Oracle数据迁移至MySQL 一、生成测试数据表和数据 1.在Oracle创建数据表和数据 2.在MySQL创建数据表 二、生成模板文件 1.模板文件内容 2.模板文件参数详解 2.1 全局设置 2.2 数据读取(Reader) 2.3 数据写入(Writer) 2.4 性能设置 三、案例
# 创建数据库查看上面的部署教程
# 1.创建表
CREATE TABLE student (id INTEGER,name VARCHAR2(20),create_time TIMESTAMP DEFAULT SYSTIMESTAMP,update_time TIMESTAMP DEFAULT SYSTIMESTAMP
);
# 2.插入测试数据
INSERT INTO student (id, name)
SELECT level, 'Name ' || level
FROM dual
CONNECT BY level <= 10;
# 1.创建数据库
CREATE DATABASE oracle_test charset=utf8mb4;
# 2.创建数据库表
use oracle_test;
CREATE TABLE student (id INT,name VARCHAR(20),create_time DATETIME DEFAULT CURRENT_TIMESTAMP,update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
当前安装DataX的目录为:/data/datax # 1.进入datax的工具目录
cd /data/datax/bin/
# 2.生成模板
python datax.py -r oraclereader -w mysqlwriter > ../job/oracle_to_mysql.json
{"job": {"content": [{"reader": {"name": "oraclereader", "parameter": {"column": [], "connection": [{"jdbcUrl": ["jdbc:oracle:thin:@[HOST_NAME]:PORT:[DATABASE_NAME]"], "table": []}], "password": "", "username": "","where": ""}}, "writer": {"name": "mysqlwriter", "parameter": {"column": [], "connection": [{"jdbcUrl": "", "table": []}], "password": "", "preSql": [], "session": [], "username": "", "writeMode": ""}}}], "setting": {"speed": {"channel": ""}}}
}job: 定义了整个数据迁移作业的配置。 content: 包含了一个或多个数据同步任务的列表。 reader: 定义了数据来源的相关配置。 name: 使用的读取插件名称,这里是oraclereader,表示从Oracle数据库读取数据。 parameter: 读取数据时的参数配置。 column: 需要读取的列名列表。 connection: 数据库连接信息。 jdbcUrl: 数据库的JDBC连接URL。需要替换[HOST_NAME], [PORT], [DATABASE_NAME]为实际的服务器地址、端口和数据库名。 table: 指定要读取数据的表名列表。 password: 用于连接Oracle数据库的密码。 username: 用于连接Oracle数据库的用户名。 where: 可以指定一个WHERE条件来过滤读取的数据,这里留空表示不过滤,读取所有数据。 writer: 定义了数据目的地的相关配置。 name: 使用的写入插件名称,这里是mysqlwriter,表示数据将被写入到MySQL数据库。 parameter: 写入数据时的参数配置。 column: 指定写入到目标表的列名。应与读取的列对应。 connection: 目标数据库的连接信息。 jdbcUrl: MySQL的JDBC连接URL。 table: 指定要写入数据的表名。 password: 用于连接MYSQL数据库的密码。 postSql: 在数据写入完成后执行的SQL语句列表,这里留空。 preSql: 在数据写入前执行的SQL语句列表,这里留空。 username: 用于连接MYSQL数据库的用户名。 writeMode: 写入模式,这里设置为insert,表示通过INSERT语句进行数据写入。 setting: 定义了作业的全局设置。 speed: 控制数据同步的速度。 channel: 指定并发通道的数量,这里设置为4,意味着数据迁移任务将并行执行,使用4个并发通道。 {"job": {"content": [{"reader": {"name": "oraclereader", "parameter": {"column": ["id", "name", "create_time", "update_time"], "connection": [{"jdbcUrl": ["jdbc:oracle:thin:@192.168.86.128:1521/helowin"], "table": ["student"]}], "password": "***", "username": "ora_user"}}, "writer": {"name": "mysqlwriter", "parameter": {"column": ["id", "name", "create_time", "update_time"], "connection": [{"jdbcUrl": "jdbc:mysql://192.168.86.128:3306/oracle_test?useUnicode=true&characterEncoding=utf-8", "table": ["student"]}], "password": "****", "preSql": [], "username": "root", "writeMode": "insert"}}}], "setting": {"speed": {"channel": "1"}}}
}
python /data/datax/bin/datax.py /data/datax/job/mysql_to_clickhouse.json
主要差别在于,需要有一个createTime字段,代表源数据的创建时间,那么更新的时候,只迁移过滤这个时间段的数据,达到增量数据迁移 {"job": {"content": [{"reader": {"name": "oraclereader", "parameter": {"column": ["id", "name", "create_time", "update_time"], "connection": [{"jdbcUrl": ["jdbc:oracle:thin:@192.168.86.128:1521/helowin"], "table": ["student"]}], "password": "***", "username": "ora_user","where":"CREATE_TIME >= TO_TIMESTAMP('2024-02-14 00:00:00', 'YYYY-MM-DD HH24:MI:SS') AND CREATE_TIME <= TO_TIMESTAMP('2024-02-14 23:59:59', 'YYYY-MM-DD HH24:MI:SS')"}}, "writer": {"name": "mysqlwriter", "parameter": {"column": ["id", "name", "create_time", "update_time"], "connection": [{"jdbcUrl": "jdbc:mysql://192.168.86.128:3306/oracle_test?useUnicode=true&characterEncoding=utf-8", "table": ["student"]}], "password": "****", "preSql": [], "username": "root", "writeMode": "insert"}}}], "setting": {"speed": {"channel": "1"}}}
}
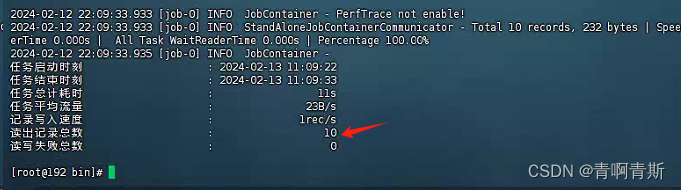
python /data/datax/bin/datax.py /data/datax/job/oracle_to_mysql.json -p "-DstartDatetime=2024-02-14 -DendDatetime=2024-02-14"