机器学习 1:第 1 课
原文:
medium.com/@hiromi_suenaga/machine-learning-1-lesson-1-84a1dc2b5236译者:飞龙
协议:CC BY-NC-SA 4.0
来自机器学习课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和 Rachel 给了我这个学习的机会。
简要课程大纲
根据时间和班级兴趣,我们将涵盖类似以下内容(不一定按照这个顺序):
训练 vs. 测试
- 有效的验证集构建
树和集成
-
创建随机森林
-
解释随机森林
什么是机器学习?为什么我们使用它?
-
什么构成了一个好的机器学习项目?
-
结构化 vs 非结构化数据
-
失败/错误的例子
特征工程
-
领域特定 — 日期,URL,文本
-
嵌入/潜在因子
使用 SGD 训练的正则化模型
- 广义线性模型,Elasticnet 等(注意:查看 James 讲解的内容)
基本神经网络
-
PyTorch
-
广播,矩阵乘法
-
训练循环,反向传播
KNN
CV / bootstrap(糖尿病数据集?)
伦理考虑
跳过:
-
降维
-
交互
-
监控训练
-
协同过滤
-
动量和学习率退火
随机森林:蓝皮书对于推土机
笔记本 / Kaggle
%load_ext autoreload
%autoreload 2
%matplotlib inline
from fastai.imports import *
from fastai.structured import *
from pandas_summary import DataFrameSummary
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
from IPython.display import display
from sklearn import metrics
数据科学 ≠ 软件工程 [08:43]。你会看到一些不符合 PEP 8 的代码和import *之类的东西,但暂时跟着走一段时间。我们现在正在做的是原型模型,原型模型有一套完全不同的最佳实践,这些实践在任何地方都没有教授。关键是能够非常互动和迭代地进行操作。Jupyter 笔记本使这变得容易。如果你曾经想知道display是什么,你可以做以下三件事之一:
-
在一个单元格中键入
display,然后按 shift+enter — 它会告诉你它来自哪里<function IPython.core.display.display> -
在一个单元格中键入
?display,然后按 shift+enter — 它会显示文档 -
在一个单元格中键入
??display,然后按 shift+enter — 它会显示源代码。这对于 fastai 库特别有用,因为大多数函数都很容易阅读,而且不超过 5 行。
下载数据 [12:05]
参加 Kaggle 竞赛将让你知道你是否在这种模型中的这种数据上有竞争力。准确率低是因为数据太嘈杂,你无法做得更好吗?还是实际上是一个简单的数据集,而你犯了错误?当你在自己的项目中使用自己的数据集时,你将得不到这种反馈 — 我们只需要知道我们有良好的有效技术来可靠地构建基线模型。
机器学习应该帮助我们理解数据集,而不仅仅是对其进行预测 [15:36]。因此,选择一个我们不熟悉的领域,这是一个很好的测试,看看我们是否能够建立理解。否则,你的直觉可能会使你很难保持足够开放的心态去看待数据真正的含义。
有几种下载数据的选项:
-
下载到您的计算机并通过
scp传输到 AWS -
从 Firefox [17:32],按
ctrl + shift + i打开 Web 开发者工具。转到Network选项卡,点击Download按钮,然后取消对话框。它会显示已启动的网络连接。然后右键单击它,选择Copy as cURL。粘贴命令并在末尾添加-o bulldozer.zip(可能删除 cURL 命令中的— — 2.0)
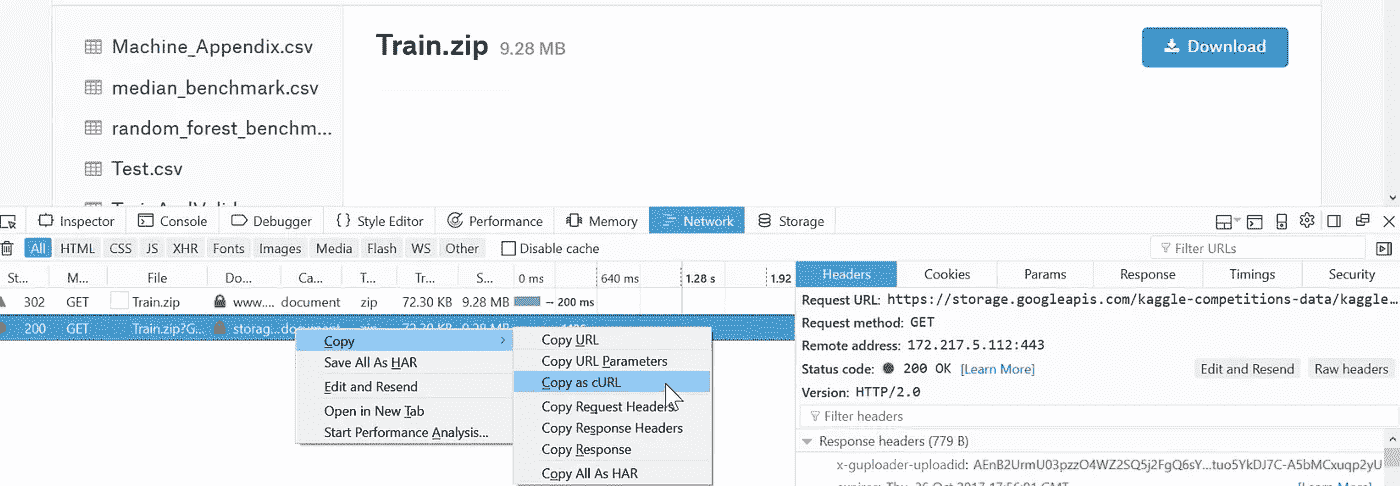
Jupyter 技巧[21:39] - 您可以打开基于 Web 的终端,如下所示:
这个竞赛的目标是使用包含截至 2011 年底的数据的训练集来预测推土机的销售价格。
让我们看看数据[25:25]:
结构化数据:代表各种不同类型事物的列,如标识符、货币、日期、大小。
非结构化数据:图像
当您处理通常作为pd导入的结构化数据时,pandas是最重要的库。
df_raw = pd.read_csv(f'{PATH}Train.csv', low_memory=False, parse_dates=["saledate"]
)
-
parse_dates- 包含日期的任何列的列表 -
low_memory=False- 强制它读取更多文件以确定类型。
def display_all(df):with pd.option_context("display.max_rows", 1000): with pd.option_context("display.max_columns", 1000): display(df)display_all(df_raw.tail().transpose())
在 Jupyter Notebook 中,如果您键入一个变量名并按ctrl+enter,无论是 DataFrame、视频、HTML 等 - 它通常会找到一种显示方式供您使用[32:13]。

我们想要预测的变量在这种情况下被称为因变量,在这种情况下我们的因变量是SalePrice。
问题:因为过拟合的风险而永远不应查看数据吗?[33:08] 我们至少想知道我们已经成功导入了足够的数据,但在这一点上通常不会真正研究它,因为我们不想对它做太多假设。许多书籍建议首先进行大量的探索性数据分析(EDA)。我们今天将学习机器学习驱动的 EDA。
项目目的 - 评估[34:06]
均方根对数误差。我们使用对数的原因是因为通常,您更关心的不是差$10,而是差 10%。所以如果是$1000,000 的物品,您差$100,000,或者如果是$10,000 的物品,您差$1,000 - 我们会认为这些是等价的规模问题。
df_raw.SalePrice = np.log(df_raw.SalePrice)
np- Numpy 让我们将数组、矩阵、向量、高维张量视为 Python 变量。
什么是随机森林?[36:37]
随机森林是一种通用的机器学习技术。
-
它可以预测任何类型的东西 - 它可以是一个类别(分类),一个连续变量(回归)。
-
它可以预测任何类型的列 - 像素、邮政编码、收入等(即结构化和非结构化数据)。
-
它通常不会过度拟合,而且很容易阻止过度拟合。
-
通常情况下不需要单独的验证集。即使只有一个数据集,它也可以告诉您它的泛化程度如何。
-
它几乎没有任何统计假设。它不假设您的数据是正态分布的,关系是线性的,或者您已经指定了交互作用。
-
它需要非常少的特征工程。对于许多不同类型的情况,您不必对数据取对数或将交互作用相乘。
问题:维度的诅咒是什么?[38:16] 你经常听到两个概念 - 维度的诅咒和没有免费午餐定理。它们两者在很大程度上是毫无意义的,基本上是愚蠢的,然而许多领域的人不仅知道这一点,而且认为相反,因此值得解释。维度的诅咒是这样一个想法,即你拥有的列越多,就会创造出一个越来越空的空间。有这样一个迷人的数学思想,即你拥有的维度越多,所有点就越多地位于该空间的边缘。如果你只有一个随机的维度,那么它们就会分散在各处。另一方面,如果是一个正方形,那么它们在中间的概率意味着它们不能在任一维度的边缘,因此它们不太可能不在边缘。每增加一个维度,点不在至少一个维度的边缘上的可能性就会成倍减少,因此在高维度中,一切都位于边缘。从理论上讲,这意味着点之间的距离变得不那么有意义。因此,如果我们认为这很重要,那么它会暗示当你有很多列并且没有小心删除你不关心的列时,事情将不起作用。出于许多原因,结果并非如此
-
点之间仍然有不同的距离。只是因为它们在边缘上,它们仍然在彼此之间的距离上有所不同,因此这一点在这一点上比在那一点上更相似。
-
所以像 k 最近邻居这样的东西在高维度中实际上表现得非常好,尽管理论家们声称的不同。这里真正发生的是,在 90 年代,理论主导了机器学习。有这样一个概念,支持向量机在理论上得到了很好的证明,极易进行数学分析,你可以证明关于它们的事情 - 我们失去了十年的真正实际发展。所有这些理论变得非常流行,比如维度的诅咒。如今,机器学习的世界变得非常经验主义,事实证明,在实践中,在许多列上构建模型确实效果非常好。
-
没有免费午餐定理[41:08] - 他们声称没有一种模型适用于任何类型的数据集。在数学意义上,任何随机数据集的定义都是随机的,因此不会有一种方法可以查看每个可能的随机数据集,使其在某种程度上比其他方法更有用。在现实世界中,我们看的是不随机的数据。从数学上讲,我们会说它位于某个较低维度的流形上。它是由某种因果结构创建的。其中存在一些关系,因此事实是我们并没有使用随机数据集,因此实际上有一些技术比其他技术在你查看的几乎所有数据集上都要好得多。如今,有经验的研究人员研究哪些技术在大多数情况下效果很好。决策树的集成,其中随机森林是其中最常见的技术之一。Fast.ai 提供了一种标准的方法来适当地预处理它们并设置它们的参数。
scikit-learn[42:54]
Python 中最受欢迎和重要的机器学习包。它并非在所有方面都是最好的(例如,XGBoost 比梯度提升树更好),但在几乎所有方面都表现得相当不错。
m = RandomForestRegressor(n_jobs=-1)
-
RandomForestRegressor - 回归器是一种预测连续变量(即回归)的方法
-
RandomForestClassifier - 分类器是一种预测分类变量(即分类)的方法
m.fit(df_raw.drop('SalePrice', axis=1), df_raw.SalePrice)
scikit-learn 中的所有内容都具有相同的形式。
-
为机器学习模型创建一个对象的实例
-
通过传入独立变量(你要用来预测的东西)和因变量(你想要预测的东西)来调用
fit。 -
axis=1表示删除列。 -
在 Jupyter Notebook 中按下
shift + tab将显示函数的参数检查。 -
“类似列表”意味着任何你可以在 Python 中索引的东西。

以上的代码会导致错误。数据集“Conventional”中有一个值,它不知道如何使用该字符串创建模型。我们必须将大多数机器学习模型和随机森林转换为数字。因此,第一步是将所有内容转换为数字。
这个数据集包含了连续和分类变量的混合。
-
continuous — 数字,其含义是数值,比如价格。
-
categorical — 要么是数字,其含义不是连续的,比如邮政编码,要么是字符串,比如“大”,“中”,“小”
以下是我们可以从日期中提取的一些信息 — 年份、月份、季度、月中的日期、星期几、一年中的周数、是否是假期?周末?下雨了吗?那天有体育赛事吗?这取决于你在做什么。如果你正在预测 SoMa 地区的苏打销售额,你可能想知道那天是否有旧金山巨人队的比赛。日期中包含的信息是你可以进行的最重要的特征工程之一,没有任何机器学习算法可以告诉你那天巨人队是否在比赛,以及这一点有多重要。因此,这就是你需要进行特征工程的地方。
add_datepart方法从完整的日期时间中提取特定的日期字段,以构建分类变量。在处理日期时间时,你应该始终考虑这个特征提取步骤。如果不将日期时间扩展到这些额外字段,你就无法捕捉到任何趋势/周期性行为,作为时间的函数在任何这些粒度上。
def add_datepart(df, fldname, **drop=True**):fld = df[fldname]if not np.issubdtype(fld.dtype, np.datetime64):df[fldname] = fld = pd.to_datetime(fld, infer_datetime_format=True)targ_pre = re.sub('[Dd]ate$', '', fldname)for n in ('Year', 'Month', 'Week', 'Day', 'Dayofweek', 'Dayofyear', 'Is_month_end', 'Is_month_start', 'Is_quarter_end', 'Is_quarter_start', 'Is_year_end', 'Is_year_start'):df[targ_pre+n] = getattr(fld.dt,n.lower()) df[targ_pre+'Elapsed'] = fld.astype(np.int64) // 10**9if drop: df.drop(fldname, axis=1, inplace=True)
-
getattr— 查找对象内部并找到具有该名称的属性 -
drop=True— 除非指定,它将删除日期时间字段,因为我们不能直接使用“saledate”,因为它不是一个数字。
fld = df_raw.saledate
fld.dt.year
-
fld— Pandas 系列 -
dt—fld没有“year”,因为它只适用于 Pandas 系列,这些系列是日期时间对象。因此,Pandas 会将不同的方法拆分到特定于它们的属性中。因此,日期时间对象将有dt属性定义,那里你会找到所有日期时间特定的属性。
add_datepart(df_raw, 'saledate')
df_raw.saleYear.head()
问题:[55:40] df['saleYear'] 和 df.saleYear 之间有什么区别?在分配值时最好使用方括号,尤其是在列不存在的情况下。
运行add_datepart后,它添加了许多数字列并删除了saledate列。这还不足以解决我们之前看到的错误,因为我们仍然有其他包含字符串值的列。Pandas 有一个类别数据类型的概念,但默认情况下它不会将任何内容转换为类别。Fast.ai 提供了一个名为train_cats的函数,它会为所有是字符串的内容创建分类变量。在幕后,它创建了一个整数列,并将从整数到字符串的映射存储在其中。train_cats被称为“train”,因为它是特定于训练数据的。验证和测试集将使用相同的类别映射(换句话说,如果你在训练数据集中使用 1 表示“高”,那么在验证和测试数据集中 1 也应该表示“高”)。对于验证和测试数据集,使用apply_cats。
train_cats(df_raw)
df_raw.UsageBand.cat.categories
'''
Index(['High', 'Low', 'Medium'], dtype='object)
'''
df_raw.UsageBand.cat— 类似于fld.dt.year,.cat让你可以访问假设某个东西是一个类别的内容。
顺序并不太重要,但由于我们将创建一个在单个点(即高 vs. 低 和 中,高 和 低 vs. 中)分割事物的决策树,这有点奇怪。为了以合理的方式对它们进行排序,您可以执行以下操作:
df_raw.UsageBand.cat.set_categories(['High', 'Medium', 'Low'],ordered=True, inplace=True
)
inplace将要求 Pandas 更改现有数据框而不是返回一个新的。
有一种称为“有序”的分类变量。有序分类变量具有某种顺序(例如“低” < “中” < “高”)。随机森林对此事实并不敏感,但值得注意。
display_all(df_raw.isnull().sum().sort_index()/len(df_raw))
上述操作将为每个系列添加一些空值,我们按索引排序它们([pandas.Series.sort_index](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.sort_index.html)),并除以数据集的数量。
读取 CSV 大约需要 10 秒,处理另外需要 10 秒,因此如果我们不想再等待,最好将它们保存下来。这里我们将以 feather 格式保存。这将以与 RAM 中相同基本格式保存到磁盘。这是迄今为止最快的保存和读取方式。Feather 格式不仅在 Pandas 中成为标准,而且在 Java、Apache Spark 等中也是如此。
os.makedirs('tmp', exist_ok=True)
df_raw.to_feather('tmp/bulldozers-raw')
我们可以这样读取它:
df_raw = pd.read_feather('tmp/raw')
我们将用它们的数字代码替换类别,处理缺失的连续值,并将因变量拆分为一个单独的变量。
df, y, nas = proc_df(df_raw, 'SalePrice')
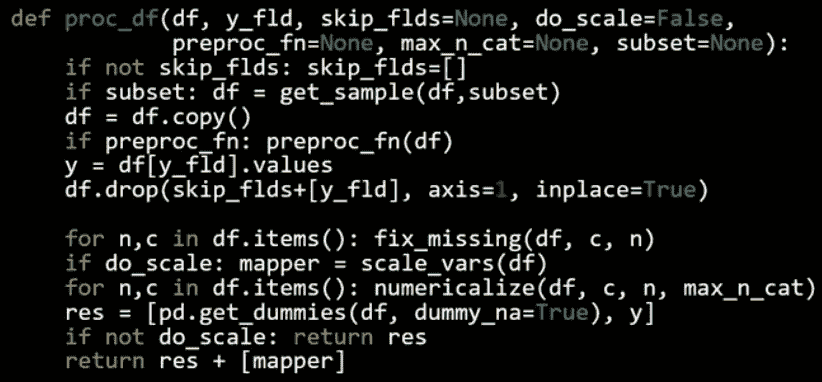
structured.py 中的 proc_df
-
df— 数据框 -
y_fld— 依赖变量的名称 -
它会复制数据框,获取依赖变量值(
y_fld),并从数据框中删除依赖变量。 -
然后它将
fix_missing(见下文) -
然后我们将遍历数据框并调用
numericalize(见下文)。 -
dummies— 有少量可能值的列,可以放入虚拟变量而不是数值化它们。但我们现在不会这样做。
fix_missing

-
对于数值数据类型,首先我们检查是否有空列。如果有,它将创建一个新列,名称末尾附加
_na,如果缺失则设置为 1;否则设置为 0(布尔值)。然后将缺失值替换为中位数。 -
我们不需要为分类变量执行此操作,因为 Pandas 会自动处理它们并将它们设置为
-1。
numericalize
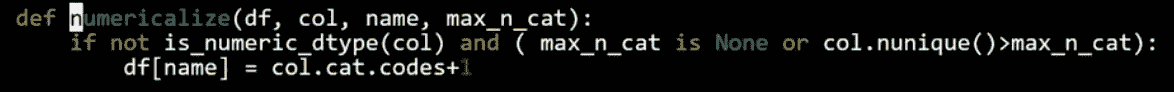
- 如果不是数字且是分类类型,我们将用其代码加 1 替换该列。默认情况下,Pandas 对缺失使用
-1,因此现在缺失将具有 ID 为0。
df.head()

现在我们有所有的数值值。请注意,布尔值被视为数字。因此我们可以创建一个随机森林。
m = RandomForestRegressor(n_jobs=-1)
m.fit(df, y)
m.score(df,y)
随机森林是极易并行化的 — 意味着如果您有多个 CPU,可以将数据分配到不同的 CPU 上并且它会线性扩展。因此,您拥有的 CPU 越多,花费的时间就会按照该数字减少(不完全准确,但大致如此)。n_jobs=-1告诉随机森林回归器为每个 CPU 创建一个单独的作业/进程。
m.score将返回 r²值(1 是好的,0 是坏的)。我们将在下周学习 r²。
哇,r²为 0.98 — 那很棒,对吧?嗯,也许不是…
机器学习中最重要的想法之一是拥有单独的训练和验证数据集。作为动机,假设您不将数据分割,而是使用全部数据。假设您有很多参数:
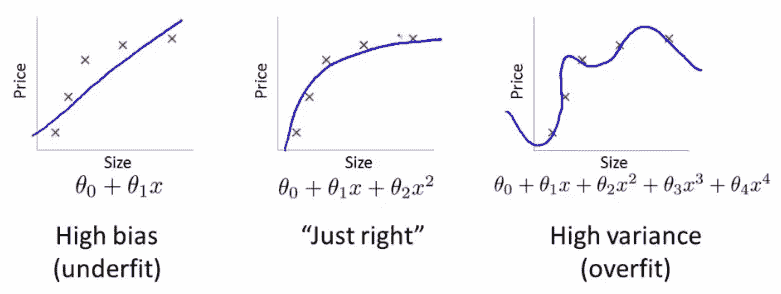
欠拟合和过拟合
图片中数据点的误差对于最右侧的模型最低(蓝色曲线几乎完美地穿过红色点),但这并不是最佳选择。为什么呢?如果您收集一些新的数据点,它们很可能不会在右侧图表中的那条曲线上,而是会更接近中间图表中的曲线。
这说明如何使用所有数据可能导致过拟合。验证集有助于诊断这个问题。
def split_vals(a,n): return a[:n].copy(), a[n:].copy()
n_valid = 12000 # same as Kaggle's test set size
n_trn = len(df)-n_valid
raw_train, raw_valid = split_vals(df_raw, n_trn)
X_train, X_valid = split_vals(df, n_trn)
y_train, y_valid = split_vals(y, n_trn)
X_train.shape, y_train.shape, X_valid.shape
'''
((389125, 66), (389125,), (12000, 66))
'''
基础模型
通过使用验证集,您会发现验证集的 r²为 0.88。
def rmse(x,y): return math.sqrt(((x-y)**2).mean())
def print_score(m):res = [rmse(m.predict(X_train), y_train),rmse(m.predict(X_valid), y_valid),m.score(X_train, y_train), m.score(X_valid, y_valid)]if hasattr(m, 'oob_score_'): res.append(m.oob_score_)print(res)
m = RandomForestRegressor(n_jobs=-1)
%time m.fit(X_train, y_train)
print_score(m)
'''
CPU times: user 1min 3s, sys: 356 ms, total: 1min 3s
Wall time: 8.46 s
[0.09044244804386327, 0.2508166961122146, 0.98290459302099709, 0.88765316048270615]
'''
*[训练集 rmse,验证集 rmse,训练集 r²,验证集 r²]
如果您查看 Kaggle 竞赛的公共榜单,RMSE 为 0.25 的排名将在前 25%左右。随机森林非常强大,这种完全标准化的过程对任何数据集都非常好。
下节课之前
请尝试使用这个过程尽可能多地解决 Kaggle 竞赛。您很可能会惊喜地发现,仅仅一小时的讲座您就能做得相当不错。
机器学习 1:第 2 课
原文:
medium.com/@hiromi_suenaga/machine-learning-1-lesson-2-d9aebd7dd0b0译者:飞龙
协议:CC BY-NC-SA 4.0
来自机器学习课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和 Rachel 给了我这个学习的机会。
随机森林深入研究
笔记本 / 视频
在接下来的几堂课中,我们将研究:
-
随机森林的实际工作原理
-
如果它们不能正常工作该怎么办
-
优缺点是什么
-
我们可以调整什么
-
如何解释结果
Fastai 库是一组实现最先进结果的最佳技术。对于结构化数据分析,scikit-learn 有很多优秀的代码。因此,fastai 的作用是帮助我们将事物转换为 scikit-learn,然后从 scikit-learn 中解释事物。
正如我们所指出的,深入理解评估指标是非常重要的。
均方根对数误差(RMSLE):
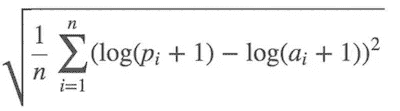

因此,我们取价格的对数并使用均方根误差(RMSE)。
df_raw.SalePrice = np.log(df_raw.SalePrice)
然后我们通过以下方式将数据集中的所有内容转换为数字:
-
add_datepart— 提取日期时间特征Elapsed表示自 1970 年 1 月 1 日以来经过的天数。 -
train_cats— 将string转换为 pandascategory数据类型。然后我们通过运行**proc_df**将分类列替换为类别代码。 -
proc_df还用中位数替换连续列的缺失值,并添加名为[column name]_na的列,并将其设置为 true 以指示它是缺失的。
m = RandomForestRegressor(n_jobs=-1)
m.fit(df, y)
m.score(df, y)
'''
0.98304680998313232
'''
什么是 R²?
Jeremy 的回答

-
yi : 实际/目标数据
-
ȳ : 平均值
-
SStot: 数据变化的程度 -
上周我们想出的最简单的非愚蠢模型是创建一个平均值的列并将其提交给 Kaggle。在这种情况下,RMSE =
SStot(即一个天真模型的 RMSE) -
fi: 预测
-
SSres是实际模型的 RMSE -
如果我们正好像只预测平均值一样有效,
SSres/SStot= 1 并且 R² = 0 -
如果我们完美(即 yi = fi 对于所有情况),
SSres/SStot= 0 并且 R² = 1
R²的可能范围是多少?
正确答案:任何等于或小于 1 的值。如果你为每一行预测无穷大,R² = 1 −∞
因此,当你的 R²为负数时,这意味着你的模型比预测平均值更差。
R² 不一定是你实际尝试优化的内容,但它是一个你可以用于每个模型的数字,你可以开始感受到 0.8 看起来是什么样子,0.9 看起来是什么样子。你可能会发现有趣的是创建具有不同随机噪声量的合成 2D 数据集,并查看它们在散点图上的样子和它们的 R²,以了解它们与实际值有多接近。
R²是你的模型有多好(RMSE)与天真的平均模型有多好(RMSE)之间的比率。
过拟合 [17:33]
在我们的案例中,R²= 0.98 是一个非常好的模型。然而,可能会出现像右边这样的情况:
它擅长运行我们给定的点,但不会很好地运行我们没有给定的点。这就是为什么我们总是希望有一个验证集的原因。
创建验证集是进行机器学习项目时最重要的事情。您需要做的是提出一个数据集,您的模型在该数据集上的得分将代表您的模型在真实世界中的表现如何。
如果您的数据集中有一个时间部分(如蓝皮书比赛中),您可能希望预测未来的价格/价值等。Kaggle 所做的是在训练集中给我们提供代表特定日期范围的数据,然后测试集呈现了训练集中没有的未来日期集。因此,我们需要创建一个具有相同属性的验证集:
def split_vals(a,n): return a[:n].copy(), a[n:].copy()
n_valid = 12000 # same as Kaggle's test set size
n_trn = len(df)-n_valid
raw_train, raw_valid = split_vals(df_raw, n_trn)
X_train, X_valid = split_vals(df, n_trn)
y_train, y_valid = split_vals(y, n_trn)
X_train.shape, y_train.shape, X_valid.shape
'''
((389125, 66), (389125,), (12000, 66))
'''
现在我们有了一个希望看起来像 Kaggle 测试集的东西-足够接近,使用这个将给我们相当准确的分数。我们想要这样做的原因是因为在 Kaggle 上,您只能提交很多次,如果您提交得太频繁,最终您会适应排行榜。在现实生活中,我们希望构建一个在生产中表现良好的模型。
问题:您能解释验证集和测试集之间的区别吗[20:58]?今天我们要学习的一件事是如何设置超参数。超参数是会改变模型行为的调整参数。如果您只有一个保留集(即一个您不用来训练的数据集),并且我们用它来决定使用哪组超参数。如果我们尝试一千种不同的超参数组合,我们可能最终会过拟合到那个保留集。因此,我们要做的是有一个第二个保留集(测试集),在那里我们可以说我已经尽力了,现在就在最后一次,我要看看它是否有效。
您必须实际上从数据中删除第二个保留集(测试集),将其交给其他人,并告诉他们在您承诺完成之前不要让您看到它。否则很难不去看它。在心理学和社会学领域,这被称为复制危机或 P-值调整。这就是为什么我们想要有一个测试集。
问题:我们已经将分类变量转换为数字,但其他模型使用独热编码将其转换为不同的列-应该使用哪种方法[22:55]?我们今天将解决这个问题。
基础模型[23:42]

正如您所看到的,训练集上的 R²为 0.982,验证集上仅为 0.887,这让我们认为我们过拟合得相当严重。但并不是太糟糕,因为 RMSE 为 0.25 会让我们进入比赛的前 25%。
问题:为什么不选择随机行集作为验证集[24:19]?因为如果我们这样做,我们将无法复制测试集。如果您实际上查看测试集中的日期,您会发现这些日期比训练集中的任何日期都要新。因此,如果我们使用一个随机样本作为验证集,那将更容易,因为我们正在预测在这一天的工业设备的价值,而我们已经有了那一天的一些观察结果。一般来说,每当您构建具有时间元素的模型时,您希望您的测试集是一个单独的时间段,因此您确实需要您的验证集也是一个单独的时间段。
问题:最终不会过拟合验证集吗?[25:30] 是的,实际上这就是问题所在。最终可能会在验证集上过拟合,当你在测试集上尝试或提交到 Kaggle 时,结果可能并不好。这在 Kaggle 竞赛中经常发生,他们实际上有第四个数据集,称为私人排行榜集。每次提交到 Kaggle 时,你实际上只会得到在公共排行榜集上的表现反馈,你不知道它们是哪些行。在比赛结束时,你将根据完全不同的数据集进行评判,称为私人排行榜集。避免这种情况的唯一方法是成为一个优秀的机器学习从业者,并尽可能有效地设置这些参数,这部分我们今天和未来几周将会做。
PEP8[27:09]
def rmse(x,y): return math.sqrt(((x-y)**2).mean())
这是一个代码不符合 PEP8 规范的例子。能够用眼睛一次看到某些东西,并随着时间学会立即看出发生了什么具有很大的价值。在数据科学中,始终使用特定的字母或缩写表示特定的含义是有效的。但是如果你在家里面试中测试,要遵循 PEP8 标准。
执行时间[29:29]
如果你加上%time,它会告诉你花了多长时间。经验法则是,如果某个操作花费超过 10 秒,那么用它进行交互式分析就太长了。所以我们要确保事情能在合理的时间内运行。然后当我们一天结束时,我们可以说好了,这个特征工程,这些超参数等都运行良好,我们现在将以大慢精确的方式重新运行它。
加快速度的一种方法是将 subset 参数传递给 proc_df,这将随机抽样数据:
df_trn, y_trn, nas = proc_df(df_raw, 'SalePrice', subset=30000, na_dict=nas
)
X_train, _ = split_vals(df_trn, 20000)
y_train, _ = split_vals(y_trn, 20000)
-
请确保验证集不会改变
-
还要确保训练集与日期不重叠
如上所示,在调用split_vals时,我们没有将结果放入验证集。_表示我们丢弃了返回值。我们希望保持验证集始终相同。
在将训练集重新采样为 30,000 个子集中的前 20,000 个后,运行时间为 621 毫秒。
构建单棵树[31:50]
我们将建立由树组成的森林。让我们从树开始。在 scikit-learn 中,他们不称之为树,而是估计器。
m = RandomForestRegressor(n_estimators=1, max_depth=3,bootstrap=False, n_jobs=-1
)
m.fit(X_train, y_train)
print_score(m)
-
n_estimators=1— 创建只有一棵树的森林 -
max_depth=3— 使其成为一棵小树 -
bootstrap=False— 随机森林会随机化很多东西,我们希望通过这个参数关闭它
这棵小的确定性树在拟合后的 R²为 0.4028,所以这不是一个好模型,但比平均模型好,因为它大于 1,我们实际上可以绘制[33:00]:

一棵树由一系列二进制决策组成。
-
第一行表示二进制分割标准
-
根节点的
samples为 20,000,因为这是我们在拆分数据时指定的。 -
较深的颜色表示较高的
value -
value是价格的对数的平均值,如果我们构建了一个模型,只使用平均值,那么均方误差mse将为 0.495 -
我们能够做出的最佳单一二进制分割结果是
Coupler_system ≤ 0.5,这将使mse在错误路径上提高到 0.109;在正确路径上为 0.414。
我们想要从头开始构建一个随机森林[36:28]。第一步是创建一棵树。创建树的第一步是创建第一个二进制决策。你打算如何做?
-
我们需要选择一个变量和一个值来分割,使得这两个组尽可能不同
-
对于每个变量,对于该变量的每个可能值,看看哪个更好。
-
如何确定哪个更好?取两个新节点的加权平均值
-
得到的模型将类似于平均模型——我们有一个具有单一二进制决策的模型。对于所有
coupler_system大于 0.5 的人,我们将填入 10.345,对于其他人,我们将填入 9.363。然后我们将计算这个模型的 RMSE。
现在我们有一个单一数字来表示一个分割有多好,这个数字是创建这两个组的均方误差的加权平均值。我们还有一种找到最佳分割的方法,就是尝试每个变量和每个可能的值,看哪个变量和哪个值给出了最佳得分的分割。
问题:是否有情况下最好分成 3 组?在一个级别上永远不需要做多次分割,因为你可以再次分割它们。
这就是创建决策树的全部过程。停止条件:
-
当达到所请求的限制(
max_depth) -
当你的叶节点只有一个元素时
让我们的决策树更好
现在,我们的决策树的 R²为 0.4。让我们通过去掉max_depth=3来使其更好。这样做后,训练 R²变为 1(因为每个叶节点只包含一个元素),验证 R²为 0.73——比浅树好,但不如我们希望的那么好。
m = RandomForestRegressor(n_estimators=1, bootstrap=False, n_jobs=-1
)
m.fit(X_train, y_train)
print_score(m)
'''
[6.5267517864504e-17, 0.3847365289469930, 1.0, 0.73565273648797624]
'''
为了让这些树更好,我们将创建一个森林。要创建一个森林,我们将使用一种称为bagging的统计技术。
Bagging
迈克尔·乔丹开发了一种称为小自助袋的技术,他展示了如何对任何类型的模型使用 bagging,使其更加稳健,并为您提供置信区间。
随机森林——一种 bagging 树的方法。
那么什么是 bagging?Bagging 是一个有趣的想法,即如果我们创建了五个不同的模型,每个模型只是有些预测性,但这些模型给出的预测彼此之间没有相关性。这意味着这五个模型对数据中的关系有着截然不同的见解。如果你取这五个模型的平均值,你实际上是将每个模型的见解带入其中。因此,平均模型的这种想法是一种集成技术。
如果我们创建了很多树——大的、深的、过度拟合的树,但每棵树只选择数据的随机 1/10。假设我们这样做了一百次(每次使用不同的随机样本)。它们都过度拟合了,但由于它们都使用不同的随机样本,它们在不同的方面以不同的方式过度拟合。换句话说,它们都有错误,但这些错误是随机的。一堆随机错误的平均值是零。如果我们取这些树的平均值,每棵树都是在不同的随机子集上训练的,那么错误将平均为零,剩下的就是真正的关系——这就是随机森林。
m = RandomForestRegressor(n_jobs=-1)
m.fit(X_train, y_train)
print_score(m)
n_estimators默认为 10(记住,estimators 就是树)。
问题:你是在说我们平均了 10 个糟糕的模型,然后得到了一个好模型吗?确实是这样。因为这些糟糕的模型是基于不同的随机子集,它们的错误之间没有相关性。如果错误是相关的,这种方法就行不通。
这里的关键见解是构建多个比没有好的模型,而且错误尽可能不相关的模型。
要使用的树的数量是我们要调整的第一个超参数,以实现更高的度量。
问题:您选择的子集,它们是互斥的吗?是否可以重叠?[52:27]我们讨论了随机选择 1/10,但 scikit-learn 默认情况下是对n行进行替换选择n行——这称为自助法。如果记忆无误,平均而言,63.2%的行将被表示,其中许多行将多次出现。
机器学习中建模的整个目的是找到一个模型,告诉您哪些变量很重要,它们如何相互作用以驱动您的因变量。在实践中,使用随机森林空间来找到最近邻居与欧几里得空间之间的区别是一个模型做出良好预测和做出无意义预测之间的区别。
有效的机器学习模型能够准确地找到训练数据中的关系,并且能够很好地泛化到新数据[55:53]。在装袋中,这意味着您希望每个单独的估计器尽可能具有预测性,但希望每棵树的预测尽可能不相关。研究界发现,更重要的事情似乎是创建不相关的树,而不是更准确的树。在 scikit-learn 中,还有另一个称为ExtraTreeClassifier的类,它是一种极端随机树模型。它不是尝试每个变量的每个分割,而是随机尝试几个变量的几个分割,这样训练速度更快,可以构建更多的树——更好的泛化。如果您有糟糕的单独模型,您只需要更多的树来获得一个好的最终模型。
提出预测[1:04:30]
preds = np.stack([t.predict(X_valid) for t in m.estimators_])
preds[:,0], np.mean(preds[:,0]), y_valid[0]
'''
(array([ 9.21034, 8.9872 , 8.9872 , 8.9872 , 8.9872 , 9.21034, 8.92266, 9.21034, 9.21034, 8.9872 ]),
9.0700003890739005,
9.1049798563183568)
'''
preds.shape
'''
(10, 12000)
'''
每棵树都存储在名为estimators_的属性中。对于每棵树,我们将使用验证集调用predict。np.stack将它们连接在一起形成一个新轴,因此结果preds的形状为(10, 12000)(10 棵树,12000 个验证集)。对于第一个数据的 10 个预测的平均值为 9.07,实际值为 9.10。正如你所看到的,没有一个单独的预测接近 9.10,但平均值最终相当不错。

这里是给定前i棵树的 R²值的图。随着我们添加更多的树,R²值会提高。但似乎已经趋于平缓。

正如你所看到的,添加更多的树并没有太大帮助。它不会变得更糟,但也不会显著改善事情。这是要学会设置的第一个超参数——估计器的数量。一种设置的方法是,尽可能多地拟合,而且实际上似乎有所帮助。
添加更多的树会减慢速度,但使用更少的树仍然可以获得相同的见解。所以当 Jeremy 构建大部分模型时,他从 20 或 30 棵树开始,项目结束或当天工作结束时,他会使用 1000 棵树并在夜间运行。
袋外(OOB)得分[1:10:04]
有时您的数据集会很小,您不想提取验证集,因为这样做意味着您现在没有足够的数据来构建一个好的模型。然而,随机森林有一个非常聪明的技巧,称为袋外(OOB)误差,可以处理这种情况(以及更多!)
我们可以意识到,在我们的第一棵树中,一些行没有用于训练。我们可以通过第一棵树传递那些未使用的行,并将其视为验证集。对于第二棵树,我们可以通过未用于第二棵树的行,依此类推。实际上,我们将为每棵树创建一个不同的验证集。为了计算我们的预测,我们将对所有未用于训练的行进行平均。如果您有数百棵树,那么很可能所有行都会在这些袋外样本中多次出现。然后,您可以在这些袋外预测上计算 RMSE、R²等。
m = RandomForestRegressor(n_estimators=40, n_jobs=-1, oob_score=True
)
m.fit(X_train, y_train)
print_score(m)
'''
[0.10198464613020647, 0.2714485881623037, 0.9786192457999483, 0.86840992079038759, 0.84831537630038534]
'''
将oob_score设置为 true 将执行此操作,并为模型创建一个名为oob_score_的属性,如您在 print_score 函数中看到的,如果具有此属性,它将在最后打印出来。
问题:oob_score_难道不总是低于整个森林的分数吗[1:12:51]?准确率往往较低,因为在 OOB 样本中,每行出现的树较少,而在完整树集中出现的次数较多。因此,OOB R²会稍微低估模型的泛化能力,但是您添加的树越多,这种低估就越不严重。
在设置超参数时,OOB 分数会派上用场[1:13:47]。我们将设置相当多的超参数,并希望找到一种自动化的方法来设置它们。一种方法是进行网格搜索。Scikit-learn 有一个名为网格搜索的函数,您可以传入要调整的所有超参数的列表以及要尝试的所有这些超参数的值。它将在所有这些超参数的所有可能组合上运行您的模型,并告诉您哪一个是最佳的。OOB 分数是一个很好的选择,可以告诉您哪一个是最佳的。
子采样[1:14:52]
之前,我们取了 30,000 行,并创建了使用该 30,000 行不同子集的所有模型。为什么不每次取一个完全不同的 30,000 子集?换句话说,让我们保留全部 389,125 条记录,如果我们想加快速度,每次选择一个不同的 30,000 子集。因此,而不是对整个行集进行自助抽样,只需随机抽取数据的一个子集。
df_trn, y_trn = proc_df(df_raw, 'SalePrice')
X_train, X_valid = split_vals(df_trn, n_trn)
y_train, y_valid = split_vals(y_trn, n_trn)
set_rf_samples(20000)
set_rf_samples:与之前一样,我们在训练集中使用 20,000 个样本(之前是 30,000,这次是 389,125)。

这将花费与之前相同的时间来运行,但是每棵树都可以访问整个数据集。在使用 40 个估计器后,我们得到了 R²分数为 0.876。
问题:这个 OOB 分数是在哪些样本上计算的[1:18:26]?Scikit-learn 不支持这个功能,因此set_rf_samples是一个自定义函数。因此,在使用set_rf_samples时,需要关闭 OOB 分数,因为它们不兼容。reset_rf_samples()将把它恢复到原来的状态。
最重要的提示[1:20:30]:大多数人总是使用最佳参数在所有时间内在所有数据上运行所有模型,这是毫无意义的。如果您想找出哪些特征重要以及它们之间的关系,那么准确度的第四位小数点根本不会改变您的任何见解。在足够大的样本量上运行大多数模型,使得您的准确度合理(在最佳准确度的合理距离内),并且训练时间短,以便您可以交互式地进行分析。
另外两个参数[1:21:18]
让我们为这个完整集合建立一个基准来进行比较:
reset_rf_samples()
m = RandomForestRegressor(n_estimators=40, n_jobs=-1, oob_score=True
)
m.fit(X_train, y_train)
print_score(m)
'''
[0.07843013746508616, 0.23879806957665775, 0.98490742269867626, 0.89816206196980131, 0.90838819297302553]
'''
这里 OOB 高于验证集。这是因为我们的验证集是不同的时间段,而 OOB 样本是随机的。预测不同时间段要困难得多。
min_sample
m = RandomForestRegressor(n_estimators=40, min_samples_leaf=3, n_jobs=-1, oob_score=True
)
m.fit(X_train, y_train)
print_score(m)
'''
[0.11595869956476182, 0.23427349924625201, 0.97209195463880227, 0.90198460308551043, 0.90843297242839738]
'''
-
min_sample_leaf=3:当叶节点具有 3 个或更少的样本时停止训练树(之前我们一直下降到 1)。这意味着将减少一到两个决策级别,这意味着我们需要训练的实际决策标准数量减半(即更快的训练时间)。 -
对于每棵树,我们不仅仅取一个点,而是取至少三个点的平均值,我们期望每棵树都能更好地泛化。但是每棵树本身的能力会稍微减弱。
-
效果很好的数字是 1、3、5、10、25,但相对于您的整体数据集大小而言。
-
通过使用 3 而不是 1,验证 R²从 0.89 提高到 0.90
max_feature [1:24:07]
m = RandomForestRegressor(n_estimators=40, min_samples_leaf=3, max_features=0.5, n_jobs=-1, oob_score=True
)
m.fit(X_train, y_train)
print_score(m)
'''
[0.11926975747908228, 0.22869111042050522, 0.97026995966445684, 0.9066000722129437, 0.91144914977164715]
'''
-
max_features=0.5:这个想法是,树之间的相关性越小,越好。想象一下,如果有一列比其他所有列更好地预测,那么您构建的每棵树总是从那一列开始。但是可能存在一些变量之间的相互作用,其中该相互作用比单个列更重要。因此,如果每棵树总是首次在相同的内容上分裂,那么这些树的变化就不会很大。 -
除了取一部分行之外,在每个单独的分割点,取不同的列子集。
-
对于行抽样,每棵新树都基于一组随机行,对于列抽样,每个单独的二元分割,我们从不同的列子集中选择。
-
0.5 意味着随机选择其中一半。您可以使用特殊值,如
sqrt或log2 -
使用的好值是
1、0.5、log2或sqrt
0.2286 的 RMSLE 将使我们进入这场比赛的前 20 名——只需使用一些无脑的随机森林和一些无脑的次要超参数调整。这就是为什么随机森林不仅是机器学习的第一步,而且通常是唯一的一步。很难搞砸。
为什么随机森林效果如此好[1:30:21]
让我们看看小单树中的一个分割点。
fiProductClassDesc ≤ 7.5将分割:
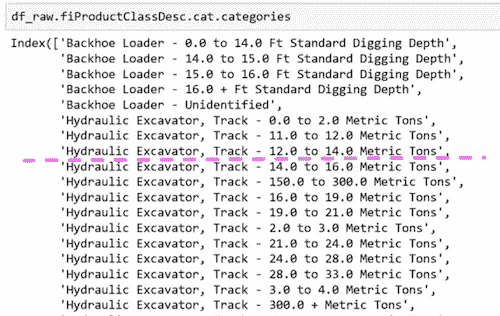
为什么这样做有效呢?想象一下,唯一重要的是液压挖掘机,履带−0.0 到 2.0 公吨,其他都不重要。它可以通过首先分割fiProductClassDesc ≤ 5.5然后fiProductClassDesc > 4.5来选择单个元素。只需两次分割,我们就可以提取出一个单一类别。即使是具有分类变量的树也是无限灵活的。如果有一个具有不同价格水平的特定类别,它可以通过多次分割逐渐缩小到这些组。随机森林非常易于使用,而且非常弹性。
下一课,我们将学习如何分析模型,了解更多关于数据的信息,使其变得更好。
机器学习 1:第 3 课
原文:
medium.com/@hiromi_suenaga/machine-learning-1-lesson-3-fa4065d8cb1e译者:飞龙
协议:CC BY-NC-SA 4.0
来自机器学习课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和 Rachel 给了我这个学习的机会。
今天的课程内容:
笔记本 / 视频
通过使用机器学习更好地理解数据
- 这个想法与常见的说法相反,即随机森林等东西是隐藏我们意义的黑匣子。事实恰恰相反。随机森林让我们比传统方法更深入更快地理解我们的数据。
如何查看更大的数据集
- 拥有超过 1 亿行的数据集 - 杂货销售预测
问题:何时使用随机森林[2:41]?我无法想到任何绝对不会至少有些用处的情况。因此,值得一试。真正的问题可能是在什么情况下我们应该尝试其他方法,简短的答案是对于非结构化数据(图像,声音等),您几乎肯定要尝试深度学习。对于协同过滤模型(杂货竞赛属于这种类型),随机森林和深度学习方法都不是您想要的,您需要做一些调整。
上周回顾[4:42]
读取 CSV 花了一两分钟,我们将其保存为羽毛格式文件。羽毛格式几乎与 RAM 中的格式相同,因此读写速度非常快。我们在第 2 课笔记本中做的第一件事是读取羽毛格式文件。
proc_df 问题[5:28]
在这一周期间提出的一个有趣的小问题是在proc_df函数中。proc_df函数执行以下操作:
-
查找具有缺失值的数值列,并创建一个额外的布尔列,同时用中位数替换缺失值。
-
将分类对象转换为整数代码。
问题#1:您的测试集中可能有一些列中的缺失值,这些列在训练集中不存在,反之亦然。如果发生这种情况,当您尝试进行随机森林时,您将会出现错误,因为“缺失”布尔列出现在训练集中,但不在测试集中。
问题#2:测试集中数值的中位数可能与训练集不同。因此,它可能将其处理为具有不同语义的内容。
解决方案:现在有一个额外的返回变量nas从proc_df,它是一个字典,其键是具有缺失值的列的名称,字典的值是中位数。可选地,您可以将nas作为参数传递给proc_df,以确保它添加这些特定列并使用这些特定中位数:
df, y, nas = proc_df(df_raw, 'SalePrice', nas)
Corporación Favorita 杂货销售预测[9:25]
让我们走一遍当您处理一个真正大的数据集时的相同过程。几乎相同,但有一些情况下我们不能使用默认值,因为默认值运行速度有点慢。
能够解释您正在处理的问题是很重要的。在机器学习问题中理解的关键事项是:
-
独立变量是什么?
-
什么是因变量(您试图预测的东西)?
在这个比赛中
-
因变量 — 在两周期间每天每个商店销售了多少种产品。
-
自变量 — 过去几年每个产品在每个商店每天销售了多少单位。对于每个商店,它的位置在哪里以及它是什么类型的商店(元数据)。对于每种产品,它是什么类别的产品等。对于每个日期,我们有元数据,比如油价是多少。
这就是我们所说的关系数据集。关系数据集是指我们可以将许多不同信息连接在一起的数据集。具体来说,这种关系数据集是我们所说的“星型模式”,其中有一张中心交易表。在这个比赛中,中心交易表是train.csv,其中包含了按日期、store_nbr和item_nbr销售的数量。通过这个表,我们可以连接各种元数据(因此称为“星型”模式 — 还有一种叫做“雪花”模式)。
读取数据[15:12]
types = {'id': 'int64','item_nbr': 'int32','store_nbr': 'int8','unit_sales': 'float32','onpromotion': 'object'
}
%%time df_all = pd.read_csv(f'{PATH}train.csv', parse_dates=['date'], dtype=types, infer_datetime_format=True
)
'''
CPU times: user 1min 41s, sys: 5.08s, total: 1min 46s
Wall time: 1min 48s
'''
-
如果设置
low_memory=False,无论您有多少内存,它都会耗尽内存。 -
为了在读取时限制占用的空间量,我们为每个列名创建一个字典,指定该列的数据类型。您可以通过运行或在数据集上使用
less或head来找出数据类型。 -
通过这些调整,我们可以在不到 2 分钟内读取 125,497,040 行数据。
-
Python 本身并不快,但几乎我们在 Python 中进行数据科学时想要做的一切都已经为我们用 C 或更常见的 Cython 编写好了,Cython 是一种类似 Python 的语言,可以编译成 C。在 Pandas 中,很多代码是用汇编语言编写的,这些代码经过了大量优化。在幕后,很多代码都是调用基于 Fortran 的线性代数库。
问题:指定int64与int是否有任何性能考虑[18:33]?这里的关键性能是使用尽可能少的位数来完全表示列。如果我们对item_nbr使用int8,最大的item_nbr大于 255,将无法容纳。另一方面,如果我们对store_nbr使用int64,它使用的位数比必要的多。鉴于这里的整个目的是避免耗尽 RAM,我们不希望使用比必要多 8 倍的内存。当您处理大型数据集时,很多时候最慢的部分是读取和写入 RAM,而不是 CPU 操作。另外,作为一个经验法则,较小的数据类型通常会运行得更快,特别是如果您可以使用单指令多数据(SIMD)矢量化代码,它可以将更多数字打包到一个单独的矢量中一次运行。
问题:我们不再需要对数据进行洗牌了吗[20:11]?尽管在这里我已经读取了整个数据,但当我开始时,我从不会一开始就读取整个数据。通过使用 UNIX 命令shuf,您可以在命令提示符下获取数据的随机样本,然后您可以直接读取该样本。这是一个很好的方法,例如,找出要使用的数据类型 — 读取一个随机样本,让 Pandas 为您找出。通常情况下,我会尽可能多地在样本上工作,直到我确信我理解了样本后才会继续。
要使用shuf从文件中随机选择一行,请使用-n选项。这将限制输出为指定的数量。您还可以指定输出文件:
shuf -n 5 -o sample_training.csv train.csv
'onpromotion': ‘object' [21:28]— object是一个通用的 Python 数据类型,速度慢且占用内存。原因是它是一个布尔值,还有缺失值,所以我们需要在将其转换为布尔值之前处理它,如下所示:
df_all.onpromotion.fillna(False, inplace=True)
df_all.onpromotion = df_all.onpromotion.map({'False': False, 'True': True
})
df_all.onpromotion = df_all.onpromotion.astype(bool)
%time df_all.to_feather('tmp/raw_groceries')
-
fillna(False): 我们不会在没有先检查的情况下这样做,但一些探索性数据分析显示这可能是一个合适的做法(即缺失值表示 false)。 -
map({‘False’: False, ‘True’: True}):object通常读取为字符串,所以用实际的布尔值替换字符串‘True’和‘False’。 -
astype(bool):最后将其转换为布尔类型。 -
拥有超过 1.25 亿条记录的 feather 文件占用了不到 2.5GB 的内存。
-
现在它以一个很好的快速格式,我们可以在不到 5 秒的时间内将它保存为 feather 格式。
Pandas 通常很快,所以你可以在 20 秒内总结所有 1.25 亿条记录的每一列:
%time df_all.describe(include='all')

-
首先要看的是日期。日期很重要,因为你在实践中放入的任何模型,都会在比你训练的日期晚的某个日期放入。所以如果世界上的任何事情发生变化,你需要知道你的预测准确性也会如何变化。所以对于 Kaggle 或你自己的项目,你应该始终确保你的日期不重叠。
-
在这种情况下,训练集从 2013 年到 2017 年 8 月。
df_test = pd.read_csv(f'{PATH}test.csv', parse_dates = ['date'],dtype=types, infer_datetime_format=True
)
df_test.onpromotion.fillna(False, inplace=True)
df_test.onpromotion = df_test.onpromotion.map({'False': False, 'True': True
})
df_test.onpromotion = df_test.onpromotion.astype(bool)
df_test.describe(include='all')
-
在我们的测试集中,它们从第二天开始直到月底。
-
这是一个关键的事情 —— 除非你理解这个基本的部分,否则你无法真正做出任何有用的机器学习。你有四年的数据,你正在尝试预测接下来的两周。在你能够做好这个工作之前,这是你需要理解的基本事情。
-
如果你想使用一个较小的数据集,我们应该使用最近的 —— 而不是随机的集合。
问题:四年前大约在同一时间段重要吗(例如在圣诞节左右)?确实。并不是说四年前没有有用的信息,所以我们不想完全抛弃它。但作为第一步,如果你要提交平均值,你不会提交 2012 年销售额的平均值,而可能想要提交上个月销售额的平均值。之后,我们可能希望更高权重最近的日期,因为它们可能更相关。但我们应该进行大量的探索性数据分析来检查。
df_all.tail()
这是数据底部的样子。
df_all.unit_sales = np.log1p(np.clip(df_all.unit_sales, 0, None))
-
我们必须对销售额取对数,因为我们正在尝试预测根据比率变化的某些东西,而他们告诉我们,在这个比赛中,均方根对数误差是他们关心的事情。
-
np.clip(df_all.unit_sales, 0, None): 有一些代表退货的负销售额,组织者告诉我们在这个比赛中将它们视为零。clip截断到指定的最小值和最大值。 -
np.log1p:值加 1 的对数。比赛细节告诉你他们将使用均方根对数加 1 误差,因为 log(0)没有意义。
%time add_datepart(df_all, 'date')
'''
CPU times: user 1min 35s, sys: 16.1 s, total: 1min 51s
Wall time: 1min 53s
'''
我们可以像往常一样添加日期部分。这需要几分钟,所以我们应该先在样本上运行所有这些,以确保它有效。一旦你知道一切都是合理的,然后回去在整个集合上运行。
n_valid = len(df_test)
n_trn = len(df_all) - n_valid
train, valid = split_vals(df_all, n_trn)
train.shape, valid.shape
'''
((122126576, 18), (3370464, 18))
'''
这些代码行与我们在推土机比赛中看到的代码行是相同的。我们不需要运行train_cats或apply_cats,因为所有的数据类型已经是数字的了(记住apply_cats将相同的分类代码应用于验证集和训练集)。
%%time
trn, y, nas = proc_df(train, 'unit_sales')
val, y_val, nas = proc_df(valid, 'unit_sales', nas)
调用proc_df来检查缺失值等。
def rmse(x,y): return math.sqrt(((x-y)**2).mean())
def print_score(m):res = [rmse(m.predict(X_train), y_train),rmse(m.predict(X_valid), y_valid),m.score(X_train, y_train), m.score(X_valid, y_valid)]if hasattr(m, 'oob_score_'): res.append(m.oob_score_)print(res)
这些代码行再次是相同的。然后有两个变化:
set_rf_samples(1_000_000)
%time x = np.array(trn, dtype=np.float32)
'''
CPU times: user 1min 17s, sys: 18.9 s, total: 1min 36s
Wall time: 1min 37s
'''
m = RandomForestRegressor(n_estimators=20, min_samples_leaf=100, n_jobs=8
)
%time m.fit(x, y)
我们上周学习了set_rf_samples。我们可能不想从 1.25 亿条记录中创建一棵树(不确定需要多长时间)。你可以从 10k 或 100k 开始,然后找出你可以运行多少。数据集的大小与构建随机森林所需时间之间没有关系,关系在于估计器数量乘以样本大小。
问题: n_job是什么?过去,它总是-1[29:42]。作业数是要使用的核心数。我在一台大约有 60 个核心的计算机上运行这个,如果你尝试使用所有核心,它会花费很多时间来启动作业,速度会变慢。如果你的计算机有很多核心,有时你想要更少(-1表示使用每个核心)。
另一个变化是x = np.array(trn, dtype=np.float32)。这将数据框转换为浮点数组,然后我们在其上进行拟合。在随机森林代码内部,他们无论如何都会这样做。鉴于我们想要运行几个不同的随机森林,使用几种不同的超参数,自己做一次可以节省 1 分 37 秒。
分析器:%prun[30:40]
如果你运行一行需要很长时间的代码,你可以在前面加上%prun。
%prun m.fit(x, y)
-
这将运行一个分析器,并告诉你哪些代码行花费了最多的时间。这里是 scikit-learn 中将数据框转换为 numpy 数组的代码行。
-
查看哪些事情占用了时间被称为“分析”,在软件工程中是最重要的工具之一。但数据科学家往往低估了它。
-
有趣的是,尝试不时运行
%prun在需要 10-20 秒的代码上,看看你是否能学会解释和使用分析器输出。 -
Jeremy 在分析器中注意到的另一件事是,当我们使用
set_rf_samples时,我们不能使用 OOB 分数,因为如果这样做,它将使用其他 124 百万行来计算 OOB 分数。此外,我们希望使用最近日期的验证集,而不是随机的。
print_score(m)
'''
[0.7726754289860, 0.7658818632043, 0.23234198105350, 0.2193243264]
'''
所以这让我们得到了 0.76 的验证均方根对数误差。
m = RandomForestRegressor(n_estimators=20, min_samples_leaf=10, n_jobs=8
)
%time m.fit(x, y)
这使我们降到了 0.71,尽管花了更长的时间。
m = RandomForestRegressor(n_estimators=20, min_samples_leaf=3, n_jobs=8
)
%time m.fit(x, y)
这将错误降低到 0.70。min_samples_leaf=1并没有真正帮助。所以我们在这里有一个“合理”的随机森林。但是这在排行榜上并没有取得好的结果[33:42]。为什么?让我们回头看看数据:

这些是我们必须用来预测的列(以及由add_datepart添加的内容)。关于明天预计销售多少的大部分见解可能都包含在关于商店位置、商店通常销售的物品种类以及给定物品的类别是什么的细节中。随机森林除了在诸如星期几、商店编号、物品编号等方面创建二元分割之外,没有其他能力。它不知道物品类型或商店位置。由于它理解正在发生的事情的能力有限,我们可能需要使用整整 4 年的数据才能得到一些有用的见解。但是一旦我们开始使用整整 4 年的数据,我们使用的数据中有很多是非常陈旧的。有一个 Kaggle 内核指出,你可以做的是[35:54]:
-
看看最后两周。
-
按商店编号、物品编号、促销情况的平均销售额,然后跨日期取平均。
-
只需提交,你就能排在第 30 名左右🎉
我们将在下一堂课上讨论这个问题,但如果你能找出如何从那个模型开始并使其变得更好一点,你将排在第 30 名以上。
问题:您能否尝试通过创建新列来捕捉季节性和趋势效应,比如 8 月份的平均销售额?这是一个很好的主意。要解决的问题是如何做到这一点,因为有一些细节需要正确,这些细节很困难-不是在智力上困难,而是以一种让你在凌晨 2 点撞头的方式困难。
为机器学习编码是非常令人沮丧和非常困难的。如果你弄错了一个细节,很多时候它不会给你一个异常,它只会默默地比原来稍微差一点。如果你在 Kaggle 上,你会知道你的表现不如其他人。但否则,你没有什么可以比较的。你不会知道你的公司模型是否只有它可能的一半好,因为你犯了一个小错误。这就是为什么现在在 Kaggle 上练习是很好的。
你将练习找到所有可能令人恼火地搞砸事情的方法,你会感到惊讶。
即使对于 Jeremy 来说,这些验证集也是非常丰富的。当你开始了解它们是什么时,你将开始知道如何在进行时检查它们。你应该假设你按下的每个按钮都会按错按钮。只要你有一种找出来的方法就可以。
不幸的是,没有一套你应该总是做的具体事情,你只需要考虑一下我即将做的事情的结果。这里有一个非常简单的例子。如果你创建了一个基本的条目,其中你按日期、店铺编号、促销状态取平均值,然后提交了它,并得到了一个合理的分数。然后你认为你有一些稍微好一点的东西,你为此做了预测。你可以创建一个散点图,显示你的平均模型预测在一个轴上,与你的新模型预测在另一个轴上。你应该看到它们几乎形成一条直线。如果不是,那么这非常明显地表明你搞砸了什么。
问题:您多久从其他来源获取数据来补充您已有的数据集?非常频繁。星型模式的整个重点是你有一个中心表,你有其他表与之相连,提供关于它的元数据。在 Kaggle 上,大多数比赛的规则是你可以使用外部数据,只要在论坛上发布并且是公开可用的(双重检查规则!)。在 Kaggle 之外,你应该始终寻找可能利用的外部数据。
问题:如何添加厄瓜多尔的假期来补充数据?这个信息实际上是提供的。一种解决这种问题的一般方法是创建许多新列,其中包含假期销售平均数量,一月和二月之间销售平均百分比变化等。在德国的一个杂货连锁店曾经有一场先前的比赛,几乎是一样的。获胜者是一个领域专家,擅长做物流预测。他根据自己的经验创建了许多列,这些列通常对于做预测是有用的。所以这是一个可以奏效的方法。然而,第三名获奖者几乎没有进行特征工程,而且他们也有一个大的疏忽,这可能导致他们失去第一名。随着比赛的进行,我们将学到更多关于如何赢得这场比赛以及类似比赛的知识。
好的验证集的重要性
如果你没有一个好的验证集,要创建一个好的模型是困难的,甚至是不可能的。如果你试图预测下个月的销售额,并建立模型。如果你无法知道你建立的模型是否擅长提前一个月预测销售额,那么当你将模型投入生产或在测试集上使用时,你就无法知道它是否真的会很好。你需要一个可靠的验证集,告诉你你的模型是否有可能在投入生产或在测试集上使用时表现良好。
通常情况下,你不应该对测试集做任何其他操作,除非在比赛结束时或项目结束时使用它来查看你的表现。但是有一件事你可以在测试集中使用 —— 那就是校准你的验证集[46:02]。
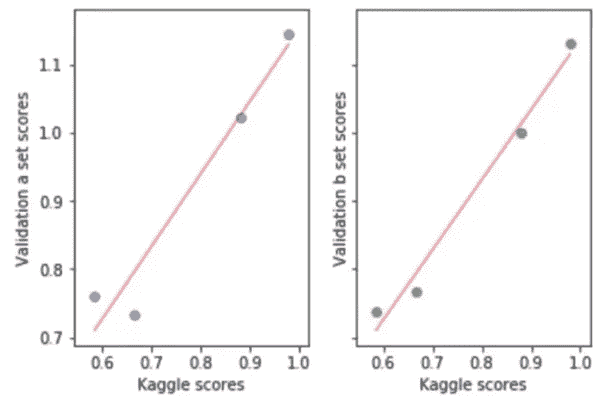
Terrance 在这里做的是建立了四种不同的模型,并将这四种模型分别提交到 Kaggle 上,以找出它们的得分。X 轴是 Kaggle 在排行榜上告诉我们的得分,y 轴是他在一个特定的验证集上绘制的得分,他试图看看这个验证集是否会很好。如果你的验证集很好,那么排行榜得分(即测试集得分)之间的关系应该是一条直线。理想情况下,它将位于y = x线上,但老实说,这并不太重要,只要相对来说告诉你哪些模型比哪些模型更好,那么你就知道哪个模型是最好的。在这种情况下,Terrance 设法找到了一个看起来能够很好地预测 Kaggle 排行榜得分的验证集。这真的很酷,因为他可以尝试一百种不同类型的模型、特征工程、加权、调整、超参数等等,看看它们在验证集上的表现,而不必提交到 Kaggle。因此,你将得到更多的迭代,更多的反馈。这不仅适用于 Kaggle,而且适用于你做的每一个机器学习项目。一般来说,如果你的验证集没有显示出良好的拟合线,你需要仔细思考[48:02]。测试集是如何构建的?我的验证集有什么不同?你将不得不绘制很多图表等等来找出。
**问题:**如何构建一个与测试集尽可能接近的验证集[48:23]?以下是 Terrance 的一些建议:
-
日期接近(即最近的)
-
首先看一下测试集的日期范围(16 天),然后看一下描述如何在排行榜上获得 0.58 分的内核的日期范围(14 天)。
-
测试集从发薪日的第二天开始,到下一个发薪日结束。
-
绘制很多图片。即使你不知道今天是发薪日,你也想绘制时间序列图,希望看到每两周有一个高峰,并确保验证集中有与测试集相同数量的高峰。
解释机器学习模型[50:38 / 笔记本]
PATH = "data/bulldozers/"df_raw = pd.read_feather('tmp/raw')
df_trn, y_trn, nas = proc_df(df_raw, 'SalePrice')
我们首先读取蓝色书籍对推土机比赛的 feather 文件。提醒:我们已经读取了 CSV 文件,将其处理为类别,并保存为 feather 格式。接下来我们调用proc_df将类别转换为整数,处理缺失值,并提取出因变量。然后创建一个像上周一样的验证集:
def split_vals(a,n): return a[:n], a[n:]n_valid = 12000
n_trn = len(df_trn)-n_valid
X_train, X_valid = split_vals(df_trn, n_trn)
y_train, y_valid = split_vals(y_trn, n_trn)
raw_train, raw_valid = split_vals(df_raw, n_trn)
绕道到第 1 课笔记本[51:59]
上周,在proc_df中有一个 bug,当传入subset时会打乱数据框,导致验证集不是最新的 12000 条记录。这个问题已经修复。
## From lesson1-rf.ipynb
df_trn, y_trn, nas = proc_df(df_raw, 'SalePrice', subset=30000, na_dict=nas
)
X_train, _ = split_vals(df_trn, 20000)
y_train, _ = split_vals(y_trn, 20000)
问题:为什么nas既是该函数的输入又是输出[53:03]?proc_df返回一个告诉您哪些列丢失以及每个丢失列的中位数的字典。
-
当您在较大的数据集上调用
proc_df时,不需要传入nas,但您希望保留该返回值。 -
稍后,当您想要创建一个子集(通过传入
subset)时,您希望使用相同的丢失列和中位数,因此您传入nas。 -
如果发现子集来自完全不同的数据集并且具有不同的丢失列,它将使用附加键值更新字典。
-
它会跟踪您在传递给
proc_df的任何内容中遇到的任何丢失列。
回到第 2 课笔记本[54:40]
一旦我们完成了proc_df,它看起来是这样的。SalePrice是销售价格的对数。

我们已经知道如何进行预测。我们在通过每棵树运行特定行后,在每棵树的每个叶节点中取平均值。通常,我们不仅想要一个预测 - 我们还想知道我们对该预测的信心有多大。
如果我们没有看到许多类似这一行的示例,我们对预测会更不自信。在这种情况下,我们不希望任何树都通过 - 这有助于我们预测该行。因此,在概念上,您会期望当您通过不同树传递此不寻常的行时,它会最终出现在非常不同的位置。换句话说,与其只取树的预测平均值并说这是我们的预测,不如我们取树的预测标准差呢?如果标准差很高,这意味着每棵树都为我们提供了对该行预测的非常不同的估计。如果这是一种非常常见的行,树将已经学会为其做出良好的预测,因为它已经看到了许多基于这些行的分割机会。因此,跨树的预测标准差至少让我们相对了解我们对该预测的信心有多大[56:39]。这在 scikit-learn 中不存在,因此我们必须创建它。但我们已经有几乎需要的确切代码。
对于模型解释,没有必要使用完整的数据集,因为我们不需要一个非常准确的随机森林 - 我们只需要一个指示所涉及关系性质的随机森林。
只需确保样本大小足够大,以便如果多次调用相同的解释命令,每次都不会得到不同的结果。在实践中,50,000 是一个很高的数字,如果这还不够的话会令人惊讶(而且运行时间只需几秒)。
set_rf_samples(50000)m = RandomForestRegressor(n_estimators=40, min_samples_leaf=3, max_features=0.5, n_jobs=-1, oob_score=True
)
m.fit(X_train, y_train)
print_score(m)
这里我们可以做与上次完全相同的列表推导[58:35]:
%time preds = np.stack([t.predict(X_valid) for t in m.estimators_])
np.mean(preds[:,0]), np.std(preds[:,0])
'''
CPU times: user 1.38 s, sys: 20 ms, total: 1.4 s
Wall time: 1.4 s**(9.1960278072006023, 0.21225113407342761)
'''
这是针对一个观察结果的方法。这需要相当长的时间,特别是它没有充分利用我的计算机有很多核心这一事实。列表推导本身是 Python 代码,Python 代码(除非您在做一些特殊的事情)运行在串行模式下,这意味着它在单个 CPU 上运行,不利用您的多 CPU 硬件。如果我们想在更多树和更多数据上运行此代码,执行时间会增加。墙上时间(实际花费的时间)大致等于 CPU 时间,否则如果它在许多核心上运行,CPU 时间将高于墙上时间[1:00:05]。
原来 Fast.ai 库提供了一个方便的函数称为parallel_trees:
def get_preds(t): return t.predict(X_valid)
%time preds = np.stack(parallel_trees(m, get_preds))
np.mean(preds[:,0]), np.std(preds[:,0])
'''
CPU times: user 100 ms, sys: 180 ms, total: 280 ms
Wall time: 505 ms**(9.1960278072006023, 0.21225113407342761)
'''
-
parallel_trees接受一个随机森林模型m和要调用的某个函数(这里是get_preds)。这会并行在每棵树上调用此函数。 -
调用该函数对每棵树应用后返回一个结果列表。
-
这将把墙上的时间缩短到 500 毫秒,并给出完全相同的答案。如果时间允许,我们将讨论更一般的编写并行代码的方法,这对数据科学非常有用,但这里有一种我们可以用于随机森林的方法。
绘制[1:02:02]
我们首先将数据复制一份,并将预测的标准差和预测本身(均值)作为新列添加进去:
x = raw_valid.copy()
x['pred_std'] = np.std(preds, axis=0)
x['pred'] = np.mean(preds, axis=0)
x.Enclosure.value_counts().plot.barh();

你可能还记得上一课中我们有一个叫做Enclosure的预测变量,这是一个重要的变量,我们稍后会看到。让我们从做一个直方图开始。Pandas 的一个好处是它具有内置的绘图功能。
问题:你能提醒我围栏是什么吗[01:02:50]?我们不知道它的意思,也不重要。这个过程的整个目的是我们将学习关于事物是什么(或者至少重要的事物,然后弄清楚它们是什么以及它们的重要性)。所以我们一开始对这个数据集一无所知。我们只是要看一下一个叫做Enclosure的东西,里面有一个叫做EROPS和ROPS的东西,我们甚至还不知道这是什么。我们只知道在任何大量出现的情况下,只有OROPS、EROPS w AC和EROPS。这在数据科学家中非常常见。你经常发现自己在看一些你不太熟悉的数据,并且你必须弄清楚哪些部分需要更仔细地研究,哪些部分似乎很重要,等等。在这种情况下,至少知道EROPS AC、NO ROPS和None or Unspecified我们真的不关心,因为它们基本上不存在。所以我们将关注OROPS、EROPS w AC和EROPS。
在这里,我们取了我们的数据框,按Enclosure分组,然后取了 3 个字段的平均值[1:04:00]:
flds = ['Enclosure', 'SalePrice', 'pred', 'pred_std']
enc_summ = x[flds].groupby('Enclosure', as_index=False).mean()
enc_summ
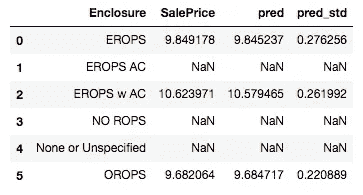
我们已经开始在这里学习一点:
-
预测和销售价格平均接近(好迹象)
-
标准差有些变化
enc_summ = enc_summ[~pd.isnull(enc_summ.SalePrice)]
enc_summ.plot('Enclosure', 'SalePrice', 'barh', xlim=(0,11));
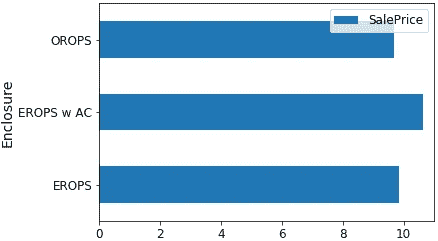
enc_summ.plot('Enclosure', 'pred', 'barh', xerr='pred_std', alpha=0.6, xlim=(0,11)
);
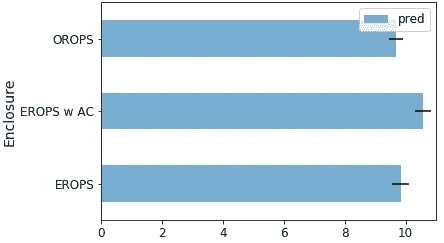
我们使用了上面预测的标准差来绘制误差线。这将告诉我们是否有一些组或一些行我们并不是很有信心。我们可以对产品尺寸做类似的事情:
raw_valid.ProductSize.value_counts().plot.barh();
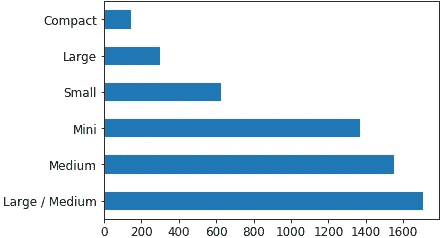
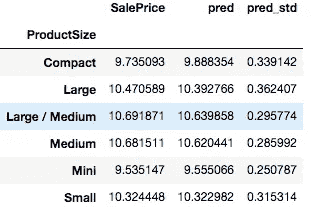
flds = ['ProductSize', 'SalePrice', 'pred', 'pred_std']
summ = x[flds].groupby(flds[0]).mean()
summ
你期望,平均而言,当你预测一个更大的数字时,你的标准差会更高。所以你可以按照预测的标准差与预测本身的比率排序[1:05:51]。
(summ.pred_std/summ.pred).sort_values(ascending=False)
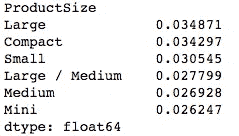
这告诉我们的是产品尺寸Large和Compact,我们的预测不太准确(相对于总价格的比率)。所以如果我们回头看一下,你会明白为什么。这些是直方图中最小的组。正如你所期望的,在小组中,我们的工作效果不太好。
你可以用这个置信区间做两个主要目的:
-
你可以按组查看平均置信区间,以找出你似乎不太有信心的组。
-
也许更重要的是,你可以查看特定行的重要性。当你投入生产时,你可能总是想看到置信区间。例如,如果你正在进行信用评分来决定是否给某人贷款,你可能不仅想知道他们的风险水平,还想知道我们有多大的信心。如果他们想借很多钱,而我们对我们的预测能力毫无信心,我们可能会给他们较小的贷款。
特征重要性 [1:07:20]
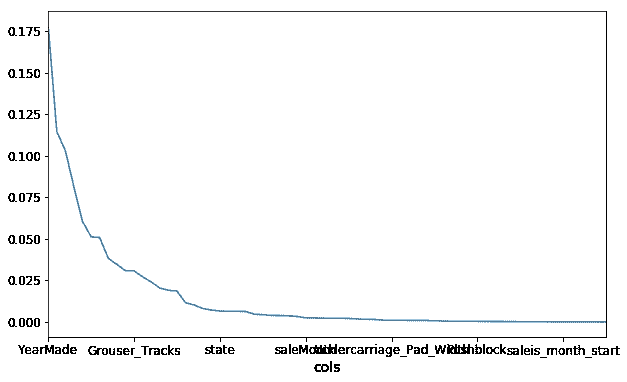
在实践中,我总是首先查看特征重要性。无论我是在参加 Kaggle 竞赛还是在进行真实世界项目,我都会尽快构建一个随机森林,试图让它达到明显优于随机的水平,但不必比那更好太多。接下来我要做的事情是绘制特征重要性。
特征重要性告诉我们在这个随机森林中,哪些列很重要。在这个数据集中有几十列,而在这里,我们挑选出前十个。rf_feat_importance 是 Fast.ai 库的一部分,它接受一个模型 m 和一个数据框 df_trn(因为我们需要知道列的名称),然后会返回一个 Pandas 数据框,按重要性顺序显示每列的重要性。
fi = rf_feat_importance(m, df_trn); fi[:10]

fi.plot('cols', 'imp', figsize=(10,6), legend=False);

由于 fi 是一个 DataFrame,我们可以使用 DataFrame 绘图命令 [1:09:00]。重要的是要看到一些列真的很重要,而大多数列实际上并不重要。在你在现实生活中使用的几乎每个数据集中,你的特征重要性都会是这个样子。只有少数几列是你关心的,这就是为什么 Jeremy 总是从这里开始的原因。在这一点上,就学习这个重型工业设备拍卖领域,我们只需要关心那些重要的列。我们是否要去了解 Enclosure?取决于 Enclosure 是否重要。结果表明它出现在前十名,所以我们需要了解 Enclosure。
我们也可以将其绘制为条形图:
def plot_fi(fi): return fi.plot('cols','imp','barh', figsize=(12,7), legend=False)
plot_fi(fi[:30]);

现在最重要的事情是和你的客户、数据字典,或者任何你的信息来源坐下来,然后说“好的,告诉我关于 YearMade。那是什么意思?它来自哪里?”[1:10:31] 绘制很多东西,比如 YearMade 的直方图和 YearMade 与价格的散点图,尽可能学到更多,因为 YearMade 和 Coupler_System —— 这些才是重要的事情。
在现实项目中经常发生的情况是,你和客户坐在一起,你会说“结果 Coupler_System 是第二重要的事情”,而他们可能会说“这毫无意义”。这并不意味着你的模型有问题,而是意味着他们对他们给你的数据的理解有问题。
让我举个例子。我参加了一个 Kaggle 竞赛,目标是预测大学的资助申请哪些会成功。我使用了这种确切的方法,发现了一些几乎完全预测因变量的列。具体来说,当我查看它们是如何预测的时候,结果是它们是否缺失是数据集中唯一重要的事情。由于这一发现,我最终赢得了那场比赛。后来,我听说了发生了什么。原来在那所大学,填写其他数据库是一项行政负担,因此对于很多资助申请,他们没有为那些未被接受的申请者填写数据库。换句话说,数据集中的这些缺失值表明这笔资助没有被接受,因为如果被接受,行政人员会输入那些信息。这就是我们所说的数据泄漏。数据泄漏意味着在我建模时数据集中有信息,而在大学在做决定时实际上并没有这些信息。当他们实际决定哪些资助申请要优先考虑时,他们不知道行政人员将来会添加信息的哪些申请,因为事实证明它们被接受了。
这里你会发现的一个关键问题是数据泄漏问题,这是一个你需要处理的严重问题。另一个问题是你经常会发现共线性的迹象。就像Coupler_System发生的情况一样。Coupler_System告诉你特定类型的重型工业设备是否具有特定功能。但如果根本不是那种工业设备,它就会缺失。因此,它指示了是否属于某一类重型工业设备。这不是数据泄漏。这是你在正确时间实际拥有的信息。你只需要谨慎解释它。因此,你应该至少查看前 10 个或寻找自然的分界点,并仔细研究这些事情。
为了让生活更轻松,有时候最好抛弃一些数据,看看是否会有任何不同。在这种情况下,我们有一个随机森林,r²为 0.889。在这里,我们筛选出那些重要性等于或小于 0.005 的数据(即只保留重要性大于 0.005 的数据)。
to_keep = fi[fi.imp>0.005].cols; len(to_keep)
df_keep = df_trn[to_keep].copy()
X_train, X_valid = split_vals(df_keep, n_trn)
m = RandomForestRegressor(n_estimators=40, min_samples_leaf=3, max_features=0.5, n_jobs=-1, oob_score=True
)
m.fit(X_train, y_train)
print_score(m)
'''
[0.20685390156773095, 0.24454842802383558, 0.91015213846294174, 0.89319840835270514, 0.8942078920004991]
'''
r²并没有太大变化 - 实际上略微增加了一点。一般来说,删除多余的列不应该使情况变得更糟。如果情况变得更糟,那么这些列实际上并不多余。这可能会使结果略微好一点,因为当决定要分裂时,它需要考虑的事情更少,不太可能偶然发现一个糟糕的列。因此,有稍微更好的机会创建一个稍微更好的树,使用稍微更少的数据,但不会有太大变化。但这会使速度更快,让我们专注于重要的事情。让我们在这个新结果上重新运行特征重要性。
fi = rf_feat_importance(m, df_keep)
plot_fi(fi);
把这个文本翻译成中文。
发生的关键事情是,当你移除冗余列时,你也在移除共线性的来源。换句话说,可能彼此相关的两列。共线性不会使你的随机森林更少预测,但如果 A 列与 B 列稍微相关,而 B 是独立变量的一个强驱动因素,那么重要性将在 A 和 B 之间分配。通过移除一些对结果影响很小的列,使得你的特征重要性图更清晰。之前YearMade与Coupler_System相当接近。但肯定有一堆与YearMade共线的东西,现在你可以看到YearMade真的很重要。这个特征重要性图比之前更可靠,因为它减少了很多共线性,不会让我们感到困惑。
让我们谈谈这是如何运作的[1:17:21]
这不仅非常简单,而且是一种你可以用于任何类型的机器学习模型的技术。有趣的是,几乎没有人知道这一点。许多人会告诉你,没有办法解释这种特定类型的模型(模型的最重要解释是知道哪些因素是重要的),这几乎肯定不会是真的,因为我要教给你的技术实际上适用于任何类型的模型。

-
我们拿我们的推土机数据集,我们有一个列
Price我们正在尝试预测(因变量)。 -
我们有 25 个自变量,其中之一是
YearMade。 -
我们如何确定
YearMade有多重要?我们有一个完整的随机森林,我们可以找出我们的预测准确性。因此,我们将把所有这些行通过我们的随机森林,它将输出一些预测。然后我们将它们与实际价格进行比较(在这种情况下,我们得到我们的均方根误差和 r²)。这是我们的起点。 -
让我们做完全相同的事情,但这次,拿
YearMade列并随机洗牌它(即随机排列只是那一列)。现在YearMade与之前完全相同的分布(相同的均值,相同的标准差)。但它与我们的因变量没有任何关系,因为我们完全随机重新排序了它。 -
之前,我们可能发现我们的 r²是 0.89。在我们洗牌
YearMade之后,我们再次检查,现在 r²是 0.80。当我们破坏那个变量时,得分变得更糟了。 -
好的,让我们再试一次。我们把
YearMade恢复到原来的状态,这次让我们拿Enclosure来洗牌。这次,r²是 0.84,我们可以说YearMade得分减少了 0.09,而Enclosure的得分减少了 0.05。这将为我们提供每一列的特征重要性。
问题:我们不能只排除这一列然后检查性能的下降吗[1:20:31]?你可以删除该列并训练一个全新的随机森林,但那将会非常慢。而通过这种方式,我们可以保留我们的随机森林,再次测试其预测准确性。因此,相比之下,这种方式更快速。在这种情况下,我们只需将每个洗牌列的每一行再次通过森林运行一遍。
问题:如果你想做多重共线性,你会做两个然后随机洗牌,然后三个[1:21:12]?我认为你不是指多重共线性,我认为你是指寻找交互效应。因此,如果你想知道哪些变量对是最重要的,你可以依次对每对变量做完全相同的事情。实际上,有更好的方法来做到这一点,因为显然这在计算上是非常昂贵的,所以如果可能的话,我们将尝试找时间来做到这一点。
我们现在有一个稍微更准确的模型,我们对它了解更多。所以我们时间不够了,我建议你在下一堂课之前尝试做的是,查看前 5 或 10 个预测变量,尝试学习如何在 Pandas 中绘制图表,并尝试回来带一些关于以下事项的见解:
-
YearMade和因变量之间的关系是什么 -
YearMade的直方图是什么样的 -
现在你知道
YearMade非常重要,检查一下这一列中是否有一些噪音,我们可以修复。 -
检查一下这一列中是否有一些奇怪的编码问题,我们可以修复。
-
Jeremy 提出的这个想法,也许
Coupler_System完全存在是因为它与其他某些东西共线,你可能想要尝试弄清楚这是否属实。如果是这样,你会怎么做呢? -
fiProductClassDesc这个让人警惕的名字——听起来可能是一个高基数分类变量。它可能是一个有很多级别的东西,因为它听起来像是一个型号名称。所以去看看那个型号名称——它有一定的顺序吗?你能把它变成一个有序变量吗?它在字符串中有一些层次结构,我们可以通过连字符拆分它来创建更多的子列。
想一想这个问题。试着让你回来时,你有一些新的,最好是比我刚刚展示的更准确的东西,因为你找到了一些新的见解,或者至少你可以告诉班上一些你学到的有关重型工业设备拍卖的实际工作方式的事情。
机器学习 1:第 4 课
原文:
medium.com/@hiromi_suenaga/machine-learning-1-lesson-4-a536f333b20d译者:飞龙
协议:CC BY-NC-SA 4.0
来自机器学习课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和 Rachel 给了我这个学习的机会。
在开始之前有一个问题:我们能否总结随机森林的超参数与过拟合、处理共线性等之间的关系?绝对可以。回到第 1 课笔记本。
感兴趣的超参数:
- 设置 _rf_samples
-
确定每棵树中有多少行。因此,在我们开始新树之前,我们要么对整个数据进行自助抽样(即有放回地抽样),要么从中抽取较少行数的子样本,然后从中构建一棵树。
-
第一步是我们有一个完整的大数据集,我们随机抽取几行数据,并将它们转换成一个较小的数据集。然后,我们构建一棵树。
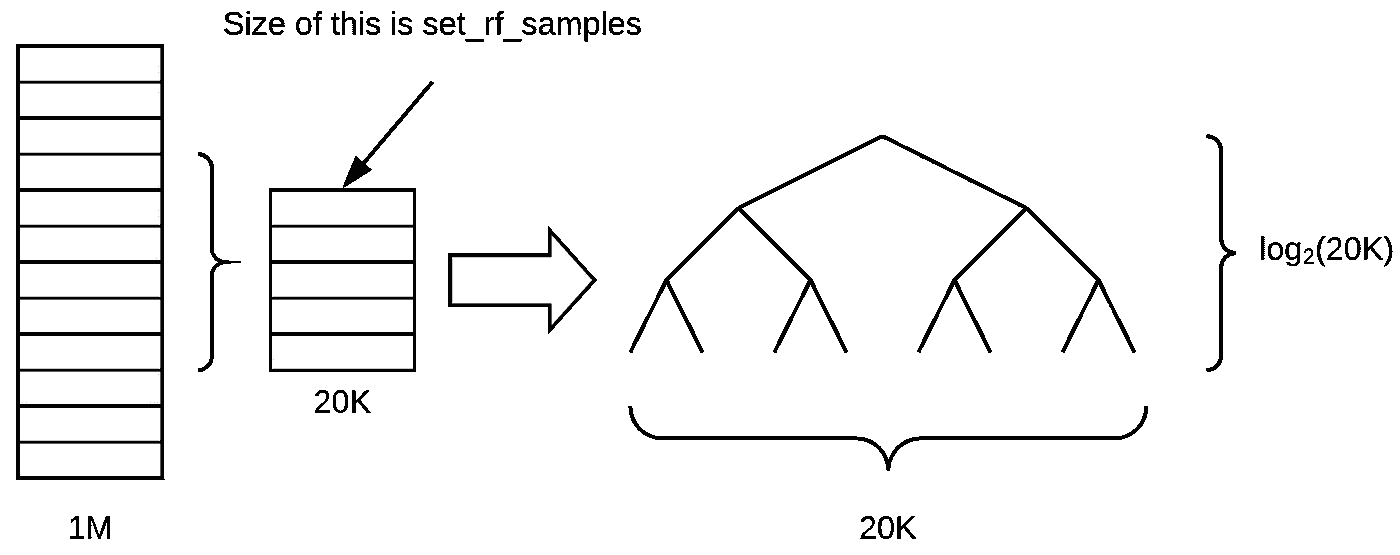
-
假设树在我们生长过程中保持平衡,这棵树将有多少层深(假设我们生长到每个叶子的大小为一)?log2(20000)。树的深度实际上并不会因为样本数量的不同而变化太大,因为它与大小的对数相关。
-
当我们一直走到底部时,会有多少叶节点?20K。叶节点的数量与样本大小之间存在线性关系。因此,当你减少样本大小时,可以做出的最终决策就会减少。因此,树在预测方面会变得不那么丰富,因为它做出的个别决策更少,也做出更少的二元选择来达到这些决策。
-
将 RF 样本设置较低意味着过拟合的可能性较小,但也意味着每个单独的树模型的准确性会降低。随机森林的发明者 Breiman 描述了这一点,即在使用装袋法构建模型时,你要做两件事情。一是确保每个单独的树/估计器尽可能准确(因此每个模型都是一个强预测模型)。但是在估计器之间,相关性要尽可能低,这样当将它们平均在一起时,你会得到一个泛化的模型。通过降低
set_rf_samples的数量,实际上是降低了估计器的能力并增加了相关性,那么这会对你的验证集结果产生更好还是更差的影响呢?这取决于情况。这就是在进行机器学习模型时必须要考虑的妥协。
关于oob=True的问题[6:46]。oob=True的作用就是说,无论你的子样本是什么(可能是一个自助采样或一个子样本),将所有其他行(对于每棵树)放入一个不同的数据集中,并计算这些行的错误。因此,它实际上并不影响训练。它只是给你一个额外的度量,即 OOB 错误。因此,如果你没有验证集,那么这允许你免费获得一种准验证集。
问题:如果我不执行set_rf_samples,那会被称为什么?默认情况是,如果你说reset_rf_samples,那会导致引导,因此它将对原始数据集进行重新采样,但是会有替换。
set_rf_samples的第二个好处是你可以更快地运行。特别是当你在一个非常庞大的数据集上运行,比如一亿行,就不可能在完整的数据集上运行。所以你要么在开始之前自己选择一个子样本,要么使用set_rf_samples。
min_samples_leaf[8:48]
之前,我们假设min_samples_leaf=1,如果设置为 2,树的新深度为log2(20000)-1。每次将min_samples_leaf加倍,我们都会从树中移除一层,并将叶节点数量减半(即 10k)。增加min_samples_leaf的结果是现在每个叶节点中都有多于一个元素,因此我们在每棵树中计算的平均值会更加稳定。我们的深度稍微减少(即我们需要做出的决策更少),叶节点数量也减少。因此,我们预期每个估算器的结果会更少预测性,但估算器之间的相关性也会减少。这可能有助于我们避免过拟合。
问题:我不确定每个叶节点是否一定会有两个节点。不,不一定会有两个。不均匀分裂的例子,比如一个叶节点包含 100 个项目,当它们在因变量方面都相同时(假设是这样,但更有可能是因变量)。所以,如果你到达一个叶节点,每一个都有相同的拍卖价格,或者在分类中每一个都是一只狗,那么你无法进行任何可以改善你的信息的分裂。记住,“信息”是我们在随机森林中使用的一个术语,用来描述我们从分裂中创造的额外信息的差异量,我们通过分裂改善模型的程度。所以你经常会看到这个词“信息增益”,意思是通过添加额外的分裂点,模型变得更好了多少,这可能基于 RMSE 或交叉熵或与标准差的差异等。
这就是我们可以做的第二件事情。这将加快我们的训练速度,因为它少了一组决策要做。尽管少了一组决策,但这些决策的数据量与之前的一样多。因此,树的每一层可能比前一层花费的时间多一倍。因此,它肯定可以加快训练速度并且泛化得更好。
3. max_features [12:22]
在每次分裂时,它会随机抽样列(与set_rf_samples选择每棵树的行子集相对)。听起来是一个小的区别,但实际上这是一种完全不同的思考方式。我们使用set_rf_samples来提取我们的子样本或自举样本,并将其保留整个树中,其中包含所有列。使用max_features=0.5,在每次分裂时,我们会选择不同的一半特征。我们这样做的原因是因为我们希望树尽可能丰富。特别是,如果您只做了少量的树(例如 10 棵树),并且在整个树中选择了相同的列集,那么您实际上并没有获得太多不同种类的发现。因此,这种方式,至少在理论上,似乎会通过在每个决策点处选择不同的随机特征子集来给我们提供更好的树集。
max_features 的整体效果是相同的 - 这意味着每棵单独的树可能会更不准确,但树的变化会更多。特别是在这里,这可能是至关重要的,因为想象一下,你有一个特征是非常具有预测性的。它是如此具有预测性,以至于你查看的每个随机子样本总是从相同的特征开始分裂,那么这些树在某种意义上将非常相似,因为它们都具有相同的初始分裂。但可能会有一些其他有趣的初始分裂,因为它们会创建不同的变量交互。因此,有一半的时间该特征甚至不会出现在树的顶部,至少有一半的树会有不同的初始分裂。这绝对可以给我们更多的变化,因此可以帮助我们创建更具一般性的树,这些树之间的相关性更小,即使单独的树可能不会那么具有预测性。
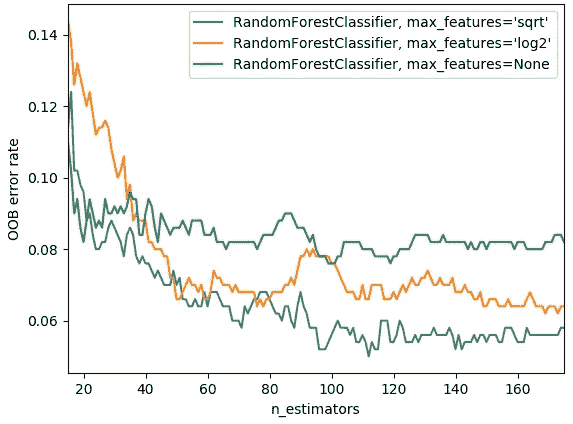
在实践中,当你添加更多的树时,如果你设置max_features=None,那么每次都会使用所有的特征。然后在很少的树的情况下,这仍然可以给你一个相当不错的误差。但是随着你创建更多的树,它不会帮助太多,因为它们都很相似,它们都在尝试每一个变量。另外,如果你设置max_features=sqrt或log2,那么随着我们添加更多的估计器,我们会看到改进,所以这两者之间存在有趣的互动。上面的图表来自 scikit-learn 文档。
4. 完全不影响我们训练的事情
n_jobs:简单地指定我们运行在多少个 CPU 或核心上,因此在某种程度上会使其更快。一般来说,将其设置为超过 8 个左右,可能会有递减的回报。-1 表示使用所有核心。默认使用一个核心似乎有点奇怪。通过使用更多核心,您肯定会获得更好的性能,因为现在大多数计算机都有多个核心。
oob_score=True: 这只是让我们看到 OOB 得分。如果你将 set_rf_samples 设置得相对较小,而数据集很大,OOB 将需要很长时间来计算。希望在某个时候,我们能够修复库,使其不再发生这种情况。没有理由需要那样,但目前,库就是这样工作的。
所以它们是我们可以更改的关键基本参数。您可以在文档中查看更多内容,或者按shift+tab查看它们,但您已经看到的是我发现有用的,可以随意尝试其他参数。一般来说,这些值效果很好。
max_features: None, 0.5, sqrt, log2
min_samples_leaf : 1, 3, 5, 10, 25, 100… 随着增加,如果你注意到当你达到 10 时,情况已经变得更糟,那么继续下去就没有意义了。如果你达到 100 时情况仍在好转,那么你可以继续尝试。
随机森林解释 [18:50]
随机森林解释是你可以用来创建一些非常酷的 Kaggle 内核的东西。基于树方差的置信度是其他地方不存在的。特征重要性肯定存在,并且已经在许多 Kaggle 内核中。如果你正在看一个竞赛或一个数据集,没有人做过特征重要性,成为第一个这样做的人总是会赢得很多票,因为最重要的是哪些特征是重要的。
基于树方差的置信度
正如我所提到的,当我们进行模型解释时,我倾向于将set_rf_samples设置为某个子集——足够小,可以在不到 10 秒内运行一个模型,因为运行一个超级准确的模型没有意义。五万个样本已经足够了,每次运行解释时,你会得到相同的结果,只要这是真的,那么你已经在使用足够的数据了。
set_rf_samples(50000)
m = RandomForestRegressor(n_estimators=40, min_samples_leaf=3, max_features=0.5, n_jobs=-1, oob_score=True
)
m.fit(X_train, y_train)
print_score(m)
特征重要性
我们学到它是通过随机洗牌一列,每次一列,然后看看在将所有数据传递给预训练模型时,当其中一列被洗牌时,模型的准确性如何。
课后我收到的一些问题让我想起,很容易低估这种方法有多么强大和神奇。为了解释,我会提到我听到的一些问题。
一个问题是“如果我们一次只取一列,然后在那一列上创建一棵树会怎样”。然后我们会看到哪一列的树是最具预测性的。为什么这可能会导致关于特征重要性的误导性结果?我们将失去特征之间的相互作用。如果我们只是随机打乱它们,那么会增加随机性,我们就能捕捉到特征之间的相互作用和重要性。这种相互作用的问题并不是一个细枝末节。它非常重要。想想这个推土机数据集,例如,有一个字段叫做“制造年份”,另一个字段叫做“销售日期”。如果我们想一想,很明显重要的是这两者的组合。换句话说,两者之间的区别是设备在售出时的年龄。因此,如果我们只包含其中一个,我们将严重低估该特征的重要性。现在,这里有一个非常重要的观点。如果你事先知道你需要哪些变量,它们如何相互作用,以及它们需要如何转换,那么几乎总是可以创建一个简单的逻辑回归,它和几乎任何随机森林一样好。在这种情况下,例如,我们可以创建一个新字段,它等于销售年份减去制造年份,然后将其输入模型并为我们获取该相互作用。但关键是,我们永远不知道这一点。你可能会猜测 — 我认为其中一些事物是以这种方式相互作用的,我认为这个东西我们需要取对数,等等。但事实是,世界运作的方式,因果结构,有许多许多事物以许多微妙的方式相互作用。这就是为什么使用树,无论是梯度提升机还是随机森林,都能够如此出色地工作。
Terrance 的评论: 多年前咬我一口的一件事也是我尝试一次只处理一个变量,认为“哦,好吧,我会弄清楚哪个与因变量最相关”[24:45]。但它没有分开的是,如果所有变量基本上都是复制的同一个变量,那么它们看起来都同样重要,但实际上只是一个因素。
这在这里也是正确的。如果我们有一列出现两次,那么对该列进行洗牌不会使模型变得更糟。如果你考虑它是如何构建的,特别是如果我们设置了max_features=0.5,有时我们会得到列的版本 A,有时我们会得到列的版本 B。因此,一半的时间,对列的版本 A 进行洗牌会使树变得稍微糟糕,一半的时间对列的版本 B 进行洗牌会使其稍微糟糕,因此它将显示这两个特征都有一定重要性。它将在这两个特征之间共享重要性。这就是为什么“共线性”(我写的是共线性,但它意味着它们是线性相关的,所以这不太对)——但这就是为什么拥有两个彼此密切相关的变量或更多彼此密切相关的变量意味着您经常会低估它们在使用这种随机森林技术时的重要性。
问题:一旦我们洗牌并获得一个新模型,这些重要性的单位究竟是什么?这是否是 R²的变化?这取决于我们使用的库。所以这些单位有点像……我从来没有考虑过它们。我只知道在这个特定的库中,0.005 经常是我倾向于使用的一个截止值。但我真正关心的是这张图片(每个变量的特征重要性排序):
然后放大,将其转换为条形图,然后找到其变平的地方(约 0.005)。

所以我在那时将它们移除,并检查验证分数没有变差。
to_keep = fi[fi.imp>0.005].cols; len(to_keep)
如果情况变得更糟,我只需稍微降低截止值,直到情况不再恶化。因此,这个度量单位并不太重要。顺便说一下,我们以后会学习另一种计算变量重要性的方法。
移除它们的目的是什么?在查看我们的特征重要性图后,我们发现小于 0.005 的那些是无聊的长尾。所以我说让我们尝试只选择大于 0.005 的列,创建一个名为df_keep的新数据框,其中只包含那些保留的列,创建一个只包含这些列的新训练和验证集,创建一个新的随机森林,并查看验证集得分。验证集的 RMSE 发生了变化,变得更好了一点。所以如果它们大致相同或稍微好一点,那么我的想法是这是一个同样好的模型,但现在更简单。
因此,当我重新进行特征重要性分析时,相关性较小。在这种情况下,我发现制造年份从略优于下一个最好的特征(连接器系统)变得更好了,但现在它更好了。因此,它似乎确实改变了这些特征的重要性,并希望能给我一些更多的见解。
问题:那么这如何帮助我们的模型呢?我们现在要深入研究这个问题。基本上,它告诉我们,例如,如果我们正在寻找如何处理缺失值,数据中是否有噪音,如果是高基数分类变量——这些都是我们会采取的不同步骤。例如,如果原来是一个字符串的高基数分类变量,也许在上面的情况下是 fiProductClassDesc,我记得我们前几天看的一个,首先是车辆类型,然后是一个连字符,然后是车辆的大小。我们可能会看到这个并说“好的,这是一个重要的列。让我们尝试在连字符上分割它成两部分,然后取那部分,即它的大小,并解析它并转换为整数。”我们可以尝试进行一些特征工程。基本上,直到你知道哪些是重要的,你就不知道在哪里集中特征工程的时间。你可以与负责创建这些数据的客户或相关人员交谈。如果你实际上在一个推土机拍卖公司工作,你现在可能会去找实际的拍卖人,说“我真的很惊讶,连接器系统似乎对人们的定价决策产生了如此大的影响。你认为这可能是为什么?”他们可能会告诉你“哦,实际上是因为只有这些类别的车辆有连接器系统,或者只有这个制造商有连接器系统。所以实际上这并不是告诉你关于连接器系统的,而是关于其他事情。哦,嘿,这让我想起来,我们实际上还测量了其他东西。它在另一个不同的 CSV 文件中。我去拿给你。”所以它帮助你集中注意力。
问题:所以你知道,这个周末我遇到了一个有趣的小问题。我在我的随机森林中引入了一些疯狂的计算,突然间它们就像是哦,这些是最重要的变量,压制了其他所有变量。但是我得到了一个糟糕的分数,那是因为我现在认为我的分数计算正确了吗,我注意到重要性飙升了,但验证集仍然很糟糕,甚至更糟。这是因为某种计算方式让训练几乎像一个标识符映射到了训练答案,但当然这并不能推广到验证集。这就是我观察到的吗?你的验证分数可能不太好的两个原因。

所以我们得到了这五个数字:训练的 RMSE,验证的 RMSE,训练的 R²,验证的 R²和 OOB 的 R²。最终我们关心的是这个 Kaggle 竞赛的验证集的 RMSE,假设我们已经创建了一个好的验证集。Terrance 的情况,他说当我进行一些特征工程时,验证的 RMSE 变糟了。为什么呢?有两个可能的原因。
-
原因一是你过拟合了。如果你过拟合了,那么你的 OOB 也会变得更糟。如果你在一个大数据集上使用了一个小的
set_rf_samples,以至于无法使用 OOB,那么可以创建一个第二个验证集,这个验证集是一个随机样本。换句话说,如果你的 OOB 或者随机样本验证集变得更糟,那么你一定是过拟合了。我认为在你的情况下,Terrance,这不太可能是问题,因为随机森林不会过拟合得那么严重。除非你使用一些非常奇怪的参数,比如只有一个估计器,否则很难让它们过拟合得那么严重。一旦我们有了十棵树,应该有足够的变化,你肯定可以过拟合,但不会过度到添加一个变量就破坏你的验证分数。所以我认为你会发现这可能不是问题,但很容易检查。如果不是这种情况,那么你会发现你的 OOB 分数或者随机样本验证分数并没有变得更糟。 -
如果您的验证分数变差的第二个原因是,如果您的 OOB 分数没有变差,那么您并没有过拟合,但是您的验证分数变差了,这意味着您在训练集中做了一些在验证集中不成立的事情。因此,这种情况只会发生在您的验证集不是随机抽样的情况下。例如,在这个推土机比赛或者杂货购物比赛中,我们故意制作了一个验证集,该验证集涵盖了不同的日期范围——最近的两周。因此,如果在最近两周发生了与之前几周不同的事情,那么您可能会完全破坏您的验证集。例如,如果有一种在两个日期段中不同的唯一标识符,那么您可能会学会在训练集中使用该标识符来识别事物。但是最近的两周可能有完全不同的 ID 集或不同的行为集,这可能会变得更糟。尽管您所描述的情况并不常见。所以我有点怀疑——这可能是一个错误,但希望您现在有足够的方法来确定是否是一个错误。我们将很乐意听到您学到了什么。
线性回归,逻辑回归
这就是特征重要性。我想将其与在机器学习之外的行业和学术界(如心理学、经济学等)通常进行的特征重要性比较一下。一般来说,在这些环境中,人们倾向于使用某种线性回归、逻辑回归、一般线性模型等方法。他们从数据集开始,然后说我要假设我知道自己的自变量和因变量之间的参数关系。所以我要假设这是一个线性关系或者一个带有链接函数(如 sigmoid)的线性关系,从而创建逻辑回归。所以假设我已经知道了这一点,我现在可以将其写成一个方程。所以如果你有 x1、x2 等等。
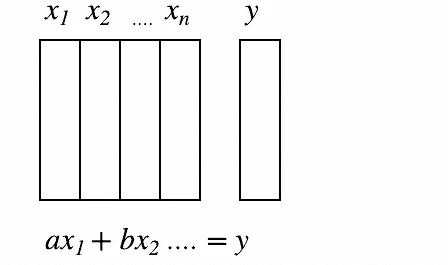
我可以说我的 y 值等于ax1 + bx2 = y,因此我可以通过查看这些系数并看到哪个最高来很容易地找出特征的重要性,特别是如果您首先对数据进行了归一化。有一个常见的误解是,这种方法在某种程度上更准确,更纯粹,更好,但事实并非如此。如果您考虑一下,如果您缺少一个交互作用,如果您缺少所需的转换,或者如果您在任何预处理方面不完美,以至于您的模型是情况的绝对正确真相 - 除非您全部正确,否则您的系数是错误的。您的系数告诉您“在您完全错误的模型中,这些事物有多重要”,这基本上是毫无意义的。而另一方面,随机森林的特征重要性告诉您,在这种极高参数、高度灵活的函数形式中,几乎没有任何统计假设,这是您的特征重要性。所以我会非常谨慎。
再次强调,当您离开这个程序时,您更多地会看到人们谈论逻辑回归系数,而不是随机森林变量重要性。每当您看到这种情况发生时,您应该非常怀疑您所看到的内容。每当您阅读经济学或心理学的论文,或者市场营销部门告诉您这种回归或其他内容时,这些系数都会受到模型中任何问题的严重偏见。此外,如果他们进行了大量的预处理,实际上模型相当准确,那么现在您看到的系数将会像来自 PCA 的某个主成分的系数或某个集群的某个距离的系数。在这种情况下,它们非常难以解释。它们不是实际的变量。所以这是我看到的人们尝试使用经典统计技术来进行等效变量重要性时的两种选择。我认为事情开始慢慢改变。有一些领域开始意识到这完全是错误的做法。但自从随机森林出现以来已经将近 20 年了,所以需要很长时间。人们说,只有当上一代人死去时,知识才会真正进步,这在某种程度上是真的。特别是学者,他们以擅长某个特定子领域而成为职业,通常直到下一代人出现时,人们才会注意到实际上这不再是一个好的做事方式。我认为这就是这里发生的事情。
我们现在有一个模型,从预测准确性的角度来看并没有更好,但我们有一种很好的感觉,似乎有四个主要重要的因素:YearMade,Coupler_System,ProductSize,fiProductClassDesc。
一热编码
然而,我们还可以做另一件事,那就是我们可以做一种称为独热编码的东西。这就是我们在谈论分类变量时所说的。记住,分类变量,假设我们有一个字符串高、低、中(我们得到的顺序有点奇怪——默认按字母顺序排列)。所以我们将其映射为 0、1、2。当它进入我们的数据框时,现在它是一个数字,因此随机森林不知道它最初是一个类别——它只是一个数字。因此,当构建随机森林时,它基本上会说它是否大于 1 或不大于 1。或者它是否大于 0 或不大于 0。这基本上是它可以做出的两个可能决定。对于有 5 或 6 个级别的东西,可能只有一个类别级别是有趣的。也许唯一重要的是它是否未知。也许不知道它的大小会以某种方式影响价格。因此,如果我们想要能够识别这一点,特别是如果恰好数字编码的方式是未知的最终出现在中间,那么它将需要两次分割才能看到实际上重要的是未知的事情。因此,这有点低效,我们正在浪费树的计算。浪费树的计算很重要,因为每次我们进行分割时,我们至少要减少一半的数据量来进行更多的分析。因此,如果我们没有以方便它进行所需工作的方式提供数据,那么我们的树将变得不那么丰富和有效。
我们可以做的是为每个类别创建 6 列,每列包含 1 和 0。在我们的数据集中添加了 6 列后,随机森林现在可以选择其中一列并说“哦,让我们看看 is_unknown”。我可以做一个可能的拟合,即 1 对 0。让我们看看这是否有效。因此,它现在可以在一个步骤中提取一个类别级别,并且这种编码称为独热编码。对于许多类型的机器学习模型,这样的东西是必要的。如果你正在进行逻辑回归,你不可能放入一个分类变量,它经过 0 到 5,因为显然它与任何东西之间没有线性关系。因此,许多人错误地认为所有机器学习都需要独热编码。但在这种情况下,我将向您展示如何可以选择使用它,并查看它是否有时可能会改善事情。
问题:如果我们有六个类别,就像在这种情况下一样,为每个类别添加一列会有什么问题吗?在线性回归中,如果有六个类别,我们应该只对其中五个进行操作。你当然可以说,让我们不要担心添加is_medium,因为我们可以从其他五个中推断出来。我会建议无论如何都要包括它,因为否则,随机森林就必须做出五个决定才能到达那一点。你不包括一个在线性模型中的原因是因为线性模型讨厌共线性,但在这里我们不在乎这个。
因此,我们可以很容易地进行独热编码,我们的做法是向proc_df传递一个额外的参数,即最大类别数(max_n_cat)。因此,如果我们说是七,那么任何级别少于七的东西都将被转换为一组独热编码的列。
df_trn2, y_trn, nas = proc_df(df_raw, 'SalePrice', max_n_cat=7)
X_train, X_valid = split_vals(df_trn2, n_trn)
m = RandomForestRegressor(n_estimators=40, min_samples_leaf=3, max_features=0.6, n_jobs=-1, oob_score=True
)
m.fit(X_train, y_train)
print_score(m)
'''
[0.2132925755978791, 0.25212838463780185, 0.90966193351324276, 0.88647501408921581, 0.89194147155121262]
'''
例如邮政编码有超过六个级别,因此将保留为数字。一般来说,您显然不希望对邮政编码进行独热编码,因为这只会创建大量数据、内存问题、计算问题等。因此,这是您可以尝试的另一个参数。
所以如果我尝试一下,像往常一样运行随机森林,你可以看到验证集的 R²和验证集的 RMSE 会发生什么变化。在这种情况下,我发现它变得稍微糟糕了。这并不总是这样,这将取决于你的数据集。这取决于你的数据集是否有单个类别往往相当重要。在这种特殊情况下,它并没有使预测更准确。然而,它所做的是我们现在有了不同的特征。proc_df 将变量的名称、下划线和级别名称放在一起。有趣的是,结果表明以前说围栏是有些重要的。当我们将其进行独热编码时,它实际上说Enclosure_EROPS w AC是最重要的事情。所以至少在解释模型的目的上,你应该尝试对你的变量进行独热编码。我经常发现大约 6 或 7 个变量相当不错。你可以尝试将这个数字尽可能地提高,这样计算不会花费太长时间,而且特征重要性不会包括那些不感兴趣的非常小的级别。这取决于你自己去尝试,但在这种情况下,我发现这非常有趣。它清楚地告诉我我需要找出Enclosure_EROPS w AC是什么,为什么它很重要,因为现在对我来说毫无意义,但它是最重要的事情。所以我应该去弄清楚。

问题:你能解释一下如何改变类别的最大数量吗?因为对我来说,似乎只有五个类别或六个类别[49:15]。它所做的就是这里有一个叫做邮政编码、使用频段和性别的列,例如。比如说,邮政编码有 5,000 个级别。类别中的级别数量,我们称之为“基数”。所以它的基数是 5,000。使用频段可能有六个基数。性别有两个基数。所以当 proc_df 遍历并说好的时候,这是一个分类变量,我应该进行独热编码吗?它会检查基数与max_n_cat进行比较,说 5,000 大于七,所以我不进行独热编码。然后它转到使用频段——6 小于 7,所以我进行独热编码。它转到性别,2 小于 7,所以也进行独热编码。所以它只是为每个变量决定是否进行独热编码。一旦我们决定进行独热编码,它就不会保留原始变量。
如果你确实努力将你的有序变量转换为适当的有序变量,使用 proc_df 可能会破坏这一点。避免这种情况的简单方法是,如果我们知道我们总是想要使用使用频段的代码,你可以直接替换它:

现在它是一个整数。所以它永远不会改变。
去除冗余特征[54:57]
我们已经看到,基本上测量相同事物的变量会混淆我们的变量重要性。它也会使我们的随机森林稍微不那么好,因为需要更多的计算来做同样的事情,还有更多的列要检查。所以我们要做一些额外的工作来尝试去除冗余特征。我做的方法是做一些叫做“树状图”的东西。它有点像分层聚类。
聚类分析是一种尝试查看对象的方法,它们可以是数据集中的行或列,并找出彼此相似的对象。通常你会看到人们特别谈论聚类分析,他们通常指的是数据的行,并会说“让我们绘制它”并找出聚类。一种常见的聚类分析类型,如果时间允许,我们可能会详细讨论一下,被称为 k 均值。基本上,你假设你根本没有任何标签,然后随机选择几个数据点,逐渐找到靠近它的数据点,并将它们移动到离质心更近的位置,然后再次重复这个过程。这是一种迭代的方法,你告诉它你想要多少个聚类,它会告诉你它认为哪些类别在哪里。
一个真正被低估的技术(20 或 30 年前比今天更受欢迎)是层次聚类,也称为凝聚聚类。在层次或凝聚聚类中,我们查看每对对象,并说哪两个对象最接近。然后我们取最接近的一对,删除它们,并用两者的中点替换它们。然后再重复这个过程。由于我们正在删除点并用它们的平均值替换它们,您逐渐通过成对组合减少了点的数量。很酷的是,您可以绘制出来。
from scipy.cluster import hierarchy as hc
corr = np.round(scipy.stats.spearmanr(df_keep).correlation, 4)
corr_condensed = hc.distance.squareform(1-corr)
z = hc.linkage(corr_condensed, method='average')
fig = plt.figure(figsize=(16,10))
dendrogram = hc.dendrogram(z, labels=df_keep.columns, orientation='left', leaf_font_size=16
)
plt.show()
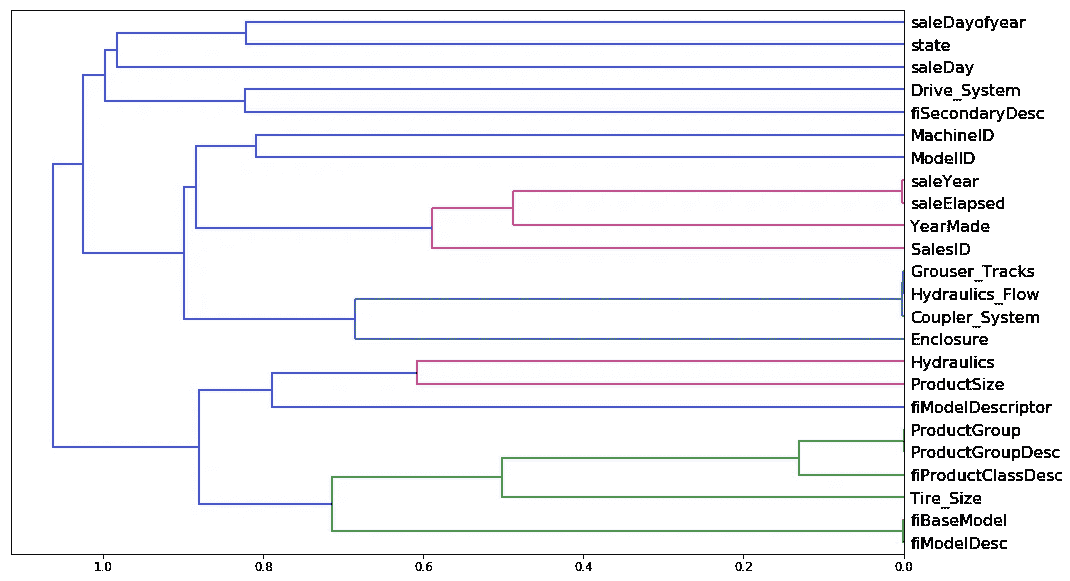
就像这样。不是看点,而是看变量,我们可以看到哪两个变量最相似。saleYear和saleElapsed非常相似。因此,这里的横轴是正在比较的两个点有多相似。如果它们更靠近右侧,那意味着它们非常相似。因此,saleYear和saleElapsed已经被合并,并且它们非常相似。
在这种情况下,我实际上使用了斯皮尔曼相关系数 R。你们已经熟悉相关系数了吗?所以相关性几乎与 R²完全相同,但它是在两个变量之间而不是一个变量和它的预测之间。普通相关性的问题在于,如果你有这样的数据,那么你可以进行相关性分析,你会得到一个好的结果。

但是如果你有这样的数据,并尝试进行相关性分析(假设是线性的),那就不太好了。

因此有一种称为秩相关的东西,这是一个非常简单的想法。用每个点的秩替换它。

从左到右,我们按照 1、2、…6 的顺序排名。然后你也要对 y 轴做同样的操作。然后你创建一个新的图,不是绘制数据,而是绘制数据的排名。如果你仔细想一想,这个数据集的排名看起来会像一条直线,因为每当 x 轴上的某个值更大时,y 轴上的值也更大。因此,如果我们对排名进行相关性分析,那就是称为排名相关性。
因为我们想要找到那些在某种方式上与随机森林发现它们相似的列(随机森林不关心线性,它们只关心排序),所以秩相关是正确的思考方式。所以斯皮尔曼相关系数是最常见的秩相关的名称。但你可以用数据的秩替换数据,然后将其传递给常规相关性,你将得到基本相同的答案。唯一的区别在于如何处理并列的数据,这是一个相当次要的问题。
一旦我们有了一个相关矩阵,基本上有几个标准步骤可以将其转换为树状图,每次我都必须在 stackoverflow 上查找。你基本上将其转换为一个距离矩阵,然后创建一个告诉你哪些东西在层次上连接到彼此的东西的东西。所以这是你总是必须做的三个标准步骤来创建一个树状图:
corr_condensed = hc.distance.squareform(1-corr)
z = hc.linkage(corr_condensed, method='average')
dendrogram = hc.dendrogram(z, labels=df_keep.columns, orientation='left', leaf_font_size=16
)
然后你可以绘制它[1:01:30]。saleYear和saleElapsed基本上在衡量相同的东西(至少在排名上),这并不奇怪,因为saleElapsed是自我的数据集中的第一天以来的天数,所以显然这两者几乎完全相关。Grouser_Tracks、Hidraulics_Flow和Coupler_System似乎在衡量相同的东西。这很有趣,因为记住,Coupler_System被认为非常重要。所以这更支持了我们的假设,这与是否是一个连接器系统无关,而是与它是什么类型的车辆具有这种特征。ProductGroup和ProductGroupDesc似乎在衡量相同的东西,fiBaseModel和fiModelDesc也是如此。一旦我们超过这一点,突然之间的距离更远,所以我可能不会担心那些。所以我们将研究那些非常相似的四组。
如果你只想知道这个东西与那个东西有多相似,最好的方法是查看 Spearman’s R 相关矩阵[1:03:43]。这里没有使用随机森林。距离度量完全是基于秩相关性进行的。
然后我做的是,我取这些组并创建一个小函数get_oob(获取 Out Of Band 分数)[1:04:29]。它为某个数据框执行一个随机森林。我确保已经将该数据框拆分为训练集和验证集,然后调用fit并返回 OOB 分数。
def get_oob(df):m = RandomForestRegressor(n_estimators=30, min_samples_leaf=5, max_features=0.6, n_jobs=-1, oob_score=True
)x, _ = split_vals(df, n_trn)m.fit(x, y_train)return m.oob_score_
基本上我要做的是尝试逐个去掉这 9 个左右的变量中的每一个,看看哪些我可以去掉而不会使 OOB 分数变得更糟。
get_oob(df_keep)
'''
0.89019425494301454
'''
每次我运行这个,我得到稍微不同的结果,所以实际上看起来上一次我有 6 个而不是 9 个。所以你可以看到,我只是循环遍历我认为可能可以去掉的每一个东西,因为它是多余的,然后打印出模型的列名和在去掉那个列之后训练的模型的 OOB 分数。
for c in ('saleYear', 'saleElapsed', 'fiModelDesc', 'fiBaseModel', 'Grouser_Tracks', 'Coupler_System'
):print(c, get_oob(df_keep.drop(c, axis=1)))
整个数据框的 OOB 分数为 0.89,然后在去掉每一个这些东西之后,基本上没有一个变得更糟。saleElapsed比saleYear要糟糕得多。但看起来其他几乎所有的东西,我只能去掉一个小数点问题。所以显然,你必须记住树状图。让我们看看 fiModelDesc 和 fiBaseModel,它们非常相似。所以这意味着的不是我可以去掉它们中的两个,而是我可以去掉其中一个,因为它们基本上在衡量同一件事情。
saleYear 0.889037446375
saleElapsed 0.886210803445
fiModelDesc 0.888540591321
fiBaseModel 0.88893958239
Grouser_Tracks 0.890385236272
Coupler_System 0.889601052658
然后我尝试了。让我们尝试每组中去掉一个:
to_drop = ['saleYear', 'fiBaseModel', 'Grouser_Tracks']
get_oob(df_keep.drop(to_drop, axis=1))
'''
0.88858458047200739
'''
我们从 0.890 到 0.888,再次,它们之间的差距太小以至于无关紧要。听起来不错。简单就是好。所以我现在要从我的数据框中删除这些列,然后我可以尝试再次运行完整的模型。
df_keep.drop(to_drop, axis=1, inplace=True)
X_train, X_valid = split_vals(df_keep, n_trn)
np.save('tmp/keep_cols.npy', np.array(df_keep.columns))
keep_cols = np.load('tmp/keep_cols.npy')
df_keep = df_trn[keep_cols]
reset_rf_samples意味着我使用了整个自助采样。有 40 个估计器,我们得到了 0.907。
reset_rf_samples()
m = RandomForestRegressor(n_estimators=40, min_samples_leaf=3, max_features=0.5, n_jobs=-1, oob_score=True
)
m.fit(X_train, y_train)
print_score(m)
'''
[0.12615142089579687, 0.22781819082173235, 0.96677727309424211, 0.90731173105384466, 0.9084359846323049]
'''
现在我有了一个更小更简单的模型,并且得分很好。所以在这一点上,我已经尽可能地去掉了许多列(那些要么没有很好的特征重要性,要么与其他变量高度相关,当我去掉它们时,模型没有显著变差)。
部分依赖[1:07:34]
现在我到了想要通过利用模型更好地了解我的数据的阶段。我们将使用一种称为偏依赖的技术。再次强调,这是你可以在 Kaggle 内核中使用的东西,很多人会欣赏这一点,因为几乎没有人知道偏依赖,它是一种非常强大的技术。我们要做的是找出对于重要的特征,它们如何与因变量相关。让我们来看看。
from pdpbox import pdp
from plotnine import *
再次,由于我们正在进行解释,我们将设置set_rf_samples为 50,000,以便快速运行事务。
set_rf_samples(50000)
我们将获取我们的特征重要性,并注意我们正在使用max_n_cat,因为我实际上对看到解释的各个级别很感兴趣。
df_trn2, y_trn, nas = proc_df(df_raw, 'SalePrice', max_n_cat=7)
X_train, X_valid = split_vals(df_trn2, n_trn)
m = RandomForestRegressor(n_estimators=40, min_samples_leaf=3, max_features=0.6, n_jobs=-1
)
m.fit(X_train, y_train);
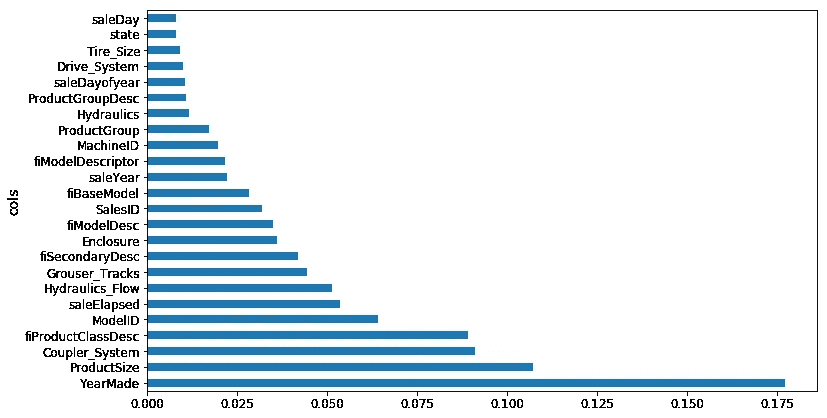
这是前 10 个:
plot_fi(rf_feat_importance(m, df_trn2)[:10]);
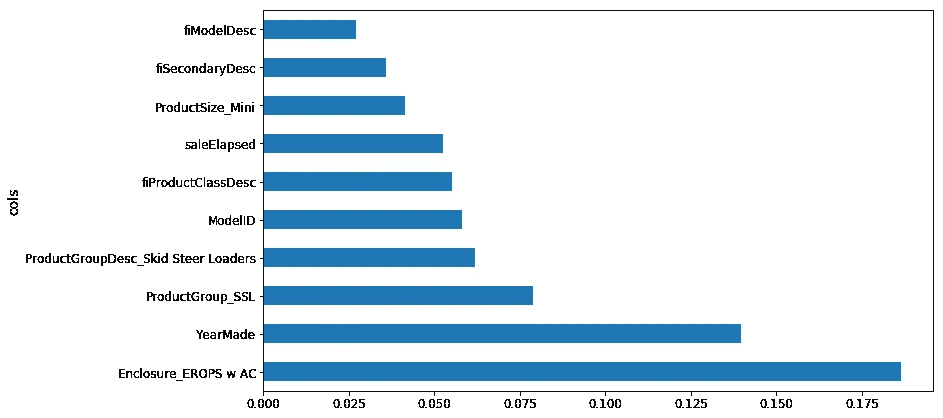
让我们尝试更多地了解那些前 10 个。YearMade是第二重要的。所以一个明显的事情是我们可以做的是绘制YearMade与saleElapsed的关系,因为正如我们已经讨论过的,它们似乎是重要的,但很可能它们是结合在一起找出产品在销售时的年龄。所以我们可以尝试绘制YearMade与saleElapsed,看看它们之间的关系。
df_raw.plot('YearMade', 'saleElapsed', 'scatter', alpha=0.01, figsize=(10,8));
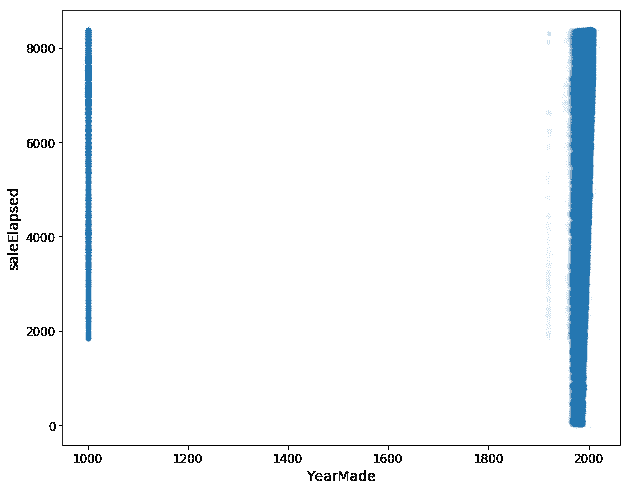
当我们这样做时,我们得到了这个非常丑陋的图表。它告诉我们YearMade实际上有很多是一千。显然,这是我会倾向于回到客户那里并说好的,我猜这些推土机实际上不是在公元 1000 年制造的,他们可能会对我说“是的,这些是我们不知道制造地点的产品”。也许“1986 年之前,我们没有追踪”或者“在伊利诺伊州销售的产品,我们没有提供这些数据”等等——他们会告诉我们一些原因。为了更好地理解这个图,我只是要从分析的解释部分中将它们移除。我们只会获取YearMade大于 1930 的数据。
x_all = get_sample(df_raw[df_raw.YearMade>1930], 500)
ggplot(x_all, aes('YearMade', 'SalePrice')) + \stat_smooth(se=True, method='loess')
现在让我们看一下YearMade和SalePrice之间的关系。有一个非常棒的包叫做ggplot。ggplot最初是一个 R 包(GG 代表图形语法)。图形语法是一种非常强大的思考方式,可以以非常灵活的方式生成图表。我在这门课上不会谈论它太多。网上有很多信息可供参考。但我绝对推荐它作为一个很棒的包来使用。ggplot可以通过pip安装,它已经是 fast.ai 环境的一部分。Python 中的ggplot基本上具有与 R 版本相同的参数和 API。R 版本有更好的文档,所以你应该阅读它的文档以了解如何使用它。但基本上你会说“好的,我想为这个数据框(x_all)创建一个图。当你创建图时,你使用的大多数数据集都太大而无法绘制。例如,如果你做一个散点图,它会创建很多点,导致一团糟,而且会花费很长时间。记住,当你绘制东西时,你是在看它,所以没有必要绘制一个有一亿个样本的东西,当你只使用十万个时,它们会完全相同。这就是为什么我首先调用get_sample。get_sample只是抓取一个随机样本。
ggplot(x_all, aes('YearMade', 'SalePrice')) + \stat_smooth(se=True, method='loess')
所以我只是从我的数据框中抓取 500 个点,然后绘制YearMade和SalePrice。aes代表“美学” - 这是你在ggplot中设置列的基本方式。然后在ggplot中有一个奇怪的东西,“+”表示添加图表元素。所以我要添加一个平滑线。通常你会发现散点图很难看清楚发生了什么,因为有太多的随机性。或者,平滑线基本上为图的每个小子集创建一个小线性回归。这样可以连接起来,让你看到一个漂亮的平滑曲线。这是我倾向于查看单变量关系的主要方式。通过添加se=True,它还会显示这个平滑线的置信区间。loess代表局部加权回归,这是做许多小型回归的想法。
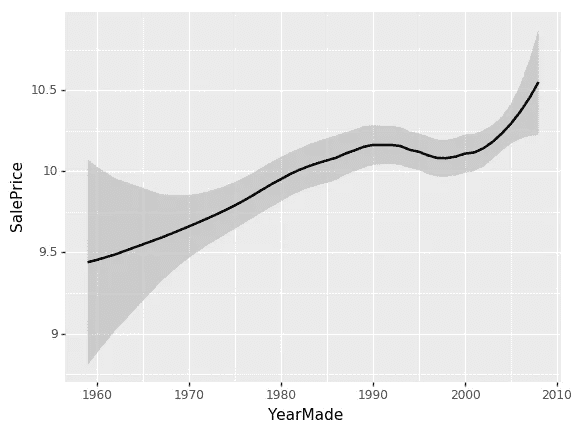
所以我们可以在这里看到,YearMade和SalePrice之间的关系非常混乱,这并不是我们所期望的。我本来以为最近卖出的东西可能会更贵,因为通货膨胀和更现代的型号。问题在于,当你看一个像这样的单变量关系时,会有很多共线性发生 - 很多互动被忽略了。例如,价格为什么会下降?是因为 1991 年至 1997 年之间制造的东西价值更低吗?还是因为大部分产品在那个时期也被卖出,那时可能有经济衰退?或者是因为在那个时期卖出的产品,更多人购买了价格更低的车辆类型?有各种各样的原因。所以再次,作为数据科学家,你将会看到的一件事是,在你加入的公司里,人们会拿着这种单变量图来找你,他们会说“哦天啊,我们在芝加哥的销售量消失了。变得很糟糕。”或者“人们不再点击这个广告了”,然后他们会给你看一个看起来像这样的图表,问发生了什么。大多数情况下,你会发现答案是“发生了什么”的问题是有其他原因的。比如,“实际上上周在芝加哥,我们在做一个新的促销活动,这就是为什么我们的收入下降了 - 不是因为人们不再在芝加哥购买东西了;价格更低了”。
所以我们真正想要做的是说“嗯,SalePrice和YearMade之间的关系是什么,其他所有事情都相等。” “其他所有事情都相等”基本上意味着如果我们在 1990 年和 1980 年卖了同样的东西给同样的人在同样的拍卖会上等等,价格会有什么不同?为了做到这一点,我们做了一个叫做部分依赖图的东西。
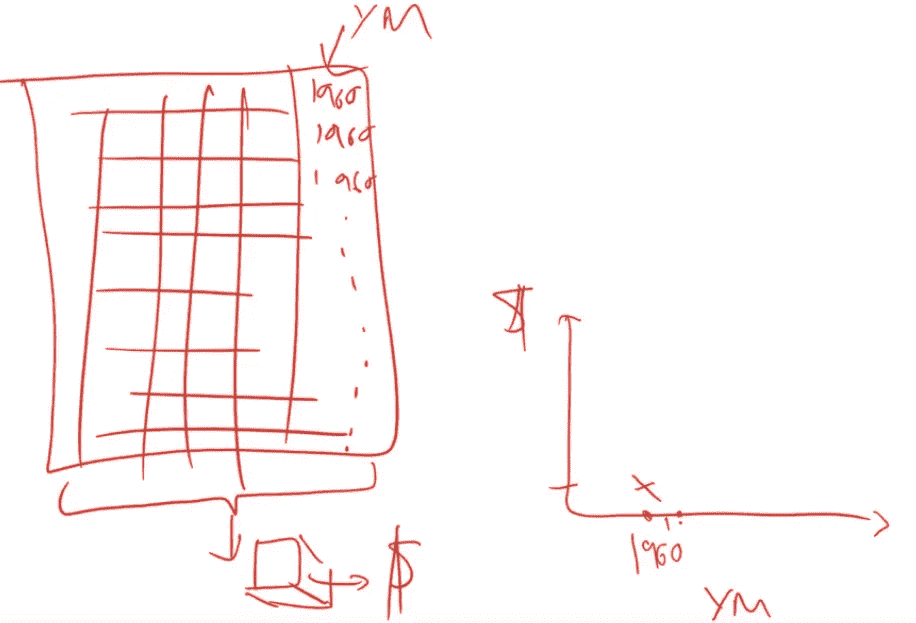
x = get_sample(X_train[X_train.YearMade>1930], 500)
有一个非常好的库,没有人听说过,叫做pdp,它可以做这些部分依赖图,发生的情况是这样的。我们有 500 个数据点的样本,我们要做一些非常有趣的事情。我们将对这 500 个随机选择的拍卖会进行处理,然后我们将从中制作一个小数据集。
这是我们的数据集,有 500 个拍卖品,这是我们的列,其中一个是我们感兴趣的事物YearMade。我们现在要尝试创建一个图表,在这个图表中我们说在 1960 年,其他所有事物都相等的情况下,拍卖品的成本是多少?我们将用 1960 年替换YearMade列。我们将一直复制值 1960,直到最后。现在每一行,制造年份都是 1960,所有其他数据都将完全相同。我们将使用我们的随机森林,将所有这些数据传递给我们的随机森林来预测销售价格。这将告诉我们,对于所有被拍卖的物品,如果那个物品是在 1960 年制造的,我们认为它将被卖出多少钱。这就是我们将在右侧绘制的内容。
我们将为 1961 年做同样的事情。
问题:明确一点,我们已经拟合了随机森林,然后我们只是传递一个新的年份,看看它确定的价格应该是多少?是的,这很像我们做特征重要性的方式。但是,我们不是随机洗牌列,而是用一个常数值替换列。随机洗牌列告诉我们当您不再使用该列时它有多准确。用一个常数值替换整个列为我们估计了如果那个产品是在 1961 年制造的,我们将在那天在那个地方的那个拍卖会上卖出那个产品多少钱。然后我们取所有从那个随机森林计算出的销售价格的平均值。我们在 1961 年这样做,得到这个值:
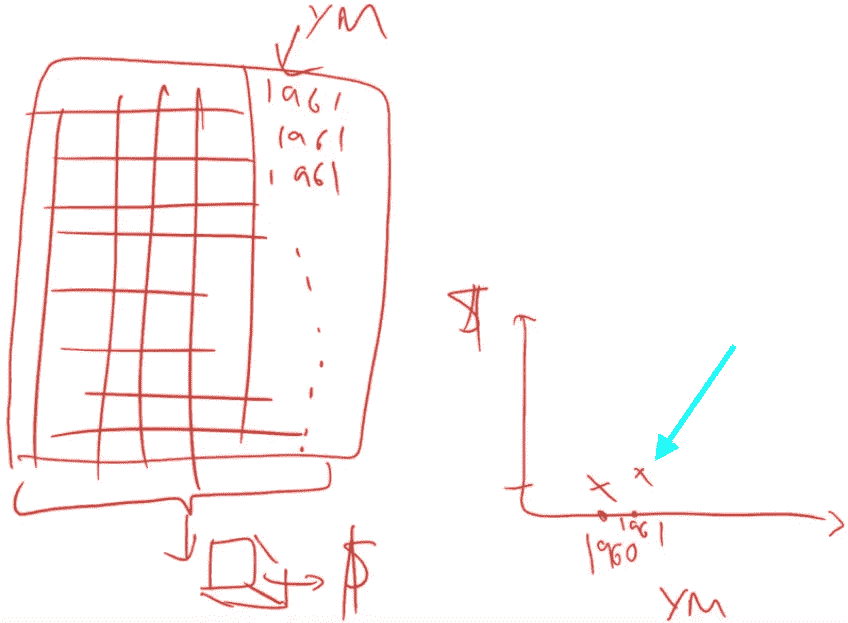
def plot_pdp(feat, clusters=None, feat_name=None):feat_name = feat_name or featp = pdp.pdp_isolate(m, x, feat)return pdp.pdp_plot(p, feat_name, plot_lines=True, cluster=clusters is not None, n_cluster_centers=clusters)
plot_pdp('YearMade')

所以这里的部分依赖图(PDP)向我们展示的是每一条浅蓝色线实际上都显示了所有 500 条线。因此,对于我们数据集中的第 1 行,如果我们在 1960 年卖出它,我们将将其索引为零,称之为零。如果在 1970 年卖出那个特定的拍卖品,它将在这里,等等。我们实际上绘制了所有 500 个预测,即如果我们用不同的值替换其YearMade,那么这 500 个拍卖品中的每一个将会卖出多少钱。然后这条深色线是平均值。因此,这告诉我们,如果所有这些产品实际上是在 1985 年、1990 年、1993 年等制造的,我们将平均卖出这些拍卖品多少钱。因此,您可以看到,这里发生的情况是,至少在我们有相当多数据的时期,即自 1990 年以来,这基本上是一条完全直线,这是您所期望的。因为如果在同一日期卖出,而且是同一种拖拉机,卖给同一个人在同一个拍卖行,那么您会期望更近期的车辆更昂贵,因为通货膨胀和它们是更新的。您会期望这种关系大致是线性的,这正是我们发现的。通过消除所有这些外部因素,通常能够更清楚地看到真相。
这个部分依赖图是使用随机森林来更清晰地解释我们数据中发生的情况。步骤是:
-
首先看一下未来的重要性,告诉我们我们认为我们关心哪些事情。
-
然后使用部分依赖图告诉我们平均情况下发生了什么。
我们可以用 PDP 做另一件很酷的事情,那就是我们可以使用聚类。聚类的作用是利用聚类分析来查看这 500 行中的每一行,并判断这 500 行中是否有一些行以相同的方式移动。我们可以看到似乎有很多行是先下降然后上升,还有一些行是先上升然后趋于平缓。看起来似乎有一些不同类型的行为被隐藏了,所以这里是进行聚类分析的结果:
plot_pdp('YearMade', clusters=5)
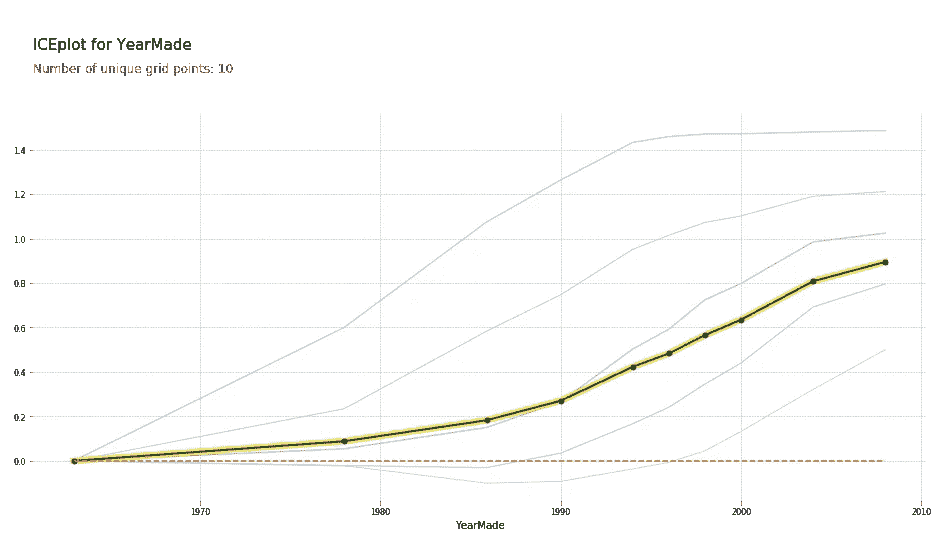
我们仍然得到相同的平均值,但这里列出了我们看到的五种最常见的形状。这就是你可以进去并说好吧,看起来有些车辆在 1990 年后,它们的价格相当稳定。在那之前,它们是相当线性的。其他一些车辆则恰恰相反,所以不同种类的车辆有不同的形状。因此,这是你可以深入研究的内容。
问题:那么我们要如何处理这些信息呢?解释的目的是为了了解数据集,那么你为什么想要了解一个数据集呢?因为你想要对其进行某些操作。所以在这种情况下,如果你试图赢得 Kaggle 竞赛,这并不是什么大不了的事情——一些洞察可能让你意识到我可以转换这个变量或创建这种互动等等。显然,特征重要性对于 Kaggle 竞赛非常重要。但这更多地是为了现实生活。所以当你与某人交谈时,你对他们说“好的,你一直向我展示的那些图表实际上表明在 1990 年至 1997 年之间基于某些因素价格出现了下降。实际上并没有。实际上它们是在增长,那时发生了其他事情。”这基本上是让你说出,无论我试图在我的业务中推动的结果是什么,这就是某种驱动力。所以如果我在看广告技术,是什么在推动点击,我实际上正在深入研究,看看点击是如何被推动的。这实际上是在推动它的变量。这是它们之间的关系。因此,我们应该以这种方式改变我们的行为。这实际上是任何模型的目标。我想有两个可能的目标:一个模型的目标只是为了获得预测,比如如果你在进行对冲基金交易,你可能想知道那只股票的价格会是多少。如果你在做保险,你可能只想知道那个人会有多少索赔。但大多数情况下,你实际上是在尝试改变你的业务方式——你如何做市场营销,如何做物流,所以你真正关心的是这些事物之间的关系。

问题:你能再解释一下为什么这个下降并不意味着我们所认为的吗?是的。这是一个经典的无聊的单变量图。这只是将所有的点,所有的选项,将制造年份与销售价格进行绘图,并且我们只是通过它们拟合一个粗略的平均值。在我们的数据集中,1992 年至 1997 年制造的产品平均销售价格较低。在商业中,你经常会听到有人看到这样的情况并说“我们应该停止拍卖那些在这些年份制造的设备,因为我们得到的钱更少”,例如。但事实上,可能是在那些年份,人们制造了更多的小型工业设备,你会期望它们的售价更低,而实际上我们的利润也同样高。或者并不是那些年份制造的东西现在会更便宜,而是在那些年份卖东西时,它们更便宜,因为当时正值经济衰退。如果你真的想根据这个采取一些行动,你可能并不只关心那些年份制造的东西平均更便宜,而是这对今天有什么影响。因此,我们采用 PDP 方法,实际上是说让我们尝试消除所有这些外部因素。因此,如果同一天向同一人出售同一种类型的车辆,那么实际上制造年份如何影响价格。这基本上是说,例如,如果我在拍卖会上决定买什么,那么这对我来说意味着平均而言,购买一辆更近期的车辆确实会给你更多的钱,这并不是单变量图所说的。
评论:2010 年生产的推土机可能与 1960 年生产的推土机类型不太接近。如果你拿一个非常不同的东西,比如 2010 年的推土机,然后试图说“哦,如果它是 1960 年生产的”,这可能会导致预测不准确,因为它远远超出了训练集的范围。绝对。这是一个很好的观点。然而,这是一个限制,如果你有一个数据点在它以前没有见过的空间中,比如也许 1960 年的推土机没有安装空调,你在说这台带空调的推土机在 1960 年会卖多少钱,你实际上没有任何信息来知道这一点。这仍然是我知道的最好的技术,但并不完美。你希望树仍然能找到一些有用的真相,即使它以前没有见过这些特征的组合。但是,是的,这是需要注意的事情。
feats = ['saleElapsed', 'YearMade']
p = pdp.pdp_interact(m, x, feats)
pdp.pdp_interact_plot(p, feats)
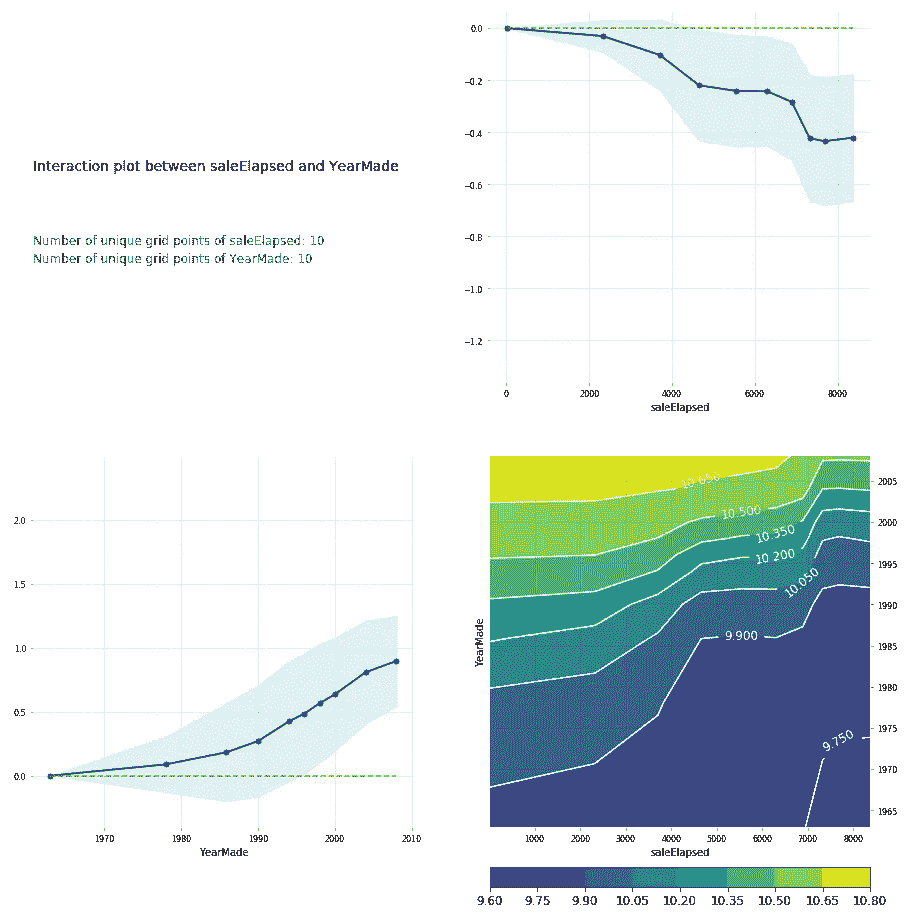
您也可以在 PDP 交互图中执行相同的操作[1:27:36]。而我真正想要的 PDP 交互图是,saleElapsed 和 YearMade 如何共同影响价格。如果我做一个 PDP 交互图,它会显示给我 saleElapsed vs. price,YearMade vs. price,以及两者的组合 vs. price。请记住,这里始终是价格的对数。这就是为什么这些价格看起来很奇怪。您可以看到 saleElapsed 和 YearMade 的组合正如您所期望的那样——价格最高的是那些经过的时间最短和最近制造的年份。右上角是 saleElapsed 和价格之间的单变量关系,左下角是 YearMade 和价格之间的单变量关系,右下角是两者的组合。足以清楚地看到这两个因素共同推动价格。您还可以看到这些不是简单的对角线,因此存在一些有趣的交互作用。根据观察这些图,我认为,也许我们应该加入某种交互项并看看会发生什么。所以让我们稍后再回到这个问题,但让我们先看几个例子。
请记住,在这种情况下,我们进行了独热编码——在最开始时,我们说max_n_cat=7[1:29:18]。因此,我们有像Enclosure_EROPS w AC这样的变量。因此,如果您有独热编码的变量,您可以将它们的数组传递给plot_pdp,它将把它们视为一个类别。
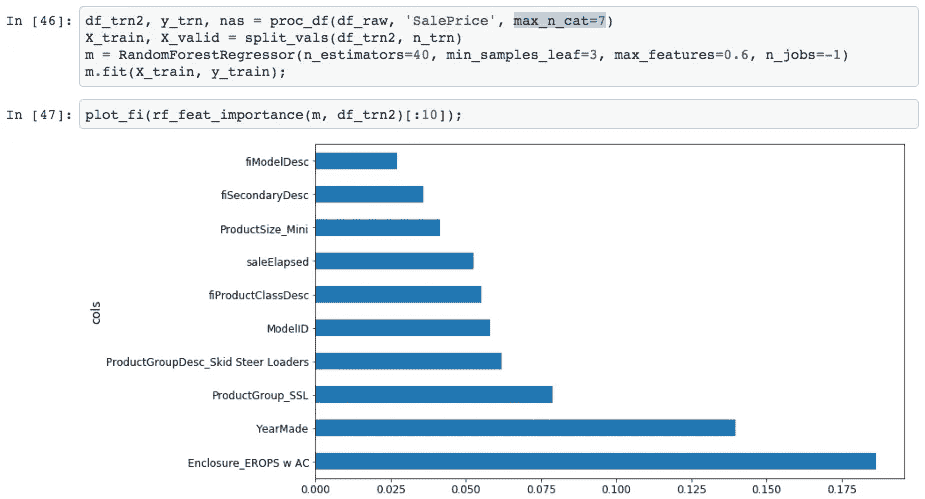
因此,在这种情况下,我将创建这三个类别的 PDP 图,并将其命名为“Enclosure”。
plot_pdp(['Enclosure_EROPS w AC', 'Enclosure_EROPS', 'Enclosure_OROPS'
], 5, 'Enclosure')
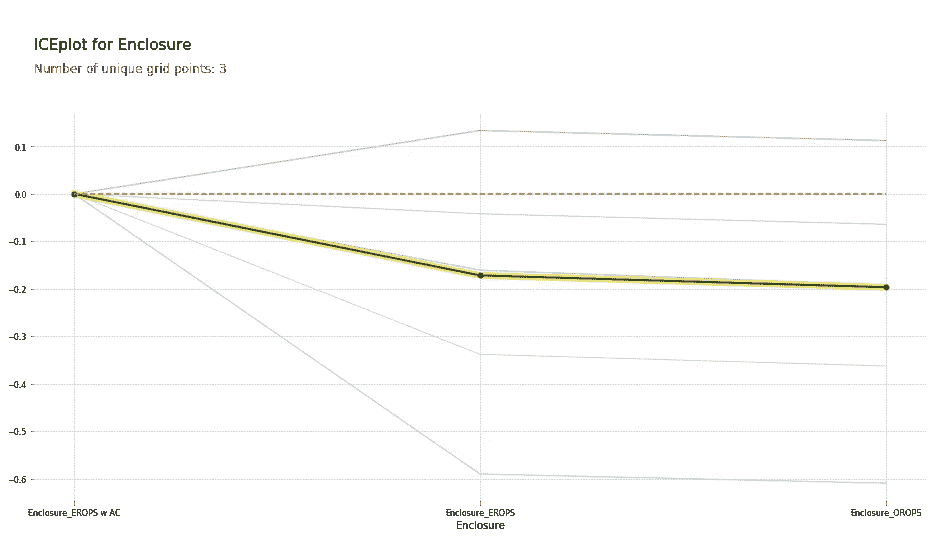
我可以看到Enclosure_EROPS w AC的平均价格要高于Enclosure_EROPS或Enclosure_OROPS。实际上,后两者看起来相似,或者Enclosure_EROPS w AC更高。因此,此时我可能倾向于跳转到 Google 并搜索“erops orops”以了解这些内容,然后我们继续。

事实证明,EROPS 是封闭式翻转保护结构,因此如果您的推土机完全封闭,则可以选择安装空调。因此,这实际上告诉我们它是否有空调。如果是开放式结构,那么显然根本没有空调。这就是这三个级别的含义。因此,我们现在知道,其他条件相同的情况下,同一时间销售,同一时间制造,销售给同一人的推土机,如果有空调,价格会比没有空调的要高得多。因此,我们再次获得了这种很好的解释能力。现在我花了一些时间处理这个数据集,我肯定注意到了知道这一点是最重要的事情,您会注意到现在有更多的带空调的推土机,比过去有更多,因此日期和这之间肯定存在交互作用。
df_raw.YearMade[df_raw.YearMade<1950] = 1950
df_keep['age'] = df_raw['age'] = df_raw.saleYear-df_raw.YearMade
X_train, X_valid = split_vals(df_keep, n_trn)
m = RandomForestRegressor(n_estimators=40, min_samples_leaf=3, max_features=0.6, n_jobs=-1
)
m.fit(X_train, y_train)
plot_fi(rf_feat_importance(m, df_keep));
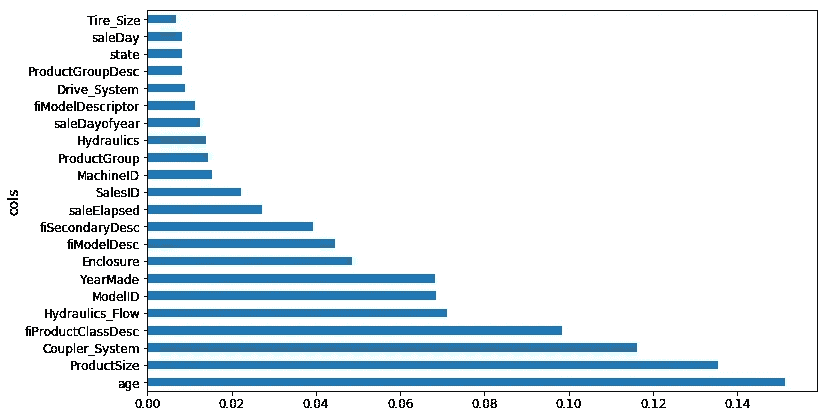
根据之前的交互分析,首先我尝试将 1950 年之前的所有内容设置为 1950 年,因为这似乎是某种缺失值[1:31:25]。我将age设置为saleYear - YearMade。然后我尝试在此基础上运行随机森林。确实,age现在是最重要的因素,saleElapsed 远远落后,YearMade 也落后。因此,我们使用这个找到了一个交互作用。但请记住,随机森林可以通过具有多个分割点来创建交互作用,因此我们不应该假设这实际上会带来更好的结果。实际上,当我查看我的得分和 RMSE 时,我发现添加 age 实际上效果稍差。也许在下一节课中我们会看到更多相关内容。
树解释器[1:32:34]
最后一件事是树解释器。这也属于大多数人不知道存在的事物类别,但它非常重要。对于 Kaggle 竞赛几乎毫无意义,但对于现实生活非常重要。这是个想法。假设你是一家保险公司,有人打电话给你,你给他们报价,他们说“哦,比去年贵了 500 美元。为什么?”总的来说,你从某个模型中做出了预测,有人问为什么。这就是我们使用的这种叫做树解释器的方法。树解释器的作用是允许我们取出特定的一行。
from treeinterpreter import treeinterpreter as ti
df_train, df_valid = split_vals(df_raw[df_keep.columns], n_trn)
所以在这种情况下,我们将选择零行。
row = X_valid.values[None,0]; row
这是零行中的所有列。

我可以用树解释器做的是,我可以调用ti.predict,传入我的随机森林和我的行(这将是这个特定客户的保险信息,或者在这种情况下是这个特定拍卖)。它会给我三件事:
-
预测: 随机森林的预测 -
偏差: 整个原始数据集的平均销售价格 -
贡献度: 一列和要拆分的值(即预测器),以及它对预测值的影响有多大。
prediction, bias, contributions = ti.predict(m, row)
所以你可以这样想[1:34:51]。整个数据集的平均对数销售价格为 102。那些联接器系统≤0.5的数据集平均为 10.3。联接器系统≤0.5和围栏≤2.0的数据集为 9.9,然后最终我们一直到这里,还有ModelID≤4573.0,为 10.2。所以你可以问,为什么我们为这个特定行预测了 10.2?
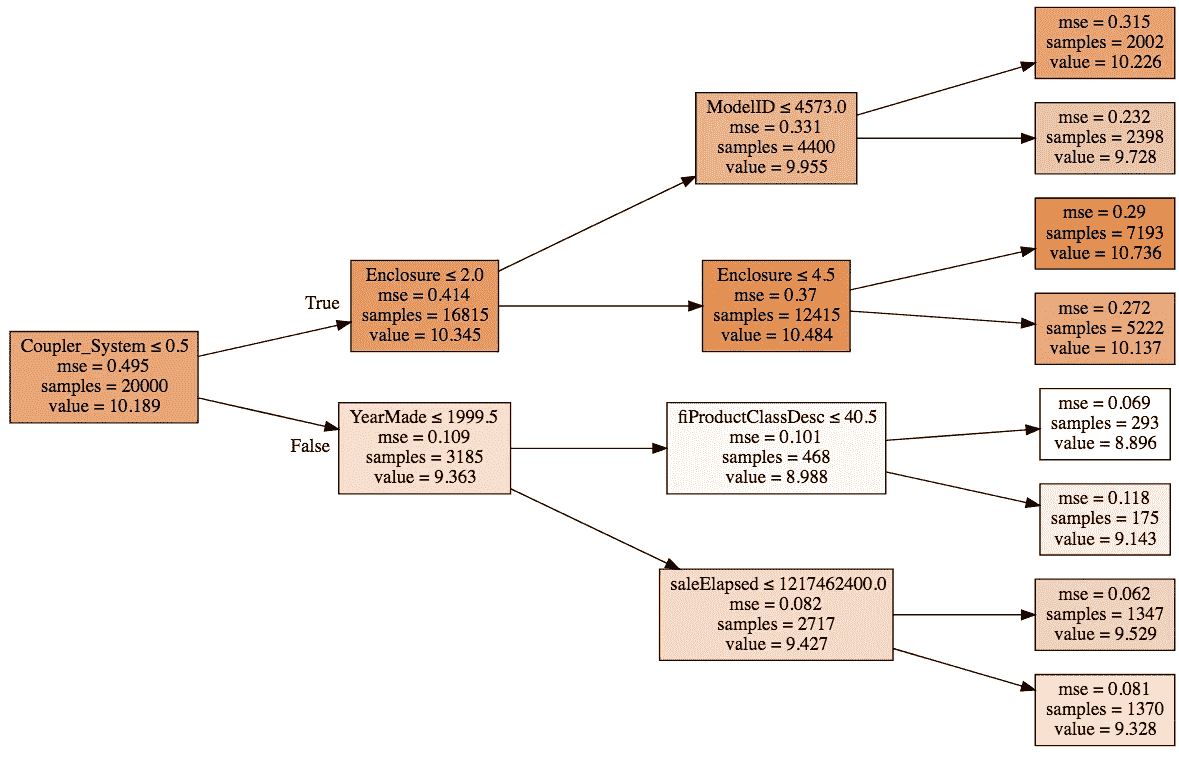
这是因为我们从 10.19 开始:
-
因为联接器系统小于 0.3,我们增加了大约 0.2(所以我们从 10.19 增加到 10.34)。
-
因为围栏小于 2,我们减去了大约 0.4。
-
然后因为模型 ID 小于 4573,我们增加了大约 0.7
所以你可以看到,通过一棵树,你可以分解为什么我们预测了 10.2。在每一个决策点,我们都会对值进行一点点的加减。然后我们可以对所有树都这样做,然后我们可以取平均值。每次我们看到围栏,我们增加还是减少了值,以及多少?每次我们看到模型 ID,我们增加还是减少了值,以及多少?我们可以取所有这些的平均值,这就是所谓的贡献度。
prediction[0], bias[0]
'''
(9.1909688098736275, 10.10606580677884)
'''
idxs = np.argsort(contributions[0])
[o for o in zip(df_keep.columns[idxs], df_valid.iloc[0][idxs], contributions[0][idxs])
]
这里是我们所有的预测因子和每个值[1:37:54]。
[('ProductSize', 'Mini', -0.54680742853695008),('age', 11, -0.12507089451852943),('fiProductClassDesc','Hydraulic Excavator, Track - 3.0 to 4.0 Metric Tons',-0.11143111128570773),('fiModelDesc', 'KX1212', -0.065155113754146801),('fiSecondaryDesc', nan, -0.055237427792181749),('Enclosure', 'EROPS', -0.050467175593900217),('fiModelDescriptor', nan, -0.042354676935508852),('saleElapsed', 7912, -0.019642242073500914),('saleDay', 16, -0.012812993479652724),('Tire_Size', nan, -0.0029687660942271598),('SalesID', 4364751, -0.0010443985823001434),('saleDayofyear', 259, -0.00086540581130196688),('Drive_System', nan, 0.0015385818526195915),('Hydraulics', 'Standard', 0.0022411701338458821),('state', 'Ohio', 0.0037587658190299409),('ProductGroupDesc', 'Track Excavators', 0.0067688906745931197),('ProductGroup', 'TEX', 0.014654732626326661),('MachineID', 2300944, 0.015578052196894499),('Hydraulics_Flow', nan, 0.028973749866174004),('ModelID', 665, 0.038307429579276284),('Coupler_System', nan, 0.052509808150765114),('YearMade', 1999, 0.071829996446492878)]
视频中存在排序问题,因为没有使用索引排序,但上面的示例是已更正的版本。
contributions[0].sum()
'''
-0.7383536391949419
'''
然后有一个叫做偏差的东西,偏差只是我们在开始进行任何拆分之前的平均值[1:39:03]。如果你从平均对数值开始,然后我们沿着每棵树走,每次看到 YearMade 时,我们有一些影响,联接器系统有一些影响,产品尺寸有一些影响,等等。
我们可能会在下次回到树解释器,但基本思想(这是我们关键解释点的最后一个)是,我们希望不仅能告诉我们关于整个模型以及平均工作原理的信息,还要查看模型如何为单个行进行预测。这就是我们在这里所做的。