欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送!
在我后台回复 「资料」 可领取
编程高频电子书!
在我后台回复「面试」可领取硬核面试笔记!文章导读地址:点击查看文章导读!
感谢你的关注!

十亿量级评论表SQL调优实战
先说一下案例背景:
在电商系统的评论表中,数据量非常大,达到了十亿量级,因此对评论的数据库进行分库分表处理,在分库分表之后,基本上单表的评论数据在百万级别左右
那么就存在着某些商品比较火爆,销量达到几百万,评论的数量也有几十万条,用户可能会查看该商品中的评论,不停的分页查询,以及跳转到某一页查看具体的好评、差评信息,SQL 语句如下:
select * from comments where product_id = xx and is_good_comment = 1 order by desc limit 10000, 20
上边 SQL 语句的意思就是从评论表中取出来 20 条数据,limit 中的 offset 为 10000 条,分页中每页 20 条数据,10000 条数据也就是 500 页,表明用户要查询第 501 页的好评数据
**索引建立情况:**评论表中的核心索引为 index_product_id ,那么你可能会有疑问,为什么不对 (product_id, is_good_comment) 两个字段做联合索引呢?不要着急,在下边会说这个问题
慢查询原因分析:
那么上边的 SQL 语句出现了慢查询的情况,SQL 执行耗时达到 1-2 秒,接下来我们根据已知信息分析一下为什么 SQL 耗时这么久
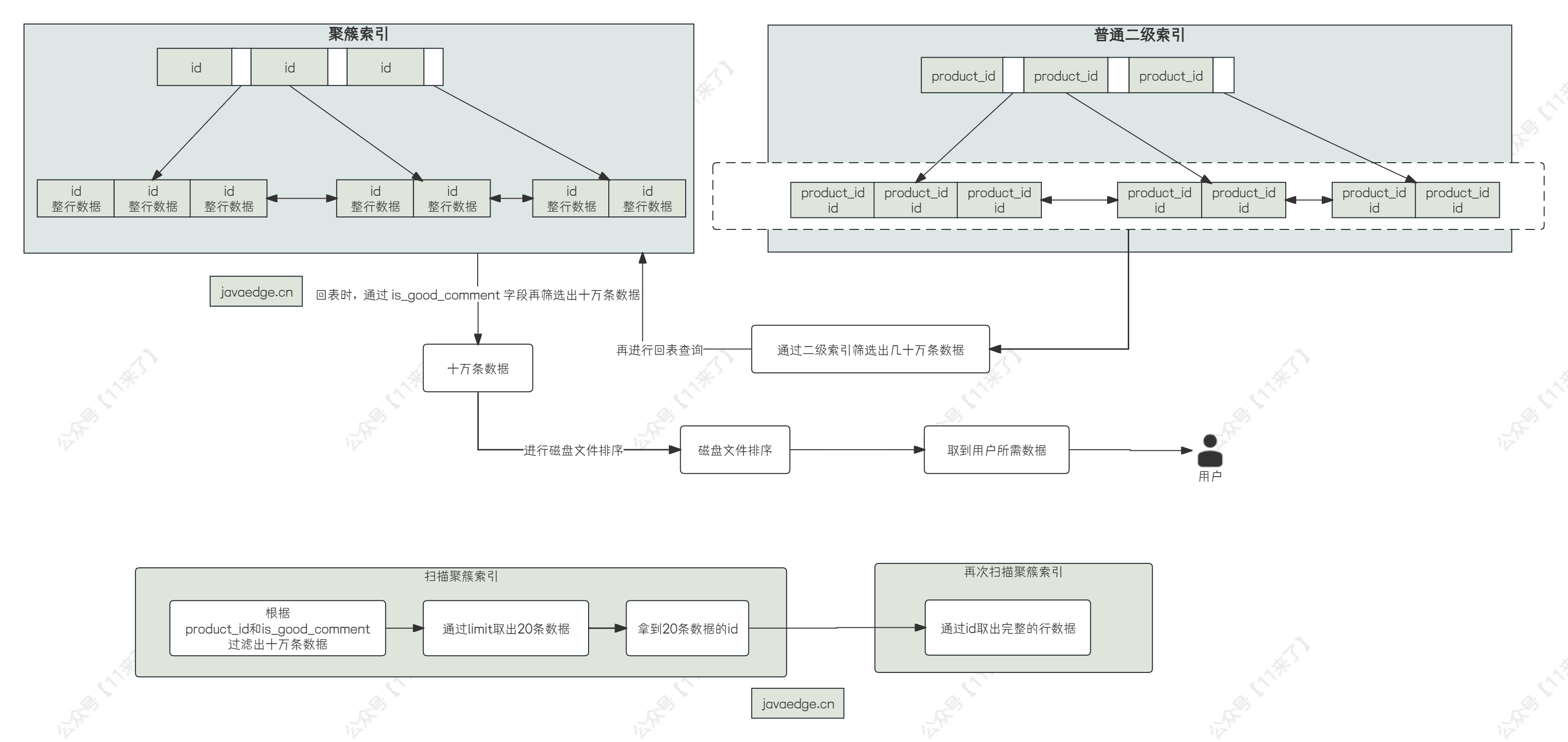
where 条件中使用 product_id 进行条件过滤,而 product_id 作为索引存在,因此 MySQL 是会走这个二级索引的,但是由于是 select *,因此走二级索引查不到全部的数据,因此还需要进行回表查询
那么上边 SQL 执行的流程是先通过 product_id 索引对评论数据进行筛选,就按火爆商品来举例,筛选出来几十万条评论数据,那么接下来还要拿这几十万条评论数据回表查询,回表时通过 is_good_comment 字段筛选数据,筛选完数据之后可能还有十万条数据,此时再根据 id 字段进行倒序排序,这里又是基于临时磁盘文件进行排序,比较耗时,排序完毕之后,再根据偏移量取出当前分页的数据
因此,通过分析,这条 SQL 慢在了两个地方,第一是拿了几十万条数据进行回表查询;第二是对十万条数据进行磁盘排序
SQL 优化:
这里是有三个优化方案的:
- 第一个方案是对
(product_id, is_good_comment)建立联合索引,product_id 值是唯一的,但是 is_good_comment 字段的值就几个,如果建立联合索引会导致数据分布的不均匀,并且可能在用户评论之后,会有后台定时任务来对 is_good_comment 字段更新,更新时会导致索引节点移动,因此 is_good_comment 不适合用于建立联合索引,所以没有使用这种方案 - 第二个方案是使用 force index 强制 MySQL 走聚簇索引,但是一般不建议使用 force index,因此没有使用这种方案
- 第三个方案是改写 SQL 语句,本次优化使用的就是这种方案
改写后的 SQL 语句如下:
select * from comments a, (select id from comments where product_id = xx and is_good_comment = 1 order by id desc limit 10000, 20) b where a.id = b.id;
通过执行计划可以看到,上边的 SQL 语句会先执行括号内的子查询,执行子查询的时候 MySQL 就会认为直接走聚簇索引比较快一些,根据 id 倒序扫描数据,在扫描过程中根据 product_id 和 is_good_comment 两个字段进行数据的过滤,此时过滤出来了十万条数据,再通过 limit 取出来我们所需要的 20 条数据
接着就会拿这 20 条数据再去聚簇索引中找到完整的数据就可以了,优化之后 SQL 执行耗时为几百毫秒,流程如下:

总结一下: 昨天我们说的 SQL 调优案例是强制让 MySQL 走二级索引来优化,但是这一次是我们通过修改 SQL 语句来让 MySQL 走聚簇索引来优化,因此在 MySQL 中对 SQL 的优化方式并不是固定的,也没有通用的方法,因此一定要掌握执行计划,了解 SQL 底层如何处理数据,才可以很快找到慢查询的原因!