一、缓存穿透
缓存穿透是指查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库
比如一个get请求:api/getById/1
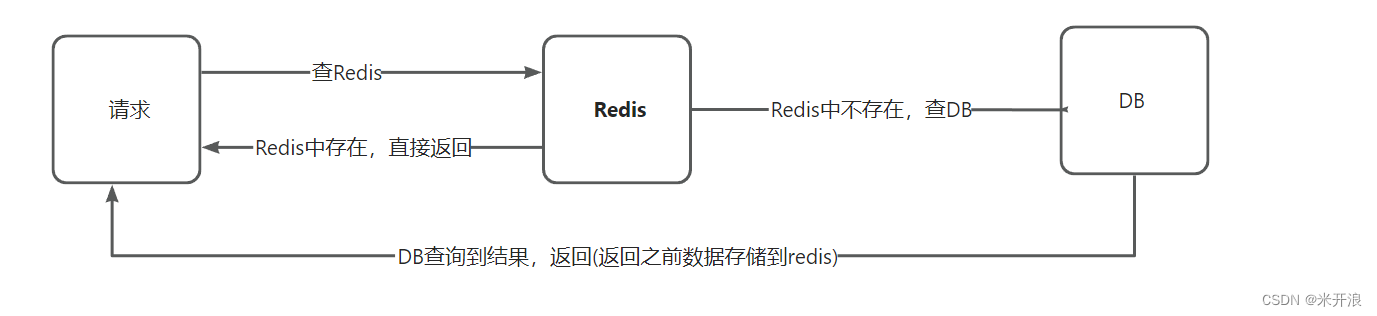
解决方案一:缓存空数据,查询返回的数据为空,仍把这个空结果进行缓存
优点:简单
缺点:消耗内存,可能会发生不一致的问题
解决方案二:布隆过滤器
优点:内存占用较少,没有多余key
缺点:实现复杂,存在误判

布隆过滤器
bitmap(位图):相当于是一个以(bit)位为单位的数组,数组中每个单元只能存储二进制数01布隆过滤器作用:布隆过滤器可以用于检索一个元素是否在一个集合中。
存储数据:id为1的数据,通过多个hash函数获取hash值,根据hash计算数组对应位置改为1
查询数据:使用相同hash函数获取hash值,判断对应位置是否都为1
判率:数组越小误判率就越大,数组越大误判率就越小,但是同时带来了更多的内存消耗。
二、缓存击穿
缓存击穿:给某一个key设置了过期时间,当key过期的时候,恰好这时间点对这个key有大量的并发请求过来,这些并发的请求可能会瞬间把DB压垮
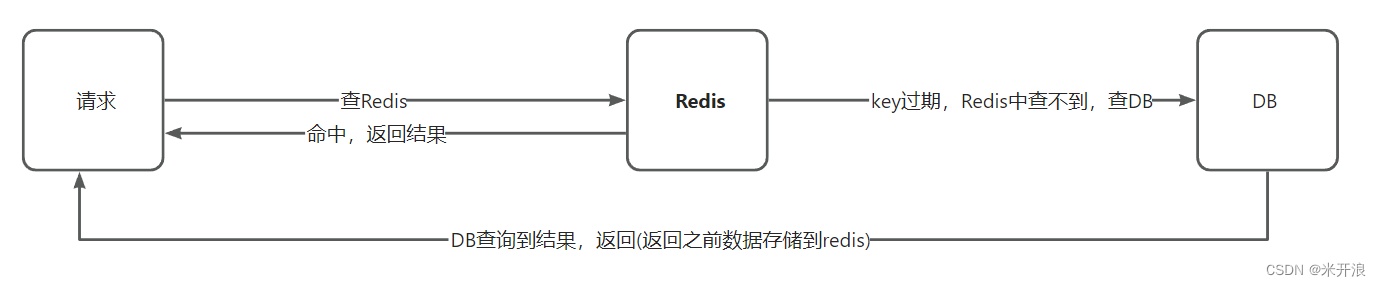
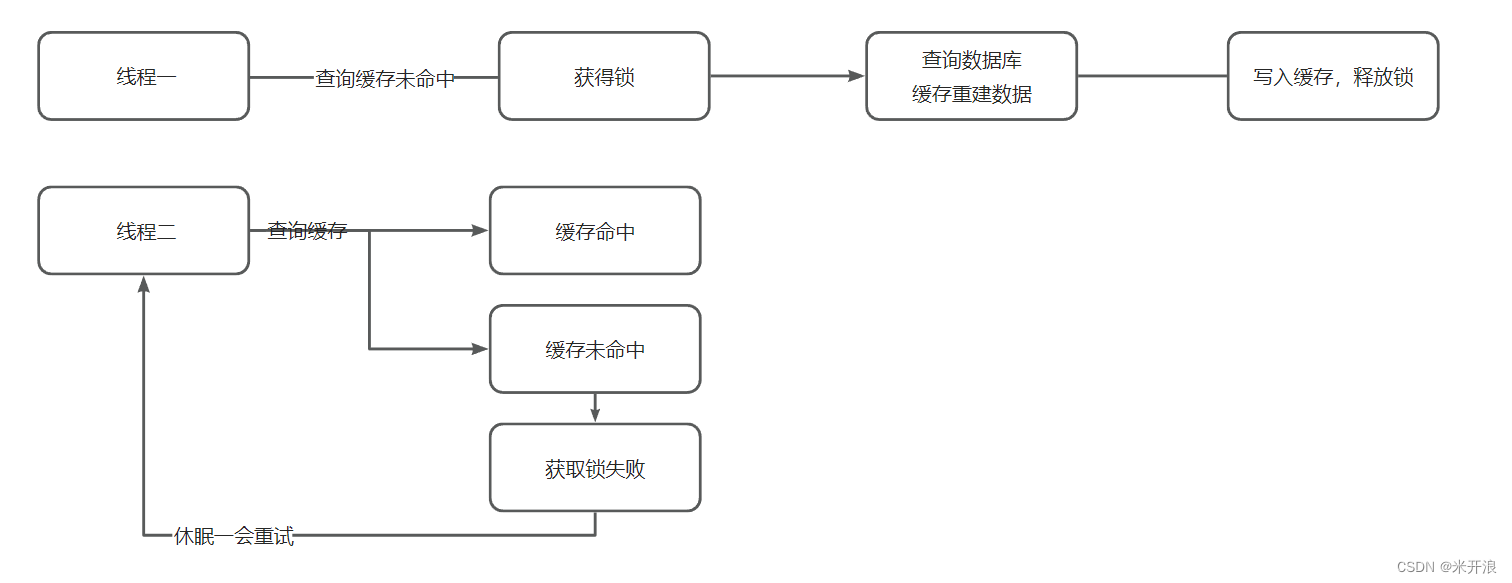
解决方案一:互斥锁
优点:数据强一致性
缺点:性能低
解决方案二: 设置热点数据永不过期
对于某个频繁被访问的数据,缓存在Redis中,且设置key永不过期;
缺点:简单粗暴,对于某些业务场景不适用——热点数据越来越多时
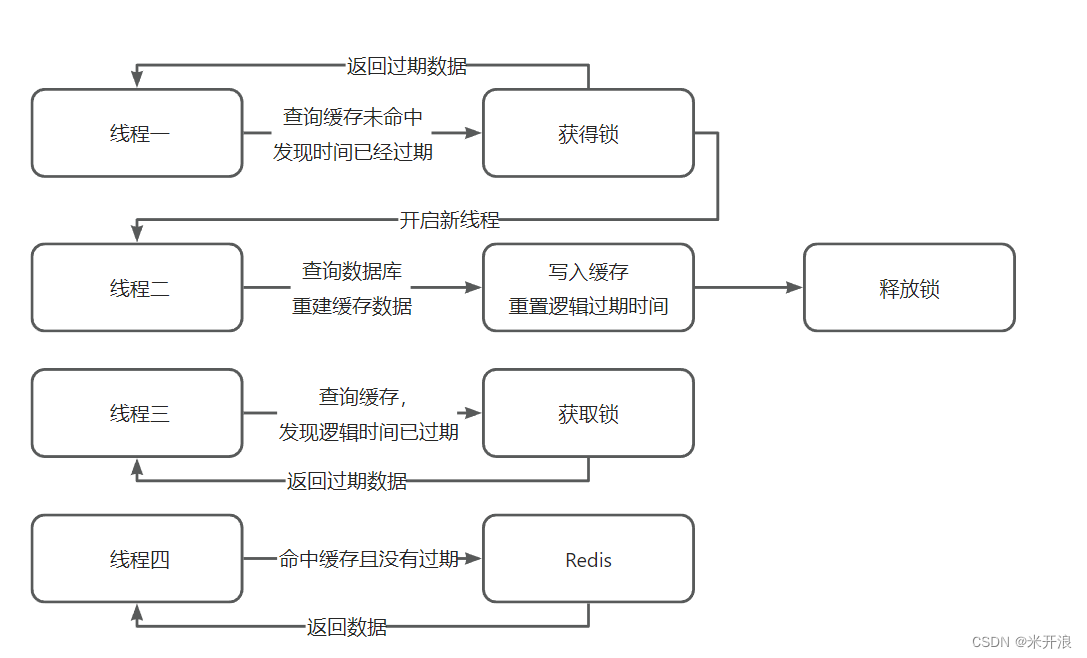
解决方案三:设置逻辑过期
1、在设置key的时候,设置一个过期时间字段一块存入缓存中,不给当前key设置过期时间
2、当查询的时候,从redis取出数据后判断时间是否过期
3、如果过期则开通另外一个线程进行数据同步,当前线程正常返回数据,这个数据不是最新
三、缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力
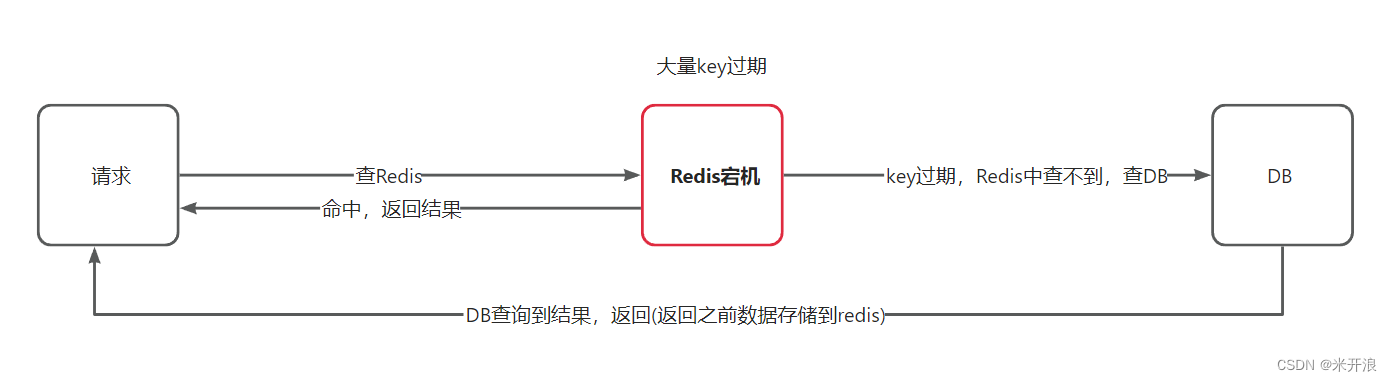
解决方案:
给不同的Key的TTL添加随机值
利用Redis集群提高服务的可用性 (哨兵模式、集群模式)
给缓存业务添加降级限流策略(ngxin或spring cloud gateway)
给业务添加多级缓存(Guava或Caffeine)