掌握Pandas.to_datetime函数:时间序列数据处理的利器
在数据处理和分析中,时间序列数据的处理是一个重要的环节。Pandas库中的to_datetime函数为我们提供了一个方便而强大的工具,用于将字符串或数字等格式的日期转换为Pandas中的datetime对象。本文将介绍Pandas.to_datetime函数的基础知识,并通过实际代码示例演示如何在数据分析中运用这一函数。

1. to_datetime函数基础
to_datetime函数的基本语法如下:
pandas.to_datetime(arg, errors='raise', dayfirst=False, yearfirst=False, utc=None, format=None, exact=True, unit=None, infer_datetime_format=False, origin='unix', cache=False)
其中,常用的参数有:
arg:待转换为日期时间的对象,可以是字符串、列表、Series等。errors:指定错误处理方式,可选值为’raise’、‘coerce’和’ignore’。format:指定日期时间的格式,用于提高转换速度。unit:指定输入数据的时间单位,如’s’表示秒。
2. 代码实战
下面我们通过一个实际的例子来演示如何使用to_datetime函数处理时间数据。假设我们有一个包含日期字符串的DataFrame,我们希望将其转换为datetime类型,并进行一些基本的时间操作。
import pandas as pd# 创建包含日期字符串的DataFrame
data = {'date_str': ['2022-01-01', '2022-02-15', '2022-03-20']}
df = pd.DataFrame(data)# 将字符串列转换为datetime类型
df['datetime'] = pd.to_datetime(df['date_str'])# 输出转换后的DataFrame
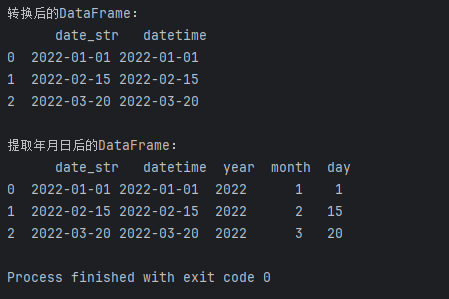
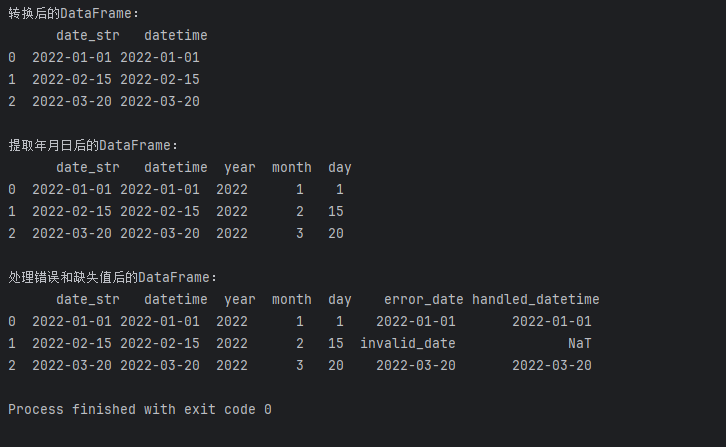
print("转换后的DataFrame:\n", df)# 提取年份、月份和日期
df['year'] = df['datetime'].dt.year
df['month'] = df['datetime'].dt.month
df['day'] = df['datetime'].dt.day# 输出提取后的DataFrame
print("\n提取年月日后的DataFrame:\n", df)
在上面的代码中,我们首先创建了一个包含日期字符串的DataFrame,然后使用to_datetime函数将其转换为datetime类型的新列。接着,通过dt属性,我们提取了年、月、日等时间信息,并将其作为新的列添加到DataFrame中。
3. 代码解析
pd.to_datetime(df['date_str']):使用to_datetime函数将日期字符串列转换为datetime类型,并创建新的列。df['datetime'].dt.year:使用dt属性提取datetime列的年份。df['datetime'].dt.month:提取datetime列的月份。df['datetime'].dt.day:提取datetime列的日期。
通过这些操作,我们成功地将日期字符串转换为datetime对象,并进行了一些基本的时间操作,使得我们能够更方便地进行后续的数据分析和可视化工作。
总的来说,Pandas.to_datetime函数是处理时间序列数据的重要工具,掌握其基础用法并灵活运用可以大大提高数据处理的效率和准确性。在实际工作中,根据数据的不同特点,可以灵活调整函数的参数以满足具体需求。
4. 错误处理与优化
在使用to_datetime函数时,经常会遇到一些数据格式错误或缺失值。errors参数允许我们指定对于这些情况的处理方式:
errors='raise'(默认):当发生错误时,抛出异常。errors='coerce':将无法转换的值设为NaT(Not a Time)。errors='ignore':忽略错误,保留原始数据。
# 处理错误和缺失值
df['error_date'] = ['2022-01-01', 'invalid_date', '2022-03-20']
df['handled_datetime'] = pd.to_datetime(df['error_date'], errors='coerce')# 输出处理后的DataFrame
print("\n处理错误和缺失值后的DataFrame:\n", df)
上述代码中,我们故意在日期字符串中引入一个无效的日期,并使用errors='coerce'将无法转换的值设为NaT,以便更好地处理错误情况。
5. 优化性能
为了提高处理大量时间序列数据的性能,我们可以使用infer_datetime_format参数来告知Pandas尝试推断输入数据的日期时间格式。这样可以避免逐个尝试各种格式,提高转换速度。
# 优化性能
df['optimized_datetime'] = pd.to_datetime(df['date_str'], infer_datetime_format=True)# 输出优化性能后的DataFrame
print("\n优化性能后的DataFrame:\n", df)
使用infer_datetime_format=True参数,Pandas将尝试根据输入数据的格式推断日期时间格式,从而提高转换效率。
7. 扩展应用:处理时间间隔
除了处理日期时间,to_datetime函数还能处理时间间隔的数据,如处理时间差异或持续时间的情况。通过设置unit参数,我们可以指定输入数据的时间单位。
# 扩展应用:处理时间间隔
df['duration'] = ['2 days', '5 hours', '3 minutes']
df['timedelta'] = pd.to_datetime(df['duration'], unit='s')# 输出处理时间间隔后的DataFrame
print("\n处理时间间隔后的DataFrame:\n", df)
上述代码中,我们创建了一个包含时间间隔字符串的列,并使用to_datetime函数将其转换为timedelta类型。通过设置unit='s'参数,我们告诉Pandas输入数据的时间单位是秒,从而正确解析时间间隔。
8. 时间序列索引
to_datetime函数还可以用于创建时间序列索引,使得时间成为数据框的索引,方便进行时间相关的分析和切片操作。
# 创建时间序列索引
df.set_index('datetime', inplace=True)# 输出带有时间序列索引的DataFrame
print("\n带有时间序列索引的DataFrame:\n", df)
在上述代码中,我们使用set_index函数将datetime列设置为数据框的索引,从而创建了时间序列索引。
10. 高级应用:自定义日期格式
在实际情况中,数据集中的日期时间格式可能会因为多样性而变得复杂。to_datetime函数提供了format参数,允许我们指定自定义的日期时间格式。
# 高级应用:自定义日期格式
df['custom_date'] = ['20220214', '2023-08-30']
df['custom_datetime'] = pd.to_datetime(df['custom_date'], format='%Y%m%d')# 输出使用自定义日期格式后的DataFrame
print("\n使用自定义日期格式后的DataFrame:\n", df)
在上述代码中,我们创建了一个包含自定义日期格式的列,并使用to_datetime函数将其转换为datetime类型。通过设置format='%Y%m%d'参数,我们告诉Pandas数据集中的日期时间遵循年月日的格式。
11. 多列合并
有时,我们需要将数据集中的多个列合并为一个datetime列,这时候可以利用pd.to_datetime函数的多列合并功能。
# 多列合并为datetime
df['date'] = ['2022-01-01', '2022-02-15']
df['time'] = ['12:30', '18:45']
df['combined_datetime'] = pd.to_datetime(df['date'] + ' ' + df['time'])# 输出合并后的DataFrame
print("\n合并多列为datetime后的DataFrame:\n", df)
通过将日期和时间列进行字符串拼接,然后使用to_datetime函数转换为datetime类型,我们成功地将多列合并为一个datetime列。
13. 高级技巧:处理时区信息
Pandas.to_datetime函数还支持处理时区信息,使得我们能够更好地处理跨时区的时间序列数据。通过utc参数,我们可以将时间序列数据转换为协调世界时(UTC)。
# 高级技巧:处理时区信息
df['datetime_utc'] = pd.to_datetime(df['date_str'], utc=True)# 输出带有时区信息的DataFrame
print("\n带有时区信息的DataFrame:\n", df)
在上述代码中,我们使用utc=True参数将转换后的datetime列标记为UTC时区。这对于处理全球性的时间序列数据是非常有用的。
14. 处理非标准时间格式
有时,数据中的时间信息可能以非标准格式存在,这时候我们可以通过自定义的函数将其转换为标准格式。
# 处理非标准时间格式
def custom_parser(date_str):# 自定义处理逻辑,例如:将月份缩写转换为数字month_mapping = {'Jan': '01', 'Feb': '02', 'Mar': '03', 'Apr': '04', 'May': '05', 'Jun': '06','Jul': '07', 'Aug': '08', 'Sep': '09', 'Oct': '10', 'Nov': '11', 'Dec': '12'}date_parts = date_str.split('-')date_parts[1] = month_mapping.get(date_parts[1], date_parts[1])return '-'.join(date_parts)# 应用自定义解析函数
df['non_standard_date'] = ['2022-Jan-01', '2022-Feb-15']
df['parsed_datetime'] = pd.to_datetime(df['non_standard_date'].apply(custom_parser))# 输出处理后的DataFrame
print("\n处理非标准时间格式后的DataFrame:\n", df)
在上述代码中,我们定义了一个自定义的解析函数custom_parser,用于处理非标准的日期时间格式。然后,通过apply函数将该解析函数应用于数据集中的非标准日期字符串列。
总结
通过本篇技术博客,我们深入探讨了Pandas库中的强大工具——to_datetime函数,它在处理时间序列数据时展现了出色的灵活性和功能。以下是本文的主要亮点:
-
基础知识与语法: 我们首先介绍了
to_datetime函数的基础知识,包括函数的语法和常用参数,使读者对该函数有了全面的了解。 -
代码实战: 通过实际代码示例,我们展示了如何使用
to_datetime函数将日期字符串转换为datetime类型,并演示了基本的时间操作,如提取年月日等。 -
错误处理与优化: 我们讨论了处理错误和缺失值的方法,以及如何通过设置参数优化性能,提高函数的转换速度。
-
扩展应用: 我们展示了
to_datetime函数在处理时间间隔、创建时间序列索引等方面的扩展应用,使读者能更灵活地处理不同类型的时间序列数据。 -
高级技巧: 通过案例,我们介绍了一些高级技巧,包括处理时区信息、自定义日期格式、多列合并以及处理非标准时间格式,拓展了读者在实际工作中处理时间序列数据的能力。
-
总结与展望: 最后,我们总结了
Pandas.to_datetime函数的关键用法和优势,并鼓励读者灵活运用这一工具。同时,我们提到了结合其他库和技术,可以更全面地满足不同数据处理需求。
通过学习本文,读者应该对Pandas.to_datetime函数有了更深入的理解,并能够在实际工作中灵活运用,提高数据处理的效率和准确性。时间序列数据的处理是数据科学家和分析师工作中的常见任务,而to_datetime函数无疑是解决这类问题的得力助手之一。希望读者能够充分利用这一工具,更加轻松地应对日常的数据挑战。
![[Java][算法 滑动窗口]Day 02---LeetCode 热题 100---08~09](https://img-blog.csdnimg.cn/direct/a5a604495a964d8e9768e5917c5f0b70.png)


![[计算机网络]---网络编程套接字](https://img-blog.csdnimg.cn/direct/9ba6711f9d244203bf22160cc92332a5.png)