Python实现EMV指标计算:股票技术分析的利器系列(2)
- 介绍
- 算法解释:
- 核心代码:
- rolling函数介绍
- 完整代码:
- 一定要看
介绍
先看看官方介绍:
EMV(简易波动指标)
用法
1.EMV 由下往上穿越0 轴时,视为中期买进信号;
2.EMV 由上往下穿越0 轴时,视为中期卖出信号;
3.EMV 的平均线穿越0 轴,产生假信号的机会较少;
4.当ADX 低于±DI时,本指标失去效用;
5.须长期使用EMV指标才能获得最佳利润。
算法解释:
VOLUME:=MA(VOL,N)/VOL;
MID:=100*(HIGH+LOW-REF(HIGH+LOW,1))/(HIGH+LOW);
EMV:MA(MID*VOLUME*(HIGH-LOW)/MA(HIGH-LOW,N),N);
MAEMV:MA(EMV,M);
| 指标 | 描述 | 计算方法 |
|---|---|---|
| MA (Moving Average) | 移动平均线 | 通过计算一段时间内的价格平均值来观察价格的长期趋势。 |
| VOLUME | 成交量 | 指在某一时间段内股票交易的总量。成交量通常被认为是价格走势的重要指标之一。 |
| MID | 价格中点 | 用于衡量价格在一个周期内的相对位置。计算方式为100*(最高价+最低价-上一周期的最高价+最低价)/(最高价+最低价)。 |
| EMV (Ease of Movement) | 动量潜在指标 | 通过价格变动和成交量的变化率之间的关系来计算,用于衡量价格相对于成交量的变化速度。 |
| MAEMV | EMV的移动平均值 | 通过计算EMV的移动平均线,可以进一步平滑数据,更好地观察价格走势的长期趋势。 |
这些数据都依赖于收盘价格。我们找一个股票进行参考:
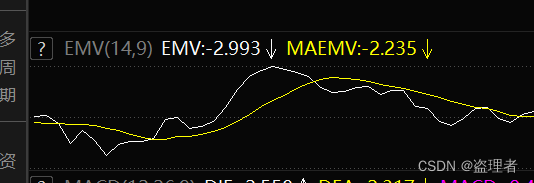
核心代码:
data:包含股票数据的DataFrame。n:用于计算移动平均值的窗口大小。m:用于计算MAEMV的窗口大小。
执行步骤:
- 计算VOLUME:首先计算成交量的移动平均值,并将其除以原始成交量,得到VOLUME。
- 计算MID:根据公式计算价格中点(MID)。
- 计算EMV:根据给定的数据,计算EMV值。这里使用了价格中点、VOLUME以及价格波动范围的移动平均值。
- 计算MAEMV:计算EMV的移动平均值,以平滑数据。
返回四个Series对象,分别是VOLUME、MID、EMV和MAEMV。
def calculate_EMV(data, n, m):# 计算VOLUMEdata['MA_VOL'] = data['VOL'].rolling(window=n).mean()data['VOLUME'] = data['MA_VOL'] / data['VOL']# 计算MIDdata['MID'] = 100 * (data['HIGH'] + data['LOW'] - data['HIGH'].shift(1) - data['LOW'].shift(1)) / (data['HIGH'] + data['LOW'])# 计算EMVdata['HL_MA'] = data['HIGH'] - data['LOW']data['MA_HL'] = data['HL_MA'].rolling(window=n).mean()data['EMV'] = data['MID'] * data['VOLUME'] * data['HL_MA'] / data['MA_HL']data['EMV'] = data['EMV'].rolling(window=n).mean()# 计算MAEMVdata['MAEMV'] = data['EMV'].rolling(window=m).mean()return data['VOLUME'], data['MID'], data['EMV'], data['MAEMV']
rolling函数介绍
rolling 函数通常与其他函数(如 mean、sum、std 等)一起使用,以计算滚动统计量,例如滚动均值、滚动总和等。
以下是 rolling 函数的基本语法:
DataFrame.rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0, closed=None)
window: 用于计算统计量的窗口大小。min_periods: 每个窗口最少需要的非空观测值数量。center: 确定窗口是否居中,默认为False。win_type: 窗口类型,例如None、boxcar、triang等,默认为None。on: 在数据帧中执行滚动操作的列,默认为None,表示对整个数据帧执行操作。axis: 执行滚动操作的轴,默认为0,表示按列执行操作。closed: 确定窗口的哪一端是闭合的,默认为None。
完整代码:
import pandas as pddef calculate_EMV(data, n, m):# 计算VOLUMEdata['MA_VOL'] = data['VOL'].rolling(window=n).mean()data['VOLUME'] = data['MA_VOL'] / data['VOL']# 计算MIDdata['MID'] = 100 * (data['HIGH'] + data['LOW'] - data['HIGH'].shift(1) - data['LOW'].shift(1)) / (data['HIGH'] + data['LOW'])# 计算EMVdata['HL_MA'] = data['HIGH'] - data['LOW']data['MA_HL'] = data['HL_MA'].rolling(window=n).mean()data['EMV'] = data['MID'] * data['VOLUME'] * data['HL_MA'] / data['MA_HL']data['EMV'] = data['EMV'].rolling(window=n).mean()# 计算MAEMVdata['MAEMV'] = data['EMV'].rolling(window=m).mean()return data['VOLUME'], data['MID'], data['EMV'], data['MAEMV']# 示例数据:数据可以参考附件文件,这里就展示一部分
data = {'HIGH': [35.6, 36.74, 38.21, 38.32, 38.2, 37.77, 38.88, 38.65, 38.8, 42.63, 37.75, 37.85, 37.74, 39.97, 38.88, 38.5, 39.07, 38.35, 36.33, 36.5, 38.3, 35.06, 35.66, 35.5, 33.76, 32.0, 34.0, 35.39, 35.1, 35.36, 33.74, 34.25, 37.41, 38.76, 39.0, 37.4, 36.83, 36.99, 37.45, 36.3, 36.4, 36.25, 36.21, 34.95, 33.29, 33.55, 33.05, 32.38, 34.38, 34.01, 34.01, 34.0, 36.3, 33.69, 32.36, 32.96, 32.51, 33.86, 33.44, 32.87, 32.23, 32.68, 31.26, 29.7, 28.36, 28.2, 27.25, 27.1, 27.98, 28.18, 28.36, 27.84, 26.85, 26.03, 25.68, 24.9, 24.98, 24.69, 25.33, 24.95, 23.98, 23.71, 22.87, 23.55, 23.6, 23.38, 22.82, 22.34, 23.99, 24.46, 22.47, 21.39, 20.36, 19.73, 19.44, 18.06, 17.17, 18.15, 17.31],'LOW': [32.89, 33.08, 36.43, 35.97, 36.4, 35.13, 36.3, 37.0, 37.27, 37.91, 35.88, 35.64, 35.9, 36.3, 37.52, 37.28, 36.4, 37.0, 33.34, 32.65, 34.6, 33.0, 32.8, 33.58, 30.8, 30.4, 30.5, 33.02, 33.09, 33.5, 32.72, 32.8, 35.0, 36.51, 36.22, 35.75, 35.84, 35.65, 35.89, 35.37, 35.45, 35.34, 34.38, 32.91, 32.33, 32.43, 32.34, 31.34, 31.3, 33.09, 32.81, 33.04, 34.11, 31.88, 31.72, 32.04, 31.68, 32.37, 32.35, 31.9, 31.8, 30.0, 29.07, 27.96, 27.01, 26.6, 25.89, 26.36, 26.4, 27.09, 27.68, 26.85, 24.7, 25.29, 24.48, 23.77, 23.72, 23.5, 24.0, 23.59, 23.0, 22.63, 21.85, 21.88, 22.7, 21.39, 21.2, 21.21, 21.7, 22.55, 20.84, 20.15, 18.82, 18.41, 17.48, 16.43, 15.3, 15.88, 15.5],'VOL': [45580764, 54578742, 75472698, 55958044, 43471376, 39089870, 65993166, 51725987, 59664851, 95828287, 64692075, 54151833, 54581088, 75630350, 40636266, 32590643, 46535705, 32208972, 65659275, 67488698, 57100011, 37509303, 44494331, 42006720, 56294769, 34236402, 57346512, 52584472, 46156969, 37854741, 30233442, 36844909, 74136219, 93002594, 72105475, 50722258, 30929788, 37269600, 32723194, 27491825, 26022766, 29478877, 37061997, 48042058, 22018987, 18617008, 16107171, 24764608, 47160698, 27157282, 27117523, 19243785, 55337568, 46107093, 22111567, 26169489, 18677657, 33233951, 22255922, 16218969, 11992250, 20560729, 37683555, 33974856, 28911947, 30993108, 23882463, 16380457, 38697438, 33720984, 33462661, 24071288, 40303016, 19186983, 26433462, 26414742, 36953528, 29789634, 54935510, 43667255, 28811811, 39282170, 38366540, 76358853, 40857274, 33171789, 44004578, 35894397, 70170103, 110181175, 62916228, 44189093, 46894875, 46711694, 45525470, 50214148, 56091415, 68644768, 78480358]
}# 转换为DataFrame
df = pd.DataFrame(data)# 设置参数
N = 14
M = 9# 计算指标
volume, mid, emv, maemv = calculate_EMV(df, N, M)print("VOLUME:")
print(volume)
print("\nMID:")
print(mid)
print("\nEMV:")
print(emv)
print("\nMAEMV:")
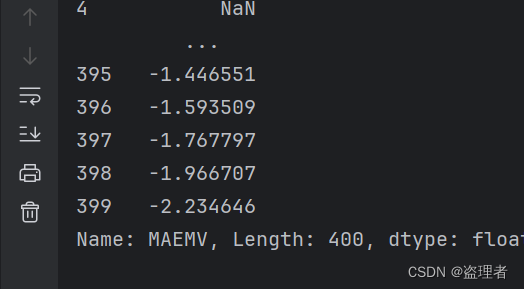
print(maemv)四舍五入后:就是 -2.235,和图片一致了,数据越多指标小数点末尾也会随之变化
一定要看
EMV 指标的准确性取决于所选择的窗口大小以及市场的波动性。一般来说,窗口大小越大,需要的数据量也就越多才能获得更准确的结果。
通常来说,为了获得相对准确的 EMV 指标,至少需要足够长的时间序列数据,以便考虑到市场的变化和波动性。具体来说,EMV 的准确性至少需要数月甚至数年的数据,这样可以更好地捕捉到市场的长期趋势和周期性变化。
然而,对于具体的市场和交易策略,可能需要进行测试和优化,以确定合适的窗口大小和所需的历史数据量。




![【蓝桥杯冲冲冲】[CEOI2015 Day2] 世界冰球锦标赛](https://img-blog.csdnimg.cn/direct/eb56df1dfcbe45408a5d9b024cd53b02.jpeg#pic_center)






