文章目录
- 前言
- 代码
- 数据
- 熵权法代码
- 结果
前言
熵权法做实证的好像很爱用,matlab的已经实现过了,但是matlab太大了早就删了,所以搞一搞python实现的,操作空间还比较大
代码
数据
import pandas as pd
data = [[100,90,100,84,90,100,100,100,100],[100,100,78.6,100,90,100,100,100,100],[75,100,85.7,100,90,100,100,100,100],[100,100,78.6,100,90,100,94.4,100,100],[100,90,100,100,100,90,100,100,80],[100,100,100,100,90,100,100,85.7,100],[100,100,78.6,100,90,100,55.6,100,100],[87.5,100,85.7,100,100,100,100,100,100],[100,100,92.9,100,80,100,100,100,100],[100,90,100,100,100,100,100,100,100],[100,100,92.9,100,90,100,100,100,100]]
data = pd.DataFrame(data)
熵权法代码
from sklearn.preprocessing import MinMaxScaler
import numpy as np# 需要进行评价的特征(一般列名)
selected_features = list(data.columns.values)# 对选取的特征进行归一化
scaler = MinMaxScaler()
norm_data = scaler.fit_transform(data[selected_features]) #定义熵值法函数、熵值法计算变量的权重
def cal_weight(feature_num,sample_num,value):p= np.array([[0.0 for i in range(feature_num)] for i in range(sample_num)]) for i in range(feature_num):value[:,i] += 1e-10 # 防止log0p[:,i]=(value[:,i])/np.sum(value[:,i],axis=0) # 计算特征值占比e=-1/np.log(sample_num)*sum(p*np.log(p)) #计算熵值g=1-e # 计算一致性程度w=g/sum(g) #计算权重return wf_num = len(selected_features) # 指标个数
s_num = len(data.index.values) # 方案数、评价主体
w = cal_weight(f_num, s_num, norm_data)
w = pd.DataFrame(w,index=selected_features,columns=['weight']) # 计算出的权重
scores = np.dot(data,w).round(2) # 计算综合分数
result = pd.DataFrame(scores,index=data.index.values,columns=['score']).sort_values(by =['score'],ascending = False) # 对球员的分数进行排名结果
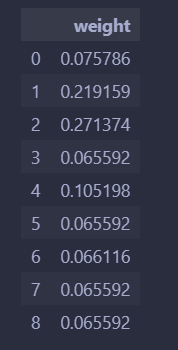
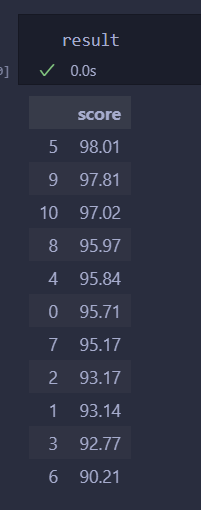
和matlab结果差不多,可能归一化不一样有点差别。
不过这里指标都是正向的,即越大越好,负向指标、区间指标等还并未兼容,以后要是用到了再说吧。