生成模型 + 医学知识图谱 = 发现三元组新关系实体对
- 提出背景
- 问题:如何自动发现并生成医疗领域中未被标注的实体关系三元组?
- CRVAE模型
提出背景
论文:https://dl.acm.org/doi/pdf/10.1145/3219819.3220010
以条件关系变分自编码器(CRVAE)模型为基础,解决关系医疗实体对发现问题,并生成新的、有意义的医疗实体对。
尽管有些疾病与症状之间的关系已经被广泛记录,但仍然存在许多未被探索或记录的潜在关系。
问题1:医疗实体,如症状,可能以多种方式表达。
- “鼻塞”可以表述为“鼻子堵了”、“鼻塞”或“鼻腔阻塞”。
问题2:尽管数据库中记录了一些疾病与症状的关系,但还有许多未被发现或记录的关系。
- 发现隐藏的关系,如模型可能生成一个新的实体对<季节性过敏, 鼻塞>。
问题3:特定医疗关系的实体对发现
- 假设我们有一个巨大的医疗信息库,里面记录了很多关于疾病和症状之间的关系。
- 例如,“流感会引起发热”或“过敏会引起皮肤痒”。
- 但是,这个信息库并不完整,还有很多我们不知道的疾病和症状之间的关系。
- 怎么在不需要人工去一一验证每种可能的疾病和症状组合的情况下,自动发现新的医疗关系(疾病和症状之间的关系)。
总问题:如何在不依赖大量未标注数据和复杂数据预处理的情况下,自动发现这些新的、有意义的疾病与症状之间的关系?
- 问题1的解法:深度学习与贝叶斯推断:CRVAE结合了深度学习和贝叶斯推断的优点,通过无需手动特征工程的强大学习能力,捕捉医疗实体对的共性。
- 问题2的解法:基于密度的采样策略:CRVAE采用基于密度的采样策略,通过解码采样的潜在变量来生成新的医疗实体对。
- 问题3的解法:条件推断能力:CRVAE的条件推断能力使其能够更有效地为特定的医疗关系发现结构化医疗知识。
问题:如何自动发现并生成医疗领域中未被标注的实体关系三元组?
-
子问题1:无监督表示学习的效率问题
- 背景:传统的自编码器(AE)广泛用于无监督表示学习,但在具体生成任务上的应用受限。
- 子解法1:变分自编码器(VAE):采用VAE模型,通过建立输入数据与潜在变量间的概率分布关系,实现更具表现力的生成。
- 通过VAE,我们学习到“糖尿病”这样的疾病实体和“频繁尿意”这样的症状实体的潜在表示,捕捉到它们之间的统计关联性。
-
子问题2:生成特定类型数据的能力不足
- 背景:VAE能生成多种类型的数据,但难以生成属于特定类型的输出。
- 子解法2:条件变分自编码器(CVAE):引入CVAE,通过在模型中添加条件变量,实现生成特定类型数据的目标。
- 我们希望模型不仅能学习到疾病和症状之间的一般关系,还能生成具体的、未被标注的“引起”关系实体对。
- CVAE允许我们在生成过程中引入条件,如特定的“引起”关系,从而专注于生成表示该关系的疾病与症状实体对。
-
子问题3:特定医疗关系实体对的精准生成
- 背景:需要一种方法,能够精确生成表示特定医疗关系的实体对,如疾病和症状之间的“引起”关系。
- 子解法3:条件关系变分自编码器(CRVAE):开发CRVAE模型,不仅考虑了实体的初始表示,还引入了关系指示器作为输入,通过编码器、解码器和生成器三个模块的协同工作,有效地生成特定医疗关系的实体对。
- 我们需要一种机制,能够准确生成如“长时间坐姿”(疾病实体)与“下背痛”(症状实体)之间的“引起”关系,这种关系在数据集中可能尚未存在。
- 通过CRVAE,模型学习现有的实体对和它们的关系,如“糖尿病”和“频繁尿意”的“引起”关系。然后,模型能够生成新的、合理的实体对,比如预测“长时间坐姿”可能会“引起”“下背痛”。
-
为什么使用VAE:VAE通过建立数据的潜在概率分布模型,为生成可观测数据提供了理论基础,相较于传统AE,具有更强的表现力和生成能力。
-
为什么引入CVAE:在VAE的基础上引入条件变量(如类标签),CVAE能够生成符合特定条件的数据,这在需要控制生成数据类型时尤为重要。
-
为什么开发CRVAE:针对医疗实体关系发现的特定需求,CRVAE通过整合实体表示和关系指示器,实现了对特定医疗关系实体对的精准生成。这种方法不仅能够从现有数据中学习实体对之间的关系,还能够生成训练数据中未出现的新实体对,极大地扩展了医疗知识库。
这种分层次的解决方案结构,从基础的自编码器到针对具体应用场景的CRVAE模型,展示了如何通过深入分析问题的特征和背景,逐步提出并实施有效的解决策略。
在CRVAE模型训练完成后,我们向模型提供一个条件,即“引起”关系的标识。
模型接着在学习到的潜在空间中探索,并生成新的疾病与症状实体对,如生成了一个未在训练数据中直接观察到的实体对:“缺乏维生素D”(疾病实体)和“骨痛”(症状实体)之间的“引起”关系。
这个新生成的实体对为医疗研究和临床实践提供了可能的新见解,有助于扩展现有的医疗知识库。
CRVAE模型
-
学习阶段
在CRVAE模型的学习阶段,模型执行以下步骤:a. 输入数据获取:
模型接收医疗实体对,例如“糖尿病”和“视力模糊”作为输入。
这些实体对通过自然语言在医疗文本中被表述,可能包含不同的表达方式和同义词。b. 实体表示学习:
CRVAE模型使用预训练的词嵌入(word embeddings)来转换文本输入到数值向量,这些向量捕捉了实体的丰富语义信息。c. 编码器操作:
编码器网络部分接着将这些数值向量转换为潜在变量(latent variables),这个过程通过一系列的非线性变换层实现。
这些潜在变量旨在捕捉疾病与症状之间的核心关系特征。d. 特征提取:
在编码过程中,CRVAE模型学习到的是不仅与具体实体有关,还与它们之间的医疗关系相关的潜在特征。
例如,它可以学习到“糖尿病”和“视力模糊”之间的“引起”关系。
图示:

这张图展示了条件关系变分自编码器(CRVAE)在训练过程中的结构和工作流程。
图中描述了CRVAE模型的两个主要部分:编码器(Encoder)和解码器(Decoder),以及它们之间的潜在变量(Latent Variables)。
-
模型输入:
- 输入数据(在白色方框中),分别为头实体 ( e_h ) 和尾实体 ( e_t ),它们代表医疗实体对,如疾病和症状。
-
编码器(绿色部分):
- 实体通过预训练的嵌入(embeddings)转换为数值向量 ( embed_h ) 和 ( embed_t )。
- 这些嵌入通过一系列转换 ( trans ) 进一步处理,以增强与医疗关系相关的信息。
- 处理后的向量 ( trans_{ht} ) 被送入潜在变量层,生成均值 ( \mu ) 和方差 ( \sigma^2 ),这些变量结合了关系指示器 ( r )。
-
潜在变量(紫色部分):
- 均值 ( \mu ) 和方差 ( \sigma^2 ) 用于定义实体对的潜在空间分布,这是生成新的实体对的基础。
-
解码器(蓝色部分):
- 潜在变量 ( z ),从潜在空间分布中采样得到,结合关系指示器 ( r ),通过解码器网络重构实体对。
- 解码过程中,潜在变量重新转化为增强后的转换 ( trans’ ),进而重构为实体嵌入 ( embed’_h ) 和 ( embed’_t )。
- 这些重构的嵌入是原始输入实体对的近似表示,目标是最小化输入实体和重构实体之间的差异。
- 这样,模型就能学习如何有效地表示和重建医疗实体对。
-
重建过程:
- 在重建过程中,( trans’_h ) 和 ( trans’_t ) 被解码器网络处理,并尝试恢复成最初的实体嵌入 ( embed_h ) 和 ( embed_t )。
- 这一过程涉及到多层非线性变换,旨在复原实体对的原始数据表示。
-
模型输出:
- 解码器的输出 ( embed’_h ) 和 ( embed’_t ) 是头实体和尾实体的预测嵌入,它们反映了模型对原始输入的理解和重构能力。
这个过程使CRVAE能够学习如何从训练数据中捕捉到医疗实体对之间的复杂关系,并将这种理解用于生成新的、潜在的医疗实体对,这可能有助于发现之前未知的医疗关系。
模型的这种生成能力特别适用于数据稀疏的领域,比如医疗实体关系发现,其中许多潜在的关系可能尚未被发现或记录在现有的医疗数据库中。
-
生成阶段
学习阶段完成后,CRVAE模型进入生成阶段,执行以下步骤:a. 潜在空间采样:
模型在潜在空间中进行采样。
在这个空间中,每一点都代表了一种可能的医疗实体对关系。
这个采样过程是基于学习到的潜在变量的分布进行的。b. 解码器
操作:解码器网络部分接收潜在空间中的采样点,并将它们转换回医疗实体对的数值向量。
这一步骤是逆编码过程,目的是重建或生成新的实体对。c. 实体对生成:
通过解码过程,模型生成新的实体对,这些实体对尚未在医疗数据库中记录。
由于潜在空间的采样点可能对应于从未观察到的实体组合,因此这个过程能够产生新颖的医疗实体对。d. 输出解释:
生成的数值向量通过与预训练词嵌入的逆操作转换回自然语言实体。
这允许模型提出新的、有医学意义的疾病与症状关系,如可能由“糖尿病”引起的新症状“心脏疼痛”。e. 后处理和验证:
生成的实体对可能需要通过医疗专家进行验证,以确认它们的医学意义和新颖性。
这一步骤不是CRVAE模型自动执行的,通常是后续的一个步骤。
图示:
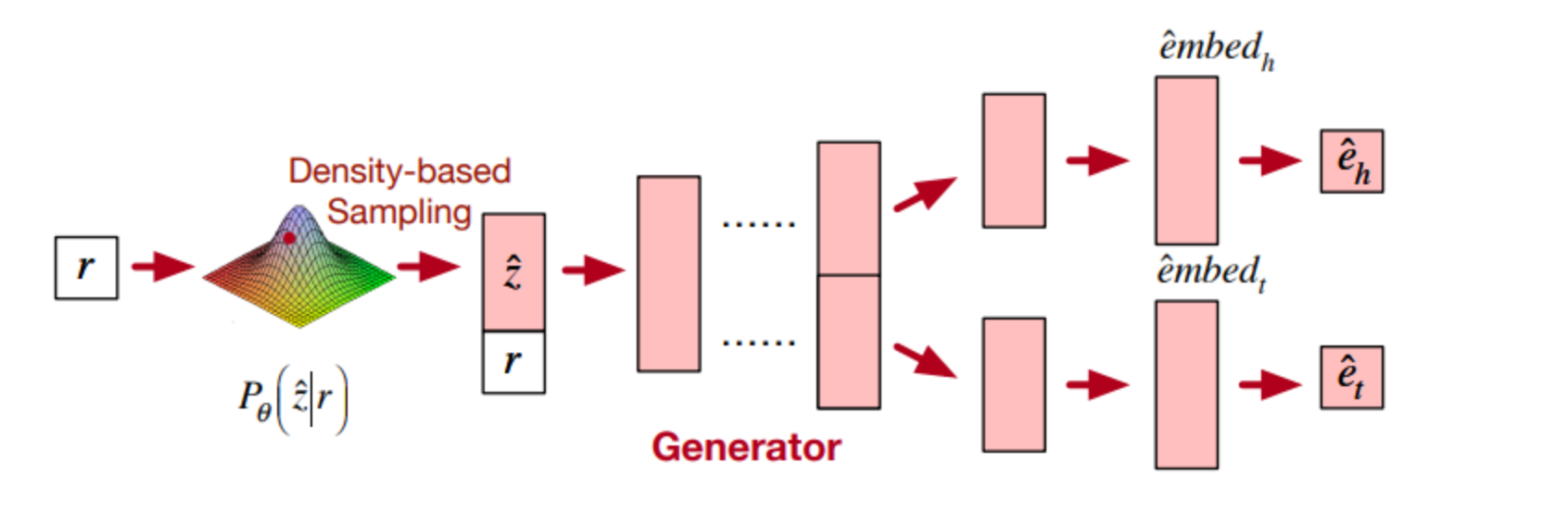
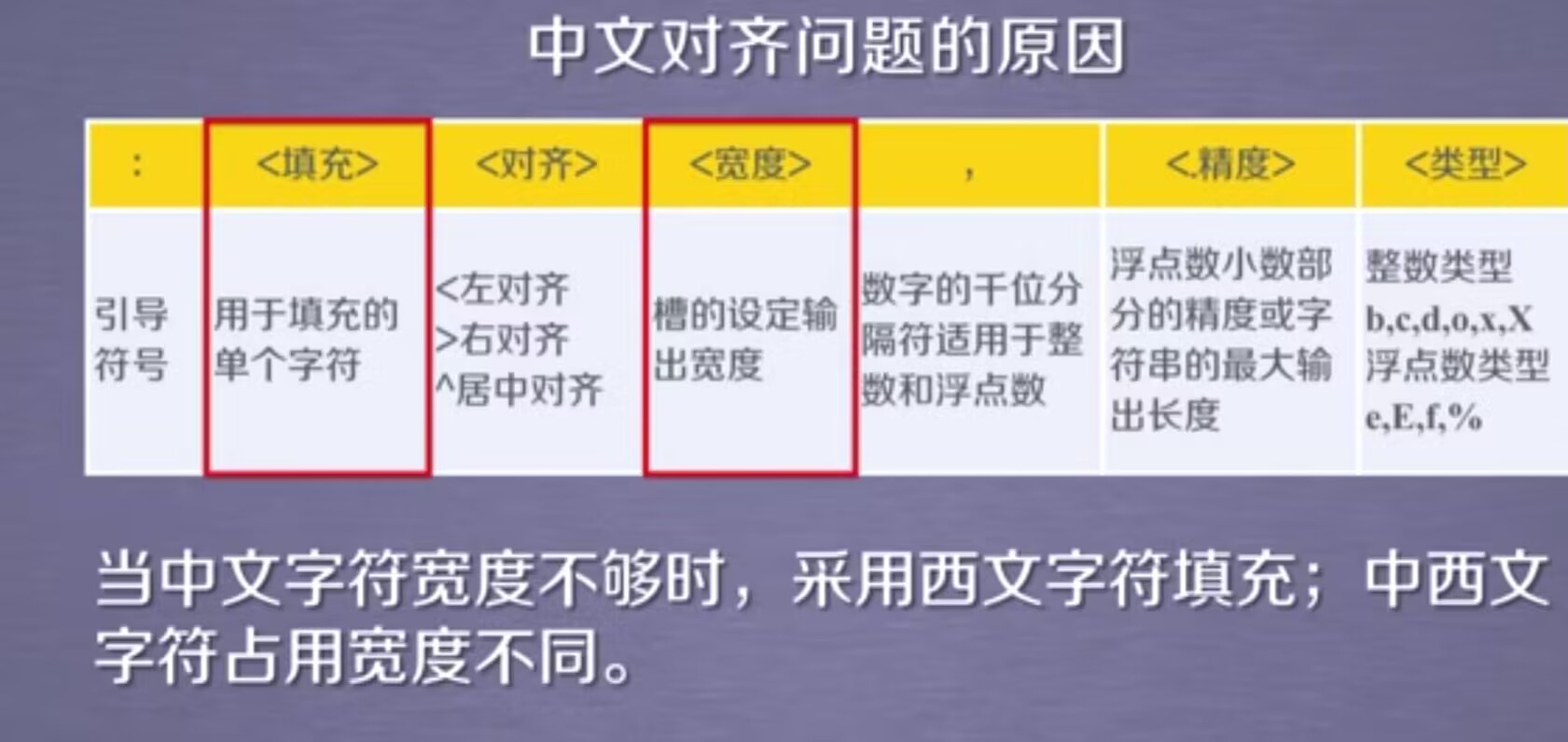
这张图是关于条件关系变分自编码器(CRVAE)中的生成器(Generator)模块的插图。
图解说明了生成器如何从潜在空间生成有意义的、新颖的医疗实体对。
-
密度基采样(Density-based Sampling):
- 这一步骤表示生成器如何在潜在空间中选择样本点。
- 密度基采样意味着从潜在空间中的高密度区域(即更可能的或常见的实体对区域)选择样本点。
-
潜在空间与实体关系指示器(r):
- 采样点(记为 z ^ \hat{z} z^ 结合了实体关系指示器(r),这里的 r 代表了医疗实体对之间的特定关系(例如“引起”)。
-
生成器网络:
- 接下来,采样点和关系指示器一起通过生成器网络。
- 这个网络的结构设计用于将潜在空间的点转换为可识别的医疗实体对。
-
生成医疗实体对:
- z ^ \hat{z} z^ 通过网络处理后,得到两个输出: e ^ h \hat{e}_h e^h 和 e ^ t \hat{e}_t e^t,这两个输出代表了生成的头实体(如疾病)和尾实体(如症状)。
-
结果:
- 最终结果是一对医疗实体,如 e ^ h \hat{e}_h e^h 可能代表一个特定的疾病,而 e ^ t \hat{e}_t e^t 代表该疾病可能引起的症状。
通过这个两阶段的过程,CRVAE模型利用从现有医疗实体对学习到的信息,能够生成新的、有医学价值的实体对。
它提供了一种在没有大规模标注数据的情况下自动扩展医疗知识库的有效方法。