🌈个人主页: 会编程的果子君
💫个人格言:“成为自己未来的主人~”

上一小节我们实现了一个网页的整体抓取工作,那么本小节,给各位好好剖析一下web请求的全部过程,这样有助于后面我们遇到的各种各样的网站就有了入手的基本准则了
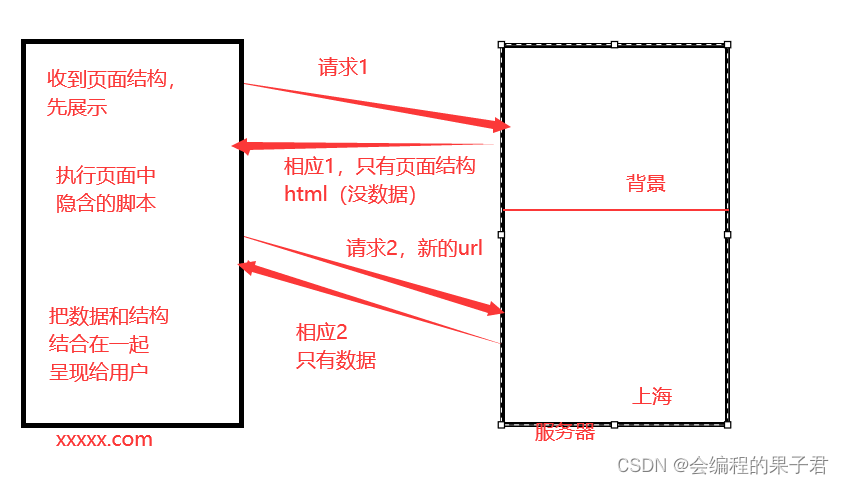
那么到底我们浏览器在输入完网址到我们看到网页的整体内容,这个过程究竟发生了写什么?
这里我们以百度为例,在访问百度的时候,浏览器会把这一次的请求发送给百度的服务器(百度的一台电脑 ),由服务器接收到这个请求,然后加载一些数据,返回给浏览器,再由浏览器进行显示,听起来好像是个废话......但是这里蕴含着一个极为重要的东西在里面,注意,百度的服务器返回给浏览器的不直接是页面,而是页面源代码(有html,css,js组成)由浏览器把页面源代码进行执行,然后把执行之后的结果展示给用户,所以我们能看到在上一届的内容中,我们拿到的是百度的源代码(就是那堆看不懂的鬼东西),具体过程如图:

接下来就是一个比较重要的事情了,所有的数据都在页面源代码里么,非也~这里要介绍一个新的概念。
那就是页面渲染数据的过程,我们常见的页面渲染过程有两种
1.服务器渲染
这个最容易理解,也是最简单的,含义呢就是我们在请求到服务器的时候,服务器直接把数据全部写入到html中,我们浏览器就能直接拿到带有数据的html内容,比如:

由于数据是直接写到html当中的,所以我们能看到的数据都在页面源代码中能找的到的
这种网页一般都相对比较容易就能抓取到页面内容。
2.前段JS渲染
这种就稍显麻烦,这种机制一般是第一次请求服务器返回一堆HTML框架结构,然后再次请求到真正保存数据的服务器,由这个服务器返回数据,最后在浏览器丧对数据进行加载。
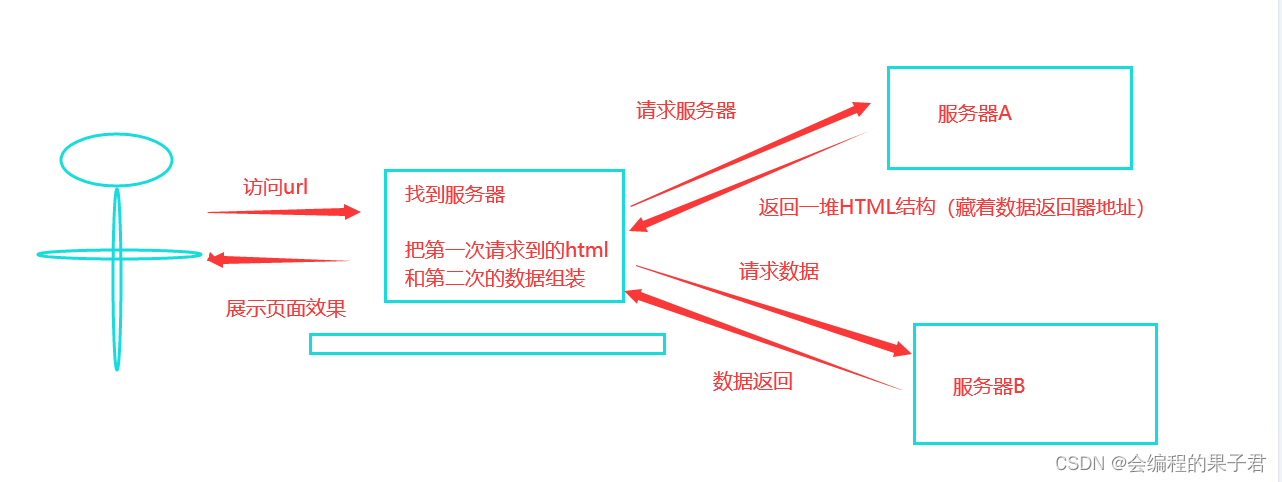
这样做的好处是服务器那边能缓解压力,而且分工明确,比较容易维护,典型的有这么一个网页
 那数据是何时加载进来的呢,其实就是在我们页面向下滚动的时候,JD就在偷偷的加载数据了,此时想要看到这个页面的加载全过程,我们就需要借助浏览器的调试工具(F12)
那数据是何时加载进来的呢,其实就是在我们页面向下滚动的时候,JD就在偷偷的加载数据了,此时想要看到这个页面的加载全过程,我们就需要借助浏览器的调试工具(F12)
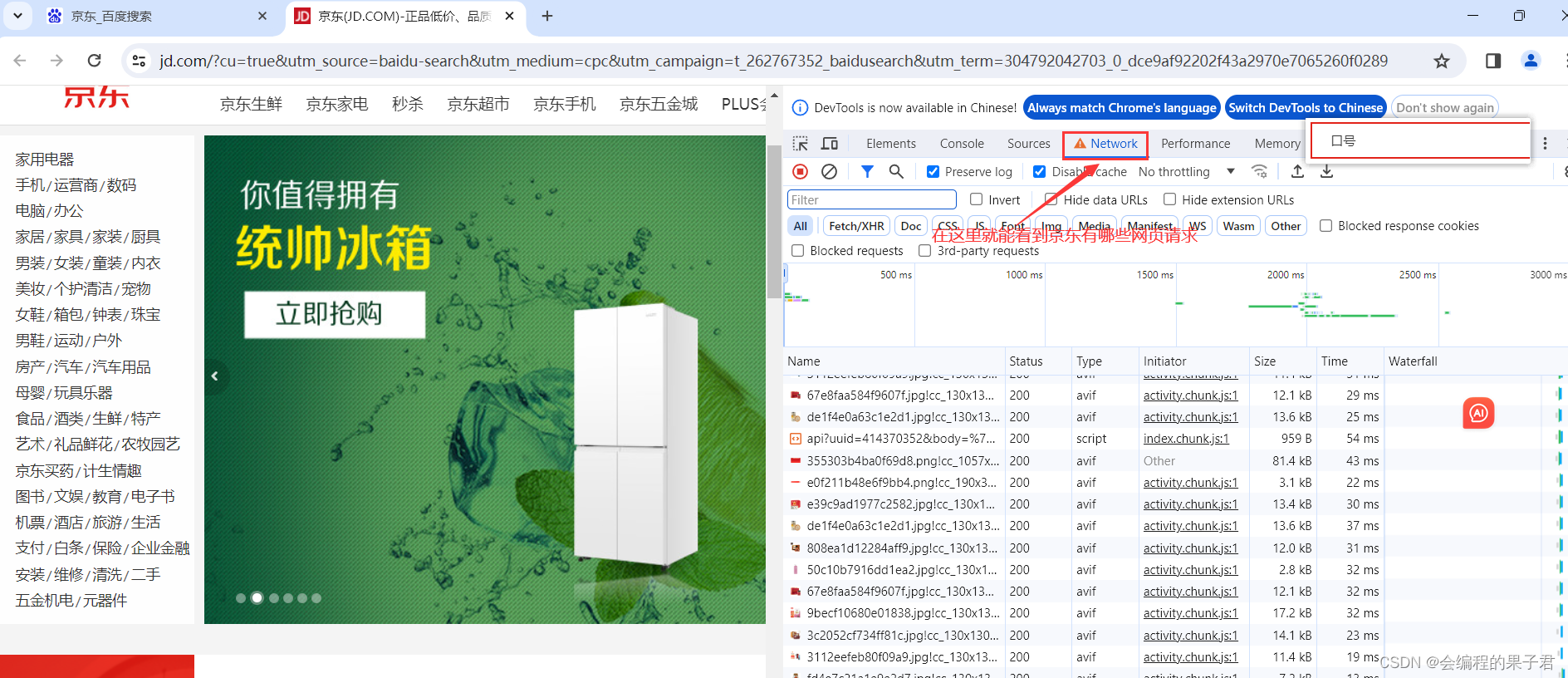
有些时候,我们的数据不一定都是直接来自于页面源代码,如果你在页面源代码里面找不到你要的数据的时候,那很可能数据是存放在另一个请求里