DataX简介
- 一、什么是DataX
- 二、DataX设计
- 三、支持的数据源
- 四、框架设计
- 五、运行原理
- 六、DataX和Sqoop对比
一、什么是DataX
- DataX是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
- DataX的github地址:https://github.com/alibaba/DataX
二、DataX设计
- 为了解决异构数据源同步问题,DataX 将复杂的网状的同步链路变成了星型数据链路,DataX 作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到 Datax,便能跟已有的数据源做到无缝数据同步。
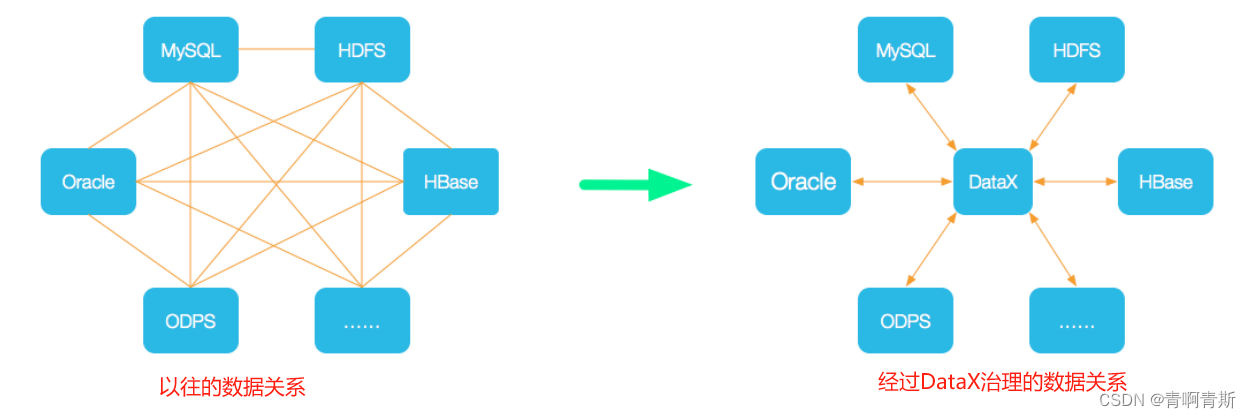
- DataX的设计理念是插件式的,这样后续有新的数据库,对源码改动是很少的。
- 对于一个数据的驱动分为两种:writer和reader
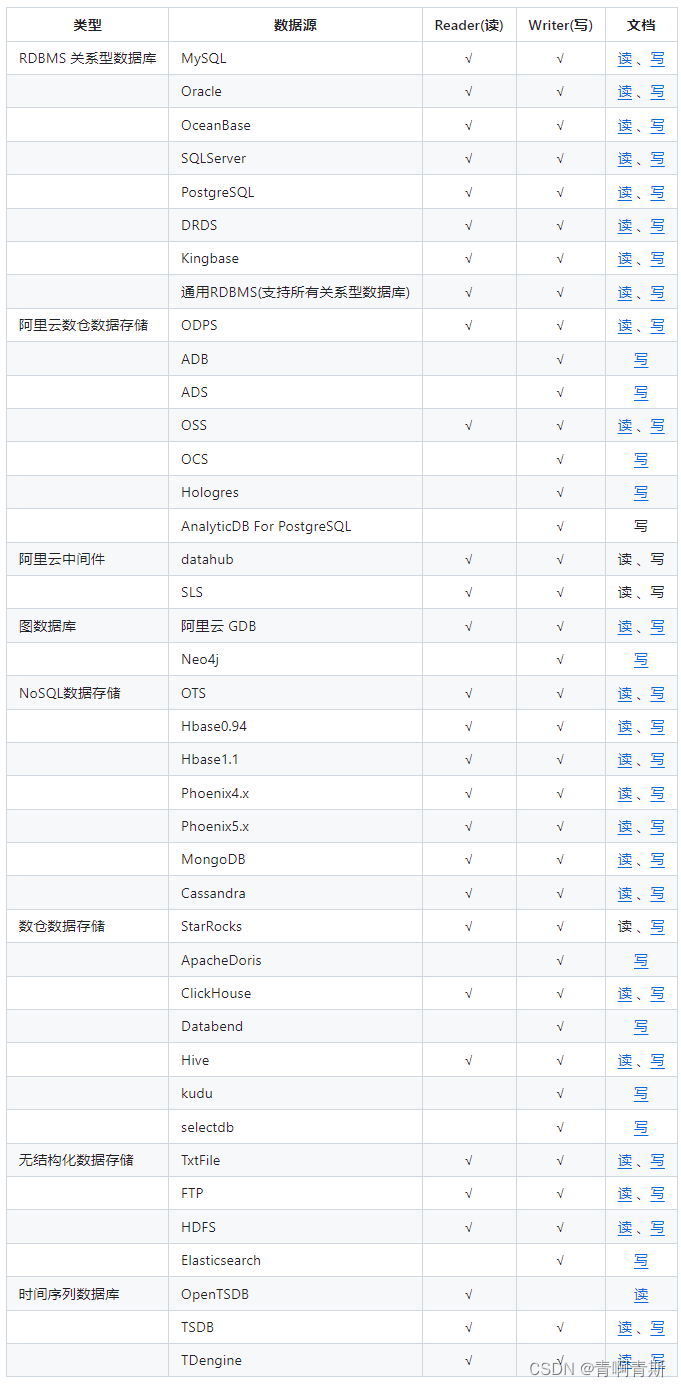
三、支持的数据源
- 对于文档那一列,官网给出了 读和写的配置案例和参数描述
四、框架设计

- Reader:数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer:数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
五、运行原理
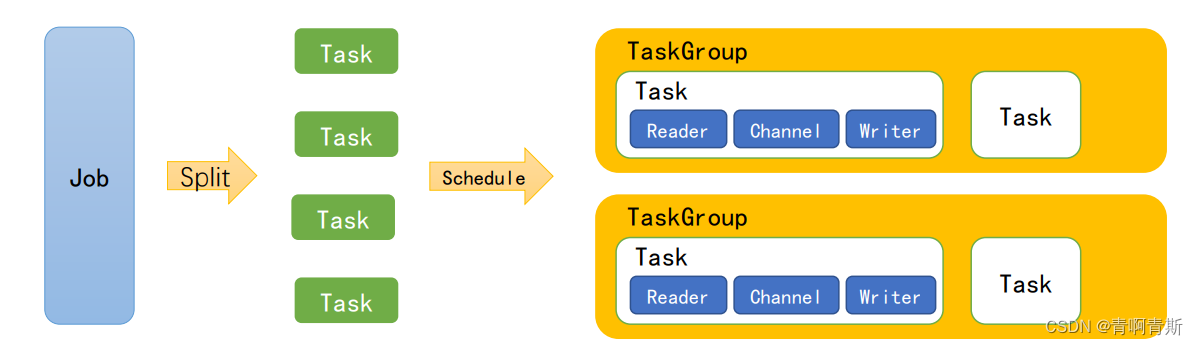
- 模块说明:
- Job:单个作业的管理节点,负责数据清理、子任务划分、TaskGroup监控管理。
- Task:由Job切分而来,是DataX作业的最小单元,每个Task负责一部分数据的同步工作。
- Schedule:将Task组成TaskGroup,单个TaskGroup的并发数量为5。
- TaskGroup:负责启动Task。
- 举例
- 举例来说,用户提交了一个 DataX 作业,并且配置了 20 个并发,目的是将一个 100 张
分表的 mysql 数据同步到 odps 里面。 DataX 的调度决策思路是:- 第一步:DataXJob 根据分库分表切分成了 100 个 Task。
- 第二步:根据 20 个并发,DataX 计算共需要分配 4 个 TaskGroup。
- 第三步:4 个 TaskGroup 平分切分好的 100 个 Task,每一个 TaskGroup 负责以 5 个并发共计运行 25 个 Task。
- 举例来说,用户提交了一个 DataX 作业,并且配置了 20 个并发,目的是将一个 100 张
六、DataX和Sqoop对比
| 功能 | DataX | Sqoop |
|---|---|---|
| 运行模式 | 单进程多线程 | MR(分布式) |
| MySQL读写 | 单机压力大; 读写力度容易控制; | MR模式重,写出错处理麻烦 |
| Hive读写 | 单机压力大 | 很好 |
| 文件格式 | orc支持 | orc不支持,可添加 |
| 分布式 | 不支持,可以通过调度系统规避 | 支持 |
| 流控 | 有流控功能 | 需要定制 |
| 统计信息 | 已有一些统计,上报需定制 | 没有,分布式的数据收集不方便 |
| 数据校验 | 在core部分有校验功能 | 没有,分布式的数据手机不方便 |
| 监控 | 需要定制 | 需要定制 |
![linux信号机制[一]](https://img-blog.csdnimg.cn/direct/30d249e454374316adf51e33c7f72e06.png)