原文:
www.bookstack.cn/read/th-fastai-book译者:飞龙
协议:CC BY-NC-SA 4.0
序言
原文:
www.bookstack.cn/read/th-fastai-book/README.md译者:飞龙
协议:CC BY-NC-SA 4.0
在很短的时间内,深度学习已经成为一种广泛应用的技术,解决和自动化计算机视觉、机器人技术、医疗保健、物理学、生物学等领域的问题。深度学习的一大乐趣在于其相对简单性。强大的深度学习软件已经构建起来,使得快速入门变得快速简单。在几周内,你就可以理解基础知识并熟悉技术。
这打开了一个创造性的世界。你开始将其应用于手头的数据问题,并且看到机器为你解决问题时感到很棒。然而,你慢慢感到自己越来越接近一个巨大的障碍。你构建了一个深度学习模型,但它的效果并不如你希望的那样好。这时你进入下一个阶段,寻找并阅读关于深度学习的最新研究。
然而,关于深度学习有大量的知识,有三十年的理论、技术和工具支持。当你阅读一些研究时,你会意识到人类可以用非常复杂的方式解释简单的事情。科学家在这些论文中使用的词语和数学符号看起来很陌生,没有任何教科书或博客文章似乎涵盖了你需要的背景知识。工程师和程序员假设你知道 GPU 如何工作,并且了解一些晦涩的工具。
这时候你会希望有一个导师或者一个可以交流的朋友。一个曾经身临其境、了解工具和数学的人——一个可以指导你掌握最佳研究、最先进技术和高级工程,并使其变得滑稽简单的人。十年前,我曾经身临其境,当时我正在进入机器学习领域。多年来,我努力理解那些含有一点数学的论文。我周围有很好的导师,这对我帮助很大,但我花了很多年才对机器学习和深度学习感到舒适。这激励我成为 PyTorch 的合著者,这是一个使深度学习变得易于接触的软件框架。
Jeremy Howard 和 Sylvain Gugger 也曾身临其境。他们想学习和应用深度学习,但没有任何以前的机器学习科学家或工程师的正式培训。像我一样,Jeremy 和 Sylvain 在多年的学习中逐渐成为专家和领导者。但与我不同的是,Jeremy 和 Sylvain 无私地投入了大量精力,确保其他人不必像他们走过的痛苦之路。他们建立了一个名为 fast.ai 的优秀课程,使了解前沿深度学习技术的人们能够掌握基本编程知识。这个课程已经毕业了成千上万渴望学习的学习者,他们已经成为了优秀的实践者。
在这本书中,Jeremy 和 Sylvain 构建了一个通过深度学习的神奇之旅。他们用简单的语言介绍每个概念。他们将前沿深度学习和最新研究带给你,同时使其变得非常易于理解。
你将通过最新的计算机视觉进展,深入自然语言处理,并在 500 页的愉快旅程中学习一些基础数学。而这个旅程并不仅仅停留在有趣,因为他们还会带你将你的想法投入生产。你可以将 fast.ai 社区视为你的扩展家庭,成千上万的从业者在线上,像你一样的个人可以交流和构思大小解决方案,无论问题是什么。
我很高兴你找到了这本书,我希望它能激励你将深度学习应用到实际问题中,无论问题的性质如何。
Soumith Chintala
PyTorch 的共同创作者
第一部分:实践中的深度学习
第一章:你的深度学习之旅
原文:
www.bookstack.cn/read/th-fastai-book/85a70c895d8d75be.md译者:飞龙
协议:CC BY-NC-SA 4.0
你好,感谢你让我们加入你的深度学习之旅,无论你已经走了多远!在本章中,我们将告诉你更多关于本书的内容,介绍深度学习背后的关键概念,并在不同任务上训练我们的第一个模型。无论你是否有技术或数学背景(尽管如果你有也没关系!),我们写这本书是为了让尽可能多的人能够接触到深度学习。
深度学习适合每个人
很多人认为你需要各种难以找到的东西才能在深度学习中取得出色的结果,但正如你在本书中所看到的,这些人是错误的。表 1-1 列出了一些你绝对不需要进行世界级深度学习的东西。
表 1-1。深度学习不需要的东西
| 迷思(不需要) | 真相 |
|---|---|
| 大量的数学 | 高中数学就足够了。 |
| 大量的数据 | 我们已经看到少于 50 个数据项取得了创纪录的结果。 |
| 大量昂贵的计算机 | 你可以免费获得进行最先进工作所需的设备。 |
深度学习是一种计算机技术,通过使用多层神经网络从人类语音识别到动物图像分类等用例来提取和转换数据。每个层从前一层获取输入,并逐渐完善它们。这些层通过最小化错误并提高准确性的算法进行训练。这样,网络学会执行指定的任务。我们将在下一节详细讨论训练算法。
深度学习具有强大、灵活和简单的特点。这就是为什么我们认为它应该应用于许多学科。这些学科包括社会科学、自然科学、艺术、医学、金融、科学研究等等。举个个人例子,尽管没有医学背景,Jeremy 创办了 Enlitic 公司,该公司使用深度学习算法来诊断疾病。在公司成立几个月后,宣布其算法能够比放射科医生更准确地识别恶性肿瘤。
以下是一些不同领域中数千个任务的列表,其中深度学习或大量使用深度学习的方法现在是世界上最好的:
自然语言处理(NLP)
回答问题;语音识别;总结文件;分类文件;在文件中查找名称、日期等;搜索提及某一概念的文章
计算机视觉
卫星和无人机图像解释(例如用于灾害韧性),人脸识别,图像字幕,读取交通标志,定位自动驾驶车辆中的行人和车辆
医学
在放射学图像中找到异常,包括 CT、MRI 和 X 射线图像;在病理学幻灯片中计数特征;在超声波中测量特征;诊断糖尿病视网膜病变
生物学
折叠蛋白;分类蛋白质;许多基因组学任务,如肿瘤-正常测序和分类临床可操作的遗传突变;细胞分类;分析蛋白质/蛋白质相互作用
图像生成
给图像上色,增加图像分辨率,去除图像中的噪音,将图像转换为著名艺术家风格的艺术品
推荐系统
网络搜索,产品推荐,主页布局
玩游戏
国际象棋,围棋,大多数 Atari 视频游戏以及许多实时策略游戏
机器人技术
处理难以定位的物体(例如透明、闪亮、缺乏纹理)或难以拾取的物体
其他应用
金融和物流预测,文本转语音等等…
令人惊讶的是,深度学习有如此多样的应用,然而几乎所有的深度学习都基于一种创新的模型类型:神经网络。
但事实上,神经网络并不是完全新的。为了对该领域有更广泛的视角,值得从一点历史开始。
神经网络:简史
1943 年,神经生理学家沃伦·麦卡洛克和逻辑学家沃尔特·皮茨联手开发了人工神经元的数学模型。在他们的论文《神经活动中内在思想的逻辑演算》中,他们宣称:
由于神经活动的“全有或全无”特性,神经事件及其之间的关系可以通过命题逻辑来处理。发现每个网络的行为都可以用这些术语来描述。
麦卡洛克和皮茨意识到,可以使用简单的加法和阈值处理来表示真实神经元的简化模型,如图 1-1 所示。皮茨是自学成才的,12 岁时就收到了与伟大的伯特兰·罗素一起在剑桥大学学习的邀请。他没有接受这个邀请,事实上,他一生中没有接受任何高级学位或权威职位的邀请。他大部分著名的工作都是在无家可归时完成的。尽管他没有正式认可的职位,社交孤立日益加剧,但他与麦卡洛克的合作对心理学家弗兰克·罗森布拉特产生了影响。
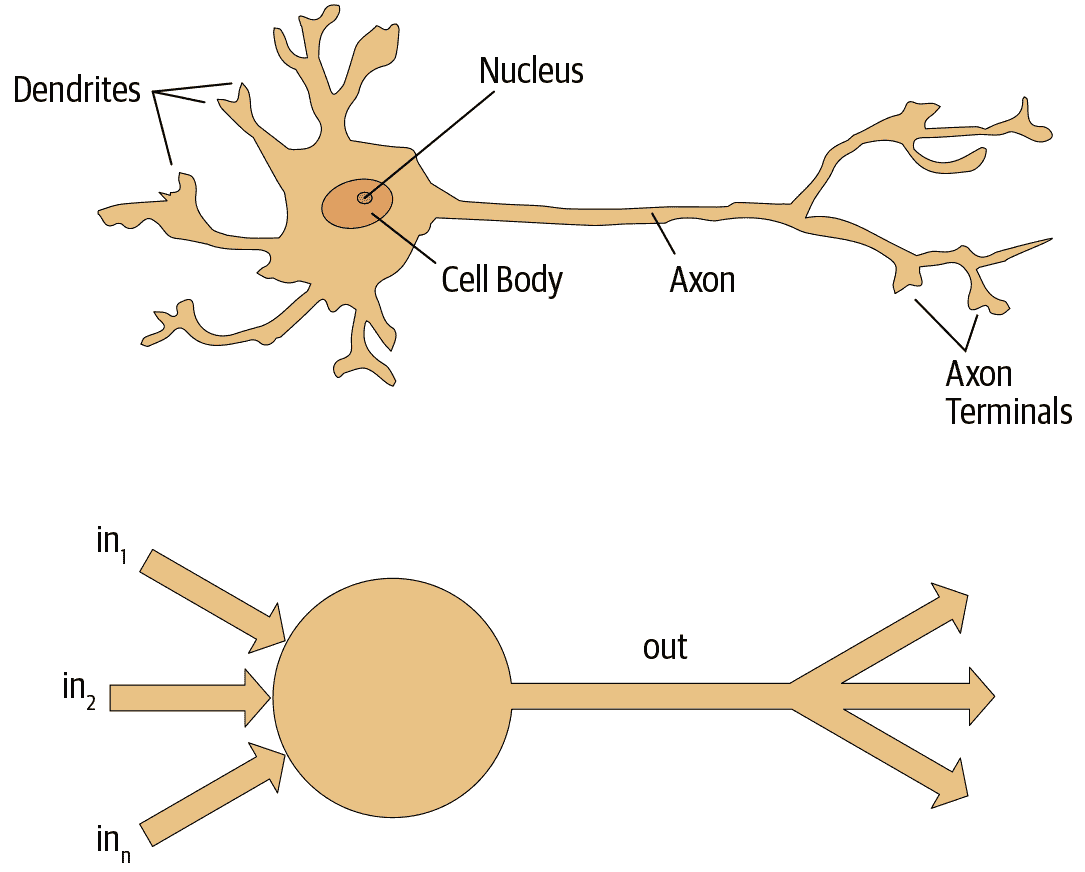
图 1-1. 自然和人工神经元
罗森布拉特进一步发展了人工神经元,使其具有学习能力。更重要的是,他致力于构建第一个使用这些原则的设备,即 Mark I 感知器。在《智能自动机的设计》中,罗森布拉特写道:“我们现在将见证这样一台机器的诞生——一台能够在没有任何人类训练或控制的情况下感知、识别和辨认其周围环境的机器。”感知器被建造出来,并成功地识别了简单的形状。
麻省理工学院的教授马文·明斯基(与罗森布拉特在同一所高中,但比他晚一年)与西摩·帕帕特合著了一本名为《感知器》(麻省理工学院出版社)的书,讲述了罗森布拉特的发明。他们表明,这些设备的单层无法学习一些简单但关键的数学函数(如异或)。在同一本书中,他们还表明,使用多层设备可以解决这些限制。不幸的是,这些洞见中只有第一个被广泛认可。因此,全球学术界在接下来的两十年几乎完全放弃了神经网络。
在过去 50 年中,神经网络领域最具影响力的工作可能是由大卫·鲁梅尔哈特、詹姆斯·麦克莱兰和 PDP 研究小组于 1986 年由麻省理工学院出版社出版的多卷本《并行分布式处理》(PDP)。第一章提出了与罗森布拉特所展示的类似希望:
人类比今天的计算机更聪明,因为大脑采用了一种更适合处理人类擅长的自然信息处理任务的基本计算架构。我们将介绍一个用于建模认知过程的计算框架,它似乎比其他框架更接近大脑可能进行的计算风格。
PDP 所使用的前提是,传统计算机程序与大脑的工作方式非常不同,这可能是为什么计算机程序在那时如此糟糕地执行大脑发现容易的任务(如识别图片中的物体)。作者声称 PDP 方法“比其他框架更接近”大脑的工作方式,因此可能更能够处理这些任务。
事实上,PDP 中提出的方法与今天的神经网络所使用的方法非常相似。该书将并行分布式处理定义为需要以下内容:
-
一组处理单元
-
激活状态
-
每个单元的输出函数
-
单位之间的连接模式
-
通过网络连接传播活动模式的传播规则
-
将输入与单位的当前状态相结合以产生单位输出的激活规则
-
通过经验修改连接模式的学习规则
-
系统必须运行的环境
我们将在本书中看到现代神经网络如何处理这些要求。
在 20 世纪 80 年代,大多数模型都建立了第二层神经元,从而避免了由明斯基和帕佩特(这是他们“单元之间的连接模式”,使用前面的框架)所确定的问题。事实上,神经网络在 80 年代和 90 年代被广泛用于真实的实际项目。然而,对理论问题的误解再次阻碍了该领域的发展。理论上,只需添加一个额外的神经元层就足以使这些神经网络能够近似任何数学函数,但实际上这样的网络通常太大且太慢,无法发挥作用。
尽管研究人员 30 年前就表明,要获得实际的良好性能,你需要使用更多层的神经元,但直到最近十年,这个原则才被更广泛地认可和应用。现在,由于计算机硬件的改进、数据可用性的增加以及允许神经网络更快更容易地训练的算法调整,神经网络终于实现了其潜力。我们现在拥有了 Rosenblatt 所承诺的:“一台能够感知、识别和辨认周围环境的机器,无需任何人类训练或控制。”
这就是你将在本书中学会如何构建的内容。但首先,因为我们将花很多时间在一起,让我们彼此稍微了解一下…
我们是谁
我们是 Sylvain 和 Jeremy,是你们在这个旅程中的向导。我们希望你们认为我们非常适合这个职位。
Jeremy 已经使用和教授机器学习约 30 年。他在 25 年前开始使用神经网络。在此期间,他领导了许多以机器学习为核心的公司和项目,包括成立专注于深度学习和医学的第一家公司 Enlitic,并担任全球最大的机器学习社区 Kaggle 的总裁兼首席科学家。他与 Rachel Thomas 博士共同创立了 fast.ai,这个组织建立了本书基于的课程。
不时地,你会直接从我们这里听到一些侧边栏的信息,比如 Jeremy 在这里说的:
Jeremy 说
大家好,我是 Jeremy!你可能会感兴趣知道,我没有接受过任何正式的技术教育。我获得了哲学专业的学士学位,成绩并不好。我对做实际项目比对理论研究更感兴趣,所以在大学期间我全职在一家名为麦肯锡公司的管理咨询公司工作。如果你更愿意亲自动手建造东西而不是花费数年学习抽象概念,你会理解我的想法!请留意我的侧边栏,以找到最适合没有数学或正式技术背景的人的信息,也就是像我这样的人…
另一方面,Sylvain 对正式的技术教育了解很多。他已经写了 10 本数学教科书,涵盖了整个法国高级数学课程!
Sylvain 说
与杰里米不同,我没有花很多年编写和应用机器学习算法。相反,我最近通过观看杰里米的 fast.ai 课程视频进入了机器学习世界。因此,如果你是一个从未打开终端并在命令行中编写命令的人,你会理解我在说什么!请留意我的旁注,以找到最适合具有更多数学或正式技术背景,但缺乏实际编码经验的人的信息,也就是像我这样的人…
fast.ai 课程已经被来自世界各地各行各业的数十万学生研究过。Sylvain 被认为是 Jeremy 见过的该课程中最令人印象深刻的学生,这导致他加入了 fast.ai,然后与 Jeremy 一起成为 fastai 软件库的合著者。
所有这些意味着,在我们之间,你拥有最好的两个世界:那些比任何人都更了解软件的人,因为他们编写了它;数学专家,编码和机器学习专家;以及那些了解在数学中作为相对外行者和在编码和机器学习中作为相对外行者的感受的人。
任何看过体育比赛的人都知道,如果有一个两人评论团队,你还需要第三个人来做“特别评论”。我们的特别评论员是亚历克西斯·加拉格尔(Alexis Gallagher)。亚历克西斯有着非常多样化的背景:他曾是数学生物学研究员,编剧,即兴表演者,麦肯锡顾问(就像 Jeremy 一样!),Swift 编码者和首席技术官。
亚历克西斯说
我决定是时候学习这个人工智能的东西了!毕竟,我几乎尝试了所有其他的东西…但我并没有建立机器学习模型的背景。不过…这有多难呢?我将在这本书中一直学习,就像你一样。请留意我的旁注,找到我在学习过程中发现有用的学习提示,希望你也会觉得有用。
如何学习深度学习
哈佛教授大卫·帕金斯(David Perkins)在《全面学习》(Jossey-Bass)一书中有很多关于教学的观点。基本思想是教授“整个游戏”。这意味着,如果你在教棒球,你首先带人们去看一场棒球比赛或让他们玩棒球。你不会教他们如何缠绕麻线从头开始制作棒球,也不会教他们抛物线的物理学,或者球在球拍上的摩擦系数。
哥伦比亚数学博士、前布朗大学教授和 K-12 数学教师保罗·洛克哈特(Paul Lockhart)在具有影响力的文章《数学家的悲歌》中设想了一个噩梦般的世界,在那里音乐和艺术的教学方式与数学的教学方式相同。孩子们在掌握音乐符号和理论十多年后才被允许听音乐或演奏音乐,花时间将乐谱转换到不同的音调。在艺术课上,学生学习颜色和应用工具,但直到大学才被允许真正绘画。听起来荒谬吗?这就是数学的教学方式——我们要求学生花费多年时间进行死记硬背和学习干燥、脱离实际的“基础知识”,我们声称这些知识在大多数学生放弃这门学科后才会有回报。
不幸的是,这正是许多关于深度学习的教学资源开始的地方——要求学习者跟随 Hessian 的定义和泰勒近似定理的步伐,而从未给出实际工作代码的示例。我们并不是在抨击微积分。我们喜欢微积分,Sylvain 甚至在大学教过微积分,但我们认为学习深度学习时不是最好的起点!
在深度学习中,如果你有动力修复模型使其表现更好,那真的会有帮助。那时你开始学习相关的理论。但你首先需要有模型。我们几乎所有的教学都是通过真实例子展示的。随着我们构建这些例子,我们会越来越深入,向您展示如何使您的项目变得更好。这意味着您将逐渐学习所有您需要的理论基础,以上下文方式,这样您就会明白为什么重要以及如何运作。
因此,这是我们对您的承诺。在整本书中,我们遵循以下原则:
教授整个游戏
我们将从向您展示如何使用完整、可用、最先进的深度学习网络来解决现实世界问题,使用简单、表达力强的工具开始。然后我们将逐渐深入了解这些工具是如何制作的,以及制作这些工具的工具是如何制作的,依此类推…
始终通过示例教学
我们将确保您能直观理解背景和目的,而不是从代数符号操作开始。
尽可能简化
我们花了多年时间建立工具和教学方法,使以前复杂的主题变得简单。
消除障碍
深度学习直到现在一直是一个独家游戏。我们正在打破这个局面,确保每个人都能参与。
深度学习中最困难的部分是手工制作的:你如何知道你是否有足够的数据,数据是否以正确的格式存在,你的模型是否正确训练,如果不正确,你应该怎么做?这就是为什么我们相信通过实践学习。与基本的数据科学技能一样,通过实践经验才能变得更好。花太多时间在理论上可能会适得其反。关键是只需编写代码并尝试解决问题:理论可以稍后再来,当你有了上下文和动力时。
在旅程中会有困难的时候。有时你会感到困惑。不要放弃!回顾一下书中你肯定没有困惑的部分,然后从那里开始慢慢阅读,找到第一个不清楚的地方。然后尝试一些代码实验,自己搜索更多关于你遇到问题的教程——通常你会找到一个不同的角度来理解材料,可能会帮助你理解。此外,第一次阅读时不理解一切(尤其是代码)是正常的。有时在继续之前按顺序理解材料有时会很困难。有时在你从后面的部分获得更多上下文后,事情就会豁然开朗,从整体上看到更多。所以如果你在某个部分卡住了,尝试继续前进,做个笔记以后再回来。
请记住,要在深度学习中取得成功,您不需要任何特定的学术背景。许多重要的突破是由没有博士学位的人在研究和工业领域取得的,比如 Alec Radford 在大学本科时写的一篇论文《使用深度卷积生成对抗网络进行无监督表示学习》,这是过去十年中最有影响力的论文之一,被引用超过 5000 次。甚至在特斯拉,他们正在努力解决制造自动驾驶汽车这个极具挑战性的问题,首席执行官埃隆·马斯克表示:
绝对不需要博士学位。重要的是对人工智能有深刻理解和能够实际应用神经网络(后者才是真正困难的)。甚至不在乎你是否高中毕业。
然而,要成功,您需要将本书中学到的知识应用到个人项目中,并始终坚持不懈。
你的项目和心态
无论您是因为兴奋地想要从植物叶片的图片中识别植物是否患病,自动生成编织图案,从 X 射线诊断结核病,还是确定浣熊何时使用您的猫门,我们将尽快让您使用深度学习解决自己的问题(通过他人预训练的模型),然后将逐步深入更多细节。在下一章的前 30 分钟内,您将学会如何使用深度学习以最先进的准确性解决自己的问题!(如果您迫不及待地想要立即开始编码,请随时跳转到那里。)有一个错误的观念认为,要进行深度学习,您需要像谷歌那样拥有计算资源和数据集的规模,但这是不正确的。
那么,什么样的任务适合作为良好的测试案例?您可以训练模型区分毕加索和莫奈的画作,或者挑选您女儿的照片而不是您儿子的照片。专注于您的爱好和激情有助于您设定四到五个小项目,而不是努力解决一个大问题,这在刚开始时效果更好。由于很容易陷入困境,过早野心勃勃往往会适得其反。然后,一旦掌握了基础知识,就努力完成一些让您真正自豪的事情!
杰里米说
深度学习几乎可以应用于任何问题。例如,我的第一家创业公司叫做 FastMail,它于 1999 年推出时提供了增强的电子邮件服务(至今仍在提供)。2002 年,我将其设置为使用一种原始形式的深度学习,即单层神经网络,以帮助分类电子邮件并阻止客户收到垃圾邮件。
在深度学习中表现良好的人的共同特征包括好玩和好奇。已故物理学家理查德·费曼就是我们期望在深度学习方面表现出色的人的一个例子:他对亚原子粒子运动的理解来自于他对盘子在空中旋转时摇晃的好奇。
现在让我们专注于您将学到的内容,从软件开始。
软件:PyTorch、fastai 和 Jupyter(以及为什么这不重要)
我们已经完成了数百个机器学习项目,使用了数十种软件包和多种编程语言。在 fast.ai,我们编写了大多数当今主要的深度学习和机器学习软件包的课程。在 2017 年 PyTorch 发布后,我们花费了一千多个小时进行测试,然后决定将其用于未来的课程、软件开发和研究。自那时以来,PyTorch 已成为全球增长最快的深度学习库,并且已经被用于顶级会议上的大多数研究论文。这通常是行业使用的领先指标,因为这些论文最终会被商业产品和服务使用。我们发现 PyTorch 是最灵活和表达力强的深度学习库。它不会以速度为代价而简化,而是提供了两者。
PyTorch 最适合作为低级基础库,提供高级功能的基本操作。fastai 库是在 PyTorch 之上添加高级功能的最流行的库。它也特别适合本书的目的,因为它在提供深度分层软件架构方面是独一无二的(甚至有一篇同行评审的学术论文介绍了这种分层 API)。在本书中,随着我们深入研究深度学习的基础,我们也将深入研究 fastai 的各个层次。本书涵盖了 fastai 库的第 2 版,这是一个从头开始重写的版本,提供了许多独特的功能。
然而,学习哪种软件并不重要,因为只需要几天就可以学会从一个库切换到另一个库。真正重要的是正确学习深度学习的基础和技术。我们的重点将是使用尽可能清晰地表达你需要学习的概念的代码。在教授高级概念时,我们将使用高级 fastai 代码。在教授低级概念时,我们将使用低级 PyTorch 或甚至纯 Python 代码。
尽管现在似乎新的深度学习库以快速的速度出现,但你需要为未来几个月和几年内更快的变化做好准备。随着更多人进入这个领域,他们将带来更多的技能和想法,并尝试更多的事情。你应该假设你今天学到的特定库和软件将在一两年内过时。想想在网络编程领域中一直发生的库和技术栈的变化数量——这是一个比深度学习更成熟和增长缓慢的领域。我们坚信学习的重点应该放在理解基础技术以及如何将其应用于实践中,以及如何在新工具和技术发布时快速建立专业知识。
到书的结尾,你将几乎理解 fastai 中的所有代码(以及大部分 PyTorch 代码),因为在每一章中,我们都会深入挖掘,向你展示我们构建和训练模型时究竟发生了什么。这意味着你将学到现代深度学习中使用的最重要的最佳实践,不仅是如何使用它们,还有它们是如何真正工作和实现的。如果你想在另一个框架中使用这些方法,你将有必要的知识来做到这一点。
由于学习深度学习最重要的是编写代码和实验,所以重要的是你有一个很好的代码实验平台。最流行的编程实验平台称为 Jupyter。这是我们将在整本书中使用的工具。我们将向你展示如何使用 Jupyter 训练和实验模型,并审查数据预处理和模型开发流程的每个阶段。Jupyter 是在 Python 中进行数据科学最流行的工具,理由充分。它功能强大、灵活且易于使用。我们相信你会喜欢它!
让我们实践一下,训练我们的第一个模型。
你的第一个模型
正如我们之前所说,我们将教你如何做事情,然后再解释为什么它们有效。遵循这种自上而下的方法,我们将首先实际训练一个图像分类器,几乎可以 100%准确地识别狗和猫。为了训练这个模型并运行我们的实验,你需要进行一些初始设置。不要担心,这并不像看起来那么难。
Sylvain 说
即使初始设置看起来令人生畏,也不要跳过设置部分,特别是如果你很少或没有使用终端或命令行的经验。大部分并不是必要的,你会发现最简单的服务器只需使用你平常的网络浏览器就可以设置好。在学习过程中,与本书并行运行你自己的实验是至关重要的。
获取 GPU 深度学习服务器
在本书中几乎所有的事情都需要使用一台带有 NVIDIA GPU 的计算机(不幸的是,其他品牌的 GPU 并没有得到主要深度学习库的全面支持)。然而,我们不建议你购买一台;事实上,即使你已经有一台,我们也不建议你立即使用!设置一台计算机需要时间和精力,而你现在想要把所有精力集中在深度学习上。因此,我们建议你租用一台已经预装并准备就绪的计算机。使用时的成本可能只需每小时 0.25 美元,甚至有些选项是免费的。
术语:图形处理单元(GPU)
也称为图形卡。计算机中一种特殊类型的处理器,可以同时处理成千上万个单个任务,专门设计用于在计算机上显示 3D 环境以进行游戏。这些相同的基本任务与神经网络所做的非常相似,因此 GPU 可以比常规 CPU 快数百倍运行神经网络。所有现代计算机都包含 GPU,但很少包含进行深度学习所需的正确类型的 GPU。
随着公司的兴衰和价格的变化,与本书一起使用的 GPU 服务器的最佳选择将随时间而变化。我们在书的网站上维护了我们推荐选项的列表,所以现在去那里,按照说明连接到 GPU 深度学习服务器。不用担心;在大多数平台上,设置只需要大约两分钟,许多甚至不需要任何付款或信用卡即可开始。
Alexis 说
我的建议:听取这些建议!如果您喜欢计算机,您可能会想要设置自己的计算机。小心!这是可行的,但令人惊讶地复杂和分散注意力。这本书没有标题为关于 Ubuntu 系统管理、NVIDIA 驱动程序安装、apt-get、conda、pip 和 Jupyter 笔记本配置的所有内容。那将是一本独立的书。在工作中设计和部署我们的生产机器学习基础设施后,我可以证明它有其满足感,但与建模无关,就像维护飞机与驾驶飞机无关。
网站上显示的每个选项都包括一个教程;完成教程后,您将看到一个屏幕,看起来像图 1-2。

图 1-2. Jupyter 笔记本的初始视图
您现在已经准备好运行您的第一个 Jupyter 笔记本!
行话:Jupyter 笔记本
一种软件,允许您在单个交互式文档中包含格式化文本、代码、图像、视频等。Jupyter 因其在许多学术领域和工业中的广泛使用和巨大影响而获得了软件的最高荣誉,ACM 软件系统奖。Jupyter 笔记本是数据科学家用于开发和与深度学习模型交互的最广泛使用的软件。
运行您的第一个笔记本
笔记本按章节编号,与本书中呈现的顺序相同。因此,您将看到列出的第一个笔记本是您现在需要使用的笔记本。您将使用此笔记本来训练一个可以识别狗和猫照片的模型。为此,您将下载一组狗和猫照片的数据集,并使用该数据集训练模型。
数据集只是一堆数据——可以是图像、电子邮件、财务指标、声音或其他任何东西。有许多免费提供的数据集适合用于训练模型。许多这些数据集是由学者创建的,以帮助推动研究,许多是为竞赛提供的(有一些竞赛,数据科学家可以竞争,看看谁有最准确的模型!),有些是其他过程的副产品(如财务申报)。
完整和剥离的笔记本
有两个包含不同版本笔记本的文件夹。full文件夹包含用于创建您现在阅读的书的确切笔记本,包括所有散文和输出。stripped版本具有相同的标题和代码单元格,但所有输出和散文都已删除。阅读书的一部分后,我们建议关闭书,通过 stripped 笔记本进行练习,并尝试在执行之前弄清楚每个单元格将显示什么。还要尝试回想代码正在演示什么。
要打开一个笔记本,只需单击它。笔记本将打开,看起来类似于图 1-3(请注意,不同平台之间可能存在细节上的轻微差异;您可以忽略这些差异)。
图 1-3. 一个 Jupyter 笔记本
一个笔记本由单元格组成。有两种主要类型的单元格:
-
包含格式化文本、图像等内容的单元格。这些使用一种称为Markdown的格式,您很快就会了解。
-
包含可执行代码的单元格,输出将立即显示在其下方(可以是纯文本、表格、图像、动画、声音,甚至交互式应用程序)。
Jupyter 笔记本可以处于两种模式之一:编辑模式或命令模式。在编辑模式下,键盘上的输入以通常的方式输入到单元格中。但是,在命令模式下,您将看不到任何闪烁的光标,键盘上的每个键都将具有特殊功能。
在继续之前,请按下键盘上的 Escape 键切换到命令模式(如果您已经在命令模式下,则此操作无效,因此现在请按下它)。要查看所有可用功能的完整列表,请按 H;按 Escape 键以删除此帮助屏幕。请注意,在命令模式下,与大多数程序不同,命令不需要按住 Control、Alt 或类似键,您只需按下所需的字母键。
您可以通过按下 C 键(需要首先选择单元格,显示为周围有轮廓;如果尚未选择,请单击一次)来复制单元格。然后按 V 键粘贴副本。
单击以“# CLICK ME”开头的单元格以选择它。该行中的第一个字符表示后面的内容是 Python 中的注释,因此在执行单元格时会被忽略。单元格的其余部分是一个完整的系统,用于创建和训练一个用于识别猫和狗的最先进模型。所以,现在让我们开始训练吧!要这样做,只需在键盘上按 Shift-Enter,或单击工具栏上的播放按钮。然后等待几分钟,以下事情会发生:
-
一个名为牛津-IIIT 宠物数据集的数据集,其中包含来自 37 个品种的 7,349 张猫和狗的图像,将从 fast.ai 数据集合中下载到您正在使用的 GPU 服务器上,然后进行提取。
-
一个预训练模型,已经在 130 万张图像上训练过,使用了一个获奖模型,将从互联网上下载。
-
预训练模型将使用迁移学习的最新进展进行微调,以创建一个专门定制用于识别狗和猫的模型。
前两个步骤只需要在您的 GPU 服务器上运行一次。如果再次运行单元格,它将使用已经下载的数据集和模型,而不是重新下载它们。让我们看看单元格的内容和结果(表 1-2):
# CLICK ME
from fastai.vision.all import *
path = untar_data(URLs.PETS)/'images'def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(path, get_image_files(path), valid_pct=0.2, seed=42,label_func=is_cat, item_tfms=Resize(224))learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)
表 1-2. 第一次训练的结果
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.169390 | 0.021388 | 0.005413 | 00:14 |
| epoch | train_loss | valid_loss | error_rate | time |
| — | — | — | — | — |
| 0 | 0.058748 | 0.009240 | 0.002706 | 00:19 |
您可能不会看到这里显示的完全相同的结果。训练模型涉及许多小随机变化的来源。在这个例子中,我们通常看到错误率远低于 0.02,然而。
训练时间
根据您的网络速度,下载预训练模型和数据集可能需要几分钟。运行fine_tune可能需要一两分钟。通常,本书中的模型需要几分钟来训练,您自己的模型也是如此,因此最好想出一些好的技巧来充分利用这段时间。例如,当您的模型训练时,继续阅读下一节,或者打开另一个笔记本并用它进行一些编码实验。
那么,我们如何知道这个模型是否好用?在表的最后一列中,你可以看到错误率,即被错误识别的图像的比例。错误率作为我们的度量标准——我们选择的模型质量的衡量标准,旨在直观和易于理解。正如你所看到的,即使训练时间只有几秒钟(不包括数据集和预训练模型的一次性下载),模型几乎是完美的。事实上,你已经取得的准确率比任何人在 10 年前取得的都要好得多!
最后,让我们检查一下这个模型是否真的有效。去找一张狗或猫的照片;如果你手头没有,只需搜索 Google 图片并下载你找到的一张图片。现在执行定义了uploader的单元格。它会输出一个按钮,你可以点击它,然后选择你想分类的图片:
uploader = widgets.FileUpload()
uploader

现在你可以将上传的文件传递给模型。确保它是一张清晰的狗或猫的照片,而不是线描、卡通或类似的照片。笔记本会告诉你它认为这是一只狗还是一只猫,以及它的自信程度。希望你会发现你的模型表现得很好:
img = PILImage.create(uploader.data[0])
is_cat,_,probs = learn.predict(img)
print(f"Is this a cat?: {is_cat}.")
print(f"Probability it's a cat: {probs[1].item():.6f}")
Is this a cat?: True.
Probability it's a cat: 0.999986
恭喜你的第一个分类器!
但是这意味着什么?你实际上做了什么?为了解释这一点,让我们再次放大,看看整体情况。
什么是机器学习?
你的分类器是一个深度学习模型。正如已经提到的,深度学习模型使用神经网络,这些神经网络最初可以追溯到上世纪 50 年代,并且最近由于最新的进展变得非常强大。
另一个重要的背景是,深度学习只是更一般的机器学习领域中的一个现代领域。要理解当你训练自己的分类模型时所做的事情的本质,你不需要理解深度学习。看到你的模型和训练过程是如何成为适用于机器学习的概念的例子就足够了。
因此,在本节中,我们将描述机器学习。我们将探讨关键概念,并看看它们如何可以追溯到最初介绍它们的原始文章。
机器学习就像常规编程一样,是让计算机完成特定任务的一种方式。但是如果要用常规编程来完成前面部分我们刚刚做的事情:在照片中识别狗和猫,我们将不得不为计算机写下完成任务所需的确切步骤。
通常,当我们编写程序时,很容易为我们写下完成任务的步骤。我们只需考虑如果我们必须手动完成任务时会采取的步骤,然后将它们转换为代码。例如,我们可以编写一个对列表进行排序的函数。一般来说,我们会编写一个类似于图 1-4 的函数(其中inputs可能是一个未排序的列表,results是一个排序后的列表)。

图 1-4. 传统程序
但是要在照片中识别物体,这有点棘手;当我们在图片中识别物体时,我们采取了什么步骤?我们真的不知道,因为这一切都发生在我们的大脑中,而我们并没有意识到!
早在计算机诞生之初,1949 年,IBM 的一位研究员阿瑟·塞缪尔开始研究一种让计算机完成任务的不同方式,他称之为机器学习。在他经典的 1962 年文章“人工智能:自动化的前沿”中,他写道:
为这样的计算编程对于我们来说是相当困难的,主要不是因为计算机本身的任何固有复杂性,而是因为需要详细说明过程的每一个细微步骤。任何程序员都会告诉你,计算机是巨大的白痴,而不是巨大的大脑。
他的基本想法是这样的:不是告诉计算机解决问题所需的确切步骤,而是向其展示解决问题的示例,并让它自己找出如何解决。结果证明这非常有效:到 1961 年,他的跳棋程序学到了很多,以至于击败了康涅狄格州冠军!这是他描述自己想法的方式(与之前提到的同一篇文章):
假设我们安排一些自动手段来测试任何当前权重分配的有效性,以实际表现为准,并提供一种机制来改变权重分配以最大化性能。我们不需要详细了解这种程序的细节,就可以看到它可以完全自动化,并且可以看到一个这样编程的机器将从中学习。
这个简短陈述中嵌入了一些强大的概念:
-
“权重分配”的想法
-
每个权重分配都有一些“实际表现”的事实
-
要求有一种“自动手段”来测试该性能
-
需要一个“机制”(即,另一个自动过程)来通过改变权重分配来提高性能
让我们逐一了解这些概念,以便了解它们在实践中如何结合。首先,我们需要了解塞缪尔所说的权重分配是什么意思。
权重只是变量,权重分配是这些变量的特定值选择。程序的输入是它处理以产生结果的值,例如,将图像像素作为输入,并返回分类“狗”作为结果。程序的权重分配是定义程序操作方式的其他值。
因为它们会影响程序,它们在某种意义上是另一种输入。我们将更新我们的基本图片图 1-4,并用图 1-5 替换,以便考虑到这一点。
图 1-5。使用权重分配的程序
我们已将方框的名称从程序更改为模型。这是为了遵循现代术语并反映模型是一种特殊类型的程序:它可以根据权重做许多不同的事情。它可以以许多不同的方式实现。例如,在塞缪尔的跳棋程序中,不同的权重值会导致不同的跳棋策略。
(顺便说一句,塞缪尔所说的“权重”如今通常被称为模型参数,以防您遇到这个术语。术语权重保留给特定类型的模型参数。)
接下来,塞缪尔说我们需要一种自动测试任何当前权重分配的有效性的方法,以实际表现为准。在他的跳棋程序中,“实际表现”模型的表现有多好。您可以通过让两个模型相互对战并看哪个通常获胜来自动测试两个模型的表现。
最后,他说我们需要一种机制来改变权重分配,以最大化性能。例如,我们可以查看获胜模型和失败模型之间的权重差异,并将权重进一步调整到获胜方向。
我们现在可以看到他为什么说这样的程序可以完全自动化,并且…一个这样编程的机器将从中学习。当权重的调整也是自动的时,学习将变得完全自动——当我们不再通过手动调整权重来改进模型,而是依赖于根据性能产生调整的自动化机制时。
图 1-6 展示了塞缪尔关于训练机器学习模型的完整图景。
!基本训练循环
图 1-6。训练机器学习模型
注意模型的结果(例如,在跳棋游戏中的移动)和其性能(例如,是否赢得比赛,或者赢得比赛的速度)之间的区别。
还要注意,一旦模型训练好了,也就是说,一旦我们选择了最终的、最好的、最喜欢的权重分配,那么我们可以将权重视为模型的一部分,因为我们不再对它们进行变化。
因此,实际上在训练后使用模型看起来像图 1-7。

图 1-7。使用训练后的模型作为程序
这看起来与我们在图 1-4 中的原始图表相同,只是将程序一词替换为模型。这是一个重要的观点:训练后的模型可以像常规计算机程序一样对待。
行话:机器学习
通过让计算机从经验中学习而不是通过手动编码个别步骤来开发程序的培训。
什么是神经网络?
不难想象跳棋程序的模型可能是什么样子。可能编码了一系列跳棋策略,以及某种搜索机制,然后权重可以变化以决定如何选择策略,在搜索期间关注棋盘的哪些部分等等。但是对于图像识别程序,或者理解文本,或者我们可能想象的许多其他有趣的问题,模型可能是什么样子却一点也不明显。
我们希望有一种函数,它如此灵活,以至于可以通过调整其权重来解决任何给定问题。令人惊讶的是,这种函数实际上存在!这就是我们已经讨论过的神经网络。也就是说,如果您将神经网络视为数学函数,那么它将是一种极其灵活的函数,取决于其权重。一种称为通用逼近定理的数学证明表明,这种函数在理论上可以解决任何问题,达到任何精度水平。神经网络如此灵活的事实意味着,在实践中,它们通常是一种合适的模型,您可以将精力集中在训练过程上,即找到良好的权重分配。
但是这个过程呢?人们可以想象,您可能需要为每个问题找到一种新的“机制”来自动更新权重。这将是费力的。我们在这里也希望有一种完全通用的方法来更新神经网络的权重,使其在任何给定任务上都能提高。方便的是,这也存在!
这被称为随机梯度下降(SGD)。我们将在第四章中详细了解神经网络和 SGD 的工作原理,以及解释通用逼近定理。然而,现在,我们将使用塞缪尔自己的话来说:我们不需要深入了解这样一个过程的细节,就可以看到它可以完全自动化,并且可以看到这样一个机器编程的机器可以从中学习经验。
杰里米说
不要担心;无论是 SGD 还是神经网络,在数学上都不复杂。它们几乎完全依赖于加法和乘法来完成工作(但它们进行了大量的加法和乘法!)。当学生们看到细节时,我们听到的主要反应是:“就是这样吗?”
换句话说,简而言之,神经网络是一种特殊类型的机器学习模型,它完全符合塞缪尔最初的构想。神经网络之所以特殊,是因为它们非常灵活,这意味着它们可以通过找到正确的权重来解决异常广泛的问题。这是强大的,因为随机梯度下降为我们提供了一种自动找到这些权重值的方法。
放大后,让我们现在缩小范围,重新审视使用塞缪尔框架解决我们的图像分类问题。
我们的输入是图像。我们的权重是神经网络中的权重。我们的模型是一个神经网络。我们的结果是由神经网络计算出的值,比如“狗”或“猫”。
下一个部分是什么,一个自动测试任何当前权重分配的有效性的手段?确定“实际表现”很容易:我们可以简单地将模型的表现定义为其在预测正确答案时的准确性。
将所有这些放在一起,假设 SGD 是我们更新权重分配的机制,我们可以看到我们的图像分类器是一个机器学习模型,就像 Samuel 所设想的那样。
一些深度学习术语
Samuel 在 1960 年代工作,自那时术语已经发生了变化。以下是我们讨论过的所有部分的现代深度学习术语:
-
模型的功能形式被称为架构(但要小心—有时人们将模型用作架构的同义词,这可能会让人困惑)。
-
权重被称为参数。
-
预测是从独立变量计算出来的,这是不包括标签的数据。
-
模型的结果被称为预测。
-
性能的度量被称为损失。
-
损失不仅取决于预测,还取决于正确的标签(也称为目标或因变量);例如,“狗”或“猫”。
在进行这些更改后,我们在图 1-6 中的图表看起来像图 1-8。

图 1-8. 详细训练循环
机器学习固有的限制
从这幅图片中,我们现在可以看到关于训练深度学习模型的一些基本事情:
-
没有数据就无法创建模型。
-
模型只能学习操作训练数据中看到的模式。
-
这种学习方法只创建预测,而不是推荐的行动。
-
仅仅拥有输入数据的示例是不够的;我们还需要为这些数据提供标签(例如,仅有狗和猫的图片不足以训练模型;我们需要为每个图片提供一个标签,说明哪些是狗,哪些是猫)。
一般来说,我们已经看到大多数组织声称他们没有足够的数据实际上意味着他们没有足够的带标签数据。如果任何组织有兴趣在实践中使用模型做一些事情,那么他们可能有一些输入数据计划运行他们的模型。并且可能他们已经以其他方式做了一段时间(例如,手动或使用一些启发式程序),因此他们有来自这些过程的数据!例如,放射学实践几乎肯定会有医学扫描的存档(因为他们需要能够检查他们的患者随时间的进展),但这些扫描可能没有包含诊断或干预措施列表的结构化标签(因为放射科医生通常创建自由文本自然语言报告,而不是结构化数据)。在本书中,我们将大量讨论标记方法,因为这在实践中是一个非常重要的问题。
由于这类机器学习模型只能进行预测(即试图复制标签),这可能导致组织目标与模型能力之间存在显著差距。例如,在本书中,您将学习如何创建一个推荐系统,可以预测用户可能购买的产品。这通常用于电子商务,例如通过显示排名最高的商品来定制主页上显示的产品。但这样的模型通常是通过查看用户及其购买历史(输入)以及他们最终购买或查看的内容(标签)来创建的,这意味着该模型很可能会告诉您关于用户已经拥有或已经了解的产品,而不是他们最有可能对其感兴趣的新产品。这与您当地书店的专家所做的事情大不相同,他们会询问您的口味,然后告诉您您以前从未听说过的作者或系列。
另一个关键的洞察来自于考虑模型如何与其环境互动。这可能会产生反馈循环,如此处所述:
-
基于过去的逮捕地点创建了一个预测性执法模型。实际上,这并不是在预测犯罪,而是在预测逮捕,因此部分地只是反映了现有执法过程中的偏见。
-
然后执法人员可能会使用该模型来决定在哪里集中他们的执法活动,导致这些地区的逮捕增加。
-
这些额外逮捕的数据将被反馈回去重新训练未来版本的模型。
这是一个正反馈循环:模型被使用得越多,数据就变得越有偏见,使模型变得更加有偏见,依此类推。
反馈循环也可能在商业环境中造成问题。例如,视频推荐系统可能会偏向于推荐由视频最大观看者消费的内容(例如,阴谋论者和极端分子倾向于观看比平均水平更多的在线视频内容),导致这些用户增加他们的视频消费量,进而导致更多这类视频被推荐。我们将在第三章中更详细地讨论这个话题。
既然你已经看到了理论的基础,让我们回到我们的代码示例,详细看看代码如何与我们刚刚描述的过程相对应。
我们的图像识别器是如何工作的
让我们看看我们的图像识别器代码如何映射到这些想法。我们将把每一行放入一个单独的单元格,并查看每一行正在做什么(我们暂时不会解释每个参数的每个细节,但会给出重要部分的描述;完整细节将在本书后面提供)。第一行导入了整个 fastai.vision 库:
from fastai.vision.all import *
这为我们提供了创建各种计算机视觉模型所需的所有函数和类。
Jeremy 说
许多 Python 编程人员建议避免像这样导入整个库(使用import *语法),因为在大型软件项目中可能会引起问题。然而,在交互式工作中,比如在 Jupyter 笔记本中,它非常有效。fastai 库专门设计用于支持这种交互式使用,它只会将必要的部分导入到您的环境中。
第二行从fast.ai 数据集合下载一个标准数据集(如果之前没有下载),将其提取出来(如果之前没有提取),并返回一个提取位置的Path对象:
path = untar_data(URLs.PETS)/'images'
Sylvain 说
在 fast.ai 学习期间,甚至到今天,我学到了很多关于高效编码实践的知识。fastai 库和 fast.ai 笔记本中充满了许多有用的小贴士,这些贴士帮助我成为了一个更好的程序员。例如,请注意 fastai 库不仅返回包含数据集路径的字符串,而是一个Path对象。这是 Python 3 标准库中一个非常有用的类,使得访问文件和目录变得更加容易。如果你之前没有接触过它,请务必查看其文档或教程并尝试使用。请注意,书籍网站包含了每章推荐教程的链接。我会继续在我们遇到时告诉你我发现有用的小编码技巧。
在第三行,我们定义了一个函数is_cat,根据数据集创建者提供的文件名规则来标记猫:
def is_cat(x): return x[0].isupper()
我们在第四行使用了这个函数,告诉 fastai 我们拥有什么类型的数据集以及它的结构:
dls = ImageDataLoaders.from_name_func(path, get_image_files(path), valid_pct=0.2, seed=42,label_func=is_cat, item_tfms=Resize(224))
不同类型的深度学习数据集和问题有各种类别,这里我们使用ImageDataLoaders。类名的第一部分通常是你拥有的数据类型,比如图像或文本。
我们必须告诉 fastai 的另一个重要信息是如何从数据集中获取标签。计算机视觉数据集通常以标签作为文件名或路径的一部分进行结构化,最常见的是父文件夹名称。fastai 带有许多标准化的标记方法,以及编写自己的方法。在这里,我们告诉 fastai 使用我们刚刚定义的is_cat函数。
最后,我们定义了我们需要的Transform。Transform包含在训练期间自动应用的代码;fastai 包含许多预定义的Transform,添加新的Transform就像创建一个 Python 函数一样简单。有两种类型:item_tfms应用于每个项目(在本例中,每个项目都被调整为 224 像素的正方形),而batch_tfms应用于一次处理一批项目的 GPU,因此它们特别快速(我们将在本书中看到许多这样的例子)。
为什么是 224 像素?出于历史原因(旧的预训练模型需要这个确切的尺寸),但你几乎可以传入任何尺寸。如果增加尺寸,通常会得到更好的模型结果(因为它可以关注更多细节),但代价是速度和内存消耗;如果减小尺寸,则相反。
术语:分类和回归
分类和回归在机器学习中有非常具体的含义。这两种模型是我们在本书中将要研究的两种主要类型。分类模型试图预测一个类别。也就是说,它从许多离散的可能性中进行预测,比如“狗”或“猫”。回归模型试图预测一个或多个数值,比如温度或位置。有时人们使用回归一词来指代一种特定类型的模型,称为线性回归模型;这是一个不好的做法,在本书中我们不会使用这种术语!
Pet 数据集包含 7390 张狗和猫的图片,包括 37 种品种。每个图像都使用其文件名进行标记:例如,文件great_pyrenees_173.jpg是数据集中大白熊犬品种的第 173 个示例图像。如果图像是猫,则文件名以大写字母开头,否则以小写字母开头。我们必须告诉 fastai 如何从文件名中获取标签,我们通过调用from_name_func来实现(这意味着可以使用应用于文件名的函数来提取文件名),并传递x[0].isupper(),如果第一个字母是大写字母(即是猫),则评估为True。
在这里提到的最重要的参数是valid_pct=0.2。这告诉 fastai 保留 20%的数据,完全不用于训练模型。这 20%的数据被称为验证集;剩下的 80%被称为训练集。验证集用于衡量模型的准确性。默认情况下,被保留的 20%是随机选择的。参数seed=42将随机种子设置为每次运行此代码时相同的值,这意味着每次运行时我们都会得到相同的验证集,这样,如果我们更改模型并重新训练它,我们知道任何差异都是由于对模型的更改,而不是由于有不同的随机验证集。
fastai 将始终仅使用验证集显示模型的准确性,永远不会使用训练集。这是绝对关键的,因为如果您为足够长的时间训练足够大的模型,它最终会记住数据集中每个项目的标签!结果将不是一个有用的模型,因为我们关心的是我们的模型在以前未见过的图像上的工作效果。这总是我们创建模型时的目标:使其在模型仅在未来看到的数据上有用,经过训练后。
即使您的模型尚未完全记住所有数据,在训练的早期阶段可能已经记住了其中的某些部分。因此,您训练的时间越长,您在训练集上的准确性就会越好;验证集的准确性也会在一段时间内提高,但最终会开始变差,因为模型开始记住训练集而不是在数据中找到可泛化的潜在模式。当这种情况发生时,我们说模型过拟合。
图 1-9 展示了过拟合时会发生什么,使用一个简化的例子,我们只有一个参数和一些基于函数x**2随机生成的数据。正如您所看到的,尽管过拟合模型在接近观察到的数据点的数据上的预测是准确的,但在该范围之外时则相差甚远。
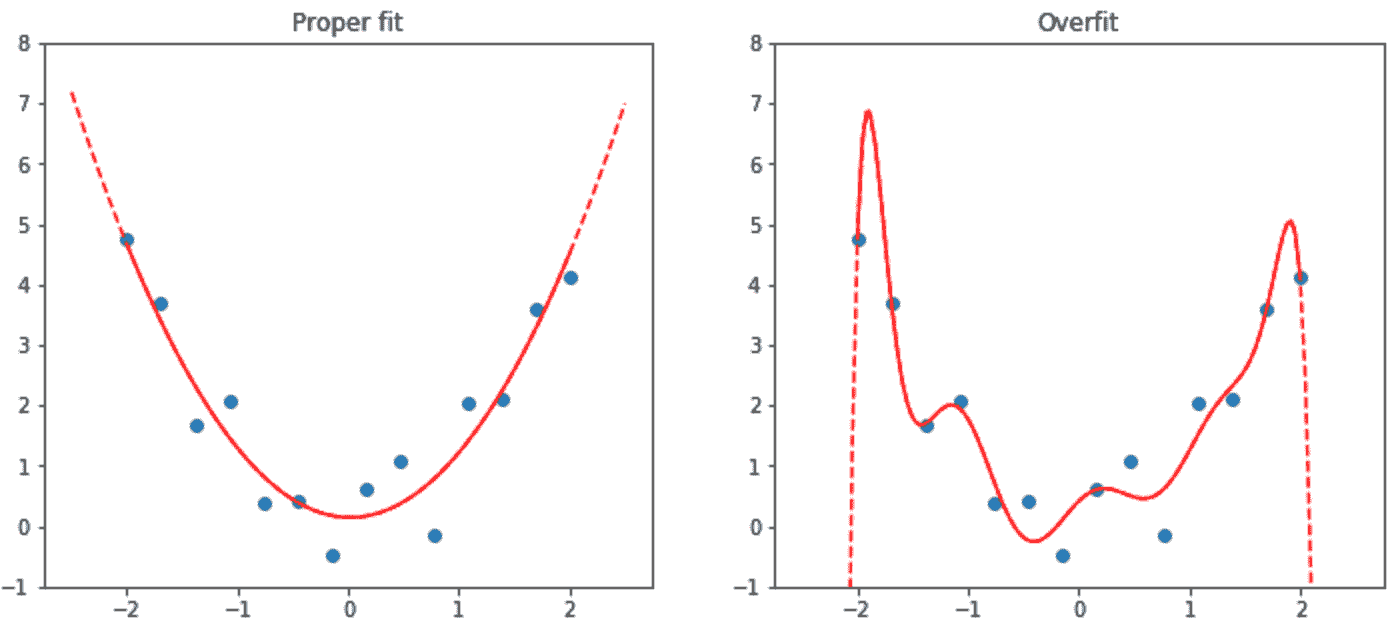
图 1-9. 过拟合示例
过拟合是训练所有机器学习从业者和所有算法时最重要和具有挑战性的问题。正如您将看到的,很容易创建一个在准确预测其训练数据上做得很好的模型,但要在模型从未见过的数据上做出准确预测要困难得多。当然,这些数据在实践中是重要的。例如,如果您创建一个手写数字分类器(我们很快就会!)并将其用于识别支票上写的数字,那么您永远不会看到模型训练过的任何数字——每张支票都会有稍微不同的书写变化。
您将在本书中学习许多避免过拟合的方法。但是,只有在确认发生过拟合时(即,如果您观察到训练过程中验证准确性变差)才应使用这些方法。我们经常看到从业者在有足够数据的情况下也使用过拟合避免技术,最终得到的模型可能比他们本可以实现的更不准确。
验证集
当您训练模型时,您必须始终同时拥有训练集和验证集,并且必须仅在验证集上测量模型的准确性。如果您训练时间过长,数据不足,您将看到模型的准确性开始变差;这被称为过拟合。fastai 将valid_pct默认设置为0.2,因此即使您忘记了,fastai 也会为您创建一个验证集!
我们的图像识别器训练代码的第五行告诉 fastai 创建一个卷积神经网络(CNN),并指定要使用的架构(即要创建的模型类型)、我们要对其进行训练的数据以及要使用的度量标准:
learn = cnn_learner(dls, resnet34, metrics=error_rate)
为什么使用 CNN?这是创建计算机视觉模型的当前最先进方法。我们将在本书中学习有关 CNN 如何工作的所有知识。它们的结构受到人类视觉系统工作方式的启发。
在 fastai 中有许多架构,我们将在本书中介绍(以及讨论如何创建您自己的架构)。然而,大多数情况下,选择架构并不是深度学习过程中非常重要的部分。这是学术界喜欢谈论的内容,但实际上您不太可能需要花费太多时间。有一些标准架构在大多数情况下都有效,而在这种情况下,我们使用的是一种称为ResNet的架构,我们将在本书中大量讨论;它对许多数据集和问题都既快速又准确。resnet34中的34指的是该架构变体中的层数(其他选项是18、50、101和152)。使用层数更多的架构模型训练时间更长,更容易过拟合(即在验证集上的准确率开始变差之前无法训练多少个时期)。另一方面,当使用更多数据时,它们可能会更准确。
什么是度量标准?度量标准是一个函数,使用验证集来衡量模型预测的质量,并将在每个时期结束时打印出来。在这种情况下,我们使用error_rate,这是 fastai 提供的一个函数,它正是它所说的:告诉您验证集中有多少百分比的图像被错误分类。分类的另一个常见度量标准是accuracy(即1.0 - error_rate)。fastai 提供了许多其他度量标准,这将在本书中讨论。
度量标准的概念可能会让您想起损失,但有一个重要区别。损失的整个目的是定义一个“性能度量”,训练系统可以使用它来自动更新权重。换句话说,损失的一个好选择是易于随机梯度下降使用的选择。但度量标准是为人类消费而定义的,因此一个好的度量标准是您易于理解的,并且尽可能接近您希望模型执行的任务。有时,您可能会决定损失函数是一个合适的度量标准,但这并不一定是情况。
cnn_learner还有一个名为pretrained的参数,默认值为True(因此在这种情况下使用,即使我们没有指定),它将您模型中的权重设置为已经由专家训练过的值,以识别 130 万张照片中的一千个不同类别(使用著名的ImageNet数据集)。具有已在另一个数据集上训练过的权重的模型称为预训练模型。您几乎总是应该使用预训练模型,因为这意味着您的模型在您甚至没有展示任何数据之前就已经非常有能力。正如您将看到的,在深度学习模型中,许多这些能力是您几乎无论项目细节如何都需要的。例如,预训练模型的部分将处理边缘、梯度和颜色检测,这些对许多任务都是必需的。
使用预训练模型时,cnn_learner将移除最后一层,因为该层始终是针对原始训练任务(即 ImageNet 数据集分类)专门定制的,并将其替换为一个或多个具有随机权重的新层,适合您正在处理的数据集的大小。模型的最后部分被称为头。
使用预训练模型是我们训练更准确、更快速、使用更少数据和更少时间和金钱的最重要方法。您可能会认为使用预训练模型将是学术深度学习中最研究的领域…但您会非常、非常错误!预训练模型的重要性通常在大多数课程、书籍或软件库功能中没有得到认可或讨论,并且在学术论文中很少被考虑。当我们在 2020 年初写这篇文章时,事情刚刚开始改变,但这可能需要一段时间。因此要小心:您与之交谈的大多数人可能会严重低估您可以在深度学习中使用少量资源做些什么,因为他们可能不会深入了解如何使用预训练模型。
使用一个预训练模型来执行一个与其最初训练目的不同的任务被称为迁移学习。不幸的是,由于迁移学习研究不足,很少有领域提供预训练模型。例如,目前在医学领域很少有预训练模型可用,这使得在该领域使用迁移学习具有挑战性。此外,目前还不清楚如何将迁移学习应用于诸如时间序列分析之类的任务。
术语:迁移学习
使用一个预训练模型来执行一个与其最初训练目的不同的任务。
我们代码的第六行告诉 fastai 如何适应模型:
learn.fine_tune(1)
正如我们所讨论的,架构只是描述数学函数的模板;直到我们为其包含的数百万参数提供值之前,它才会真正发挥作用。
这是深度学习的关键之处——确定如何适应模型的参数以使其解决您的问题。要适应一个模型,我们必须提供至少一条信息:每个图像查看多少次(称为时代数)。您选择的时代数将在很大程度上取决于您有多少时间可用,以及您发现在实践中适应模型需要多长时间。如果选择的数字太小,您可以随时稍后进行更多时代的训练。
但为什么这种方法被称为fine_tune,而不是fit?fastai 确实有一个名为fit的方法,它确实适合一个模型(即,多次查看训练集中的图像,每次更新参数使预测越来越接近目标标签)。但在这种情况下,我们已经从一个预训练模型开始,并且我们不想丢弃它已经具有的所有这些功能。正如您将在本书中了解到的,有一些重要的技巧可以使预训练模型适应新数据集,这个过程称为微调。
术语:微调
一种迁移学习技术,通过使用与预训练不同的任务进行额外时代的训练来更新预训练模型的参数。
当您使用fine_tune方法时,fastai 将为您使用这些技巧。您可以设置一些参数(我们稍后会讨论),但在此处显示的默认形式中,它执行两个步骤:
-
使用一个时代来适应模型的那些部分,以使新的随机头部能够正确地与您的数据集配合工作。
-
在调用适合整个模型的方法时,请使用请求的时代数,更快地更新后面的层(特别是头部)的权重,而不是早期的层(正如我们将看到的,通常不需要对预训练权重进行太多更改)。
模型的头部是新添加的部分,专门针对新数据集。一个时代是对数据集的一次完整遍历。在调用fit之后,每个时代后的结果都会被打印出来,显示时代编号,训练和验证集的损失(用于训练模型的“性能度量”),以及您请求的任何指标(在这种情况下是错误率)。
因此,通过所有这些代码,我们的模型学会了仅仅通过标记的示例来识别猫和狗。但它是如何做到的呢?
我们的图像识别器学到了什么
在这个阶段,我们有一个工作良好的图像识别器,但我们不知道它在做什么!尽管许多人抱怨深度学习导致不可理解的“黑匣子”模型(即,可以提供预测但没有人能理解的东西),但事实并非如此。有大量研究表明如何深入检查深度学习模型并从中获得丰富的见解。话虽如此,各种机器学习模型(包括深度学习和传统统计模型)都可能难以完全理解,特别是考虑到它们在遇到与用于训练它们的数据非常不同的数据时的行为。我们将在本书中讨论这个问题。
2013 年,博士生 Matt Zeiler 和他的导师 Rob Fergus 发表了《可视化和理解卷积网络》,展示了如何可视化模型每一层学到的神经网络权重。他们仔细分析了赢得 2012 年 ImageNet 比赛的模型,并利用这一分析大大改进了模型,使他们能够赢得 2013 年的比赛!图 1-10 是他们发表的第一层权重的图片。

图 1-10。CNN 第一层的激活(由 Matthew D. Zeiler 和 Rob Fergus 提供)
这张图片需要一些解释。对于每一层,具有浅灰色背景的图像部分显示了重建的权重,底部较大的部分显示了与每组权重最匹配的训练图像部分。对于第一层,我们可以看到模型发现了代表对角线、水平和垂直边缘以及各种梯度的权重。(请注意,对于每一层,只显示了部分特征;实际上,在所有层中有成千上万个特征。)
这些是模型为计算机视觉学习的基本构建块。它们已经被神经科学家和计算机视觉研究人员广泛分析,结果表明,这些学习的构建块与人眼的基本视觉机制以及在深度学习之前开发的手工计算机视觉特征非常相似。下一层在图 1-11 中表示。

图 1-11。CNN 第二层的激活(由 Matthew D. Zeiler 和 Rob Fergus 提供)
对于第 2 层,模型找到的每个特征都有九个权重重建示例。我们可以看到模型已经学会创建寻找角、重复线条、圆圈和其他简单模式的特征检测器。这些是从第一层中开发的基本构建块构建的。对于每个特征,图片右侧显示了与这些特征最匹配的实际图像的小块。例如,第 2 行第 1 列中的特定模式与日落相关的梯度和纹理相匹配。
图 1-12 显示了一篇论文中展示第 3 层特征重建结果的图片。

图 1-12。CNN 第三层的激活(由 Matthew D. Zeiler 和 Rob Fergus 提供)
通过观察图片右侧,您可以看到特征现在能够识别和匹配更高级的语义组件,如汽车车轮、文字和花瓣。利用这些组件,第 4 层和第 5 层可以识别更高级的概念,如图 1-13 所示。

图 1-13。CNN 的第四和第五层的激活(由 Matthew D. Zeiler 和 Rob Fergus 提供)
本文研究了一个名为AlexNet的旧模型,该模型只包含五层。自那时以来开发的网络可以有数百层 - 所以你可以想象这些模型开发的特征有多丰富!
当我们早期微调我们的预训练模型时,我们调整了最后几层关注的内容(花朵、人类、动物),以专注于猫与狗问题。更一般地,我们可以将这样的预训练模型专门用于许多不同的任务。让我们看一些例子。
图像识别器可以处理非图像任务
图像识别器只能识别图像,顾名思义。但很多事物可以被表示为图像,这意味着图像识别器可以学会完成许多任务。
例如,声音可以转换为频谱图,这是一种图表,显示音频文件中每个时间的每个频率的数量。fast.ai 学生 Ethan Sutin 使用这种方法,轻松击败了一种最先进的环境声音检测模型的发布准确率,使用了 8732 个城市声音的数据集。fastai 的show_batch清楚地显示了每个声音具有相当独特的频谱图,如图 1-14 所示。
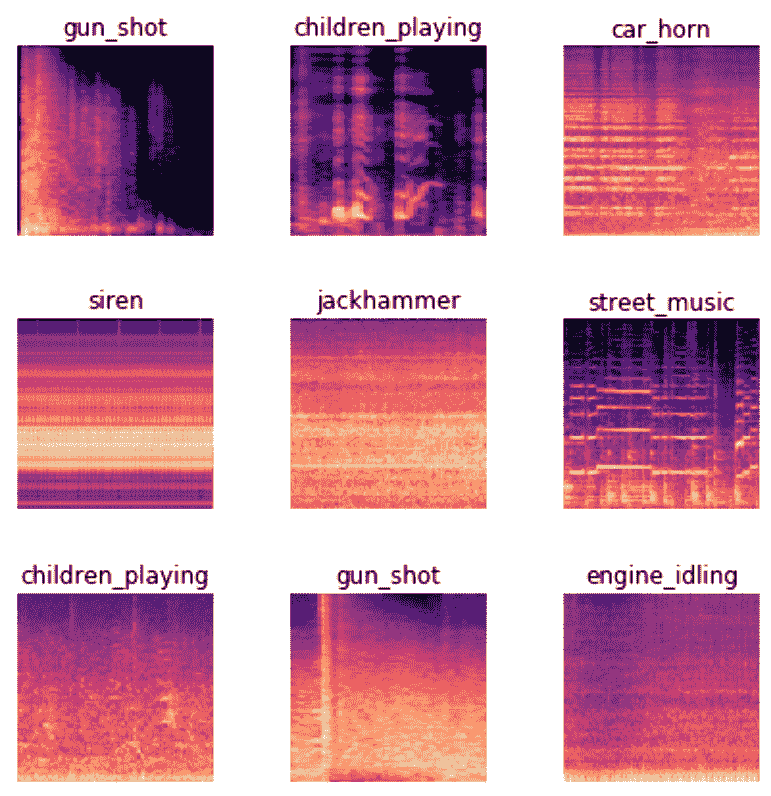
图 1-14。显示具有声音频谱图的 show_batch
时间序列可以很容易地通过简单地在图表上绘制时间序列来转换为图像。然而,通常最好尝试以尽可能简单的方式表示数据,以便提取出最重要的组件。在时间序列中,季节性和异常很可能是感兴趣的。
时间序列数据有各种转换方法。例如,fast.ai 学生 Ignacio Oguiza 使用一种称为 Gramian Angular Difference Field(GADF)的技术,从一个时间序列数据集中为橄榄油分类创建图像,你可以在图 1-15 中看到结果。然后,他将这些图像输入到一个图像分类模型中,就像你在本章中看到的那样。尽管只有 30 个训练集图像,但他的结果准确率超过 90%,接近最先进水平。
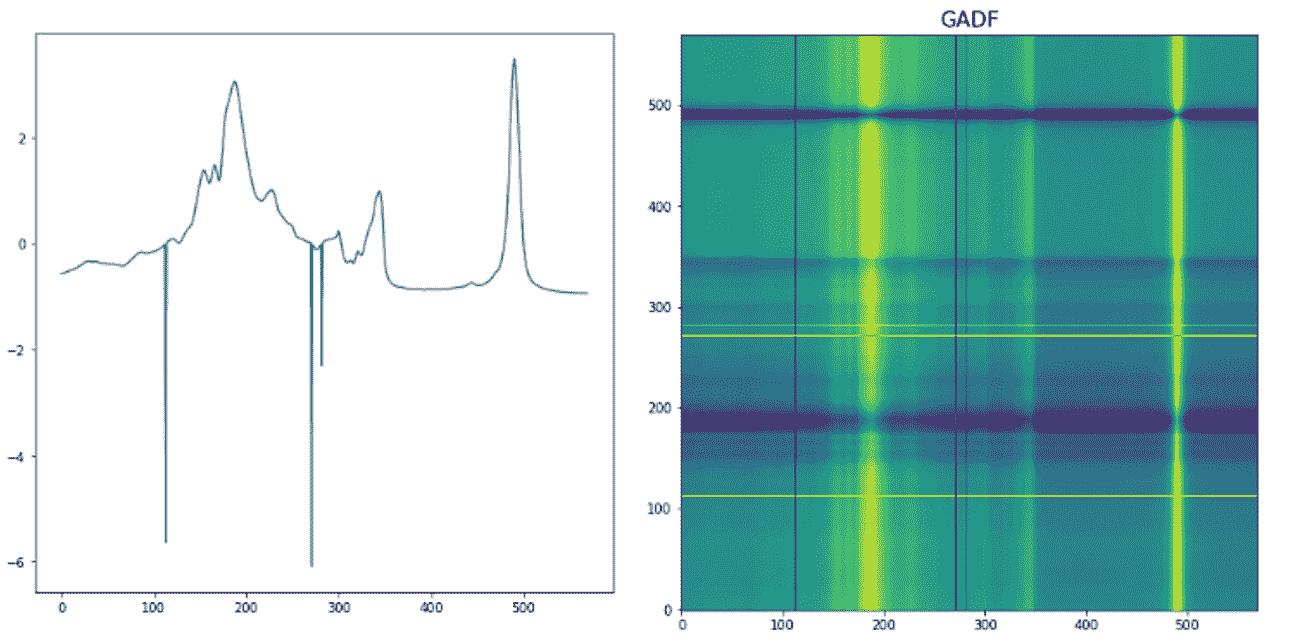
图 1-15。将时间序列转换为图像
另一个有趣的 fast.ai 学生项目示例来自 Gleb Esman。他在 Splunk 上进行欺诈检测,使用了用户鼠标移动和鼠标点击的数据集。他通过绘制显示鼠标指针位置、速度和加速度的图像,使用彩色线条,并使用小彩色圆圈显示点击,将这些转换为图片,如图 1-16 所示。他将这些输入到一个图像识别模型中,就像我们在本章中使用的那样,效果非常好,导致了这种方法在欺诈分析方面的专利!

图 1-16。将计算机鼠标行为转换为图像
另一个例子来自 Mahmoud Kalash 等人的论文“使用深度卷积神经网络进行恶意软件分类”,解释了“恶意软件二进制文件被分成 8 位序列,然后转换为等效的十进制值。这个十进制向量被重塑,生成了一个代表恶意软件样本的灰度图像”,如图 1-17 所示。
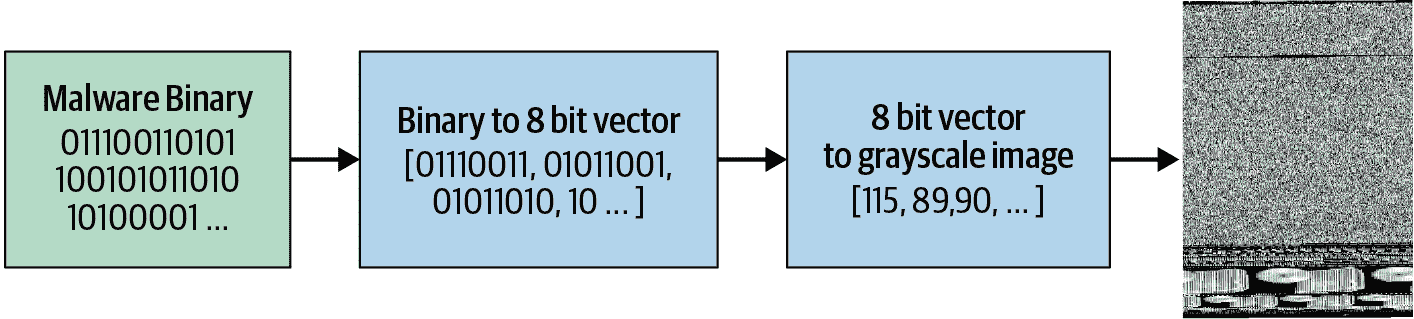
图 1-17。恶意软件分类过程
作者们随后展示了通过恶意软件分类生成的“图片”,如图 1-18 所示。

图 1-18。恶意软件示例
正如您所看到的,不同类型的恶意软件在人眼中看起来非常独特。研究人员基于这种图像表示训练的模型在恶意软件分类方面比学术文献中显示的任何先前方法都更准确。这表明将数据集转换为图像表示的一个很好的经验法则:如果人眼可以从图像中识别类别,那么深度学习模型也应该能够做到。
总的来说,您会发现在深度学习中,少数几种通用方法可以走得很远,只要您在如何表示数据方面有点创造性!您不应该将这里描述的方法视为“巧妙的变通方法”,因为它们通常(如此处)击败了以前的最先进结果。这确实是正确思考这些问题领域的方法。
术语回顾
我们刚刚涵盖了很多信息,让我们简要回顾一下。表 1-3 提供了一个方便的词汇表。
表 1-3. 深度学习词汇表
| 术语 | 意义 |
|---|---|
| 标签 | 我们试图预测的数据,比如“狗”或“猫” |
| 架构 | 我们试图拟合的模型的 * 模板 *;即我们将输入数据和参数传递给的实际数学函数 |
| 模型 | 架构与特定一组参数的组合 |
| 参数 | 模型中改变任务的值,通过模型训练进行更新 |
| 拟合 | 更新模型的参数,使得使用输入数据的模型预测与目标标签匹配 |
| 训练 | * 拟合 * 的同义词 |
| 预训练模型 | 已经训练过的模型,通常使用大型数据集,并将进行微调 |
| 微调 | 为不同任务更新预训练模型 |
| 纪元 | 一次完整通过输入数据 |
| 损失 | 衡量模型好坏的指标,选择以驱动通过 SGD 进行训练 |
| 指标 | 使用验证集衡量模型好坏的测量标准,选择供人类消费 |
| 验证集 | 从训练中保留的一组数据,仅用于衡量模型好坏 |
| 训练集 | 用于拟合模型的数据;不包括验证集中的任何数据 |
| 过拟合 | 以使模型 * 记住 * 输入数据的特定特征而不是很好地泛化到训练期间未见的数据的方式训练模型 |
| CNN | 卷积神经网络;一种特别适用于计算机视觉任务的神经网络 |
有了这个词汇表,我们现在可以将迄今介绍的所有关键概念汇集在一起。花点时间回顾这些定义,并阅读以下摘要。如果您能理解解释,那么您就有能力理解接下来的讨论。
- 机器学习 *是一种学科,我们通过从数据中学习来定义程序,而不是完全自己编写它。 * 深度学习 *是机器学习中使用具有多个 * 层 * 的 * 神经网络 * 的专业领域。 * 图像分类 * 是一个代表性的例子(也称为 * 图像识别 *)。我们从 * 标记数据 * 开始 - 一组我们为每个图像分配了 * 标签 * 的图像,指示它代表什么。我们的目标是生成一个称为 * 模型 * 的程序,给定一个新图像,将对该新图像代表的内容进行准确的 * 预测 *。
每个模型都从选择 * 架构 * 开始,这是该类型模型内部工作方式的一般模板。 * 训练 *(或 * 拟合 *)模型的过程是找到一组 * 参数值 *(或 * 权重 *),这些参数值将该一般架构专门化为适用于我们特定数据类型的模型。为了定义模型在单个预测上的表现如何,我们需要定义一个 * 损失函数 *,它确定我们如何将预测评分为好或坏。
为了让训练过程更快,我们可以从一个预训练模型开始——一个已经在其他人的数据上训练过的模型。然后我们可以通过在我们的数据上进一步训练它来使其适应我们的数据,这个过程称为微调。
当我们训练一个模型时,一个关键问题是确保我们的模型泛化:它从我们的数据中学到的一般性教训也适用于它将遇到的新项目,这样它就可以对这些项目做出良好的预测。风险在于,如果我们训练模型不当,它实际上会记住它已经看到的内容,而不是学习一般性教训,然后它将对新图像做出糟糕的预测。这样的失败被称为过拟合。
为了避免这种情况,我们总是将数据分为两部分,训练集和验证集。我们通过只向模型展示训练集来训练模型,然后通过查看模型在验证集中的表现来评估模型的表现如何。通过这种方式,我们检查模型从训练集中学到的教训是否适用于验证集。为了评估模型在验证集上的整体表现,我们定义一个度量。在训练过程中,当模型看到训练集中的每个项目时,我们称之为一个周期。
所有这些概念都适用于机器学习。它们适用于各种通过训练数据定义模型的方案。深度学习的独特之处在于一类特定的架构:基于神经网络的架构。特别是,像图像分类这样的任务在卷积神经网络上严重依赖,我们将很快讨论。
深度学习不仅仅适用于图像分类
近年来,深度学习在分类图像方面的有效性已经被广泛讨论,甚至在识别 CT 扫描中的恶性肿瘤等复杂任务上显示出超人类的结果。但它可以做的远不止这些,正如我们将在这里展示的。
例如,让我们谈谈对于自动驾驶汽车至关重要的一点:在图片中定位物体。如果自动驾驶汽车不知道行人在哪里,那么它就不知道如何避开!创建一个能够识别图像中每个单独像素内容的模型被称为分割。以下是我们如何使用 fastai 训练一个分割模型,使用来自 Gabriel J. Brostow 等人的论文“视频中的语义对象类:高清实况数据库”中的CamVid数据集的子集:
path = untar_data(URLs.CAMVID_TINY)
dls = SegmentationDataLoaders.from_label_func(path, bs=8, fnames = get_image_files(path/"images"),label_func = lambda o: path/'labels'/f'{o.stem}_P{o.suffix}',codes = np.loadtxt(path/'codes.txt', dtype=str)
)learn = unet_learner(dls, resnet34)
learn.fine_tune(8)
| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 2.906601 | 2.347491 | 00:02 |
| epoch | train_loss | valid_loss | time |
| — | — | — | — |
| 0 | 1.988776 | 1.765969 | 00:02 |
| 1 | 1.703356 | 1.265247 | 00:02 |
| 2 | 1.591550 | 1.309860 | 00:02 |
| 3 | 1.459745 | 1.102660 | 00:02 |
| 4 | 1.324229 | 0.948472 | 00:02 |
| 5 | 1.205859 | 0.894631 | 00:02 |
| 6 | 1.102528 | 0.809563 | 00:02 |
| 7 | 1.020853 | 0.805135 | 00:02 |
我们甚至不会逐行走过这段代码,因为它几乎与我们之前的示例完全相同!(我们将在第十五章深入探讨分割模型,以及本章中我们简要介绍的所有其他模型以及更多更多。)
我们可以通过要求模型为图像的每个像素着色来可视化它的任务完成情况。正如您所看到的,它几乎完美地对每个对象中的每个像素进行分类。例如,请注意所有的汽车都被叠加着相同的颜色,所有的树都被叠加着相同的颜色(在每对图像中,左侧图像是地面实况标签,右侧是模型的预测):
learn.show_results(max_n=6, figsize=(7,8))

另一个深度学习在过去几年显著改进的领域是自然语言处理(NLP)。计算机现在可以生成文本,自动从一种语言翻译到另一种语言,分析评论,标记句子中的单词等等。以下是训练一个模型所需的所有代码,该模型可以比五年前世界上任何东西更好地分类电影评论的情感:
from fastai.text.all import *dls = TextDataLoaders.from_folder(untar_data(URLs.IMDB), valid='test')
learn = text_classifier_learner(dls, AWD_LSTM, drop_mult=0.5, metrics=accuracy)
learn.fine_tune(4, 1e-2)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.594912 | 0.407416 | 0.823640 | 01:35 |
| epoch | train_loss | valid_loss | accuracy | time |
| — | — | — | — | — |
| 0 | 0.268259 | 0.316242 | 0.876000 | 03:03 |
| 1 | 0.184861 | 0.246242 | 0.898080 | 03:10 |
| 2 | 0.136392 | 0.220086 | 0.918200 | 03:16 |
| 3 | 0.106423 | 0.191092 | 0.931360 | 03:15 |
这个模型使用了 Andrew Maas 等人的论文“Learning Word Vectors for Sentiment Analysis”中的IMDb Large Movie Review dataset。它在许多千字长的电影评论中表现良好,但让我们在一个短评论上测试一下看看它的表现如何:
learn.predict("I really liked that movie!")
('pos', tensor(1), tensor([0.0041, 0.9959]))
在这里我们可以看到模型认为评论是积极的。结果的第二部分是我们数据词汇中“pos”的索引,最后一部分是分配给每个类的概率(“pos”为 99.6%,“neg”为 0.4%)。
现在轮到你了!写下你自己的迷你电影评论,或者从互联网上复制一个,看看这个模型对它的看法。
如果您对 fastai 的任何方法有任何疑问,您应该使用doc函数,将方法名称传递给它:
doc(learn.predict)

一个窗口弹出,包含一个简短的一行解释。 “在文档中显示”链接将带您到完整的文档,在那里您将找到所有细节和许多示例。此外,fastai 的大多数方法只是几行代码,因此您可以单击“源”链接查看幕后发生的情况。
让我们继续讨论一些不那么性感,但可能在商业上更有用的事情:从普通表格数据构建模型。
术语:表格
表格形式的数据,例如来自电子表格、数据库或逗号分隔值(CSV)文件。表格模型是一种试图根据表格中其他列的信息来预测表格中一列的模型。
事实证明,这看起来非常相似。以下是训练一个模型所需的代码,该模型将根据个人的社会经济背景预测一个人是否是高收入者:
from fastai.tabular.all import *
path = untar_data(URLs.ADULT_SAMPLE)dls = TabularDataLoaders.from_csv(path/'adult.csv', path=path, y_names="salary",cat_names = ['workclass', 'education', 'marital-status', 'occupation','relationship', 'race'],cont_names = ['age', 'fnlwgt', 'education-num'],procs = [Categorify, FillMissing, Normalize])learn = tabular_learner(dls, metrics=accuracy)
正如您所看到的,我们不得不告诉 fastai 哪些列是分类(包含一组离散选择之一的值,例如occupation)与连续(包含表示数量的数字,例如age)。
这个任务没有预训练模型可用(一般来说,预训练模型在任何表格建模任务中都不广泛可用,尽管一些组织已经为内部使用创建了这些模型),所以在这种情况下我们不使用fine_tune。相反,我们使用fit_one_cycle,这是训练 fastai 模型从头开始(即没有迁移学习)最常用的方法:
learn.fit_one_cycle(3)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.359960 | 0.357917 | 0.831388 | 00:11 |
| 1 | 0.353458 | 0.349657 | 0.837991 | 00:10 |
| 2 | 0.338368 | 0.346997 | 0.843213 | 00:10 |
这个模型使用了 Ron Kohavi 的论文“Scaling Up the Accuracy of Naive-Bayes Classifiers: a Decision-Tree Hybrid”中的Adult数据集,其中包含一些关于个人的人口统计数据(如他们的教育、婚姻状况、种族、性别以及是否年收入超过 5 万美元)。该模型的准确率超过 80%,训练时间约为 30 秒。
让我们再看一个例子。推荐系统很重要,特别是在电子商务中。像亚马逊和 Netflix 这样的公司努力推荐用户可能喜欢的产品或电影。以下是如何训练一个模型,根据用户以前的观影习惯,预测用户可能喜欢的电影,使用MovieLens 数据集:
from fastai.collab import *
path = untar_data(URLs.ML_SAMPLE)
dls = CollabDataLoaders.from_csv(path/'ratings.csv')
learn = collab_learner(dls, y_range=(0.5,5.5))
learn.fine_tune(10)
| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 1.554056 | 1.428071 | 00:01 |
| epoch | train_loss | valid_loss | time |
| — | — | — | — |
| 0 | 1.393103 | 1.361342 | 00:01 |
| 1 | 1.297930 | 1.159169 | 00:00 |
| 2 | 1.052705 | 0.827934 | 00:01 |
| 3 | 0.810124 | 0.668735 | 00:01 |
| 4 | 0.711552 | 0.627836 | 00:01 |
| 5 | 0.657402 | 0.611715 | 00:01 |
| 6 | 0.633079 | 0.605733 | 00:01 |
| 7 | 0.622399 | 0.602674 | 00:01 |
| 8 | 0.629075 | 0.601671 | 00:00 |
| 9 | 0.619955 | 0.601550 | 00:01 |
这个模型在 0.5 到 5.0 的范围内预测电影评分,平均误差约为 0.6。由于我们预测的是一个连续数值,而不是一个类别,我们必须告诉 fastai 我们的目标范围是多少,使用y_range参数。
虽然我们实际上并没有使用预训练模型(和表格模型一样的原因),但这个例子显示了 fastai 在这种情况下仍然让我们使用fine_tune(您将在第五章中学习到这是如何以及为什么有效)。有时最好尝试fine_tune和fit_one_cycle,看看哪个对您的数据集效果更好。
我们可以使用之前看到的相同的show_results调用来查看一些用户和电影 ID、实际评分和预测:
learn.show_results()
| userId | movieId | rating | rating_pred | |
|---|---|---|---|---|
| 0 | 157 | 1200 | 4.0 | 3.558502 |
| 1 | 23 | 344 | 2.0 | 2.700709 |
| 2 | 19 | 1221 | 5.0 | 4.390801 |
| 3 | 430 | 592 | 3.5 | 3.944848 |
| 4 | 547 | 858 | 4.0 | 4.076881 |
| 5 | 292 | 39 | 4.5 | 3.753513 |
| 6 | 529 | 1265 | 4.0 | 3.349463 |
| 7 | 19 | 231 | 3.0 | 2.881087 |
| 8 | 475 | 4963 | 4.0 | 4.023387 |
| 9 | 130 | 260 | 4.5 | 3.979703 |
我们训练的每个模型都显示了训练和验证损失。一个好的验证集是训练过程中最重要的部分之一。让我们看看为什么,并学习如何创建一个。
验证集和测试集
正如我们所讨论的,模型的目标是对数据进行预测。但模型训练过程基本上是愚蠢的。如果我们用所有的数据训练一个模型,然后使用同样的数据评估模型,我们将无法判断我们的模型在未见过的数据上表现如何。没有这个非常宝贵的信息来指导我们训练模型,很有可能模型会擅长对这些数据进行预测,但在新数据上表现不佳。
为了避免这种情况,我们的第一步是将数据集分成两组:训练集(模型在训练中看到的)和验证集,也称为开发集(仅用于评估)。这样我们可以测试模型是否从训练数据中学到的经验可以推广到新数据,即验证数据。
理解这种情况的一种方式是,在某种意义上,我们不希望我们的模型通过“作弊”来获得好的结果。如果它对一个数据项做出准确的预测,那应该是因为它已经学到了那种类型的特征,而不是因为模型已经被实际看到那个特定项所塑造。
将验证数据集分离出来意味着我们的模型在训练中从未见过它,因此完全没有被它污染,并且没有以任何方式作弊。对吧?
实际上,并非一定如此。情况更为微妙。这是因为在现实场景中,我们很少仅通过一次训练参数来构建模型。相反,我们可能通过各种建模选择来探索模型的许多版本,包括网络架构、学习率、数据增强策略等因素,我们将在接下来的章节中讨论。其中许多选择可以描述为超参数的选择。这个词反映了它们是关于参数的参数,因为它们是控制权重参数含义的高级选择。
问题在于,即使普通的训练过程只看训练数据的预测结果来学习权重参数的值,我们却不是这样。作为建模者,当我们决定探索新的超参数值时,我们通过查看验证数据的预测结果来评估模型!因此,模型的后续版本间接地受到我们看到验证数据的影响。就像自动训练过程有过拟合训练数据的危险一样,我们通过人为试错和探索有过拟合验证数据的危险。
解决这个难题的方法是引入另一个更高度保留数据的层级:测试集。就像我们在训练过程中保留验证数据一样,我们必须连自己都不使用测试集数据。它不能用来改进模型;它只能在我们努力的最后阶段用来评估模型。实际上,我们定义了一个基于我们希望如何完全隐藏数据的层次结构:训练数据完全暴露,验证数据较少暴露,测试数据完全隐藏。这种层次结构与不同种类的建模和评估过程本身相对应——自动训练过程与反向传播,尝试不同超参数之间的更手动过程,以及我们最终结果的评估。
测试集和验证集应该有足够的数据来确保您对准确性有一个良好的估计。例如,如果您正在创建一个猫检测器,通常您希望验证集中至少有 30 只猫。这意味着如果您有数千个项目的数据集,使用默认的 20%验证集大小可能超出您的需求。另一方面,如果您有大量数据,将其中一部分用于验证可能没有任何不利之处。
拥有两个级别的“保留数据”——验证集和测试集,其中一个级别代表您几乎隐藏自己的数据——可能看起来有点极端。但通常是必要的,因为模型往往倾向于朝着做出良好预测的最简单方式(记忆)发展,而我们作为易犯错误的人类往往倾向于欺骗自己关于我们的模型表现如何。测试集的纪律帮助我们保持思想上的诚实。这并不意味着我们总是需要一个单独的测试集——如果您的数据很少,您可能只需要一个验证集——但通常最好尽可能使用一个。
如果您打算雇用第三方代表您进行建模工作,这种纪律也可能至关重要。第三方可能无法准确理解您的要求,或者他们的激励甚至可能鼓励他们误解。一个好的测试集可以极大地减轻这些风险,并让您评估他们的工作是否解决了您实际的问题。
直截了当地说,如果你是组织中的高级决策者(或者你正在为高级决策者提供建议),最重要的要点是:如果你确保真正理解测试和验证集以及它们的重要性,你将避免我们看到的组织决定使用 AI 时最大的失败源。例如,如果你考虑引入外部供应商或服务,请确保保留一些测试数据,供供应商永远看不到。然后你在你的测试数据上检查他们的模型,使用你根据实际情况选择的度量标准,并你决定什么水平的性能是足够的。(你自己尝试一个简单的基线也是个好主意,这样你就知道一个真正简单的模型能够实现什么。通常情况下,你的简单模型的表现会和外部“专家”制作的模型一样好!)
在定义测试集时要有判断力
要很好地定义验证集(以及可能的测试集),有时你需要做的不仅仅是随机抽取原始数据集的一部分。记住:验证和测试集的一个关键特性是它们必须代表你将来看到的新数据。这听起来可能像一个不可能的要求!根据定义,你还没有看到这些数据。但通常你仍然会知道一些事情。
看一些例子是很有启发性的。这些例子中的许多来自于Kaggle平台上的预测建模竞赛,这是你可能在实践中看到的问题和方法的很好代表。
一个情况可能是当你在查看时间序列数据时。对于时间序列,选择数据的随机子集既太容易(你可以查看你试图预测的日期之前和之后的数据),又不代表大多数业务用例(在这些用例中,你使用历史数据构建模型以供将来使用)。如果你的数据包含日期,并且你正在构建一个将来使用的模型,你将希望选择最新日期的连续部分作为验证集(例如,可用数据的最后两周或最后一个月)。
假设你想将图 1-19 中的时间序列数据分成训练集和验证集。
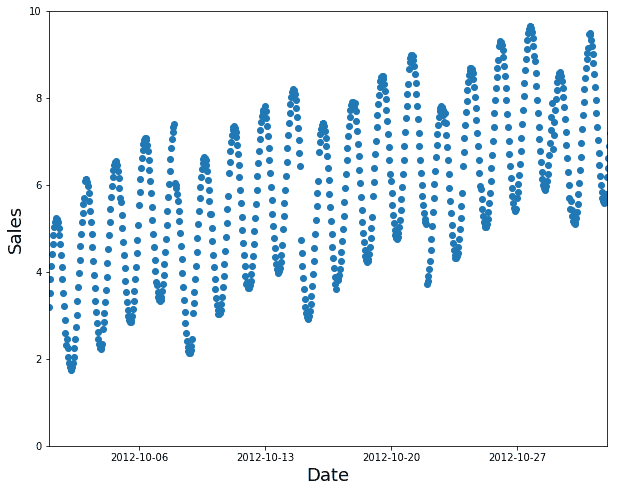
图 1-19. 一个时间序列
一个随机子集是一个糟糕的选择(填补缺失太容易,且不代表你在生产中所需的),正如我们在图 1-20 中所看到的。
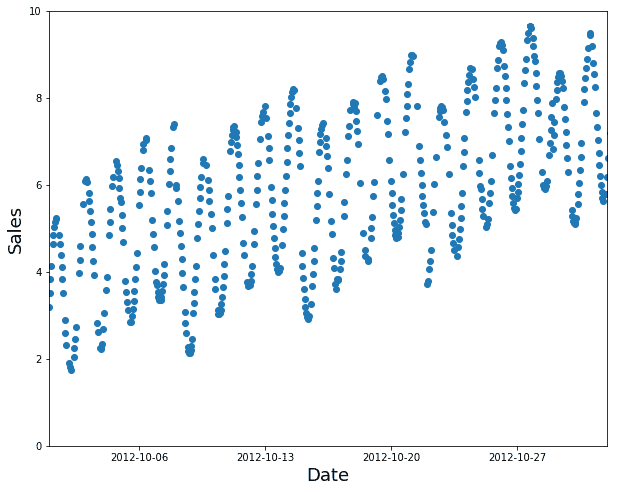
图 1-20. 一个糟糕的训练子集
相反,使用早期数据作为训练集(以及后期数据作为验证集),如图 1-21 所示。

图 1-21. 一个好的训练子集
例如,Kaggle 曾举办一场竞赛,要求预测厄瓜多尔杂货店连锁店的销售额。 Kaggle 的训练数据从 2013 年 1 月 1 日到 2017 年 8 月 15 日,测试数据跨越了 2017 年 8 月 16 日到 2017 年 8 月 31 日。这样,竞赛组织者确保参赛者在未来时间段进行预测,从他们模型的角度来看。这类似于量化对冲基金交易员进行回测,以检查他们的模型是否能够根据过去的数据预测未来的时间段。
第二种常见情况是,当你可以很容易地预见到你将用来训练模型的数据与你将在生产中进行预测的数据可能在质量上有所不同时。
在 Kaggle 分心司机比赛中,自变量是司机在车轮上的照片,因变量是文本、吃东西或安全地向前看等类别。很多照片是同一司机在不同位置的照片,正如我们在图 1-22 中所看到的。如果你是一家保险公司根据这些数据构建模型,注意你最感兴趣的是模型在未见过的司机身上的表现(因为你可能只有一小部分人的训练数据)。为此,比赛的测试数据包括那些在训练集中没有出现的人的图像。

图 1-22. 训练数据中的两张图片
如果你将图 1-22 中的一张图片放入训练集,另一张放入验证集,你的模型将更容易预测验证集中的那张图片,因此它看起来表现得比在新人身上更好。另一个角度是,如果你在训练模型时使用了所有人,你的模型可能会过度拟合这些特定人的特点,而不仅仅是学习状态(发短信、吃东西等)。
在Kaggle 渔业比赛中,也存在类似的动态,目的是识别渔船捕捞的鱼类物种,以减少对濒临灭绝种群的非法捕捞。测试集包括来自训练数据中没有出现的船只的图像,因此在这种情况下,你希望你的验证集也包括训练集中没有的船只。
有时可能不清楚你的验证数据会有什么不同。例如,对于使用卫星图像的问题,你需要收集更多信息,了解训练集是否只包含某些地理位置或来自地理分散的数据。
现在你已经尝试了如何构建模型,你可以决定接下来想深入研究什么。
一个选择你自己的冒险时刻
如果你想了解如何在实践中使用深度学习模型,包括如何识别和修复错误、创建一个真正的工作网络应用程序,并避免你的模型对你的组织或社会造成意外伤害,那么请继续阅读接下来的两章。如果你想开始学习深度学习在幕后是如何工作的基础知识,请跳到第四章。(你小时候有读过选择你自己的冒险系列书吗?嗯,这有点像那个……只不过比那本书系列包含更多的深度学习。)
你需要阅读所有这些章节才能在书中进一步前进,但你阅读它们的顺序完全取决于你。它们不相互依赖。如果你跳到第四章,我们会在最后提醒你回来阅读你跳过的章节,然后再继续前进。
问卷调查
阅读了一页又一页的散文之后,很难知道你真正需要专注和记住的关键事项。因此,我们准备了一份问题列表和建议的步骤清单,供你在每章末完成。所有答案都在章节的文本中,所以如果你对这里的任何事情不确定,重新阅读文本的那部分,并确保你理解了它。所有这些问题的答案也可以在书的网站上找到。如果你遇到困难,也可以访问论坛寻求其他学习这些材料的人的帮助。
-
你需要这些来进行深度学习吗?
-
很多数学 T/F
-
很多数据 T/F
-
很多昂贵的电脑 T/F
-
一个博士学位 T/F
-
-
列出深度学习现在是世界上最好的工具的五个领域。
-
第一个基于人工神经元原理的设备的名称是什么?
-
根据同名书籍,分布式并行处理(PDP)的要求是什么?
-
是什么两个理论误解阻碍了神经网络领域的发展?
-
什么是 GPU?
-
打开一个笔记本并执行包含:
1+1的单元格。会发生什么? -
跟随本章笔记本的精简版本中的每个单元格。在执行每个单元格之前,猜测会发生什么。
-
完成Jupyter Notebook 在线附录。
-
为什么使用传统计算机程序来识别照片中的图像很困难?
-
塞缪尔所说的“权重分配”是什么意思?
-
在深度学习中,我们通常用什么术语来表示塞缪尔所说的“权重”?
-
画一幅总结塞缪尔对机器学习模型看法的图片。
-
为什么很难理解深度学习模型为什么会做出特定的预测?
-
展示了一个定理的名称,该定理表明神经网络可以解决任何数学问题并达到任何精度水平是什么?
-
为了训练模型,您需要什么?
-
反馈循环如何影响预测性警务模型的推出?
-
我们在猫识别模型中总是需要使用 224×224 像素的图像吗?
-
分类和回归之间有什么区别?
-
什么是验证集?什么是测试集?为什么我们需要它们?
-
如果不提供验证集,fastai 会怎么做?
-
我们总是可以使用随机样本作为验证集吗?为什么或为什么不?
-
什么是过拟合?举个例子。
-
什么是度量?它与损失有什么不同?
-
预训练模型如何帮助?
-
模型的“头”是什么?
-
CNN 的早期层找到了什么样的特征?后期层呢?
-
图像模型仅对照片有用吗?
-
什么是架构?
-
什么是分割?
-
y_range用于什么?什么时候需要它? -
什么是超参数?
-
在组织中使用 AI 时避免失败的最佳方法是什么?
进一步研究
每章还有一个“进一步研究”部分,提出了一些在文本中没有完全回答的问题,或者给出了更高级的任务。这些问题的答案不在书的网站上;您需要自己进行研究!
-
为什么 GPU 对深度学习有用?CPU 有什么不同之处,为什么对深度学习效果不佳?
-
试着想出三个反馈循环可能影响机器学习使用的领域。看看是否能找到实践中发生这种情况的文档示例。
第二章:从模型到生产
原文:
www.bookstack.cn/read/th-fastai-book/fc07273d062b4173.md译者:飞龙
协议:CC BY-NC-SA 4.0
我们在第一章中看到的六行代码只是在实践中使用深度学习过程的一小部分。在本章中,我们将使用一个计算机视觉示例来查看创建深度学习应用的端到端过程。更具体地说,我们将构建一个熊分类器!在这个过程中,我们将讨论深度学习的能力和限制,探讨如何创建数据集,在实践中使用深度学习时可能遇到的问题等等。许多关键点同样适用于其他深度学习问题,例如第一章中的问题。如果您解决的问题在关键方面类似于我们的示例问题,我们期望您可以快速获得极好的结果,而只需很少的代码。
让我们从如何构建您的问题开始。
深度学习的实践
我们已经看到深度学习可以快速解决许多具有挑战性的问题,并且只需很少的代码。作为初学者,有一些问题与我们的示例问题足够相似,以便您可以非常快速地获得极其有用的结果。然而,深度学习并不是魔法!同样的六行代码不会适用于今天任何人可以想到的每个问题。
低估深度学习的限制并高估其能力可能导致令人沮丧的糟糕结果,至少在您获得一些经验并能解决出现的问题之前。相反,高估深度学习的限制并低估其能力可能意味着您不会尝试可解决的问题,因为您自己否定了它。
我们经常与低估深度学习的限制和能力的人交谈。这两者都可能是问题:低估能力意味着您可能甚至不会尝试可能非常有益的事情,而低估限制可能意味着您未能考虑和应对重要问题。
最好的做法是保持开放的心态。如果您对深度学习可能以比您预期的更少的数据或复杂性解决部分问题持开放态度,您可以设计一个过程,通过该过程您可以找到与您特定问题相关的特定能力和限制。这并不意味着进行任何冒险的赌注-我们将向您展示如何逐渐推出模型,以便它们不会带来重大风险,并且甚至可以在投入生产之前对其进行回测。
开始您的项目
那么您应该从哪里开始深度学习之旅呢?最重要的是确保您有一个要处理的项目-只有通过处理自己的项目,您才能获得构建和使用模型的真实经验。在选择项目时,最重要的考虑因素是数据的可用性。
无论您是为了自己的学习还是为了在组织中的实际应用而进行项目,您都希望能够快速开始。我们看到许多学生、研究人员和行业从业者在试图找到他们完美的数据集时浪费了几个月甚至几年的时间。目标不是找到“完美”的数据集或项目,而只是开始并从那里迭代。如果您采取这种方法,您将在完美主义者仍处于规划阶段时进行第三次迭代学习和改进!
我们还建议您在项目中端到端迭代;不要花几个月来微调您的模型,或打磨完美的 GUI,或标记完美的数据集……相反,尽可能在合理的时间内完成每一步,一直到最后。例如,如果您的最终目标是一个在手机上运行的应用程序,那么每次迭代后您都应该拥有这个。但也许在早期迭代中您会采取捷径;例如,在远程服务器上进行所有处理,并使用简单的响应式 Web 应用程序。通过完成项目的端到端,您将看到最棘手的部分在哪里,以及哪些部分对最终结果产生最大影响。
当您阅读本书时,我们建议您完成许多小实验,通过运行和调整我们提供的笔记本,同时逐渐开发自己的项目。这样,您将获得所有我们解释的工具和技术的经验,同时我们讨论它们。
Sylvain 说
为了充分利用这本书,花时间在每一章之间进行实验,无论是在您自己的项目上还是通过探索我们提供的笔记本。然后尝试在新数据集上从头开始重写这些笔记本。只有通过大量练习(和失败),您才能培养出如何训练模型的直觉。
通过使用端到端迭代方法,您还将更好地了解您实际需要多少数据。例如,您可能会发现您只能轻松获得 200 个标记数据项,而在尝试之前,您无法真正知道这是否足以使您的应用在实践中良好运行。
在组织环境中,您可以通过展示一个真实的工作原型来向同事展示您的想法是可行的。我们反复观察到,这是获得项目良好组织支持的秘诀。
由于最容易开始的项目是您已经有数据可用的项目,这意味着最容易开始的项目可能与您已经在做的事情相关,因为您已经有关于您正在做的事情的数据。例如,如果您在音乐行业工作,您可能可以访问许多录音。如果您是放射科医生,您可能可以访问大量医学图像。如果您对野生动物保护感兴趣,您可能可以访问大量野生动物图像。
有时您必须有点创造性。也许您可以找到一个先前的机器学习项目,比如一个与您感兴趣的领域相关的 Kaggle 竞赛。有时您必须做出妥协。也许您找不到您所需的确切数据来完成您心中的项目;但您可能会找到一些来自类似领域的数据,或者以不同方式测量的数据,解决一个略有不同的问题。在这些类似项目上工作仍然会让您对整个过程有很好的理解,并可能帮助您识别其他捷径、数据来源等。
特别是当您刚开始学习深度学习时,最好不要涉足非常不同的领域,不要涉足深度学习之前未应用的领域。因为如果您的模型一开始就不起作用,您将不知道是因为您犯了错误,还是您试图解决的问题根本无法用深度学习解决。您也不知道从哪里寻求帮助。因此,最好首先找到在线的一个例子,该例子已经取得了良好的结果,并且至少与您尝试实现的目标有些相似,通过将您的数据转换为其他人以前使用过的格式(例如从您的数据创建图像)。让我们看看深度学习的现状,这样您就知道深度学习目前擅长的领域。
深度学习的现状
让我们首先考虑深度学习是否能够解决您要解决的问题。本节概述了 2020 年初深度学习的现状。然而,事情发展得非常快,当您阅读本文时,其中一些限制可能已经不存在。我们将尽力保持本书网站的最新信息;此外,搜索“AI 现在能做什么”可能会提供当前信息。
计算机视觉
深度学习尚未用于分析图像的许多领域,但在已经尝试过的领域中,几乎普遍表明计算机可以至少与人类一样好地识别图像中的物品,甚至是经过专门训练的人,如放射科医生。这被称为物体识别。深度学习还擅长识别图像中物体的位置,并可以突出它们的位置并命名每个找到的物体。这被称为物体检测(在我们在第一章中看到的变体中,每个像素根据其所属的对象类型进行分类—这被称为分割)。
深度学习算法通常不擅长识别结构或风格与用于训练模型的图像明显不同的图像。例如,如果训练数据中没有黑白图像,模型可能在黑白图像上表现不佳。同样,如果训练数据不包含手绘图像,模型可能在手绘图像上表现不佳。没有一般方法可以检查训练集中缺少哪些类型的图像,但我们将在本章中展示一些方法,以尝试识别当模型在生产中使用时数据中出现意外图像类型的情况(这被称为检查域外数据)。
物体检测系统面临的一个主要挑战是图像标记可能会很慢且昂贵。目前有很多工作正在进行中,旨在开发工具以尝试使这种标记更快速、更容易,并且需要更少的手工标签来训练准确的物体检测模型。一个特别有帮助的方法是合成生成输入图像的变化,例如通过旋转它们或改变它们的亮度和对比度;这被称为数据增强,并且对文本和其他类型的模型也很有效。我们将在本章中详细讨论这一点。
另一个要考虑的问题是,尽管您的问题可能看起来不像是一个计算机视觉问题,但通过一点想象力可能可以将其转变为一个。例如,如果您要分类的是声音,您可以尝试将声音转换为其声学波形的图像,然后在这些图像上训练模型。
自然语言处理
计算机擅长基于类别对短文档和长文档进行分类,例如垃圾邮件或非垃圾邮件、情感(例如,评论是积极的还是消极的)、作者、来源网站等。我们不知道在这个领域是否有任何严格的工作来比较计算机和人类,但从经验上看,我们认为深度学习的性能在这些任务上与人类的性能相似。
深度学习还擅长生成与上下文相关的文本,例如回复社交媒体帖子,并模仿特定作者的风格。它还擅长使这些内容对人类具有吸引力—事实上,甚至比人类生成的文本更具吸引力。然而,深度学习不擅长生成正确的回应!例如,我们没有可靠的方法来将医学信息知识库与深度学习模型结合起来,以生成医学上正确的自然语言回应。这是危险的,因为很容易创建对外行人看来具有吸引力但实际上完全不正确的内容。
另一个问题是,社交媒体上的上下文适当、高度引人入胜的回应可能被大规模使用——比以前见过的任何喷子农场规模大几千倍——来传播虚假信息,制造动荡,鼓励冲突。一般来说,文本生成模型总是在技术上略领先于识别自动生成文本的模型。例如,可以使用一个能够识别人工生成内容的模型来实际改进创建该内容的生成器,直到分类模型无法完成其任务为止。
尽管存在这些问题,深度学习在自然语言处理中有许多应用:可以用来将文本从一种语言翻译成另一种语言,将长篇文档总结为更快消化的内容,找到感兴趣概念的所有提及等。不幸的是,翻译或总结可能包含完全错误的信息!然而,性能已经足够好,许多人正在使用这些系统——例如,谷歌的在线翻译系统(以及我们所知道的每个其他在线服务)都是基于深度学习的。
结合文本和图像
深度学习将文本和图像结合成一个单一模型的能力通常比大多数人直觉期望的要好得多。例如,一个深度学习模型可以在输入图像上进行训练,输出用英语编写的标题,并且可以学会为新图像自动生成令人惊讶地适当的标题!但是,我们再次提出与前一节讨论的相同警告:不能保证这些标题是正确的。
由于这个严重问题,我们通常建议深度学习不要作为完全自动化的过程,而是作为模型和人类用户密切互动的过程的一部分。这可能使人类的生产力比完全手动方法高出几个数量级,并且比仅使用人类更准确。
例如,自动系统可以直接从 CT 扫描中识别潜在的中风患者,并发送高优先级警报,以便快速查看这些扫描。治疗中风只有三个小时的时间窗口,因此这种快速的反馈循环可以挽救生命。同时,所有扫描仍然可以按照通常的方式发送给放射科医生,因此不会减少人类的参与。其他深度学习模型可以自动测量扫描中看到的物品,并将这些测量结果插入报告中,警告放射科医生可能错过的发现,并告诉他们可能相关的其他病例。
表格数据
对于分析时间序列和表格数据,深度学习最近取得了巨大进展。然而,深度学习通常作为多种模型集成的一部分使用。如果您已经有一个正在使用随机森林或梯度提升机(流行的表格建模工具,您很快将了解)的系统,那么切换到或添加深度学习可能不会带来任何显著的改进。
深度学习确实大大增加了您可以包含的列的种类——例如,包含自然语言(书名、评论等)和高基数分类列(即包含大量离散选择的内容,如邮政编码或产品 ID)。不过,与随机森林或梯度提升机相比,深度学习模型通常需要更长的训练时间,尽管由于提供 GPU 加速的库(如RAPIDS),情况正在改变。我们在第九章中详细介绍了所有这些方法的优缺点。
推荐系统
推荐系统实际上只是一种特殊类型的表格数据。特别是,它们通常具有代表用户的高基数分类变量,以及代表产品(或类似物品)的另一个变量。像亚马逊这样的公司将客户所做的每一次购买都表示为一个巨大的稀疏矩阵,其中客户是行,产品是列。一旦他们以这种格式拥有数据,数据科学家们会应用某种形式的协同过滤来填充矩阵。例如,如果客户 A 购买产品 1 和 10,客户 B 购买产品 1、2、4 和 10,引擎将推荐 A 购买 2 和 4。
由于深度学习模型擅长处理高基数分类变量,它们非常擅长处理推荐系统。尤其是当将这些变量与其他类型的数据(如自然语言或图像)结合时,它们就像处理表格数据一样发挥作用。它们还可以很好地将所有这些类型的信息与其他元数据(如用户信息、先前交易等)表示为表格进行组合。
然而,几乎所有的机器学习方法都有一个缺点,那就是它们只告诉你一个特定用户可能喜欢哪些产品,而不是对用户有用的推荐。用户可能喜欢的产品的许多种推荐可能根本不会有任何帮助——例如,如果用户已经熟悉这些产品,或者如果它们只是用户已经购买过的产品的不同包装(例如,当他们已经拥有该套装中的每一件物品时,推荐一个小说的套装)。Jeremy 喜欢读特里·普拉切特的书,有一段时间亚马逊一直在向他推荐特里·普拉切特的书(见图 2-1),这实际上并不是有用的,因为他已经知道这些书了!

图 2-1. 一个不太有用的推荐
其他数据类型
通常,您会发现特定领域的数据类型非常适合现有的类别。例如,蛋白质链看起来很像自然语言文档,因为它们是由复杂关系和意义贯穿整个序列的离散令牌组成的长序列。事实上,使用 NLP 深度学习方法是许多类型蛋白质分析的最先进方法。另一个例子,声音可以表示为频谱图,可以被视为图像;标准的图像深度学习方法在频谱图上表现得非常好。
驱动系统方法
许多准确的模型对任何人都没有用,而许多不准确的模型却非常有用。为了确保您的建模工作在实践中有用,您需要考虑您的工作将如何使用。2012 年,Jeremy 与 Margit Zwemer 和 Mike Loukides 一起提出了一种称为驱动系统方法的思考这个问题的方法。
驱动系统方法,如图 2-2 所示,详细介绍在“设计出色的数据产品”中。基本思想是从考虑您的目标开始,然后考虑您可以采取哪些行动来实现该目标以及您拥有的(或可以获取的)可以帮助的数据,然后构建一个模型,您可以使用该模型确定为实现目标而采取的最佳行动。
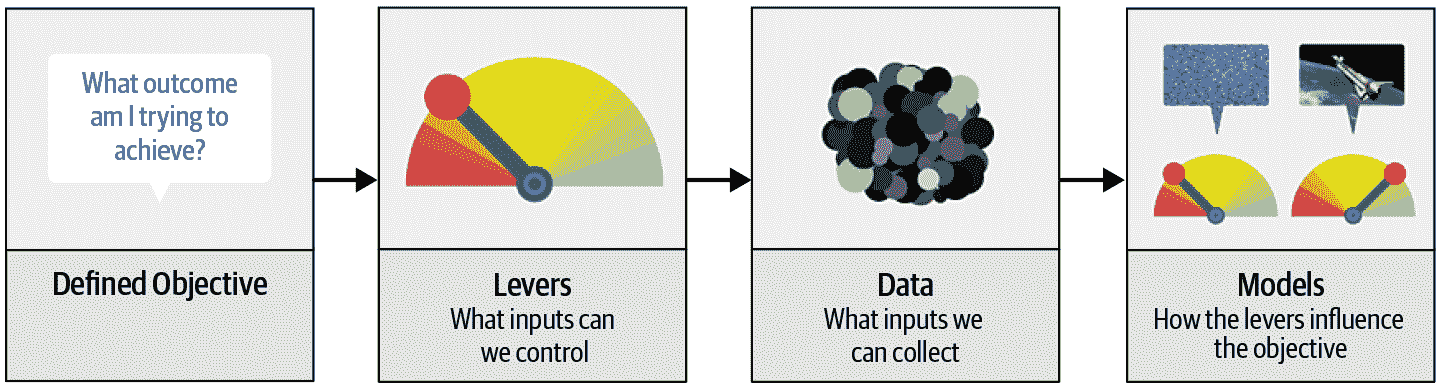
图 2-2. 驱动系统方法
考虑自动驾驶汽车中的模型:您希望帮助汽车安全地从 A 点驾驶到 B 点,而无需人为干预。出色的预测建模是解决方案的重要组成部分,但它并不是独立存在的;随着产品变得更加复杂,它会消失在管道中。使用自动驾驶汽车的人完全不知道使其运行的数百(甚至数千)个模型和海量数据。但随着数据科学家构建越来越复杂的产品,他们需要一种系统化的设计方法。
我们使用数据不仅仅是为了生成更多数据(以预测的形式),而是为了产生可操作的结果。这是 Drivetrain 方法的目标。首先要明确定义一个明确的目标。例如,当谷歌创建其第一个搜索引擎时,考虑了“用户在输入搜索查询时的主要目标是什么?”这导致了谷歌的目标,即“显示最相关的搜索结果”。下一步是考虑您可以拉动的杠杆(即您可以采取的行动)以更好地实现该目标。在谷歌的情况下,这是搜索结果的排名。第三步是考虑他们需要什么新数据来生成这样的排名;他们意识到关于哪些页面链接到哪些其他页面的隐含信息可以用于此目的。
只有在完成了这前三个步骤之后,我们才开始考虑构建预测模型。我们的目标和可用的杠杆,我们已经拥有的数据以及我们需要收集的额外数据,决定了我们可以构建的模型。这些模型将以杠杆和任何不可控变量作为输入;模型的输出可以结合起来预测我们的目标的最终状态。
让我们考虑另一个例子:推荐系统。推荐引擎的目标是通过推荐客户不会在没有推荐的情况下购买的物品来推动额外的销售。杠杆是推荐的排名。必须收集新数据以生成将导致新销售的推荐。这将需要进行许多随机实验,以收集关于各种客户的各种推荐的数据。这是很少有组织采取的一步;但是没有它,您就没有所需的信息来根据您的真正目标(更多销售!)优化推荐。
最后,您可以为购买概率构建两个模型,条件是看到或没有看到推荐。这两个概率之间的差异是给定推荐给客户的效用函数。在算法推荐客户已经拒绝的熟悉书籍(两个组成部分都很小)或者他们本来就会购买的书籍(两个组成部分都很大并互相抵消)的情况下,效用函数会很低。
正如您所看到的,在实践中,您的模型的实际实施通常需要比仅仅训练一个模型更多!您通常需要运行实验来收集更多数据,并考虑如何将您的模型整合到您正在开发的整个系统中。说到数据,现在让我们专注于如何为您的项目找到数据。
收集数据
对于许多类型的项目,您可能能够在线找到所需的所有数据。本章中我们将完成的项目是一个“熊探测器”。它将区分三种类型的熊:灰熊、黑熊和泰迪熊。互联网上有许多每种类型熊的图片可供我们使用。我们只需要找到它们并下载它们。
我们提供了一个工具供您使用,这样您就可以跟随本章并为您感兴趣的任何对象创建自己的图像识别应用程序。在 fast.ai 课程中,成千上万的学生在课程论坛上展示了他们的作品,展示了从特立尼达的蜂鸟品种到巴拿马的公交车类型的一切——甚至有一名学生创建了一个应用程序,可以帮助他的未婚妻在圣诞假期期间认出他的 16 个表兄弟!
在撰写本文时,Bing 图像搜索是我们知道的用于查找和下载图像的最佳选择。每月免费提供最多 1,000 次查询,每次查询可下载最多 150 张图片。然而,在我们撰写本书时和您阅读本书时之间可能会出现更好的选择,因此请务必查看本书籍网站以获取我们当前的推荐。
与最新服务保持联系
用于创建数据集的服务时常变化,它们的功能、接口和定价也经常变化。在本节中,我们将展示如何在撰写本书时作为 Azure 认知服务一部分提供的Bing 图像搜索 API。
要使用 Bing 图像搜索下载图像,请在 Microsoft 注册一个免费帐户。您将获得一个密钥,您可以将其复制并输入到一个单元格中(用您的密钥替换*XXX*并执行):
key = 'XXX'
或者,如果您在命令行上感到自在,您可以在终端中设置它
export AZURE_SEARCH_KEY=*your_key_here*
然后重新启动 Jupyter 服务器,在一个单元格中键入以下内容,并执行:
key = os.environ['AZURE_SEARCH_KEY']
设置了key之后,您可以使用search_images_bing。这个函数是在线笔记本中包含的小utils类提供的(如果您不确定一个函数是在哪里定义的,您可以在笔记本中输入它来找出,如下所示):
search_images_bing
<function utils.search_images_bing(key, term, min_sz=128)>
让我们尝试一下这个函数:
results = search_images_bing(key, 'grizzly bear')
ims = results.attrgot('content_url')
len(ims)
150
我们已成功下载了 150 只灰熊的 URL(或者至少是 Bing 图像搜索为该搜索词找到的图像)。让我们看一个:
dest = 'images/grizzly.jpg'
download_url(ims[0], dest)
im = Image.open(dest)
im.to_thumb(128,128)

这似乎运行得很好,所以让我们使用 fastai 的download_images来下载每个搜索词的所有 URL。我们将每个放在一个单独的文件夹中:
bear_types = 'grizzly','black','teddy'
path = Path('bears')
if not path.exists():path.mkdir()for o in bear_types:dest = (path/o)dest.mkdir(exist_ok=True)results = search_images_bing(key, f'{o} bear')download_images(dest, urls=results.attrgot('content_url'))
我们的文件夹中有图像文件,正如我们所期望的那样:
fns = get_image_files(path)
fns
(#421) [Path('bears/black/00000095.jpg'),Path('bears/black/00000133.jpg'),Path('> bears/black/00000062.jpg'),Path('bears/black/00000023.jpg'),Path('bears/black> /00000029.jpg'),Path('bears/black/00000094.jpg'),Path('bears/black/00000124.j> pg'),Path('bears/black/00000056.jpeg'),Path('bears/black/00000046.jpg'),Path(> 'bears/black/00000045.jpg')...]
Jeremy 说
我就是喜欢在 Jupyter 笔记本中工作的这一点!逐步构建我想要的东西并在每一步检查我的工作是如此容易。我犯了很多错误,所以这对我真的很有帮助。
通常当我们从互联网下载文件时,会有一些文件损坏。让我们检查一下:
failed = verify_images(fns)
failed
(#0) []
要删除所有失败的图像,您可以使用unlink。像大多数返回集合的 fastai 函数一样,verify_images返回一个类型为L的对象,其中包括map方法。这会在集合的每个元素上调用传递的函数:
failed.map(Path.unlink);
在这个过程中要注意的一件事是:正如我们在第一章中讨论的,模型只能反映用于训练它们的数据。而世界充满了有偏见的数据,这最终会反映在,例如,Bing 图像搜索(我们用来创建数据集的)。例如,假设您有兴趣创建一个应用程序,可以帮助用户确定他们是否拥有健康的皮肤,因此您训练了一个模型,该模型基于搜索结果(比如)“健康皮肤”。图 2-3 展示了您将获得的结果类型。

图 2-3. 用于健康皮肤检测器的数据?
使用此作为训练数据,您最终不会得到一个健康皮肤检测器,而是一个年轻白人女性触摸她的脸检测器!一定要仔细考虑您可能在应用程序中实际看到的数据类型,并仔细检查以确保所有这些类型都反映在您模型的源数据中。(感谢 Deb Raji 提出了健康皮肤的例子。请查看她的论文“可操作的审计:调查公开命名商业 AI 产品偏见性能结果的影响”以获取更多有关模型偏见的迷人见解。)
现在我们已经下载了一些数据,我们需要将其组装成适合模型训练的格式。在 fastai 中,这意味着创建一个名为DataLoaders的对象。
从数据到数据加载器
DataLoaders是一个简单的类,只是存储您传递给它的DataLoader对象,并将它们作为train和valid可用。尽管它是一个简单的类,但在 fastai 中非常重要:它为您的模型提供数据。DataLoaders中的关键功能仅用这四行代码提供(它还有一些其他次要功能我们暂时跳过):
class DataLoaders(GetAttr):def __init__(self, *loaders): self.loaders = loadersdef __getitem__(self, i): return self.loaders[i]train,valid = add_props(lambda i,self: self[i])
术语:DataLoaders
一个 fastai 类,存储您传递给它的多个DataLoader对象——通常是一个train和一个valid,尽管可以有任意数量。前两个作为属性提供。
在本书的后面,您还将了解Dataset和Datasets类,它们具有相同的关系。要将我们下载的数据转换为DataLoaders对象,我们至少需要告诉 fastai 四件事:
-
我们正在处理什么类型的数据
-
如何获取项目列表
-
如何为这些项目打标签
-
如何创建验证集
到目前为止,我们已经看到了一些特定组合的工厂方法,当您有一个应用程序和数据结构恰好适合这些预定义方法时,这些方法非常方便。当您不适用时,fastai 有一个名为数据块 API的极其灵活的系统。使用此 API,您可以完全自定义创建DataLoaders的每个阶段。这是我们需要为刚刚下载的数据集创建DataLoaders的步骤:
bears = DataBlock(blocks=(ImageBlock, CategoryBlock),get_items=get_image_files,splitter=RandomSplitter(valid_pct=0.2, seed=42),get_y=parent_label,item_tfms=Resize(128))
让我们依次查看每个参数。首先,我们提供一个元组,指定我们希望独立变量和因变量的类型:
blocks=(ImageBlock, CategoryBlock)
独立变量是我们用来进行预测的东西,因变量是我们的目标。在这种情况下,我们的独立变量是一组图像,我们的因变量是每个图像的类别(熊的类型)。在本书的其余部分中,我们将看到许多其他类型的块。
对于这个DataLoaders,我们的基础项目将是文件路径。我们必须告诉 fastai 如何获取这些文件的列表。get_image_files函数接受一个路径,并返回该路径中所有图像的列表(默认情况下递归):
get_items=get_image_files
通常,您下载的数据集已经定义了验证集。有时,这是通过将用于训练和验证集的图像放入不同的文件夹中来完成的。有时,这是通过提供一个 CSV 文件,在该文件中,每个文件名都与应该在其中的数据集一起列出。有许多可以完成此操作的方法,fastai 提供了一种通用方法,允许您使用其预定义类之一或编写自己的类。
在这种情况下,我们希望随机拆分我们的训练和验证集。但是,我们希望每次运行此笔记本时都具有相同的训练/验证拆分,因此我们固定随机种子(计算机实际上不知道如何创建随机数,而只是创建看起来随机的数字列表;如果您每次都为该列表提供相同的起始点——称为种子,那么您将每次都获得完全相同的列表)。
splitter=RandomSplitter(valid_pct=0.2, seed=42)
自变量通常被称为x,因变量通常被称为y。在这里,我们告诉 fastai 要调用哪个函数来创建数据集中的标签:
get_y=parent_label
parent_label是 fastai 提供的一个函数,它简单地获取文件所在文件夹的名称。因为我们将每个熊图像放入基于熊类型的文件夹中,这将为我们提供所需的标签。
我们的图像大小各不相同,这对深度学习是一个问题:我们不是一次向模型提供一个图像,而是多个图像(我们称之为mini-batch)。为了将它们分组到一个大数组(通常称为张量)中,以便通过我们的模型,它们都需要是相同的大小。因此,我们需要添加一个转换,将这些图像调整为相同的大小。Item transforms是在每个单独项目上运行的代码片段,无论是图像、类别还是其他。fastai 包含许多预定义的转换;我们在这里使用Resize转换,并指定大小为 128 像素:
item_tfms=Resize(128)
这个命令给了我们一个DataBlock对象。这就像创建DataLoaders的模板。我们仍然需要告诉 fastai 我们数据的实际来源——在这种情况下,图像所在的路径:
dls = bears.dataloaders(path)
DataLoaders包括验证和训练DataLoader。DataLoader是一个类,它一次向 GPU 提供几个项目的批次。我们将在下一章中更多地了解这个类。当您循环遍历DataLoader时,fastai 会一次给您 64 个(默认值)项目,全部堆叠到一个单一张量中。我们可以通过在DataLoader上调用show_batch方法来查看其中一些项目:
dls.valid.show_batch(max_n=4, nrows=1)

默认情况下,Resize会将图像裁剪成适合请求大小的正方形形状,使用完整的宽度或高度。这可能会导致丢失一些重要细节。或者,您可以要求 fastai 用零(黑色)填充图像,或者压缩/拉伸它们:
bears = bears.new(item_tfms=Resize(128, ResizeMethod.Squish))
dls = bears.dataloaders(path)
dls.valid.show_batch(max_n=4, nrows=1)

bears = bears.new(item_tfms=Resize(128, ResizeMethod.Pad, pad_mode='zeros'))
dls = bears.dataloaders(path)
dls.valid.show_batch(max_n=4, nrows=1)

所有这些方法似乎都有些浪费或问题。如果我们压缩或拉伸图像,它们最终会变成不现实的形状,导致模型学习到事物看起来与实际情况不同,这会导致更低的准确性。如果我们裁剪图像,我们会移除一些允许我们进行识别的特征。例如,如果我们试图识别狗或猫的品种,我们可能会裁剪掉区分相似品种所需的身体或面部的关键部分。如果我们填充图像,就会有很多空白空间,这对我们的模型来说只是浪费计算,并导致我们实际使用的图像部分具有较低的有效分辨率。
相反,我们在实践中通常做的是随机选择图像的一部分,然后裁剪到该部分。在每个纪元(即数据集中所有图像的完整遍历),我们随机选择每个图像的不同部分。这意味着我们的模型可以学习关注和识别图像中的不同特征。这也反映了图像在现实世界中的工作方式:同一物体的不同照片可能以略有不同的方式构图。
事实上,一个完全未经训练的神经网络对图像的行为一无所知。它甚至不认识当一个物体旋转一度时,它仍然是同一物体的图片!因此,通过训练神经网络使用物体在略有不同位置并且大小略有不同的图像的示例,有助于它理解物体的基本概念,以及如何在图像中表示它。
这里是另一个示例,我们将Resize替换为RandomResizedCrop,这是提供刚才描述行为的转换。传递的最重要参数是min_scale,它确定每次选择图像的最小部分:
bears = bears.new(item_tfms=RandomResizedCrop(128, min_scale=0.3))
dls = bears.dataloaders(path)
dls.train.show_batch(max_n=4, nrows=1, unique=True)

在这里,我们使用了unique=True,以便将相同图像重复使用不同版本的RandomResizedCrop变换。
RandomResizedCrop是更一般的数据增强技术的一个具体示例。
数据增强
数据增强指的是创建输入数据的随机变化,使它们看起来不同但不改变数据的含义。对于图像的常见数据增强技术包括旋转、翻转、透视变形、亮度变化和对比度变化。对于我们在这里使用的自然照片图像,我们发现一组标准的增强技术与aug_transforms函数一起提供,效果非常好。
因为我们的图像现在都是相同大小,我们可以使用 GPU 将这些增强应用于整个批次的图像,这将节省大量时间。要告诉 fastai 我们要在批次上使用这些变换,我们使用batch_tfms参数(请注意,在此示例中我们没有使用RandomResizedCrop,这样您可以更清楚地看到差异;出于同样的原因,我们使用了默认值的两倍的增强量):
bears = bears.new(item_tfms=Resize(128), batch_tfms=aug_transforms(mult=2))
dls = bears.dataloaders(path)
dls.train.show_batch(max_n=8, nrows=2, unique=True)

现在我们已经将数据组装成适合模型训练的格式,让我们使用它来训练一个图像分类器。
训练您的模型,并使用它来清理您的数据
现在是时候使用与第一章中相同的代码行来训练我们的熊分类器了。对于我们的问题,我们没有太多的数据(每种熊最多 150 张图片),因此为了训练我们的模型,我们将使用RandomResizedCrop,图像大小为 224 像素,这对于图像分类来说是相当标准的,并且使用默认的aug_transforms:
bears = bears.new(item_tfms=RandomResizedCrop(224, min_scale=0.5),batch_tfms=aug_transforms())
dls = bears.dataloaders(path)
现在我们可以按照通常的方式创建我们的Learner并进行微调:
learn = cnn_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(4)
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 1.235733 | 0.212541 | 0.087302 | 00:05 |
| epoch | train_loss | valid_loss | error_rate | time |
| — | — | — | — | — |
| 0 | 0.213371 | 0.112450 | 0.023810 | 00:05 |
| 1 | 0.173855 | 0.072306 | 0.023810 | 00:06 |
| 2 | 0.147096 | 0.039068 | 0.015873 | 00:06 |
| 3 | 0.123984 | 0.026801 | 0.015873 | 00:06 |
现在让我们看看模型犯的错误主要是认为灰熊是泰迪熊(这对安全性来说是不好的!),还是认为灰熊是黑熊,或者其他情况。为了可视化这一点,我们可以创建一个混淆矩阵:
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()

行代表数据集中所有黑色、灰熊和泰迪熊,列分别代表模型预测为黑色、灰熊和泰迪熊的图像。因此,矩阵的对角线显示了被正确分类的图像,而非对角线的单元格代表被错误分类的图像。这是 fastai 允许您查看模型结果的许多方式之一。当然,这是使用验证集计算的。通过颜色编码,目标是在对角线以外的地方都是白色,而在对角线上我们希望是深蓝色。我们的熊分类器几乎没有犯错!
看到我们的错误发生在哪里是有帮助的,以便确定它们是由数据集问题(例如,根本不是熊的图像,或者标记错误)还是模型问题(也许它无法处理使用不同光照或从不同角度拍摄的图像等)。为了做到这一点,我们可以根据损失对图像进行排序。
损失是一个数字,如果模型不正确(尤其是如果它对其不正确的答案也很自信),或者如果它是正确的但对其正确答案不自信,那么损失就会更高。在第二部分的开头,我们将深入学习损失是如何计算和在训练过程中使用的。现在,plot_top_losses向我们展示了数据集中损失最高的图像。正如输出的标题所说,每个图像都标有四个内容:预测、实际(目标标签)、损失和概率。这里的概率是模型对其预测分配的置信水平,从零到一:
interp.plot_top_losses(5, nrows=1)

这个输出显示,损失最高的图像是一个被预测为“灰熊”的图像,且置信度很高。然而,根据我们的必应图像搜索,它被标记为“黑熊”。我们不是熊专家,但在我们看来,这个标签显然是错误的!我们可能应该将其标签更改为“灰熊”。
进行数据清洗的直观方法是在训练模型之前进行。但正如您在本例中所看到的,模型可以帮助您更快速、更轻松地找到数据问题。因此,我们通常更喜欢先训练一个快速简单的模型,然后使用它来帮助我们进行数据清洗。
fastai 包括一个方便的用于数据清洗的 GUI,名为ImageClassifierCleaner,它允许您选择一个类别和训练与验证集,并查看损失最高的图像(按顺序),以及菜单允许选择要删除或重新标记的图像:
cleaner = ImageClassifierCleaner(learn)
cleaner

我们可以看到在我们的“黑熊”中有一张包含两只熊的图片:一只灰熊,一只黑熊。因此,我们应该在此图片下的菜单中选择<Delete>。ImageClassifierCleaner不会为您删除或更改标签;它只会返回要更改的项目的索引。因此,例如,要删除(取消链接)所有选定要删除的图像,我们将运行以下命令:
for idx in cleaner.delete(): cleaner.fns[idx].unlink()
要移动我们选择了不同类别的图像,我们将运行以下命令:
for idx,cat in cleaner.change(): shutil.move(str(cleaner.fns[idx]), path/cat)
Sylvain 说
清理数据并为您的模型做好准备是数据科学家面临的两个最大挑战;他们说这需要他们 90%的时间。fastai 库旨在提供尽可能简单的工具。
在本书中,我们将看到更多基于模型驱动的数据清洗示例。一旦我们清理了数据,我们就可以重新训练我们的模型。自己尝试一下,看看你的准确性是否有所提高!
不需要大数据
通过这些步骤清理数据集后,我们通常在这个任务上看到 100%的准确性。即使我们下载的图像比我们在这里使用的每类 150 张要少得多,我们也能看到这个结果。正如您所看到的,您需要大量数据才能进行深度学习的常见抱怨可能与事实相去甚远!
现在我们已经训练了我们的模型,让我们看看如何部署它以便在实践中使用。
将您的模型转化为在线应用程序
现在我们将看看将这个模型转化为一个可工作的在线应用程序需要什么。我们将只创建一个基本的工作原型;在本书中,我们没有范围来教授您有关 Web 应用程序开发的所有细节。
使用模型进行推断
一旦您拥有一个满意的模型,您需要保存它,以便随后将其复制到一个服务器上,在那里您将在生产中使用它。请记住,模型由两部分组成:架构和训练的参数。保存模型的最简单方法是保存这两部分,因为这样,当您加载模型时,您可以确保具有匹配的架构和参数。要保存这两部分,请使用export方法。
这种方法甚至保存了如何创建您的DataLoaders的定义。这很重要,因为否则您将不得不重新定义如何转换您的数据以便在生产中使用您的模型。fastai 默认使用验证集DataLoader进行推理,因此不会应用数据增强,这通常是您想要的。
当您调用export时,fastai 将保存一个名为export.pkl的文件:
learn.export()
让我们通过使用 fastai 添加到 Python 的Path类的ls方法来检查文件是否存在:
path = Path()
path.ls(file_exts='.pkl')
(#1) [Path('export.pkl')]
您需要这个文件在您部署应用程序的任何地方。现在,让我们尝试在我们的笔记本中创建一个简单的应用程序。
当我们使用模型进行预测而不是训练时,我们称之为推理。要从导出的文件创建我们的推理学习者,我们使用load_learner(在这种情况下,这并不是真正必要的,因为我们已经在笔记本中有一个工作的Learner;我们在这里这样做是为了让您看到整个过程的始终):
learn_inf = load_learner(path/'export.pkl')
在进行推理时,通常一次只为一个图像获取预测。要做到这一点,将文件名传递给predict:
learn_inf.predict('images/grizzly.jpg')
('grizzly', tensor(1), tensor([9.0767e-06, 9.9999e-01, 1.5748e-07]))
这返回了三个东西:以与您最初提供的格式相同的预测类别(在本例中,这是一个字符串),预测类别的索引以及每个类别的概率。最后两个是基于DataLoaders的vocab中类别的顺序;也就是说,所有可能类别的存储列表。在推理时,您可以将DataLoaders作为Learner的属性访问:
learn_inf.dls.vocab
(#3) ['black','grizzly','teddy']
我们可以看到,如果我们使用predict返回的整数索引到 vocab 中,我们会得到“灰熊”,这是预期的。另外,请注意,如果我们在概率列表中进行索引,我们会看到几乎有 1.00 的概率这是一只灰熊。
我们知道如何从保存的模型中进行预测,因此我们拥有开始构建我们的应用程序所需的一切。我们可以直接在 Jupyter 笔记本中完成。
从模型创建一个笔记本应用
要在应用程序中使用我们的模型,我们可以简单地将predict方法视为常规函数。因此,使用任何应用程序开发人员可用的各种框架和技术都可以创建一个从模型创建的应用程序。
然而,大多数数据科学家并不熟悉 Web 应用程序开发领域。因此,让我们尝试使用您目前已经了解的东西:事实证明,我们可以仅使用 Jupyter 笔记本创建一个完整的工作 Web 应用程序!使这一切成为可能的两个因素如下:
-
IPython 小部件(ipywidgets)
-
Voilà
IPython 小部件是 GUI 组件,它在 Web 浏览器中将 JavaScript 和 Python 功能结合在一起,并可以在 Jupyter 笔记本中创建和使用。例如,我们在本章前面看到的图像清理器完全是用 IPython 小部件编写的。但是,我们不希望要求我们的应用程序用户自己运行 Jupyter。
这就是Voilà存在的原因。它是一个使 IPython 小部件应用程序可供最终用户使用的系统,而无需他们使用 Jupyter。Voilà利用了一个事实,即笔记本已经是一种 Web 应用程序,只是另一个复杂的依赖于另一个 Web 应用程序:Jupyter 本身的 Web 应用程序。基本上,它帮助我们自动将我们已经隐式创建的复杂 Web 应用程序(笔记本)转换为一个更简单、更易部署的 Web 应用程序,它的功能类似于普通的 Web 应用程序,而不是笔记本。
但是我们仍然可以在笔记本中开发的优势,因此使用 ipywidgets,我们可以逐步构建我们的 GUI。我们将使用这种方法创建一个简单的图像分类器。首先,我们需要一个文件上传小部件:
btn_upload = widgets.FileUpload()
btn_upload
现在我们可以获取图像:
img = PILImage.create(btn_upload.data[-1])

我们可以使用Output小部件来显示它:
out_pl = widgets.Output()
out_pl.clear_output()
with out_pl: display(img.to_thumb(128,128))
out_pl
然后我们可以得到我们的预测:
pred,pred_idx,probs = learn_inf.predict(img)
并使用Label来显示它们:
lbl_pred = widgets.Label()
lbl_pred.value = f'Prediction: {pred}; Probability: {probs[pred_idx]:.04f}'
lbl_pred
预测:灰熊;概率:1.0000
我们需要一个按钮来进行分类。它看起来与上传按钮完全相同:
btn_run = widgets.Button(description='Classify')
btn_run
我们还需要一个点击事件处理程序;也就是说,当按下按钮时将调用的函数。我们可以简单地复制之前的代码行:
def on_click_classify(change):img = PILImage.create(btn_upload.data[-1])out_pl.clear_output()with out_pl: display(img.to_thumb(128,128))pred,pred_idx,probs = learn_inf.predict(img)lbl_pred.value = f'Prediction: {pred}; Probability: {probs[pred_idx]:.04f}'btn_run.on_click(on_click_classify)
您现在可以通过单击按钮来测试按钮,您应该会看到图像和预测会自动更新!
现在,我们可以将它们全部放在一个垂直框(VBox)中,以完成我们的 GUI:
VBox([widgets.Label('Select your bear!'),btn_upload, btn_run, out_pl, lbl_pred])

我们已经编写了所有必要的应用程序代码。下一步是将其转换为我们可以部署的内容。
将您的笔记本变成一个真正的应用程序
现在我们在这个 Jupyter 笔记本中已经让一切运转起来了,我们可以创建我们的应用程序。为此,请启动一个新的笔记本,并仅添加创建和显示所需小部件的代码,以及任何要显示的文本的 Markdown。查看书中存储库中的bear_classifier笔记本,看看我们创建的简单笔记本应用程序。
接下来,如果您尚未安装 Voilà,请将这些行复制到笔记本单元格中并执行:
!pip install voila
!jupyter serverextension enable voila --sys-prefix
以!开头的单元格不包含 Python 代码,而是包含传递给您的 shell(bash,Windows PowerShell 等)的代码。如果您习惯使用命令行,我们将在本书中更详细地讨论这一点,您当然可以直接在终端中键入这两行(不带!前缀)。在这种情况下,第一行安装voila库和应用程序,第二行将其连接到您现有的 Jupyter 笔记本。
Voilà运行 Jupyter 笔记本,就像您现在使用的 Jupyter 笔记本服务器一样,但它还做了一件非常重要的事情:它删除了所有单元格输入,仅显示输出(包括 ipywidgets),以及您的 Markdown 单元格。因此,剩下的是一个 Web 应用程序!要将您的笔记本视为 Voilà Web 应用程序,请将浏览器 URL 中的“notebooks”一词替换为“voila/render”。您将看到与您的笔记本相同的内容,但没有任何代码单元格。
当然,您不需要使用 Voilà或 ipywidgets。您的模型只是一个可以调用的函数(pred,pred_idx,probs = learn.predict(img)),因此您可以将其与任何框架一起使用,托管在任何平台上。您可以将在 ipywidgets 和 Voilà中原型设计的内容稍后转换为常规 Web 应用程序。我们在本书中展示这种方法,因为我们认为这是数据科学家和其他不是 Web 开发专家的人从其模型创建应用程序的绝佳方式。
我们有了我们的应用程序;现在让我们部署它!
部署您的应用程序
正如您现在所知,几乎任何有用的深度学习模型都需要 GPU 来训练。那么,在生产中使用该模型需要 GPU 吗?不需要!您几乎可以肯定在生产中不需要 GPU 来提供您的模型。这样做有几个原因:
-
正如我们所见,GPU 仅在并行执行大量相同工作时才有用。如果您正在进行(比如)图像分类,通常一次只会对一个用户的图像进行分类,而且通常在一张图像中没有足够的工作量可以让 GPU 忙碌足够长的时间以使其非常有效。因此,CPU 通常更具成本效益。
-
另一种选择可能是等待一些用户提交他们的图像,然后将它们批量处理并一次性在 GPU 上处理。但是这样会让用户等待,而不是立即得到答案!而且您需要一个高流量的网站才能实现这一点。如果您确实需要这种功能,您可以使用诸如 Microsoft 的ONNX Runtime或AWS SageMaker之类的工具。
-
处理 GPU 推理的复杂性很大。特别是,GPU 的内存需要仔细手动管理,您需要一个仔细的排队系统,以确保一次只处理一个批次。
-
CPU 服务器的市场竞争要比 GPU 服务器更激烈,因此 CPU 服务器有更便宜的选项可供选择。
由于 GPU 服务的复杂性,许多系统已经出现尝试自动化此过程。然而,管理和运行这些系统也很复杂,通常需要将您的模型编译成专门针对该系统的不同形式。通常最好避免处理这种复杂性,直到/除非您的应用程序变得足够受欢迎,以至于您有明显的财务理由这样做。
至少对于您的应用程序的初始原型以及您想展示的任何爱好项目,您可以轻松免费托管它们。最佳位置和最佳方式随时间而变化,因此请查看本书网站以获取最新的建议。由于我们在 2020 年初撰写本书,最简单(且免费!)的方法是使用Binder。要在 Binder 上发布您的 Web 应用程序,请按照以下步骤操作:
-
将您的笔记本添加到GitHub 存储库。
-
将该存储库的 URL 粘贴到 Binder 的 URL 字段中,如图 2-4 所示。
-
将文件下拉菜单更改为选择 URL。
-
在“要打开的 URL”字段中,输入
/voila/render/*name*.ipynb(将*name*替换为您笔记本的名称)。 -
单击右下角的剪贴板按钮以复制 URL,并将其粘贴到安全位置。
-
单击“启动”。
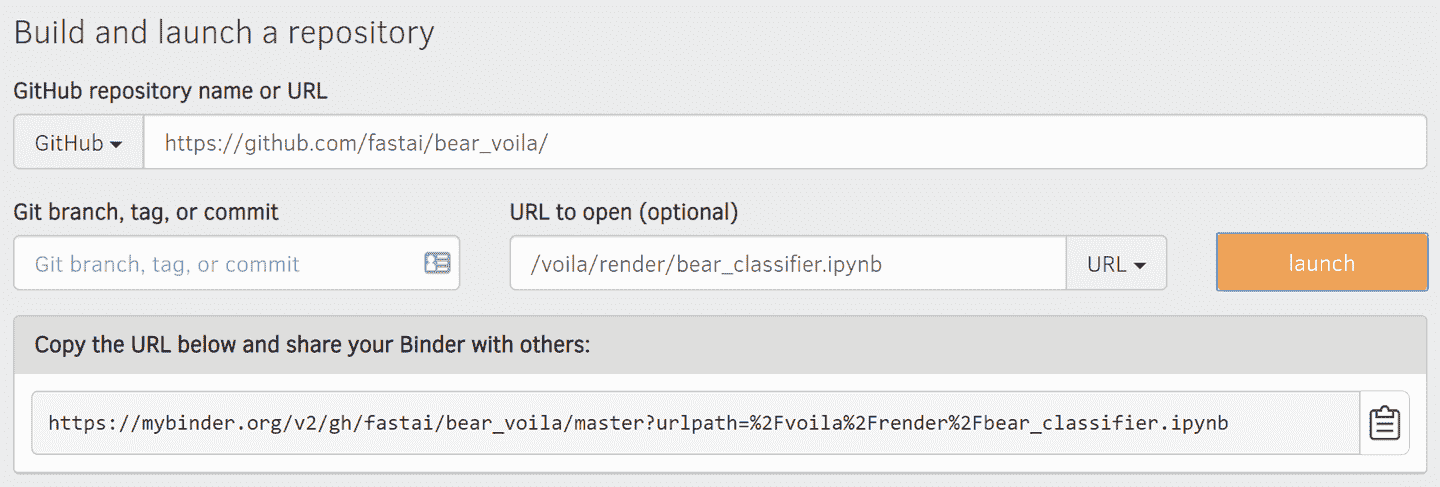
图 2-4. 部署到 Binder
第一次执行此操作时,Binder 将花费大约 5 分钟来构建您的站点。在幕后,它正在查找一个可以运行您的应用程序的虚拟机,分配存储空间,并收集所需的文件以用于 Jupyter、您的笔记本以及将您的笔记本呈现为 Web 应用程序。
最后,一旦启动应用程序运行,它将导航您的浏览器到您的新 Web 应用程序。您可以分享您复制的 URL 以允许其他人访问您的应用程序。
要了解部署 Web 应用程序的其他(免费和付费)选项,请务必查看书籍网站。
您可能希望将应用程序部署到移动设备或边缘设备,如树莓派。有许多库和框架允许您将模型直接集成到移动应用程序中。但是,这些方法往往需要许多额外的步骤和样板文件,并且并不总是支持您的模型可能使用的所有 PyTorch 和 fastai 层。此外,您所做的工作将取决于您针对部署的移动设备的类型 - 您可能需要做一些工作以在 iOS 设备上运行,不同的工作以在较新的 Android 设备上运行,不同的工作以在较旧的 Android 设备上运行,等等。相反,我们建议在可能的情况下,将模型本身部署到服务器,并让您的移动或边缘应用程序连接到它作为 Web 服务。
这种方法有很多优点。初始安装更容易,因为您只需部署一个小型 GUI 应用程序,该应用程序连接到服务器执行所有繁重的工作。更重要的是,核心逻辑的升级可以在您的服务器上进行,而不需要分发给所有用户。您的服务器将拥有比大多数边缘设备更多的内存和处理能力,并且如果您的模型变得更加苛刻,那么扩展这些资源将更容易。您在服务器上拥有的硬件也将更加标准化,并且更容易受到 fastai 和 PyTorch 的支持,因此您不必将模型编译成不同的形式。
当然也有缺点。你的应用程序将需要网络连接,每次调用模型时都会有一些延迟。(神经网络模型本来就需要一段时间来运行,所以这种额外的网络延迟在实践中可能对用户没有太大影响。事实上,由于你可以在服务器上使用更好的硬件,总体延迟甚至可能比在本地运行时更少!)此外,如果你的应用程序使用敏感数据,你的用户可能会担心采用将数据发送到远程服务器的方法,因此有时隐私考虑将意味着你需要在边缘设备上运行模型(通过在公司防火墙内部设置本地服务器可能可以避免这种情况)。管理复杂性和扩展服务器也可能会带来额外的开销,而如果你的模型在边缘设备上运行,每个用户都会带来自己的计算资源,这将导致随着用户数量的增加更容易扩展(也称为水平扩展)。
Alexis 说
我有机会近距离看到移动机器学习领域在我的工作中是如何变化的。我们提供一个依赖于计算机视觉的 iPhone 应用程序,多年来我们在云中运行我们自己的计算机视觉模型。那时这是唯一的方法,因为那些模型需要大量的内存和计算资源,并且需要几分钟来处理输入。这种方法不仅需要构建模型(有趣!),还需要构建基础设施来确保一定数量的“计算工作机器”始终在运行(可怕),如果流量增加,更多的机器会自动上线,有稳定的存储用于大型输入和输出,iOS 应用程序可以知道并告诉用户他们的工作进展如何等等。如今,苹果提供了 API,可以将模型转换为在设备上高效运行,大多数 iOS 设备都有专用的 ML 硬件,所以这是我们用于新模型的策略。这仍然不容易,但在我们的情况下,为了更快的用户体验和更少地担心服务器,这是值得的。对你来说有效的方法将取决于你试图创建的用户体验以及你个人认为容易做的事情。如果你真的知道如何运行服务器,那就去做。如果你真的知道如何构建本地移动应用程序,那就去做。有很多条路通往山顶。
总的来说,我们建议在可能的情况下尽可能使用简单的基于 CPU 的服务器方法,只要你能够做到。如果你足够幸运拥有一个非常成功的应用程序,那么你将能够在那个时候为更复杂的部署方法进行投资。
恭喜你——你已经成功构建了一个深度学习模型并部署了它!现在是一个很好的时机停下来思考可能出现的问题。
如何避免灾难
在实践中,一个深度学习模型只是一个更大系统中的一部分。正如我们在本章开头讨论的那样,构建数据产品需要考虑整个端到端的过程,从概念到在生产中使用。在这本书中,我们无法希望涵盖所有管理部署数据产品的复杂性,比如管理多个模型版本,A/B 测试,金丝雀发布,刷新数据(我们应该一直增加和增加我们的数据集,还是应该定期删除一些旧数据?),处理数据标记,监控所有这些,检测模型腐烂等等。
在本节中,我们将概述一些需要考虑的最重要问题;关于部署问题的更详细讨论,我们建议您参考 Emmanuel Ameisin(O’Reilly)的优秀著作《构建机器学习驱动的应用程序》。
需要考虑的最大问题之一是,理解和测试深度学习模型的行为比大多数其他代码更困难。在正常软件开发中,您可以分析软件所采取的确切步骤,并仔细研究这些步骤中哪些与您试图创建的期望行为相匹配。但是,对于神经网络,行为是从模型尝试匹配训练数据中产生的,而不是精确定义的。
这可能导致灾难!例如,假设我们真的正在推出一个熊检测系统,将连接到国家公园露营地周围的视频摄像头,并警告露营者有熊靠近。如果我们使用下载的数据集训练的模型,实际上会出现各种问题,比如:
-
处理视频数据而不是图像
-
处理可能不在数据集中出现的夜间图像
-
处理低分辨率摄像头图像
-
确保结果返回得足够快以在实践中有用
-
在照片中很少见到的位置识别熊(例如从背后,部分被灌木覆盖,或者离摄像机很远)
问题的一个重要部分是,人们最有可能上传到互联网的照片是那些能够清晰艺术地展示主题的照片,而这并不是该系统将获得的输入类型。因此,我们可能需要进行大量自己的数据收集和标记以创建一个有用的系统。
这只是更一般的“域外”数据问题的一个例子。也就是说,在生产中,我们的模型可能看到与训练时非常不同的数据。这个问题没有完全的技术解决方案;相反,我们必须谨慎地推出技术。
我们还需要小心的其他原因。一个非常常见的问题是域漂移,即我们的模型看到的数据类型随着时间的推移而发生变化。例如,一个保险公司可能将深度学习模型用作其定价和风险算法的一部分,但随着时间的推移,公司吸引的客户类型和代表的风险类型可能发生如此大的变化,以至于原始训练数据不再相关。
域外数据和域漂移是更大问题的例子:您永远无法完全理解神经网络的所有可能行为,因为它们有太多参数。这是它们最好特性的自然缺点——它们的灵活性,使它们能够解决我们甚至可能无法完全指定首选解决方案的复杂问题。然而,好消息是,有办法通过一个经过深思熟虑的过程来减轻这些风险。这些细节将根据您正在解决的问题的细节而变化,但我们将尝试提出一个高层次的方法,总结在图 2-5 中,我们希望这将提供有用的指导。

图 2-5. 部署过程
在可能的情况下,第一步是使用完全手动的过程,您的深度学习模型方法并行运行,但不直接用于驱动任何操作。参与手动过程的人员应查看深度学习输出,并检查其是否合理。例如,对于我们的熊分类器,公园管理员可以在屏幕上显示所有摄像头的视频源,任何可能的熊目击都会被简单地用红色突出显示。在部署模型之前,公园管理员仍然应该像以前一样警惕;模型只是在这一点上帮助检查问题。
第二步是尝试限制模型的范围,并由人仔细监督。例如,对模型驱动方法进行小范围地理和时间限制的试验。与其在全国各地的每个国家公园推出我们的熊分类器,我们可以选择一个单一的观测站,在一个星期的时间内,让一名公园管理员在每次警报发出之前检查。
然后,逐渐扩大您的推出范围。在这样做时,请确保您有非常好的报告系统,以确保您了解与您的手动流程相比所采取的行动是否发生了重大变化。例如,如果在某个地点推出新系统后,熊警报数量翻倍或减半,您应该非常关注。尝试考虑系统可能出错的所有方式,然后考虑什么措施、报告或图片可以反映出这个问题,并确保您的定期报告包含这些信息。
杰里米说
20 年前,我创办了一家名为 Optimal Decisions 的公司,利用机器学习和优化帮助巨大的保险公司设定价格,影响数千亿美元的风险。我们使用这里描述的方法来管理可能出错的潜在风险。此外,在与客户合作将任何东西投入生产之前,我们尝试通过在他们去年的数据上测试端到端系统的影响来模拟影响。将这些新算法投入生产总是一个非常紧张的过程,但每次推出都取得了成功。
意想不到的后果和反馈循环
推出模型的最大挑战之一是,您的模型可能会改变其所属系统的行为。例如,考虑一个“预测执法”算法,它预测某些社区的犯罪率更高,导致更多警察被派往这些社区,这可能导致这些社区记录更多犯罪,依此类推。在皇家统计学会的论文“预测和服务?”中,Kristian Lum 和 William Isaac 观察到“预测性执法的命名恰如其分:它预测未来的执法,而不是未来的犯罪。”
在这种情况下的部分问题是,在存在偏见的情况下(我们将在下一章中深入讨论),反馈循环可能导致该偏见的负面影响变得越来越严重。例如,在美国已经存在着在种族基础上逮捕率存在显著偏见的担忧。根据美国公民自由联盟的说法,“尽管使用率大致相等,黑人因大麻被逮捕的可能性是白人的 3.73 倍。”这种偏见的影响,以及在美国许多地区推出预测性执法算法,导致 Bärí Williams 在纽约时报中写道:“在我的职业生涯中引起如此多兴奋的技术正在以可能意味着在未来几年,我的 7 岁儿子更有可能因为他的种族和我们居住的地方而被无故定性或逮捕,甚至更糟。”
在推出重要的机器学习系统之前,一个有用的练习是考虑这个问题:“如果它真的很成功会发生什么?”换句话说,如果预测能力非常高,对行为的影响非常显著,那么会发生什么?谁会受到最大影响?最极端的结果可能是什么样的?你怎么知道到底发生了什么?
这样的思考练习可能会帮助你制定一个更加谨慎的推出计划,配备持续监控系统和人类监督。当然,如果人类监督没有被听取,那么它就没有用,因此确保可靠和有弹性的沟通渠道存在,以便正确的人会意识到问题并有权力解决它们。
开始写作吧!
我们的学生发现最有帮助巩固对这一材料的理解的事情之一是把它写下来。尝试教给别人是对你对一个主题的理解的最好测试。即使你从不向任何人展示你的写作,这也是有帮助的,但如果你分享了,那就更好了!因此,我们建议,如果你还没有开始写博客,那么现在就开始吧。现在你已经完成了这一章并学会了如何训练和部署模型,你已经可以写下你的第一篇关于深度学习之旅的博客文章了。你有什么惊讶?你在你的领域看到了深度学习的机会?你看到了什么障碍?
fast.ai 的联合创始人 Rachel Thomas 在文章“为什么你(是的,你)应该写博客”中写道:
我会给年轻的自己的最重要建议是尽早开始写博客。以下是一些写博客的理由:
- 这就像一份简历,只不过更好。我知道有几个人因为写博客文章而得到了工作机会!
- 帮助你学习。组织知识总是帮助我整合自己的想法。是否理解某事的一个测试是你是否能够向别人解释它。博客文章是一个很好的方式。
- 我通过我的博客文章收到了参加会议的邀请和演讲邀请。我因为写了一篇关于我不喜欢 TensorFlow 的博客文章而被邀请参加 TensorFlow Dev Summit(太棒了!)。
- 结识新朋友。我认识了几个回复我写的博客文章的人。
- 节省时间。每当你通过电子邮件多次回答同一个问题时,你应该把它变成一篇博客文章,这样下次有人问起时你就更容易分享了。
也许她最重要的建议是:
你最适合帮助比你落后一步的人。这些材料仍然新鲜在你的脑海中。许多专家已经忘记了作为初学者(或中级学习者)时的感受,忘记了当你第一次听到这个话题时为什么难以理解。你特定背景、风格和知识水平的背景将为你所写的内容带来不同的视角。
我们已经提供了如何在附录 A 中设置博客的详细信息。如果你还没有博客,现在就看看吧,因为我们有一个非常好的方法让你免费开始写博客,没有广告,甚至可以使用 Jupyter Notebook!
问卷调查
-
文本模型目前存在哪些主要不足之处?
-
文本生成模型可能存在哪些负面社会影响?
-
在模型可能犯错且这些错误可能有害的情况下,自动化流程的一个好的替代方案是什么?
-
深度学习在哪种表格数据上特别擅长?
-
直接使用深度学习模型进行推荐系统的一个主要缺点是什么?
-
驱动器方法的步骤是什么?
-
驱动器方法的步骤如何映射到推荐系统?
-
使用你策划的数据创建一个图像识别模型,并将其部署在网络上。
-
DataLoaders是什么? -
我们需要告诉 fastai 创建
DataLoaders的四件事是什么? -
DataBlock中的splitter参数是做什么的? -
我们如何确保随机分割总是给出相同的验证集?
-
哪些字母通常用来表示自变量和因变量?
-
裁剪、填充和压缩调整方法之间有什么区别?在什么情况下你会选择其中之一?
-
什么是数据增强?为什么需要它?
-
提供一个例子,说明熊分类模型在生产中可能因训练数据的结构或风格差异而效果不佳。
-
item_tfms和batch_tfms之间有什么区别? -
混淆矩阵是什么?
-
export保存了什么? -
当我们使用模型进行预测而不是训练时,这被称为什么?
-
IPython 小部件是什么?
-
什么时候会使用 CPU 进行部署?什么时候 GPU 可能更好?
-
将应用部署到服务器而不是客户端(或边缘)设备(如手机或 PC)的缺点是什么?
-
在实践中推出熊警告系统时可能出现的三个问题的例子是什么?
-
什么是域外数据?
-
什么是领域转移?
-
部署过程中的三个步骤是什么?
进一步研究
-
考虑一下驱动器方法如何映射到你感兴趣的项目或问题。
-
在什么情况下最好避免某些类型的数据增强?
-
对于你有兴趣应用深度学习的项目,考虑一下这个思维实验,“如果它进展得非常顺利会发生什么?”
-
开始写博客,撰写你的第一篇博客文章。例如,写一下你认为深度学习在你感兴趣的领域可能有用的地方。




![[Vue warn]: Duplicate keys detected: ‘1‘. This may cause an update error.](https://img-blog.csdnimg.cn/direct/e2583e8dce28417eb1fce98d423402f2.png)

{kind=link}