目录
一、综合评价指标预处理
1.定量指标的一致化处理(正向化处理)
2.定量指标的无量纲化处理
二、熵权法(EWM)
三、TOPSIS法
四、熵权法-TOPSIS的使用流程
案例:熵权法-TOPSIS的案例分析:水质评价
(一)数据导入
(二)指标一致化处理(正向化)
(三)指标的无量纲化处理
(四)确定正负理想解
(五)熵权法确定权重
(六)TOPSIS计算综合评分
(七)结果的分析及绘图
一、综合评价指标预处理
1.定量指标的一致化处理(正向化处理)
一致化处理就是将评价指标的类型进行统一。一般来说,在评价指标体系中,可能会同时存在极大型指标(指指标越大越好的指标)、极小型指标(指指标越小越好的指标)、居中型指标(指标值取一个中间值最好的指标)和区间型指标(指指标值取在某个区间内为最好的指标)。若指标体系中存在不同类型的指标,必须在综合评价之前将评价指标的类型做一致化处理。例如,将各类指标都转化为极大型指标,或极小型指标。一般的做法是将非极大型指标转化为极大型指标。

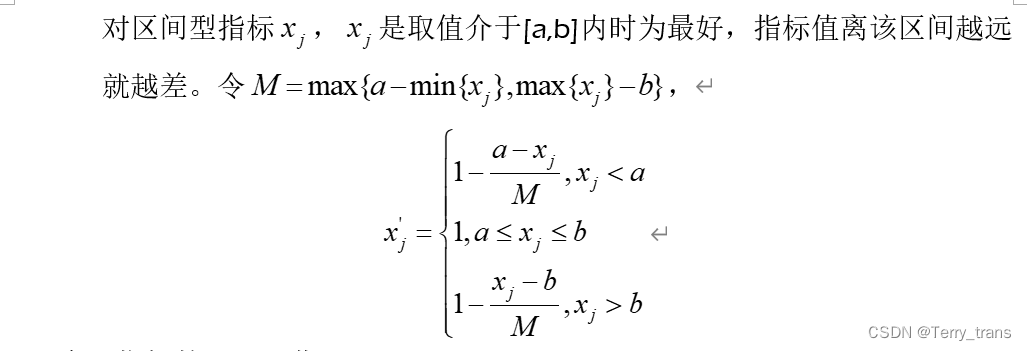
2.定量指标的无量纲化处理
通俗来说:就是矩阵的标准化(每一个数 /其所在列数的平方和的再开方)

二、熵权法(EWM)
在信息论中信息熵是信息不确定性的一种度量。
熵值法是一种依据各指标值所包含的信息量的多少确定指标权重的客观赋权法,某个指标的熵越小,说明该指标值的变异程度越大,提供的信息量也就越多,在综合评价中起的作用越大,则该指标的权重也应越大。
熵值法可单独进行综合评价;也可以与其他方法相结合,如TOPSIS法,用熵值法确定各指标的权重,然后运用TOPSIS法得到各个评价对象的综合得分。用熵值法确定权重就是所谓的熵权法。


三、TOPSIS法
TOPSIS法是理想解的排序方法(Technique for Order Preference by Similarity to Ideal Solution)的英文缩写。它借助于评价问题的正理想解和负理想解,对各评价对象进行排序。
正理想解是一个虚拟的最佳对象,其每个指标值都是多所有评价对象中该指标的最好值;
而负理想解则是另一个虚拟的最差对象,其每个指标都是评价对象中该指标的最差值。求出各评价对象与正理想解和负理想解的距离,并以此对评价对象进行优劣排序。



四、熵权法-TOPSIS的使用流程
以美赛O奖论文为例:来自美赛2023E Team # 2307336

- 导入数据
- 正向化
- 无量纲化
- 得出正负理想解
- EWM熵权法计算权重
- TOPSIS计算加权相对距离和相对接近度
- 排序、得出结论、画图描述结果
案例:熵权法-TOPSIS的案例分析:水质评价
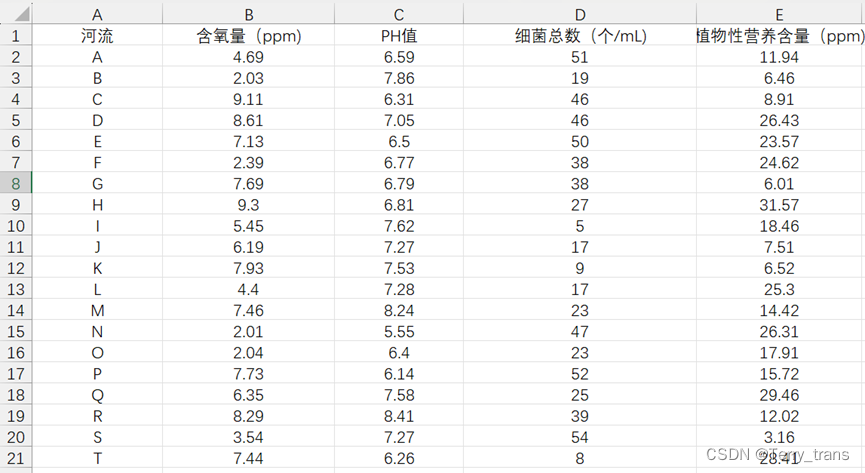
案例描述:一共20条河流从A-T排序,其中含氧量(极大化指标), PH值(中间型指标,近7越好), 细菌总数(极小指标), 植物性营养含量 (【10,20】区间型指标),使用合适的方法评价河流水质。
(一)数据导入
import pandas as pd
data = pd.read_excel(r"data.xlsx")
(二)指标一致化处理(正向化)

# 1.最小化指标极大化 细菌总数
data["细菌总数_极大化"] = data["细菌总数(个/mL)"].apply(lambda x : max(data["细菌总数(个/mL)"]) - x)


# 2.居中型转化为极大型指标 PH值 7
PH_M = max(abs(data["PH值"] - 7))
data["PH值_极大化"] = data["PH值"].apply(lambda x: 1 - abs(x - 7) / PH_M)

# 3.区间型转化为极大型指标 植物性营养含量(ppm)
nutrition_Max = max(data["植物性营养含量(ppm)"])
nutrition_min = min(data["植物性营养含量(ppm)"])
nutrition_M = max(10 - nutrition_min, nutrition_Max - 20)
data['植物性营养含量_极大化'] = data["植物性营养含量(ppm)"].apply(lambda x: 1 - (10 - x) / nutrition_M if x < 10 else (1 - (x - 20) / nutrition_M if x >20 else 1))
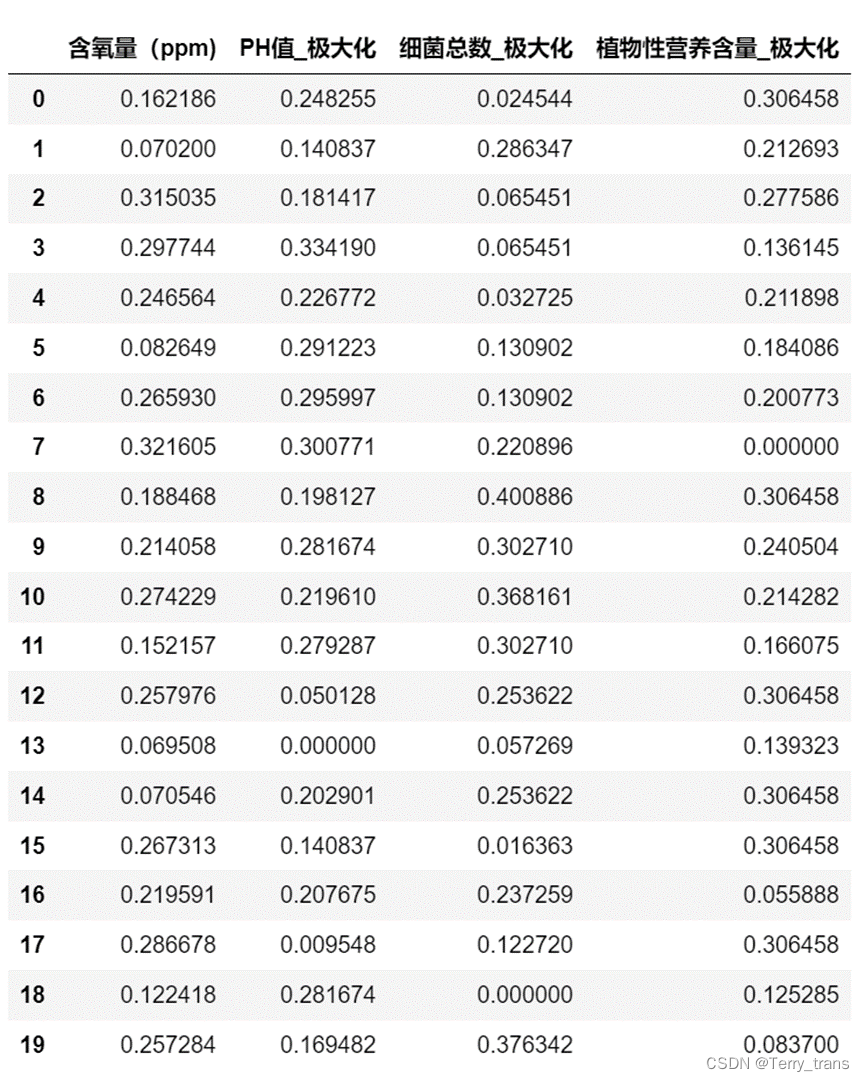
(三)指标的无量纲化处理

import numpy as np
normalized_data = data.loc[:,["含氧量(ppm)","PH值_极大化","细菌总数_极大化","植物性营养含量_极大化"]]# 将每一列的每一个数除以该列所有数的平方和再开方
for column in normalized_data.columns:squared_sum = np.square(normalized_data[column]).sum() normalized_data[column] = normalized_data[column] / np.sqrt(squared_sum)
(四)确定正负理想解

# 确定正负理想解
C_positive = [max(normalized_data[i]) for i in list(normalized_data.columns)]
C_negative = [min(normalized_data[i]) for i in list(normalized_data.columns)]

(五)熵权法确定权重

# 计算特征比重
normalized_data["P_含氧量"] = normalized_data["含氧量(ppm)"].apply(lambda x: x / sum(normalized_data["含氧量(ppm)"]))
normalized_data["P_PH值"] = normalized_data["PH值_极大化"].apply(lambda x: x / sum(normalized_data["PH值_极大化"]))
normalized_data["P_细菌总数"] = normalized_data["细菌总数_极大化"].apply(lambda x: x / sum(normalized_data["细菌总数_极大化"]))
normalized_data["P_植物性营养含量"] = normalized_data["植物性营养含量_极大化"].apply(lambda x: x / sum(normalized_data["植物性营养含量_极大化"]))
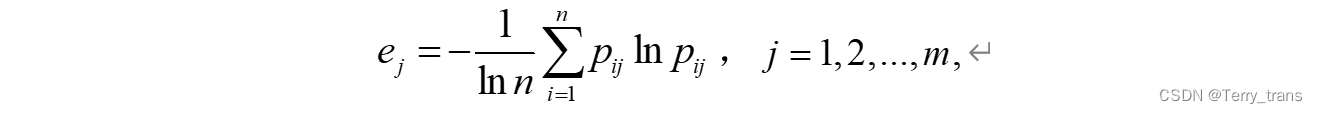
# 计算每个指标的信息熵
import math
e_1 = - (1 / math.log(20)) * sum(normalized_data["P_含氧量"].apply(lambda x: x * (math.log(x + 0.0000001))))
e_2 = - (1 / math.log(20)) * sum(normalized_data["P_PH值"].apply(lambda x: x * (math.log(x + 0.0000001))))
e_3 = - (1 / math.log(20)) * sum(normalized_data["P_细菌总数"].apply(lambda x: x * (math.log(x + 0.0000001))))
e_4 = - (1 / math.log(20)) * sum(normalized_data["P_植物性营养含量"].apply(lambda x: x * (math.log(x + 0.0000001))))
e = [e_1, e_2, e_3, e_4]

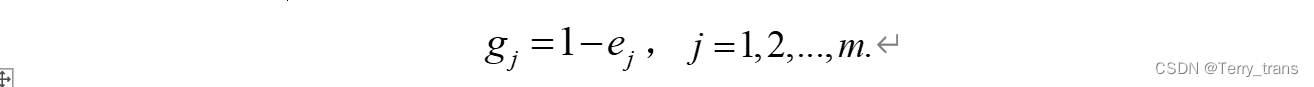
# 计算信息效用值
d = [1 - e_i for e_i in e]

# 信息效用值归一化 - 得到四个指标的权重
w = [d_i / sum(d) for d_i in d]
(六)TOPSIS计算综合评分

# 计算正负理想解距离
normalized_data_copy = normalized_data.iloc[:,:4]
w = np.array(w) # 权重矩阵
C_positive = np.array(C_positive) # 正理想解
C_negative = np.array(C_negative) # 负理想解
normalized_data['dist_to_C_positive'] = normalized_data_copy.apply(lambda row: np.sqrt(np.sum(np.square((row - C_positive) * w))), axis=1)
normalized_data['dist_to_C_negative'] = normalized_data_copy.apply(lambda row: np.sqrt(np.sum(np.square((row - C_negative) * w))), axis=1)

# 计算相对接近度
normalized_data['f'] = normalized_data['dist_to_C_negative'] / (normalized_data['dist_to_C_negative'] + normalized_data['dist_to_C_positive'])
(七)结果的分析及绘图
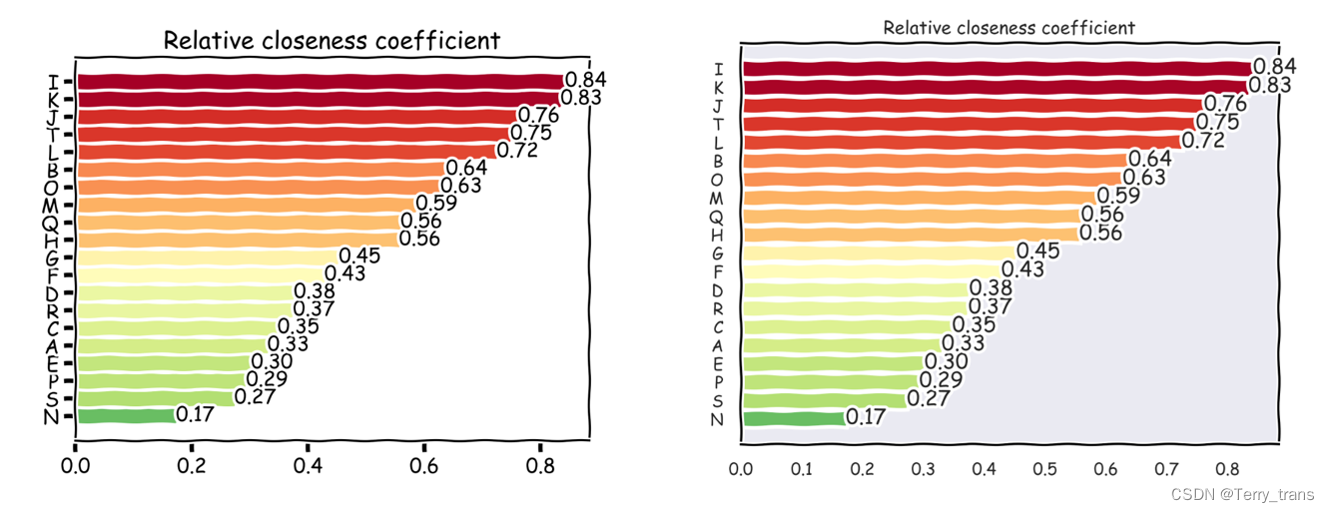
使用柱状图,描述相对接近度即水质质量评分的情况。可以看出河流I、河流K水质最为良好,河流N水质最差,排名如图2
import matplotlib.pyplot as plt
import seaborn as sns
# 高清图像输出
%config InlineBackend.figure_format = 'retina'
%matplotlib inline
# 设置Seaborn样式
sns.set()
# 对数据按照 "f" 列进行降序排序。
data_show = data_show.sort_values(by="f", ascending=True)
# 获取colormap
cmap = plt.cm.get_cmap("RdYlGn_r") # 颜色可变如tab20 RdYlGn_r等等
# 计算颜色
colors = cmap(data_show["f"].values / data_show["f"].values.max())
# 创建水平柱状图
with plt.xkcd():plt.barh(data_show["河流"], data_show["f"], color=colors)for i, (index, row) in enumerate(data_show.iterrows()):plt.text(row['f'], i, f"{row['f']:.2f}", va='center') # 将数据标签添加到条形图的右侧plt.title("Relative closeness coefficient")plt.show()
雷达图的使用:多维度评价,4-6维度效果较好。可以使用PPT进一步加工。
# 雷达图 需要添加正理想解
import plotly.graph_objects as go# # 数据映射到0-1区间(可选)
# from sklearn.preprocessing import MinMaxScaler
# scaler = MinMaxScaler()
# df_normalized = pd.DataFrame(scaler.fit_transform(normalized_data.iloc[:,:4]), columns=normalized_data.iloc[:,:4].columns)df_normalized = normalized_data.iloc[:,:4]
# 先进行拼接
df = pd.concat([data.iloc[:,0],df_normalized],axis=1)
# 然后添加新的行 "正理想解" 和 "负理想解"
df.loc["正理想解"] = ["正理想解"] + list(df.iloc[:, 1:].max())
df.loc["负理想解"] = ["负理想解"] + list(df.iloc[:, 1:].min())
# 定义属性
categories = ['含氧量(ppm)', 'PH值_极大化', '细菌总数_极大化', '植物性营养含量_极大化']
# 绘制雷达图
fig = go.Figure()
for i in range(len(df)):fig.add_trace(go.Scatterpolar(r=[df.iloc[i][col] for col in categories],theta=categories,fill='toself',name=f'河流 - {df.iloc[i]["河流"]}'))
fig.update_layout(polar=dict(radialaxis=dict(visible=True,)),showlegend=True
)
fig.update_layout(template = "presentation") # plotly_dark presentation plotly
fig.show()





![前沿重器[42] | self-RAG-大模型决策的典型案例探究](https://img-blog.csdnimg.cn/img_convert/9180d10a66419327b603b4f547c0f20e.png)
![第三节课[LangChain]作业](https://img-blog.csdnimg.cn/direct/d7a15989b04f4efc806cbd0b82e94ab5.png)