🎇个人主页:Ice_Sugar_7
🎇所属专栏:Java数据结构
🎇欢迎点赞收藏加关注哦!
基本概念
- 🍉哈希表
- 🍉哈希冲突
- 🍌负载因子调节
- 🍌解决哈希冲突
- 🥝1. 闭散列法
- 🥝2. 开散列法(哈希桶)
🍉哈希表
哈希表是一种数据结构,它使用哈希函数将键映射到数组中的一个位置(即将元素的存储位置和它的key之间建立映射关系)
- 在存储一个键值对时,哈希函数根据key计算出一个索引(哈希地址),然后将键值对存储在对应的索引位置上
举个例子:
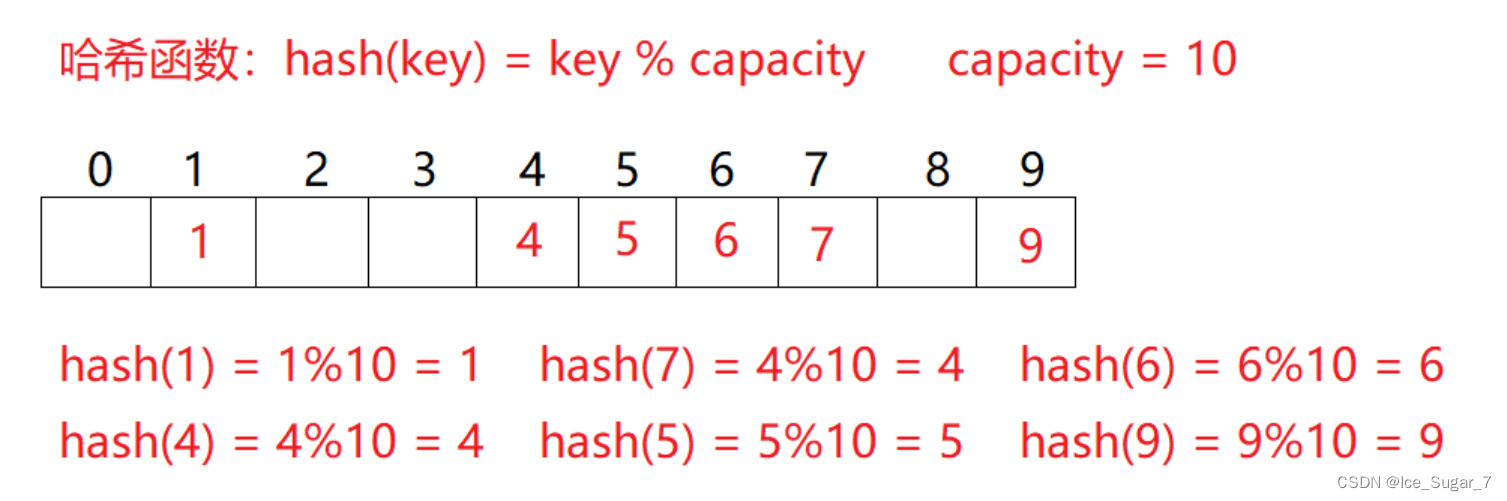
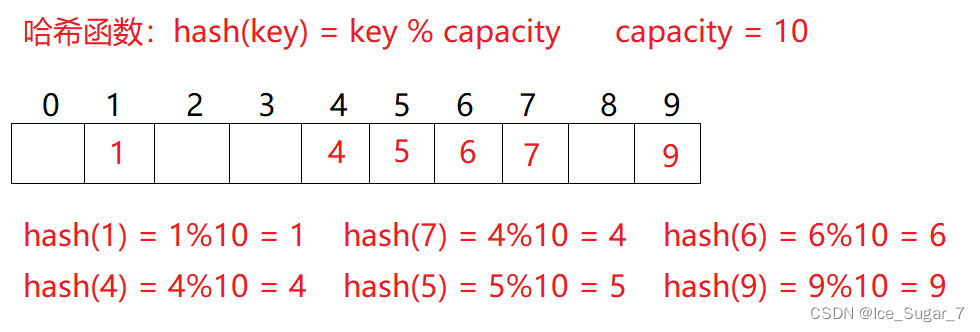
数据集合{1,7,6,4,5,9}
哈希函数设置为:hash(key) = key % capacity(capacity为存储元素底层空间的大小)
那我们可以推出每个元素存储的位置为
- 在搜索元素时,对元素的key进行同样的计算,把求得的函数值当做元素的存储位置,在哈希表中取这个位置的元素进行比较,若key相等,则搜索成功
因为通过哈希函数计算得到的索引可以直接指向元素所在的位置,所以在理想情况下,查找、插入和删除操作的时间复杂度可以达到O(1)
🍉哈希冲突
不同的关键字通过相同的哈希函数计算出相同的哈希地址,该种现象称为哈希冲突
造成哈希冲突的原因之一是:哈希函数设计不够合理
我们在设计哈希函数时,应遵循:
- 哈希函数的定义域需要包括所有待存储的关键码
- 计算出来的哈希地址能均匀分布在整个空间中
- 哈希函数应该比较简单
🍌负载因子调节
哈希表载荷因子定义为 α = 填入表中的元素个数 / 哈希表长度
α越大,表明填入表中的元素越多,发生冲突的可能性越大
当α超过一定阈值时,会触发哈希表的扩容操作
在Java中,HashMap默认负载因子是0.75,0.75是一个被认为在时间和空间效率上做了平衡的经验值,它既保证了空间的有效利用,又尽量减少了冲突的发生,是一个相对较优的选择。
负载因子和冲突率的关系粗略演示:
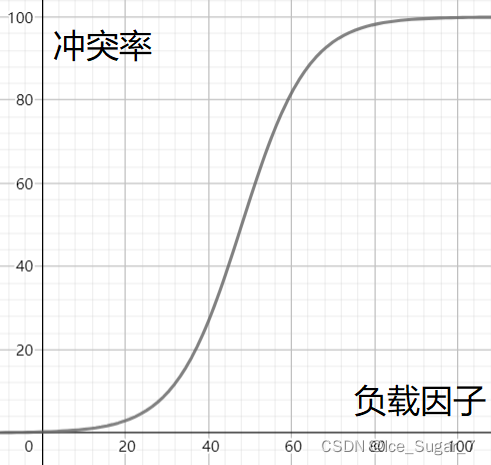
我们可以通过降低负载因子来降低冲突率,因为哈希表中已有的关键字个数是不可变的,那么我们能调整的就只有哈希表中的数组的大小
注意:哈希表扩容后,需要重新计算里面的关键字的哈希地址
🍌解决哈希冲突
解决哈希冲突两种常见的方法是:闭散列和开散列
🥝1. 闭散列法
也叫开放定址法,发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置的“下一个”空位置中
那怎么找空位置呢?
- 线性探测
从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止
比如对于刚才上面的例子:
如果要插入44,那它会和4产生冲突,采用线性探测解决冲突的话,那就会插入到下标为8这个空位置: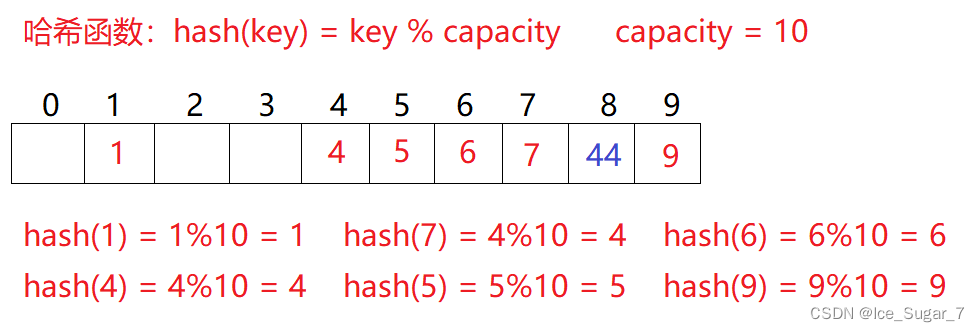
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找。如果表中只填入4,而接下来要填入44,14,24,34一系列数字的话:

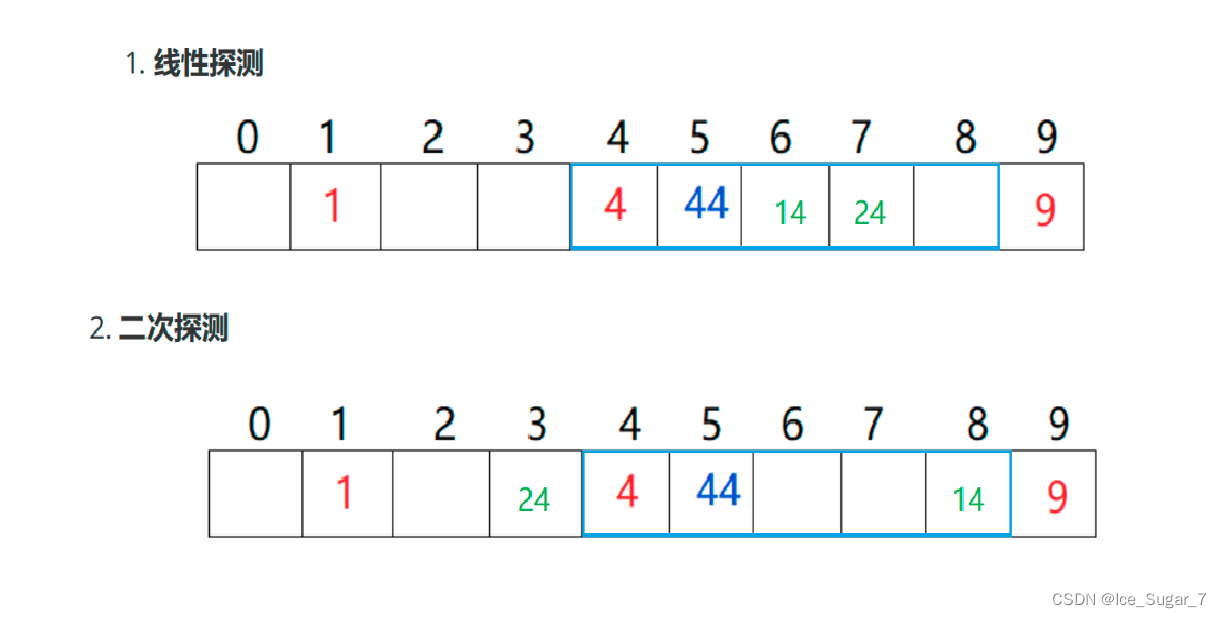
采用二次探测可以避免这个问题
- 二次探测
二次探测通过下面的公式算出要插入哪个空位置

比如对于上面的例子,使用二次探测解决冲突后得到:
🥝2. 开散列法(哈希桶)
又叫链地址法、开链法
先用哈希函数算出每个关键码的哈希地址,具有相同地址的关键码归于同一子集合,每个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中
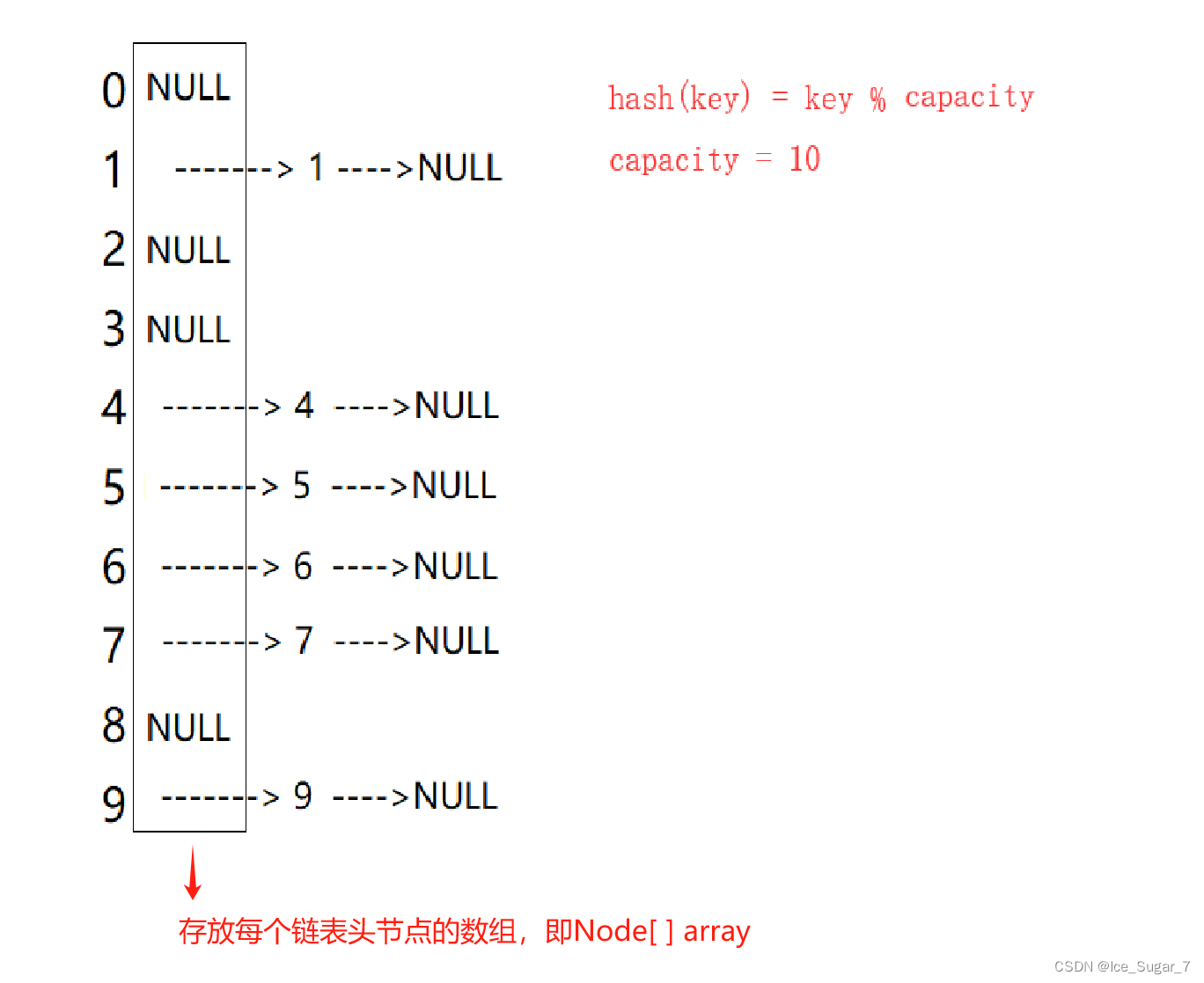
从这个图可以看出:开散列中每个桶放的都是发生哈希冲突的元素
- 在一些哈希表的实现中,当哈希桶中的链表长度超过一定阈值时,可能会将链表转换为红黑树。因为当链表长度较长时,查找、插入和删除操作的时间复杂度会变得较高,而红黑树的时间复杂度相对较低,将链表转换为红黑树可以提高哈希表的性能
- 在JDK 8中的HashMap实现中,当链表长度超过8个元素时,会将链表转换为红黑树