可能发生丢包的位置-linux配置项梳理(TCP连接的建立和断开、收发包过程)-SYN Flood攻击和防御原理
参考来源:
极客时间-Linux性能优化实战
极客时间-Linux内核技术实战课
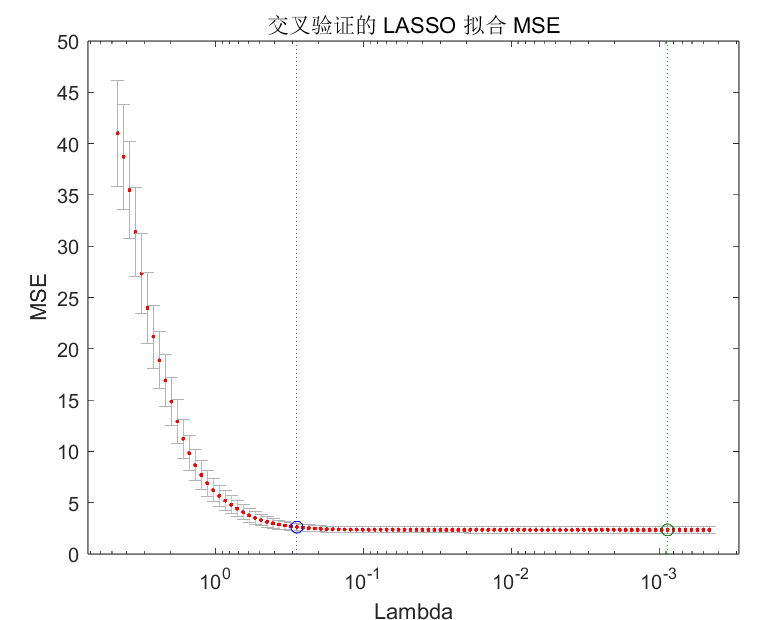
到底是哪里发生了丢包呢?
Linux 的网络收发流程

从图中你可以看出,可能发生丢包的位置,实际上贯穿了整个网络协议栈。换句话说,全程都有丢包的可能。比如我们从下往上看:
在两台 VM 连接之间,可能会发生传输失败的错误,比如网络拥塞、线路错误等;
在网卡收包后,环形缓冲区可能会因为溢出而丢包;
在链路层,可能会因为网络帧校验失败、QoS 等而丢包;
在 IP 层,可能会因为路由失败、组包大小超过 MTU 等而丢包;
在传输层,可能会因为端口未监听、资源占用超过内核限制等而丢包;
在套接字层,可能会因为套接字缓冲区溢出而丢包;
在应用层,可能会因为应用程序异常而丢包;
此外,如果配置了 iptables 规则,这些网络包也可能因为 iptables 过滤规则而丢包。
TCP连接建立和释放相关的问题描述
Client 为什么无法和 Server 建立连接呢?
三次握手都完成了,为什么会收到 Server 的 reset 呢?
建立 TCP 连接怎么会消耗这么多时间?
系统中为什么会有这么多处于 time-wait 的连接?该这么处理?
系统中为什么会有这么多 close-wait 的连接?
针对我的业务场景,这么多的网络配置项,应该要怎么配置呢?

TCP连接建立相关的 linux配置项梳理
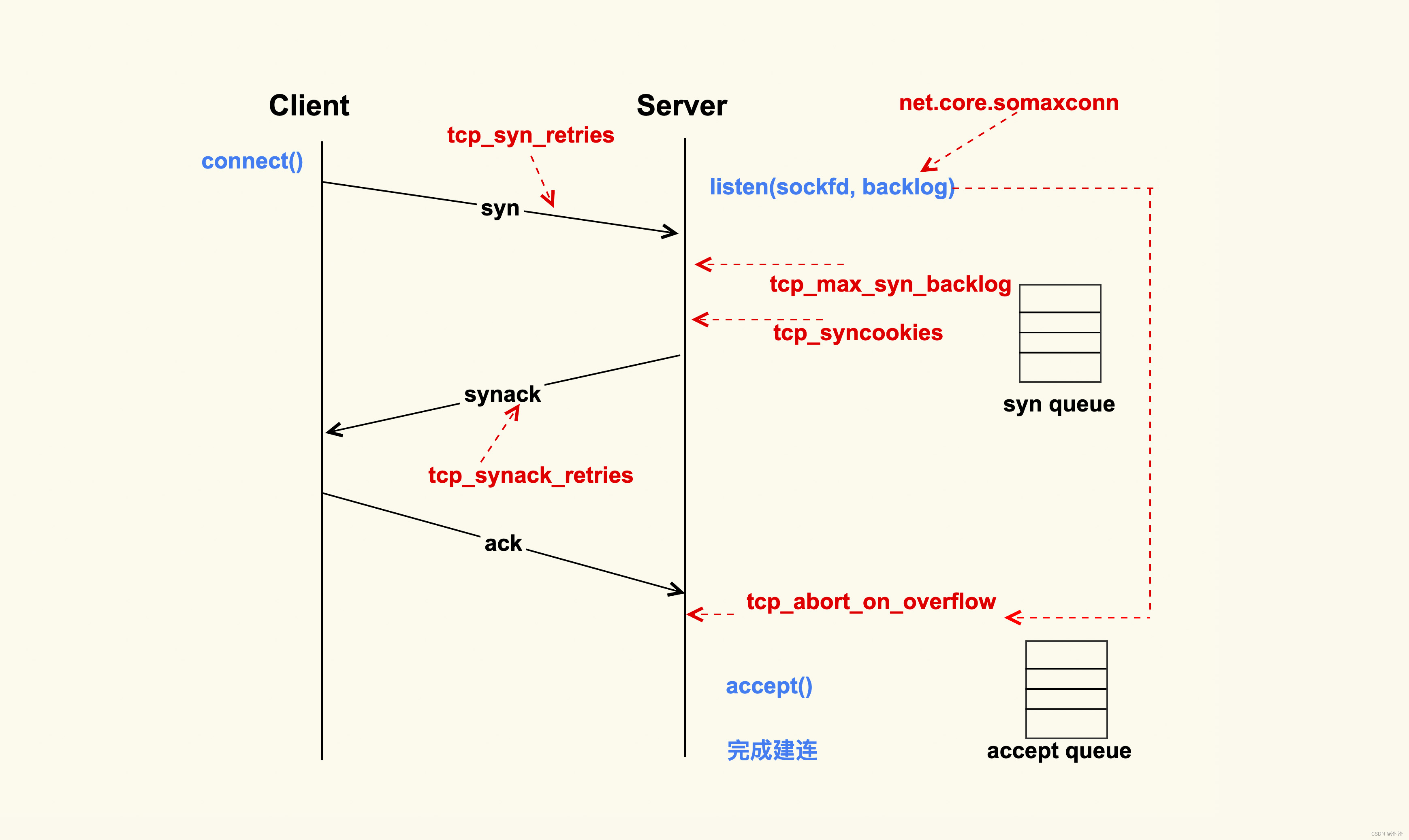
上图就是一个 TCP 连接的建立过程。TCP 连接的建立是一个从 Client 侧调用 connect(),
到 Server 侧 accept() 成功返回的过程。你可以看到,在整个 TCP 建立连接的过程中,各
个行为都有配置选项来进行控制。
Client 调用 connect() 后,Linux 内核就开始进行三次握手。’
首先 Client 会给 Server 发送一个 SYN 包,但是该 SYN 包可能会在传输过程中丢失,或
者因为其他原因导致 Server 无法处理,此时 Client 这一侧就会触发超时重传机制。但是
也不能一直重传下去,重传的次数也是有限制的,这就是 tcp_syn_retries 这个配置项来决
定的
假设 tcp_syn_retires 为 3,那么 SYN 包重传的策略大致如下:
在 Client 发出 SYN 后,如果过了 1 秒 ,还没有收到 Server 的响应,那么就会进行第一
次重传;如果经过 2s 的时间还没有收到 Server 的响应,就会进行第二次重传;一直重传
tcp_syn_retries 次。
对于 tcp_syn_retries 为 3 而言,总共会重传 3 次,也就是说从第一次发出 SYN 包后,会
一直等待(1 + 2 + 4 + 8)秒,如果还没有收到 Server 的响应,connect() 就会产生
ETIMEOUT 的错误。
tcp_syn_retries 的默认值是 6,也就是说如果 SYN 一直发送失败,会在(1 + 2 + 4 + 8
- 16+ 32 + 64)秒,即 127 秒后产生 ETIMEOUT 的错误。
所以通常情况下,我们都会将数据中心内部服务器的 tcp_syn_retries 给调小,这里推荐
设置为 2,来减少阻塞的时间。因为对于数据中心而言,它的网络质量是很好的,如果得
不到 Server 的响应,很可能是 Server 本身出了问题。在这种情况下,Client 及早地去尝
试连接其他的 Server 会是一个比较好的选择。
如果 Server 没有响应 Client 的 SYN,除了我们刚才提到的 Server 已经不存在了这种情况
外,还有可能是因为 Server 太忙没有来得及响应,或者是 Server 已经积压了太多的半连
接(incomplete)而无法及时去处理。
半连接,即收到了 SYN 后还没有回复 SYNACK 的连接,Server 每收到一个新的 SYN
包,都会创建一个半连接,然后把该半连接加入到**半连接队列(syn queue)**中。syn
queue 的长度就是 tcp_max_syn_backlog 这个配置项来决定的,当系统中积压的半连接
个数超过了该值后,新的 SYN 包就会被丢弃。对于服务器而言,可能瞬间会有非常多的新
建连接,所以我们可以适当地调大该值,以免 SYN 包被丢弃而导致 Client 收不到
SYNACK:
net.ipv4.tcp_max_syn_backlog = 16384
Server 中积压的半连接较多,也有可能是因为有些恶意的 Client 在进行 SYN Flood 攻
击。
Server 向 Client 发送的 SYNACK 包也可能会被丢弃,或者因为某些原因而收不到 Client
的响应,这个时候 Server 也会重传 SYNACK 包。同样地,重传的次数也是由配置选项来
控制的,该配置选项是 tcp_synack_retries。
它在系统中默认是 5,对于数据中心的服务器而言,通常都不需要
这么大的值,推荐设置为 2 :
net.ipv4.tcp_synack_retries = 2
Client 在收到 Serve 的 SYNACK 包后,就会发出 ACK,Server 收到该 ACK 后,三次握
手就完成了,即产生了一个 TCP 全连接(complete),它会被添加到全连接队列
(accept queue)中。然后 Server 就会调用 accept() 来完成 TCP 连接的建立。
但是,就像半连接队列(syn queue)的长度有限制一样,全连接队列(accept queue)
的长度也有限制,目的就是为了防止 Server 不能及时调用 accept() 而浪费太多的系统资
源。
全连接队列(accept queue)的长度是由 listen(sockfd, backlog) 这个函数里的 backlog
控制的,而该 backlog 的最大值则是 somaxconn。somaxconn 在 5.4 之前的内核中,
默认都是 128(5.4 开始调整为了默认 4096),建议将该值适当调大一些:
net.core.somaxconn = 16384
当服务器中积压的全连接个数超过该值后,新的全连接就会被丢弃掉。Server 在将新连接
丢弃时,有的时候需要发送 reset 来通知 Client,这样 Client 就不会再次重试了。不过,
默认行为是直接丢弃不去通知 Client。至于是否需要给 Client 发送 reset,是由
tcp_abort_on_overflow 这个配置项来控制的,该值默认为 0,即不发送 reset 给
Client。推荐也是将该值配置为 0:
net.ipv4.tcp_abort_on_overflow = 0
这是因为,Server 如果来不及 accept() 而导致全连接队列满,这往往是由瞬间有大量新建
连接请求导致的,正常情况下 Server 很快就能恢复,然后 Client 再次重试后就可以建连
成功了。也就是说,将 tcp_abort_on_overflow 配置为 0,给了 Client 一个重试的机会。
当然,你可以根据你的实际情况来决定是否要使能该选项。
accept() 成功返回后,一个新的 TCP 连接就建立完成了,TCP 连接进入到了
ESTABLISHED 状态,至此,Client 和 Server 两边就
可以正常通信了。
SYN Flood 攻击原理和应对
典型的 SYN Flood 攻击如下:Client 高频地向 Server 发 SYN 包,并且这个 SYN 包
的源 IP 地址不停地变换,那么 Server 每次接收到一个新的 SYN 后,都会给它分配一个半
连接,Server 的 SYNACK 根据之前的 SYN 包找到的是错误的 Client IP, 所以也就无法
收到 Client 的 ACK 包,导致无法正确建立 TCP 连接,这就会让 Server 的半连接队列耗
尽,无法响应正常的 SYN 包。
为了防止 SYN Flood 攻击,Linux 内核引入了 SYN Cookies 机制。SYN Cookie 的原理
是什么样的呢?
在 Server 收到 SYN 包时,不去分配资源来保存 Client 的信息,而是根据这个 SYN 包计
算出一个 Cookie 值,然后将 Cookie 记录到 SYNACK 包中发送出去。对于正常的连接,
该 Cookies 值会随着 Client 的 ACK 报文被带回来。然后 Server 再根据这个 Cookie 检查
这个 ACK 包的合法性,如果合法,才去创建新的 TCP 连接。通过这种处理,SYN
Cookies 可以防止部分 SYN Flood 攻击。所以对于 Linux 服务器而言,推荐开启 SYN
Cookies:
net.ipv4.tcp_syncookies = 1
##TCP连接断开相关的 linux配置项梳理
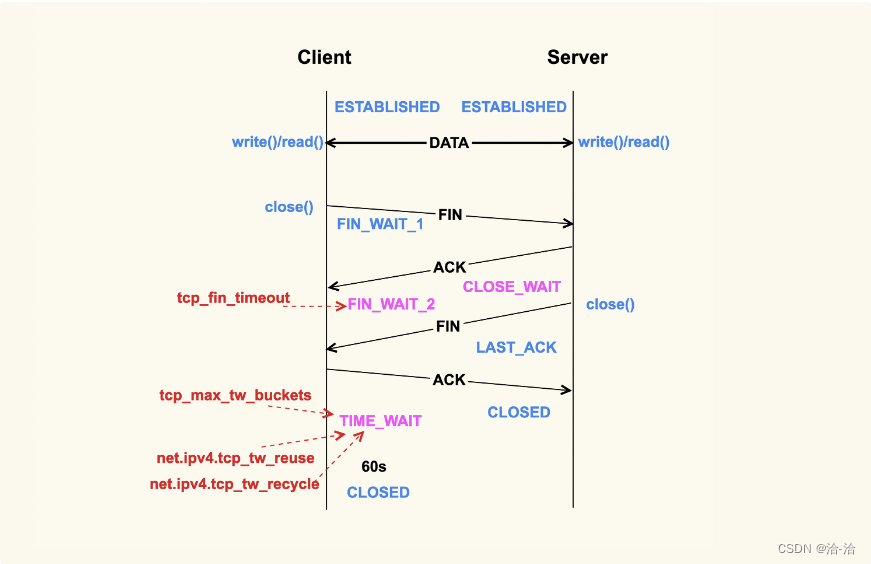
如上所示,当应用程序调用 close() 时,会向对端发送 FIN 包,然后会接收 ACK;对端也
会调用 clsoe() 来发送 FIN,然后本端也会向对端回 ACK,这就是 TCP 的四次挥手过程。
首先调用 close() 的一侧是 active close(主动关闭);而接收到对端的 FIN 包后再调用
close() 来关闭的一侧,称之为 passive close(被动关闭)。在四次挥手的过程中,有三
个 TCP 状态需要额外关注,就是上图中深红色的那三个状态:主动关闭方的 FIN_WAIT_2
和 TIME_WAIT,以及被动关闭方的 CLOSE_WAIT 状态。除了 CLOSE_WAIT 状态外,其
余两个状态都有对应的系统配置项来控制。
我们首先来看 FIN_WAIT_2 状态,TCP 进入到这个状态后,如果本端迟迟收不到对端的
FIN 包,那就会一直处于这个状态,于是就会一直消耗系统资源。Linux 为了防止这种资源
的开销,设置了这个状态的超时时间 tcp_fin_timeout,默认为 60s,超过这个时间后就会
自动销毁该连接。
至于本端为何迟迟收不到对端的 FIN 包,通常情况下都是因为对端机器出了问题,或者是
因为太繁忙而不能及时 close()。所以,通常我们都建议将 tcp_fin_timeout 调小一些,以
尽量避免这种状态下的资源开销。对于数据中心内部的机器而言,将它调整为 2s 足以
net.ipv4.tcp_fin_timeout = 2
我们再来看 TIME_WAIT 状态,TIME_WAIT 状态存在的意义是:最后发送的这个 ACK 包
可能会被丢弃掉或者有延迟,这样对端就会再次发送 FIN 包。如果不维持 TIME_WAIT 这
个状态,那么再次收到对端的 FIN 包后,本端就会回一个 Reset 包,这可能会产生一些异
常。
所以维持 TIME_WAIT 状态一段时间,可以保障 TCP 连接正常断开。TIME_WAIT 的默认
存活时间在 Linux 上是 60s(TCP_TIMEWAIT_LEN),这个时间对于数据中心而言可能还
是有些长了,所以有的时候也会修改内核做些优化来减小该值,或者将该值设置为可通过
sysctl 来调节。
TIME_WAIT 状态存在这么长时间,也是对系统资源的一个浪费,所以系统也有配置项来限
制该状态的最大个数,该配置选项就是 tcp_max_tw_buckets。对于数据中心而言,网络
是相对很稳定的,基本不会存在 FIN 包的异常,所以建议将该值调小一些:
net.ipv4.tcp_max_tw_buckets = 10000
Client 关闭跟 Server 的连接后,也有可能很快再次跟 Server 之间建立一个新的连接,而
由于 TCP 端口最多只有 65536 个,如果不去复用处于 TIME_WAIT 状态的连接,就可能
在快速重启应用程序时,出现端口被占用而无法创建新连接的情况。所以建议你打开复用
TIME_WAIT 的选项:
net.ipv4.tcp_tw_reuse = 1
还有另外一个选项 tcp_tw_recycle 来控制 TIME_WAIT 状态,但是该选项是很危险的,因
为它可能会引起意料不到的问题,比如可能会引起 NAT 环境下的丢包问题。所以建议将该
选项关闭:
net.ipv4.tcp_tw_recycle = 0
因为打开该选项后引起了太多的问题,所以在4.12版本的内核就索性删掉了这个配置选项.
对于 CLOSE_WAIT 状态而言,系统中没有对应的配置项。但是该状态也是一个危险信号,
如果这个状态的 TCP 连接较多,那往往意味着应用程序有 Bug,在某些条件下没有调用
close() 来关闭连接。我们在生产环境上就遇到过很多这类问题。所以,如果你的系统中存
在很多 CLOSE_WAIT 状态的连接,那你最好去排查一下你的应用程序,看看哪里漏掉了
close()。
TCP收发数据包相关的问题描述
网卡中断太多,占用太多 CPU,导致业务频繁被打断;
应用程序调用 write() 或者 send() 发包,怎么会发不出去呢;
数据包明明已经被网卡收到了,可是应用程序为什么没收到呢;
我想要调整缓冲区的大小,可是为什么不生效呢;
是不是内核缓冲区满了从而引起丢包,我该怎么观察呢;
TCP 数据包的发送过程
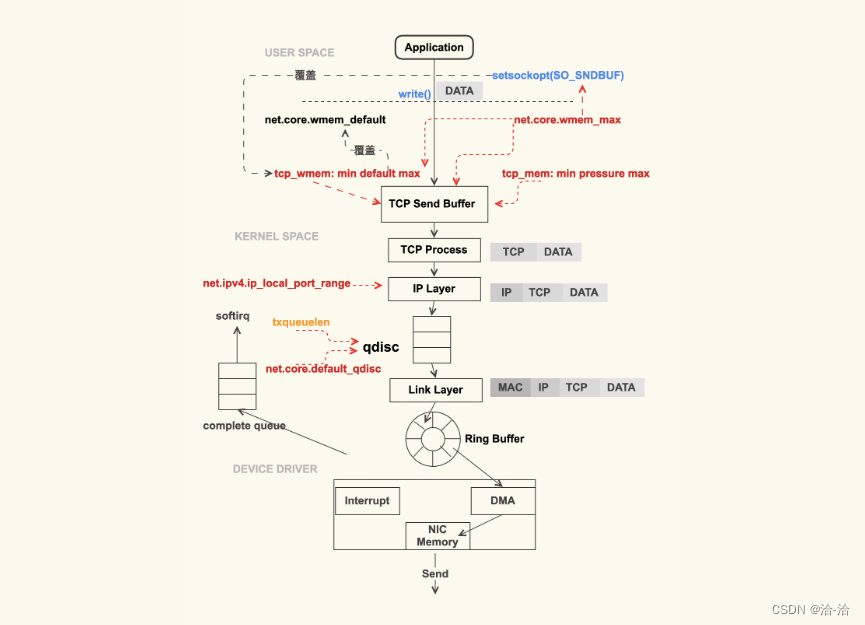
上图就是一个简略的 TCP 数据包的发送过程。应用程序调用 write(2) 或者 send(2) 系列系
统调用开始往外发包时,这些系统调用会把数据包从用户缓冲区拷贝到 TCP 发送缓冲区
(TCP Send Buffer),这个 TCP 发送缓冲区的大小是受限制的,这里也是容易引起问题
的地方。
TCP 发送缓冲区的大小默认是受 net.ipv4.tcp_wmem 来控制:
net.ipv4.tcp_wmem = 8192 65536 16777216
tcp_wmem 中这三个数字的含义分别为 min、default、max。TCP 发送缓冲区的大小会
在 min 和 max 之间动态调整,初始的大小是 default,这个动态调整的过程是由内核自动
来做的,应用程序无法干预。自动调整的目的,是为了在尽可能少的浪费内存的情况下来
满足发包的需要。
tcp_wmem 中的 max 不能超过 net.core.wmem_max 这个配置项的值,如果超过了,
TCP 发送缓冲区最大就是 net.core.wmem_max。通常情况下,我们需要设置
net.core.wmem_max 的值大于等于 net.ipv4.tcp_wmem 的 max:
net.core.wmem_max = 16777216
对于 TCP 发送缓冲区的大小,我们需要根据服务器的负载能力来灵活调整。通常情况下我
们需要调大它们的默认值,我上面列出的 tcp_wmem 的 min、default、max 这几组数值
就是调大后的值,也是我们在生产环境中配置的值。
应用程序有的时候会很明确地知道自己发送多大的数据,需要多大的 TCP 发送缓冲区,这
个时候就可以通过 setsockopt(2) 里的 SO_SNDBUF 来设置固定的缓冲区大小。一旦进行
了这种设置后,tcp_wmem 就会失效,而且这个缓冲区大小设置的是固定值,内核也不会
对它进行动态调整。
但是,SO_SNDBUF 设置的最大值不能超过 net.core.wmem_max,如果超过了该值,内
核会把它强制设置为 net.core.wmem_max。所以,如果你想要设置 SO_SNDBUF,一定
要确认好 net.core.wmem_max 是否满足需求,否则你的设置可能发挥不了作用。通常情
况下,我们都不会通过 SO_SNDBUF 来设置 TCP 发送缓冲区的大小,而是使用内核设置
的 tcp_wmem,因为如果 SO_SNDBUF 设置得太大就会浪费内存,设置得太小又会引起
缓冲区不足的问题。
另外,如果你关注过 Linux 的最新技术动态,你一定听说过 eBPF。你也可以通过 eBPF 来
设置 SO_SNDBUF 和 SO_RCVBUF,进而分别设置 TCP 发送缓冲区和 TCP 接收缓冲区的
大小。同样地,使用 eBPF 来设置这两个缓冲区时,也不能超过 wmem_max 和
rmem_max。不过 eBPF 在一开始增加设置缓冲区大小的特性时并未考虑过最大值的限
制。
tcp_wmem 以及 wmem_max 的大小设置都是针对单个 TCP 连接的,这两个值的单位都
是 Byte(字节)。系统中可能会存在非常多的 TCP 连接,如果 TCP 连接太多,就可能导
致内存耗尽。因此,所有 TCP 连接消耗的总内存也有限制:
net.ipv4.tcp_mem = 8388608 12582912 16777216
我们通常也会把这个配置项给调大。与前两个选项不同的是,该选项中这些值的单位是
Page(页数),也就是 4K。它也有 3 个值:min、pressure、max。当所有 TCP 连接消
耗的内存总和达到 max 后,也会因达到限制而无法再往外发包。
因 tcp_mem 达到限制而无法发包或者产生抖动的问题,我们也是可以观测到的。
TCP 层处理完数据包后,就继续往下来到了 IP 层。IP 层这里容易触发问题的地方是
net.ipv4.ip_local_port_range 这个配置选项,它是指和其他服务器建立 IP 连接时本地端
口(local port)的范围。我们在生产环境中就遇到过默认的端口范围太小,以致于无法创
建新连接的问题。所以通常情况下,我们都会扩大默认的端口范围:
net.ipv4.ip_local_port_range = 1024 65535
为了能够对 TCP/IP 数据流进行流控,Linux 内核在 IP 层实现了 qdisc(排队规则)。我
们平时用到的 TC 就是基于 qdisc 的流控工具。qdisc 的队列长度是我们用 ifconfig 来看
到的 txqueuelen,我们在生产环境中也遇到过因为 txqueuelen 太小导致数据包被丢弃的
情况,这类问题可以通过下面这个命令来观察:
Linux 系统默认的 qdisc 为 pfifo_fast(先进先出),通常情况下我们无需调整它。如果你
想使用TCP BBR来改善 TCP 拥塞控制的话,那就需要将它调整为 fq(fair queue, 公平
队列):
net.core.default_qdisc = fq
##TCP 数据包的接收过程
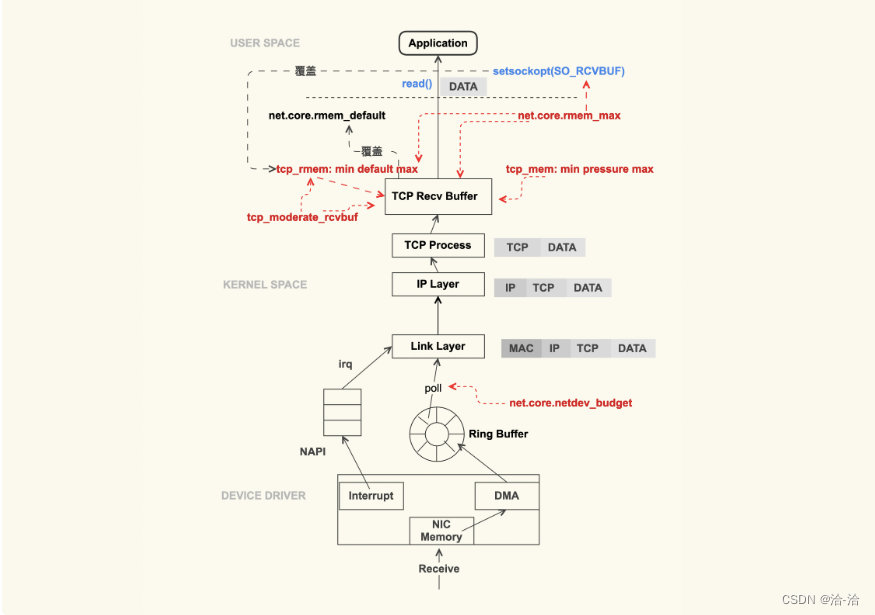
从上图可以看出,TCP 数据包的接收流程在整体上与发送流程类似,只是方向是相反的。
数据包到达网卡后,就会触发中断(IRQ)来告诉 CPU 读取这个数据包。但是在高性能网
络场景下,数据包的数量会非常大,如果每来一个数据包都要产生一个中断,那 CPU 的处
理效率就会大打折扣,所以就产生了 NAPI(New API)这种机制让 CPU 一次性地去轮询
(poll)多个数据包,以批量处理的方式来提升效率,降低网卡中断带来的性能开销。
那在 poll 的过程中,一次可以 poll 多少个呢?这个 poll 的个数可以通过 sysctl 选项来控
制:
net.core.netdev_budget = 600
该控制选项的默认值是 300,在网络吞吐量较大的场景中,我们可以适当地增大该值,比
如增大到 600。增大该值可以一次性地处理更多的数据包。但是这种调整也是有缺陷的,
因为这会导致 CPU 在这里 poll 的时间增加,如果系统中运行的任务很多的话,其他任务
的调度延迟就会增加。
接下来继续看 TCP 数据包的接收过程。我们刚才提到,数据包到达网卡后会触发 CPU 去
poll 数据包,这些 poll 的数据包紧接着就会到达 IP 层去处理,然后再达到 TCP 层,这时
就会面对另外一个很容易引发问题的地方了:TCP Receive Buffer(TCP 接收缓冲区)
通常情况下,默认都是使用 tcp_rmem 来控制缓冲区的大小。同样地,我们也会适当地增大这几个值的默认值,来
获取更好的网络性能,调整为如下数值:
net.ipv4.tcp_rmem = 8192 87380 16777216
它也有 3 个字段:min、default、max。TCP 接收缓冲区大小也是在 min 和 max 之间动
态调整 ,不过跟发送缓冲区不同的是,这个动态调整是可以通过控制选项来关闭的,这个
选项是 tcp_moderate_rcvbuf 。通常我们都是打开它,这也是它的默认值:
net.ipv4.tcp_moderate_rcvbuf = 1
之所以接收缓冲区有选项可以控制自动调节,而发送缓冲区没有,那是因为 TCP 接收缓冲
区会直接影响 TCP 拥塞控制,进而影响到对端的发包,所以使用该控制选项可以更加灵活
地控制对端的发包行为。
除了 tcp_moderate_rcvbuf 可以控制 TCP 接收缓冲区的动态调节外,也可以通过
setsockopt() 中的配置选项 SO_RCVBUF 来控制,这与 TCP 发送缓冲区是类似的。如果
应用程序设置了 SO_RCVBUF 这个标记,那么 TCP 接收缓冲区的动态调整就是关闭,即使
tcp_moderate_rcvbuf 为 1,接收缓冲区的大小始终就为设置的 SO_RCVBUF 这个值。
也就是说,只有在 tcp_moderate_rcvbuf 为 1,并且应用程序没有通过 SO_RCVBUF 来
配置缓冲区大小的情况下,TCP 接收缓冲区才会动态调节。
同样地,与 TCP 发送缓冲区类似,SO_RCVBUF 设置的值最大也不能超过
net.core.rmem_max。通常情况下,我们也需要设置 net.core.rmem_max 的值大于等于
net.ipv4.tcp_rmem 的 max:
net.core.rmem_max = 16777216