2023 年已经过去,TiDB 经过了一年的迭代,又往前进步了一点点,我们非常自豪的看到,TiDB 正在不断地帮助我们的客户成功,包括但不限于:
○ 首个云原生、分布式、全栈国产化银行核心业务系统投产上线丨TiDB × 杭州银行
○ 国产数据库的珠穆朗玛峰,到底在哪里?
○ Scaling TiDB To 1 Million QPS ( https://blog.flipkart.tech/scaling-tidb-to-1-million-qps-d556aa6a16ef )
○ ……
要取得上面的成绩并不容易,在 2023 年我们也经历了很多,下面,我会简单的梳理回顾下,我们在 2023 年一些有意思的事情。

TiDB 6.5
在 2022 年的年底,我们发布 了 TiDB 6.5 LTS 版本, 这个版本我是非常期待的。实际结果来看,到 2023 年截止,TiDB 6.5 已经逐渐成为客户最重度的使用版本。
在 TiDB 6.5 之前,用户高频吐槽我们的一个问题就是 - 有时候来了一个大查询,直接把 TiDB Server 给弄 OOM 了,这样影响了一批其他的请求。所以我们在 TiDB 6.5 重点解决了 OOM 问题,结果也是很令人满意的,下图是我们实际在 TiDB Cloud 上面客户集群的报警情况,可以看到,TiDB OOM 的问题下降的非常明显。

不光在 TiDB Cloud 上面,我自己也从客户那边得到了非常多的直接反馈。 除了 OOM 问题的缓解,在 TiDB 6.5 里面,我们还重点的优化了 DDL 的速度,增强了优化器的能力等等。 所以在 2023 年一开始,我是信心满满的,觉得 TiDB 6.5 版本已经很不错。 现在想想,我那时候真的太天真了。
『不错』这个 flag 立了之后,立刻被打脸。TiDB 6.5 解决了不少之前客户遗留的问题,不过当客户开始更大规模使用 TiDB, 把 TiDB 用到更 critical 或者更复杂的场景的时候,新的问题又来了。
TiDB 7.1
在 2023 年有一段时间,我一般见到做数据库的朋友,都会问他们一个看起来比较好玩的问题,『你的客户有试过一次性导入一张 50TB 大小的单表吗?』如果是做 TP 数据库的朋友,通常会来一句『哪有这样的场景?』
嗯,我本来也以为,『哪有这样的场景?』,直到我们一个北美的客户真的进行了这样的操作。他们在 4 月份的时候开启了一次单表 50TB 的导入操作,开始的结果是悲催的 - 无论客户怎么操作,导入都遇到各种各样的问题,包括但不限于数据倾斜打满了一台 TiKV 的磁盘,PD 在 scatter region 的时候太慢导致的导入 timeout 等。本来我们希望帮助客户去操作导入,这样我们遇到问题之后能直接修复,然后继续,不过这个提议被客户直接拒绝,因为他们就是要自己亲自验证,能一次性的导入成功。
随着客户多次导入失败,客户生气的放下狠话,如果一周后还搞不定,那么就不用 TiDB 了。压力到了我们这边,我们开始了几乎连轴转的导入增强工作,终于在一周后,客户直接一次性的单表 50TB 数据导入成功。
这一次的导入优化经历,让我们学习到了很多,如果有机会后面可以再开文章详细说明。当然也有很大的收获,在北美这个客户导入成功一周以后,我们日本的一个客户进行了单表 100TB 的数据导入,结果当然是非常振奋人心的。
挑战还不仅仅限于此,又是北美的一个重要客户,他们将他们自己非常核心的一个元信息管理的业务放到了 TiDB 上面,然后这个业务大部分时候都只是涉及到 meta 的简单操作,属于 TP workload,不过也有不少的时候,他们需要直接进行一些轻量级的复杂查询,而且明确要求了当这样的复杂查询过来的时候,几乎完全不能影响他们的 TP workload。这个在 TiDB 6.5 还是比较有挑战的。而不光是这个客户,我们也发现,越来越多的客户将多个负载跑在一个 TiDB 集群,负载之间的隔离就变得尤其重要。于是我们跟这个客户一起开始了 resource control 的开发,也取得了非常不错的效果。

上面只是分 享了 TiDB 7.1 LTS 两个功 能的开发经历,我们也非常欣喜的看到,这些功能都得到了客户非常积极正向的反馈。也坚定了我们 - 聚焦样板客户的业务场景,不断打磨 TiDB,支持好这些业务场景,复制到其他客户,助力客户成功。
TiDB 7.5
随着越来越多的客户将 TiDB 用在非常核心的系统上面,在发布 TiDB 7.1 之后,我们决定,在 TiDB 7.5 LTS 版本,我们将专注于产品质量的提升。产品质量是一个很大的话题,这里仅仅列一些我们做的一点工作。
我们认为,要控制版本质量,一个非常朴素的逻辑就是少做 feature,当然我们不可能不做 feature,所以这一定是基于我们当前团队带宽的一个平衡和折中。下面是我们大概统计的不同 LTS 版本开发的 feature 个数,可以明显的看到,趋势是明显减少的。因为做的 feature 少,多出来的带宽我们就用到更多的质量加固的工作上面,所以我非常有理由相信,我们的 TiDB 的质量会越来越好。

减少 feature 个数对于研发工程师来说是一个极大的挑战,因为在很多研发的脑子里面,还是固有的认为我要通过做更多的 feature 来拿到更好的绩效,以及晋升。所以在 2023,我们花了大量的时间来解释为啥我们要控制 feature 个数,加固质量等,而且也会在绩效上面对相关工作的同学进行了倾斜。
这里大家可能会有另一个疑惑,就是我们 feature 做的少,产品的竞争力是不是就不行了?之前我也是这样的认为,不过后来我发现,我自己做为程序员也一样,我们太容易低估业务的复杂度,而高估自己的技术能力,所以总认为自己能开发很多 feature。不过后来我认识到,与其开发 10 个半吊子的 feature,真的还不如好好的开发 5 个或者更少的开箱即用的 feature,这样给客户的感受会更好。这也是我们后面会持续努力的目标。
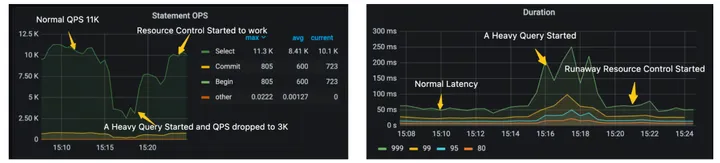
譬如在 7.5 里面,我们花了大量的经历仍然去完善和优化 resource control,譬如我们引入了 runaway query 机制,给用户提供了对于 heavy query 的控制机制,更好的防止了一些突发 heavy query 引起的 TP 业务抖动问题,效果如下:
除了控制 feature 的个数,我们还致力于提升我们自己的测试效率,2023 年一个非常大的工作就是将很多写在 unit test 文件里面的 integration tests 挪出去,让 UT 真的变成 UT,详细见这个 issue - Split integration tests(IT) and unit tests(UT) in TiDB repo ( https://github.com/pingcap/tidb/issues/45961 )。这个工作非常的重要,在没开始之前,如果我们在本地单纯的跑 TiDB 的 UT 测试,不出意外,大概率会跑挂,即使通过,耗时也接近 50 分钟,而这个工作开始一段时间之后,我们当前跑完 UT 只需要 15 分钟(后面还会继续优化),这个对于我们自身的测试效率是一个极大的提升,当效率提升之后,我们就能有更多的时间写代码,加测试了。
这里仅仅只是简单的列了一些我们在质量上面做的事情,如果后面有机会,我可以专门写一篇文章讲讲 2023 年 TiDB 在质量上面做的工作。坦白的说,直到现在,我也没找到一系列很好的指标来评估我们发出去的一个版本质量到底好不好,无论我们做了多少的测试,我总认为是不够的。
小结
上面就是 TiDB 2023 的一个简单的回顾了,我们在 2023 年真的取得了许多非常不错的成绩。总结来说,就是我们发布了一个不错的产品,以及明确了以稳定性为基础的研发策略。回顾 2023,我们也有不少做错的地方,也走了一些弯路,这个有机会,后面再重新开一个新坑,讲讲『那些年我们开发 TiDB 所踩过的坑 :-) 』。
对于 2024 年,在 TiDB 上面,我们也会非常聚焦,首先仍然会以稳定性为基础,在这个基础上面,我们会投入带宽来改进 TiDB 的可观测性以及提升一些场景下面的性能,具体的大家可以关注我们 TiDB 的 roadmap,我们会定期的刷新。
在 2023 年,我们在 cloud 上面也取得了不错的进展,在后面一篇文章中,我就会来讲讲 “TiDB Cloud in 2023”。