalLM
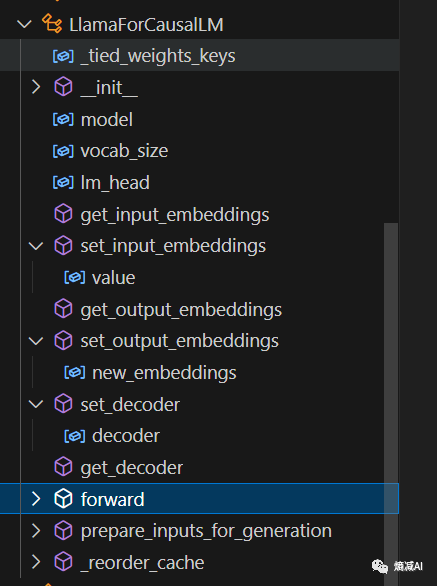
可以看到它包含很多内容,这里面重点肯定还是forward(前向),我们就看一下它的前向是怎么进行的,输入是啥,输出是啥?
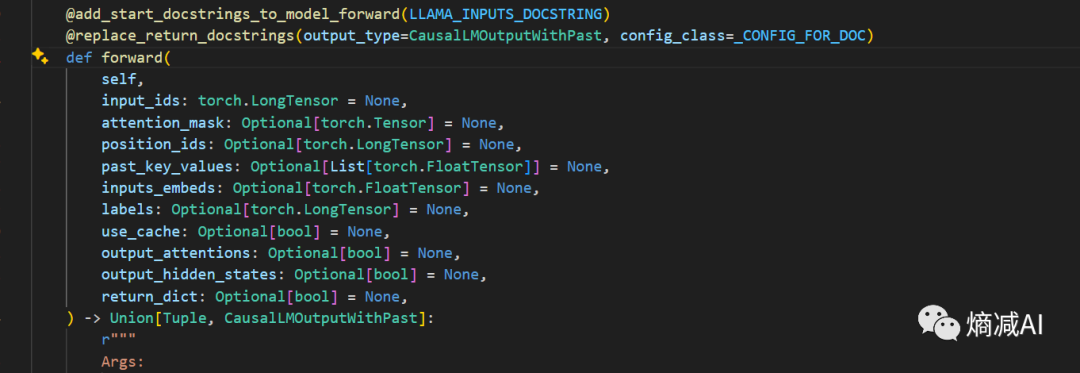
我们先看forward输入部分,要求输入的参数和前面都一样唯一的区别就是Label
-
Labels:没法解释,就是字面上的Labels

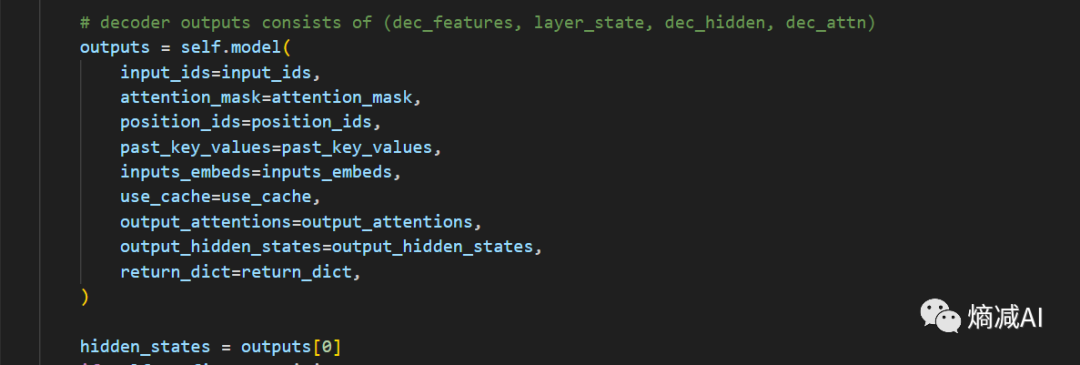
输出这块我们就关注hidden_states就行了,这也是最重要的
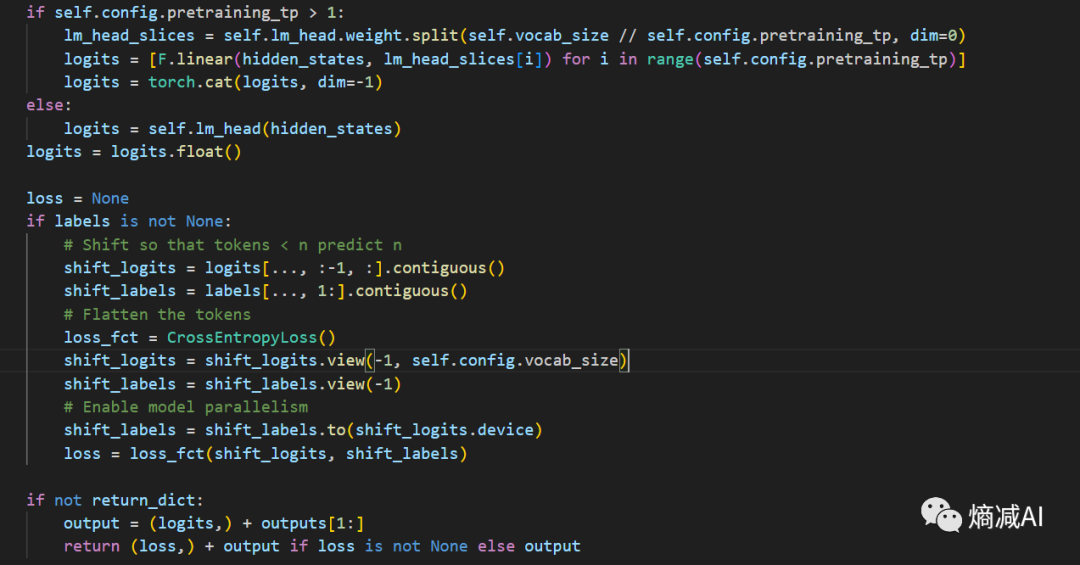
然后hiden_states和你的labels进行匹配求交叉熵损失,最后损失最小的就是最高概率生成的token
下面那个文本分类的其实也是一样的,只不过它计算Loss的时候会有说明,单标签就是回归任务,多标签就变分类任务了
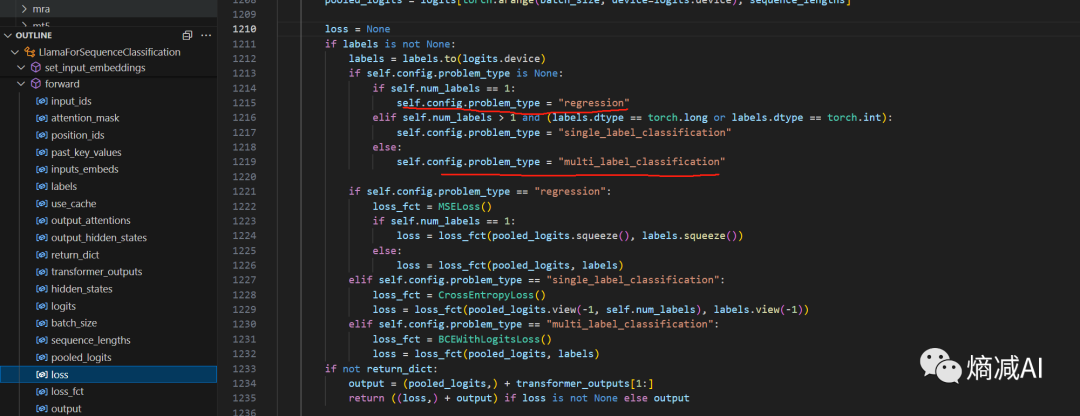
通过这些简单的方法,就能把读者们把以前理解不太透彻的网络模块都理一遍,加深印象
本章完