Python-web自动化-Playwright的学习
- 1. 安装playwright
- 2. 界面等待
- 3. 自动化代码助手
- 4. 定位元素
- 1. css selector定位
- 2. xpath定位
- 3. get_by_XXX定位
- 5. 操作元素
- 1. 单选框、复选框
- 2. select下拉框
- 3. 网页操作
- 4. 框架页 frame
- 5. 窗口切换
- 6. 截屏
1. 安装playwright
pip命令
pip install playwright
之后还需要安装对应浏览器的驱动程序,使用命令
playwright install chromium
这是谷歌浏览器的驱动程序的下载
下面这是一段playwright-web自动化实例代码
from playwright.sync_api import sync_playwrightp = sync_playwright().start()
# 启动playwrite driver进程
browser = p.chromium.launch(headless=False)
# 驱动谷歌浏览器 启动浏览器
# headless = False 有界面的page = browser.new_page()
# 创建新页面
page.goto(url='https://www.baidu.com')page.locator('#kw').fill('科技')
# 定位输入框 输入科技
page.locator('#su').click()
# 点击搜索
# 关闭浏览器
browser.close()
# 关闭进程
p.stop()
2. 界面等待
不推荐使用time.sleep方法进行界面等待
因为playwright底层使用的是异步的python库进行各种事件处理,time.sleep会破坏异步框架的处理逻辑。
使用page对象的wait_for_timeout方法达到等待效果,单位为毫秒
page.wait_for_timeout(2000)
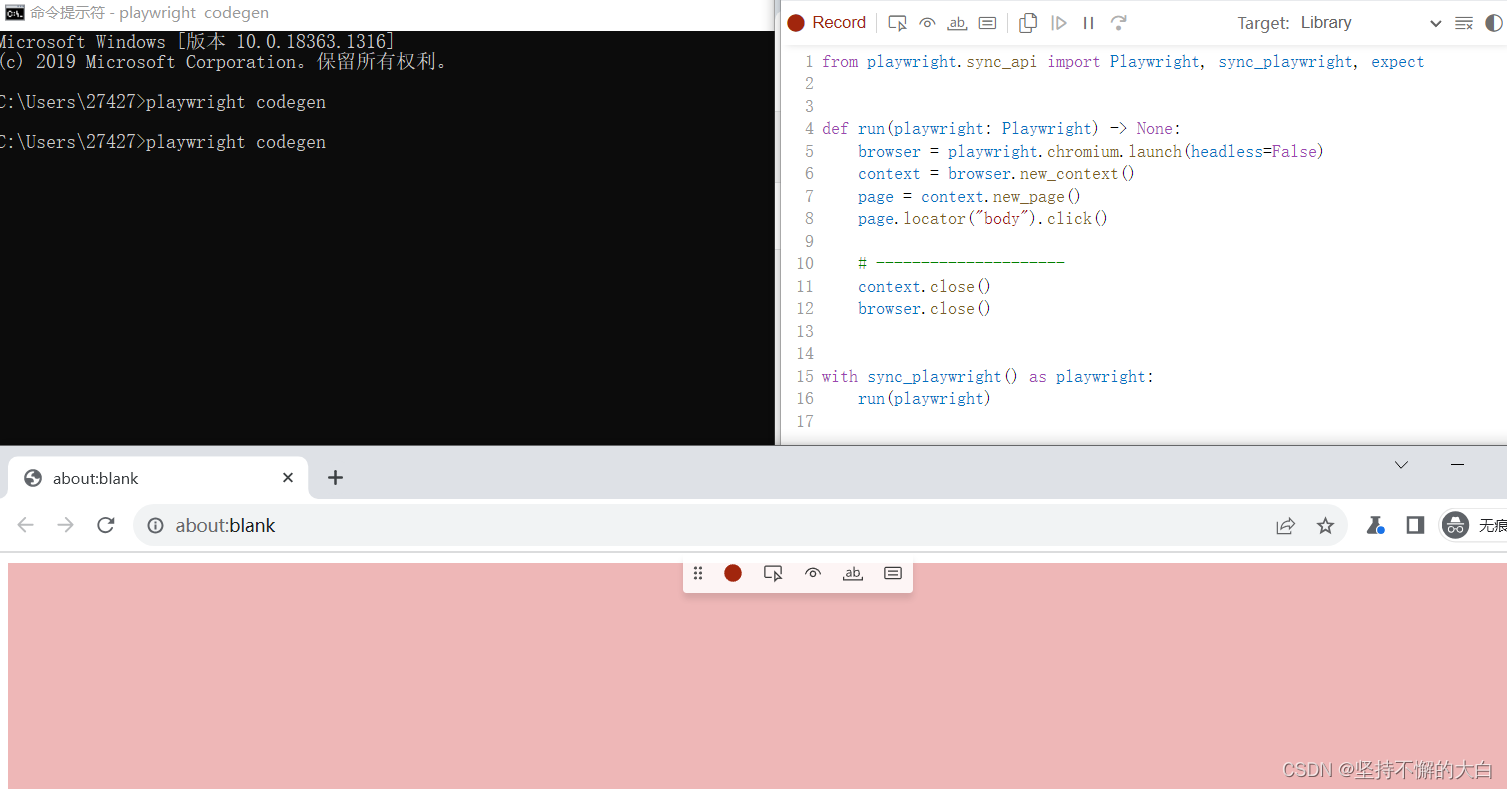
3. 自动化代码助手
输入命令
playwright codegen
相当于selenium中的selenium ide脚本录制工具
4. 定位元素
1. css selector定位
使用Locator类型的对象来进行定位元素,比如上述代码中
page.locator('#kw').fill('科技')
# 定位输入框 输入科技
page.locator('#su').click()
# 点击搜索
locator()就是,之后的fill、click属于元素操作,可以根据tag名、id、class选择元素,这种定位方式如果有一些html/css基础的,应该在定位元素方面基本没有问题,因为这个定位元素的表达式和css样式元素定位基本差不多的。

2. xpath定位
上述代码可以修改为:
page.locator('//input[@id="kw"]').fill('科技')
# 定位输入框 输入科技
page.locator('//input[@id="su"]').click()
# 点击搜索
有一定xpath基础绝对是没有问题的
3. get_by_XXX定位
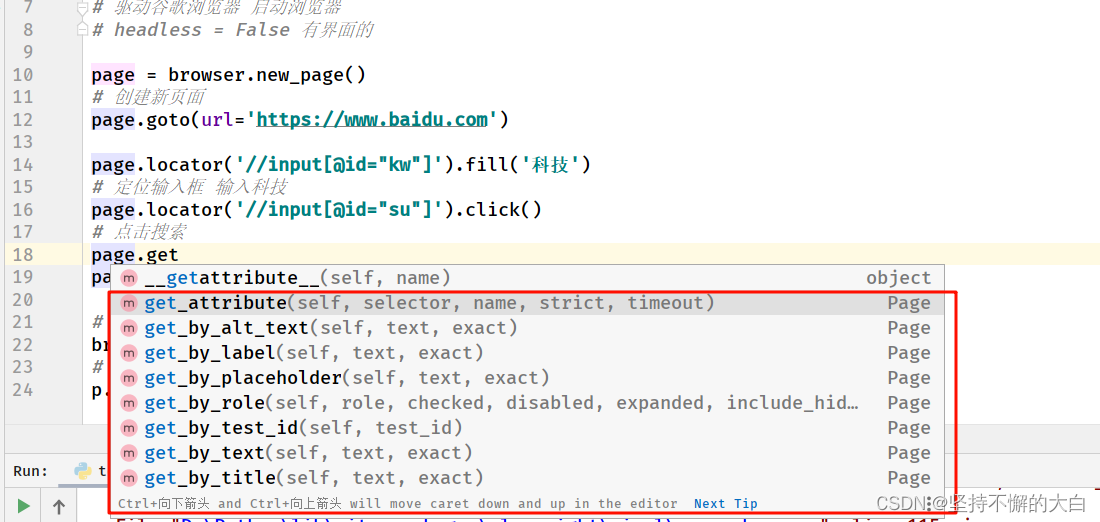
get_attribute只是获取对应元素的某个属性值
5. 操作元素
1.click,点击元素(单击)、dblclick(双击元素)
2. fill,输入文本,clear,清空文本框中的内容,input_value,获取文本框中的内容
3. inner_text,获取元素内部文本
4. all_inner_texts,获取所有匹配的文本
5. text_centent、all_text_contents,和inner_text、all_inner_texts相对应,不同的是text_content、all_text_contents会匹配隐藏元素。
html代码:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>ceshi</title><style>ul{list-style:none;}</style>
</head>
<body><ul><li>混合</li><li style="display:block;">混合2</li><li>混合3</li><li>混合4</li></ul>
</body>
</html>
界面效果:

e1 = page.locator('//ul').all_text_contents()
e2 = page.locator('//ul').all_inner_texts()print(e1)
print(e2)
运行结果:

包含隐藏元素时:
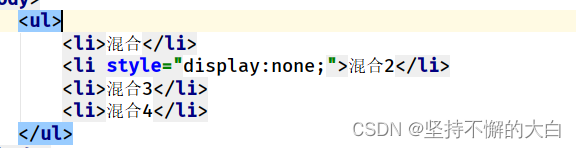
运行结果:

6. inner_html,获取元素内部的HTML
e1 = page.locator('//ul').inner_html()print(e1)
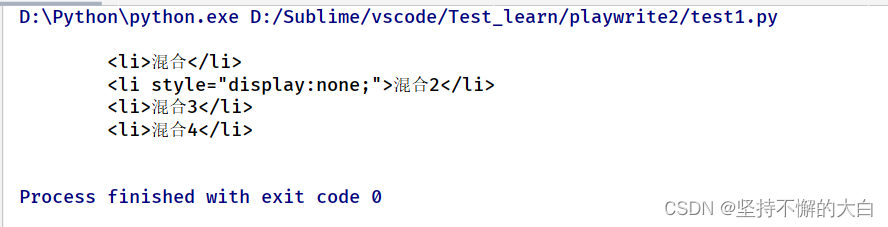
7. 等待元素可见
有个时候我们的代码并不是操作某个元素,而是要等待某个元素出现后,再进行其他操作,可以使用wait_for方法
有两个参数,分别为state、timeout,state,默认值为‘visible’,等待元素可见,如果值为‘hidden’,等待元素消失。
timeout默认值为30秒,超出时长,元素还没有出现,会抛出错误。
8. 判断元素是否可见
is_visible,判断在当前页面是否存在某个元素
9. 文件输入框
通过set_input_files方法
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>ceshi</title>
</head>
<body><input type="file" name="" id="file">
</body>
<script type="text/javascript">const ele = document.querySelector('#file');ele.onchange = function(){let file = this.files[0];console.log(file);}
</script>
</html>
page.goto(url='file:///D:/Sublime/vscode/Test_learn/playwrite2/1.html')
#
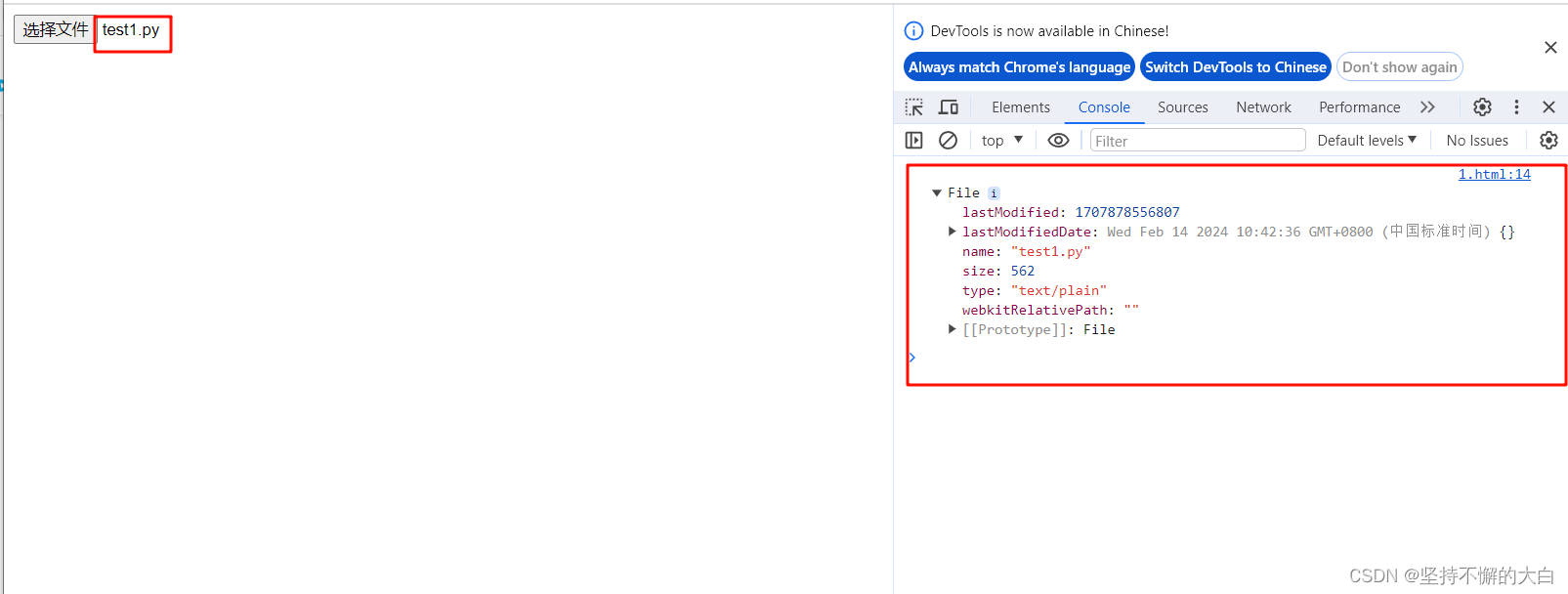
file_ele = page.locator('#file')
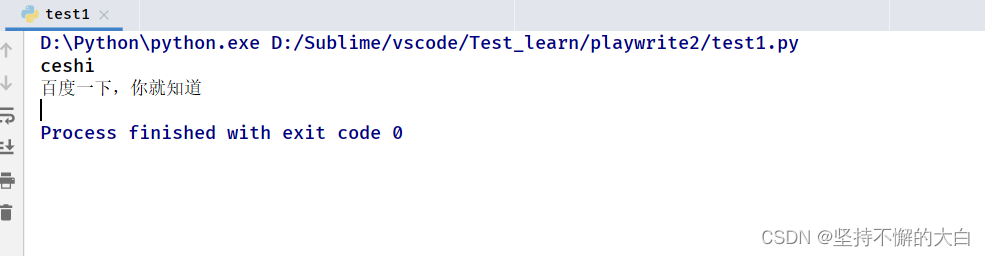
file_ele.set_input_files(r'D:\Sublime\vscode\Test_learn\playwrite2\test1.py')
运行结果:
1. 单选框、复选框
单选框的选择
- 如果要点选radio框,可以使用Locator对象的check方法
- 如果要取消选radio框,可以使用Locator对象的uncheck方法
- 如果要判断radio框是否被选中,可以使用Locator对象的is_checked方法
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>ceshi</title>
</head>
<body><input type="radio" name="gender" value="man" checked> 男<input type="radio" name="gender" value="female"> 女 <br>
</body>
</html>
page.wait_for_timeout(2000)
for e in eles:print(e.is_checked(),e.get_attribute('value'))if not e.is_checked():e.check()# 如果没有选中
page.wait_for_timeout(10000)
运行结果:

复选框
- 如果要点选checkbox框,可以使用Locator对象的check方法
- 如果要取消选checkbox框,可以使用Locator对象的uncheck方法
- 如果要判断checkbox框是否被选中,可以使用Locator对象的is_checked方法
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>ceshi</title>
</head>
<body><input type="checkbox" name="music" value="1"> 1 <br><input type="checkbox" name="music" value="2"> 2 <br><input type="checkbox" name="music" value="3"> 3 <br><input type="checkbox" name="music" value="4"> 4
</body>
</html>
eles = page.locator(selector='[name=music]').all()
page.wait_for_timeout(2000)
for e in eles:v = e.get_attribute('value')if int(v) % 2 == 0:e.check()
运行结果:

2. select下拉框
通过**select_option()**方法,里面的值可以是index、value、lable上的值,但是需要完全匹配才行。
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>ceshi</title>
</head>
<body><select name="sex"><option value="man">男</option><option value="female">女</option></select>
</body>
</html>
page.goto(url='file:///D:/Sublime/vscode/Test_learn/playwrite2/1.html')
page.locator('[name=sex]').select_option(index=1)
默认什么都没有选择,显示为男,现在选择女

3. 网页操作
- page.go_back() 后退
- page.go_forward() 前进
- page.reload() 刷新
4. 框架页 frame
使用frame_locator找到对应frame框架页
1.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>ceshi</title>
</head>
<body><iframe src="./2.html"></iframe>
</body>
</html>
2.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>ceshi2</title>
</head>
<body><p id="name">步文曜</p>
</body>
</html>
frame = page.frame_locator('iframe')
print(frame.locator('#name').inner_text())
运行结果:

5. 窗口切换
需要使用BrowserContext对象创建page
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>ceshi</title>
</head>
<body><p id="baidu">baidu</p><script>const e = document.querySelector('#baidu');e.onclick = function(){window.open('https://www.baidu.com');}</script>
</body>
</html>
page.locator('#baidu').click()
page.wait_for_timeout(2000)
print(context.pages[0].title())
print(context.pages[1].title())
运行结果:
6. 截屏
page.screenshot(path=‘’,full_page=True)
full_page=True,截屏截取不可见的部分,默认为False,只截取可见的部分。