西瓜书&南瓜书笔记集
绪论
-
属性张成的空间为属性空间、样本空间或输入空间,一个示例称为一个特征向量。
-
有d个属性描述的示例是d维样本空间中的一个向量。
-
学得模型对应了关于数据的某种潜在规律称为假设,拥有了标记信息的示例称为样例。
-
通常假设获得的每个样本都是独立同分布的从一个未知分布。
-
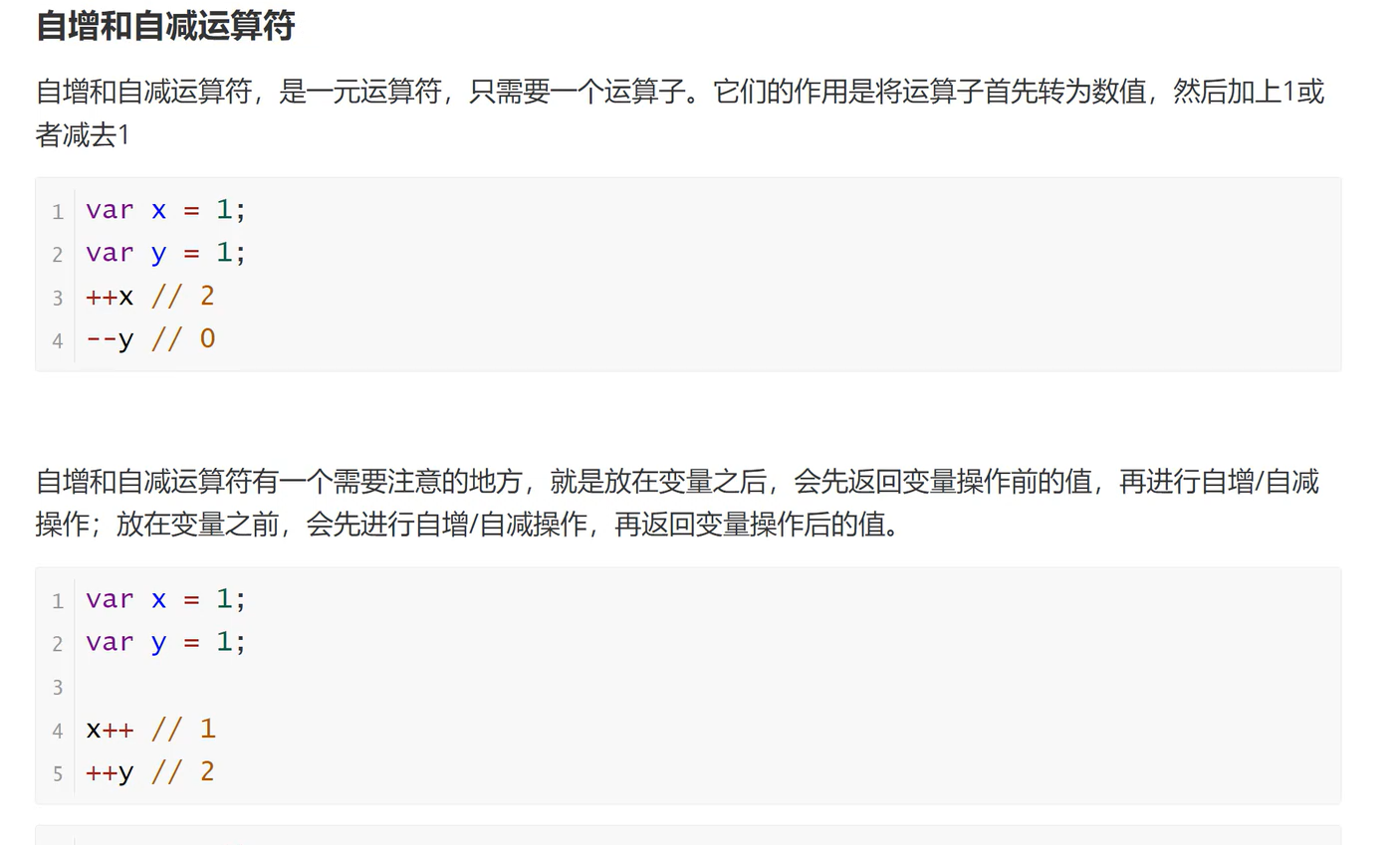
归纳是特殊到一般的泛化,演绎是一般到特殊的特化,狭义的归纳学习是从训练数据中学得概念,即概念学习。
-
学习是一个在所有假设组成的空间中进行搜索的过程,搜索目标是找到与训练集匹配(fit)的假设。
-
存在着一个与训练集一致的假设集合,即版本空间。
-
机器学习算法在学习过程中对某种类型假设的偏好,即归纳偏好;任何一个有效的机器学习算法必有其归纳偏好。
-
归纳偏好可以看作学习算法在一个假设空间中对假设进行选择的启发式;奥卡姆剃刀原则是若有多个假设与观察一致,则选择最简单的那个。
-
算法的归纳偏好是否与问题匹配大部分时候直接决定了算法能否取得好的性能。
-
可证明误差与学习算法,聪明和笨拙的算法的期望性能相同,即没有免费的午餐定理(NFL),但前提是所有问题出现的机会相同或所有问题同等重要(真实目标函数均匀分布,不考虑对已有样本的拟合)(但实际很难有),即真实目标函数很难是均匀分布(即会对已有样本高度拟合)。
-
如果考虑所有潜在问题或者脱离具体问题,则所有学习算法一样好,针对具体问题学习算法的归纳偏好与问题相配最重要。
模型评估与选择
-
留出法一般使用分层抽样,以确保训练/测试集的划分尽可能保持数据分布的一致性,且要采用若干次随机划分+重复实验评估取平均,交叉验证法的本质是多次留出。
-
交叉验证的特化:留一法(LOO)的评估结果往往准确(未比其他评估方法更优准确),但数据集较大时开销较大。
-
自助法:从m大小的数据集中随机挑选样本拷贝放入训练集,然后放回继续重复m次,最后会有约0.368m的样本未出现在训练集中,即得到训练集和测试集(称为包外估计)。
-
自助法在数据集较小、难以有效划分测试集时很有用,但划分方法改变了初始数据集的分布,引入了估计偏差。
-
一般向用户提交的模型应用所有样本训练而成。
-
查准率P(准确率)是指被学习器预测为正例的样例中有多大比例为真正例,真正例TP/真正例TP+假正例FP;查全率R(召回率)是指所有正例中有多大比例被学习器预测为正例,真正例TP/真正例TP+假反例FN;PR是一对矛盾的度量。
-
对所有样本的正例置信度排序,然后逐个样本阈值选择划分正负例(逐逐渐改变阈值作x轴),最终得到P-R图(查准率-召回率图);若一个学习器的P-R曲线被另一个学习器完全包住,则可断言后者性能优于前者。
-
在查准率P=查全率R时,可以得到平衡点BEP,当曲线交叉时,可以根据曲线下面积或BEP值或\(F1\)度量(比BEP值更有效)或\(F_{\beta}\)的大小比较。
-
\(F1\)度量是查准率和查全率的平均调和,\(F_{\beta}\)度量则是加权平均调和,\(\beta\)为查全率对查准率的相对重要性(以1为界);调和平均相较于算数平均和几何平均更重视较小值(凸显缺点)。
-
执行多次训练测试或多个数据集上训练测试或执行多分类任务中两分类组合会产生多个二分类混淆矩阵。
-
在此多个混淆矩阵上进行考察可以有两种做法:
- 分别计算查准率和查全率再得平均,可获得宏查准率(macro-P)、宏查全率和宏F1;
- 分别将各混淆矩阵的对应元素进行平均的4均值,再基于此计算出微查准率(micro-P)、微查全率和微F1。
宏没有考虑样本数量,平等看待各类;微考虑了样本数量,样本数量多的主导结果。