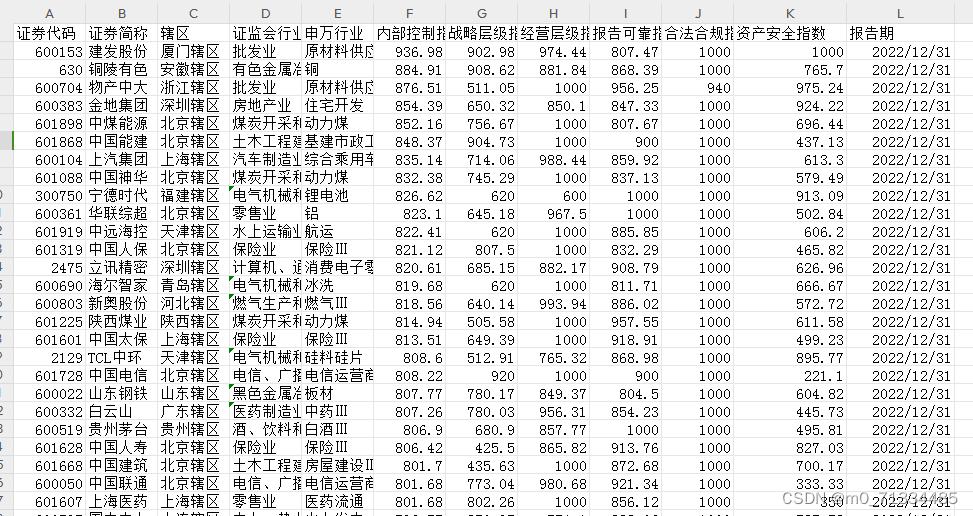
当我们谈论Elasticsearch(简称ES)时,我们经常会提到它的高效搜索能力。而这背后的核心技术之一就是倒排索引。那么,什么是倒排索引,以及它是如何在Elasticsearch中工作的呢?
深入解析Elasticsearch的内部数据结构和机制:行存储、列存储与倒排索引之行存(一)
深入解析Elasticsearch的内部数据结构和机制:行存储、列存储与倒排索引之列存(二)
一、什么是倒排索引?
首先,我们需要了解传统的正向索引。在正向索引中,文档是按照它们在磁盘上的顺序进行存储的,每个文档都有一个与之关联的文档ID。如果我们要查找某个词在哪些文档中出现,就需要遍历整个文档集合,这显然是非常低效的。
倒排索引则解决了这个问题。在倒排索引中,有一个单词列表,对于列表中的每个单词,都有一个包含它的文档的列表。这样,当我们要查找某个词在哪些文档中出现时,只需要查找该词的条目,然后获取与之关联的文档列表即可。
二、Elasticsearch中的倒排索引
Elasticsearch使用了一种称为Lucene的库来实现倒排索引。在Elasticsearch中,每个文档的每个字段都被索引为一个独立的倒排索引。
- 当用户在Elasticsearch中执行一个搜索查询时,查询会被解析成一个或多个查询词。
- 对于每个查询词,Elasticsearch首先在单词词典中查找它。由于单词词典通常很大,直接查找可能会很慢,因此Elasticsearch会使用词项索引来加速这个过程。
- 一旦找到了查询词,Elasticsearch就获取与之关联的倒排列表。这些倒排列表记录了包含查询词的所有文档的ID以及相关信息。
- Elasticsearch可以根据需要合并多个倒排列表,并根据相关性算法对结果进行排序,最终返回给用户。
那么当我们谈论倒排索引结构时,我们主要涉及到三个部分:倒排表(Posting List)、词项字典(Term Dictionary)和词项索引(Term Index)。下面,我将详细解释这三个部分的作用和工作原理。

1. 倒排表(Posting List)
倒排表是倒排索引结构中最核心的部分。对于文档集合中出现的每个单词(或称为词项),倒排表中都有一个条目与之对应。这个条目包含了该单词在哪些文档中出现的信息,通常包括文档ID和单词在该文档中出现的位置、频率等附加信息。
例如,假设我们有一个文档集合,包含三个文档:
Doc1: "The quick brown fox"
Doc2: "Quick foxes jump over lazy dogs"
Doc3: "Brown foxes are not quick"
对于单词"quick",倒排表中的条目可能如下:
quick -> Doc1:1; Doc3:3 (这里的数字表示单词在文档中的位置)
倒排表通常会被压缩以节省存储空间,例如使用差分编码或位图等技术。
2. 词项字典(Term Dictionary)
词项字典是一个包含文档集合中所有唯一单词的列表。每个单词在词项字典中都有一个唯一的条目,这个条目指向倒排表中与该单词对应的条目。
使用上面的文档集合作为例子,词项字典可能如下:
The
quick
brown
fox
foxes
jump
over
lazy
dogs
are
not
每个单词都按照某种顺序(例如字典序)排列,并且每个单词都有一个指针或引用,指向倒排表中相应的条目。
3. 词项索引(Term Index)
词典查找的挑战
-
全文检索系统通常需要处理大量的文本数据,这意味着词典(Term Dictionary)也会非常大。虽然可以使用各种高效的数据结构(如哈希表、B树等)来加速查找,但这些数据结构通常都需要将数据加载到内存中才能实现最优的查找性能。然而,将整个词典加载到内存中可能会导致巨大的内存消耗,甚至耗尽可用内存。
-
此外,即使词典被加载到内存中,由于内存访问速度仍然远低于CPU的处理速度,因此查找性能仍然可能受到限制。特别是在需要进行大量的随机内存访问时,性能影响会更加显著。
词项索引(Term Index)的作用
-
为了解决这些问题,引入了词项索引(Term Index)。词项索引的目的是提供一个更紧凑、更快速的方式来查找词典中的词项。它通常使用Trie树(或前缀树)结构来存储词项的前缀信息。
-
Trie树是一种树形数据结构,用于高效地存储和查找字符串(或其他类型的数据)。在Trie树中,从根到任何一个节点,按照路径上的标签字符顺序连接起来,就是一个相应的字符串。这种结构非常适合于存储大量的字符串,并且可以快速查找具有相同前缀的字符串。
-
然而,传统的Trie树可能会消耗大量的内存,特别是当词典非常大时。为了解决这个问题,可以使用一种压缩版的Trie树,称为有限状态转换器(Finite State Transducers,FST)。FST是一种特殊类型的有限状态机,它可以用来表示字符串之间的映射关系,并且非常节省内存。
基于词项索引的查找流程
- 通过Term Index定位:首先,系统使用Term Index(以FST的形式保存在内存中)来快速定位到词典中可能包含目标词项的区块(Block)。由于Term Index只存储词项的前缀信息,并且使用了高效的FST结构,这一步的查找速度非常快,并且内存消耗很低。
- 在词典中查找:一旦定位到了可能的区块,系统就可以在词典(Term Dictionary)中按照其内部的数据结构(如排序数组、B树等)进行精确的查找。由于这一步的查找范围已经大大缩小,因此查找速度也很快。
- 通过这种方式,词项索引(Term Index)和词典(Term Dictionary)的结合使用可以在不消耗大量内存的情况下实现高效的词典查找,从而支持全文检索系统中的快速查找操作。
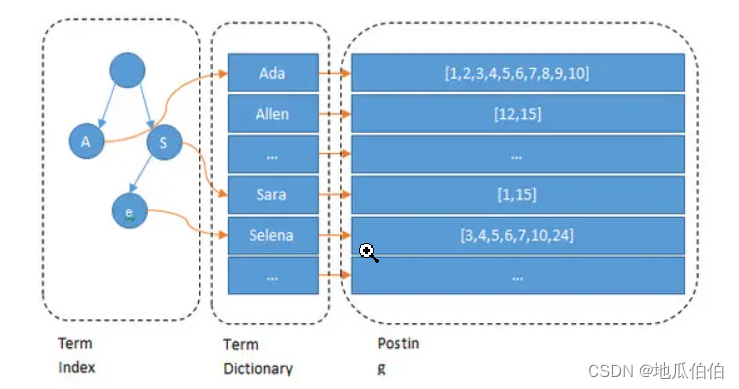
倒排索引结构通过倒排表、词项字典和词项索引这三个部分,实现了从单词到包含这些单词的文档的快速映射。这种结构使得搜索引擎能够高效地处理大量的文本数据和复杂的查询请求。
当我们在Elasticsearch中执行一个搜索查询时,以下是发生的主要步骤**:**
- 查询被解析成一个或多个查询词。
- 对于每个查询词,Elasticsearch在单词词典中查找它。
- 如果找到了查询词,Elasticsearch就获取与之关联的倒排列表,并根据需要将这些列表合并。
- 根据合并后的倒排列表,Elasticsearch可以快速地确定哪些文档与查询匹配,以及这些匹配文档的相关性。
三、优化与扩展
当然,上述的描述只是倒排索引的基础原理。在实际应用中,Elasticsearch还使用了许多优化技术来提高搜索性能,例如:
- 压缩技术:倒排列表可以被压缩以减少存储空间和提高查询速度。
- 跳跃表:对于大型倒排列表,Elasticsearch使用了一种称为跳跃表的数据结构来加速查询。
- 前缀共享:单词词典中的单词可以通过共享前缀来减少存储空间。
此外,Elasticsearch还支持多种查询类型和分析器,可以根据需要定制搜索行为。
总结
倒排索引是Elasticsearch实现高效搜索的核心技术之一。通过将文档分解为单词,并为每个单词建立倒排列表,Elasticsearch可以快速地确定哪些文档与查询匹配。通过使用各种优化技术,Elasticsearch可以进一步提高搜索性能,满足各种复杂查询的需求。