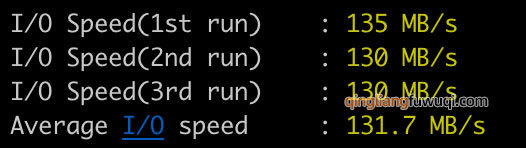
1. JVM是什么?
JVM是Java Virtual Machine的简称,它是一个虚拟的计算机,专门为执行Java程序而设计。
你可以想象它是一个能够运行Java字节码的平台,无论你的程序在Windows、Mac还是Linux上,它们都能通过JVM在这些系统中平稳运行。
因此,JVM提供了一个抽象层,让Java程序摆脱了具体硬件和操作系统的限制。这就是为什么你可以在任何安装了JVM的设备上运行同一个Java程序。
举一个生活中的例子:
想象一下,你写了一封信,希望全世界的人都能读懂,不论他们说什么语言。
JVM就相当于一个翻译机器,能够把你的信(也就是Java程序)翻译成任何地方的“本地语言”(也就是机器码),让你的程序无论在中国的Windows、美国的Mac还是英国的Linux系统上运行得都很好。
2. JVM的工作原理
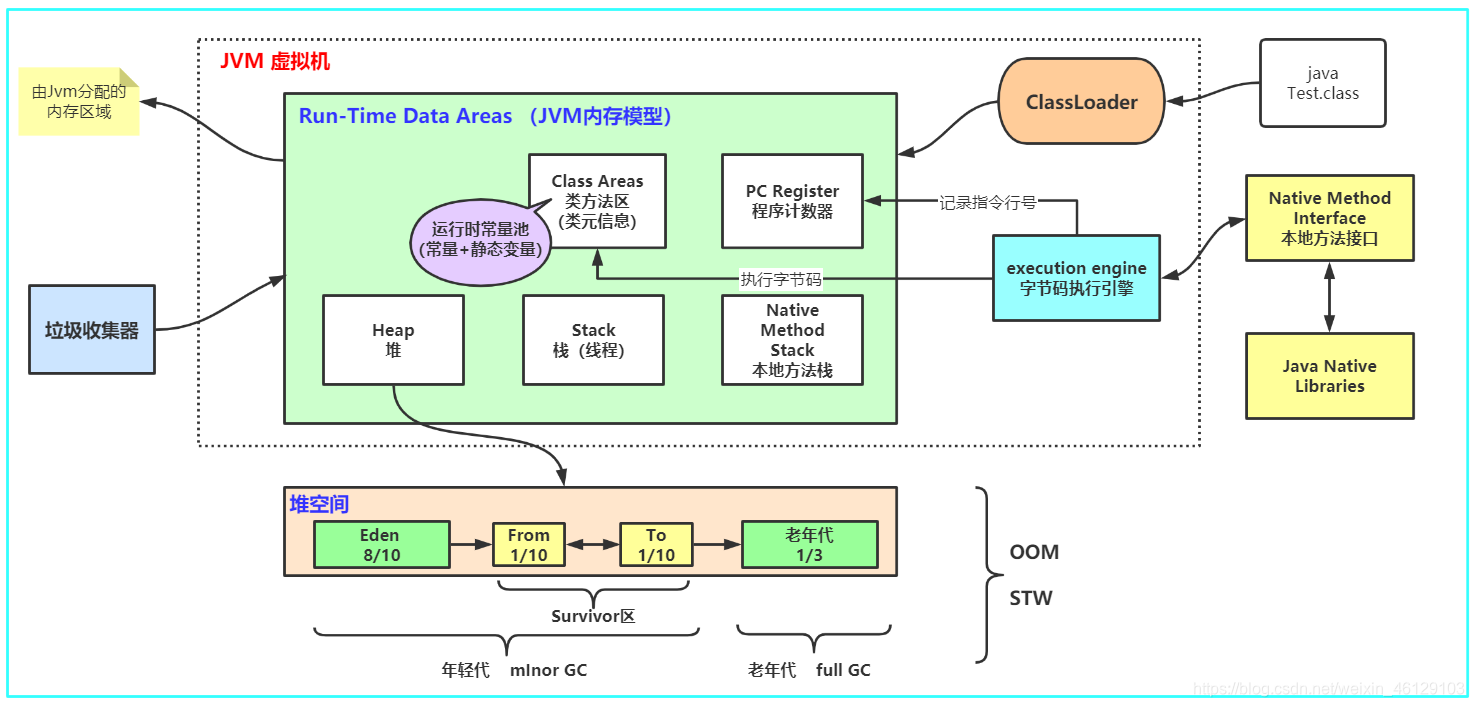
要理解JVM是如何工作的,我们先得知道,JVM主要有三个重要的组成部分:类加载器(Class Loaders)、执行引擎(Execution Engine)和内存区(Memory Areas)。
类加载器(Class Loaders)
类加载器的作用就像是一位图书管理员,负责将书籍(也就是你的Java类)按照一定的顺序放到图书馆的书架上(即加载到JVM内存中)。
这个过程分为三个阶段:
1、加载(Loading)
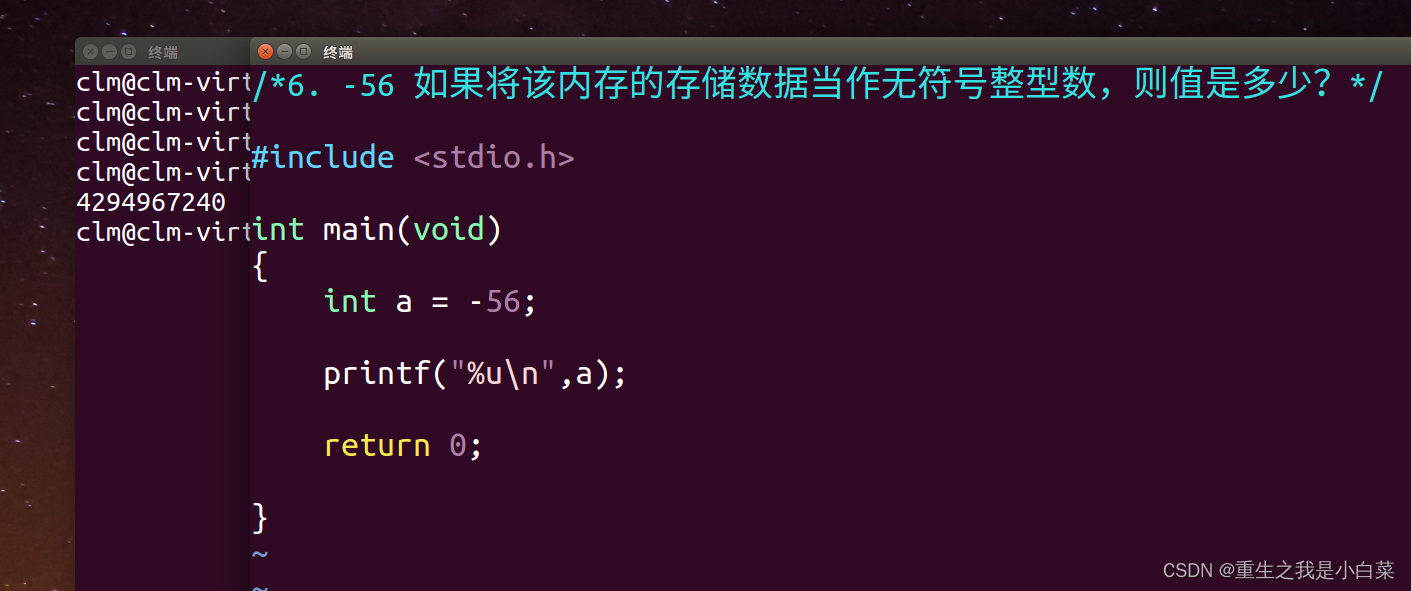
在这个阶段,类加载器读取.class文件,将这些静态数据转换成方法区的运行时数据结构,然后在堆中生成一个代表这个类的java.lang.Class对象,作为方法区这些数据的入口。
2、链接(Linking)
链接阶段验证类的正确性,为静态字段分配存储空间,并且如果必要的话,将原始码转换成机器码。
3、初始化(Initialization)
最后,在初始化阶段,JVM负责对类的静态变量赋予正确的初始值,以及执行静态代码块。
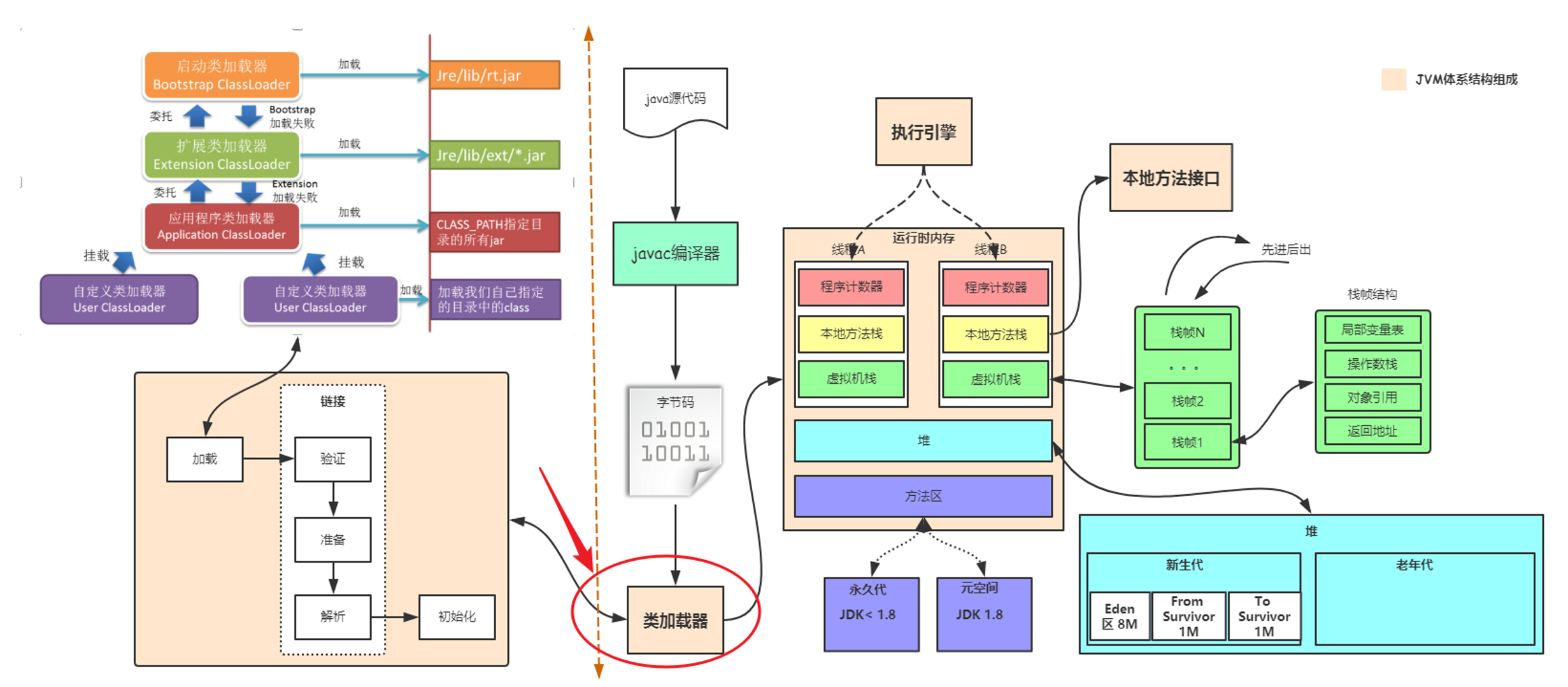
执行引擎(Execution Engine)
执行引擎就像一个翻译官,它读取字节码,将其转换成机器能理解和执行的指令。
它主要包括解释器和即时编译器(JIT Compiler):
1、解释器(Interpreter)
当Java程序运行时,解释器逐条读取字节码,并且将它们一条一条地翻译成机器码。这种方式简单但效率不高,因为每次执行都需要重新翻译。
2、即时编译器(JIT Compiler)
为了提高效率,JIT编译器会将热点代码(频繁执行的代码)编译成本地代码,以便直接执行,极大地提高了程序的性能。
内存区(Memory Areas)
JVM内存区是执行Java程序过程中存储各种数据的地方。
它主要包括以下几个部分:
1、堆(Heap)
这是JVM的工作重地,所有的对象实例和数组都在这里分配内存。堆是在虚拟机启动时创建,是垃圾收集器管理的主要区域,因此也被称为GC堆(Garbage-Collected Heap)。
2、方法区(Method Area)
方法区与堆一样,是各个线程共享的内存区域。它用于存储已被虚拟机加载的类信息、常量、静态变量,以及即时编译器编译后的代码等。
3、程序计数器(Program Counter Register)
这是一小块内存空间,可以看作是当前线程所执行的字节码的行号指示器。每个线程都有一个程序计数器,是线程私有的。
4、虚拟机栈(VM Stack)
每个方法在执行的同时都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每个方法从调用直至执行完成的过程,就是一个栈帧在虚拟机栈中入栈到出栈的过程。
5、本地方法栈(Native Method Stack)
本地方法栈与虚拟机栈发挥的作用非常相似,差别在于虚拟机栈为虚拟机执行Java方法(即字节码)服务,而本地方法栈则为虚拟机使用到的Native方法服务。
3. 探秘JVM内存模型
了解JVM内存模型,就像是学会了如何给电脑升级内存一样,你会了解Java程序是如何使用内存的,以及如何高效利用内存。
- 堆和栈:堆是Java内存中最大的一块,用于存储对象实例,而栈用于存储局部变量和方法调用。堆是所有线程共享的,栈是每个线程私有的。
- 方法区:这里存储了每个类的结构信息,如运行时常量池、字段和方法数据、构造函数和普通方法的字节码内容。
- 直接内存:直接内存并不是JVM运行时数据区的一部分,但它经常被用于NIO操作,以提高性能。
打两个比喻来解释复杂的内存概念:
- 堆和栈:假设内存是一个仓库,堆就像仓库中的大仓库,存放着所有的货物(对象实例)。栈则像仓库里的货架,用于放置我们日常工作中需要用到的工具箱(局部变量)。
- 方法区和运行时常量池:这里可以想象成仓库的档案室,存放着产品说明书和制造标准(类信息和常量)。
理解JVM内存模型的重要性在于,它能帮助我们更好地管理系统资源,避免内存溢出和泄露,同时也是性能调优的基础。
例如,合理配置新生代和老年代的大小,可以优化垃圾收集器的性能,从而提高应用程序的响应速度和吞吐量。
在实际开发中,我们会使用JVM提供的监控和分析工具(如JConsole、VisualVM等)来观察和调整内存使用情况。
通过这些工具,可以了解到当前的堆内存使用状况、监控垃圾收集过程、查看方法区中类的加载情况等,这对于发现内存泄漏、调试以及提高应用性能非常有帮助。
4. 垃圾收集是什么?
垃圾收集器(Garbage Collector, GC)的任务是自动监控和回收JVM内存中不再使用的对象。
垃圾收集就像是JVM内部的清洁工,它帮助程序回收不再使用的内存空间,防止内存泄漏,确保程序的健康运行。
- 垃圾收集的基础:当程序创建对象后,如果这些对象不再被使用,就会成为垃圾收集器的回收目标。
- 垃圾收集器的种类:有多种垃圾收集器,例如Serial GC、Parallel GC、CMS GC、G1 GC等,不同的收集器适用于不同的场景和需求。
- 如何监控和调优:可以使用JDK的工具如jVisualVM、jConsole等来监控垃圾收集的情况,并根据情况进行调优。
举两个例子来说明垃圾回收的必要性和原理:
- 垃圾收集的基础:就像我们家中会定期扔掉不再使用的物品,JVM也需要定期清理不再使用的对象,以节省空间和资源。
- 垃圾收集器的种类:不同的房子(应用场景)可能需要不同类型的清洁工具(垃圾收集器),这部分将介绍最常见的几种垃圾收集器,和它们各自的优缺点。
虽然垃圾收集器减轻了内存管理的负担,但它们也会对应用性能产生影响。
因此,在选择垃圾收集器时,需要考虑应用程序的需求,如响应时间、吞吐量或内存大小等。
使用JVM提供的参数,可以调整垃圾收集器的行为,以达到最佳的应用性能。
理解垃圾收集的原理和不同垃圾收集器的特性,有助于在开发过程中做出更明智的决策,以及在性能调优中找到合适的平衡点。
同时,搭配适当的监控工具,定期分析垃圾收集日志,可以让我们及时发现并解决内存相关的问题。
5. 实战技巧:学习和使用JVM
- 安装和配置JVM:这就像是为你的Java程序搭建一个舞台。我将介绍如何设置环境变量,以及如何确定JVM参数。
- 使用JDK内置工具:这些工具就像是观察和诊断工具,可以帮助你了解JVM的内部工作情况。
1、安装和配置JVM
安装JVM通常是通过安装Java Development Kit(JDK)来完成的,因为JDK中包含了JVM。
配置JVM实际上就是在系统中设置一些环境变量,这些环境变量会告诉你的计算机如何找到Java编译器和运行时环境。
-
设置环境变量
你需要设置JAVA_HOME环境变量,它指向你安装JDK的目录。另外,还需要把%JAVA_HOME%\bin(Windows)或$JAVA_HOME/bin(Linux/Mac)添加到系统的PATH变量中,这样你才能在命令行中方便地运行java和javac命令。 -
确定JVM参数
JVM的行为可以通过传递参数来调整,例如堆大小(-Xms和-Xmx),选择垃圾收集器(-XX:+UseG1GC),生成堆转储文件(-XX:+HeapDumpOnOutOfMemoryError)等。这些参数可以在启动Java程序时传递给JVM,也可以在系统环境变量中设置。
2、使用JDK内置工具
JDK提供了许多强大的监控和故障排查工具,它们可以帮助开发者深入了解JVM的运行状况。
-
jconsole
这是一个Java监视和管理控制台,可以用来监控Java虚拟机的性能和资源消耗。 -
jvisualvm
它是一个多合一故障排除工具,包括了对JVM的实时监控、应用程序快照、堆转储分析、内存泄漏检测等功能。 -
jstat
用于收集并显示虚拟机运行时的性能数据,非常适合监控垃圾收集过程。 -
jmap
生成堆内存映射,对于分析堆内存使用和查找内存泄露非常有用。 -
jstack
这个命令可以生成虚拟机当前时刻的线程快照,通常用来分析线程的堆栈信息,对于定位线程阻塞和死锁等问题非常有帮助。 -
javap
Java反汇编命令,可以用来查看类文件中的字节码。
掌握这些工具,能帮助我们更好地理解JVM的内部运作机制,以及在开发、测试和生产环境中对Java应用程序进行有效的监控和故障排查。
实际运用中,最好结合日志信息及时调整JVM参数,以达到最优性能。
6. JVM的实战案例
通过真实的案例,我们可以看到JVM知识在实际开发中的应用,理论结合实践,帮助我们更好地理解和掌握JVM。
- 内存泄漏案例:我们将通过一个简单的购物车例子来解释内存泄漏,并展示如何定位和修复这些问题。
- 性能调优经历:我们将分享一个电商网站在“双十一”大促期间的性能调优案例,包括如何监控、定位瓶颈和调优策略。
1、内存泄漏案例
内存泄漏是指已分配的内存由于某种原因未被释放或未能回收,随着程序的运行,这些不再使用的内存占用会逐渐积累,最终可能导致内存溢出错误(OutOfMemoryError)。
-
案例描述
一个在线购物平台,用户在添加商品到购物车时,系统会创建一个购物车对象并保持会话。 -
但是,由于某些对象引用没有被正确清除,在用户会话结束后,购物车对象没有被垃圾收集器回收,导致内存泄漏。
-
定位和修复
使用JDK内置的工具,如jvisualvm,我们可以监控堆内存的使用情况。通过分析堆转储(Heap Dump),我们可以看到哪些对象占用了最多的内存,并检查这些对象的引用链。一旦找到问题点,我们可以检查相关的代码,比如session管理,确保在用户会话结束后,移除购物车对象的引用,允许垃圾收集器进行回收。
2、性能调优经历
性能调优是保证应用稳定运行、响应快速的关键环节,特别是在流量高峰期间,比如“双十一”。
-
案例描述
电商网站在“双十一”大促期间,面临巨大的访问压力。系统出现了响应延迟,分析后发现是由于垃圾收集器频繁执行Full GC造成的。 -
监控与定位瓶颈
通过JVM监控工具(如jconsole)可以实时监控JVM的各项性能指标。观察到垃圾收集的时间和频率异常上升。通过进一步分析GC日志,发现老年代(Old Generation)内存不足。 -
调优策略
调整了JVM的启动参数,增加了老年代的大小,并根据系统的实际运行情况调整了堆内存的初始大小(-Xms)和最大大小(-Xmx)。同时,进行了代码层面的优化,比如重用对象、减少大对象的创建等,减少了内存占用和GC压力。
通过实战经历,你会慢慢积累起一套属于自己的性能调优和问题定位的方法论。这不是一蹴而就的,而是需要在日常开发和维护中不断实践和学习。
7. JVM学习资源和社区
推荐一些个人认为还不错的资源和社区:
1、书籍推荐
-
《深入理解Java虚拟机》
这本书由周志明著作,是学习JVM的经典之作,书中不仅详细介绍了JVM的工作原理,还涉及了性能监控与调优,垃圾收集器与内存分配策略等实用内容。 -
《Java性能权威指南》
由Scott Oaks所著,这本书全面介绍了Java的性能。从代码层面到JVM,再到操作系统和硬件层面,都有深入的探讨和建议。 -
《Java并发编程实战》
虽然这本书重点在于并发,但良好的并发性能离不开对JVM内存模型的理解。书中对JVM内存模型有深入的讲解,是高级Java开发者必读的书籍。
2、在线资源
-
Oracle官方文档
这是获取最权威JVM信息的途径之一。Oracle的官方文档详细描述了JVM规范和JDK工具的使用。 -
InfoQ
InfoQ上有很多关于JVM的高质量文章、演讲以及新闻,是了解行业动态的好地方。 -
Stack Overflow
在这个问题和答案网站上,你可以找到关于JVM的大量技术问题和解决方案,也可以提出自己的疑问。
3、社区和论坛
-
Reddit上的 r/java
这里是一个活跃的Java社区,可以在这里找到很多关于JVM的讨论。 -
OpenJDK邮件列表
如果你对JVM的开发和未来方向感兴趣,可以关注OpenJDK邮件列表,那里有很多核心开发者参与讨论。 -
GitHub
关注一些开源JVM项目,比如OpenJDK、GraalVM等,可以了解到最前沿的开发动态,并且可以贡献代码或者提出问题。
通过这些社区的学习与交流,不仅能系统地学习JVM的理论知识,还能深入了解实际开发中的问题和解决方案,甚至参与到相关项目的贡献中去。
同时,与其他开发者的交流也能帮助你开阔视野,获得灵感,学习路上,遇到任何问题,提出来,社区里总会有人愿意帮忙。
8. 结语
JVM的学习是一个长期而有趣的过程,希望你能保持好奇心和实践精神,不断探索,不断学习。
求一键三连:点赞、分享、收藏
点赞对我真的非常重要!在线求赞,加个关注我会非常感激!@小郑说编程