数据存储
peewee模块
第三方模块,也需要在cmd中安装。
from peewee import *db = MySQLDatabase("spider",host="127.0.0.1",port=3306,user='root',password='123456'
)# 类==》表
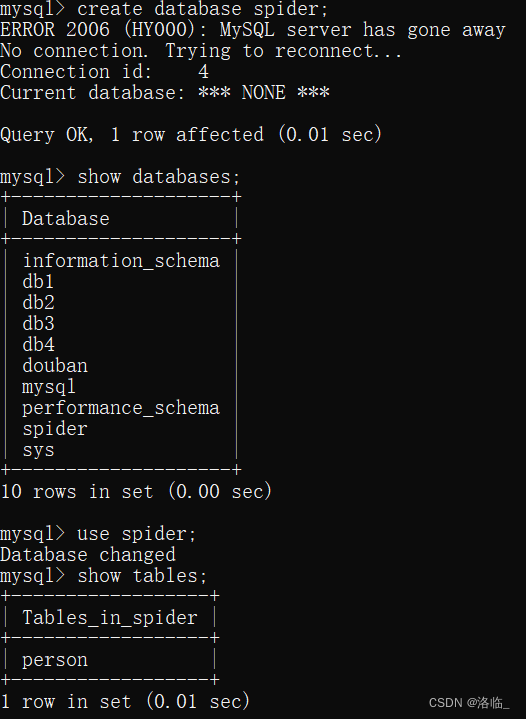
class Person(Model):name = CharField(max_length=20) # 类型/约束birthday = DateField(null=True)class Meta:database = dbdb.create_tables([Person])需要提前先创建一个库,如下:
# 插入数据
p1 = Person(name='XX', birthday='2004-04-09')
p1.save()
import reimport requests
from peewee import *db = MySQLDatabase("spider",host="127.0.0.1",port=3306,user='root',password='123456'
)class MaoYanData(Model):name = CharField(max_length=100)star = CharField(max_length=100)release_time = CharField(max_length=100)class Meta:database = db # 把这张表创建到库里面class MaoYanSpider:def __init__(self):self.url = 'https://www.maoyan.com/board/4?offset={}'self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}def get_html(self, url):response = requests.get(url, headers=self.headers)return response.textdef parse_html(self, html):'''提取数据的函数:param html: 在那个代码中寻找'''r_list = re.findall('<div class="movie-item-info">.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>', html, re.S)self.save(r_list)def save(self, data_list):for data in data_list:li = [data[0],data[1].split(':')[1].strip(),data[2].split(':')[1].strip(),]data_object = MaoYanData(name=li[0], start=li[1], release_time=li[2])data_object.save()print(li)def run(self):for offset in range(0, 91, 10):url = self.url.format(offset)html = self.get_html(url=url)self.parse_html(html)print('-'*100)db.create_tables([MaoYanData]) # 创建出这张表
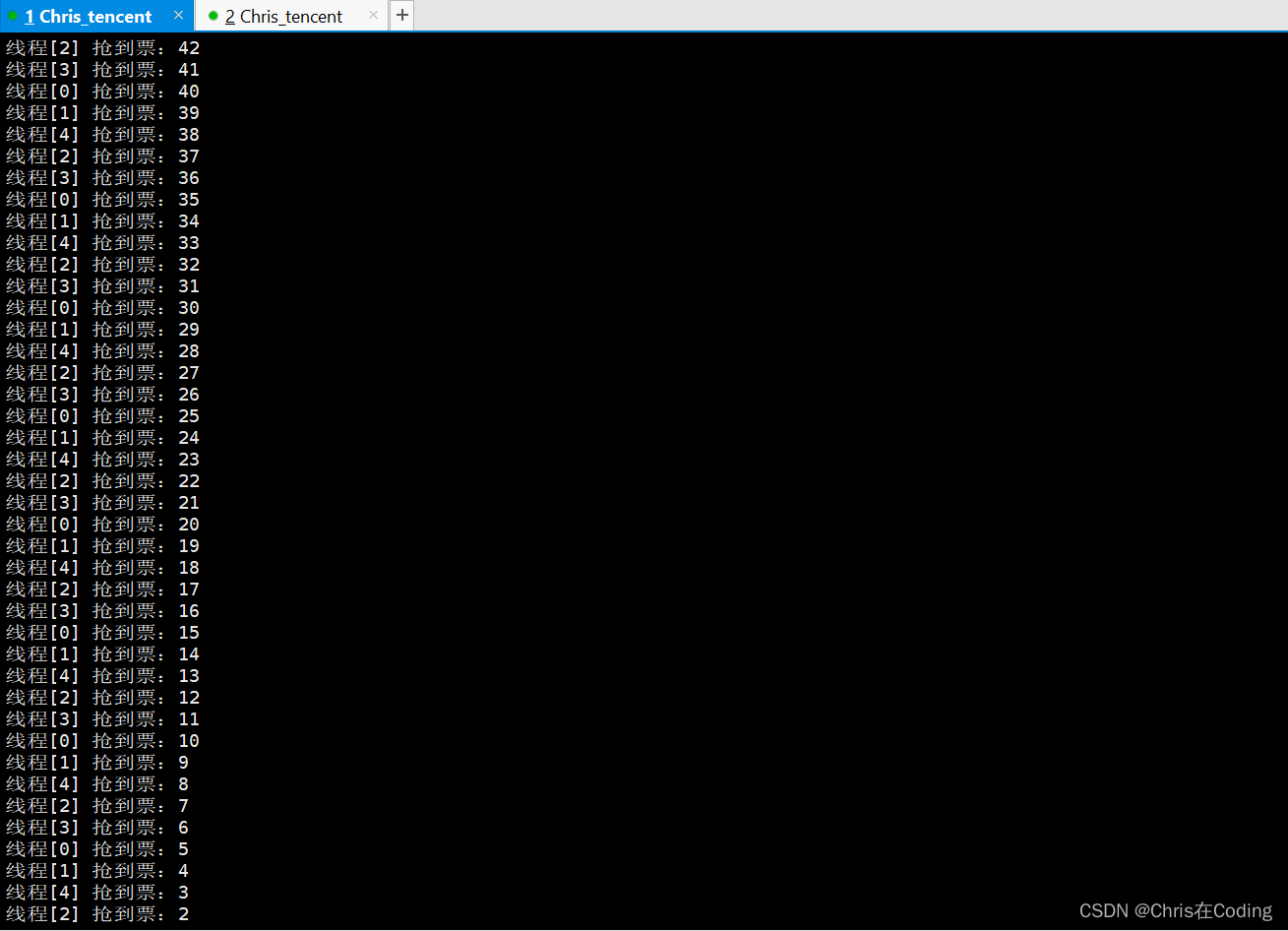
MaoYanSpider().run()多任务爬虫--进程
进程:程序在计算机中的一次执行过程
创建进程的两种方式:
方式一:
1.将需要进程执行的时间封装为函数
2.通过模块的Process类创建进程对象,关联函数
Process() 参数:
- target 绑定要执行的目标函数
- args元组 给target函数位置传参
3.可以通过进程对象设置进程信息及属性
4.通过进程对象调用start启动进程
- 新的进程是由原有进程的子进程,子进程复制父进程全部内存空间代码段,一个进程可以创建多个子进程。
- 进程创建后,各个进程空间独立,互相没有影响。
- 各个进程在执行上互不影响,也没有先后顺序关系。
方式二:
1.继承Process类
2.重写__init__方法添加自己的属性,使用super()加载父类属性
3.重写run()方法,调用start自动执行run方法
生产者消费者模型:生产者专门生产数据,然后存在一个中间容器中。消费者在这个中间容器取出数据进行消费。通过生产者消费者模型,可以让代码达到高内聚低耦合的目标,让程序分工更加明确。
进程通信:进程间空间独立,资源部共享,此时在需要进程间数据传输就需要特定手段进行数据通信。常用进程间通信方法:消息队列,套接字等。
进程池:创建一定数量的进程来处理事件,事件处理完进程不退出而是继续处理其他事件,直到所有事件全都处理完毕统一销毁。增加进程的重复利用,降低资源消耗
一般爬取图片:
import os.pathimport requests'''获得所有英雄id'''
# https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?ts=2845381
'''用获取到的英雄id拼接{}获取不同英雄皮肤数据'''
# https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js?ts=2845381class LolImageSpider:def __init__(self):self.hero_list_url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?ts=2845381'self.hero_info_url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js?ts=2845381'self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}def get_hero_url(self, url):json_data = requests.get(url, headers=self.headers).json()for hero in json_data['hero']:# print(hero['heroId']) # 在这里打印出所有数据后发现数字并不连贯,取出他们的id去进行拼接info_url = self.hero_info_url.format(hero['heroId'])response = requests.get(info_url, headers=self.headers).json()self.parse_data(response)def parse_data(self, response):skins_list = response['skins']for skins in skins_list:# print(skins) # 拿到每个英雄的皮肤name = skins['name']main_img = skins['mainImg']if main_img: # 判断是否有对应图片的皮肤self.parse_img_data(name, main_img)def parse_img_data(self, name, main_img):img = requests.get(main_img).contentfilename = 'lol'if not os.path.exists(filename):os.mkdir(filename) # 如果没有名为lol的文件就创建文件with open(filename+f"/{name.replace('/', '')}.jpg", 'wb')as f: # 以该皮肤命名这个图片(记得f"后面加一个/,在该文件夹下下载图片。其中将名字内有/的皮肤名字(k/DA)改成空格)f.write(img)print(name, main_img)def run(self):# 获取所有英雄的id,拼接成英雄图片的url请求地址self.get_hero_url(self.hero_list_url)spider = LolImageSpider()
spider.run()但是会发现爬取速度很慢。
使用了进程的生产者消费者就会快很多:
import re
import requestsfrom multiprocessing import Process, Queueheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}class Producer(Process):def __init__(self, url_q, img_q):super().__init__()self.url_q = url_qself.img_q = img_qdef run(self) -> None:while not self.url_q.empty():url = self.url_q.get()json_data = requests.get(url, headers=headers).json()skins_list = json_data['skins']for skins in skins_list:name = skins['name']main_img = skins['mainImg']if main_img:self.img_q.put({"name": name, "main_img": main_img})class Consumer(Process):def __init__(self, img_q):super().__init__()self.img_q = img_qdef run(self) -> None:while True:img_obj = self.img_q.get()img = requests.get(img_obj.get("main_img")).content # 拿到数据with open(f'lol/{img_obj.get("name")}.jpg', 'wb')as f:f.write(img)print(img_obj)if __name__ == '__main__':# 存储不同英雄的url链接urlQueue = Queue()imgQueue = Queue()hero_list_url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?ts=2845381'hero_info_url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js?ts=2845381'json_data = requests.get(hero_list_url, headers=headers).json()for hero in json_data['hero']:info_url = hero_info_url.format(hero['heroId'])urlQueue.put(info_url) # 得到数据链接p_list = []# 启动三个生产者for i in range(3):p = Producer(urlQueue, imgQueue)p.start() # 执行这个线程p_list.append(p)#for i in range(5):p = Consumer(imgQueue)p.start()for p in p_list:p.join()进程池与线程池
创建一定数量的进程来处理事件,事件处理完进程不退出,继续处理其他事件,直到所有时间全都处理完毕统一销毁。会增加进程的重复利用,降低资源消耗。
开启进程池例子:
import time # 开启一个进程池 from concurrent.futures import ProcessPoolExecutordef task(url):time.sleep(3)print(url)if __name__ == '__main__':pool = ProcessPoolExecutor(4) # 固定开了4个进程url_list = ["www.xxx-{}.com".format(i) for i in range(12)]for url in url_list:pool.submit(task, url) # 提交:函数名,参数
开启线程池:
''' 进程:资源分配单位 线程:执行单位 '''import time # 开启一个线程池 from concurrent.futures import ThreadPoolExecutordef task(url):time.sleep(3)print(url)if __name__ == '__main__':pool = ThreadPoolExecutor(4) # 固定开了4个进程url_list = ["www.xxx-{}.com".format(i) for i in range(12)]for url in url_list:pool.submit(task, url) # 提交:函数名,参数
线程的生产者消费者模型:
import re
import requestsfrom threading import Thread
import queueheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}class Producer(Thread):def __init__(self, url_q, img_q):super().__init__()self.url_q = url_qself.img_q = img_qdef run(self) -> None:while not self.url_q.empty():url = self.url_q.get()json_data = requests.get(url, headers=headers).json()skins_list = json_data['skins']for skins in skins_list:name = skins['name']main_img = skins['mainImg']if main_img:self.img_q.put({"name": name, "main_img": main_img})class Consumer(Thread):def __init__(self, img_q):super().__init__()self.img_q = img_qdef run(self) -> None:filename = 'lol'while True:img_obj = self.img_q.get()if not img_obj:breakname = re.sub(r'[\/:*?<>|]', " ", img_obj.get("name"))img = requests.get(img_obj.get("main_img")).content # 拿到数据with open(f'{filename}/{name}.jpg', 'wb')as f:f.write(img)print(img_obj)self.img_q.task_done() # 提示完成(join的阻塞)if __name__ == '__main__':# 存储不同英雄的url链接urlQueue = queue.Queue()imgQueue = queue.Queue()hero_list_url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?ts=2845381'hero_info_url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js?ts=2845381'json_data = requests.get(hero_list_url, headers=headers).json()for hero in json_data['hero']:info_url = hero_info_url.format(hero['heroId'])urlQueue.put(info_url) # 得到数据链接p_list = []# 启动三个生产者for i in range(3):p = Producer(urlQueue, imgQueue)p.start() # 执行这个线程p_list.append(p)#for i in range(5):p = Consumer(imgQueue)p.start()for p in p_list:p.join() 注意:与进程区别——导包的不同和queue的调用。
线程对于交互等的运行速度会比进程快
进程对于算数等的运行速度会比线程快
Excel
安装第三方模块openpyxl
创建:
from openpyxl import workbook wb = workbook.Workbook() wb.save("1.xlsx") # 在当前文件夹下创建一个excel表
获取内容:
from openpyxl import load_workbook# 打开Excel wb = load_workbook("1.xlsx") # (相对路径)读取 # 选择要操作的sheet print(wb.sheetnames) # 获取所有表名 ['1表', '2表', '3表', '4表'] sheet = wb["1表"] # 也可以:sheet = wb.worksheets[0] print(sheet) # <Worksheet "1表"> print(sheet.cell(1, 1).value) # 拿到表中1行1列的数据 没获取到的话记得看一下编辑之后有没有保存哦
例子:
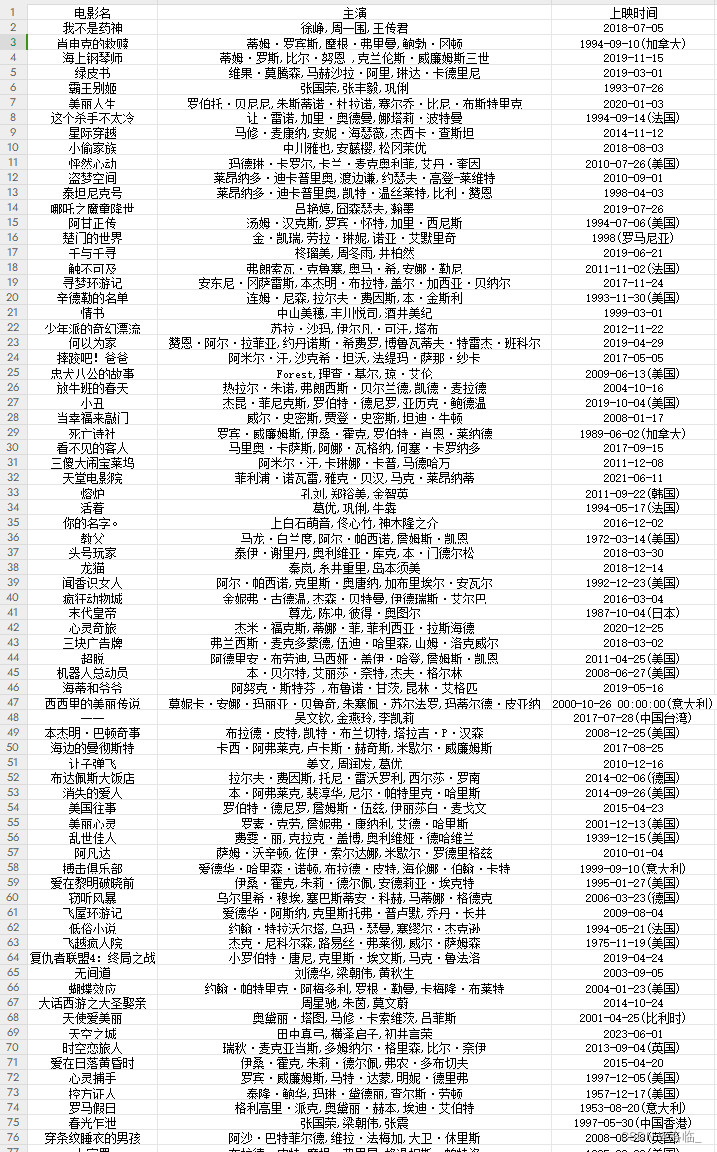
import reimport requestsfrom openpyxl import workbookclass MaoYanSpider:def __init__(self):self.url = 'https://www.maoyan.com/board/4?offset={}'self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}self.wb = workbook.Workbook() # 创建Excelself.sheet = self.wb.worksheets[0] # 第一个表self.header = ["电影名", "主演", "上映时间"] # 定义表头名字for i, item in enumerate(self.header, 1): # 索引从1开始# print(i, item) # 枚举(获取索引和名字)0 电影名 1 主演 2 上映时间(self.header后没有注明1之后打印出的结果)self.sheet.cell(1, i).value = item # 把表头一个一个写进去(第一行第一个,第一行第二个...)self.wb.save("Top100.xlsx")def get_html(self, url):response = requests.get(url, headers=self.headers)return response.textdef parse_html(self, html):'''提取数据的函数:param html: 在那个代码中寻找'''r_list = re.findall('<div class="movie-item-info">.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>', html, re.S)self.save(r_list)def save(self, data_list):for data in data_list:li = [data[0],data[1].split(':')[1].strip(),data[2].split(':')[1].strip(),]print(li)# 获取Excel中最大行号max_row = self.sheet.max_rowfor i, item in enumerate(li, 1):cell = self.sheet.cell(max_row + 1, i)cell.value = itemself.wb.save("Top100.xlsx")def run(self):for offset in range(0, 91, 10):url = self.url.format(offset)html = self.get_html(url=url)self.parse_html(html)print('-'*100)MaoYanSpider().run()结果: