目录
一. 前言
二. 生产消息
三. 幂等和事务
四. send() 发送消息
五. 原理解析
一. 前言
Kafka生产者是一个应用程序,它负责向 Kafka 主题发送消息。这些消息可以用于多种目的,如记录用户活动、收集物联网设备数据、保存日志消息或缓存即将写入数据库的数据。
二. 生产消息
生产者是线程安全的,在线程之间共享单个生产者实例,通常单例比多个实例要快。
一个简单的例子,使用 Producer 发送一个有序的 key/value(键值对),放到 Java 的 main() 方法里就能直接运行(支持的版本 >= 0.9):
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(props);
for(int i = 0; i < 100; i++)producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));producer.close();生产者的缓冲空间池保留尚未发送到服务器的消息,后台 I/O 线程负责将这些消息转换成请求发送到集群。如果使用后不关闭生产者,则会丢失这些消息。
send() 方法是异步的,添加消息到缓冲区等待发送,并立即返回。生产者将单个的消息批量在一起发送来提高效率。
ack 是判别请求是否为完整的条件(就是判断是不是成功发送了)。我们指定了 all 将会阻塞消息,这种设置性能最低,但是是最可靠的。
retries,如果请求失败,生产者会自动重试,我们指定是0次,如果启用重试,则会有重复消息的可能性。
producer(生产者)缓存每个分区未发送的消息。缓存的大小是通过 batch.size 配置指定的。值较大的话将会产生更大的批次。并需要更多的内存(因为每个“活跃”的分区都有1个缓冲区)。
默认缓冲可立即发送,即便缓冲空间还没有满。但是,如果你想减少请求的数量,可以设置linger.ms 大于0。这将指示生产者发送请求之前等待一段时间,希望更多的消息填补到未满的批次中。这类似于 TCP 的算法,例如上面的代码段,可能100条消息在一个请求发送,因为我们设置了 linger(逗留)时间为1毫秒,然后,如果我们没有填满缓冲区,这个设置将增加1毫秒的延迟请求以等待更多的消息。需要注意的是,在高负载下,相近的时间一般也会组成批,即使是 linger.ms=0。在不处于高负载的情况下,如果设置比0大,以少量的延迟代价换取更少的、更有效的请求。
buffer.memory 控制生产者可用的缓存总量,如果消息发送速度比其传输到服务器的快,将会耗尽这个缓存空间。当缓存空间耗尽,其他发送调用将被阻塞,阻塞时间的阈值通过 max.block.ms设定,之后它将抛出一个 TimeoutException。
key.serializer 和 value.serializer 示例,将用户提供的 key 和 value 对象 ProducerRecord 转换成字节,你可以使用附带的 ByteArraySerializaer 或 StringSerializer 处理简单的 String 或 Byte 类型。
三. 幂等和事务
从 Kafka 0.11 开始,KafkaProducer 又支持两种模式:幂等生产者和事务生产者。幂等生产者加强了 Kafka 的交付语义,从至少一次交付到精确一次交付。特别是生产者的重试将不再引入重复。事务性生产者允许应用程序原子地将消息发送到多个分区(和主题)。
要启用幂等(idempotence),必须将 enable.idempotence 配置设置为 true。如果设置,则retries(重试)配置将默认为 Integer.MAX_VALUE,acks 配置将默认为 all。API 没有变化,所以无需修改现有应用程序即可利用此功能。
此外,如果 send(ProducerRecord) 即使在无限次重试的情况下也会返回错误(例如消息在发送前在缓冲区中过期),那么建议关闭生产者,并检查最后产生的消息的内容,以确保它不重复。最后,生产者只能保证单个会话内发送的消息的幂等性。
要使用事务生产者和 attendant API,必须设置 transactional.id。如果设置了 transactional.id,幂等性会和幂等所依赖的生产者配置一起自动启用。此外,应该对包含在事务中的 Topic 进行耐久性配置。特别是,replication.factor 应该至少是3,而且这些 Topic 的 min.insync.replicas 应该设置为2。最后,为了实现从端到端的事务性保证,消费者也必须配置为只读取已提交的消息。
transactional.id 的目的是实现单个生产者实例的多个会话之间的事务恢复。它通常是由分区、有状态的应用程序中的分片标识符派生的。因此,它对于在分区应用程序中运行的每个生产者实例来说应该是唯一的。
所有新的事务性 API 都是阻塞的,并且会在失败时抛出异常。下面的例子说明了新的 API 是如何使用的。它与上面的例子类似,只是所有100条消息都是一个事务的一部分。
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("transactional.id", "my-transactional-id");
Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());producer.initTransactions();try {producer.beginTransaction();for (int i = 0; i < 100; i++)producer.send(new ProducerRecord<>("my-topic", Integer.toString(i), Integer.toString(i)));producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {// We can't recover from these exceptions, so our only option is to close the producer and exit.producer.close();
} catch (KafkaException e) {// For all other exceptions, just abort the transaction and try again.producer.abortTransaction();
}
producer.close();如示例所示,每个生产者只能有一个未完成的事务。在 beginTransaction() 和commitTransaction() 调用之间发送的所有消息都将是单个事务的一部分。当指定 transactional.id时,生产者发送的所有消息都必须是事务的一部分。
事务生产者使用异常来传递错误状态。特别是,不需要为 producer.send() 指定回调,也不需要在返回的 Future 上调用 get()。如果任何 producer.send() 或事务性调用在事务过程中遇到不可恢复的错误,就会抛出 KafkaException。
该客户端可以与 0.10.0 或更高版本的 Broker 进行通信。旧的或较新的 Broker 可能不支持某些客户端功能。例如,事务性 API 需要 0.11.0 或更新版本的 Broker。当调用在运行的 Broker 版本中不可用的 API 时,您将收到 UnsupportedVersionException。
四. send() 发送消息
public Future<RecordMetadata> send(ProducerRecord<K,V> record,Callback callback)异步发送一条消息到 Topic,并调用 callback(当发送已确认)。语法说明如下:
参数:
- record:发送的记录(消息)。
- callback:用户提供的 callback,服务器调用这个 callback 来应答结果(null 表示没有callback)。
声明的异常:
- InterruptException:如果线程阻塞中断。
- SerializationException:如果 key 或 value 不是给定有效配置的 serializers。
- TimeoutException:如果获取元数据或消息分配内存花费的时间超过 max.block.ms。
- KafkaException:Kafka 有关的错误(不属于公共 API 的异常)。
send() 是异步的,并且一旦消息被保存在等待发送的消息缓存中,此方法就立即返回。这样并行发送多条消息而不阻塞去等待每一条消息的响应。
发送的结果是一个 RecordMetadata,它指定了消息发送的分区,分配的 offset 和消息的时间戳。如果 Topic 使用的是 CreateTime,则使用用户提供的时间戳或发送的时间(如果用户没有指定指定消息的时间戳)如果 Topic 使用的是 LogAppendTime,则追加消息时,时间戳是 Broker 的本地时间。
由于 send() 调用是异步的,它将为此消息的 RecordMetadata 返回一个 Future。如果 future 调用 get(),则将阻塞,直到相关请求完成并返回该消息的 metadata,或抛出发送异常。
如果要模拟一个简单的阻塞调用,你可以调用 get() 方法:
byte[] key = "key".getBytes();
byte[] value = "value".getBytes();
ProducerRecord<byte[],byte[]> record = new ProducerRecord<byte[],byte[]>("my-topic", key, value)
producer.send(record).get();完全无阻塞的话,可以利用回调参数提供的请求完成时将调用的回调通知:
ProducerRecord<byte[],byte[]> record = new ProducerRecord<byte[],byte[]>("the-topic", key, value);
producer.send(myRecord,new Callback() {public void onCompletion(RecordMetadata metadata, Exception e) {if(e != null)e.printStackTrace();System.out.println("The offset of the record we just sent is: " + metadata.offset());}});发送到同一个分区的消息回调保证按一定的顺序执行,也就是说,在下面的例子中 callback1 保证执行在 callback2 之前:
producer.send(new ProducerRecord<byte[],byte[]>(topic, partition, key1, value1), callback1);producer.send(new ProducerRecord<byte[],byte[]>(topic, partition, key2, value2), callback2);注意:callback 一般在生产者的 I/O 线程中执行,所以是相当快的,否则将延迟其他的线程的消息发送。如果你需要执行阻塞或计算昂贵(消耗)的回调,建议在 callback 主体中使用自己的Executor 来并行处理。
五. 原理解析
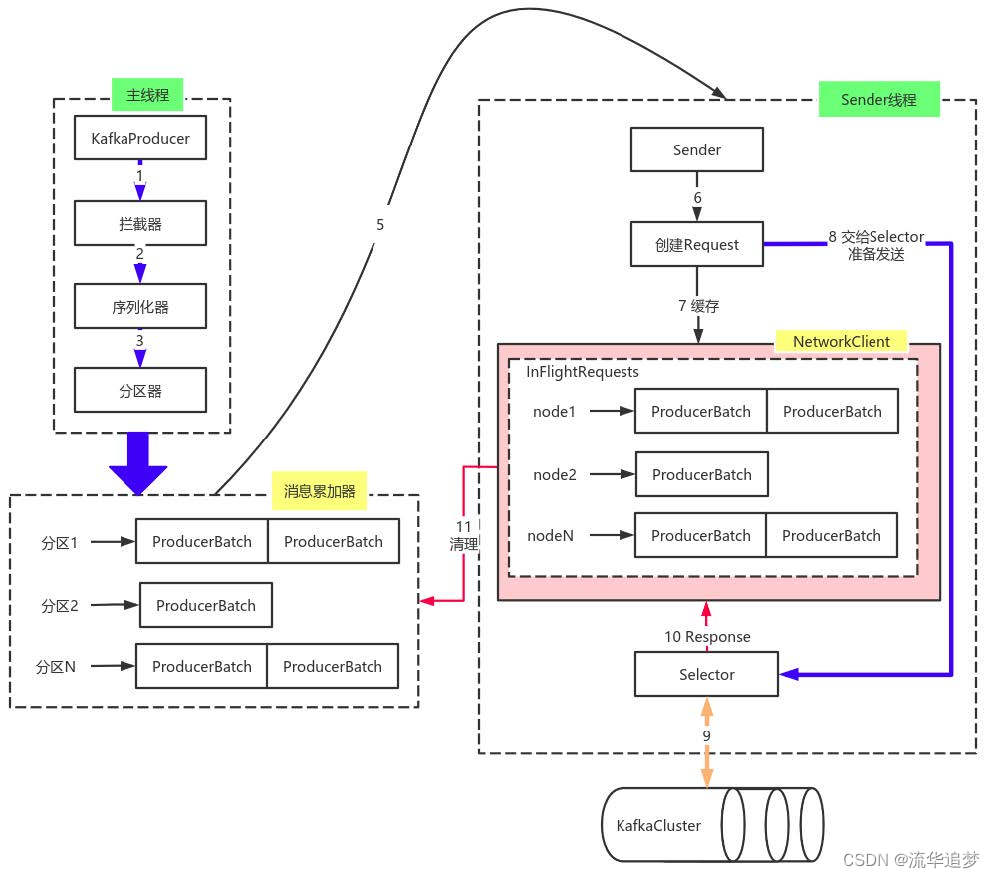
由上图可以看出:KafkaProducer 有两个基本线程:
1. 主线程:负责消息创建、拦截器、序列化器、分区器等操作,并将消息追加到消息收集器RecoderAccumulator 中;
- 消息收集器 RecoderAccumulator 为每个分区都维护了一个 Deque<ProducerBatch> 类型的双端队列。
- ProducerBatch 可以理解为是 ProducerRecord 的集合,批量发送有利于提升吞吐量,降低网络影响。
- 由于生产者客户端使用 java.io.ByteBuffer 在发送消息之前进行消息保存,并维护了一个 BufferPool 实现 ByteBuffer 的复用。该缓存池只针对特定大小(batch.size 指定)的 ByteBuffer 进行管理,对于消息过大的缓存,不能做到重复利用。
- 每次追加一条 ProducerRecord 消息,会寻找/新建对应的双端队列,从其尾部获取一个ProducerBatch,判断当前消息的大小是否可以写入该批次中。若可以写入则写入;若不可以写入,则新建一个 ProducerBatch,判断该消息大小是否超过客户端参数配置 batch.size 的值,不超过,则以 batch.size 建立新的 ProducerBatch,这样方便进行缓存重复利用;若超过,则以计算的消息大小建立对应的 ProducerBatch ,缺点就是该内存不能被复用了。
2. Sender线程:
- 该线程从消息收集器获取缓存的消息,将其处理为 <Node, List<ProducerBatch> 的式,Node 表示集群的 Broker 节点。
- 进一步将 <Node, List<ProducerBatch> 转化为 <Node, Request> 形式,此时才可以向服务端发送数据。
- 在发送之前,Sender 线程将消息以 Map<NodeId, Deque<Request>> 的形式保存到InFlightRequests 中进行缓存,可以通过其获取 leastLoadedNode,即当前 Node 中负载压力最小的一个,以实现消息的尽快发出。