文章目录
- 基于Kaggle电信用户流失案例数据(可在官网进行下载)
- 数据预处理模块
- 时序特征衍生
- 第一轮网格搜索
- 第二轮搜索
- 第三轮搜索
- 第四轮搜索
- 第五轮搜索
基于Kaggle电信用户流失案例数据(可在官网进行下载)
导入库
# 基础数据科学运算库
import numpy as np
import pandas as pd# 可视化库
import seaborn as sns
import matplotlib.pyplot as plt# 时间模块
import timeimport warnings
warnings.filterwarnings('ignore')# sklearn库
# 数据预处理
from sklearn import preprocessing
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OrdinalEncoder
from sklearn.preprocessing import OneHotEncoder# 实用函数
from sklearn.metrics import accuracy_score, recall_score, precision_score, f1_score, roc_auc_score
from sklearn.model_selection import train_test_split# 常用评估器
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier# 网格搜索
from sklearn.model_selection import GridSearchCV# 自定义评估器支持模块
from sklearn.base import BaseEstimator, TransformerMixin# re模块相关
import inspect, re# 其他模块
from tqdm import tqdm
import gc
数据预处理模块
然后进行数据清洗相关工作:
# 读取数据
tcc = pd.read_csv('WA_Fn-UseC_-Telco-Customer-Churn.csv')# 标注连续/离散字段
# 离散字段
category_cols = ['gender', 'SeniorCitizen', 'Partner', 'Dependents','PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling','PaymentMethod']# 连续字段
numeric_cols = ['tenure', 'MonthlyCharges', 'TotalCharges']# 标签
target = 'Churn'# ID列
ID_col = 'customerID'# 验证是否划分能完全
assert len(category_cols) + len(numeric_cols) + 2 == tcc.shape[1]# 连续字段转化
tcc['TotalCharges']= tcc['TotalCharges'].apply(lambda x: x if x!= ' ' else np.nan).astype(float)
tcc['MonthlyCharges'] = tcc['MonthlyCharges'].astype(float)# 缺失值填补
tcc['TotalCharges'] = tcc['TotalCharges'].fillna(0)# 标签值手动转化
tcc['Churn'].replace(to_replace='Yes', value=1, inplace=True)
tcc['Churn'].replace(to_replace='No', value=0, inplace=True)features = tcc.drop(columns=[ID_col, target]).copy()
labels = tcc['Churn'].copy()
时序特征衍生
# 定义辅助函数
def colName(ColumnTransformer, numeric_cols, category_cols):col_name = []col_value = ColumnTransformer.named_transformers_['cat'].categories_for i, j in enumerate(category_cols):if len(col_value[i]) == 2:col_name.append(j)else:for f in col_value[i]:feature_name = j + '_' + fcol_name.append(feature_name)col_name.extend(numeric_cols)return(col_name)
进行简单的时序特征衍生:
# 划分训练集和测试集
train, test = train_test_split(tcc, random_state=22)X_train = train.drop(columns=[ID_col, target]).copy()
X_test = test.drop(columns=[ID_col, target]).copy()y_train = train['Churn'].copy()
y_test = test['Churn'].copy()X_train_seq = pd.DataFrame()
X_test_seq = pd.DataFrame()# 年份衍生
X_train_seq['tenure_year'] = ((72 - X_train['tenure']) // 12) + 2014
X_test_seq['tenure_year'] = ((72 - X_test['tenure']) // 12) + 2014# 月份衍生
X_train_seq['tenure_month'] = (72 - X_train['tenure']) % 12 + 1
X_test_seq['tenure_month'] = (72 - X_test['tenure']) % 12 + 1# 季度衍生
X_train_seq['tenure_quarter'] = ((X_train_seq['tenure_month']-1) // 3) + 1
X_test_seq['tenure_quarter'] = ((X_test_seq['tenure_month']-1) // 3) + 1# 独热编码
enc = preprocessing.OneHotEncoder()
enc.fit(X_train_seq)seq_new = list(X_train_seq.columns)# 创建带有列名称的独热编码之后的df
X_train_seq = pd.DataFrame(enc.transform(X_train_seq).toarray(), columns = cate_colName(enc, seq_new, drop=None))X_test_seq = pd.DataFrame(enc.transform(X_test_seq).toarray(), columns = cate_colName(enc, seq_new, drop=None))# 调整index
X_train_seq.index = X_train.index
X_test_seq.index = X_test.index
ord_enc = OrdinalEncoder()
ord_enc.fit(X_train[category_cols])X_train_OE = pd.DataFrame(ord_enc.transform(X_train[category_cols]), columns=category_cols)
X_train_OE.index = X_train.index
X_train_OE = pd.concat([X_train_OE, X_train[numeric_cols]], axis=1)X_test_OE = pd.DataFrame(ord_enc.transform(X_test[category_cols]), columns=category_cols)
X_test_OE.index = X_test.index
X_test_OE = pd.concat([X_test_OE, X_test[numeric_cols]], axis=1)
第一轮网格搜索
| Name | Description |
|---|---|
| n_estimators | 决策树模型个数 |
| criterion | 规则评估指标或损失函数,默认基尼系数,可选信息熵 |
| splitter | 树模型生长方式,默认以损失函数取值减少最快方式生长,可选随机根据某条件进行划分 |
| max_depth | 树的最大生长深度,类似max_iter,即总共迭代几次 |
| min_samples_split | 内部节点再划分所需最小样本数 |
| min_samples_leaf | 叶节点包含最少样本数 |
| min_weight_fraction_leaf | 叶节点所需最小权重和 |
| max_features | 在进行切分时候最多带入多少个特征进行划分规则挑选 |
| random_state | 随机数种子 |
| max_leaf_nodes | 叶节点最大个数 |
| min_impurity_decrease | 数据集再划分至少需要降低的损失值 |
| bootstrap | 是否进行自助抽样 |
| oob_score | 是否输出袋外数据的测试结果 |
| min_impurity_split | 数据集再划分所需最低不纯度,将在0.25版本中移除 |
| class_weight | 各类样本权重 |
| ccp_alpha | 决策树限制剪枝参数,相当于风险项系数 |
| max_samples | 进行自助抽样时每棵树分到的样本量 |
随机森林需要搜索的7个参数及其第一轮搜索时建议的参数空间如下:
| params | 经验最优范围 |
|---|---|
| min_samples_leaf | [1, 4, 7]; range(1, 10, 3) |
| min_samples_split | [1, 4, 7]; range(1, 10, 3) |
| max_depth | [5, 10, 15]; range(5, 16, 5) |
| max_leaf_nodes | [None, 20, 40, 60]; [None] + list(range(20, 70, 20)) |
| n_estimators | [10, 80, 150]; range(10, 160, 70) |
| max_features | [‘sqrt’, ‘log2’] +[ l o g 2 ( m ) log_2{(m)} log2(m)*50%, m \sqrt{m} m*150%] 其中m为特征数量 |
| max_samples | [None, 0.4, 0.5, 0.6] |
start = time.time()# 设置超参数空间
parameter_space = {"min_samples_leaf": range(1, 10, 3), "min_samples_split": range(1, 10, 3),"max_depth": range(5, 16, 5),"max_leaf_nodes": [None] + list(range(20, 70, 20)), "n_estimators": range(10, 160, 70), "max_features":['sqrt', 'log2'] + list(range(2, 7, 2)), "max_samples":[None, 0.4, 0.5, 0.6]}# 实例化模型与评估器
RF_0 = RandomForestClassifier(random_state=12)
grid_RF_0 = GridSearchCV(RF_0, parameter_space, n_jobs=15)# 模型训练
grid_RF_0.fit(X_train_OE, y_train)grid_RF_0.score(X_train_OE, y_train), grid_RF_0.score(X_test_OE, y_test)
对比之前逻辑回归结果显示:
| Models | CV.best_score_ | train_score | test_score |
|---|---|---|---|
| Logistic+grid | 0.8045 | 0.8055 | 0.7932 |
| RF+grid_R1 | 0.8084 | 0.8517 | 0.7848 |
# 查看超参数最优取值
grid_RF_0.best_params_

- max_depth本轮最优取值为10,而原定搜索空间为[5, 10, 15],因此第二轮搜索时就可以以10为中心,缩小步长,进行更精准的搜索;
- max_features本轮最优取值为sqrt,说明最优解极有可能在4附近,因此第二轮搜索时可以设置一组更加精准的在4附近的数值,搭配sqrt参数一起进行搜索;
- max_leaf_nodes本轮最优取值为None,则有可能说明上一轮给出的其他备选数值不够激进,下一轮搜索时可以在一个更大的区间范围内设置备选数值;
- max_samples本轮最优取值为0.4,下一轮可以以0.4为中心,设置一组跨度更小、精度更高的取值进行搜索;
- min_samples_leaf本轮最优取值为1,下一轮可以设置range(1, 4)进行搜索(参数不能取得比1更小的值);
- min_samples_split本轮最优取值为7,下一轮可以以7为中心,设置更小的范围进行搜索;
- n_estimators本轮最优取值为80,下一轮可以以80为中心,设置更小的范围进行搜索,但需要注意的是,上一轮n_estimators取值搜索的跨度为70,下轮搜索时可以缩减到10。
第二轮搜索
start = time.time()# 设置超参数空间
parameter_space = {"min_samples_leaf": range(1, 4), "min_samples_split": range(6, 9),"max_depth": range(9, 12),"max_leaf_nodes": [None] + list(range(10, 100, 30)), "n_estimators": range(70, 100, 10), "max_features":['sqrt'] + list(range(2, 5)), "max_samples":[None, 0.35, 0.4, 0.45]}# 实例化模型与评估器
RF_0 = RandomForestClassifier(random_state=12)
grid_RF_0 = GridSearchCV(RF_0, parameter_space, n_jobs=15)# 模型训练
grid_RF_0.fit(X_train_OE, y_train)grid_RF_0.score(X_train_OE, y_train), grid_RF_0.score(X_test_OE, y_test)
| Models | CV.best_score_ | train_score | test_score |
|---|---|---|---|
| Logistic+grid | 0.8045 | 0.8055 | 0.7932 |
| RF+grid_R1 | 0.8084 | 0.8517 | 0.7848 |
| RF+grid_R2 | 0.8088 | 0.8459 | 0.7922 |
grid_RF_0.best_params_
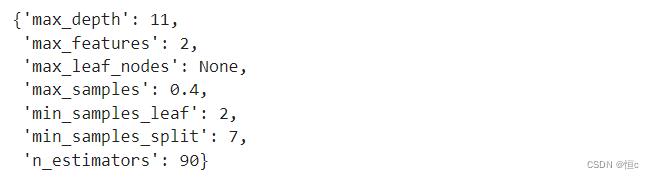
- max_depth本轮最优取值为11,在原定搜索空间上界,下次搜索可以进一步向上拓展搜索空间;
- max_features本轮最优取值为2,是原定搜索空间的下界,下次搜索可向下拓展搜索空间,也就是将1带入进行搜索。但需要注意的是,sqrt作为非数值型结果,仍然需要带入进行搜索,这轮被淘汰并不代表重新调整搜索空间后仍然被淘汰;
- max_leaf_nodes本轮最优取值仍然为None,说明在一个更大的范围内进行更激进的搜索并没有达到预想的效果,下一轮可以反其道而行之,设置一个上一轮没有搜索到的数值较小的空间(1-20),来进行更加精准的搜索;
- max_samples本轮最优取值仍然为0.4,基本可以确定最优取值就在0.4附近,下一轮可以进一步设置一个步长更小的区间进行搜索;
- min_samples_leaf本轮最优取值为2,恰好落在本轮搜索空间的中间,下一轮搜索时不用调整取值;
- min_samples_split本轮最优取值仍然为7,恰好落在本轮搜索空间的中间,下一轮搜索时不用调整取值;
- n_estimators本轮最优取值为90,下一轮可以以90为中心,设置更小的范围进行搜索,但需要注意的是,上一轮n_estimators取值搜索的跨度为10,下轮搜索时可以缩减到4。
第三轮搜索
start = time.time()# 设置超参数空间
parameter_space = {"min_samples_leaf": range(1, 4), "min_samples_split": range(6, 9),"max_depth": range(10, 15),"max_leaf_nodes": [None] + list(range(1, 20, 2)), "n_estimators": range(85, 100, 4), "max_features":['sqrt'] + list(range(1, 4)), "max_samples":[None, 0.38, 0.4, 0.42]}# 实例化模型与评估器
RF_0 = RandomForestClassifier(random_state=12)
grid_RF_0 = GridSearchCV(RF_0, parameter_space, n_jobs=15)# 模型训练
grid_RF_0.fit(X_train_OE, y_train)grid_RF_0.score(X_train_OE, y_train), grid_RF_0.score(X_test_OE, y_test)
| Models | CV.best_score_ | train_score | test_score |
|---|---|---|---|
| Logistic+grid | 0.8045 | 0.8055 | 0.7932 |
| RF+grid_R1 | 0.8084 | 0.8517 | 0.7848 |
| RF+grid_R2 | 0.808785 | 0.8459 | 0.7922 |
| RF+grid_R3 | 0.808784 | 0.8415 | 0.7927 |
grid_RF_0.best_params_

- max_depth本轮最优取值为10,在原定搜索空间下界,下次搜索可以进一步向下拓展搜索空间,当然,根据第二轮第三轮max_depth在9和10反复变动的现象,估计max_depth最终的最优取值也就是9、10左右;
- max_features本轮最优取值又回到了sqrt,也就是4附近,结合第一轮sqrt的最优结果,预计max_features最终最优取值也就在4附近,接下来的搜索将是收尾阶段,我们可以设计一个sqrt+log2+4附近的搜索组合;
- max_leaf_nodes本轮最优取值仍然为None,三轮搜索都没有改变max_leaf_nodes的最优取值,并且本轮还设置了非常多的备选取值,说明max_leaf_nodes的最优取值极有可能就是None,接下来我们只需保留None+大范围搜索的组合即可,以防其他参数变动时max_leaf_nodes的最优取值发生变化;
- max_samples本轮最优取值变成了0.38,而训练集总样本数为5282,5282*0.38约为2007,下轮开始我们将把比例转化为具体的样本数,进行更加精准的搜索,及围绕2007附近的数值空间进行搜索;
- min_samples_leaf本轮最优取值为3,恰好落在本轮搜索空间的上届,下一轮搜索时略微拓展搜索空间的上界;
- min_samples_split本轮最优取值仍然为7,恰好落在本轮搜索空间的中间,下一轮搜索时不用调整取值;
- n_estimators本轮最优取值为97,下一轮可以以97为中心,设置更小的范围进行搜索;
第四轮搜索
start = time.time()# 设置超参数空间
parameter_space = {"min_samples_leaf": range(2, 5), "min_samples_split": range(6, 9),"max_depth": range(8, 12),"max_leaf_nodes": [None] + list(range(10, 70, 20)), "n_estimators": range(95, 105, 2), "max_features":['sqrt', 'log2'] + list(range(1, 6, 2)), "max_samples":[None] + list(range(2002, 2011, 2))}# 实例化模型与评估器
RF_0 = RandomForestClassifier(random_state=12)
grid_RF_0 = GridSearchCV(RF_0, parameter_space, n_jobs=15)# 模型训练
grid_RF_0.fit(X_train_OE, y_train)grid_RF_0.score(X_train_OE, y_train), grid_RF_0.score(X_test_OE, y_test)
| Models | CV.best_score_ | train_score | test_score |
|---|---|---|---|
| Logistic+grid | 0.8045 | 0.8055 | 0.7932 |
| RF+grid_R1 | 0.8084 | 0.8517 | 0.7848 |
| RF+grid_R2 | 0.808785 | 0.8459 | 0.7922 |
| RF+grid_R3 | 0.808784 | 0.8415 | 0.7927 |
| RF+grid_R4 | 0.809542 | 0.8406 | 0.7882 |
grid_RF_0.best_params_
 - max_depth本轮最优取值为9,能够进一步肯定max_depth最终的最优取值也就是9、10左右;
- max_depth本轮最优取值为9,能够进一步肯定max_depth最终的最优取值也就是9、10左右;
- max_features本轮最优取值变成了5,仍然在4附近变化,后续继续保留sqrt+log2+4附近的搜索组合;
- max_leaf_nodes本轮最优取值仍然为None,并没有发生任何变化,后续仍然保留原定搜索范围;
- max_samples本轮最优取值为2002,这是第一次围绕max_samples进行整数搜索,接下来可以以2002为中心,设置一个更小搜索空间;
- min_samples_leaf本轮最优取值为3,恰好落在本轮搜索空间的上届,下一轮搜索时略微拓展搜索空间的上界;
- min_samples_split本轮最优取值变成了8,根据之前的搜索结果,该参数最优取值基本都在7和8之间变动,因此可以设置一个6-9的搜索空间,确保下次如果再出现参数在7、8之间变动时,仍然在搜索范围内;
- n_estimators本轮最优取值为99,结合之前搜索出来的97的结果,预计该参数最终的最优取值应该就是97-99之间,可以据此设置下一轮搜索空间;
第五轮搜索
# "min_samples_leaf":以3为中心
# "min_samples_split":重点搜索7、8两个值
# "max_depth":重点搜索9、10两个值
# "max_leaf_nodes":大概率为None
# "n_estimators": 重点搜索97、98、99三个值
# "max_features":5附近的值+['sqrt', 'log2']
# "max_samples":2002向下搜索,重点搜索2002、2001和2000三个值# 设置超参数空间
parameter_space = {"min_samples_leaf": range(2, 5), "min_samples_split": range(6, 10),"max_depth": range(8, 12),"max_leaf_nodes": [None], "n_estimators": range(96, 101), "max_features":['sqrt', 'log2'] + list(range(3, 7)), "max_samples":[None] + list(range(2000, 2005))}# 实例化模型与评估器
RF_0 = RandomForestClassifier(random_state=12)
grid_RF_0 = GridSearchCV(RF_0, parameter_space, n_jobs=15)# 模型训练
grid_RF_0.fit(X_train_OE, y_train)grid_RF_0.score(X_train_OE, y_train), grid_RF_0.score(X_test_OE, y_test)
| Models | CV.best_score_ | train_score | test_score |
|---|---|---|---|
| Logistic+grid | 0.8045 | 0.8055 | 0.7932 |
| RF+grid_R1 | 0.8084 | 0.8517 | 0.7848 |
| RF+grid_R2 | 0.808785 | 0.8459 | 0.7922 |
| RF+grid_R3 | 0.808784 | 0.8415 | 0.7927 |
| RF+grid_R4 | 0.809542 | 0.8406 | 0.7882 |
| RF+grid_R5 | 0.810488 | 0.8483 | 0.7955 |
grid_RF_0.best_params_

至此,大致得到最优结果,往后调优思路可大致照此.



![[GXYCTF2019]禁止套娃](https://img-blog.csdnimg.cn/direct/119757a5b6c34c329dd0f40277c07343.png)