Separable Multi-Concept Erasure from Diffusion Models
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
1. 简介
2. 相关工作
3. 方法
3.1. G-CiRs
3.2. 权重解耦(WD)
4. 实验
5. 结论
0. 摘要
大规模扩散模型,以其印象深刻的图像生成能力而闻名,引起了研究人员对社会影响的关切,如模仿受版权保护的艺术风格。作为回应,现有方法转向机器遗忘(machine unlearning)技术,以消除预训练模型中的不安全概念。然而,这些方法牺牲了生成性能,并忽视了多概念擦除之间的耦合,以及概念恢复问题。为了解决这些问题,我们提出了一个可分离的多概念擦除器(Separable
Multi-concept Eraser,SepME),主要包括两个部分:概念无关表示的生成和权重解耦。前者旨在避免遗忘概念无关的实质性信息。后者分离可优化的模型权重,使每个权重增量对应于特定概念的擦除,而不影响其他概念上的生成性能。具体而言,擦除指定概念的权重增量被制定为基于其他已知不良概念计算的解的线性组合。大量实验证明了我们的方法在消除概念、保持模型性能并在各种概念的擦除或恢复方面提供的灵活性。
代码:https://github.com/Dlut-lab-zmn/SepCE4MU
1. 简介
扩散模型的一个关键挑战来自各种训练数据来源,可能导致不安全的图像生成 [50, 10],例如创建暴力内容或模仿特定艺术家风格。为解决这一问题,提出了机器遗忘(machine unlearning,MU)技术 [51, 27, 45, 40],涉及擦除特定数据点或概念的影响,以增强模型安全性,而无需完全从头开始重新训练。
最近的 MU 研究,如 Erased Stable Diffusion(ESD)[10],Forget-me-not(FMN)[50],Safe self-distillation diffusion(SDD)[23] 和 Ablation Concept(AbConcept)[27],可以广泛分类为非定向概念擦除(例如 FMN)和定向概念擦除(例如ESD,SDD和AbConcept)。具体而言,FMN最小化了被遗忘概念的注意力图。相反,ESD、SDD 和 AbConcept 将被遗忘概念的去噪分布与预定义分布对齐。
尽管 MU 在最近取得了进展[16, 33],但存在一些缺点。
- 首先,先前的努力集中于概念擦除,导致生成能力的相当降级。
- 其次,当前的擦除程序仅限于单一概念的消除,并在将其扩展到多概念擦除时面临挑战。
多概念擦除可以采取两种形式:多概念同时擦除和多概念迭代擦除。前者意味着多个被遗忘的概念在预先已知,而后者意味着每个擦除步骤仅具有其先前被遗忘概念的知识。
最后,据我们所知,概念恢复问题尚未得到考虑。例如,在擦除多种艺术风格后,模型所有者可能会重新获得与一些被擦除的风格相关联的版权。
2. 相关工作
现有研究主要分为三个明确的方向:删除不安全数据和模型重新训练 [4],集成额外插件以指导模型输出 [2, 32],以及通过 MU 技术微调模型权重 [10, 50, 27]。第一方向的缺点是大规模模型重新训练需要相当的计算资源和时间。第二方向的风险在于,随着模型结构和权重的公开可用,恶意用户可以轻松删除插件。本文侧重于第三个方向,即机器遗忘。
用于 DM 的大多数遗忘方法可以总结为:
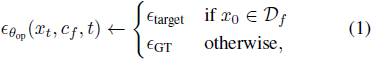
其中,θop 代表可优化的模型权重,例如 DM 中的交叉注意力模块的参数。xt 可以通过扩散过程或抽样过程获得。ϵθop(xt, cf, t) 表示在第 t 步 DM 中未学习的模型预测的噪声。Df 是包含被遗忘概念 cf 的数据集。ϵtarget 和 ϵGT 分别表示预定义目标概念的噪声和在扩散过程中添加的地面实况噪声。
例如,ESD [10] 利用了对无概念 c∅ 和被遗忘概念 cf 的预测噪声来构建 ϵtarget,
![]()
其中 θdm 代表冻结 DM 的参数。η 是超参数。SDD [23] 直接将被擦除概念cf的预测分布映射到无概念c∅的预测分布,ϵtarget = ϵθdm (xt, c∅, t)。AbConcept [27] 为每个被擦除概念 cf 分配锚定概念 c∗,例如,cf 是 “梵高的绘画”,c* 是 “绘画”,或 cf 是 “Grumpy 猫的照片”,c* 是 “猫的照片”,ϵtarget = ϵθdm (xt, c∗, t)。相比之下,FMN [50] 是一种非定向概念擦除方法,最小化了与被遗忘概念 cf 对应的注意权重。
这些先进的方法专注于遗忘概念,但显著牺牲了模型性能。此外,它们尚未考虑多概念遗忘和随后恢复的场景。在本研究中,我们引入了一个可分离的多概念遗忘框架。它包括一个非定向的概念无关遗忘机制,在概念遗忘过程中保持模型性能,以及一个权重解耦机制,为概念的遗忘和恢复提供灵活性。
3. 方法
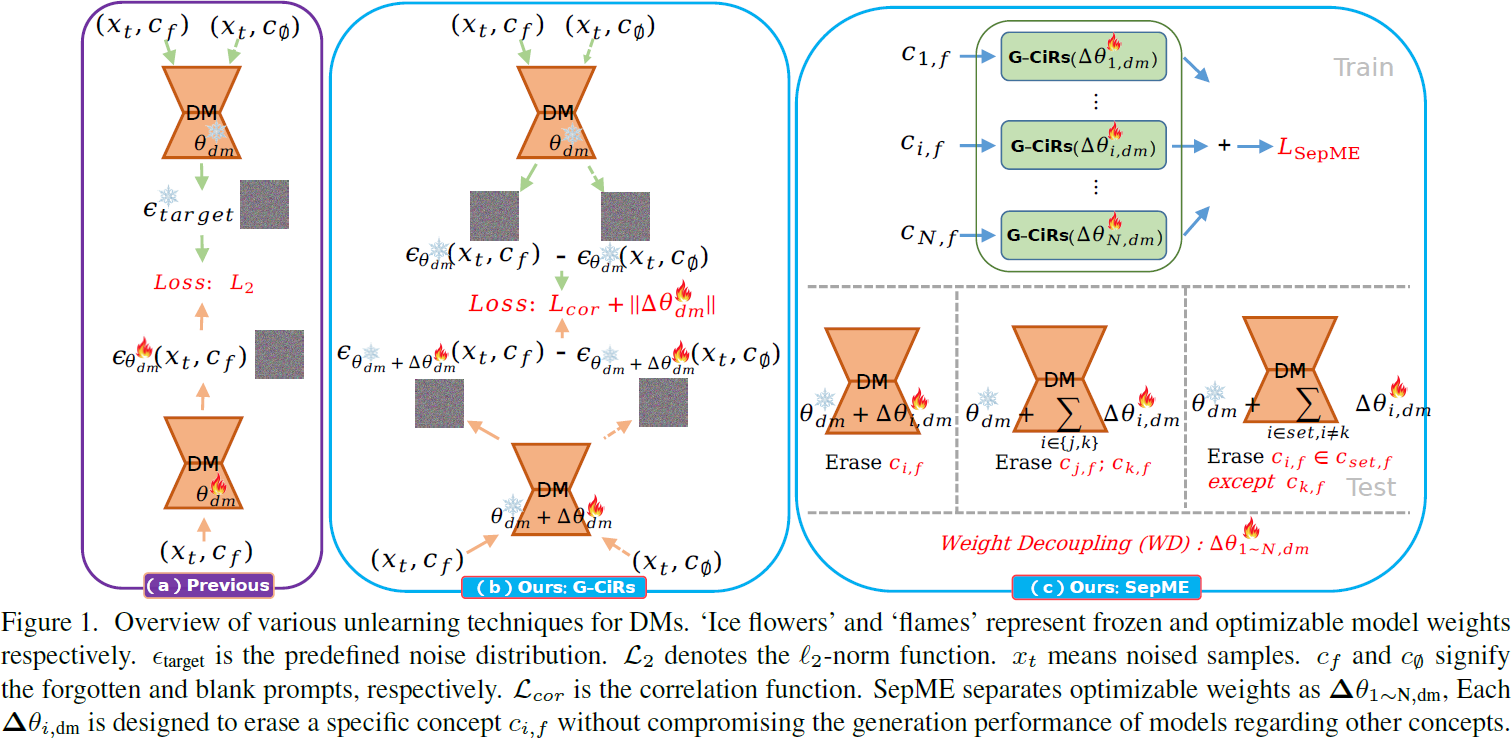
我们提出的可分离多概念擦除器(SepME)旨在在保持整体模型性能的同时,灵活地擦除或恢复多个概念。SepME 的概览如图 1 所示,它包括生成概念无关表示(generation of concept-irrelevant representations,G-CiRs)和权重解耦(weight decoupling,WD)。
3.1. G-CiRs
为了在遗忘过程中保持扩散模型(DMs)对常规概念(或无概念 c∅)的生成能力,G-CiRs 防止对已遗忘概念 c_(i,f) ∈ c_f,i ∈ [1, N] 的重要但不相关信息的擦除,其中 N 是被擦除概念的数量。具体而言,给定由 θ_dm 参数化的原始 DMs,我们使用噪声差异 Δϵ(ci,f, θdm) = ϵθdm(xt, ci,f, t) − ϵθdm(xt, c∅, t)来表示概念 c_(i,f)。为了成功从 DM 中擦除概念 cf,遗忘的概念和原始 DM 的概念 cf 的表示应该是不相关的,即
![]()
![]()
其中 Δθdm 表示遗忘的 DMs 的可学习权重增量,⊙ 表示逐元素乘积,Avg(·) 计算平均值。公式(2)实际上计算了概念 ci,f 的两个表示之间的相关性。
(注:微调 DM,使 DM 遗忘概念 ci,f,导致微调前后噪声差异 Δϵ 无关)
在此基础上,我们通过公式 3 微调 Δθdm
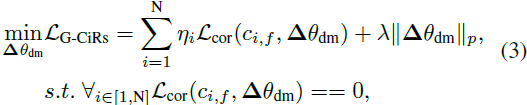
![]()
其中,ηi 用于平衡多个概念的损失。λ表示超参数。∥Δθdm∥p 限制了未学习的 DM 与原始 DM 之间的权重偏差。
为了满足等式(3)中零相关性的条件,我们使用动量统计方法,因为从各种噪声样本 xt 计算的Lcor(ci,f ,Δθdm) 的值存在显著变化。具体而言,一旦 Ln mom ≤ τ,就会启动早停,其中 τ 表示阈值,其默认值为 0。

其中α是超参数,n 是遗忘步骤。
3.2. 权重解耦(WD)
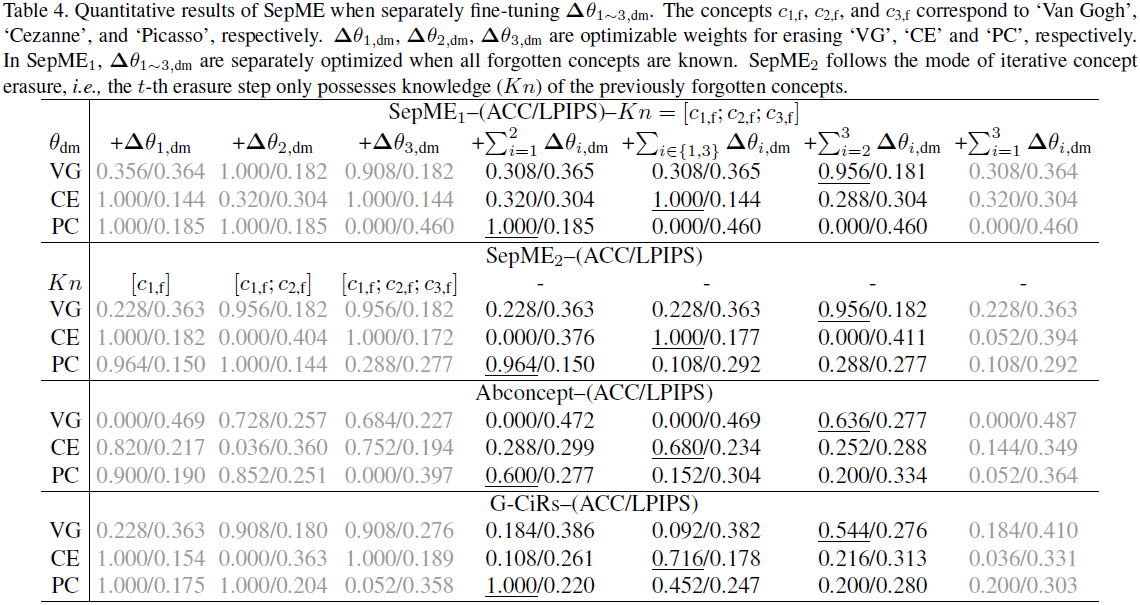
为了解决多概念遗忘后的恢复问题,我们将方程(2)中的权重 Δθdm 分解为 Δθ1∼N,dm,以灵活地操纵各种概念。每个独立的权重增量 Δθi,dm 旨在遗忘特定概念 ci,f,而不影响模型对其他概念的生成性能。可分离遗忘的过程可以表示为:

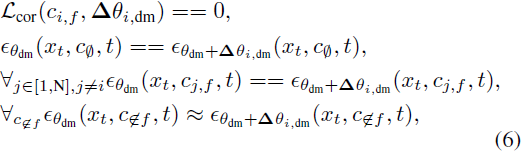
其中,xt 可以是任意图像,c ∉ f 表示不属于 cf 的概念。第一个条件旨在擦除被遗忘的概念,而其余条件则减缓对其他概念进行微调的影响。
为了满足这些条件,我们首先需要确定 Δθi,dm 的非零位置。从等式(6)可以明显看出,这些位置与图像无关。因此,只选择交叉注意力模块的 to_k 和 to_v 层,这些层专门设计用于提取 DM 中的文本嵌入。其他位置,例如用于提取图像嵌入的 to_q 层和用于更新融合嵌入的 FFN(前馈网络),已经被固定。对于 ∀i∈[1,N]Δθi,dm,它们共享相同的非零位置,但具有不同的值。
接下来,我们以 Δθto_k 为例来分析如何确定其值,其中 ∀Δθto_k ∈ Δθi,dm。值得注意的是,ϵθdm (xt, ck, t) == ϵθdm + Δθto_k (xt, ck, t) 意味着 ck ⊗ Δθto_k == 0,其中 ck ∈ R^(d_emb × d_in),Δθto_k ∈ R^(d_in × d_out)。d_emb,d_in 和 d_out 表示特征维度。⊗ 表示矩阵乘法。因此,等式(6)可以重写为:

♦ 为了使 Δθto_k 满足等式(7)中的第二和第三条件,我们首先计算线性方程组 A ⊗ Sp = 0 的特解 Sp,
![]()
其中,A 是用于指定概念 cf 的常数矩阵,A ∈ R^((N·d_emb) × d_in)。 ⊤ 表示矩阵转置。Sp ∈ R(d_in × (d_in−r)),其中 r 是 A 的秩,满足 r ≤ N·d_emb。d_in−r表示 Sp 中的解的数量。在 DM 中,d_in ≫ d_emb。值得注意的是,为了消除解 Sp 中的原始偏差,我们将 Sp 的每个元素归一化为单位向量。
然后,Δθto_k 的每一列可以表示为这些解 Sp 的线性组合,
![]()
其中,w 是一个可优化的变量,表示线性组合的权重,w ∈ R^(d_out × (d_in−r))。
♦ 为了进一步使 Δθto_k 满足等式(7)中的第四个条件,我们引入一个缩放因子 β,如下所示,
![]()
同时,w 被初始化为零矩阵。此外,我们用 ∥W∥p 替换等式(5)中的 ∥Δθ1∼N,dm∥p。这里, W 表示为 to_k 和 to_v 层定义的可优化变量 w 的集合。
总体而言,SepME 的目标简化为:
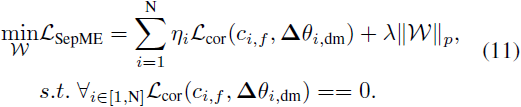
其中,W 表示对 to_k 和 to_v 层定义的可优化变量 w 的集合。
整体评估 SepME。我们组合各种 Δθi,dm 以擦除相应的概念。例如,具有
![]()
的 DM 消除了概念 cj,f 和 ck,f。
4. 实验
评估指标。评估指标包括模型参数的修改 ∥Δθdm∥p = ∥Δθdm∥/ M,由感知图像块相似度(LPIPS)测量的感知距离,以及分类准确率(ACC)。其中,M 表示层数。LPIPS 量化了原始图像和遗忘 DM 生成的图像之间的相似性,根据 AlexNet [26] 的设置计算。
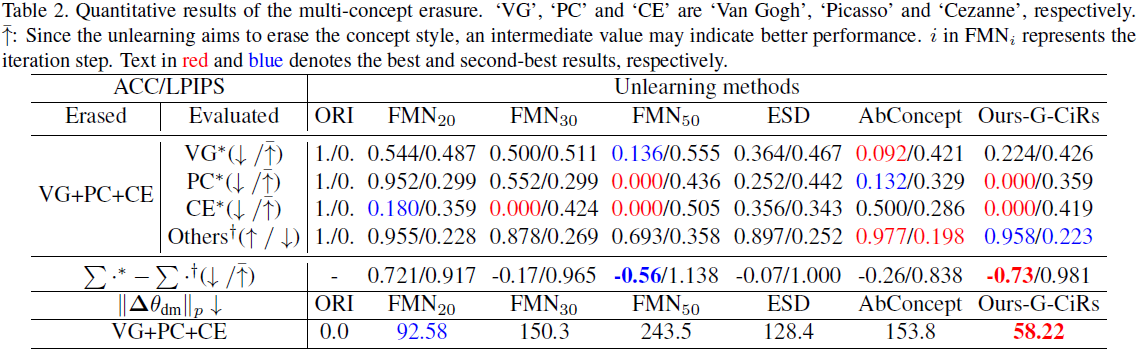
定量结果如表 1 所示。一方面,我们的 G-CiRs 在三种艺术风格的 ACC 和 LPIPS 指标方面表现出最佳性能。另一方面,所提出的 G-CiRs 对模型权重的修改较少。此外,在图 2∼4 中的定性比较中,我们的方法在擦除艺术风格和保持其他概念的生成性能方面也表现出有效性。这些视觉样本是使用包含艺术家名字或句子的提示为各种遗忘 DM 生成的。







5. 结论
在这项研究中,我们提出了一种创新的扩散模型机器遗忘技术,即可分离多概念擦除器(SepME)。SepME 利用相关项和动量统计产生与概念无关的表示。它不仅在概念遗忘过程中保持整体模型性能,还灵活地平衡多个概念之间的损失幅度。此外,SepME 允许分离权重增量,提供操纵各种概念的灵活性,包括概念恢复和迭代概念遗忘。大量实验证实了我们方法的有效性。