一、什么是原子操作
通常某一个变量的操作对应的CPU指令是大于一个的,在多线程环境下,为了确保对共享变量的操作在执行时不会被干扰,从而避免竞态条件和死锁等问题,使用原子变量。
原子变量可以看作是一种特殊的类型,它具有类似于普通变量的操作,但是这些操作都是原子操作,即要么全部完成,要么全部未完成。C++标准库提供了丰富的原子类型,包括整型、指针、布尔值等。通过std::atomic可以定义一个原子变量。
std::atomic<T>
is_lock_free: 是否支持无所操作
store(T desired, std::memory_order order): 写操作,用于将指定的值存储到原子变量中
load(std::memory_order order): 读操作,用于获取原子变量的当前值
exchange(std::atomic<T> *obj, T desired): 访问和修改原子变量的值,将原子变量的值替换为 desired,并返回原来的值
compare_exchange_weak(T& expected, T val, memory_order success, ,memory_order failure): 比较一个值和期望值是否相等,如果不相等则将该值替换为一新值并返回 false,否则不做任何操作并返回 true.
二、原子性
1. 单处理器单核的情况
需要保证操作指令序列不被打断,实现机制:
屏蔽中断、底层自旋锁
2. 多核或者多处理器
除了不被打断,还需要避免其它核心操作相关的内存空间,实现方法:
lock 指令阻止其它核心对相关内存空间的访问
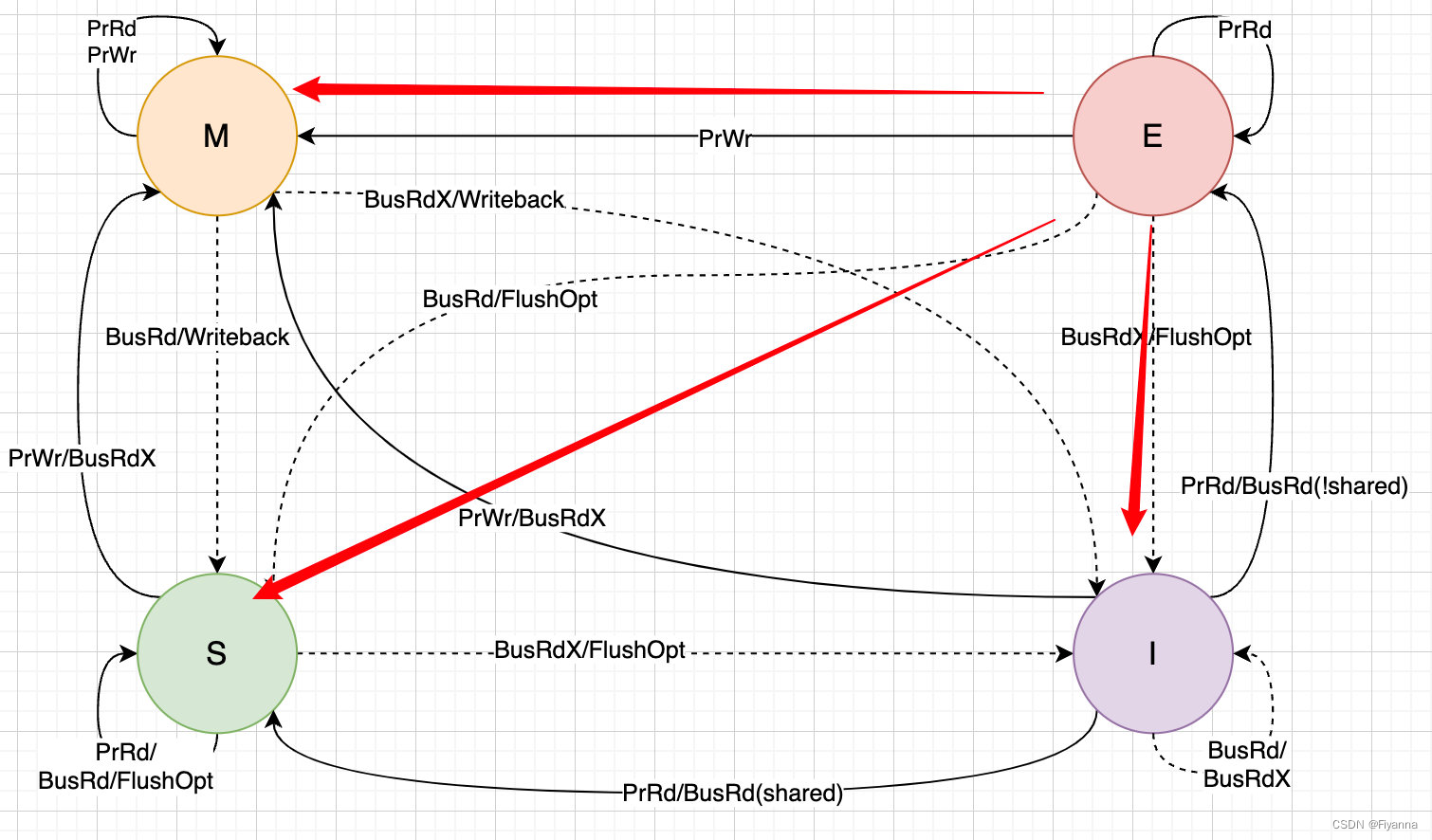
3. MESI 一致性协议
MESI 协议是一个基于失效的缓存一致性协议,支持 write-back 写回缓存的常用协议。
总线嗅探策略:将读写请求通过总线广播给所有核心,核心根据本地状态进行响应
Cache Line中的 flag 的四种状态:
Modified: 已修改,某个数据块在某核心中已修改但是没有同步到内存中
Exclusive: 独占,某个数据块只在某一个核心中,并且缓存和内存中的数据一致的
Shared: 共享,某个数据块在多个核心中加载,并且缓存和内存中数据一致
Involidated: 已失效,某个数据在核心中已失效,不是最新的数据
事件:
- PrRd : 核心从缓存中读取数据请求
- PrWr : 核心从缓存中写入数据请求
- BusRd : 总线嗅探器收到来自其它核心的读出缓存数据请求
- BusRdX : 总线嗅探器收到另一个核心写一个其不拥有的缓存块的请求
- BusUpgr : 总线嗅探器收到另一个核心写一个其拥有的缓存块的请求
- Flush : 总线嗅探器收到另一个核心把一个缓存块写回到主存的请求
- FlushOpt :总线嗅探器收到一个缓存块被放置在总线以提供给另一核心的请求,和 Flush 类似但是为缓存到缓存的数据传输
状态机
三、内存序
为什么有内存序问题:
编译器优化重排
CPU指令优化重排
内存序规定了什么
规定了多个线程访问同一个内存地址时的语义:
- 某个线程对内存地址的更新何时能被其它线程看到
- 某个线程对内存地址访问附近可以做什么样的优化
内存模型
C/C++11标准中提供了6种memory order,来描述内存模型
enum memory_order {memory_order_relaxed,memory_order_consume,memory_order_acquire,memory_order_release,memory_order_acq_rel,memory_order_seq_cst
};
memory_order_relaxed
relaxed表示一种最为宽松的内存操作约定,仅仅保证load()和store()是原子操作, 除此之外,不提供任何跨线程的同步,不干预编译器或CPU的优化
memory_order_release
在写入某原子对象时,当前线程的仍任何前面的读写操作都不允许重排到这个操作的后面,并且当前线程的所有内存写入都在对同一个原子对象进行获取的其它线程可见。通常与 memory_order_acquire 配对使用
memory_order_acquire
在读取某原子对象时,当前线程的任何后面的读写操作都不允许重排到这个操作的前面去,并且其它线程在对同一个原子对象释放之前的所有内存写入都在当前的线程中可见。通常与 memory_order_release 配合使用
memory_order_acq_rel
同时存在读写操作,前后读写操作都不允许重排。当前线程的所有内存写入都在对同一个原子对象进行获取的其它线程可见
memory_order_sec_cst
是所有原子操作的默认内存序,最严格的顺序一致性。会对所有使用此模型的原子操作建立一个全局顺序,保证了多个原子变量的操作,在所有线程里观察到的操作顺序相同,当然它是最慢的同步模型
四、使用原子操作实现无锁队列
使用场景
高性能、低延时场景中如信号处理程序,硬实时系统
MPSC队列具体实现
#include <atomic>
#include <utility>template<typename T>
class MPSCQueue{
private:struct Node{Node() = default;explicit Node(T* data) : Data(data){Next.store(nullptr, std::memory_order_relaxed);}T* Data;std::atomic<Node*> Next;};std::atomic<Node*> _head;std::atomic<Node*> _tail;
public:MPSCQueue() : _head(new Node()), _tail(_head.load(std::memory_order_relaxed)){Node* front = _head.load(std::memory_order_relaxed);front->Next.store(nullptr, std::memory_order_relaxed);}void Enqueue(T* input){Node* node = new Node(input);Node* prevHead = _head.exchange(node, std::memory_order_acq_rel);prevHead->Next.store(node, std::memory_order_release);}bool Dequeue(T*& result){Node* tail = _tail.load(std::memory_order_relaxed);Node* next = tail->Next.load(std::memory_order_acquire);if (!next)return false;result = next->Data;_tail.store(next, std::memory_order_release);delete tail;return true;}~MPSCQueueNonIntrusive(){T* output;while (Dequeue(output))delete output;Node* front = _head.load(std::memory_order_relaxed);delete front;}
};